$
RewriteRule .? %{REQUEST_URI}? [R=301,L]
Ответить
08.09.2021 23:08
Если честно не понятно для чего данный момент проверки… на всех новых движках есть атрибут canonical …. Который решает данную проблему, тем самым заморачиваться с редиректом пустая трата времени …
06.05.2021 16:24
Спасибо, давно пользуюсь для своего сайта. Не профессионально, поэтому платный ресурс неуместен. Удачи!
Ответить
31.01.2020 23:20
Спасибо большое. Главное он бесплатный
Ответить
14.11.2019 16:04
Хороший инструмент, но не хватает подсказок, как закрыть дубли. Например, одностраничник имеется, как закрыть все страницы-дубликаты после / ? Непонятно
06.07.2022 22:13
# в строке HTTP-запроса отлавливаем запрос вида /?\d*
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /\?\d*\ HTTP/
# и делаем редирект на корень сайта с удалением GET переменных (знак вопроса ОБЯЗАТЕЛЕН)
RewriteRule ^ https://allremont59. https://allremont59.ru/$0 [R=301,L]
https://allremont59.ru/$0 [R=301,L]
# Исключаем все лишние слеши.
Ответить
07.09.2021 17:55
Добрый день. Не понимаю, как убрать дубль главной /?
23.07.2020 12:47
Добрый день !
Подскажите пожалуйста? как скрыть страницы с большим количеством слешей
В роботе Disallow: ////// — Будет работать ? не заприетит ли это индексацию главной страницы?
Или нужен редирект 301?
25.11.2019 09:10
Cтраниц, которые отличаются только GET параметрами — множество.
https://site.ru/?a
https://site.ru/?b
https://site.ru/?c
https://site.ru/?d=e
https://site.ru/?f=g&h=j
Это все страницы с одинаковым request_uri, и чем именно «/?» отличается от остальных — непонятно. Поясните, если не сложно.
\n’ +
‘
\n’ +
‘
\n’ +
‘ 0\n’ +
‘ \n’ +
‘
\n’ +
‘
\n’ +
‘ 0\n’ +
‘ \n’ +
‘
\n’ +
‘
\n’ +
‘ ‘+item. author+’\n’ +
author+’\n’ +
‘
Содержание
Поиск дублей страниц сайта
От автора
О теории дублирования контента на сайте я писал стать тут, где доказывал, что дубли статей это плохо и с дубли страниц нужно выявлять и с ними нужно бороться. В этой статье я покажу, общие приемы по выявлению повторяющегося контента и акцентирую внимание на решение этой проблемы на WordPress и Joomla.
Еще немного теории
Я не поддерживаю мнение о том, что Яндекс дубли страниц воспринимает нормально, а Google выбрасывает дубли из индекса и за это может штрафовать сайт.
На сегодня я вижу, что Яндекс определяет дубли страниц и показывает их в Яндекс.Вебмастере на вкладке «Индексация». Более того, ту страницу, которую Яндекс считает дублем, он удаляет из индекса. Однако я вижу, что Яндекс примет за основную страницу первую, проиндексированную и вполне возможно, что этой страницей может быть дубль.
Также понятно и видно по выдаче, что Google выбрасывает из поиска НЕ все страницы с частичным повторением материала.
Вместе с этим, отсутствие дублей на сайте воспринимается поисковыми системами, как положительный фактор качества сайта и может влиять на позиции сайта в выдаче.
Теперь от теории к практике: как найти дубли страниц.
Поиск дублей страниц сайта
Перечисленные ниже способы поиск дублей страниц не борются с дублями, а помогают их найти в поиске. После их выявления, нужно принять меры по избавлению от них.
Программа XENU (полностью бесплатно)
Программа Xenu Link Sleuth (http://home.snafu.de/tilman/xenulink.html), работает независимо от онлайн сервисов, на всех сайтах, в том числе, на сайтах которые не проиндексированы поисковиками. Также с её помощью можно проверять сайты, у которых нет накопленной статистики в инструментах вебмастеров.
Поиск дублей осуществляется после сканирования сайта программой XENU по повторяющимся заголовкам и мета описаниям. Читать статью: Проверка неработающих, битых и исходящих ссылок сайта программой XENU
Программа Screaming Frog SEO Spider (частично бесплатна)
Адрес программы https://www. screamingfrog.co.uk/seo-spider/. Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Статья: SEO анализ сайта программой Scrimimg Seo Spider
screamingfrog.co.uk/seo-spider/. Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Статья: SEO анализ сайта программой Scrimimg Seo Spider
Программа Netpeak Spider (платная с триалом)
Сайт программы https://netpeaksoftware.com/spider. Еще один программный сканер для анализа ссылок сайта с подробным отчетом. Статья Программа для SEO анализа сайта Netpeak Spider
Яндекс.Вебмастер
Для поиска дублей можно использовать Яндекс.Вебмастер после набора статистики по сайту. В инструментах аккаунта на вкладке Индексирование >>>Страницы в поиске можно посмотреть «Исключенные страницы» и выяснить причину их удаления из индекса. Одна из причин удаления это дублирование контента. Вся информация доступна под каждым адресом страницы.
поиск дублей страниц в Яндекс.Вебмастер
Язык поисковых запросов
Используя язык поисковых запросов можно вывести список всех страниц сайта, которые есть в выдаче (оператор «site:» в Google) и поискать дубли «глазами». Как это сделать читать в статье Простые способы проверить индексацию страниц сайта.
Как это сделать читать в статье Простые способы проверить индексацию страниц сайта.
Сервисы онлайн
Есть онлайн сервисы, который показывают дубли сайта. Например, сервис Siteliner.com (http://www.siteliner.com/) На нём можно найти битые ссылки и дубли. Можно проверить до 25000 страниц по подписке и 250 страниц бесплатно.
Российский сервис Saitreport.ru, может помочь в поиске дублей. Адрес сервиса: https://saitreport.ru/poisk-dublej-stranic
Google Search Console
В консоли веб-мастера Google тоже есть инструмент поиска дублей. Откройте свой сайт в консоли Гугл вебмастер. На вкладке Вид в поиске>>>Оптимизация HTML вы увидите, если есть, повторяющиеся заголовки и мета описания. Вероятнее всего это дубли (частичные или полные).
поиск дублей страниц в консоли веб-мастера Google
Что делать с дублями
Найденные дубли, нужно удалить с сайта, а также перенастроить CMS, чтобы дубли не появлялись, либо закрыть дубли от поисковых ботов мета-тегами noindex, либо добавить тег rel=canonical в заголовок каждого дубля.
Как бороться с дублями
Здесь совет простой, бороться с дублями нужно всеми доступными способами, но прежде всего, настройкой платформы (CMS) на которой строится сайт. Уникальных рецептов нет, но для Joomla и WordPress есть практичные советы.
Поиск и удаление дублей на CMS Joomla
CMS Joomla «плодит» дубли, «как крольчиха». Причина дублирования в возможностях многоуровневой вложенности материалов, размещения материалов разных пунктах меню, в различных макетах для пунктов меню, во встроенном инструменте пагинации (листания) и различной возможности сортировки материалов.
Например, одна и та же статья, может быть в блоге категории, в списке другого пункта меню, может быть, в сортировке по дате выпуска и вместе с тем, быть в сортировке по количеству просмотров, дате обновления, автору и т.д.
Встроенного инструмента борьбы с дублями нет и даже появление новой возможности «Маршрутизация URL» не избавляет от дублирования.
Решения проблемы
Решить проблему дублирования на сайтах Joomla помогут следующие расширения и приёмы.
Бесплатный плагин «StyleWare Content Canonical Plugin». Сайт плагина: https://styleware.eu/store/item/26-styleware-content-canonical-plugin. Плагин фиксирует канонические адреса избранных материалов, статей, категорий и переадресовывает все не канонические ссылки.
SEO Компоненты Joomla, Artio JoomSEF (бесплатный) и Sh504 (платный). У этих SEO «монстров» есть кнопка поиска и удаления дублей, а также есть легкая возможность добавить каноническую ссылку и/или закрыть страницы дублей от индексации.
Перечисленные расширения эффективно работают, если их ставят на новый сайт. Также нужно понимать, что при установке на рабочий сайт:
- На сайте со статьями в индексе эти расширения «убьют» почти весь индекс.
- Удаление дублей компонентами не автоматизировано и дубли всё равно попадают в индекс.
- Хотя управлять URL сайта этими компонентами очень просто.
Если дубль страницы попадет в индекс, то поисковики, не умея без указателей определять, какая страница является основной, могут дубль принять за основную страницу, а основную определить, как дубль.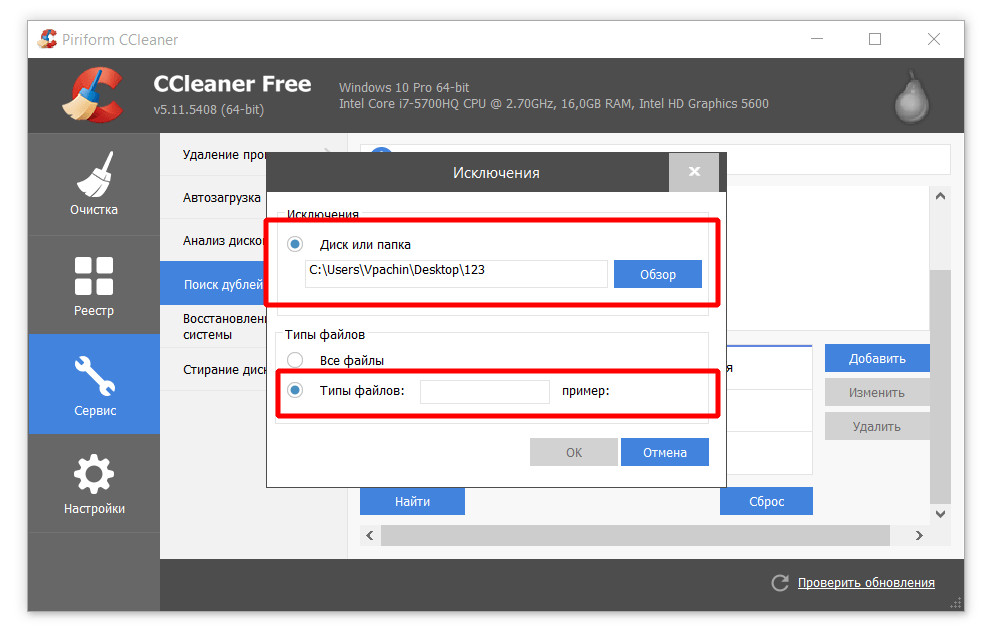 Из-за этого важно, не только бороться с дублями внутри сайта, но и подсказать поисковикам, что можно, а что нельзя индексировать. Сделать это можно в файле robots.txt, но тоже с оговорками.
Из-за этого важно, не только бороться с дублями внутри сайта, но и подсказать поисковикам, что можно, а что нельзя индексировать. Сделать это можно в файле robots.txt, но тоже с оговорками.
Закрыть дубли в robots.txt
Поисковик Яндекс, воспринимает директиву Disallow как точное указание: материал не индексировать и вывести материал из индекса. То есть, закрыв на Joomla , страницы с таким url: /index.php?option=com_content&view=featured&Itemid=xxx, а закрыть это можно такой директивой:
Disallow: /*?
вы уберете, из индекса Яндекс все страницы со знаком вопроса в URL.
В отличие от Яндекс, поисковик Google не читает директиву Disallow так буквально. Он воспринимает директиву Disallow как запрет на сканирование, но НЕ запрет на индексирование. Поэтому применение директивы [Disallow: /*?] в блоке директив для Google файла robots.txt, на уже проиндексированном сайте, скорее приведет к негативным последствиям. Google перестанет сканировать закрытые страницы, и не будет обновлять по ним информацию.
Для команд боту Google нужно использовать мета теги <meta name=”robots” content=”noindex”/>, которые можно добавить во всех редакторах Joomla, на вкладке «Публикация».
Например, вы создаете на сайте два пункта меню для одной категории, один пункт меню в виде макета блог, другой в виде макета список. Чтобы не было дублей, закройте макет список мета-тегом noindex, nofollow, и это избавит от дублей в Google выдаче.
Также рекомендую на сайте Joomla закрыть в файле robots.txt страницы навигации и поиска от Яндекс на любой стадии индексации и от Google на новом сайте:
- Disallow: /*page*
- Disallow: /*search*
Стоит сильно подумать, об индексации меток, ссылок и пользователей, если они используются на сайте.
Поиск и удаление дублей на CMS WordPress
На WordPress создаваемый пост попадает на сайт как статья, и дублируется в архивах категории, архивах тегов, по дате, по автору. Чтобы избавиться от дублей на WordPress, разумно закрыть от индексации все архивы или, по крайней мере, архивы по дате и по автору.
Использовать для этих целей можно файл robots.txt с оговорками сделанными выше. Или лучше, установить SEO плагин, который, поможет в борьбе с дублями. Рекомендую плагины:
- Yast SEO (https://ru.wordpress.org/plugins/wordpress-seo/)
- All in One SEO Pack (https://ru.wordpress.org/plugins/all-in-one-seo-pack/)
В плагинах есть настройки закрывающие архивы от индексации и масса других SEO настроек, который избавят от рутинной работы по оптимизации WordPress.
Вывод
По практике скажу, что побороть дубли на WordPress можно, а вот с дублями на Joomla поиск дублей страниц требует постоянного контроля и взаимодействия с инструментами веб-мастеров, хотя бы Яндекс и Google.
©SeoJus.ru
Еще статьи
Похожие записи:
Поиск и удаление дубликатов и почти дубликатов страниц PDF
Поиск и удаление дубликатов страниц PDF
- Введение
- В этом руководстве показано, как найти и при необходимости удалить похожие или повторяющиеся страницы в одном документе PDF с помощью
подключаемый модуль AutoSplit™ для Adobe® Acrobat®.
Эта операция обнаруживает похожие страницы и представляет их пользователю для просмотра.
Пользователь может просмотреть результаты и выбрать/отменить выбор отдельных страниц из списка дубликатов для возможного
удаление или извлечение. Вы можете выполнять следующие операции: - Поиск дубликатов и почти дубликатов
- Добавление дубликатов страниц в закладки
- Извлечь дубликаты страниц в отдельный документ PDF
- Удалить дубликаты страниц из документа
- Сохранить отчет о сходстве страниц
- Подключаемый модуль предоставляет два разных метода обнаружения дубликатов или почти дубликатов страниц:
- Сравнить только текст страницы
- Используйте этот метод для сравнения текста страницы независимо от его внешнего вида. Он вычисляет сходство страниц
на основе текстового содержимого только и полностью игнорирует внешний вид текста, макет, изображения и графику
которые могут присутствовать на странице. Это лучший метод обнаружения дубликатов в большинстве типов документов. - Сравните внешний вид страниц
- Этот метод сравнивает страницы «как изображения» и обнаруживает страницы, которые выглядят совершенно одинаково.
Этот метод не сравнивает невидимый текст, который может присутствовать на странице.
Не рекомендуется использовать этот метод для отсканированных бумажных документов.
- Использование отсканированных бумажных документов
- Довольно часто эта операция используется для поиска дубликатов страниц в отсканированных бумажных документах.
Отсканированные документы необходимо подвергнуть распознаванию, прежде чем использовать их для какой-либо текстовой обработки.
OCR — это процесс распознавания текста в отсканированных документах и обеспечения возможности поиска по ним.
Важно понимать, что распознавание текста в отсканированных документах подвержено ошибкам и
это редко бывает на 100% точным. Количество ошибок зависит от разрешения сканирования и качества исходного документа.
В большинстве случаев отсканированная страница может содержать от 1 до 10 ошибок распознавания, где некоторые буквы
неправильно идентифицирован. Например, в зависимости от шрифта строчная буква l может выглядеть точно так же, как цифра 1.
. Заглавная буква O часто ошибочно принимается за цифру 0, заглавная буква S — за цифру 5 и т. д.
Поскольку многие буквенно-цифровые символы имеют схожие или идентичные физические характеристики, часто возникает необходимость их различения.
вызов. Вот почему сравнение на основе подобия полезно для обнаружения небольших различий между страницами, которые
производится в процессе распознавания текста. Отсканированные документы низкого качества могут содержать большое количество ошибок, делающих их
непригоден для любого надежного текстового сравнения. См. следующий учебник о том, как распознавать отсканированные документы.
и оценивает их пригодность для текстовой обработки. . - Предпосылки
- Для использования этого руководства вам потребуется копия Adobe® Acrobat® вместе с подключаемым модулем AutoSplit™, установленным на вашем компьютере. Вы можете загрузить пробные версии как Adobe® Acrobat®, так и подключаемого модуля AutoSplit™.

 Это лучший метод обнаружения дубликатов в большинстве типов документов.
Это лучший метод обнаружения дубликатов в большинстве типов документов.
 См. следующий учебник о том, как распознавать отсканированные документы.
См. следующий учебник о том, как распознавать отсканированные документы.- Содержимое
- Сравнение только текста страницы
- Сравнить только внешний вид
- Сравнение нескольких документов
- Метод 1 — сравнение только текста страницы ↑обзор
- Этот метод сравнивает сходство страниц только на основе содержимого их страниц. Внешний вид, положение и порядок текста не имеют значения. Этот метод также игнорирует любые изображения и графику, присутствующие на страницах.
Метрика подобия модифицированного косинуса используется для расчета того, как
похожи две страницы на основе их текстового содержания. - Шаг 1. Откройте файл PDF
- Запустите приложение Adobe® Acrobat® и откройте файл PDF с помощью меню «Файл > Открыть…».
- Шаг 2. Откройте диалоговое окно «Поиск повторяющихся страниц»
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы…», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Шаг 3. Укажите параметры
- Установите флажок «Сравнять только текст страницы (игнорировать внешний вид страниц)».
- Использование предопределенных настроек
- Текстовый метод предоставляет ряд предопределенных наборов параметров, которые подходят для сравнения разных типов документов с разным количеством ошибок распознавания. Каждый предопределенный набор параметров обеспечивает различные условия для расчета подобия:
- Пользовательские настройки — все настройки задаются пользователем
- Отсканированный бумажный документ: высокое качество
- Отсканированный бумажный документ: среднее качество
- Факс: низкое качество
- Несканированный PDF: точное совпадение
- Неотсканированный PDF: нечеткое совпадение
- Точное совпадение (с порядком текста) — этот метод не использует косинусное сходство
- Настройки появляются под меню после выбора предопределенного набора параметров.
- Вот настройки, используемые предопределенными наборами:
- Нажмите «Изменить…», чтобы настроить параметры сходства страниц:
- Метод сравнения текста использует 3 параметра, чтобы ограничить, насколько разными могут быть две «похожие» страницы. Варьируя эти параметры, можно обнаружить страницы, имеющие разную степень сходства.
- Минимально допустимое сходство текста страницы (в процентах) — это значение метрики косинусного сходства, выраженное в процентах. Укажите минимально допустимое сходство текста страницы от 70 до 100 (в процентах).
- Максимально допустимая разница в длине страницы (в символах).
- Максимально допустимая разница текста страницы (в словах).
- Используйте эти настройки для экспериментов с настройками обработки, когда необходимо настроить алгоритм обработки для конкретного документа.
- Использовать образцы страниц
- При необходимости нажмите «Установить из образца страницы. ..», чтобы указать параметры схожести страниц на основе двух образцов страниц:
- Выберите две страницы, которые можно считать идентичными. Программное обеспечение автоматически рассчитает схожесть страниц, и статистика появится в левом нижнем углу диалогового окна.
- Нажмите «ОК», чтобы сохранить текущие настройки сходства.
- Укажите параметры фильтрации текста
- Существует несколько параметров, управляющих содержимым страницы, которое анализируется алгоритмом сравнения текста. Используйте эти параметры при сравнении отсканированных бумажных документов, которые могут содержать различные ошибки распознавания текста. Эти параметры исключают определенные виды символов из обработки. Во многих случаях это может помочь вычислить более точную метрику сходства.
- Игнорировать регистр — эта опция игнорирует регистр при сравнении текста.
- Игнорировать знаки препинания (,.!?-) — эта опция исключает из сравнения все знаки препинания.
- Игнорировать небуквенно-цифровые символы — этот параметр игнорирует все символы, кроме букв и цифр.
- Нажмите «ОК», чтобы сохранить настройки сходства страниц.
- Нажмите «ОК», чтобы начать поиск дубликатов страниц в текущем PDF-документе:
- Шаг 4. Проверка дубликатов страниц
- В диалоговом окне «Удалить повторяющиеся страницы» отображается список повторяющихся или почти повторяющихся страниц. Щелкните запись страницы, чтобы отобразить соответствующую страницу в средстве просмотра. Просмотрите страницы и выберите/отмените выбор страниц для удаления.
- При необходимости нажмите «Сохранить отчет…», чтобы создать отчет о схожести страниц в формате HTML. Или нажмите «Страницы закладок», чтобы создать закладки в PDF для выбранных дубликатов страниц.
- Плагин позволяет просматривать/сравнивать найденные дубликаты или почти дубликаты страниц.
Сходство страниц (в %) и количество
несовпадающие слова отображаются для каждой пары страниц. Вот примеры, рассчитанные для пары отсканированных бумажных документов: - Обратите внимание, что внешний вид и расположение текста не влияют на результаты.
- Эти две страницы считаются идентичными, несмотря на разницу в цвете текста:
- Эти две страницы считаются идентичными, несмотря на разницу в расположении контента:
- Эти две страницы считаются на 94% похожими, несмотря на разницу в порядке текста, макете и отсутствии изображения:
- Шаг 5. Извлечение дубликатов страниц или добавление их в закладки
- При необходимости используйте кнопку «Закладка страниц», чтобы добавить в закладки все отмеченные страницы.
Это полезно, если вы не планируете удалять найденные дубликаты страниц из документа. Используйте флажки перед страницами, чтобы выбрать или отменить их выбор в наборе обработки. - Используйте кнопку «Извлечь страницы…», чтобы извлечь все отмеченные страницы в отдельный документ PDF. Эта операция не удалит страницы из текущего документа.
- Используйте кнопку «Сохранить отчет…», чтобы сохранить отчет о вычислении схожести страниц в файл HTML.
Он содержит сведения о сходстве страниц, показывает различия между страницами и перечисляет пропущенные слова.
Это может быть очень полезно для глубокого анализа. - Шаг 6. Удаление повторяющихся страниц
- Используйте флажки перед страницами, чтобы выбрать/отменить выбор страниц для удаления. Нажмите кнопку «Удалить страницы» в диалоговом окне «Удалить дубликаты страниц», чтобы удалить все отмеченные страницы из текущего документа PDF:
- Нажмите кнопку «ОК» для подтверждения. Страницы будут удалены навсегда.
- Метод 2 — сравнение только внешнего вида ↑обзор
- Этот метод сравнивает страницы «как изображения» и обнаруживает страницы, которые выглядят совершенно одинаково.
Этот метод не сравнивает невидимый текст, который может присутствовать на странице.
Не рекомендуется использовать этот метод для отсканированных бумажных документов. - Шаг 1. Откройте файл PDF
- Запустите приложение Adobe® Acrobat® и откройте файл PDF с помощью меню «Файл > Открыть…».
- Шаг 2. Откройте диалоговое окно «Поиск повторяющихся страниц»
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы…», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Шаг 3. Укажите параметры
- Установите флажок «Сравнить внешний вид для точного соответствия (можно использовать для сравнения изображений)».
- Нажмите «ОК», чтобы начать поиск дубликатов страниц.
- Шаг 4. Проверка дубликатов страниц
- В диалоговом окне «Удалить повторяющиеся страницы» отображается список повторяющихся или почти повторяющихся страниц.
Щелкните запись страницы, чтобы отобразить соответствующую страницу в параллельном представлении.
Просмотрите страницы и выберите/отмените выбор страниц для возможного удаления. - При необходимости нажмите «Сохранить отчет…», чтобы создать отчет о схожести страниц в формате HTML. Или нажмите «Страницы закладок», чтобы создать закладки в PDF для выбранных дубликатов страниц.
- Этот метод основан на создании уменьшенных (пробных) копий страниц и сравнении их «как изображения». В следующем примере показаны две идентичные страницы, которые содержат только графику и не содержат текст для поиска:
- Если страницы визуально идентичны, то программа определяет их как дубликаты:
- Эти две страницы считаются разными из-за штампа «Утверждено» на одной из страниц:
- Эти две страницы считаются идентичными по этому методу:
- В отличие от текстового метода сравнения, если цвет или стиль текста отличаются, страницы не считаются идентичными:
- Шаг 5. Удаление повторяющихся страниц
- Нажмите «Удалить страницы» в диалоговом окне «Удалить повторяющиеся страницы», чтобы продолжить.
- Нажмите кнопку «ОК», чтобы удалить страницы из текущих документов PDF. Страницы будут удалены навсегда.
- Сравнение нескольких документов PDF
- Эту операцию можно использовать для поиска и удаления дубликатов страниц из нескольких документов PDF.
Подход состоит в том, чтобы объединить один или несколько документов в один файл PDF и запустить «Найти и удалить дубликаты страниц».
операцию над результирующим файлом. По сути, это создаст один документ без каких-либо дубликатов. При желании можно извлечь все обнаруженные дубликаты страниц в отдельный PDF-документ. - Шаг 1. Объединение нескольких PDF-документов ↑обзор
- Запустите приложение Adobe® Acrobat® и выберите «Инструменты» в меню. Выберите значок «Объединить файлы» в списке инструментов.
- Нажмите «Добавить файлы. ..» в меню «Объединить файлы» и выберите PDF-файлы для объединения для сравнения.
- Нажмите кнопку «Объединить» в меню, чтобы объединить выбранные файлы PDF.
- Шаг 2. Найдите дубликаты страниц
- На экране появится объединенный выходной PDF-файл. Если нет, откройте объединенный файл PDF.
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы…», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Установите флажок «Сравнить внешний вид для точного соответствия (можно использовать для сравнения изображений)». Нажмите «ОК», чтобы начать поиск дубликатов страниц.
- Шаг 3. Извлечение дубликатов страниц
- В диалоговом окне «Удалить дубликаты страниц» будет показан список дубликатов или почти дубликатов страниц. Щелкните запись страницы, чтобы отобразить соответствующую страницу в средстве просмотра. Просмотрите страницы и выберите/отмените выбор страниц.
- Нажмите «Извлечь страницы…», чтобы извлечь выбранные дубликаты страниц в новый документ PDF.
- Укажите выходную папку и имя файла. Нажмите «Сохранить».
- Появится диалоговое окно, показывающее количество страниц, которые были извлечены в отдельный документ. Теперь вы сохранили все повторяющиеся страницы в отдельный файл PDF перед их удалением. Вы можете изучить эти страницы и использовать их позже, если это необходимо.
- Нажмите «ОК», чтобы закрыть диалоговое окно.
- Шаг 4. Удаление повторяющихся страниц
- Нажмите «Удалить страницы» в диалоговом окне «Удалить повторяющиеся страницы», чтобы продолжить.
- Нажмите «ОК» в диалоговом окне, чтобы удалить выбранные дубликаты страниц из текущего документа PDF.
- Выбранные повторяющиеся страницы будут навсегда удалены из документа PDF. Вам нужно будет использовать меню «Файл > Сохранить», чтобы сохранить измененный документ на диск.
- Щелкните здесь, чтобы просмотреть список всех доступных пошаговых руководств.


 ..», чтобы указать параметры схожести страниц на основе двух образцов страниц:
..», чтобы указать параметры схожести страниц на основе двух образцов страниц: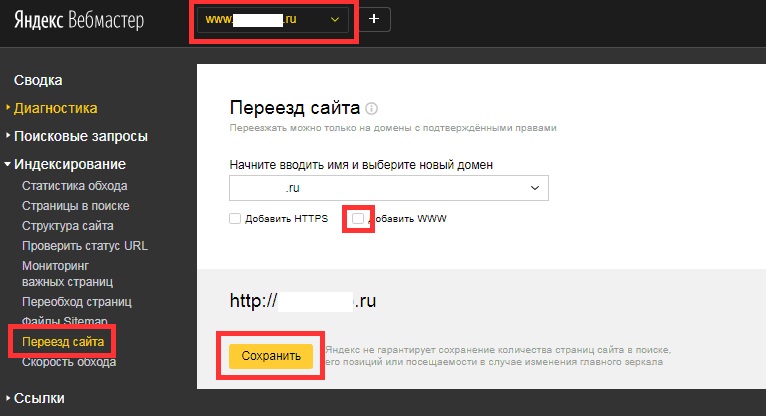
 Вот примеры, рассчитанные для пары отсканированных бумажных документов:
Вот примеры, рассчитанные для пары отсканированных бумажных документов: Эта операция не удалит страницы из текущего документа.
Эта операция не удалит страницы из текущего документа.

.
 ..» в меню «Объединить файлы» и выберите PDF-файлы для объединения для сравнения.
..» в меню «Объединить файлы» и выберите PDF-файлы для объединения для сравнения.

15 Средства проверки дублирующегося контента для веб-сайтов
Дублированный контент может нанести серьезный вред вашему сайту, поэтому мы собрали для вас наши любимые бесплатные инструменты для проверки дублированного контента или проверки на плагиат.
Плагиат контента — рискованная стратегия. Наряду с потерей уважения своих коллег, плагиаторы лишались ученых степеней, были уволены с работы, покончили с политической карьерой, не говоря уже о юридических последствиях.
Итак, если плагиат считается отвратительной практикой в офлайн-мире, почему люди считают, что дублирование контента в онлайн-мире допустимо? На самом деле, дублирование контента в Интернете — это ОГРОМНАЯ ошибка!
Почему стоит воспользоваться преимуществами средств проверки дубликатов содержимого
Поисковые системы хотят предоставлять ценный оригинальный контент, поэтому они рассматривают плагиат как угрозу для своих пользователей. Когда поисковая система индексирует веб-страницу, она сканирует содержимое страницы, а затем сравнивает содержимое с другими проиндексированными веб-сайтами.
Когда поисковая система индексирует веб-страницу, она сканирует содержимое страницы, а затем сравнивает содержимое с другими проиндексированными веб-сайтами.
Если на странице обнаруживается дублированный контент, поисковые системы часто наказывают страницу, снижая ее рейтинг или полностью удаляя ее из результатов поиска, что оказывает серьезное влияние на ваши усилия по поисковой оптимизации.
Принимая во внимание серьезные санкции, которые могут быть наложены на ваш сайт, если на нем есть плагиат, настоятельно рекомендуется проверить существующий веб-контент и любой контент, который вы планируете опубликовать, на предмет дублирования.
Лучшие бесплатные инструменты для проверки вашего веб-контента на плагиат
Даже если вы уверены, что содержимое вашего веб-сайта не было плагиатом, рекомендуется проверить, чтобы ничего не было непреднамеренно дублировано. Чтобы помочь вам выполнить эту задачу (и убедиться, что рейтинг вашего сайта остается здоровым и не подвергается штрафным санкциям), вот наши любимые 4 бесплатных инструмента для проверки дублированного контента:
1.
 Duplichecker
Duplichecker
Этот бесплатный инструмент для проверки на плагиат позволяет выполнять текстовый поиск, DocX или Текстовый файл и поиск по URL. Это бесплатно с неограниченным количеством поисков при регистрации (вам разрешен 1 бесплатный поиск перед регистрацией).
Сканирование на наличие дубликатов было завершено всего за несколько секунд (конечно, это будет зависеть от длины сканируемого текста, страницы или файла). Это просто, бесплатно и эффективно!
2. Siteliner
Для проверки целых веб-сайтов на наличие дублирующегося контента существует Siteliner. Просто вставьте URL-адрес вашего сайта в поле, и он просканирует дублированный контент, время загрузки страницы, количество слов на странице, внутренние и внешние ссылки и многое другое. В зависимости от размера вашего сайта сканирование может занять несколько минут, но результаты того стоят. После завершения сканирования вы можете щелкнуть результаты, чтобы получить более подробную информацию, и даже загрузить отчет о сканировании в формате PDF.
Примечание: Бесплатная служба Siteliner ограничена одним сканированием на сайт в месяц, но премиальная услуга Siteliner очень доступна (каждая отсканированная страница стоит всего 1 цент, и вы можете сканировать столько раз, сколько пожелаете) .
3. PlagSpotter
Поиск по URL PlagSpotter бесплатный, быстрый и тщательный. Сканирование веб-страницы на наличие дублирующегося контента заняло чуть меньше минуты с перечислением 49 источников, включая ссылки на эти источники для дальнейшего изучения. Существует также функция «Оригинальность», которая позволяет сравнивать текст, помеченный как дублированный.
Хотя поиск по URL PlagSpotter является бесплатным, вы можете подписаться на их бесплатную 7-дневную пробную версию, чтобы пользоваться множеством полезных функций, включая мониторинг плагиата, неограниченный поиск, пакетный поиск, полное сканирование сайта и многое другое. Если вы хотите продолжить использовать PlagSpotter после бесплатной пробной версии, платная версия очень доступна.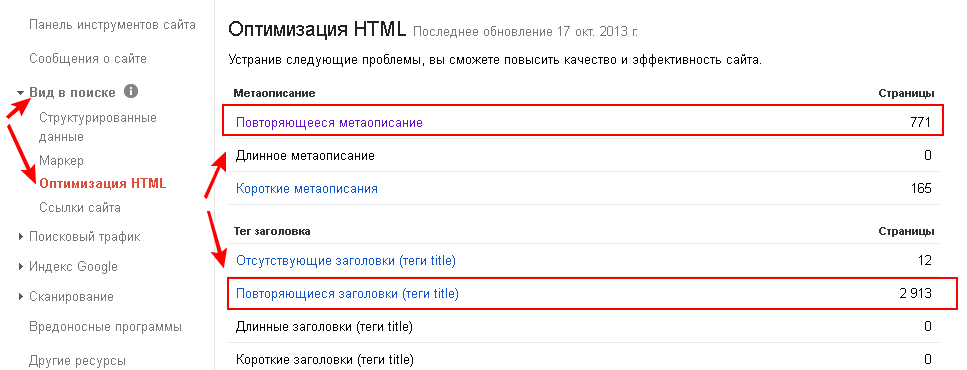
4. Copyscape
Copyscape предлагает бесплатный поиск по URL-адресам, результаты которого приходят всего за несколько секунд. Хотя бесплатная версия не выполняет глубокий поиск (разбивая текст для поиска частичного дублирования), она выполняет тщательную работу по поиску точных совпадений.
Если вы нашли два похожих URL-адреса или текстовых блока, у Copyscape есть бесплатный инструмент сравнения, который выделяет повторяющийся контент в тексте. В то время как существует ограниченное количество поисков на сайте с их бесплатной услугой, Премиум-аккаунт Copyscape (платный) позволяет вам иметь неограниченные поиски, глубокие поиски, поисковые текстовые выдержки, поиск полных сайтов и ежемесячный мониторинг дублированного контента.
Упоминания о проверке заметного дублированного контента
Обновление! Когда мы впервые написали это в 2014 году, на рынке было очень мало инструментов для проверки на плагиат или дублирование контента. Список значительно расширился и теперь включает множество новых опций для проверки оригинальности вашего контента, в том числе следующие почетные упоминания:
Список значительно расширился и теперь включает множество новых опций для проверки оригинальности вашего контента, в том числе следующие почетные упоминания:
- Copyleaks.com
- Plagtracker.com
- Viper / Scanmyessay.com
- Paperrater.com
- Plagiarisma.net
- Plagiarismchecker.com
- Smallseotools.com
Премиум (платные) средства проверки дубликатов контента
Хотя большинство упомянутых выше средств проверки дубликатов контента предлагают бесплатную версию наряду с премиальной (платной) версией, следующие веб-сайты предоставляют только платные варианты.
- Grammarly.com — нам тоже нравится их средство проверки грамматики!
- Plagiarismcheck.org
- Plagscan.com
- Plagium.com предлагает бесплатный «быстрый поиск», поэтому, если вы не используете его так часто, вам сойдет с рук бесплатная версия.
Теперь, когда вы знаете наши рекомендации по работе с дублирующимся контентом, можете поделиться своими?
Мы надеемся, что перечисленные выше ресурсы помогут вам создавать качественный веб-контент, не беспокоясь о том, что ваш веб-сайт или блог будут наказаны за дублирование контента.