Содержание
что это такое, как работает и для чего он нужен
Наверняка в адресной строке браузера вы замечали аббревиатуру, с которой начинаются все доменные имена — http (или https). Она означает, что ваш браузер для загрузки веб-страницы использует протокол HTTP. Разберем, почему все так устроено в современном интернете и каково предназначение этого протокола.
Что такое HTTP
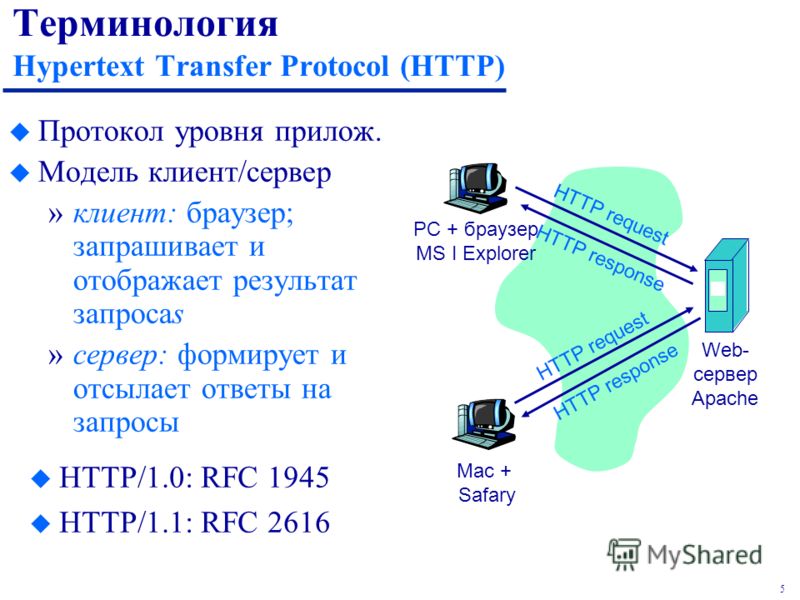
Сама аббревиатура HTTP расшифровывается как Hyper Text Transfer Protocol, или в переводе «протокол передачи гипертекста». Протокол HTTP служит для передачи данных между пользовательским приложением (как правило, браузером) и веб-сервером.
Краткая история протокола
Создателем HTTP принято считать Тима Бернерса-Ли, «отца» всемирной паутины. Тогда в 1991 году интернета, можно считать, практически не существовало. Разрабатывался он Бернерсом-Ли не ради каких-то глобальных целей, а для решения конкретной задачи — обеспечить доступ к информационным ресурсам лаборатории CERN.
Однако HTTP оказался настолько удобен, что уже в 1993 году опубликовали спецификацию HTTP/0. 9, которая была доступна любому желающему. Она содержала определения ключевых понятий, синтаксис, но в то же время давала возможность расширения и развития протокола. Кроме того, был обнародован исходный код программы, которая позволяла просматривать передаваемый по HTTP гипертекст. Это был буквально прорыв, ознаменовавших новую веху всемирной паутины.
9, которая была доступна любому желающему. Она содержала определения ключевых понятий, синтаксис, но в то же время давала возможность расширения и развития протокола. Кроме того, был обнародован исходный код программы, которая позволяла просматривать передаваемый по HTTP гипертекст. Это был буквально прорыв, ознаменовавших новую веху всемирной паутины.
Сначала HTTP использовали только для передачи непосредственно гипертекста, однако позже стало очевидно, что протокол подходит и для бинарных данных — так с его помощью стали передавать картинки и аудиофайлы.
Через три года после публикации первой спецификации, в 1996 году, свет увидел релиз HTTP/1.0. Новая версия значительно расширяла возможности первой спецификации и вводила новый тип данных для передачи application/octet-stream, благодаря чему была официально легализована передача нетекстовой информации.
А вот HTTP/1.1, опубликованную в 1999 году, можно по праву признать долгожителем среди спецификаций — она не менялась в течение целых 16 лет. И, кстати, стала фундаментом для других протоколов.
И, кстати, стала фундаментом для других протоколов.
Не так давно, в 2015 году, появилась «черновая» версия HTTP/2. Она значительно отличается от всех предыдущих спецификаци. В частности, HTTP/2:
- уже не является переработкой первой версии HTTP/0.9;
- имеет бинарный формат представления данных;
- в обязательном порядке требует шифрования и другое.
Кто участвует в передаче данных по HTTP
Уже по его названию можно догадаться, что протокол HTTP для передачи данных использует текст, несмотря на то, что пересылаемые от сервера клиенту сообщения могут содержать и видео, и аудио, и картинки.
Кто же эти клиент и сервер?
- Клиент — тот, кто посылает запрос.
- Сервер — тот, кто на этот запрос отвечает.
Любой запрос клиента отправляется на сервер, который обрабатывает его и отвечает, предоставляя данные по запросу клиента. При этом их общение не идет напрямую — на пути от клиента к серверу и наоборот присутствуют и другие объекты, а точнее прокси-серверы.
Итак, в передаче данных по протоколу HTTP участвуют три главных игрока: клиент, веб-сервер, прокси-сервер. Познакомимся с ними подробнее.
- Клиент
- Веб-сервер
- Прокси
- Балансировка нагрузки
- Кэширование
- Аутентификация
- Логирование
- Веб-фильтрация
Любое приложение, действующее от имени пользователя, чья ключевая задача — отправить запрос и получить в ответ на него сообщение. Если речь идет об обычном серфинге в интернете, то в роли клиента выступает установленный на вашем устройстве веб-браузер.
Запрос от клиента в конечном итоге приходит на веб-сервер. Он, в свою очередь, отдает документ по запросу клиента. Кстати, стоит помнить, что роль веб-сервера может играть и одна виртуальная машина (ВМ), и сразу несколько, которые делят между собой нагрузку и по очереди отвечают на запросы.
В качестве прокси-сервера может быть любое устройство, находящееся между клиентом и сервером. Казалось бы, зачем в этой парадигме какие-то посредники? Однако разработчики могут внедрять прокси-серверы для разных задач.
Благодаря балансировке все запросы будут обрабатывать не один-единственный сервер, а сразу несколько. По какому принципу будет распределяться нагрузка, зависит от конкретного способа балансировки, который решил использовать разработчик. Как правило, это делают для того, чтобы сервер «не захлебнулся» большим потоком запросов и не перестал отвечать.
Кэш-серверы сохраняют контент страниц у себя, что позволяет быстрее отвечать на запросы и меньше нагружать сервер-источник. По такому принципу работает сеть Content Delivery Network (CDN).
Для реализации политик прав доступа к данным веб-приложения или сайта.
Для хранения информации, например, IP-адресов устройств, отправивших запрос на веб-сервер.
Для контроля доступа к небезопасным или запрещенным веб-ресурсам.
HTTP: алгоритм работы
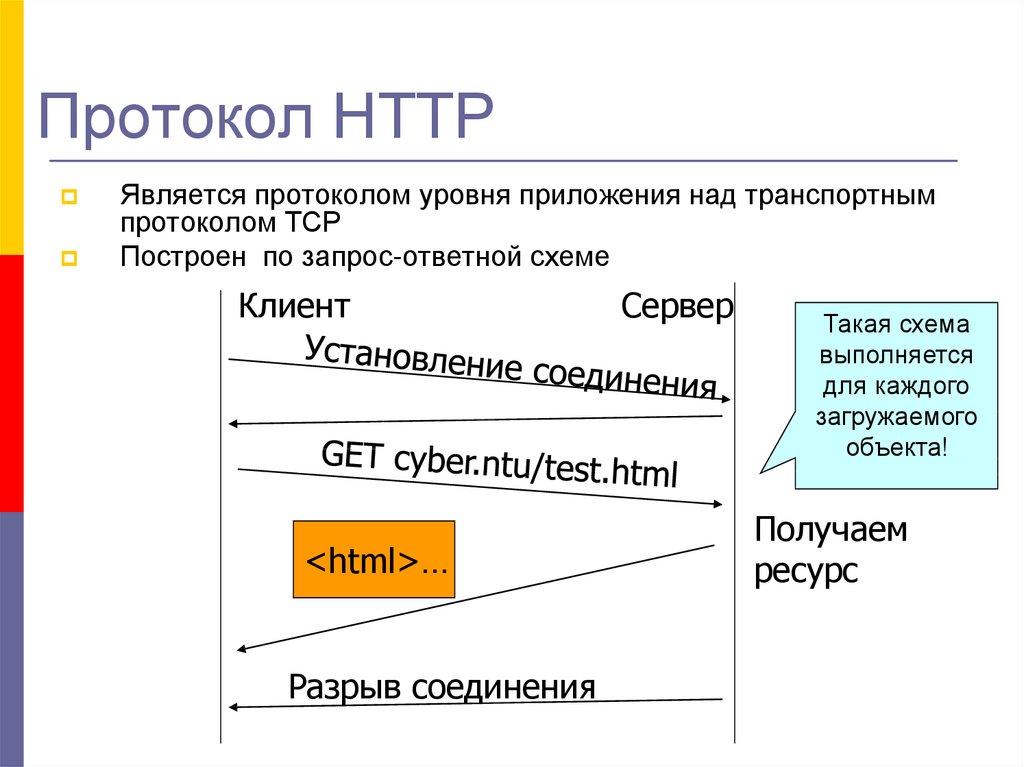
- Этап No1: ввод URL
- Этап No2: поиск IP
- Этап No3: отправка HTTP-запроса
- с помощью GET браузер как бы демонстрирует, что хочет получить некую информацию в ответ на этот запрос;
- /page.html — путь к требуемой веб-странице;
- HTTP/1.1 — используемая версия протокола;
- www.site.com — доменное имя запрашиваемого ресурса.
- POST
- HEAD
- Этап No4: отправка HTTP-ответа
- 404 — страница не найдена;
- 400 — если запрос был сформирован неправильно;
- 500 — неудачная обработка запроса и другие.
- Content-Type: text/html; charset=UTF-8
- Content-Length: 258
- Этап No5: открывается запрашиваемая страница сайта
Пользователь вводит адрес нужной веб-страницы в адресную строку браузера или переходит на новую страницу по ссылке.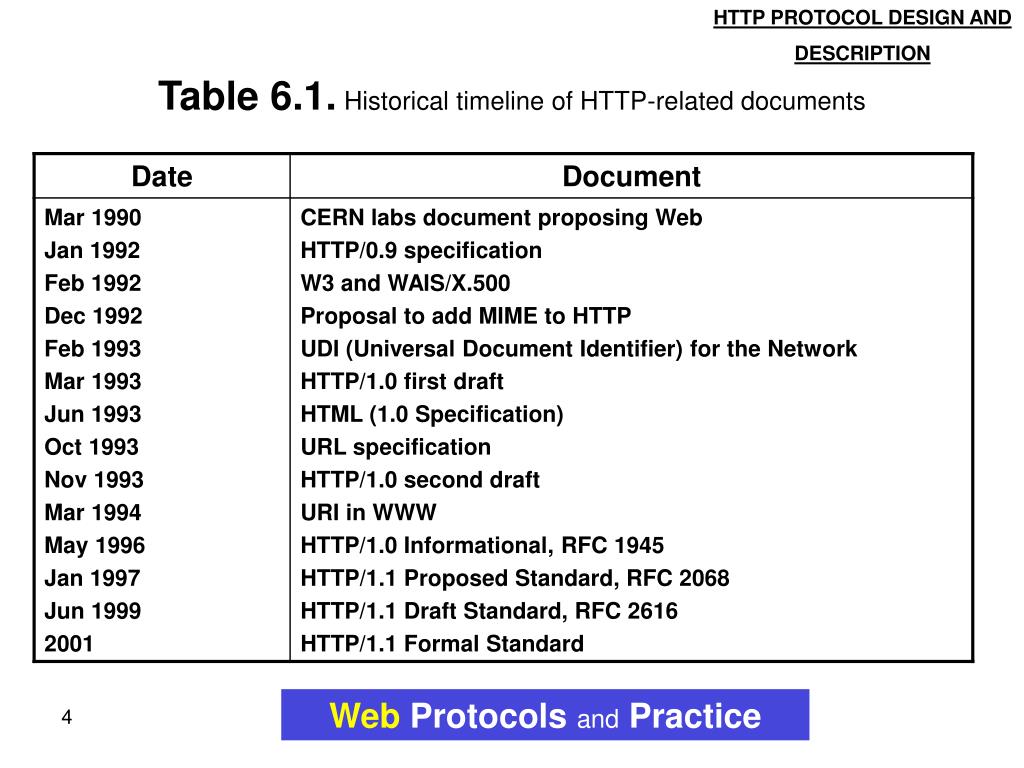
Обратите внимание: любой URL начинается с http/https. Это говорит браузеру, что для получения информации нужно использовать протокол HTTP.
Браузер с помощью DNS, о которой мы рассказывали в одной из наших статей, находит соответствующий введенному доменному имени IP-адрес.
После того как браузер установил нужный IP-адрес, он отправляет HTTP-запрос.
Пример HTTP-запроса:
GET/page.html HTTP/1.1
Host: www.site.com
Кроме GET, можно использовать и другие методы отправки запросов. Например:
При отправке POST-запроса параметры помещаются не прямо в URL, а в тело запроса.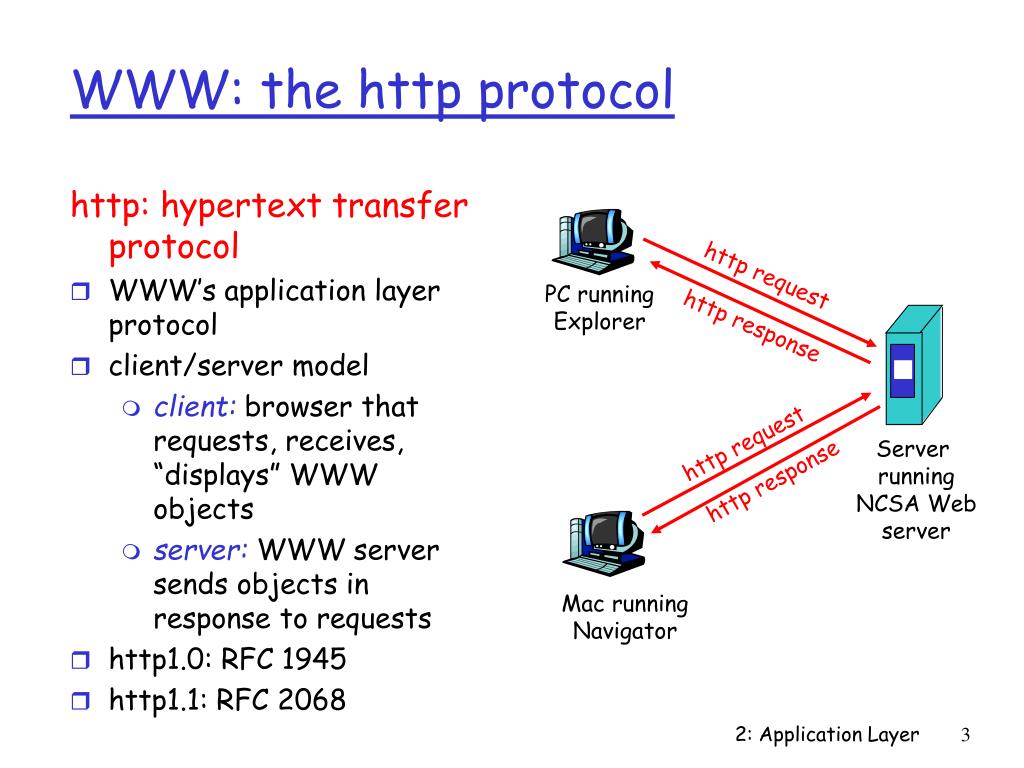
HEAD-запросы работают так же как и те, что отправляются с помощью метода GET, но клиент получает от сервера не все данные, а только информацию заголовка.
Если есть запрос, то должен быть и ответ, верно? Как мы уже разобрали выше, за отправку ответов отвечает сервер.
HTTP-ответ начинается так же, как и запрос, — с используемой версии HTTP:
HTTP/1.1 200 OK
За ним следует код ответа. В примере выше это 200, он означает, что запрашиваемый документ успешно извлечен.
Браузер может отдавать и другие коды, например:
После строки, в которой указывается версия протокола и код ответа, следуют заголовки. Благодаря им браузер получает дополнительные сведения и корректно отображает контент.
Как правило, в большинстве заголовков можно найти такие строки:
Content-Type указывает на тип отправляемого в ответ на запрос документа. Чаще всего значением этого параметра является text/html, так как любая веб-страница — это все еще текстовый HTML-файл, даже если она содержит какой-то динамический контент. Бывают и другие типы, например, изображения, скрипты и тому подобное.
Чаще всего значением этого параметра является text/html, так как любая веб-страница — это все еще текстовый HTML-файл, даже если она содержит какой-то динамический контент. Бывают и другие типы, например, изображения, скрипты и тому подобное.
В строке Content-Length записывается длина документа в байтах.
Если все шаги выше были выполнены успешно, пользователь увидит нужную ему веб-страницу.
Особенности протокола HTTP
Так как HTTP — не единственный протокол, крайне желательно понимать его особенности и отличия от «собратьев».
- Использование cookies
- Наличие заголовка Content-Type
Cookies — небольшой полученный от сервера «кусочек» данных, который хранится на клиентском устройстве, например, ПК. Используются куки для аутентификации, сохранения пользовательских настроек, отслеживания состояния сессии или ведения статистики о пользователе.
Перед передачей данных протокол передает заголовок «Content-Type: тип/подтип». С его помощью клиент (в большинстве случаев браузер) определяет, как именно обрабатывать данные, которые будут получены после заголовка. Это еще одно отличие HTTP от FTP и файловых протоколов, которые определяют тип контента по расширению файла. Эта особенность играет важную роль при обработке CGI-скриптов. В случае с ними расширение файла указывает не на тип контента, а на необходимость запуска скрипта на сервере и отправку результата его работы.
С его помощью клиент (в большинстве случаев браузер) определяет, как именно обрабатывать данные, которые будут получены после заголовка. Это еще одно отличие HTTP от FTP и файловых протоколов, которые определяют тип контента по расширению файла. Эта особенность играет важную роль при обработке CGI-скриптов. В случае с ними расширение файла указывает не на тип контента, а на необходимость запуска скрипта на сервере и отправку результата его работы.
Плюсы и минусы HTTP
Несмотря на глобальное распространение протокола, многолетняя практика его использования вскрыла как преимущества, так и недостатки HTTP.
Преимущества
- Расширяемость
- Большое количество документации
Возможность расширения была заложена в протокол еще на этапе его разработки. В процессе эволюции HTTP «обрастал» новыми методами, кодами ответов, заголовками и возможностями. Например, в HTTP/3, самой свежей версии, в качестве вместо TCP уже используется QUIC от компании Google.
HTTP хорошо задокументирован — документация есть на разных языках, что позволяет использовать его широкому кругу разработчиков.
Недостатки
- Нет «навигации»
- Нет поддержки распределенности
У HTTP нет явных средств навигации по ресурсам сервера. Простой пример: работая с FTP, пользователь может запросить полный список доступных файлов, а вот HTTP сделать это не позволяет. К счастью, этот недостаток уже устранили в протоколе WebDAV, который расширяет HTTP методом PROPFIND. С его помощью можно получить дерево каталогов и параметры каждого доступного ресурса.
Как вы помните из истории HTTP, протокол изначально создавался для решения простой задачи, поэтому время обработки HTTP-запросов не учитывали. Однако позже его популярность и распространение выросли, и стало понятно, что HTTP не подходит в ситуациях, когда на сервер идет высокая нагрузка. Решить эту проблему в 1998 году предлагали с помощью HTTP-NG (NG — Next Generation), однако этот экспериментальный протокол так никогда и не использовали.
HTTPS: да здравствует безопасность
Несмотря на все очевидные плюсы HTTP, у него есть еще один недостаток, о котором мы умолчали ранее.
Протокол HTTP никак не защищает передаваемые данные.
Помните, ранее мы говорили, что на пути от клиента к серверу (или наоборот) могут находится множество посредников? Если хотя бы один из промежуточных узлов попадет под контроль злоумышленника, данные могут быть перехвачены. Для решения этой проблемы сегодня используется HTTPS.
HTTPS — это расширение протокола HTTP с поддержкой шифрования.
И если буквально 5-10 лет назад в интернете существовало множество сайтов и сервисов, работающих по HTTP, сегодня все современные браузеры требуют применения именно HTTPS.
Как реализована защита данных в HTTPS
При передаче информации по HTTPS все данные шифруются с помощью криптографического протокола SSL/TLS. Он защищает все, что передается от сервера клиенту, от посторонних глаз и не позволяет перехватить трафик.
Давайте на простом примере посмотрим, как работает такая «обертка».
Допустим, вы хотите передать посылку знакомому.
- Для этого вы кладете ее в специальный ящик, закрываете его на замок и отправляете по почте.

- Почтальон доставляет сейф адресату, но открыть замок он все равно не может — ключа-то нет.
- Тогда получатель вешает на ящик еще один, уже свой замок, и снова отправляет его вам.
- Вы открываете свой замок и отправляете ящик опять своему знакомому.
- На пути от отправителя к адресату открыть ящик снова никто не может — он все еще закрыт на второй замок.
- А вот получатель может. Он забирает на почте или у курьера ящик и открывает его своим ключом.
Примерно так же работает SSL/TLS. Клиент и сервер выбирают общий секретный ключ и только потом обмениваются друг с другом данными, которые с помощью этого ключа зашифрованы. Перехватить или подобрать ключ не получится. Но как убедиться, что ваш визави — именно тот, за кого он себя выдает? Для этого существуют цифровые сертификаты.
Цифровой сертификат — это документ, с помощью которого происходит идентификация сервера. Его должен иметь любой сайт (сервер), с которым необходимо установить защищенное соединение. Он подтверждает, что лицо, которому он выдан, на самом деле существует и управляет указанным в сертификате сервером. Если в левой части адресной строки вы видите иконку замочка, значит, у сайта есть SSL-сертификат и данные при передаче шифруются с помощью криптографии.
Он подтверждает, что лицо, которому он выдан, на самом деле существует и управляет указанным в сертификате сервером. Если в левой части адресной строки вы видите иконку замочка, значит, у сайта есть SSL-сертификат и данные при передаче шифруются с помощью криптографии.
что это такое, для чего служит протокол
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Аудит и стратегия продвижения в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
HTTP — это протокол, позволяющий передавать данные. Изначально он создавался для отправки и принятия документов, содержащих внутри ссылки для выполнения перехода на сторонние ресурсы.
Аббревиатура читается как «HyperText Transfer Protocol», что в переводе означает «протокол для передачи гипертекста». HTTP относится к группе прикладного уровня на основании специфики, использующейся OSI.
HTTP относится к группе прикладного уровня на основании специфики, использующейся OSI.
Чтобы лучше понять, что значит HTTP, разберем простую аналогию. Представим, что вы общаетесь с иностранцем в социальной сети. Он отправляет вам сообщение на английском языке, вы его получаете. Но понять содержимое вы не можете, так как не достаточно владеете языком. Чтобы расшифровать сообщение, воспользуетесь словарем. Поняв суть, вы отвечаете иностранцу на русском языке и отправляете ответ. Иностранец получает ответ и с помощью переводчика расшифровывает послание. Если упростить весь механизм, протоколы интернета HTTP выполняют функцию переводчика. С их помощью браузер может переводить зашифрованное содержимое веб-страниц и отображать их содержимое.
Для чего нужен HTTP
Протокол HTTP служит для обмена информацией с помощью клиент-серверной модели. Клиент составляет и передает запрос на сервер, затем сервер обрабатывает и анализирует его, после этого создается ответ и отправляется пользователю. По окончании данного процесса клиент делает новую команду, и все повторяется.
По окончании данного процесса клиент делает новую команду, и все повторяется.
Таким образом, протокол HTTP позволяет осуществлять обмен информацией между различными приложениями пользователей и специальными веб-серверами, а также подключаться к веб-ресурсам (как правило, браузерам). Сегодня описываемый протокол обеспечивает работу всей сети. Протокол передачи данных HTTP применяется и для передачи информации по другим протоколам более низкого уровня, например, WebDAV или SOAP. При этом протокол представляет собой средство для транспортировки. Многие программы также основываются на применении HTTP в качестве основного инструмента для обмена информацией. Данные представляются в различных форматах, к примеру, JSON или XML.
HTTP является протоколом для обмена информацией с помощью соединения IP/ ТСР. Как правило, для этого сервер использует порт 80 типа TCP. Если порт не прописан, программное обеспечение клиента будет использовать порт 80 типа TCP по умолчанию. В некоторых случаях могут использоваться и другие порты.
В протоколе HTTP используется симметричная схема шифрования, в его работе применяются симметричные криптосистемы. Симметричные криптосистемы предполагают использование одного и того же ключа для шифрования и расшифрования информации.
Чем отличается HTTP от HTTPS
Отличие можно обнаружить даже из расшифровок аббревиатур. HTTPS расшифровывается как «защита протокола передачи гипертекста». Таким образом, HTTP — самостоятельный протокол, а HTTPS — расширение для его защиты. По HTTP информация передается незащищенной, а HTTPS обеспечивает криптографическую защиту. Особенно актуально это для ресурсов с ответственной авторизацией. Это могут быть социальные сети или сайты платежных систем.
Чем опасна передача незащищенных данных? Программа-перехватчик может в любой момент передать их злоумышленникам. HTTPS имеет сложную техническую организацию, что позволяет надежно защищать информацию и исключить возможность несанкционированного доступа к ней. Отличие заключается и в портах.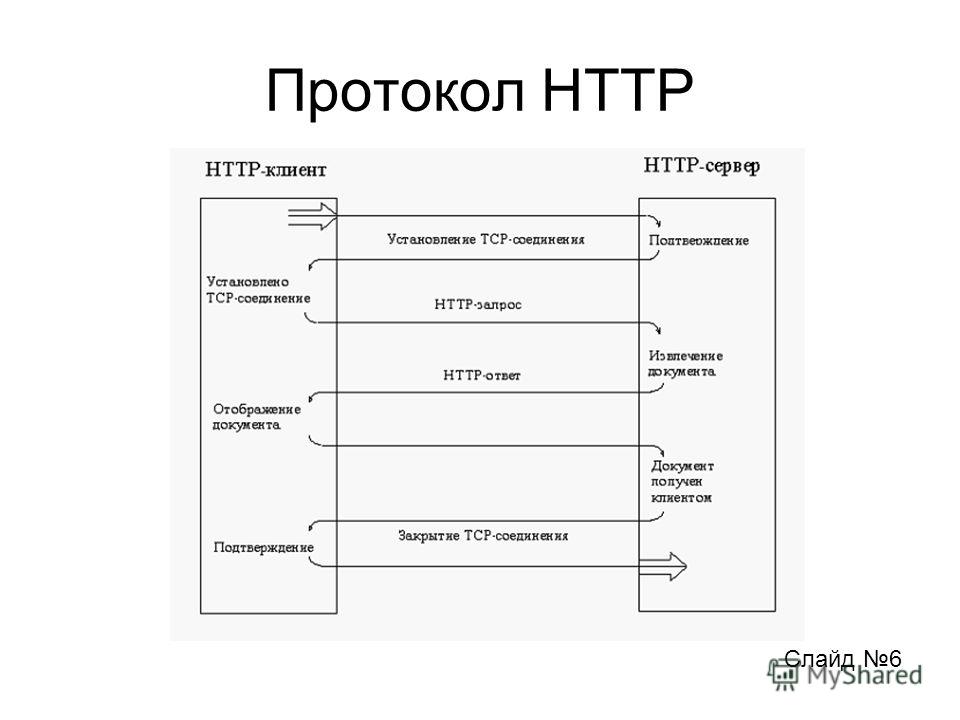 HTTPS, как правило, работает с портом 443.
HTTPS, как правило, работает с портом 443.
Таким образом, HTTP применяется для передачи данных, а HTTPS позволяет осуществлять защищенную передачу данных с помощью шифрования и выполнять авторизацию на ресурсах с высоким уровнем безопасности.
Дополнительный функционал
HTTP отличается богатым функционалом, он совместим с различными расширениями. Используемая сегодня спецификация 1.1 позволяет применять заголовок Upgrade для переключения и работы через другие протоколы при обмене данными. Для этого пользователь должен отправить запрос серверу с данным заголовком. Если же сервер нуждается в переходе на специфичный обмен по иному протоколу, он возвращает клиенту запрос, в котором отображается статус «426 Upgrade Required».
Данная возможность особенно актуальна для обмена информацией через WebSocket (имеет спецификацию RFC 6455 , позволяет обмениваться данными в любой момент, без лишних HTTP-запросов). Для перехода на WebSocket один пользователь отправляет запрос с заголовком Upgrade и значением «websocket». Далее сервер отвечает «101 Switching Protocols». После этого момента начинается передача информация по WebSocket.
Далее сервер отвечает «101 Switching Protocols». После этого момента начинается передача информация по WebSocket.
Обзор HTTP — HTTP
HTTP — это протокол для получения ресурсов, таких как HTML-документы.
Это основа любого обмена данными в Интернете, и это протокол клиент-сервер, что означает, что запросы инициируются получателем, обычно веб-браузером.
Полный документ реконструируется из различных извлеченных вложенных документов, например, текста, описания макета, изображений, видео, сценариев и т. д.
Клиенты и серверы общаются, обмениваясь отдельными сообщениями (в отличие от потока данных).
Сообщения, отправляемые клиентом, обычно веб-браузером, называются запросы и сообщения, отправленные сервером в качестве ответа, называются ответами .
HTTP, разработанный в начале 1990-х годов, представляет собой расширяемый протокол, который со временем развивался.
Это протокол прикладного уровня, который отправляется через TCP или через TCP-соединение с шифрованием TLS, хотя теоретически можно использовать любой надежный транспортный протокол.
Благодаря своей расширяемости он используется не только для извлечения гипертекстовых документов, но также изображений и видео или для отправки контента на серверы, например, с результатами HTML-форм.
HTTP также можно использовать для извлечения частей документов для обновления веб-страниц по запросу.
HTTP — это клиент-серверный протокол: запросы отправляются одним объектом — агентом пользователя (или прокси-сервером от его имени).
В большинстве случаев агентом пользователя является веб-браузер, но это может быть что угодно, например, робот, который просматривает Интернет для заполнения и поддержки индекса поисковой системы.
Каждый отдельный запрос отправляется на сервер, который обрабатывает его и предоставляет ответ, называемый ответом .
Между клиентом и сервером существует множество объектов, которые в совокупности называются прокси, которые выполняют различные операции и действуют, например, как шлюзы или кэши.
На самом деле между браузером и сервером, обрабатывающим запрос, больше компьютеров: маршрутизаторы, модемы и прочее.
Благодаря многоуровневой структуре Интернета они скрыты в сетевом и транспортном уровнях.
HTTP находится сверху, на прикладном уровне.
Хотя базовые уровни важны для диагностики сетевых проблем, они в основном не имеют отношения к описанию HTTP.
Клиент: пользовательский агент
Пользовательский агент — это любой инструмент, который действует от имени пользователя.
Эту роль в основном выполняет веб-браузер, но ее также могут выполнять программы, используемые инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда объект, инициирующий запрос.
Он никогда не является сервером (хотя с годами были добавлены некоторые механизмы для имитации сообщений, инициированных сервером).
Чтобы отобразить веб-страницу, браузер отправляет исходный запрос на получение HTML-документа, представляющего страницу.
Затем он анализирует этот файл, делая дополнительные запросы, соответствующие сценариям выполнения, информации о макете (CSS) для отображения и подресурсам, содержащимся на странице (обычно изображения и видео).
Затем веб-браузер объединяет эти ресурсы, чтобы представить полный документ, веб-страницу.
Сценарии, выполняемые браузером, могут извлекать больше ресурсов на более поздних этапах, и браузер соответствующим образом обновляет веб-страницу.
Веб-страница представляет собой гипертекстовый документ.
Это означает, что некоторые части отображаемого контента представляют собой ссылки, которые можно активировать (обычно щелчком мыши) для получения новой веб-страницы, что позволяет пользователю направлять свой пользовательский агент и перемещаться по сети.
Браузер переводит эти указания в HTTP-запросы и дополнительно интерпретирует HTTP-ответы, чтобы предоставить пользователю четкий ответ.
Веб-сервер
На противоположной стороне канала связи находится сервер, который подает документ по запросу клиента.
Сервер виртуально выглядит как одна машина; но на самом деле это может быть набор серверов, разделяющих нагрузку (балансировка нагрузки), или сложная часть программного обеспечения, опрашивающая другие компьютеры (например, кеш, сервер БД или серверы электронной коммерции), полностью или частично генерирующая документ по требованию.
Сервер не обязательно представляет собой одну машину, но на одной машине может быть размещено несколько экземпляров серверного программного обеспечения.
С HTTP/1.1 и Хост , они могут даже иметь один и тот же IP-адрес.
Прокси
Между веб-браузером и сервером многочисленные компьютеры и машины передают HTTP-сообщения.
Из-за многоуровневой структуры веб-стека большинство из них работают на транспортном, сетевом или физическом уровнях, становясь прозрачными на уровне HTTP и потенциально оказывая значительное влияние на производительность.
Те, которые работают на уровне приложений, обычно называются прокси .
Они могут быть прозрачными, пересылая запросы, которые они получают, не изменяя их каким-либо образом, или непрозрачными, и в этом случае они каким-то образом изменят запрос, прежде чем передать его на сервер.
Прокси могут выполнять множество функций:
- кэширование (кэш может быть общедоступным или частным, например, кеш браузера)
- фильтрация (например, антивирусное сканирование или родительский контроль)
- балансировка нагрузки (чтобы несколько серверов могли обслуживать разные запросы)
- аутентификация (для управления доступом к различным ресурсам)
- ведение журнала (позволяющее хранить историческую информацию)
Простой HTTP
HTTP, как правило, разработан, чтобы быть простым и понятным для человека, даже с добавленной сложностью, представленной в HTTP/2 за счет инкапсуляции сообщений HTTP в фреймы.
Сообщения HTTP могут быть прочитаны и поняты людьми, что упрощает тестирование для разработчиков и снижает сложность для новичков.
HTTP является расширяемым
Представленные в HTTP/1.0 заголовки HTTP упрощают расширение этого протокола и экспериментирование с ним.
Новая функциональность может быть введена даже простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP без сохранения состояния, но не без сеанса
HTTP не имеет состояния: нет связи между двумя запросами, последовательно выполняемыми по одному и тому же соединению.
Это немедленно создает проблемы для пользователей, пытающихся последовательно взаимодействовать с определенными страницами, например, используя корзину для покупок в электронной коммерции.
Но хотя ядро самого HTTP не имеет состояния, файлы cookie HTTP позволяют использовать сеансы с отслеживанием состояния.
С помощью расширяемости заголовков в рабочий процесс добавляются файлы cookie HTTP, что позволяет создавать сеансы для каждого HTTP-запроса для совместного использования одного и того же контекста или одного и того же состояния.
HTTP и соединения
Соединение контролируется на транспортном уровне и, следовательно, принципиально выходит за рамки HTTP.
HTTP не требует, чтобы базовый транспортный протокол был основан на соединении; требуется только, чтобы он был надежным или не терял сообщения (как минимум, в таких случаях выдавая ошибку).
Среди двух наиболее распространенных транспортных протоколов в Интернете TCP является надежным, а UDP — нет.
Таким образом, HTTP опирается на стандарт TCP, основанный на соединении.
Прежде чем клиент и сервер смогут обменяться парой HTTP-запрос/ответ, они должны установить TCP-соединение, процесс, для которого требуется несколько круговых обходов.
По умолчанию HTTP/1.0 открывает отдельное TCP-соединение для каждой пары HTTP-запрос/ответ.
Это менее эффективно, чем совместное использование одного TCP-соединения, когда несколько запросов отправляются друг за другом.
Чтобы смягчить этот недостаток, в HTTP/1.1 была введена конвейерная обработка (которая оказалась трудной для реализации) и постоянные соединения : базовое TCP-соединение можно частично контролировать с помощью заголовка Connection .
HTTP/2 пошел еще дальше, мультиплексируя сообщения по одному соединению, помогая сохранять соединение теплым и более эффективным.
В настоящее время проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP.
Например, Google экспериментирует с QUIC, который основан на UDP, чтобы обеспечить более надежный и эффективный транспортный протокол.
Эта расширяемая природа HTTP со временем позволила расширить возможности управления и функциональности Интернета.
Методы кэширования и аутентификации были функциями, которые обрабатывались в начале истории HTTP.
Напротив, возможность ослабить ограничение источника была добавлена только в 2010-х годах.
Вот список общих функций, которыми можно управлять с помощью HTTP:
- Кэширование :
Кэшированием документов можно управлять с помощью HTTP.
Сервер может указать прокси и клиентам, что кэшировать и как долго.
Клиент может указать прокси-серверам промежуточного кэша игнорировать сохраненный документ. - Ослабление ограничения источника :
Чтобы предотвратить отслеживание и другие вторжения в частную жизнь, веб-браузеры обеспечивают строгое разделение между веб-сайтами.
Только страницы из того же источника могут получить доступ ко всей информации веб-страницы.
Хотя такое ограничение является бременем для сервера, заголовки HTTP могут ослабить это строгое разделение на стороне сервера, позволяя документу стать лоскутным одеялом информации, полученной из разных доменов; для этого могут быть даже причины, связанные с безопасностью. - Аутентификация :
Некоторые страницы могут быть защищены, чтобы доступ к ним могли получить только определенные пользователи.
Базовая аутентификация может быть обеспечена HTTP, либо с использованиемWWW-Authenticateи аналогичных заголовков, либо путем установки определенного сеанса с использованием файлов cookie HTTP. - Прокси и туннелирование :
Серверы или клиенты часто располагаются в интрасетях и скрывают свой истинный IP-адрес от других компьютеров.
Затем HTTP-запросы проходят через прокси-серверы, чтобы преодолеть этот сетевой барьер.
Не все прокси являются HTTP-прокси.
Протокол SOCKS, например, работает на более низком уровне.
Другие протоколы, такие как ftp, могут обрабатываться этими прокси-серверами. - сеансов :
Использование файлов cookie HTTP позволяет связать запросы с состоянием сервера.
Это создает сеансы, несмотря на то, что базовый HTTP является протоколом без состояния.
Это полезно не только для корзин покупок электронной коммерции, но и для любого сайта, позволяющего пользователю настраивать вывод.


Когда клиент хочет связаться с сервером, конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Откройте TCP-соединение: TCP-соединение используется для отправки запроса или нескольких и получения ответа.
Клиент может открыть новое соединение, повторно использовать существующее соединение или открыть несколько TCP-соединений с серверами. - Отправить HTTP-сообщение: HTTP-сообщения (до HTTP/2) удобочитаемы.
В HTTP/2 эти простые сообщения инкапсулируются во фреймы, что делает невозможным их прямое чтение, но принцип остается прежним.
Например:ПОЛУЧИТЬ/HTTP/1.1 Хост: developer.mozilla.org Accept-Language: fr
- Прочитайте ответ, отправленный сервером, например:
HTTP/1.1 200 ОК Дата: 09 октября 2010 г., 14:28:02 по Гринвичу Сервер: Апач Последнее изменение: Вт, 01 декабря 2009 г.20:18:22 по Гринвичу ETag: "51142bc1-7449-479b075b2891b" Допустимые диапазоны: байты Длина контента: 29769 Тип содержимого: текст/html … (здесь идут 29769 байт запрошенной веб-страницы)
- Закройте или повторно используйте соединение для дальнейших запросов.

Если активирована конвейерная обработка HTTP, можно отправить несколько запросов, не дожидаясь полного получения первого ответа.
Конвейерную обработку HTTP оказалось трудно реализовать в существующих сетях, где старые части программного обеспечения сосуществуют с современными версиями.
Конвейерная обработка HTTP была заменена в HTTP/2 более надежным мультиплексированием запросов внутри кадра.
Сообщения HTTP, определенные в HTTP/1.1 и более ранних версиях, удобочитаемы.
В HTTP/2 эти сообщения встроены в двоичную структуру, кадр , что позволяет выполнять такие оптимизации, как сжатие заголовков и мультиплексирование.
Даже если в этой версии HTTP отправляется только часть исходного HTTP-сообщения, семантика каждого сообщения остается неизменной, и клиент воссоздает (виртуально) исходный запрос HTTP/1.1.
Поэтому полезно понимать сообщения HTTP/2 в формате HTTP/1.1.
Существует два типа HTTP-сообщений: запросы и ответы, каждый из которых имеет собственный формат.
Запросы
Пример HTTP-запроса:
Запросы состоят из следующих элементов:
- HTTP-метод, обычно глагол типа
GET,POSTили существительное вродеOPTIONSилиHEAD, который определяет операцию, которую хочет выполнить клиент.
Как правило, клиент хочет получить ресурс (используяGET) или отправить значение HTML-формы (используяPOST), хотя в других случаях может потребоваться больше операций. - Путь ресурса для выборки; URL-адрес ресурса, очищенный от очевидных из контекста элементов, например без протокола (
http://), домена (здесьdeveloper.mozilla.org) или TCP-порта (здесь80). - Версия протокола HTTP.
- Необязательные заголовки, передающие дополнительную информацию для серверов.
- Тело для некоторых методов, таких как
POST, аналогично ответам, которые содержат отправленный ресурс.
Ответы
Пример ответа:
Ответы состоят из следующих элементов:
- Версия протокола HTTP, которому они следуют.
- Код состояния, указывающий, был ли запрос успешным и почему.
- Сообщение о состоянии, неавторизованное краткое описание кода состояния.
- HTTP-заголовки, такие как для запросов.
- Необязательно тело, содержащее выбранный ресурс.

Наиболее часто используемым API на основе HTTP является API XMLHttpRequest , который можно использовать для обмена данными между агентом пользователя и сервером.
Современный Fetch API предоставляет те же функции с более мощным и гибким набором функций.
Другой API, события, отправленные сервером, представляет собой одностороннюю службу, которая позволяет серверу отправлять события клиенту, используя HTTP в качестве транспортного механизма.
Использование EventSource , клиент открывает соединение и устанавливает обработчики событий.
Браузер клиента автоматически преобразует сообщения, поступающие в потоке HTTP, в соответствующие объекты Event . Затем он доставляет их обработчикам событий, которые были зарегистрированы для событий типа , если они известны, или обработчику событий onmessage , если не был установлен обработчик событий конкретного типа.
HTTP — это расширяемый протокол, который прост в использовании.
Структура клиент-сервер в сочетании с возможностью добавления заголовков позволяет HTTP развиваться вместе с расширенными возможностями Интернета.
Хотя HTTP/2 добавляет некоторую сложность за счет встраивания сообщений HTTP во фреймы для повышения производительности, базовая структура сообщений осталась неизменной со времен HTTP/1.0.
Поток сеанса остается простым, что позволяет исследовать и отлаживать его с помощью простого монитора HTTP-сообщений.
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Посмотреть исходный код на GitHub.
Хотите принять участие?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Эволюция HTTP — HTTP
HTTP (протокол передачи гипертекста) — это основной протокол Всемирной паутины. Разработанный Тимом Бернерсом-Ли и его командой в период с 1989 по 1991 год, HTTP претерпел множество изменений, которые помогли сохранить его простоту и придать гибкость. Продолжайте читать, чтобы узнать, как HTTP превратился из протокола, предназначенного для обмена файлами в полудоверенной лабораторной среде, в современный интернет-лабиринт, который передает изображения и видео в высоком разрешении и 3D.
В 1989 году, работая в CERN, Тим Бернерс-Ли написал предложение о создании гипертекстовой системы через Интернет. Первоначально называвшийся Mesh , позже он был переименован в World Wide Web во время его реализации в 1990 году. Построенный на основе существующих протоколов TCP и IP, он состоял из 4 строительных блоков:
- Текстовый формат для представления гипертекстовых документов, язык гипертекстовой разметки (HTML).
- Простой протокол для обмена этими документами, Протокол передачи гипертекста (HTTP).
- Клиент для отображения (и редактирования) этих документов, первый веб-браузер под названием WorldWideWeb .
- Сервер для предоставления доступа к документу, ранняя версия httpd .
Эти четыре строительных блока были завершены к концу 1990 года, и к началу 1991 года первые серверы работали за пределами ЦЕРН. 6 августа 1991 года Тим Бернерс-Ли разместил в общедоступной группе новостей alt.hypertext . Теперь это считается официальным запуском всемирной паутины как публичного проекта.
Протокол HTTP, использовавшийся на ранних этапах, был очень простым. Позже он был назван HTTP/0.9 и иногда называется однострочным протоколом.
Первоначальная версия HTTP не имела номера версии; позже он был назван 0.9, чтобы отличить его от более поздних версий. HTTP/0.9 был предельно прост: запросы состояли из одной строки и начинались с единственно возможного метода GET , за которым следовал путь к ресурсу. Полный URL-адрес не был включен, так как протокол, сервер и порт не были необходимы после подключения к серверу.
Полный URL-адрес не был включен, так как протокол, сервер и порт не были необходимы после подключения к серверу.
ПОЛУЧИТЬ /mypage.html
Ответ тоже был чрезвычайно прост: он состоял только из самого файла.
Очень простая HTML-страница
В отличие от последующих версий заголовков HTTP не было. Это означало, что можно было передавать только файлы HTML. Не было ни статусов, ни кодов ошибок. Если возникала проблема, создавался специальный HTML-файл с описанием проблемы для человеческого восприятия.
HTTP/0.9 был очень ограничен, но браузеры и серверы быстро сделали его более универсальным:
- Информация о версии была отправлена в каждом запросе (
HTTP/1.0был добавлен к строкеGET). - В начале ответа также была отправлена строка кода состояния. Это позволяло самому браузеру распознавать успех или неудачу запроса и соответствующим образом адаптировать свое поведение. Например, обновление или использование своего локального кеша определенным образом.
- Концепция заголовков HTTP была введена как для запросов, так и для ответов. Можно было передавать метаданные, и протокол стал чрезвычайно гибким и расширяемым.
- Благодаря заголовку
Content-Typeможно было передавать документы, отличные от простых HTML-файлов.

На тот момент типичный запрос и ответ выглядели так:
GET /mypage.html HTTP/1.0 Агент пользователя: NCSA_Mosaic/2.0 (Windows 3.1) 200 ОК Дата: вторник, 15 ноября 1994 г., 08:12:31 по Гринвичу. Сервер: CERN/3.0 libwww/2.17 Тип содержимого: текст/html Страница с изображением

Затем последовало второе подключение и запрос на получение изображения (с соответствующим ответом):
ПОЛУЧИТЬ /myimage.gif HTTP/1.0 Агент пользователя: NCSA_Mosaic/2.0 (Windows 3.1) 200 ОК Дата: вторник, 15 ноября 1994 г., 08:12:32 по Гринвичу. Сервер: CERN/3.0 libwww/2.17 Тип содержимого: текст/gif (содержание изображения)
В период с 1991 по 1995 год они были введены на пробу. Сервер и браузер добавят функцию и посмотрят, будет ли она востребована. Проблемы совместимости были обычным явлением. В целях решения этих проблем 19 ноября был опубликован информационный документ, описывающий общие практики.96. Он был известен как RFC 1945 и определял HTTP/1.0.
Сервер и браузер добавят функцию и посмотрят, будет ли она востребована. Проблемы совместимости были обычным явлением. В целях решения этих проблем 19 ноября был опубликован информационный документ, описывающий общие практики.96. Он был известен как RFC 1945 и определял HTTP/1.0.
Тем временем велась надлежащая стандартизация. Это происходило параллельно с разнообразными реализациями HTTP/1.0. Первая стандартизированная версия HTTP, HTTP/1.1, была опубликована в начале 1997 года, всего через несколько месяцев после HTTP/1.0.
HTTP/1.1 прояснил неясности и представил многочисленные улучшения:
- Соединение можно было использовать повторно, что экономило время. Его больше не нужно было открывать несколько раз, чтобы отобразить ресурсы, встроенные в один исходный документ.
- Добавлен конвейер. Это позволяло отправить второй запрос до того, как ответ на первый был полностью передан. Это уменьшило задержку связи.
- Также поддерживались фрагментированные ответы.
- Введены дополнительные механизмы управления кешем.
- Добавлено согласование содержимого, включая язык, кодировку и тип. Теперь клиент и сервер могут договориться о том, каким содержимым обмениваться.
- Благодаря хосту

Типичный поток запросов через одно соединение выглядел так:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1 Хост: developer.mozilla.org Агент пользователя: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 Принять: текст/html, приложение/xhtml+xml, приложение/xml; q = 0,9, */*; q = 0,8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Реферер: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 ОК Соединение: Keep-Alive Кодировка содержимого: gzip Тип содержимого: текст/html; кодировка = utf-8 Дата: среда, 20 июля 2016 г.
 , 10:55:30 по Гринвичу
Метка: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: таймаут=5, макс=1000
Последнее изменение: Вт, 19 июля 2016 г., 00:59:33 GMT
Сервер: Апач
Передача-кодирование: по частям
Варьировать: Cookie, Accept-Encoding
(содержание)
ПОЛУЧИТЬ /static/img/header-background.png HTTP/1.1
Хост: developer.mozilla.org
Агент пользователя: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Принимать: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Реферер: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 ОК
Возраст: 9578461
Cache-Control: public, max-age=315360000
Соединение: Keep-alive
Длина контента: 3077
Тип содержимого: изображение/png
Дата: Чт, 31 марта 2016 г., 13:34:46 по Гринвичу
Последнее изменение: ср, 21 октября 2015 г., 18:27:50 GMT
Сервер: Апач
(содержание изображения 3077 байт)
, 10:55:30 по Гринвичу
Метка: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: таймаут=5, макс=1000
Последнее изменение: Вт, 19 июля 2016 г., 00:59:33 GMT
Сервер: Апач
Передача-кодирование: по частям
Варьировать: Cookie, Accept-Encoding
(содержание)
ПОЛУЧИТЬ /static/img/header-background.png HTTP/1.1
Хост: developer.mozilla.org
Агент пользователя: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Принимать: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Реферер: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 ОК
Возраст: 9578461
Cache-Control: public, max-age=315360000
Соединение: Keep-alive
Длина контента: 3077
Тип содержимого: изображение/png
Дата: Чт, 31 марта 2016 г., 13:34:46 по Гринвичу
Последнее изменение: ср, 21 октября 2015 г., 18:27:50 GMT
Сервер: Апач
(содержание изображения 3077 байт)
HTTP/1.1 был впервые опубликован как RFC 2068 в январе 1997 года.
Расширяемость HTTP упростила создание новых заголовков и методов. Несмотря на то, что протокол HTTP/1.1 был улучшен в течение двух редакций, RFC 2616, опубликованных в июне 1999 г., и RFC 7230-RFC 7235, опубликованных в июне 2014 г. до выпуска HTTP/2, он оставался чрезвычайно стабильным в течение более 15 лет.
Несмотря на то, что протокол HTTP/1.1 был улучшен в течение двух редакций, RFC 2616, опубликованных в июне 1999 г., и RFC 7230-RFC 7235, опубликованных в июне 2014 г. до выпуска HTTP/2, он оставался чрезвычайно стабильным в течение более 15 лет.
Использование HTTP для защищенной передачи
Самое крупное изменение в HTTP было сделано в конце 1994 года. Вместо отправки HTTP через базовый стек TCP/IP компания Netscape Communications, занимающаяся компьютерными услугами, создала дополнительный уровень зашифрованной передачи поверх это: SSL. SSL 1.0 никогда не публиковался, но SSL 2.0 и его преемник SSL 3.0 позволяли создавать веб-сайты электронной коммерции. Для этого они зашифровали и гарантировали подлинность сообщений, которыми обмениваются сервер и клиент. В конечном итоге SSL был стандартизирован и стал TLS.
В тот же период времени стало ясно, что необходим зашифрованный транспортный уровень. Сеть больше не была в основном академической сетью, а вместо этого превратилась в джунгли, где рекламодатели, случайные люди и преступники соревновались за как можно больше личных данных. По мере того, как приложения, созданные на основе HTTP, становились все более мощными и требовали доступа к личной информации, такой как адресные книги, электронная почта и местоположение пользователя, TLS стал необходим вне сценария использования электронной коммерции.
По мере того, как приложения, созданные на основе HTTP, становились все более мощными и требовали доступа к личной информации, такой как адресные книги, электронная почта и местоположение пользователя, TLS стал необходим вне сценария использования электронной коммерции.
Использование HTTP для сложных приложений
Тим Бернерс-Ли изначально не рассматривал HTTP как средство только для чтения. Он хотел создать сеть, в которой люди могли бы удаленно добавлять и перемещать документы — своего рода распределенную файловую систему. Примерно в 1996 году HTTP был расширен, чтобы разрешить авторизацию, и был создан стандарт под названием WebDAV. Он расширился за счет включения специальных приложений, таких как CardDAV для обработки записей адресной книги и CalDAV для работы с календарями. Но у всех этих расширений *DAV был недостаток: их можно было использовать только тогда, когда они были реализованы серверами.
В 2000 году был разработан новый шаблон для использования HTTP: передача репрезентативного состояния (или REST). API не был основан на новых методах HTTP, а вместо этого полагался на доступ к определенным URI с помощью базовых методов HTTP/1.1. Это позволило любому веб-приложению позволить API извлекать и изменять свои данные без необходимости обновлять браузеры или серверы. Вся необходимая информация была встроена в файлы, которые веб-сайты обслуживали по стандарту HTTP/1.1. Недостаток модели REST заключался в том, что каждый веб-сайт определял свой собственный нестандартный RESTful API и полностью контролировал его. Это отличалось от расширений *DAV, где клиенты и серверы были совместимы. RESTful API стали очень распространены в 2010-х годах.
API не был основан на новых методах HTTP, а вместо этого полагался на доступ к определенным URI с помощью базовых методов HTTP/1.1. Это позволило любому веб-приложению позволить API извлекать и изменять свои данные без необходимости обновлять браузеры или серверы. Вся необходимая информация была встроена в файлы, которые веб-сайты обслуживали по стандарту HTTP/1.1. Недостаток модели REST заключался в том, что каждый веб-сайт определял свой собственный нестандартный RESTful API и полностью контролировал его. Это отличалось от расширений *DAV, где клиенты и серверы были совместимы. RESTful API стали очень распространены в 2010-х годах.
С 2005 года для веб-страниц стало доступно больше API. Некоторые из этих API-интерфейсов создают расширения для протокола HTTP для определенных целей:
- События, отправленные сервером, когда сервер может отправлять случайные сообщения в браузер.
- WebSocket — новый протокол, который можно настроить путем обновления существующего HTTP-соединения.

Ослабление модели безопасности сети
HTTP не зависит от модели безопасности сети, известной как политика того же происхождения. Фактически, текущая модель веб-безопасности была разработана после создания HTTP! С годами оказалось полезным снять некоторые ограничения этой политики при определенных ограничениях. Сервер передавал клиенту, сколько и когда снимать такие ограничения, используя новый набор заголовков HTTP. Они были определены в таких спецификациях, как совместное использование ресурсов между источниками (CORS) и политика безопасности контента (CSP).
В дополнение к этим большим расширениям было добавлено много других заголовков, иногда только экспериментально. Примечательными заголовками являются заголовок «Не отслеживать» ( DNT ) для управления конфиденциальностью, X-Frame-Options и Upgrade-Insecure-Requests , но существуют и многие другие.
С годами веб-страницы стали более сложными. Некоторые из них были даже самостоятельными приложениями. Было показано больше визуальных медиа, а также увеличился объем и размер сценариев, добавляющих интерактивность. Гораздо больше данных было передано через значительно большее количество HTTP-запросов, и это создало больше сложности и накладных расходов для соединений HTTP/1.1. Чтобы учесть это, в начале 2010-х Google внедрил экспериментальный протокол SPDY. Этот альтернативный способ обмена данными между клиентом и сервером вызвал интерес у разработчиков, работающих как с браузерами, так и с серверами. SPDY определил увеличение скорости отклика и решил проблему дублирования передачи данных, послужив основой для протокола HTTP/2.
Было показано больше визуальных медиа, а также увеличился объем и размер сценариев, добавляющих интерактивность. Гораздо больше данных было передано через значительно большее количество HTTP-запросов, и это создало больше сложности и накладных расходов для соединений HTTP/1.1. Чтобы учесть это, в начале 2010-х Google внедрил экспериментальный протокол SPDY. Этот альтернативный способ обмена данными между клиентом и сервером вызвал интерес у разработчиков, работающих как с браузерами, так и с серверами. SPDY определил увеличение скорости отклика и решил проблему дублирования передачи данных, послужив основой для протокола HTTP/2.
Протокол HTTP/2 несколько отличается от HTTP/1.1:
- Это двоичный протокол, а не текстовый. Его нельзя прочитать и создать вручную. Несмотря на это препятствие, он позволяет реализовать улучшенные методы оптимизации.
- Это мультиплексный протокол. Параллельные запросы могут выполняться по одному и тому же соединению, что устраняет ограничения протокола HTTP/1. x.
- Сжимает заголовки. Поскольку они часто похожи в наборе запросов, это устраняет дублирование и накладные расходы на передаваемые данные.
- Позволяет серверу заполнять данные в клиентском кеше с помощью механизма, называемого серверной проталкиванием.
 x.
x.Официально стандартизированный в мае 2015 г., использование HTTP/2 достигло пика в январе 2022 г. на 46,9% всех веб-сайтов (см. эту статистику). Веб-сайты с высокой посещаемостью продемонстрировали наиболее быстрое внедрение в попытке сэкономить накладные расходы на передачу данных и последующие бюджеты.
Вероятно, такое быстрое внедрение было связано с тем, что HTTP/2 не требовал внесения изменений в веб-сайты и приложения. Для его использования требовался только современный сервер, который связывался с последним браузером. Для запуска внедрения требовался лишь ограниченный набор групп, а по мере обновления устаревших версий браузера и сервера использование естественным образом увеличивалось без значительной работы для веб-разработчиков.
Расширяемость HTTP все еще используется для добавления новых функций. В частности, можно привести новые расширения протокола HTTP, появившиеся в 2016 году:
- Поддержка
Alt-Svcпозволила разъединить идентификацию и местоположение данного ресурса. Это означало более умный механизм кэширования CDN. - Введение клиентских подсказок позволило браузеру или клиенту заблаговременно передавать серверу информацию о своих требованиях и аппаратных ограничениях.
- Введение связанных с безопасностью префиксов в заголовок
Cookieпомогло гарантировать невозможность изменения безопасных файлов cookie.
Следующая основная версия HTTP, HTTP/3, имеет ту же семантику, что и более ранние версии HTTP, но использует QUIC вместо TCP для части транспортного уровня. К октябрю 2022 года 26% всех веб-сайтов использовали HTTP/3.
QUIC обеспечивает значительно меньшую задержку для HTTP-соединений. Как и HTTP/2, это мультиплексный протокол, но HTTP/2 работает по одному TCP-соединению, поэтому обнаружение потери пакетов и повторная передача, выполняемые на уровне TCP, могут блокировать все потоки.