Содержание
Поисковый робот — программа сбора информации в базу поисковика
- Подробности
- Категория: SEO-словарь
Роботы поисковых систем – это специальные программы браузерного типа, считывающие информацию с веб-страниц. В Буржунете и в Рунете могут встречаться разные названия этих программ: поисковый бот, паук, веб-краулер, web robots, automatic indexer, web scutter и т.д. Поисковые боты являются важнейшим элементом любой поисковой системы. В их задачу входит постоянное сканирование Сети, сбор обновлений на ресурсах, уже имеющихся в базе, индексация новых сайтов, найденных в интернете, проверка корректности ссылок, поиск «мертвых» сайтов, чтение комментариев и многое другое.
Ведущие поисковые системы обладают большим числом самых разных ботов, у каждого из которых имеется свое предназначение, определяемое автоматическим скриптом. Так что, рано или поздно любой сайт попадает в паучьи сети, если, конечно, ресурс или отдельные его страницы не закрыты от индексации при помощи команд, прописанных в корневом файле robots. txt.
txt.
Не все боты работают одинаково быстро. Так, если поисковые роботы Google отличаются отменной шустростью, то про пауков Яндекса так не скажешь. Может пройти довольно много времени, прежде чем поисковый робот Яндекс обнаружит и проиндексирует новый ресурс. Чтобы этого не произошло, нужно добавить сайт в специальные списки-каталоги, либо аддурилку. Это действие сообщит боту о появлении новичка и поспособствует ускорению процессов индексации и продвижения веб-сайта в поисковой системе.
Комментарии
- ВКонтакте
Download SocComments v1.3
- < Назад
- Вперёд >
Услуги
Контакты
+7(995)205-35-04
Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
Новости
Роскомнадзор против Telegram: глава вторая
Твиттер и Фэйсбук в очередной раз провинились перед Роскомнадзором
«Закон Яровой» ужесточил меры в отношении интернет-трафика пользователей операторов связи
Яндекс заменяет ТИЦ на ИКС — новый показатель качества сайта
Роскомнадзором разблокировано более 7 миллионов IP-адресов
Статьи
Чем интересуются россияне во время Масленицы
Исследование Яндекса по поисковым запросам о простудных заболеваниях
Изменения в контекстной рекламе: нововведения в 2015 и прогноз на 2016
Сколько зарабатывают звезды YouTube? Рейтинг самых высокооплачиваемых блоггеров
10 крупнейших онлайн-магазинов Рунета: рейтинг Forbes
SEM-online. ruon
ruon
Читать @SEM_online
Web scraping с помощью Scrapy и Python 3
30 октября, 2016 12:23 пп
20 443 views
| 1 комментарий
Python | Amber
| 1 Comment
Web scraping (также web spidering, кроулинг, «веб-паук») – это техника сбора данных о страницах для занесения этих данных в базу поисковой системы.
Поисковые роботы позволяют извлечь информацию о ряде продуктов, получить большой объём текстовых или количественных данных, извлечь данные с сайта без официального API и многое другое.
Данное руководство ознакомит вас с основами работы поисковых роботов.
Примечание: В руководстве используется BrickSet, поддерживаемый сообществом сайт о наборах LEGO. Выполнив руководство, вы получите полностью готового к работе «веб-паука», который проанализирует ряд страниц Brickset и извлечёт данные о наборах LEGO.
Полученный в результате поисковый робот можно легко настроить для анализа другого сайта.
Требования
Для работы вам нужно настроить локальную среду разработки для Python 3. Все необходимые инструкции можно найти по ссылкам:
- Ubuntu 16.04
- CentOS 7
- Mac OS X
- Windows 10
1: Базовый поиск
Scraping состоит из двух этапов:
- Систематический поиск и загрузка веб-страниц.
- Извлечение данных с веб-страниц.
Создать поискового робота с нуля можно с помощью различных модулей и библиотек, которые предоставляет язык программирования, однако в дальнейшем – по мере роста программы – это может вызвать ряд проблем. К примеру, вам понадобится переформатировать извлечённые данные в CSV, XML или JSON. Также вы можете столкнуться с сайтами, для анализа которых необходимы специальные настройки и модели доступа.
Поэтому лучше сразу разработать робота на основе библиотеки, которая устраняет все эти потенциальные проблемы. Для этого в данном руководстве используются Python и Scrapy.
Для этого в данном руководстве используются Python и Scrapy.
Scrapy – одна из наиболее популярных и производительных библиотек Python для получения данных с веб-страниц, которая включает в себя большинство общих функциональных возможностей. Это значит, что вам не придётся самостоятельно прописывать многие функции. Scrapy позволяет быстро и без труда создать «веб-паука».
Пакет Scrapy (как и большинство других пакетов Python) можно найти в PyPI (Python Package Index, также известен как pip) – это поддерживаемый сообществом репозиторий для всех вышедших пакетов Python.
Если вы следовали одному из предложенных руководств (раздел Требования), пакетный менеджер pip уже установлен на вашу машину. Чтобы установить Scrapy, введите:
pip install scrapy
Примечание: Если во время установки у вас возникли проблемы или вы хотите установить Scrapy без помощи pip, обратитесь к официальной документации.
После установки создайте папку для проекта.
mkdir brickset-scraper
Откройте новый каталог:
cd brickset-scraper
Создайте файл для поискового робота по имени scraper.py. В этом файле будет храниться весь код «паука». Введите в терминал:
touch scraper.py
Также вы можете создать файл с помощью текстового редактора или графического файлового менеджера.
Для начала нужно создать базовый код робота, который будет основан на библиотеке Scrapy. Для этого создайте класс Python под названием scrapy.Spider, это базовый класс для поисковых роботов, предоставленный Scrapy. Этот класс имеет два обязательных атрибута:
- name – название «паука».
- start_urls – список ссылок на страницы, которые нужно проанализировать.
Откройте scrapy.py и добавьте следующий код:
import scrapy
class BrickSetSpider(scrapy.Spider):
name = "brickset_spider"
start_urls = ['http://brickset.com/sets/year-2016']
Рассмотрим этот код подробнее:
- Первая строка импортирует scrapy, что позволяет использовать доступные классы библиотеки.

- Строка class BrickSetSpider(scrapy.Spider) добавляет класс Spider из библиотеки Scrapy и создаёт подкласс BrickSetSpider. Подкласс – это, по сути, просто более узкий, специализированный вариант родительского класса. Класс Spider предоставляет методы для отслеживания URL-ов и извлечения данных с веб-страниц, но он не знает, где искать страницы и какие именно данные нужно извлечь. Чтобы передать классу недостающие данные, мы создали подкласс.
- Имя поискового робота: brickset_spider.
- Ссылка в конце кода – это ссылка на страницу, которую нужно просканировать. Если вы откроете её в браузере, вы увидите первую страницу результатов поиска наборов LEGO.

Теперь нужно проверить работу робота. Обычно файлы Python запускаются с помощью команды python path/to/file.py. Однако Scrapy предоставляет собственный интерфейс командной строки, чтобы оптимизировать процесс запуска «паука». Запустить его можно с помощью следующей команды:
scrapy runspider scraper. py
py
Команда вернёт:
2016-09-22 23:37:45 [scrapy] INFO: Scrapy 1.1.2 started (bot: scrapybot)
2016-09-22 23:37:45 [scrapy] INFO: Overridden settings: {}
2016-09-22 23:37:45 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2016-09-22 23:37:45 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
...
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-09-22 23:37:45 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
...
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-09-22 23:37:45 [scrapy] INFO: Enabled item pipelines:
[]
2016-09-22 23:37:45 [scrapy] INFO: Spider opened
2016-09-22 23:37:45 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-09-22 23:37:45 [scrapy] DEBUG: Telnet console listening on 127. 0.0.1:6023
0.0.1:6023
2016-09-22 23:37:47 [scrapy] DEBUG: Crawled (200) <GET http://brickset.com/sets/year-2016> (referer: None)
2016-09-22 23:37:47 [scrapy] INFO: Closing spider (finished)
2016-09-22 23:37:47 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 224,
'downloader/request_count': 1,
...
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 9, 23, 6, 37, 45, 995167)}
2016-09-22 23:37:47 [scrapy] INFO: Spider closed (finished)
Рассмотрим подробнее каждый фрагмент вывода.
- Сначала робот инициализирует и загружает дополнительные компоненты и расширения, необходимые ему для обработки считываемых данных.
- Затем он использует URL, указанный в start_urls, и загружает HTML (как это делает браузер).
- После этого робот передаёт HTML методу parse, который по умолчанию не делает ничего. Поскольку ранее мы не написали ни одно метода parse, «паук» больше ничего не делает.
Теперь попробуйте загрузить данные со страницы.
2: Извлечение данных с веб-страницы
Итак, теперь у вас есть базовая программа, которая загружает страницы, но не умеет анализировать их и извлекать данные.
Рассмотрите внимательно тестовую страницу. Она имеет такую структуру:
- Заголовок, который присутствует на каждой странице.
- Поисковая строка и навигационная цепочка.
- Ниже представлен список наборов.
При создании поискового робота рекомендуется открыть исходный код HTML и ознакомиться с его структурой. В данном случае он выглядит так (некоторые элементы опущены для удобства):
brickset.com/sets/year-2016
<body>
<section>
<article>
<a href=
"http://images.brickset.com/sets/images/10251-1.jpg?201510121127"
onclick="return hs.expand(this)"><img src=
"http://images.brickset.com/sets/small/10251-1.jpg?201510121127"
title="10251-1: Brick Bank"></a>
<div>
<h2><a href='/sets/10251-1/Brick-Bank'>Brick Bank</a></h2>
<div>
<a href='/sets/10251-1/Brick-Bank'>10251-1</a> <a href=
'/sets/theme-Advanced-Models'>Advanced Models</a> <a class=
'subtheme' href=
'/sets/theme-Advanced-Models/subtheme-Modular-Buildings'>Modular
Buildings</a> <a href=
'/sets/theme-Advanced-Models/year-2016'>2016</a>
</div>
<div>
©2016 LEGO Group
</div>
<div>
<a href="#" title=
"Previous (left arrow key)">« Previous</a> <a href="#"
onclick="return hs. next(this)" title=
next(this)" title=
"Next (right arrow key)">Next »</a>
</div>
</div>
...
</article>
<article>
...
</article>
</section>
</body>
Scraping этой страницы состоит из двух этапов:
- Извлечение всех наборов LEGO после анализа тех компонентов, которые содержат нужные данные.
- Загрузка искомых данных по тегам HTML.
Scrapy извлекает данные на основе заданных селекторов. Селекторы – это шаблоны, которые позволяют найти элементы страницы, содержащие необходимые данные. Scrapy поддерживает селекторы CSS и XPath.
Мы используем CSS-селекторы, поскольку это самый простой вариант. Обратите внимание: каждый набор, опубликованный на странице, имеет класс set. Используйте CSS-селектор .set, чтобы выбрать этот класс. Передайте этот селектор объекту response:
class BrickSetSpider(scrapy.Spider):
name = "brickset_spider"
start_urls = ['http://brickset. com/sets/year-2016']
com/sets/year-2016']
def parse(self, response):
SET_SELECTOR = '.set'
for brickset in response.css(SET_SELECTOR):
pass
Этот код извлечет все наборы, опубликованные на странице, а затем проанализирует и загрузит данные.
Также можно заметить, что название наборов хранится в тегах a внутри тега h2.
brickset.com/sets/year-2016
<h2><a href='/sets/10251-1/Brick-Bank'>Brick Bank</a></h2>
Объект brickset имеет собственный метод css, который можно передать в селектор, чтобы найти дочерние элементы. Чтобы найти имя набора и отобразить его, измените код следующим образом:
class BrickSetSpider(scrapy.Spider):
name = "brickset_spider"
start_urls = ['http://brickset.com/sets/year-2016']
def parse(self, response):
SET_SELECTOR = '.set'
for brickset in response.css(SET_SELECTOR):
NAME_SELECTOR = 'h2 a ::text'
yield {
'name': brickset.css(NAME_SELECTOR).extract_first(),
}
Примечание: Запятая после extract_first() – не опечатка. Вскоре мы расширим этот раздел, потому запятая там поставлена заранее.
Вскоре мы расширим этот раздел, потому запятая там поставлена заранее.
Обратите внимание:
- В селектор вместо имени вставлен::text. Это псевдоселектор CSS, который будет извлекать название набора из тега а.
- На возвращённый с помощью brickset.css(NAME_SELECTOR) объект вызывается extract_first(), потому что нам нужен только первый элемент, который соответствует селектору. Это возвращает строку, а не список элементов.
Сохраните файл и снова запустите робота:
scrapy runspider scraper.py
Теперь в выводе появятся названия наборов:
...
[scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'name': 'Brick Bank'}
[scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'name': 'Volkswagen Beetle'}
[scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'name': 'Big Ben'}
[scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'name': 'Winter Holiday Train'}
. ..
..
Расширьте код, добавив селекторы для изображений и компонентов набора:
brickset.com/sets/year-2016
<article>
<a href="http://images.brickset.com/sets/images/10251-1.jpg?201510121127">
<img src="http://images.brickset.com/sets/small/10251-1.jpg?201510121127" title="10251-1: Brick Bank"></a>
...
<div>
<h2><a href="/sets/10251-1/Brick-Bank"><span>10251:</span> Brick Bank</a> </h2>
...
<div>
<dl>
<dt>Pieces</dt>
<dd><a href="/inventories/10251-1">2380</a></dd>
<dt>Minifigs</dt>
<dd><a href="/minifigs/inset-10251-1">5</a></dd>
...
</dl>
</div>
...
</div>
</article>
Обратите внимание:
- Изображение набора хранится в атрибуте src тега img внутри тега а в начале набора. Эти значения можно извлечь с помощью других селекторов CSS.
- Получить набор компонентов набора немного сложнее. Тег dt содержит текст Pieces и тег dd, который содержит количество частей набора. Такой селектор сложно составить. Используйте язык запросов XPath, чтобы извлечь эти данные.
- Получить количество фигурок в наборе можно так же, как и количество компонентов. Тег dt содержит текст Minifigs, за которым следует тег dd, который содержит количество фигурок.

Откорректируйте код поискового робота:
class BrickSetSpider(scrapy.Spider):
name = 'brick_spider'
start_urls = ['http://brickset.com/sets/year-2016']
def parse(self, response):
SET_SELECTOR = '.set'
for brickset in response.css(SET_SELECTOR):
NAME_SELECTOR = 'h2 a ::text'
PIECES_SELECTOR = './/dl[dt/text() = "Pieces"]/dd/a/text()'
MINIFIGS_SELECTOR = './/dl[dt/text() = "Minifigs"]/dd[2]/a/text()'
IMAGE_SELECTOR = 'img ::attr(src)'
yield {
'name': brickset.css(NAME_SELECTOR).extract_first(),
'pieces': brickset. xpath(PIECES_SELECTOR).extract_first(),
xpath(PIECES_SELECTOR).extract_first(),
'minifigs': brickset.xpath(MINIFIGS_SELECTOR).extract_first(),
'image': brickset.css(IMAGE_SELECTOR).extract_first(),
}
Сохраните изменения и запустите робота:
scrapy runspider scraper.py
Программа соберёт такие данные:
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': '5', 'pieces': '2380', 'name': 'Brick Bank', 'image': 'http://images.brickset.com/sets/small/10251-1.jpg?201510121127'}
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': None, 'pieces': '1167', 'name': 'Volkswagen Beetle', 'image': 'http://images.brickset.com/sets/small/10252-1.jpg?201606140214'}
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': None, 'pieces': '4163', 'name': 'Big Ben', 'image': 'http://images.brickset.com/sets/small/10253-1. jpg?201605190256'}
jpg?201605190256'}
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': None, 'pieces': None, 'name': 'Winter Holiday Train', 'image': 'http://images.brickset.com/sets/small/10254-1.jpg?201608110306'}
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': None, 'pieces': None, 'name': 'XL Creative Brick Box', 'image': '/assets/images/misc/blankbox.gif'}
2016-09-22 23:52:37 [scrapy] DEBUG: Scraped from <200 http://brickset.com/sets/year-2016>
{'minifigs': None, 'pieces': '583', 'name': 'Creative Building Set', 'image': 'http://images.brickset.com/sets/small/10702-1.jpg?201511230710'}
Теперь можно превратить программу в «паука», который сможет переходить по ссылкам.
3: Анализ нескольких страниц
Теперь у вас есть поисковый робот, который умеет извлекать данные с веб-страниц. Вы можете усовершенствовать его, научив находить и открывать ссылки на другие страницы и анализировать их.
Вы, наверное, заметили, что каждая страница начинается и заканчивается символом >, который ссылается на следующую страницу результата.
brickset.com/sets/year-2016
<ul>
...
<li>
<a href="http://brickset.com/sets/year-2017/page-2">›</a>
</li>
<li>
<a href="http://brickset.com/sets/year-2016/page-32">»</a>
</li>
</ul>
Как видите, тег li класса next содержит тег а с ссылкой на следующую страницу. Теперь нужно добавить в программу код для перехода по ссылкам.
class BrickSetSpider(scrapy.Spider):
name = 'brick_spider'
start_urls = ['http://brickset.com/sets/year-2016']
def parse(self, response):
SET_SELECTOR = '.set'
for brickset in response.css(SET_SELECTOR):
NAME_SELECTOR = 'h2 a ::text'
PIECES_SELECTOR = './/dl[dt/text() = "Pieces"]/dd/a/text()'
MINIFIGS_SELECTOR = './/dl[dt/text() = "Minifigs"]/dd[2]/a/text()'
IMAGE_SELECTOR = 'img ::attr(src)'
yield {
'name': brickset. css(NAME_SELECTOR).extract_first(),
css(NAME_SELECTOR).extract_first(),
'pieces': brickset.xpath(PIECES_SELECTOR).extract_first(),
'minifigs': brickset.xpath(MINIFIGS_SELECTOR).extract_first(),
'image': brickset.css(IMAGE_SELECTOR).extract_first(),
}
NEXT_PAGE_SELECTOR = '.next a ::attr(href)'
next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse
)
Сначала определяется селектор для ссылки на следующую страницу и извлекается первое совпадение. С помощью scrapy.Request «паук» сможет анализировать страницы, а с помощью callback=self.parse он будет загружать HTML страницы и передавать его методу для обработки, после чего он будет искать следующую страницу.
То есть, переходя на новую страницу, робот будет искать ссылку на следующую страницу. Поиск ссылок и переход по ним – очень важный аспект web scraping-а.
Сохраните код и запустите «паука», чтобы убедиться, что он работает должным образом. Он должен просмотреть все 779 результатов на 23 страницах.
Он должен просмотреть все 779 результатов на 23 страницах.
В результате код «паука» имеет такой вид:
import scrapy
class BrickSetSpider(scrapy.Spider):
name = 'brick_spider'
start_urls = ['http://brickset.com/sets/year-2016']
def parse(self, response):
SET_SELECTOR = '.set'
for brickset in response.css(SET_SELECTOR):
NAME_SELECTOR = 'h2 a ::text'
PIECES_SELECTOR = './/dl[dt/text() = "Pieces"]/dd/a/text()'
MINIFIGS_SELECTOR = './/dl[dt/text() = "Minifigs"]/dd[2]/a/text()'
IMAGE_SELECTOR = 'img ::attr(src)'
yield {
'name': brickset.css(NAME_SELECTOR).extract_first(),
'pieces': brickset.xpath(PIECES_SELECTOR).extract_first(),
'minifigs': brickset.xpath(MINIFIGS_SELECTOR).extract_first(),
'image': brickset.css(IMAGE_SELECTOR).extract_first(),
}
NEXT_PAGE_SELECTOR = '.next a ::attr(href)'
next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()
if next_page:
yield scrapy.Request(
response. urljoin(next_page),
urljoin(next_page),
callback=self.parse
)
Заключение
Теперь вы умеете разрабатывать поисковых роботов для анализа веб-страниц и извлечения нужных вам данных. Полученный в результате код вы можете расширить или использовать в качестве шаблона для написания новых роботов.
Вот несколько идей для расширения кода «паука»:
- На данный момент обрабатываются результаты только за 2016 год (http://brickset.com/sets/year-2016). Как обработать результаты за другие годы?
- Также на страницах можно найти цену каждого набора. Как извлечь эти данные? (Подсказка: эти данные можно найти в теге dt).
- Большая часть результатов содержит теги с семантическими данными о наборах. Попробуйте извлечь их.
Больше подробной информации о библиотеке Scrapy можно найти в официальной документации Scrapy.
Tags: Python, Python 3, Scrapy
Что такое веб-краулер? Все, что вам нужно знать от TechTarget.com
К
- Александр С. Гиллис,
Технический писатель и редактор
 Гиллис,
Гиллис,Что такое поисковый робот?
Поисковый робот, поисковый робот или веб-паук — это компьютерная программа, которая используется для поиска и автоматического индексирования содержимого веб-сайтов и другой информации в Интернете. Эти программы или боты чаще всего используются для создания записей для индекса поисковой системы.
Веб-сканеры систематически просматривают веб-страницы, чтобы узнать, о чем каждая страница на веб-сайте, поэтому эту информацию можно индексировать, обновлять и извлекать, когда пользователь выполняет поисковый запрос. Другие веб-сайты используют роботов для сканирования веб-страниц при обновлении собственного веб-контента.
Поисковые системы, такие как Google или Bing, применяют алгоритм поиска к данным, собранным поисковыми роботами, для отображения релевантной информации и веб-сайтов в ответ на поисковые запросы пользователей.
Если организация или владелец веб-сайта хочет, чтобы его веб-сайт занимал высокие позиции в поисковой системе, его необходимо сначала проиндексировать.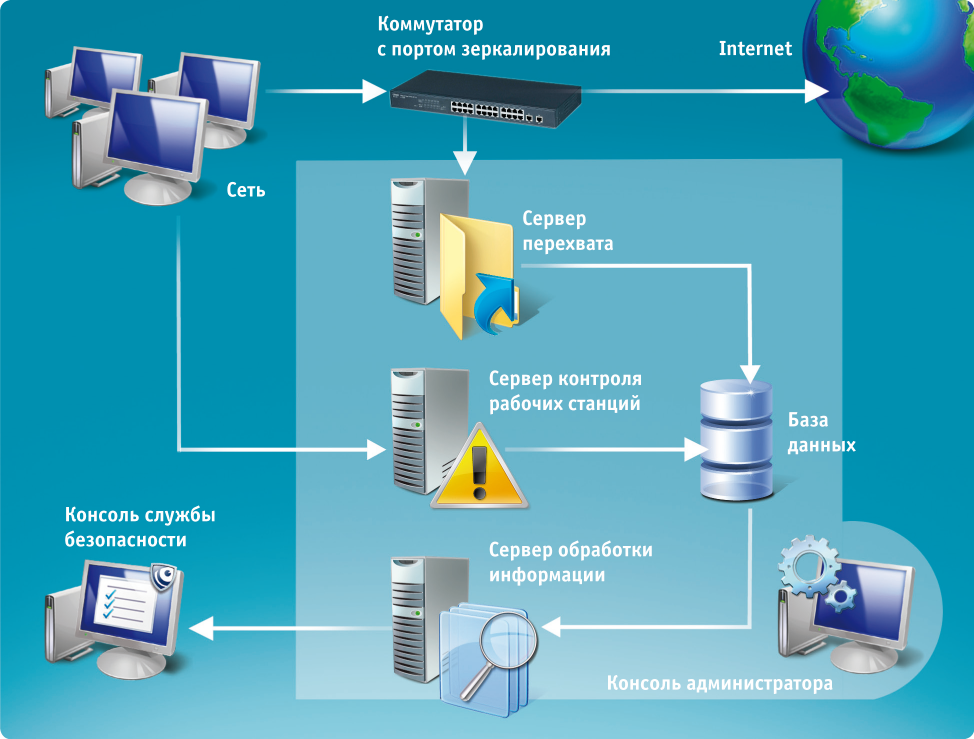 Если веб-страницы не просканированы и не проиндексированы, поисковая система не сможет найти их естественным путем.
Если веб-страницы не просканированы и не проиндексированы, поисковая система не сможет найти их естественным путем.
Поисковые роботы начинают сканирование определенного набора известных страниц, а затем переходят по гиперссылкам с этих страниц на новые страницы. Веб-сайты, которые не хотят, чтобы их сканировали или находили поисковые системы, могут использовать такие инструменты, как файл robots.txt, чтобы попросить ботов не индексировать веб-сайт или индексировать только его части.
Выполнение аудита сайта с помощью инструмента сканирования может помочь владельцам веб-сайтов выявить неработающие ссылки, дублированный контент и повторяющиеся, отсутствующие или слишком длинные или короткие заголовки.
На этой диаграмме показан процесс веб-сканирования и то, как веб-сканер ищет и индексирует веб-страницу.
Как работают поисковые роботы?
Поисковые роботы
работают, начиная с исходного состояния или списка известных URL-адресов, просматривая и затем классифицируя веб-страницы. Перед просмотром каждой страницы веб-сканер просматривает файл robots.txt веб-страницы, в котором указаны правила для ботов, обращающихся к веб-сайту. Эти правила определяют, какие страницы можно сканировать и по каким ссылкам можно переходить.
Перед просмотром каждой страницы веб-сканер просматривает файл robots.txt веб-страницы, в котором указаны правила для ботов, обращающихся к веб-сайту. Эти правила определяют, какие страницы можно сканировать и по каким ссылкам можно переходить.
Чтобы перейти на следующую веб-страницу, сканер находит гиперссылки и переходит по ним. По какой гиперссылке следует сканер, зависит от определенных политик, которые делают его более избирательным в отношении порядка следования сканера. Например, определенные политики могут включать следующее:
- сколько страниц ссылаются на эту страницу;
- количество просмотров страниц; и
- авторитет бренда.
Эти факторы означают, что страница может содержать более важную информацию для индексации.
Находясь на веб-странице, сканер сохраняет копию и описательные данные, называемые метатегами, а затем индексирует их для поисковой системы для поиска ключевых слов. Затем этот процесс решает, будет ли страница отображаться в результатах поиска по запросу, и если да, то возвращает список проиндексированных веб-страниц в порядке важности.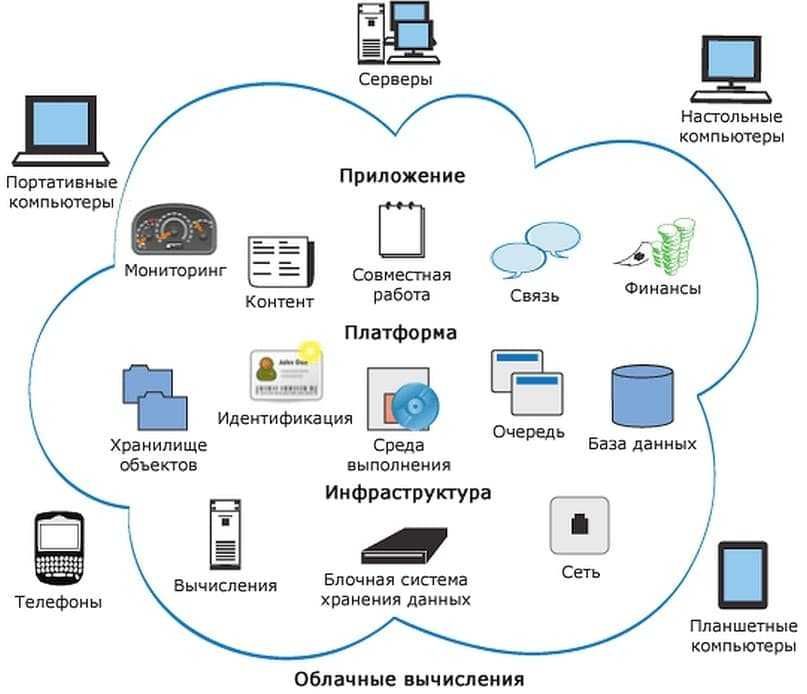
Если владелец веб-сайта не отправляет свою карту сайта поисковым системам для сканирования сайта, поисковый робот все равно может найти веб-сайт, перейдя по ссылкам с проиндексированных сайтов, которые связаны с ним.
Примеры поисковых роботов
Большинство популярных поисковых систем имеют собственные поисковые роботы, которые используют определенный алгоритм для сбора информации о веб-страницах. Инструменты веб-краулера могут быть настольными или облачными. Некоторые примеры поисковых роботов, используемых для индексации поисковыми системами, включают следующее:
- Amazonbot — поисковый робот Amazon.
- Bingbot — поисковый робот Microsoft для Bing.
- DuckDuckBot — сканер для поисковой системы DuckDuckGo.
- Googlebot — это поисковый робот Google.
- Yahoo Slurp — поисковый робот Yahoo.
- Yandex Bot — поисковый робот Яндекс.
Почему поисковые роботы важны для поисковой оптимизации
Поисковая оптимизация (SEO) — это процесс улучшения веб-сайта для повышения его видимости, когда люди ищут товары или услуги. Если на веб-сайте есть ошибки, которые затрудняют его сканирование, или он не может быть просканирован, его рейтинг страницы результатов поисковой системы (SERP) будет ниже или он не будет отображаться в результатах обычного поиска. Вот почему важно следить за тем, чтобы на веб-страницах не было неработающих ссылок или других ошибок, а также позволять ботам-сканерам получать доступ к веб-сайтам, а не блокировать их.
Если на веб-сайте есть ошибки, которые затрудняют его сканирование, или он не может быть просканирован, его рейтинг страницы результатов поисковой системы (SERP) будет ниже или он не будет отображаться в результатах обычного поиска. Вот почему важно следить за тем, чтобы на веб-страницах не было неработающих ссылок или других ошибок, а также позволять ботам-сканерам получать доступ к веб-сайтам, а не блокировать их.
Аналогичным образом, страницы, которые не сканируются регулярно, не будут отражать никаких обновленных изменений, которые в противном случае могли бы повысить SEO. Регулярное сканирование и обновление страниц могут помочь улучшить поисковую оптимизацию, особенно в отношении срочного контента.
Веб-сканирование собирает информацию о содержании опубликованных в Интернете работ, поэтому бот может затем индексировать ее для SEO.
Сканирование веб-сайтов в сравнении с просмотром веб-страниц
Веб-сканирование и веб-скрапинг — это два схожих понятия, которые легко спутать. Основное различие между ними заключается в том, что в то время как веб-сканирование связано с поиском и индексированием веб-страниц, веб-скрапинг — это извлечение данных, найденных на одной или нескольких веб-страницах.
Основное различие между ними заключается в том, что в то время как веб-сканирование связано с поиском и индексированием веб-страниц, веб-скрапинг — это извлечение данных, найденных на одной или нескольких веб-страницах.
Веб-скрапинг включает в себя создание бота, который может автоматически собирать данные с различных веб-страниц без разрешения. В то время как поисковые роботы постоянно переходят по ссылкам на основе гиперссылок, веб-скрапинг обычно является гораздо более целенаправленным процессом и может выполняться только после определенных страниц.
В то время как поисковые роботы следуют файлу robots.txt, ограничивая запросы, чтобы избежать перегрузки веб-серверов, веб-скрейперы игнорируют любую нагрузку, которую они могут вызвать.
Веб-скрапинг может использоваться в целях аналитики — сбора данных, их хранения и последующего анализа — для создания более целевых наборов данных.
Простые боты могут использоваться для парсинга веб-страниц, но более сложные боты используют искусственный интеллект для поиска соответствующих данных на странице и копирования их в нужное поле данных для обработки аналитическим приложением. Варианты использования ИИ на основе веб-скрапинга включают электронную коммерцию, исследования рынка труда, аналитику цепочки поставок, сбор корпоративных данных и исследования рынка.
Варианты использования ИИ на основе веб-скрапинга включают электронную коммерцию, исследования рынка труда, аналитику цепочки поставок, сбор корпоративных данных и исследования рынка.
Коммерческие приложения используют парсинг веб-страниц для анализа настроений при запуске новых продуктов, отбора структурированных наборов данных о компаниях и продуктах, упрощения интеграции бизнес-процессов и предиктивного сбора данных.
Узнайте больше о четырех других стратегиях SEO, включая создание лучших тематических кластеров и стратегии обратных ссылок.
Последнее обновление: сентябрь 2022 г.
Продолжить чтение О веб-сканере
- 5 бесплатных инструментов для исследования ключевых слов SEO
- Фишинговые атаки с использованием сомнительных методов SEO
- Борьба с плохими ботами — как избежать большой очистки данных
- 6 бесплатных инструментов для просмотра веб-страниц, упрощающих сбор данных
- Технологии Cisco Talos обнаруживают сайты программ-вымогателей в даркнете
враждебный ML
Состязательное машинное обучение — это метод, используемый в машинном обучении для обмана или введения в заблуждение модели с помощью злонамеренных входных данных.
Сеть
-
межсоединение центра обработки данных (DCI)Технология соединения центров обработки данных (DCI) связывает два или более центров обработки данных вместе для совместного использования ресурсов.
-
Протокол маршрутной информации (RIP)Протокол маршрутной информации (RIP) — это дистанционно-векторный протокол, в котором в качестве основного показателя используется количество переходов.
-
доступность сетиДоступность сети — это время безотказной работы сетевой системы в течение определенного интервала времени.
Безопасность
-
кража учетных данныхКража учетных данных — это тип киберпреступления, связанный с кражей удостоверения личности жертвы.
-
суверенная идентичностьСамостоятельная суверенная идентификация (SSI) — это модель управления цифровой идентификацией, в которой отдельные лица или предприятия владеют единолично .
.. -
Сертифицированный специалист по безопасности информационных систем (CISSP)Certified Information Systems Security Professional (CISSP) — это сертификат информационной безопасности, разработанный …
 ..
..ИТ-директор
-
рассказывание историй о данныхРассказывание историй о данных — это процесс перевода анализа данных в понятные термины с целью повлиять на деловое решение…
-
оншорный аутсорсинг (внутренний аутсорсинг)Оншорный аутсорсинг, также известный как внутренний аутсорсинг, представляет собой получение услуг от кого-то вне компании, но внутри …
-
FMEA (анализ видов и последствий отказов)FMEA (анализ видов и последствий отказов) представляет собой пошаговый подход к сбору сведений о возможных точках отказа в …
HRSoftware
-
самообслуживание сотрудников (ESS)Самообслуживание сотрудников (ESS) — это широко используемая технология управления персоналом, которая позволяет сотрудникам выполнять множество связанных с работой .
.. -
платформа обучения (LXP)Платформа обучения (LXP) — это управляемая искусственным интеллектом платформа взаимного обучения, предоставляемая с использованием программного обеспечения как услуги (…
-
Поиск талантовПривлечение талантов — это стратегический процесс, который работодатели используют для анализа своих долгосрочных потребностей в талантах в контексте бизнеса …
 ..
..Служба поддержки клиентов
-
виртуальный помощник (помощник ИИ)Виртуальный помощник, также называемый помощником ИИ или цифровым помощником, представляет собой прикладную программу, которая понимает естественный язык …
-
жизненный цикл клиентаВ управлении взаимоотношениями с клиентами (CRM) жизненный цикл клиента — это термин, используемый для описания последовательности шагов, которые проходит клиент.
.. -
интерактивный голосовой ответ (IVR)Интерактивный голосовой ответ (IVR) — это автоматизированная система телефонии, которая взаимодействует с вызывающими абонентами, собирает информацию и маршрутизирует …
 ..
..Веб-исследовательский проект направлен на сбор информации о пауках | News
Аспирант из штата Техас проводит добровольное исследование, чтобы лучше собирать данные о наших восьмилапых друзьях — пауках.
Проект, созданный Брией Марти, аспиранткой-биологом, называется «Друзья пауков» и ставит перед учащимися задачу найти, наблюдать и собирать информацию о пауках.
Студенты-добровольцы сначала заполняют анкету, чтобы оценить свое отношение к паукам. После того, как они дадут согласие на участие в исследовании, студенты получат пакет, содержащий задание для самостоятельного поиска определенных видов пауков.
Учащиеся используют руководство, созданное Марти, чтобы определить типы пауков, которых можно найти в Техасе, независимо от того, живут ли они внутри или снаружи.
Учащиеся могут сфотографировать пауков и поделиться ими с помощью социальной сети iNaturalist для сбора данных. Приложение позволяет пользователям обмениваться изображениями растений или животных. После выполнения задания учащиеся заполняют анкету после занятия.
Согласно веб-сайту iNaturalist, записывая и делясь своими наблюдениями, вы создаете данные исследовательского качества для ученых, работающих над тем, чтобы лучше понять и защитить природу.
Ассоциированный профессор биологии Кристи Дэниел в основном занимается изучением проблем передачи научных данных с помощью визуальных средств как в аудиториях колледжа, так и в неформальной учебной среде, например, «Друзья пауков».
«Я изучаю, как люди узнают о рыбах и змеях… или как они (педагоги) говорят об этом, чтобы помочь другим людям понять, что они делают», — сказал Даниэль.
Марти надеется объяснить науку таким образом, чтобы ее мог понять каждый, независимо от предшествующего академического опыта, и считает, что ее программа — это шаг к тщательному изучению пауков.
«Пауки абсолютно недостаточно изучены, и нам нужно больше информации о них», — сказал Марти. «Для этого не нужно быть ученым».
Марти — один из шести студентов, которые вместе работают над исследовательским проектом под названием Minding the Hill Country под руководством доцента биологии Кристи Дэниел. Проект состоит из пяти мероприятий, в том числе «Друзья пауков», которые предоставляются членам сообщества, заинтересованным в изучении природы.
Minding the Hill Country стремится сделать науку более доступной для более широких слоев населения. Проект представляет собой серию мероприятий, которые могут быть предоставлены членам сообщества, которые заинтересованы в изучении природы. Проект Марти «Друзья-пауки» — это одно из мероприятий, направленных на то, чтобы научить членов сообщества об окружающей среде.
Марти сказал, что цель состоит в том, чтобы сделать науку доступной для всех, а также посмотреть, может ли общественная наука изменить наши представления о пауках.