Содержание
Robots.txt как создать и правильно настроить
Последнее обновление: 08 ноября 2022 года
24748
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем нужен robots.txt?
- Основные директивы файла robots.txt
- Как создать robots.txt?
- Как проверить файл?
Кому будет полезна статья?
- Веб-разработчикам.
- Техническим специалистам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Поисковые роботы или веб-краулеры постоянно индексируют страницы сайтов, собирают информацию и заносят ее в базы данных поисковых систем. Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots. txt с помощью доступных инструментов Яндекс и Google.
txt с помощью доступных инструментов Яндекс и Google.
Зачем нужен robots.txt?
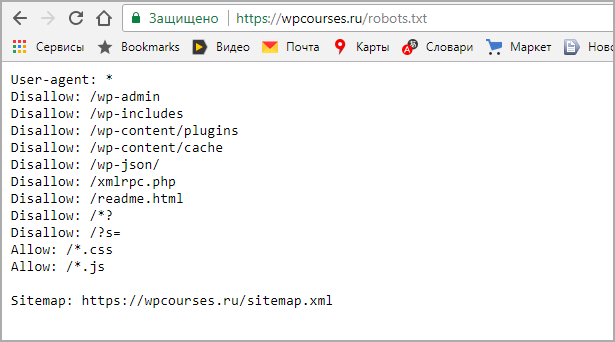
Файл robots.txt — служебный файл, который содержит информацию о том, какие страницы сайта доступны для сканирования поисковыми роботами, а какие им посещать нельзя. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
С помощью robots.txt вы можете задать уровень доступа краулеров к сайту и его разделам: полностью запретить индексацию или ограничить сканирование отдельных папок, страниц, файлов, а также закрыть ресурс для роботов, которые не относятся к основным поисковым системам.
Таким образом, создание и правильная настройка robots.txt помогут ускорить процесс индексации сайта, снизить нагрузку на сервер, положительно отразятся на ранжировании сайта в поисковой выдаче.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«Некоторым сайтам файл robots. txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
User-agent: *
Disallow: /tag/
Disallow: /wp-admin/».
Основные директивы файла robots.txt
Чтобы поисковые роботы могли корректно прочитать robots.txt, он должен быть составлен по определенным правилам. Структура служебного файла содержит следующие директивы:
- User-agent. Директива User-agent определяет уровень открытости сайта для поисковых роботов.
 Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
Пример:
User-agent: * — сайт доступен для индексации всем краулерам
User-agent: Yandex — доступ открыт только для роботов Яндекса
User-agent: Googlebot — доступ открыт только для роботов Google - Disallow. Директива Disallow определяет, какие страницы сайта необходимо закрыть для индексации. Как правило, для сканирования закрывают весь служебный контент, но при желании вы можете скрыть и любые другие разделы проекта. Подробнее о том, каким страницам и сайтам не нужно индексирование, вы можете прочитать в статье: «Как закрыть сайт от индексации в robots.txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: /wp-admin — служебная папка со всеми вложениями закрыта для индексации
Пример 2:
User-agent: Yandex — правила, размещенные ниже, действуют для роботов Яндекса
Disallow: / — все разделы сайта доступны для индексации - Allow. Директива Allow определяет, какие разделы сайта доступны для сканирования поисковыми роботами. Поскольку все, что не запрещено директивой Disallow, индексируется автоматически, здесь достаточно прописать только исключения из правил. Указывать все доступные краулерам разделы сайта не нужно.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
Allow: /catalog — раздел «Каталог» открыт для всех краулеров
Пример 2:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
User-agent: Googlebot — правила, размещенные ниже, действуют для роботов Google
Allow: / — сайт полностью открыт для роботов Google - Sitemap. Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Пример:
Sitemap: https://site.ru/sitemap.xml
 Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
 В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
 Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Как создать robots.txt?
Служебный файл robots.txt можно создать в текстовом редакторе Notepad++ или другой аналогичной программе. Весь текст внутри файла должен быть записан латиницей, русские названия можно перевести с помощью любого Punycode-конвертера. Для кодировки файла выбирайте стандарты ASCII или UTF-8.
Чтобы robots.txt корректно индексировался поисковыми роботами, при создании файла следуйте данным ниже рекомендациям:
- Объединяйте директивы в группы. Чтобы избежать путаницы и сократить время индексации, сгруппируйте директивы блоками для каждого поискового робота и разделите блоки пустой строкой. Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
- Учитывайте регистр. Прописывайте имя файла строчными буквами. Если Яндекс информирует, что для его поисковых роботов регистр не имеет значения, то Google рекомендует соблюдать регистр.
- Не указывайте несколько папок в одной директиве. Не объединяйте в одной директиве Disallow несколько папок/файлов. Создавайте отдельную директиву на каждый раздел и файл. Это позволит избежать ошибок при проверке и ускорит процесс индексации.
- Работайте с разными уровнями. В robots.txt вы можете задавать настройки на трех уровнях: сайта, страницы, папки. Используйте эту возможность, если хотите закрыть часть материалов для поисковиков.
- Удаляйте неактуальные директивы. Некоторые директивы robots. txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
- Проверьте соответствие sitemap.xml и robots.txt. Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы информация в них совпадала, и sitemap был включен в одноименную директиву.
 Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
 txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
После создания robots.txt, обратите внимание, чтобы его размер не превышал 32 КБ. При большом объеме файла, он не будет восприниматься поисковыми роботами Яндекс.
Разместите robots.txt в корневой директории сайта рядом с основным файлом index.html. Для этого используйте FTP доступ. Если сайт сделан на CMS, то с файлом можно работать через административную панель.
Как проверить файл?
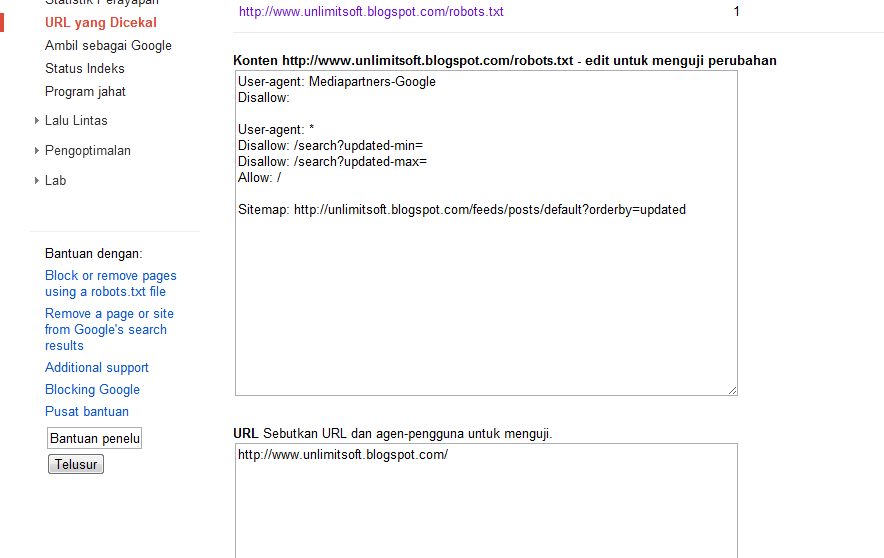
Удостовериться в том, что файл составлен корректно, можно с помощью инструментов Яндекс.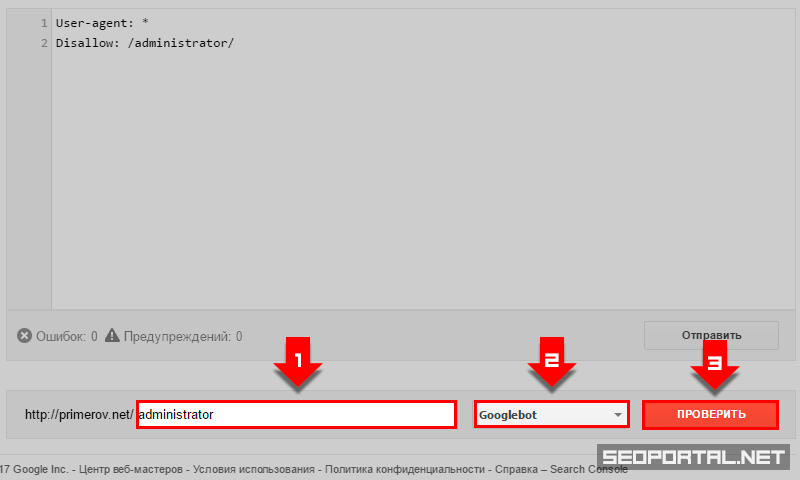 Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Проверка robots.txt в Яндекс.Вебмастер
При первом запуске Яндекс.Вебмастер необходимо создать личный кабинет, добавить сайт и подтвердить свои права на него. После этого вы получите доступ к инструментам сервиса. Для проверки файла нужно зайти в раздел «Инструменты» подраздел «Анализ robots.txt» и запустить тестирование. Если в ходе проверки сервис обнаружит ошибки, он покажет, какие строки требуют корректировки, и что нужно исправить.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«В пункте «Анализ robots.txt» вы также можете «протестировать» написание директив и их влияние на статус индексации. Если Вы сомневаетесь в правильности написания директив, то укажите в поле «Разрешены ли URL?» нужные Вам URL, после чего Вебмастер покажет вам статус индексации этих адресов при указанном robots. txt.».
txt.».
Проверка robots.txt в Google Robots Testing Tool
Проверять robots.txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
Выводы
- Файл robots.txt — это служебный документ, который создается для корректной индексации сайта поисковыми роботами. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
- Файл создается в Notepad++ или любом другом текстовом редакторе. Структура robots. txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
- Заполнять файл следует по правилам, начиная с кода User-agent. Директивы необходимо объединять в группы, отделяя блоки пустой строкой. С помощью директив Disallow и Allow можно запрещать и разрешать индексацию страниц, папок и отдельных файлов.
- Размер robots.txt не должен превышать 32 КБ. Размещать файл необходимо в корневой директории сайта рядом с основным файлом index.html.
- Проверить robots.txt на наличие ошибок можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tools.
 txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
Статья
Как закрыть сайт от индексации в robots.txt
#SEO, #Яндекс, #Google
Статья
Кейс «Горторгснаб» — увеличили видимость сайта, число запросов и трафик
#SEO, #Яндекс
Статья
Контекстная реклама
#Яндекс, #Google
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры».
Теги:
SEO, Яндекс, Google
Файл Robots txt — настройка, как создать и проверить: пример robots txt на сайте, директивы
Текстовый файл, записывающий специальные инструкции для поискового робота, ограничивающие доступ к содержимому на http сервере, находящийся в корневой директории веб-сайта и имеющий путь относительно имени самого сайта (/robots.txt ).
Robots.txt — как создать правильный файл robots.txt
Файл robots.txt позволяет управлять индексацией вашего сайта. Закрыть какой-либо раздел можно директивой disallow, открыть — allow. Проверка и анализ robots.txt.
Выгрузить в xls, файл, индексация, сайт, директива, яндекс, настройка, запрет, проверка, пример, генератор, анализ, страница, правильный, закрыть, создать, добавить, проверить, задать, запретить, сделать, robots, txt, host, закрытый, где, disallow
Robots. txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
Почему важно создавать файл robots.txt для сайта
В 2011 году случилось сразу несколько громких скандалов, связанных с нахождением в поиске Яндекса нежелательной информации.
Сначала в выдаче Яндекса оказалось более 8 тысяч SMS-сообщений, отправленных пользователями через сайт компании «МегаФон». В результатах поиска отображались тексты сообщений и телефонные номера, на которые они были отправлены.
Заместитель генерального директора «МегаФона» Валерий Ермаков заявил, что причиной публичного доступа к данным могло стать наличие у клиентов «Яндекс.Бара», который считывал информацию и отправлял поисковому роботу Яндекса.
У Яндекса было другое объяснение:
«Еще раз можем подтвердить, что страницы с SMS с сайта МегаФона были публично доступны всем поисковым системам… Ответственность за размещение информации в открытом доступе лежит на том, кто её разместил или не защитил должным образом.
Особо хотим отметить, что никакие сервисы Яндекса не виноваты в утечке данных с сайта МегаФона. Ни Яндекс.Бар, ни Яндекс.Метрика не скачивают содержимое веб-страниц. Если страница закрыта для индексации в файле robots.txt или защищена логином и паролем, то она недоступна и поисковым роботам, то есть информация, размещенная на ней, никогда не окажется в какой-либо поисковой системе».
 ..
..Вскоре после этого пользователи нашли в Яндексе несколько тысяч страниц со статусами заказов в онлайн-магазинах книг, игр, секс-товаров и т.д. По ссылкам с результатов поиска можно было увидеть ФИО, адрес и контактные данные клиента магазина, IP-адрес, наименование его покупки, дату и время заказа. И снова причиной утечки стал некорректно составленный (или вообще отсутствующий) файл robots.txt.
Чтобы не оказаться в подобных ситуациях, лучше заранее составить правильный robots.txt файл для сайта. Как сделать robots. txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
Как создать robots.txt для сайта
Настройка robots.txt начинается с создания текстового файла с именем «robots.txt». После заполнения этот файл нужно будет сохранить в корневом каталоге сайта, поэтому лучше заранее проверить, есть ли к нему доступ.
Основные директивы robots.txt
В простейшем файле robots.txt используются следующие директивы:
- User-agent
DisallowAllow
Директива User-agent
Здесь указываются роботы, которые должны следовать указанным инструкциям. Например, User-agent: Yandex означает, что команды будут распространяться на всех роботов Яндекса. User-agent: YandexBot – только на основного индексирующего робота. Если в данном пункте мы поставим *, правило будет распространяться на всех роботов.
Директива Disallow
Эта команда сообщает роботу user-agent, какие URL не нужно сканировать. При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
Как закрыть части сайта с помощью директивы Disallow:
- Если нужно закрыть от сканирования весь сайт, необходимо использовать косую черту (
/):Disallow: / -
Если нужно закрыть от сканирования каталог со всем его содержимым, необходимо ввести его название и косую черту в конце:Disallow: /events/ -
Если нужно закрыть страницу, необходимо указать название страницы после косой черты:Disallow: /file.html
Директива Allow
Разрешает роботу сканировать сайт или отдельные URL.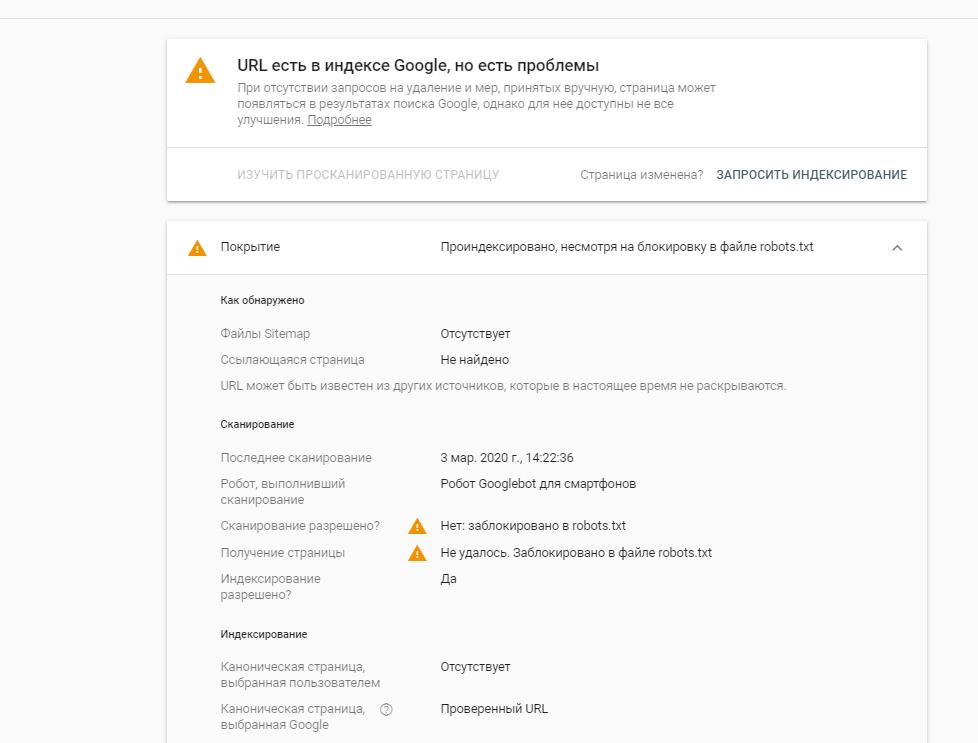
В примере ниже robots.txt запрещает роботам Яндекса сканировать весь сайт за исключением страниц, начинающихся с «events»:
User-agent: Yandex
Allow: /events
Disallow: /
Спецсимволы в директивах
Для директив Allow и Disallow используются спецсимволы «*» и «$».
Звездочка (*) подразумевает собой любую последовательность символов. Например, если нужно закрыть подкаталоги, начинающиеся с определенных символов:Disallow: /example*/-
По умолчанию символ * ставится в конце каждой строки. Если нужно закончить строку определенным символом, используется спецсимвол $. Например, если нужно закрытьURL, заканчивающиеся наdoc:Disallow: /*.doc$ -
Спецсимвол # используется для написания комментариев и не учитывается роботами.

Дополнительные директивы robots.txt
Директива Host
Директива Host в robots.txt используется, чтобы указать роботу на главное зеркало сайта.
Пример:
https://www.glavnoye-zerkalo.ru является главным зеркалом сайта, и для всех сайтов из группы зеркал необходимо прописать в robots.txt:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://www.glavnoye-zerkalo.ru
Правила использования директивы Host:
- В файле robots.txt может быть только одна директива
Host. Робот всегда ориентируется на первую директиву, даже если их указано несколько. - Если зеркало доступно по защищенному каналу, нужно добавить протокол HTTPS,
- Должно быть указано одно доменное имя и номер порта в случае необходимости.

Если директива Host прописана неправильно, роботы ее проигнорируют.
Директива Crawl-delay
Директива Crawl-delay задает для робота промежуток времени, с которым он должен загружать страницы. Пригодится в случае сильной нагрузки на сервер.
Например, если нужно задать промежуток в 3 секунды между загрузкой страниц:
User-agent: *
Disallow: /search
Crawl-delay: 3
Директива Clean-param
Пригодится для сайтов, страницы которых содержат динамические параметры, которые не влияют на их содержимое (например, идентификаторы сессий). Директива позволяет роботам не перезагружать дублирующуюся информацию, что положительно сказывается на нагрузке на сервер.
Использование кириллицы
При составлении файла robots.txt нельзя использовать кириллические символы. Допускается использование Punycode для доменов.
Как проверить robots.txt
Для проверки файла robots.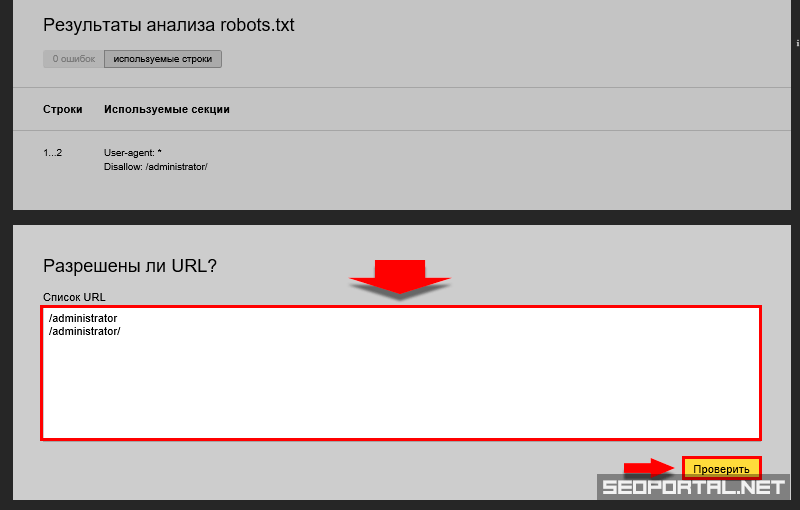 txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
Как добавить файл robots.txt на сайт
Как только файл robots.txt написан и проверен, его нужно сохранить в виде текстового файла с названием robots.txt и загрузить в каталог верхнего уровня сайта или в корневой каталог.
Веб-парсер robots.txt с открытым исходным кодом Google Код
Изюминка: недавно я играл с игрушечным проектом и развернул его как бесплатный веб-инструмент для проверки того, как Google будет анализировать ваших роботов. txt, учитывая, что их собственный онлайн-инструмент не воспроизводит реальное поведение робота Googlebot. Проверьте это на realrobotstxt.com.
Готовясь к моей недавней презентации в SearchLove London, я был слегка одержим тем, что чем глубже я копался в том, как работают файлы robots.txt, тем больше удивительных вещей я находил и тем больше я находил мест, где противоречивая информация из разных источников. Парсер Google robots.txt с открытым исходным кодом должен был все упростить, не только соответствуя их недавно опубликованному черновому варианту спецификации, но и, по-видимому, являясь реальным производственным кодом Google.
Парсер Google robots.txt с открытым исходным кодом должен был все упростить, не только соответствуя их недавно опубликованному черновому варианту спецификации, но и, по-видимому, являясь реальным производственным кодом Google.
Две проблемы завели меня дальше в кроличью нору, что в конечном итоге привело к созданию веб-инструмента:
- Это проект C++, поэтому его необходимо скомпилировать, что требует хотя бы некоторых навыков программирования/администрирования кода, поэтому я не чувствовал, что это было особенно доступно для более широкого поискового сообщества
- Когда я скомпилировал его и поэкспериментировал с ним, я обнаружил, что в нем отсутствуют важные специфические для Google функции, позволяющие нам увидеть, как поисковые роботы Google, такие как изображения и видео, будут интерпретировать файлы robots.txt
Чем этот инструмент отличается от других ресурсов
Помимо того, что он представляет собой веб-инструмент, а не требует компиляции для локального запуска, мой инструмент realrobotstxt.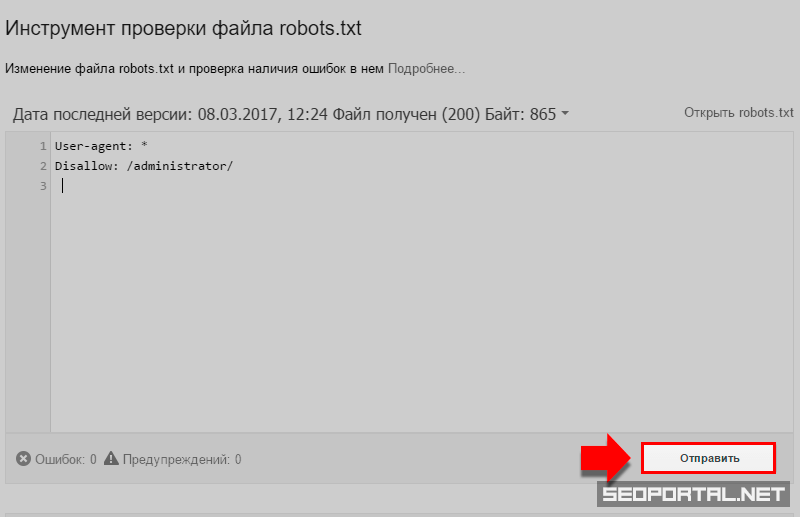 com должен на 100 % соответствовать проекту спецификации, опубликованному Google, поскольку он полностью основан на их инструменте с открытым исходным кодом, за исключением двух конкретных изменений, которые я внес, чтобы привести его в соответствие с моим пониманием того, как работают настоящие поисковые роботы Google:
com должен на 100 % соответствовать проекту спецификации, опубликованному Google, поскольку он полностью основан на их инструменте с открытым исходным кодом, за исключением двух конкретных изменений, которые я внес, чтобы привести его в соответствие с моим пониманием того, как работают настоящие поисковые роботы Google:
- Googlebot-image, Googlebot-video и Googlebot-news(*) все должны вернуться к подчинению Googlebot директивы, если нет наборов правил конкретно нацелены на их собственные индивидуальные пользовательские агенты – мы убедились, что это, по крайней мере, то, как бот изображений ведет себя в реальном мире
- У Google есть ряд ботов (AdsBot-Google, AdsBot-Google-Mobile и бот AdSense, Mediapartners-Google), которые, по-видимому, игнорируют директивы User-agent: * и только подчиняются наборам правил, специально предназначенным для их отдельных пользователей. агенты
[(*) Примечание: не имеет отношения к настройкам, которые я сделал, но имеет значение, потому что я упомянул Googlebot-news, очень мало известно, что Googlebot-news не является поисковым роботом и не был им с 2011 года, по всей видимости.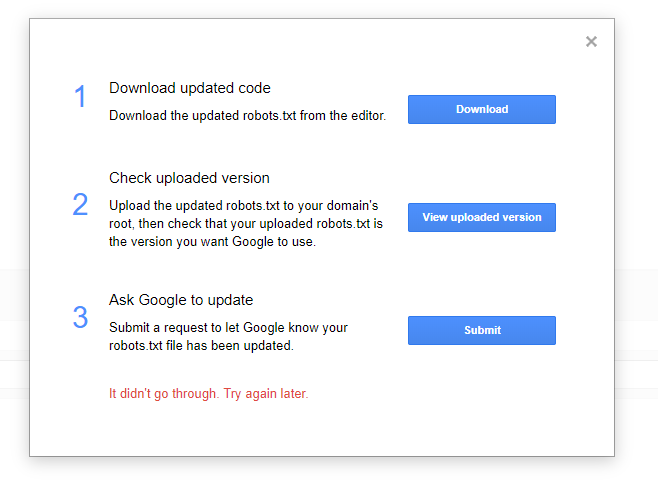 Если вы этого не знали, не переживайте — вы не одиноки. Я узнал об этом только недавно, и довольно сложно отличить его от документации, которая регулярно называет его поисковым роботом. Единственная реальная официальная ссылка, которую я могу найти, — это сообщение в блоге, объявляющее о его выходе из эксплуатации. Я имею в виду, что для меня это имеет смысл, потому что наличие разных сканеров для веб-поиска и поиска новостей открывает опасные возможности маскировки, но почему тогда в документации он упоминается как пользовательский агент сканера? Это кажется , хотя я не смог проверить это в реальной жизни, как будто правила, непосредственно нацеленные на Googlebot-news, функционируют как noindex для Google News. Это очень сбивает с толку, потому что обычная блокировка Googlebot , а не удерживает URL-адреса вне веб-индекса, но вот так.]
Если вы этого не знали, не переживайте — вы не одиноки. Я узнал об этом только недавно, и довольно сложно отличить его от документации, которая регулярно называет его поисковым роботом. Единственная реальная официальная ссылка, которую я могу найти, — это сообщение в блоге, объявляющее о его выходе из эксплуатации. Я имею в виду, что для меня это имеет смысл, потому что наличие разных сканеров для веб-поиска и поиска новостей открывает опасные возможности маскировки, но почему тогда в документации он упоминается как пользовательский агент сканера? Это кажется , хотя я не смог проверить это в реальной жизни, как будто правила, непосредственно нацеленные на Googlebot-news, функционируют как noindex для Google News. Это очень сбивает с толку, потому что обычная блокировка Googlebot , а не удерживает URL-адреса вне веб-индекса, но вот так.]
Я ожидаю скорого прекращения поддержки средства проверки robots.txt в Search Console
Мы наблюдаем постепенный переход чтобы отключить старые функции Search Console, и я ожидаю, что программа проверки robots.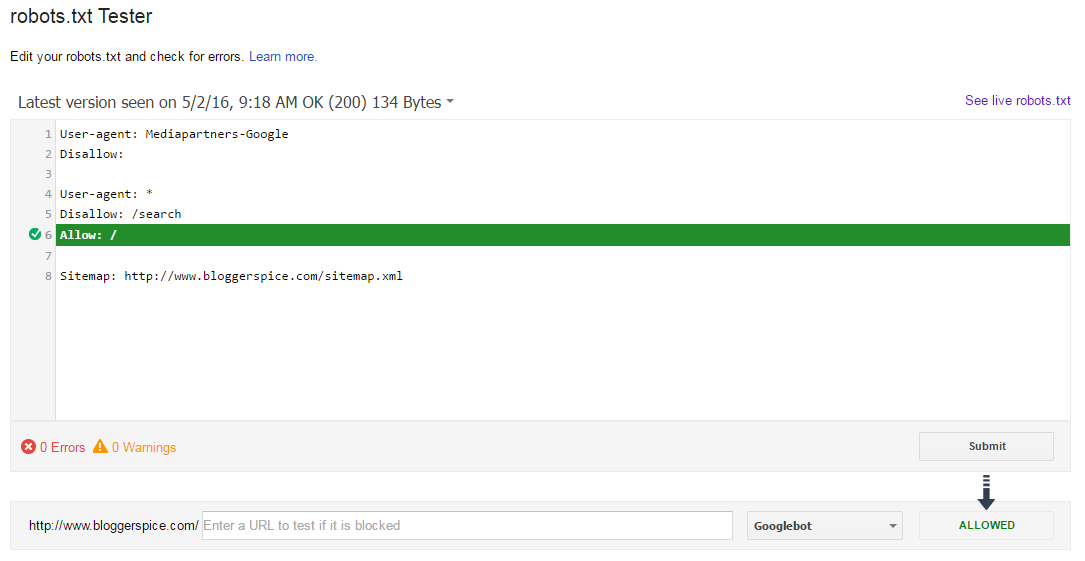 txt скоро будет удалена. Сотрудники Google недавно говорили о том, что они не соответствуют тому, как работают их настоящие сканеры, и мы можем увидеть различия в нашем собственном тестировании:
txt скоро будет удалена. Сотрудники Google недавно говорили о том, что они не соответствуют тому, как работают их настоящие сканеры, и мы можем увидеть различия в нашем собственном тестировании:
Эти случаи, кажется, правильно обрабатываются синтаксическим анализатором с открытым исходным кодом — вот мой веб-инструмент по точно такому же сценарию:
Это показалось мне еще одной причиной для выпуска моей веб-версии, поскольку единственный официальный веб-инструмент, который у нас есть, устарел и, вероятно, исчезнет. Кто знает, выпустит ли Google обновленную версию на основе своего парсера с открытым исходным кодом, но пока этого не произойдет, мой инструмент может оказаться полезным для некоторых людей.
Я бы хотел, чтобы документация обновлялась
К сожалению, хотя я могу сделать запрос на включение открытого исходного кода, я не могу сделать то же самое с документацией Google. Несмотря на заявления Google о том, что старая программа проверки Search Console не синхронизирована с реальным роботом Googlebot, и, следовательно, ей не следует доверять как авторитетному ответу о том, как Google будет анализировать файл robots.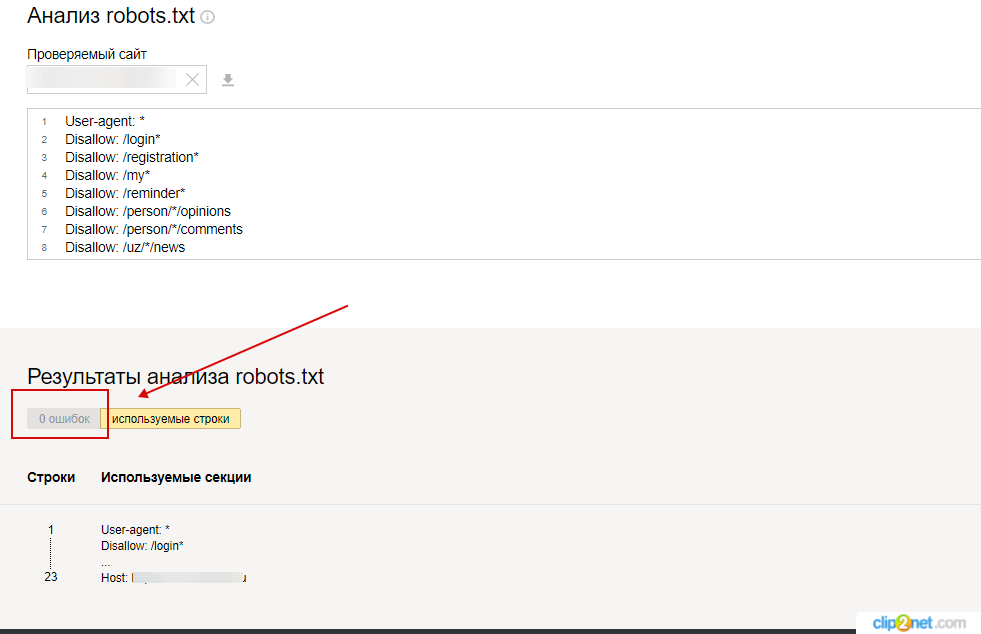 txt, ссылки на нее по-прежнему широко распространены в документации. :
txt, ссылки на нее по-прежнему широко распространены в документации. :
- Введение в robots.txt
- Избегайте распространенных ошибок
- Создайте файл robots.txt
- Проверьте файл robots.txt с помощью тестера robots.txt
- Отправьте обновленный robots.txt в Google
- Отладка ваших страниц
Кроме того, хотя вполне естественно, что старые сообщения в блогах могут не обновляться новой информацией, они по-прежнему занимают видное место в некоторых связанных поисковых запросах:
- Новая функция robots.txt и метатеги REP
- Тестирование файлов robots.txt стало проще
Кто знает. Может быть, они обновят документы со ссылками на мой инструмент 😉
Дайте мне знать, если это будет вам полезно
В любом случае. Я надеюсь, что вы найдете мой инструмент полезным — мне понравилось немного поковыряться с C++ и Python, чтобы сделать его — иногда хорошо иметь проект «создатель» на ходу, когда ваша повседневная работа не связана с доставкой кода. Если вы заметили какие-либо странности, вопросы или просто нашли это полезным, напишите мне, чтобы я знал. Вы можете найти меня в Твиттере.
Если вы заметили какие-либо странности, вопросы или просто нашли это полезным, напишите мне, чтобы я знал. Вы можете найти меня в Твиттере.
Robots.txt для электронной торговли
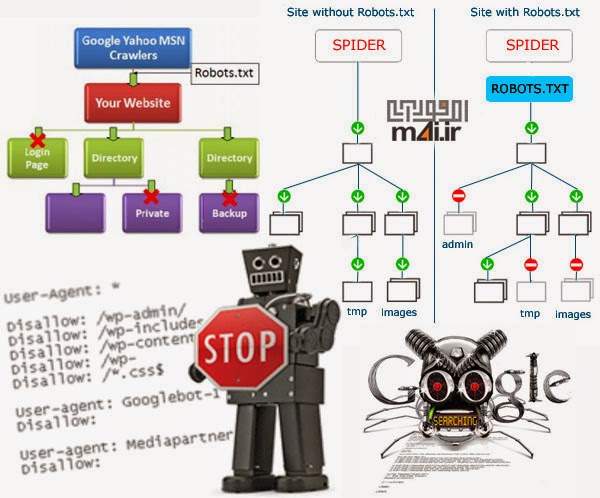
Если у вас есть веб-сайт электронной коммерции и вы работаете с хорошим разработчиком, возможно, у вас уже есть файл robots.txt в корневом каталоге. Поисковые системы используют роботов (также известных как пауки или сканеры) для поиска и классификации веб-сайтов, а страницы, которые они находят во время сканирования, — это страницы, которые отображаются в результатах поиска, когда кто-то выполняет поиск в Google, Bing или любом другом крупном веб-сайте. поисковый движок. Ваш файл robots.txt — это эффективный способ сообщить поисковым системам, какие области веб-сайта следует , а не обрабатываться или сканироваться.
Ползать или не ползать? Вот в чем вопрос
Без файла robots.txt ваш веб-сайт электронной коммерции полностью открыт и доступен для сканирования, что звучит как хорошая вещь. Но использование полосы пропускания для нерелевантного и устаревшего контента может происходить за счет сканирования и индексации важных и ценных страниц. У вас могут быть даже некоторые ключевые страницы, которые полностью пропускаются.
Но использование полосы пропускания для нерелевантного и устаревшего контента может происходить за счет сканирования и индексации важных и ценных страниц. У вас могут быть даже некоторые ключевые страницы, которые полностью пропускаются.
Если флажок не установлен, робот поисковой системы может сканировать ссылки на вашу корзину покупок, ссылки на список пожеланий, страницы входа администратора, ваш сайт разработки или тестовые ссылки или другой контент, который вы не хотите отображать в результатах поиска. Сканеры могут найти личную информацию, временные файлы, страницы администрирования и другие страницы, содержащие информацию, доступ к которой вы, возможно, не подозревали.
Важно помнить, что у каждого веб-сайта есть «бюджет сканирования» — ограниченное количество страниц, которые можно включить в сканирование. Вы хотите убедиться, что ваши самые важные страницы проиндексированы и что вы не тратите время на поиск временных файлов.
Подробнее
Хотя файл robots. txt может быть полезен для блокировки контента, который вы не хотите индексировать, иногда файлы robots.txt непреднамеренно блокируют контент, который делают владельцы веб-сайтов требуется просканировать и проиндексировать. Если у вас возникли проблемы с тем, что некоторые из ваших ключевых страниц не индексируются, файл robots.txt — хорошее место для проверки, чтобы выявить проблему. Рекомендуется следить за содержимым файла robots.txt и обновлять его.
txt может быть полезен для блокировки контента, который вы не хотите индексировать, иногда файлы robots.txt непреднамеренно блокируют контент, который делают владельцы веб-сайтов требуется просканировать и проиндексировать. Если у вас возникли проблемы с тем, что некоторые из ваших ключевых страниц не индексируются, файл robots.txt — хорошее место для проверки, чтобы выявить проблему. Рекомендуется следить за содержимым файла robots.txt и обновлять его.
Существует ряд SEO-инструментов, которые можно использовать, чтобы увидеть, что может блокировать файл robots.txt, и один из лучших инструментов можно найти бесплатно в Google Search Console.
С помощью тестера robots.txt Tester Google Search Console вы можете протестировать определенные страницы, чтобы узнать, сканируются они или нет. Не забудьте использовать файл Sitemap в формате XML, чтобы составить список страниц, которые вы сделать хотите, чтобы Google сканировал. Если вы автоматически создаете свой файл Sitemap в формате XML, вы можете непреднамеренно включить в файл robots.