Содержание
Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots. txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы.
 Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами. - Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
 Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.
 php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots. txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots. txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
- 2.
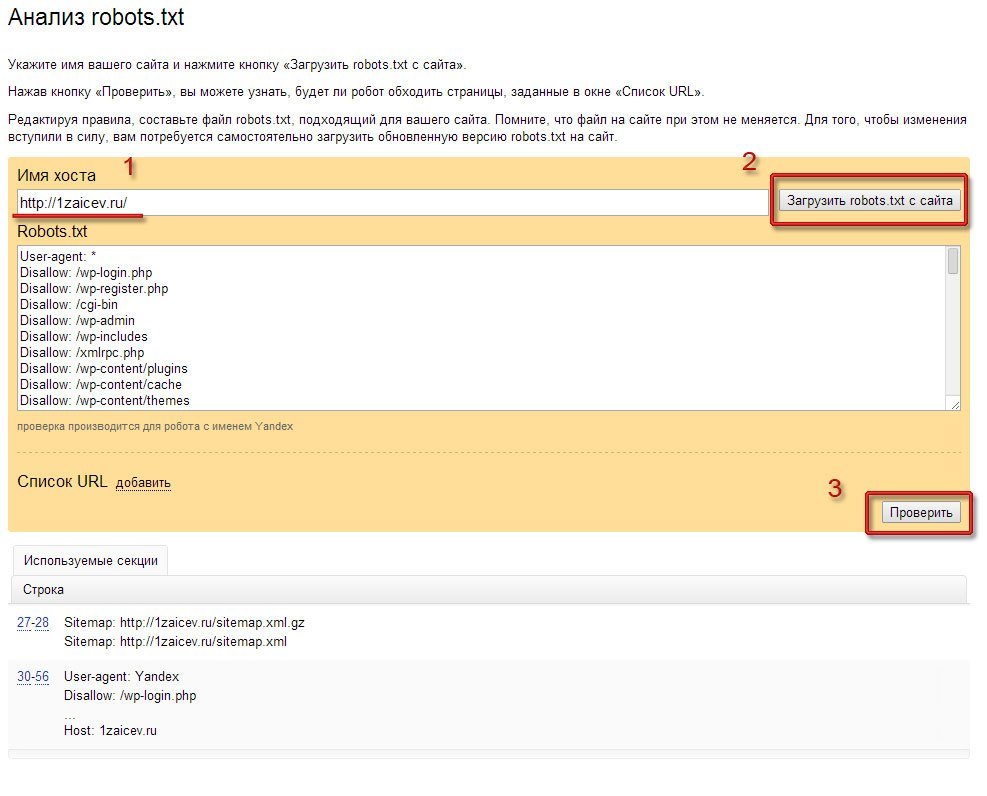
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
- 3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
 org/HowToStep»>
org/HowToStep»>4.
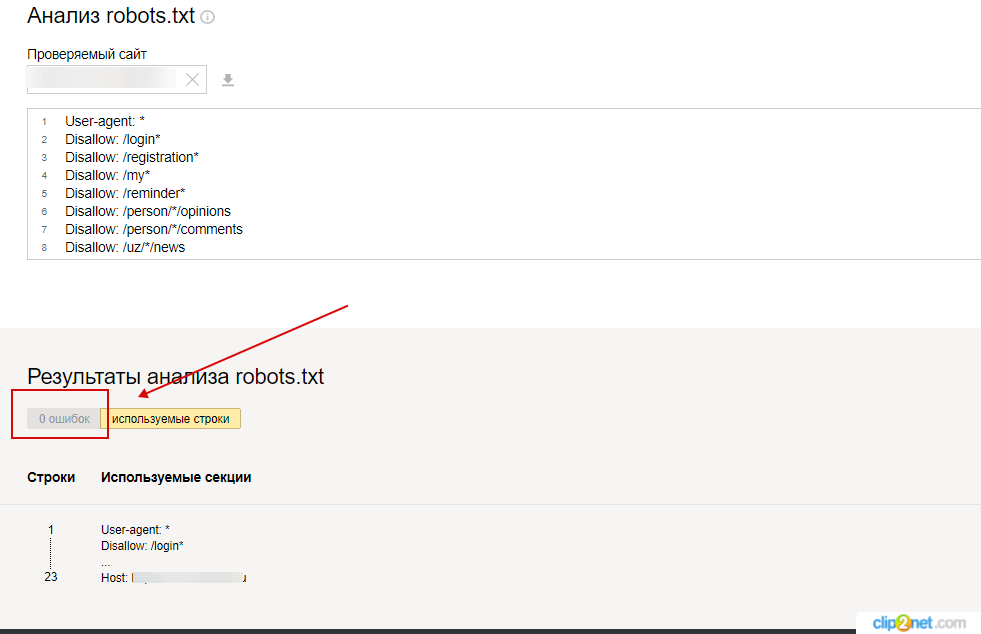
Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 1.
Перейдите на страницу инструмента проверки.
- 2.
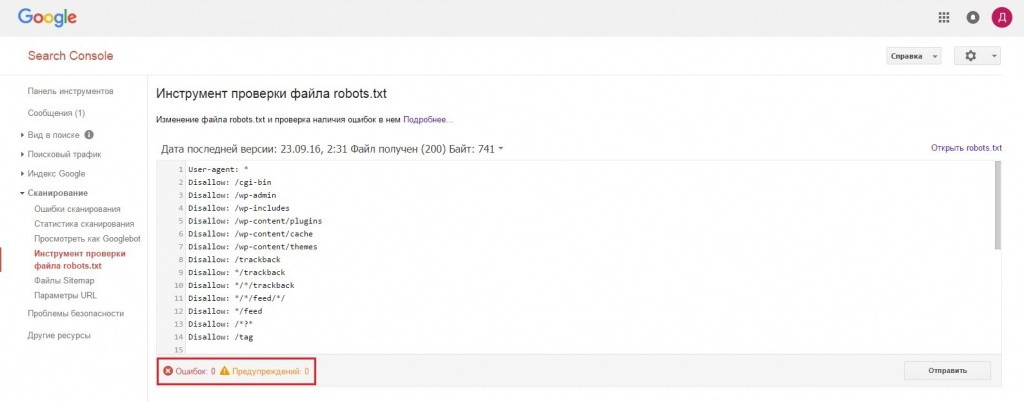
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
- 3.
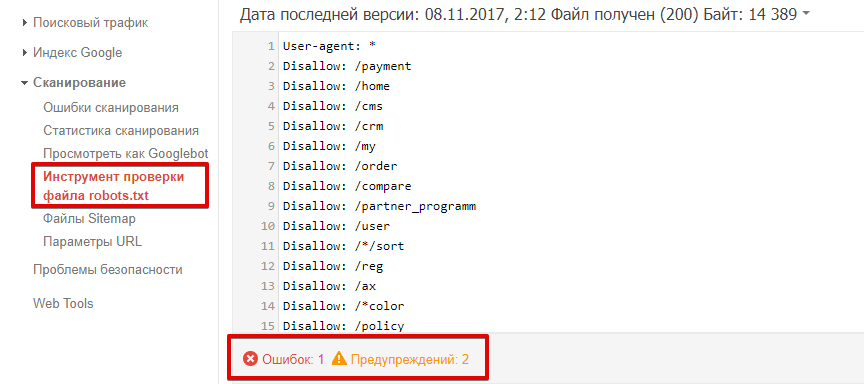
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots. txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
раз уже помогла
Robots.txt как создать и правильно настроить
Последнее обновление: 08 ноября 2022 года
26206
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем нужен robots.txt?
- Основные директивы файла robots.txt
- Как создать robots.txt?
- Как проверить файл?
Кому будет полезна статья?
- Веб-разработчикам.
- Техническим специалистам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Поисковые роботы или веб-краулеры постоянно индексируют страницы сайтов, собирают информацию и заносят ее в базы данных поисковых систем. Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.txt с помощью доступных инструментов Яндекс и Google.
Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.txt с помощью доступных инструментов Яндекс и Google.
Зачем нужен robots.txt?
Файл robots.txt — служебный файл, который содержит информацию о том, какие страницы сайта доступны для сканирования поисковыми роботами, а какие им посещать нельзя. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
С помощью robots.txt вы можете задать уровень доступа краулеров к сайту и его разделам: полностью запретить индексацию или ограничить сканирование отдельных папок, страниц, файлов, а также закрыть ресурс для роботов, которые не относятся к основным поисковым системам.
Таким образом, создание и правильная настройка robots.txt помогут ускорить процесс индексации сайта, снизить нагрузку на сервер, положительно отразятся на ранжировании сайта в поисковой выдаче.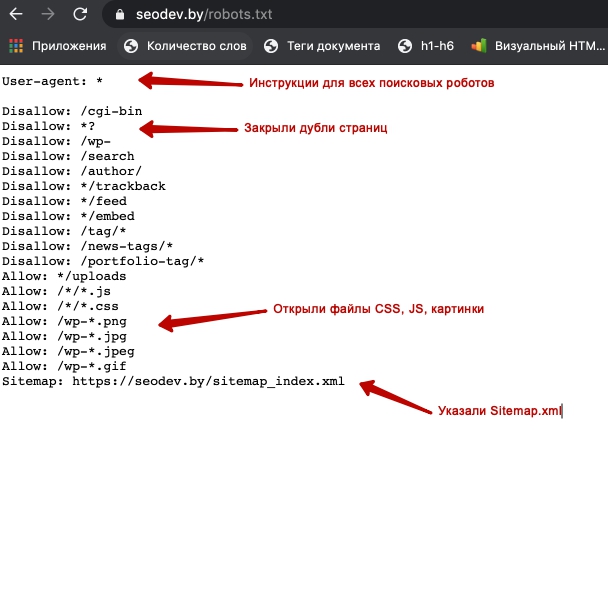
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«Некоторым сайтам файл robots.txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
User-agent: *
Disallow: /tag/
Disallow: /wp-admin/».
Основные директивы файла robots.txt
Чтобы поисковые роботы могли корректно прочитать robots.txt, он должен быть составлен по определенным правилам. Структура служебного файла содержит следующие директивы:
Структура служебного файла содержит следующие директивы:
- User-agent. Директива User-agent определяет уровень открытости сайта для поисковых роботов. Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
Пример:
User-agent: * — сайт доступен для индексации всем краулерам
User-agent: Yandex — доступ открыт только для роботов Яндекса
User-agent: Googlebot — доступ открыт только для роботов Google - Disallow. Директива Disallow определяет, какие страницы сайта необходимо закрыть для индексации. Как правило, для сканирования закрывают весь служебный контент, но при желании вы можете скрыть и любые другие разделы проекта. Подробнее о том, каким страницам и сайтам не нужно индексирование, вы можете прочитать в статье: «Как закрыть сайт от индексации в robots. txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: /wp-admin — служебная папка со всеми вложениями закрыта для индексации
Пример 2:
User-agent: Yandex — правила, размещенные ниже, действуют для роботов Яндекса
Disallow: / — все разделы сайта доступны для индексации - Allow. Директива Allow определяет, какие разделы сайта доступны для сканирования поисковыми роботами. Поскольку все, что не запрещено директивой Disallow, индексируется автоматически, здесь достаточно прописать только исключения из правил. Указывать все доступные краулерам разделы сайта не нужно.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
Allow: /catalog — раздел «Каталог» открыт для всех краулеров
Пример 2:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
User-agent: Googlebot — правила, размещенные ниже, действуют для роботов Google
Allow: / — сайт полностью открыт для роботов Google - Sitemap. Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Пример:
Sitemap: https://site.ru/sitemap.xml
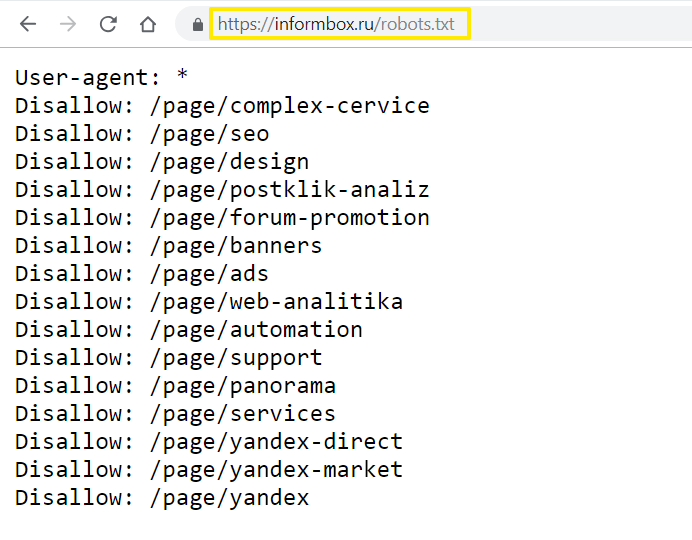 txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
 Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Как создать robots.txt?
Служебный файл robots.txt можно создать в текстовом редакторе Notepad++ или другой аналогичной программе. Весь текст внутри файла должен быть записан латиницей, русские названия можно перевести с помощью любого Punycode-конвертера. Для кодировки файла выбирайте стандарты ASCII или UTF-8.
Чтобы robots.txt корректно индексировался поисковыми роботами, при создании файла следуйте данным ниже рекомендациям:
- Объединяйте директивы в группы. Чтобы избежать путаницы и сократить время индексации, сгруппируйте директивы блоками для каждого поискового робота и разделите блоки пустой строкой. Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
- Учитывайте регистр. Прописывайте имя файла строчными буквами. Если Яндекс информирует, что для его поисковых роботов регистр не имеет значения, то Google рекомендует соблюдать регистр.
- Не указывайте несколько папок в одной директиве. Не объединяйте в одной директиве Disallow несколько папок/файлов. Создавайте отдельную директиву на каждый раздел и файл. Это позволит избежать ошибок при проверке и ускорит процесс индексации.
- Работайте с разными уровнями. В robots.txt вы можете задавать настройки на трех уровнях: сайта, страницы, папки. Используйте эту возможность, если хотите закрыть часть материалов для поисковиков.
- Удаляйте неактуальные директивы. Некоторые директивы robots. txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
- Проверьте соответствие sitemap.xml и robots.txt. Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы информация в них совпадала, и sitemap был включен в одноименную директиву.
 Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
 txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
После создания robots.txt, обратите внимание, чтобы его размер не превышал 32 КБ. При большом объеме файла, он не будет восприниматься поисковыми роботами Яндекс.
Разместите robots.txt в корневой директории сайта рядом с основным файлом index.html. Для этого используйте FTP доступ. Если сайт сделан на CMS, то с файлом можно работать через административную панель.
Как проверить файл?
Удостовериться в том, что файл составлен корректно, можно с помощью инструментов Яндекс.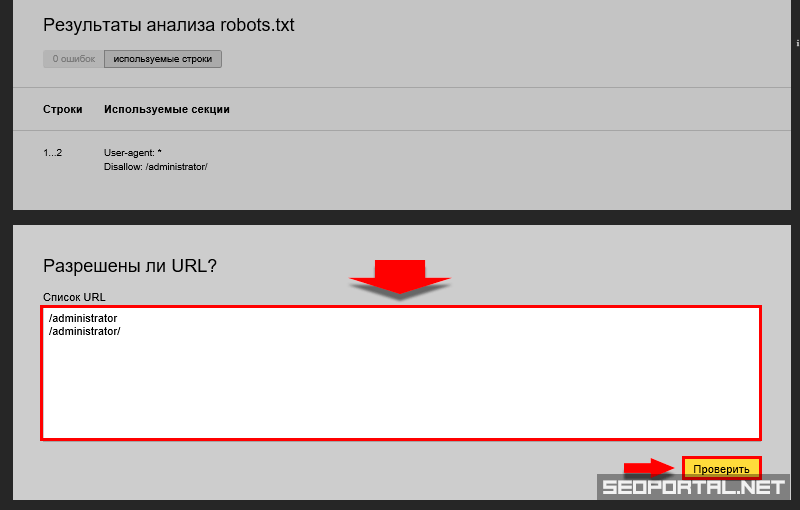 Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Проверка robots.txt в Яндекс.Вебмастер
При первом запуске Яндекс.Вебмастер необходимо создать личный кабинет, добавить сайт и подтвердить свои права на него. После этого вы получите доступ к инструментам сервиса. Для проверки файла нужно зайти в раздел «Инструменты» подраздел «Анализ robots.txt» и запустить тестирование. Если в ходе проверки сервис обнаружит ошибки, он покажет, какие строки требуют корректировки, и что нужно исправить.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«В пункте «Анализ robots.txt» вы также можете «протестировать» написание директив и их влияние на статус индексации. Если Вы сомневаетесь в правильности написания директив, то укажите в поле «Разрешены ли URL?» нужные Вам URL, после чего Вебмастер покажет вам статус индексации этих адресов при указанном robots. txt.».
txt.».
Проверка robots.txt в Google Robots Testing Tool
Проверять robots.txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
Выводы
- Файл robots.txt — это служебный документ, который создается для корректной индексации сайта поисковыми роботами. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
- Файл создается в Notepad++ или любом другом текстовом редакторе. Структура robots. txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
- Заполнять файл следует по правилам, начиная с кода User-agent. Директивы необходимо объединять в группы, отделяя блоки пустой строкой. С помощью директив Disallow и Allow можно запрещать и разрешать индексацию страниц, папок и отдельных файлов.
- Размер robots.txt не должен превышать 32 КБ. Размещать файл необходимо в корневой директории сайта рядом с основным файлом index.html.
- Проверить robots.txt на наличие ошибок можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tools.
 txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
Статья
Продвижение сайта в Яндексе
#SEO, #Яндекс
Статья
Что такое SEO
#SEO, #Яндекс, #Google
Исследование
Факторы ранжирования в «Яндексе» и Google
#SEO, #Яндекс, #Google
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры».
Теги:
SEO, Яндекс, Google
Robots.txt Tester & Validator 2023: БЕСПЛАТНЫЙ онлайн-инструмент
Это поле обязательно к заполнению
URL-адрес недействителен
Пример: www.websiteplanet.com/robots.txt
01
Простота использования:
Проверить точность файла robots.txt еще никогда не было так просто. Просто вставьте свой полный URL-адрес с /robots.txt, нажмите «Ввод», и ваш отчет будет готов быстро.
02
Точность 100%:
Наша программа проверки robots.txt не только найдет ошибки, связанные с опечатками, синтаксическими и «логическими» ошибками, но и даст вам полезные советы по оптимизации.
03
Точно:
Принимая во внимание стандарт исключения роботов и специальные расширения для поисковых роботов, наша программа проверки robots. txt создаст удобный для чтения отчет, который поможет исправить любые ошибки, которые могут быть в вашем файле robots.txt. .
txt создаст удобный для чтения отчет, который поможет исправить любые ошибки, которые могут быть в вашем файле robots.txt. .
Что такое средство проверки и проверки robots.txt?
Инструмент проверки Robots.txt предназначен для проверки правильности файла robots.txt и отсутствия ошибок. Robots.txt — это файл, который является частью вашего веб-сайта и содержит правила индексации для роботов поисковых систем, чтобы убедиться, что ваш веб-сайт сканируется (и индексируется) правильно, а наиболее важные данные на вашем веб-сайте индексируются в первую очередь (все без скрытых cost). Этот инструмент прост в использовании и дает вам отчет за считанные секунды — просто введите полный URL-адрес своего веб-сайта, а затем /robots.txt (например, yourwebsite.com/robots.txt) и нажмите кнопку «Проверить». Наша программа проверки robots.txt найдет любые ошибки (например, опечатки, синтаксические и «логические» ошибки) и даст вам советы по оптимизации вашего файла robots.txt.
Зачем мне проверять файл robots.
 txt?
txt?
Проблемы с файлом robots.txt — или вообще отсутствие файла robots.txt — могут негативно сказаться на ваших результатах SEO, ваш сайт может упасть в рейтинге на страницах результатов поисковой системы (SERP). Это связано с риском того, что нерелевантный контент будет сканироваться раньше или вместо важного контента. Проверка файла до сканирования вашего веб-сайта означает, что вы можете избежать таких проблем, как сканирование и индексирование всего содержимого вашего веб-сайта, а не только страниц. Вы хотите индексацию. Например, если у вас есть страница, к которой вы хотите, чтобы посетители обращались только после заполнения формы подписки, или страница входа участника, но вы не исключили ее в своем файле robot.txt, она может в конечном итоге быть проиндексирована.
Что означают ошибки и предупреждения?
Существует ряд ошибок, которые могут повлиять на ваш файл robots.txt, а также некоторые «рекомендуемые» предупреждения, которые вы можете увидеть при проверке файла. Это вещи, которые могут повлиять на SEO и должны быть исправлены. Предупреждения менее важны и служат советом о том, как улучшить файл robots.txt. Вы можете увидеть следующие ошибки: Неверный URL-адрес — вы увидите эту ошибку, если ваш файл robots.txt полностью отсутствует Потенциальная ошибка с подстановочными знаками — хотя технически это предупреждение, а не ошибка, если вы видите это сообщение, обычно это связано с тем, что ваш файл robots.txt содержит подстановочный знак (*) в поле Disallow (например, Disallow: /*.rss). Это проблема передовой практики — Google разрешает использовать подстановочные знаки в поле «Запретить», но это не рекомендуется. Общие и специальные пользовательские агенты в одном блоке кода — это синтаксическая ошибка в вашем файле robots.txt, которую следует исправить, чтобы избежать проблем со сканированием вашего веб-сайта. Предупреждения, которые вы можете увидеть, включают: Разрешить: / — Использование порядка разрешения не повредит вашему рейтингу и не повлияет на ваш сайт, но это не стандартная практика.
Это вещи, которые могут повлиять на SEO и должны быть исправлены. Предупреждения менее важны и служат советом о том, как улучшить файл robots.txt. Вы можете увидеть следующие ошибки: Неверный URL-адрес — вы увидите эту ошибку, если ваш файл robots.txt полностью отсутствует Потенциальная ошибка с подстановочными знаками — хотя технически это предупреждение, а не ошибка, если вы видите это сообщение, обычно это связано с тем, что ваш файл robots.txt содержит подстановочный знак (*) в поле Disallow (например, Disallow: /*.rss). Это проблема передовой практики — Google разрешает использовать подстановочные знаки в поле «Запретить», но это не рекомендуется. Общие и специальные пользовательские агенты в одном блоке кода — это синтаксическая ошибка в вашем файле robots.txt, которую следует исправить, чтобы избежать проблем со сканированием вашего веб-сайта. Предупреждения, которые вы можете увидеть, включают: Разрешить: / — Использование порядка разрешения не повредит вашему рейтингу и не повлияет на ваш сайт, но это не стандартная практика. Основные роботы, включая Google и Bing, примут эту директиву, но не все поисковые роботы — и, вообще говоря, лучше всего сделать файл robots.txt совместимым со всеми поисковыми роботами, а не только с большими. Использование заглавных букв в именах полей . Хотя имена полей не обязательно чувствительны к регистру, некоторые поисковые роботы могут требовать использования заглавных букв, поэтому рекомендуется использовать заглавные буквы в именах полей для определенных пользовательских агентов Поддержка карты сайта . Многие файлы robots.txt содержат сведения о карте сайта для веб-сайта, но это не считается лучшей практикой. Однако Google и Bing поддерживают эту функцию.
Основные роботы, включая Google и Bing, примут эту директиву, но не все поисковые роботы — и, вообще говоря, лучше всего сделать файл robots.txt совместимым со всеми поисковыми роботами, а не только с большими. Использование заглавных букв в именах полей . Хотя имена полей не обязательно чувствительны к регистру, некоторые поисковые роботы могут требовать использования заглавных букв, поэтому рекомендуется использовать заглавные буквы в именах полей для определенных пользовательских агентов Поддержка карты сайта . Многие файлы robots.txt содержат сведения о карте сайта для веб-сайта, но это не считается лучшей практикой. Однако Google и Bing поддерживают эту функцию.
Как исправить ошибки в файле Robots.txt?
Исправление ошибок в файле robots.txt зависит от используемой вами платформы. Если вы используете WordPress, рекомендуется использовать плагин, такой как WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключите свой веб-сайт к Google Search Console, вы также сможете редактировать файл robots. txt там. Некоторые конструкторы веб-сайтов, такие как Wix, не позволяют вам напрямую редактировать файл robots.txt, но позволяют добавлять индексные теги для определенных страниц.
txt там. Некоторые конструкторы веб-сайтов, такие как Wix, не позволяют вам напрямую редактировать файл robots.txt, но позволяют добавлять индексные теги для определенных страниц.
49094
49094
Нравится этот инструмент? Оцените это!
4.7
(Проголосовало 990 пользователей)
Вы уже проголосовали! Отменить
Вам нужно использовать этот инструмент, чтобы оценить его
Это поле обязательно к заполнению
Максимальная длина комментария равна 80000 символов
Минимальная длина комментария равна 10 символам
Электронная почта обязательна
Электронная почта неверна
Проверка текстовых файлов роботов | ПейджДарт
Воспользуйтесь нашей программой проверки файла robots.txt ниже, чтобы проверить, работает ли ваш файл robots.txt.
Скопируйте и вставьте файл robots.txt в текстовое поле ниже. Вы можете найти файл robots, добавив
Вы можете найти файл robots, добавив /robots.txt на свой веб-сайт. Например, https://example.com/robots.txt .
Строка: ${error.index}
`;
список результатов.innerHTML += ли;
}
если (ошибки.длина > 0) {
resultsTitle.innerHTML = errors.length + «Ошибки»
результаты.скрытый = ложь;
} еще {
resultsTitle.innerHTML = «Нет ошибок»
результаты.скрытый = ложь;
}
вернуть ложь;
}
window.onload = функция () {
document.getElementById(«отправить»).onclick = проверить;
}
Для создания этого инструмента мы проанализировали более 5000 файлов robots. В ходе нашего исследования мы обнаружили 7 распространенных ошибок.
Как только мы обнаружили эти ошибки, мы научились их исправлять. Ниже вы найдете подробные инструкции о том, как исправить все ошибки.
Продолжайте читать, чтобы узнать, почему мы создали этот инструмент и как мы завершили исследование.
Почему мы создали инструмент
Когда поисковый робот посещает ваш сайт, например Googlebot, он читает файл robots. txt, прежде чем просматривать любую другую страницу.
txt, прежде чем просматривать любую другую страницу.
Он будет использовать файл robots.txt, чтобы проверить, куда он может пойти, а куда нет.
Он также будет искать вашу карту сайта, в которой будут перечислены все страницы вашего сайта.
Каждая строка в файле robots.txt — это правило, которому должен следовать сканер.
Если в правиле есть ошибка, сканер проигнорирует это правило.
Этот инструмент предоставляет простой способ быстро проверить наличие ошибок в файле robots.txt.
Мы также даем вам список того, как это исправить.
Более подробно о том, насколько важен файл robots.txt, можно прочитать в публикации Robots txt для SEO.
Как мы проанализировали более 5000 файлов robots.txt
Мы получили список из 1 миллиона лучших веб-сайтов по версии Alexa.
У них есть CSV-файл со списком всех URL-адресов, который вы можете скачать.
Мы обнаружили, что не на каждом сайте есть или нужен файл robots. txt.
txt.
Чтобы получить более 5000 файлов robots.txt, нам пришлось просмотреть более 7500 веб-сайтов.
Это означает, что из 7541 самых популярных веб-сайтов в Интернете 24% сайтов не имеют файла robots.txt.
Из 5000+ файлов robots.txt, которые мы проанализировали, мы обнаружили 7 распространенных ошибок:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Агент пользователя не указан
- Неверный протокол URL-адреса карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Мы рассмотрим каждую из этих ошибок и способы их исправления ниже.
Но вот что мы обнаружили в результате нашего анализа.
Из 5732 проанализированных нами файлов robots.txt только 188 содержали ошибки.
Мы также обнаружили, что в 51 % случаев было более одной ошибки. Часто повторялась одна и та же ошибка.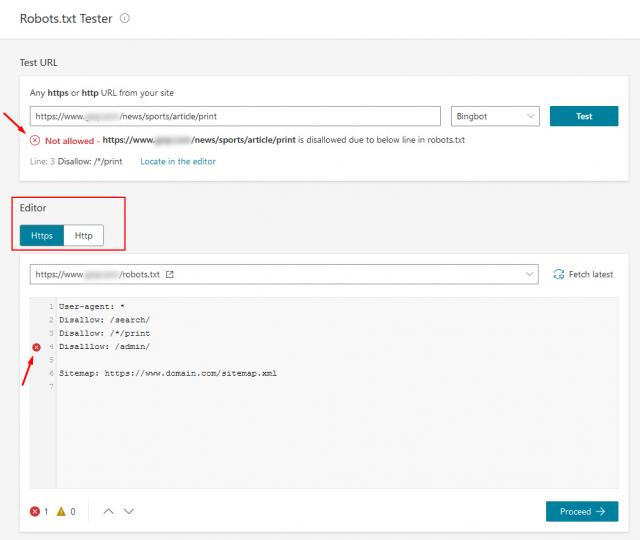
Давайте посмотрим, сколько раз возникала каждая ошибка:
| Ошибка | Граф |
|---|---|
| Шаблон должен быть пустым, начинаться с «/» или «*»‘ | 11660 |
| «$» следует использовать только в конце шаблона | 15 |
| Пользовательский агент не указан | 461 |
| Неверный протокол URL карты сайта | 0 |
| Неверный URL-адрес карты сайта | 29 |
| Неизвестная директива | 144 |
| Синтаксис не понят | 146 |
Как видите, шаблон должен быть либо пустым, либо начинаться с "/" или "*". является наиболее распространенной ошибкой.
Получив данные, мы смогли понять и исправить ошибки.
Шаблон должен быть пустым, начинаться с «/» или «*»
Это была самая распространенная ошибка, которую мы обнаружили при анализе, и в этом нет ничего удивительного.
Эта ошибка относится к правилам Разрешить и Запретить . Эти правила чаще всего встречаются в файле robots.txt.
Если вы получаете эту ошибку, это означает, что первый символ после двоеточия не является «/» или «*».
Например, Разрешить: администратор вызовет эту ошибку.
Правильный способ форматирования: Разрешить: /admin .
Подстановочный знак (*) используется, чтобы разрешить все или запретить все. Например, часто можно увидеть это, когда вы хотите остановить сканирование сайта:
Запретить: *
Чтобы исправить эту ошибку, убедитесь, что после двоеточия стоит символ «/» или «*».
«$» следует использовать только в конце шаблона
В файле robots.txt может быть знак доллара.
Вы можете использовать это, чтобы заблокировать определенный тип файла.
Например, если мы хотим заблокировать сканирование всех файлов .xls , вы можете использовать:
Агент пользователя: * Запретить: /*.xls$
Знак $ сообщает сканеру, что это конец URL-адреса. Таким образом, это правило запрещает:
https://example.com/pink.xls
Но разрешить:
https://example.com/pink.xlsocks
Если у вас нет знака доллара в конце строки, например:
Агент пользователя: * Запретить: /*$.xls
Это вызовет это сообщение об ошибке. Для исправления переместите в конец:
Агент пользователя: * Запретить: /*.xls$
Так что используйте только знак $ в конце URL для соответствия типам файлов.
Пользовательский агент не указан
В файле robots.txt необходимо указать хотя бы один User-agent . Вы используете
Вы используете User-agent для идентификации и нацеливания на определенные поисковые роботы.
Если бы мы хотели настроить таргетинг только на поисковый робот Googlebot, вы бы использовали:
Агент пользователя: Googlebot Запретить: /
Используется довольно много сканеров:
- Гуглбот
- Бингбот
- Хлеб
- УткаУткаБот
- Байдуспайдер
- ЯндексБот
- фейсбот
- ia_archiver
Если вы хотите иметь разные правила для каждого, вы можете перечислить их следующим образом:
Агент пользователя: Googlebot Запретить: / Агент пользователя: Bingbot Разрешить: /
Вы также можете использовать «*», это подстановочный знак, означающий, что он будет соответствовать всем поисковым роботам.
Агент пользователя: * Разрешить: /
Убедитесь, что у вас установлен хотя бы один User-agent .
Неверный протокол URL карты сайта
При ссылке на карту сайта из файла robot.txt необходимо указать полный URL-адрес.
Этот URL-адрес должен быть абсолютным URL-адресом, например https://www.example.com/sitemap.xml .
Протокол — это https часть URL-адреса. Для URL-адреса карты сайта вы можете использовать HTTPS , HTTP или FTP . Если у вас есть что-то еще, вы увидите эту ошибку.
Неверный URL-адрес карты сайта
Вы можете сделать ссылку на карту сайта из файла robots.txt. Это должен быть полный (абсолютный) URL. Например, https://www.example.com/sitemap.xml будет абсолютным URL.
Если у вас нет абсолютного URL-адреса, например:
Агент пользователя: * Позволять: / Карта сайта: /sitemap.xml
Это вызовет эту ошибку. Чтобы исправить это, измените абсолютный URL-адрес:
.
Агент пользователя: * Позволять: / Карта сайта: https://www.
 example.com/sitemap.xml
example.com/sitemap.xml Неизвестная директива
При написании правила вы можете использовать только фиксированное количество «директив». Это команды, которые вы вводите перед двоеточием «:». Разрешить и Запретить — обе директивы.
Вот список всех допустимых директив:
- Карта сайта
- Агент пользователя
- Разрешить
- Запретить
- Задержка сканирования
- Чистый параметр
- Хост
- Скорость запроса
- Время посещения
- Без индекса
Если у вас есть что-то еще за пределами списка выше, вы увидите эту ошибку.
Согласно нашему исследованию, наиболее распространенной причиной этой проблемы является опечатка в написании директивы.
Исправьте опечатку и повторите проверку.
Синтаксис не понят
Вы увидите эту ошибку, если в строке нет двоеточия.
В каждой строке должно стоять двоеточие, отделяющее директиву от значения.
Это вызовет ошибку:
Агент пользователя: * Разрешить /
Чтобы исправить, добавьте двоеточие (найдите разницу):
Агент пользователя: * Разрешить: /
Поместите двоеточие после директивы, чтобы устранить проблему.
Подведение итогов, проверка файлов txt для роботов
Этот инструмент может помочь вам проверить наличие наиболее распространенных ошибок в файлах robots.txt.
Скопировав и вставив файл robots.txt в указанный выше инструмент, вы можете проверить, не содержит ли он ошибок.
Проверяем на 7 ошибок в том числе:
- Шаблон должен быть пустым, начинаться с «/» или «*»’
- «$» следует использовать только в конце шаблона
- Агент пользователя не указан
- Неверный протокол URL-адреса карты сайта
- Неверный URL-адрес карты сайта
- Неизвестная директива
- Синтаксис не понят
Как только вы узнаете, в какой строке ошибка, вы можете исправить ее, используя предоставленные советы.