Содержание
Как работают браузеры — введение в безопасность веб-приложений / Хабр
Давайте начнем серию статей по безопасности веб-приложений с объяснением того, что делают браузеры и как именно они это делают. Поскольку большинство ваших клиентов будут взаимодействовать с вашим веб-приложением через браузеры, необходимо понимать основы функционирования этих замечательных программ.
Chrome и lynx
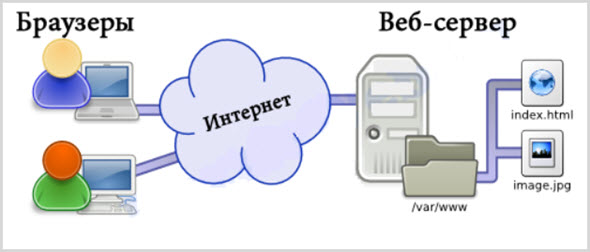
Браузер — это движок рендеринга. Его работа заключается в том, чтобы загрузить веб-страницу и представить её в понятном для человека виде.
Хоть это и почти преступное упрощение, но пока это все, что нам нужно знать на данный момент.
- Пользователь вводит адрес в строке ввода браузера.
- Браузер загружает «документ» по этому URL и отображает его.
Возможно, вы привыкли работать с одним из самых популярных браузеров, таких как Chrome, Firefox, Edge или Safari, но это не значит, что в мире нет других браузеров.
Например, lynx — это легкий текстовый браузер, работающий из командной строки. В основе lynx лежат те же самые принципы, которые вы найдете в любых других «мейнстримных» браузерах. Пользователь вводит веб-адрес (URL), браузер скачивает документ и отображает его — единственное отличие состоит в том, что lynx использует не движок графического рендеринга, а текстовый интерфейс, благодаря которому такие сайты, как Google, выглядят так:
Мы в целом имеем представление, что делает браузер, но давайте подробнее рассмотрим действия, которые эти гениальные приложения выполняют для нас.
Что делает браузер?
Короче говоря, работа браузера в основном состоит из
- Разрешение DNS
- HTTP-обмен
- Рендеринг
- Сброс и повтор
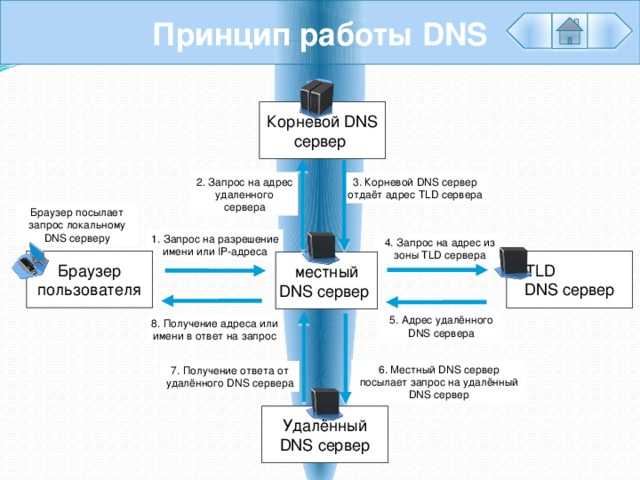
Разрешение DNS
Этот процесс помогает браузеру узнать, к какому серверу он должен подключиться, когда пользователь вводит URL. Браузер связывается с DNS-сервером и обнаруживает, что google.com соответствует набору цифр 216.58.207.110 — IP-адресу, к которому может подключиться браузер.
Браузер связывается с DNS-сервером и обнаруживает, что google.com соответствует набору цифр 216.58.207.110 — IP-адресу, к которому может подключиться браузер.
HTTP-обмен
Как только браузер определит, какой сервер будет обслуживать наш запрос, он установит с ним TCP-соединение и начнет HTTP-обмен. Это не что иное, как способ общения браузера с нужным ему сервером, а для сервера — способ отвечать на запросы браузера.
HTTP — это просто название самого популярного протокола для общения в сети, и браузеры в основном выбирают HTTP при общении с серверами. HTTP-обмен подразумевает, что клиент (наш браузер) отправляет запрос, а сервер присылает ответ.
Например, после того, как браузер успешно подключится к серверу, обслуживающему google.com, он отправит запрос, который выглядит следующим образом
GET / HTTP/1.1
Host: google.com
Accept
Давайте разберем запрос построчно:
- GET / HTTP/1.
 1: этой первой строкой браузер просит сервер извлечь документ из месторасположения /, добавляя затем, что остальная часть запроса будет происходить по протоколу HTTP/1.1 (а можно так же использовать версию 1.0 или 2)
1: этой первой строкой браузер просит сервер извлечь документ из месторасположения /, добавляя затем, что остальная часть запроса будет происходить по протоколу HTTP/1.1 (а можно так же использовать версию 1.0 или 2) - Host: google.com: это единственный HTTP-заголовок, обязательный для протокола HTTP/1.1. Поскольку сервер может обслуживать несколько доменов (google.com, google.co.uk и т. д.), Клиент здесь упоминает, что запрос был для этого конкретного хоста.
- Accept: */*: необязательный заголовок, в котором браузер сообщает серверу, что он примет любой ответ. Сервер может иметь ресурс, доступный в форматах JSON, XML или HTML, поэтому он может выбирать любой формат, который предпочитает
 1: этой первой строкой браузер просит сервер извлечь документ из месторасположения /, добавляя затем, что остальная часть запроса будет происходить по протоколу HTTP/1.1 (а можно так же использовать версию 1.0 или 2)
1: этой первой строкой браузер просит сервер извлечь документ из месторасположения /, добавляя затем, что остальная часть запроса будет происходить по протоколу HTTP/1.1 (а можно так же использовать версию 1.0 или 2)
После того, как браузер, выступающий в роли клиента, завершит выполнение своего запроса, сервер отправит ответ. Вот как выглядит ответ:
HTTP/1.1 200 OK Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.
 google.com; HttpOnly
<!doctype html><html">
...
...
</html>
google.com; HttpOnly
<!doctype html><html">
...
...
</html>
Воу, на этот раз довольно много информации, которую нужно переварить. Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Прямо сейчас вам не нужно понимать каждую строку в ответе. Позже в этой серии публикации мы подробнее расскажем о протоколе HTTP, его заголовках и т. д.
На данный момент все, что вам нужно знать — это то, что клиент и сервер обмениваются информацией и что они делают это через HTTP-протокол.
Рендеринг
Последним по счёту, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
<!doctype html><html"> .
 ..
...
</html>
..
...
</html>
В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия среднестатистического Васи.
Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Поскольку это серия посвящена безопасности, я собираюсь дать подсказку о том, что мы только что узнали: злоумышленники легко зарабатывают на жизнь уязвимостями в части HTTP-обмена и рендеринга. Уязвимости, злонамеренные пользователи и прочие фантастические твари встречаются и в других местах, но более эффективный подход к обеспечению защиты именно на упомянутых уровнях уже позволяет вам добиваться успехов в улучшении вашего состояния безопасности.
Вендоры
4 самых популярных браузера принадлежат разным вендорам:
- Chrome от Google
- Firefox от Mozilla
- Сафари от Apple
- Edge от Microsoft
Помимо борьбы друг с другом, чтобы увеличить свое проникновение на рынок, поставщики также взаимодействуют друг с другом, чтобы улучшить веб-стандарты, которые являются своего рода «минимальными требованиями» для браузеров.
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF (подробнее об этом позже). Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.
Это говорит нам о двух вещах:
- Похоже, что Safari недостаточно заботится о безопасности своих пользователей (шучу: файлы cookie SameSite будут доступны в Safari 12, который, возможно, уже был выпущен к моменту прочтения этой статьи)
- исправление уязвимости в одном браузере не означает, что все ваши пользователи в безопасности
Первый пункт — это выстрел в Safari (как я уже говорил, шучу!), а второй пункт действительно важен. При разработке веб-приложений нам нужно не только убедиться, что они выглядят одинаково в разных браузерах, но и обеспечить одинаковую защиту наших пользователей на разных платформах.
Ваша стратегия обеспечения безопасности в сети должна варьироваться в зависимости от того, какие возможности нам предоставляет вендор-поставщик браузера. В настоящее время большинство браузеров поддерживают один и тот же набор функций и редко отклоняются от своего общей дорожной карты, но случаи, подобные приведенному выше, все еще случаются, и это то, что мы должны учитывать при определении нашей стратегии безопасности.
В нашем случае, если мы решим, что будем нейтрализовывать атаки CSRF только с помощью файлов cookie SameSite, мы должны знать, что мы подвергаем риску наших пользователей Safari. И наши пользователи тоже должны это знать.
И последнее, но не менее важное: вы должны помнить, что вы можете решить, поддерживать ли версию браузера или нет: поддержка каждой версии браузера будет непрактичной (вспомните хпро Internet Explorer 6). Несмотря на это, уверенная поддержка нескольких последних версий основных браузеров — как правило, хорошее решение. Однако, если вы не планируете предоставлять защиту на какой-то определенной платформе, очень желательно, чтобы ваши пользователи об этом знали.
Совет для профи: вы никогда не должны поощрять своих пользователей использовать устаревшие браузеры или активно поддерживать их. Даже если вы приняли все необходимые меры предосторожности, другие веб-разработчики этого не сделали. Поощряйте пользователей использовать последнюю поддерживаемую версию одного из основных браузеров.
Вендор или стандартный баг?
Тот факт, что обычный пользователь обращается к нашему приложению благодаря помощи стороннего клиентского программного обеспечения (браузера), добавляет еще один уровень, усложняющий путь к удобному и безопасному просмотру веб-страниц: сам браузер может быть источником уязвимости безопасности.
Вендоры, как правило, предоставляют вознаграждения (также известные как баг-баунти) исследователям безопасности, которые могут искать уязвимость в самом браузере. Эти ошибки связаны не с вашим веб-приложением, а с тем, как браузер самостоятельно управляет безопасностью.
Например, программа поощрений Chrome позволяет исследователям безопасности обращаться к команде безопасности Chrome, чтобы сообщить об обнаруженных ими уязвимостях. Если факт наличия уязвимости подтвердится, будет выпущено исправление и, как правило, опубликовано уведомление о безопасности, а исследователь получит (обычно финансовое) вознаграждение от программы.
Такие компании, как Google, инвестируют достаточно солидный капитал в свои программы Bug Bounty, поскольку это позволяет компаниям привлекать множество исследователей, обещая им финансовую выгоду в случае обнаружения ими каких-либо проблем с тестируемым программным обеспечением.
В программе Bug Bounty выигрывают все: поставщику удается повысить безопасность своего программного обеспечения, а исследователям платят за их находки. Мы обсудим эти программы позже, так как я считаю, что инициативы Bug Bounty заслуживают отдельного раздела в ландшафте аспектов безопасности.
Джейк Арчибальд (Jake Archibald) — разработчик-«адвокат» в Google, который обнаружил уязвимость, затрагивающую несколько браузеров.
 Он задокументировал свои усилия по ее обнаружению, процесс обращения к различным вендорам, затронутым уязвимостью, и реакцию представителей вендоров в интересном блог-посте, который я рекомендую вам прочитать.
Он задокументировал свои усилия по ее обнаружению, процесс обращения к различным вендорам, затронутым уязвимостью, и реакцию представителей вендоров в интересном блог-посте, который я рекомендую вам прочитать.Браузер для разработчиков
К настоящему времени мы должны были понять очень простую, но довольно важную концепцию: браузеры — это всего лишь HTTP-клиенты, созданные для «усредненного» интернет-пользователя.
Браузеры определенно более мощны, чем простой HTTP-клиент для какой-либо платформы (например, вспомните, что у NodeJS есть зависимость от ‘http’), но, в конце концов, они «просто» продукт естественной эволюции более простых HTTP-клиентов.
Что до разработчиков, нашим HTTP-клиентом, вероятно, является cURL от Daniel Stenberg, одна из самых популярных программ, которую веб-разработчики используют ежедневно. Она позволяет нам осуществлять HTTP-обмен на лету, отправляя HTTP-запрос из нашей командной строки:
$ curl -I localhost:8080 HTTP/1.
 1 200 OK
server: ecstatic-2.2.1
Content-Type: text/html
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
cache-control: max-age=3600
Date: Fri, 20 Jul 2018 11:21:02 GMT
Connection: keep-alive
1 200 OK
server: ecstatic-2.2.1
Content-Type: text/html
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
cache-control: max-age=3600
Date: Fri, 20 Jul 2018 11:21:02 GMT
Connection: keep-alive
В приведенном выше примере мы запросили документ по адресу localhost:8080/, и локальный сервер успешно на него ответил.
Вместо того, чтобы выгружать тело ответа в командную строку, мы использовали флаг -I, который сообщает cURL, что нас интересуют только заголовки ответа. Сделав еще шаг вперед, мы можем дать команду cURL выдавать немного больше информации, включая фактический запрос, который он выполняет, чтобы мы могли лучше изучить весь этот HTTP-обмен. Опция, которую мы должны использовать: -v (verbose, подробнее):
$ curl -I -v localhost:8080 * Rebuilt URL to: localhost:8080/ * Trying 127.0.0.1... * Connected to localhost (127.0.0.1) port 8080 (#0) > HEAD / HTTP/1.
 1
> Host: localhost:8080
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< server: ecstatic-2.2.1
server: ecstatic-2.2.1
< Content-Type: text/html
Content-Type: text/html
< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
< last-modified: Fri, 20 Jul 2018 11:20:35 GMT
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
< cache-control: max-age=3600
cache-control: max-age=3600
< Date: Fri, 20 Jul 2018 11:25:55 GMT
Date: Fri, 20 Jul 2018 11:25:55 GMT
< Connection: keep-alive
Connection: keep-alive
<
* Connection #0 to host localhost left intact
1
> Host: localhost:8080
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< server: ecstatic-2.2.1
server: ecstatic-2.2.1
< Content-Type: text/html
Content-Type: text/html
< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
< last-modified: Fri, 20 Jul 2018 11:20:35 GMT
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
< cache-control: max-age=3600
cache-control: max-age=3600
< Date: Fri, 20 Jul 2018 11:25:55 GMT
Date: Fri, 20 Jul 2018 11:25:55 GMT
< Connection: keep-alive
Connection: keep-alive
<
* Connection #0 to host localhost left intact
Примерно та же информация доступна в популярных браузерах посредством их DevTools.
Как мы уже видели, браузеры представляют собой не более чем сложные HTTP-клиенты. Конечно, они добавляют огромное количество функций (например, управление учетными данными, создание закладок, история и т. Д.), Но правда в том, что они были рождены как HTTP-клиенты для людей. Это важно, так как в большинстве случаев вам не нужен браузер для проверки безопасности вашего веб-приложения, когда вы можете просто «закурлить его» и посмотреть на ответ.
Это важно, так как в большинстве случаев вам не нужен браузер для проверки безопасности вашего веб-приложения, когда вы можете просто «закурлить его» и посмотреть на ответ.
И последнее, что я хотел бы отметить: браузером может быть все, что угодно. Если у вас есть мобильное приложение, которое использует API-интерфейсы по протоколу HTTP, то такое приложение является вашим браузером — оно просто настроено вами по индивидуальному заказу, которое распознает только определенный тип HTTP-ответов (из вашего собственного API).
Погружение в протокол HTTP
Как мы уже упоминали, что собираемся наиболее подробно осветить фазы HTTP-обмена и рендеринга, поскольку именно они предоставляют наибольшее количество векторов атак для злоумышленников.
В следующей статье мы более подробно рассмотрим протокол HTTP и попытаемся понять, какие меры мы должны предпринять для обеспечения безопасности HTTP-обмена.
Перевод выполнен при поддержке компании EDISON Software, которая профессионально занимается разработкой веб-сайтов для крупных заказчиков, а так же веб-разработкой на C# и . NET.
NET.
Что такое браузер и как он работает
Что это такое? Как ни странно, но среди миллиардов пользователей Интернета многие до сих пор не совсем понимают, что такое браузер и какие возможности, кроме банального поиска информации, он способен предоставить.
Что дает при использовании? Воспользовавшись им, можно без особого труда найти несчетное количество полезных статей по данному поводу – включая эту самую. Но вы ведь ее уже нашли, не так ли? Так что давайте приступим…
В статье рассказывается:
- Суть браузеров
- Принцип работы браузера
- Критерии выбора браузера
- Самые популярные в 2023 году браузеры
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Суть браузеров
Если объяснить простыми словами, что такое браузер, то это компьютерная программа-обозреватель, позволяющая пользователю совершать различные действия в интернете. В частности, осуществлять запросы по необходимой информации и просматривать сайты.
В частности, осуществлять запросы по необходимой информации и просматривать сайты.
Сегодня практически каждый человек имеет возможность выхода в сеть через компьютер, смартфон и другие мобильные устройства с использованием браузера. Программа обрабатывает пользовательские запросы и отправляет их на сервер, а затем полученные данные демонстрирует в виде веб-страниц.
Суть браузеров
Пользователь видит сайты, содержащие различный контент – текстовый, графический, а также ссылки и кнопки, разделы меню и пр. Каждая страница имеет свой уникальный внешний вид. На сервере же веб-страницы содержатся в виде кода, созданного с помощью языков HTML, CSS или Java-script. Таким образом, браузер в компьютере служит для преображения программного кода в конечный формат страницы, которая и представлена вниманию пользователя.
При нажатии правой кнопки мыши в любом месте окна браузера появляется контекстное меню. Выбрав пункт «Посмотреть код», можно увидеть в новой вкладке HTML-код страницы, полученный с сервера.
Так как сейчас существует множество различных видов браузеров, то нет ничего удивительного в том, что их разработчики конкурируют друг с другом, пытаясь привлечь новых пользователей. В связи с этим они модифицируют версии браузера, добавляют новые функции, например:
- Возможность скачивания файлов различного формата: текстовые, графические, видеоролики и фильмы, музыка, программы и другие.
- Опция сохранения данных пользователя. В частности речь идет о закладках и истории посещений сайтов в браузере, благодаря чему пользователь может всегда снова зайти на интересный ему ресурс. При желании также можно хранить пароли.
- Взаимодействие с другими пользователями: электронная почта, форумы, чаты, страницы социальных сетей.
- Возможность совершения покупок в интернет-магазине.
- Обучающие онлайн-платформы.
- Встроенная защита от вирусов, блокировка потенциально опасных сайтов, оповещения о недостаточной безопасности страницы.
Кроме того, установленные плагины позволяют расширить функционал программы, добавить опции, которые пользователь сможет использовать по своему усмотрению. К примеру, изменить внешний вид браузера, добавить новостной или погодный блок, закрепить быстрый доступ к часто посещаемым сайтам и многое другое.
К примеру, изменить внешний вид браузера, добавить новостной или погодный блок, закрепить быстрый доступ к часто посещаемым сайтам и многое другое.
Помимо браузеров на компьютерах существуют и их мобильные версии. Допускается одновременное использование нескольких видов программ на одном устройстве.
Принцип работы браузера
Несмотря на многообразие видов браузеров, принцип их работы всегда одинаковый. Ниже рассмотрим последовательность действий программы:
- Пользователь открывает установленный браузер на устройстве и в адресной строке вводит URL-адрес нужного сайта.
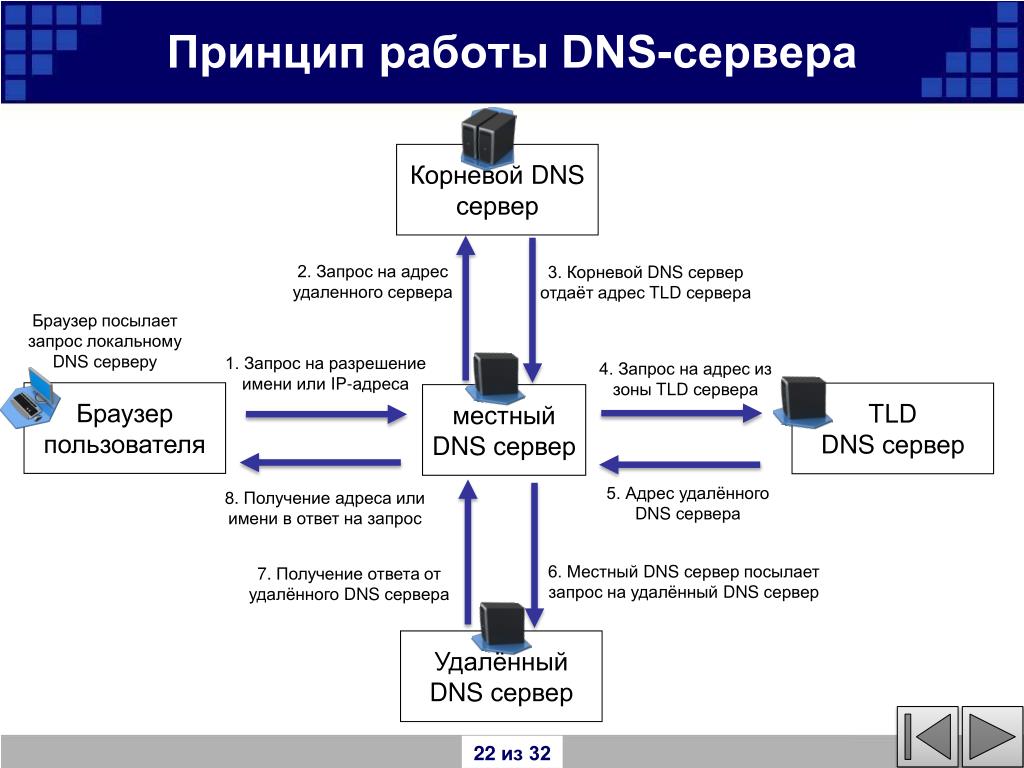
- Браузер производит поиск сервера по IP-адресу, который является уникальным для каждой страницы. Ищет он его, прежде всего, в кэше роутера, операционной системе или просматривает историю подключений. Если искомый сайт посещался ранее, то информация об IP-адресе хранится именно в ней. В случае, когда поиск не дал результатов, браузер обращается к DNS (Domain Name System) – источнику, содержащему сведения об именах доменов.
- После того, как нужный IP-адрес найден, браузер подключается к нему через специальный протокол TCP/IP. С его помощью происходит обмен данными в сети.

Принцип работы браузера
Соединение устанавливается благодаря трем этапам процесса, имеющего название «Handshaking», в переводе с английского «Рукопожатие». Происходит он следующим образом: сервер получает запрос, в котором указан номер последовательности и флаг SYN, после чего отправляет подтверждение о получении SYN-ACK, и удостоверяет прием – ACK. По завершению процесса соединение установлено.
- Для отображения страницы браузер посылает на сервер HTTP-запрос с применением методов POST и GET.
- Обработка запроса сервером производится через веб-серверы Apache, Nginx, Lighttpd, далее браузеру отправляется ответ, содержащий данные о файлах cookie, алгоритмах кэширования и контенте.
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
pdf 3,7mb
doc 1,7mb
Уже скачали 20313
- После того, как браузер обработал полученный ответ от сервера, он отображает запрашиваемую страницу. Это процесс носит название рендеринга, во время него происходит обмен данными, а после его окончания пользователь видит сайт, адрес которого вводил ранее.
 Это процесс носит название рендеринга, во время него происходит обмен данными, а после его окончания пользователь видит сайт, адрес которого вводил ранее.
Это процесс носит название рендеринга, во время него происходит обмен данными, а после его окончания пользователь видит сайт, адрес которого вводил ранее.Нужно сказать, что на этом браузер не заканчивает свою работу. Он подгружает музыку или видео, страницы, на которые можно перейти с сайта, осуществляет сбор и хранение данных о действиях пользователя, производит запись файлов в хранилище и другие действия, прописанные разработчиком.
Критерии выбора браузера
Стандартов оценки качества и степени привлекательность для каждого вида браузера не существует, так как каждый пользователь имеет свои цели использования программы. Одному обозреватель нужен только для работы с информацией, другому – для общения в социальных сетях и просмотра фильмов, а кто-то и вовсе эксплуатирует браузер для работы над проектами, с приложениями и т.д.
Критерии важности пользования обозревателем для каждого человека разные, но есть общие аспекты, на которые стоит ориентироваться, выбирая официальный браузер:
- Степень безопасности. При скачивании файла происходит идентификация его типа, и если браузер выявляет содержащиеся в нем вирусы, оповещает об этом пользователя. Кроме этого, качественная программа будет автоматически блокировать доступ к сайтам с вредоносным ПО.
 При скачивании файла происходит идентификация его типа, и если браузер выявляет содержащиеся в нем вирусы, оповещает об этом пользователя. Кроме этого, качественная программа будет автоматически блокировать доступ к сайтам с вредоносным ПО.
При скачивании файла происходит идентификация его типа, и если браузер выявляет содержащиеся в нем вирусы, оповещает об этом пользователя. Кроме этого, качественная программа будет автоматически блокировать доступ к сайтам с вредоносным ПО.Критерии выбора браузераКритерии выбора браузера
- Интеграция с другими сервисами. Выбору пользователей представлено множество развлекательных и нужных для работы ресурсов, требующих регистрации в каждом. Это неудобно и отнимает много времени. Поэтому многие предпочитают скачать бесплатный браузер, позволяющий работать с различными сервисами, используя один аккаунт.
- Способность работать на устройстве вне зависимости от типа операционной системы. Компьютерные технологии непрерывно развиваются, и современный браузер должен быть адаптирован под любую платформу.
Только до 10.04
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:
Уже скачали 7503
Самые популярные в 2023 году браузеры
Google Chrome
Среди пользователей интернета Google Chrome пользуется высоким спросом, во многом благодаря высокой скорости работы и удобному интерфейсу. Более того, с развитием технологий он также совершенствуется. Chrome разработан компанией Google на основе свободного браузера Chromium и движка Blink (до 2013 года использовался Webkit).
Более того, с развитием технологий он также совершенствуется. Chrome разработан компанией Google на основе свободного браузера Chromium и движка Blink (до 2013 года использовался Webkit).
Браузер имеет свой интернет-магазин, в котором пользователь найдет необходимые для себя веб-приложения, расширения, различные темы и функции. Имеется голосовая опция, возможность работы в режиме инкогнито. С применением технологии Sandbox система регулярно обновляет списки сайтов, угрожающих безопасности устройства пользователя и его личных данных.
К основным преимуществам браузера Google Chrome можно отнести: продуктивность, высокий уровень безопасности, синхронизация между устройствами, возможность установки дополнительных плагинов, постоянное развитие и поддержка разработчиками.
Среди недостатков выделяются: высокие требования к объему оперативной памяти устройства, технология сбора пользовательских данных, при которой сведения могут быть использованы в коммерческих целях.
Яндекс.
 Браузер
Браузер
Российская разработка снискала у пользователей сети огромную популярность, совместив в себе высокую скорость, функциональность и настраиваемые опции. Яндекс.Браузер предоставляет доступ к различным сервисам, имеет понятный и удобный интерфейс, интересный дизайн.
Отличительной особенностью Yandex является возможность активации режима турбо, который ускоряет загрузку контента на сайтах. Также в браузер встроен автоматический переводчик страницы, язык которой не совпадает с тем, что указан в настройках.
Другие преимущества браузера: кроссплатформенность, высокий уровень безопасности, поддержка дополнительных расширений, блокировка рекламы.
Недостатки: скорость работы браузера напрямую зависит от количества установленных плагинов – чем их больше, тем ниже производительность; требуется большой объем оперативной памяти.
Продвижение блога — Генератор
продаж
Рейтинг:
5
( голосов
2 )
Поделиться статьей
Как работают веб-браузеры?.
 Браузер — это программное приложение… | by Monica Raghuwanshi
Браузер — это программное приложение… | by Monica Raghuwanshi
Браузер — это программное приложение, используемое для поиска, извлечения и отображения контента во всемирной паутине, включая веб-страницы, изображения, видео и другие файлы. В качестве клиент-серверной модели браузер — это клиент, работающий на компьютере, который связывается с веб-сервером и запрашивает информацию. Веб-сервер отправляет информацию обратно в веб-браузер, который отображает результаты на компьютере или другом подключенном к Интернету устройстве, поддерживающем браузер.
Современные браузеры представляют собой полнофункциональные программные пакеты, которые могут интерпретировать и отображать веб-страницы в формате HTML, приложения, JavaScript, AJAX и другой контент, размещенный на веб-серверах. Многие браузеры предлагают подключаемые модули, которые расширяют возможности программного обеспечения, чтобы оно могло отображать мультимедийную информацию (включая звук и видео), или браузер можно было использовать для выполнения таких задач, как видеоконференции, разработка веб-страниц или добавление антифишинговых фильтров и другие функции безопасности для браузера.
Браузер — это группа структурированных кодов, которые вместе выполняют ряд задач по отображению веб-страницы на экране. В зависимости от выполняемых ими задач эти коды изготавливаются в виде различных компонентов.
На приведенном ниже рисунке показаны основные компоненты веб-браузера:
Основные компоненты браузера
- Пользовательский интерфейс : Пользовательский интерфейс — это пространство, в котором Пользователь взаимодействует с браузером. Он включает в себя адресную строку, кнопки «Назад» и «Далее», кнопку «Домой», «Обновить» и «Стоп», опцию закладки и т. Д. Все остальные части, кроме окна, в котором отображается запрошенная веб-страница, находятся под ним.
- Механизм браузера : Механизм браузера работает как мост между пользовательским интерфейсом и механизмом рендеринга. В соответствии с входными данными из различных пользовательских интерфейсов он запрашивает механизм рендеринга и управляет им.
- Механизм рендеринга : Механизм рендеринга, как следует из названия, отвечает за отображение запрошенной веб-страницы на экране браузера. Механизм рендеринга интерпретирует документы HTML, XML и изображения, отформатированные с помощью CSS, и создает макет, который отображается в пользовательском интерфейсе. Однако, используя плагины или расширения, он также может отображать данные других типов. Разные браузеры используют разные механизмы рендеринга:
* Internet Explorer: Trident
* Firefox и другие браузеры Mozilla: Gecko
* Chrome и Opera 15+: Blink
* Chrome (iPhone) и Safari: Webkit - Сеть : Компонент браузера, который извлекает URL-адреса с помощью распространенные интернет-протоколы HTTP или FTP. Сетевой компонент обрабатывает все аспекты интернет-коммуникаций и безопасности. Сетевой компонент может реализовать кэш извлеченных документов, чтобы уменьшить сетевой трафик.
- Интерпретатор JavaScript: Это компонент браузера, который интерпретирует и выполняет код javascript, встроенный в веб-сайт. Интерпретированные результаты отправляются в механизм рендеринга для отображения. Если скрипт внешний, то сначала ресурс извлекается из сети. Парсер приостанавливается до тех пор, пока скрипт не будет выполнен.
- Бэкэнд пользовательского интерфейса : Бэкенд пользовательского интерфейса используется для рисования основных виджетов, таких как поля со списком и окна. Этот бэкэнд предоставляет общий интерфейс, который не зависит от платформы. Он использует методы пользовательского интерфейса операционной системы.
- Сохранение/хранение данных: Это уровень сохранения. Браузеры поддерживают такие механизмы хранения, как localStorage, IndexedDB, WebSQL и FileSystem. Это небольшая база данных, созданная на локальном диске компьютера, на котором установлен браузер. Он управляет данными пользователя, такими как кеш, файлы cookie, закладки и настройки.
 Механизм рендеринга интерпретирует документы HTML, XML и изображения, отформатированные с помощью CSS, и создает макет, который отображается в пользовательском интерфейсе. Однако, используя плагины или расширения, он также может отображать данные других типов. Разные браузеры используют разные механизмы рендеринга:
Механизм рендеринга интерпретирует документы HTML, XML и изображения, отформатированные с помощью CSS, и создает макет, который отображается в пользовательском интерфейсе. Однако, используя плагины или расширения, он также может отображать данные других типов. Разные браузеры используют разные механизмы рендеринга:  Если скрипт внешний, то сначала ресурс извлекается из сети. Парсер приостанавливается до тех пор, пока скрипт не будет выполнен.
Если скрипт внешний, то сначала ресурс извлекается из сети. Парсер приостанавливается до тех пор, пока скрипт не будет выполнен.Здесь важно отметить, что в веб-браузерах, таких как Google Chrome, каждая вкладка выполняется в отдельном процессе (несколько экземпляров механизма рендеринга).

Сетевой уровень начнет отправлять содержимое запрошенных документов в механизм рендеринга порциями по 8 КБ.
Основной поток механизма рендеринга
Механизм рендеринга анализирует фрагменты HTML-документа и преобразует элементы в узлы DOM в дереве, называемом «дерево содержимого c » или «дерево DOM ». Он также анализирует как внешние файлы CSS, так и элементы стиля.
Во время построения дерева DOM браузер строит другое дерево, визуализировать дерево . Это дерево состоит из визуальных элементов в том порядке, в котором они будут отображаться. Это визуальное представление документа. Цель этого дерева — дать возможность рисовать содержимое в правильном порядке. Firefox называет элементы дерева рендеринга «фреймами». WebKit использует термин средство визуализации или объект визуализации.
После построения дерева рендеринга он проходит через « процесс компоновки » дерева рендеринга. Когда средство визуализации создается и добавляется в дерево, у него нет положения и размера. Процесс вычисления этих значений называется компоновкой или перекомпоновкой. Это означает предоставление каждому узлу точных координат, где он должен появиться на экране. Позиция корневого рендерера равна 0,0, а его размеры соответствуют области просмотра — видимой части окна браузера. Все средства визуализации имеют метод «макета» или «перекомпоновки», каждый модуль визуализации вызывает метод макета своих дочерних элементов, которым требуется макет.
Когда средство визуализации создается и добавляется в дерево, у него нет положения и размера. Процесс вычисления этих значений называется компоновкой или перекомпоновкой. Это означает предоставление каждому узлу точных координат, где он должен появиться на экране. Позиция корневого рендерера равна 0,0, а его размеры соответствуют области просмотра — видимой части окна браузера. Все средства визуализации имеют метод «макета» или «перекомпоновки», каждый модуль визуализации вызывает метод макета своих дочерних элементов, которым требуется макет.
Следующий этап покраска . На этапе рисования выполняется обход дерева рендеринга и вызывается метод рендерера «paint()» для отображения содержимого на экране. В рисовании используется внутренний слой пользовательского интерфейса.
Механизм рендеринга всегда пытается отобразить содержимое на экране как можно быстрее для лучшего взаимодействия с пользователем. Он не ждет завершения синтаксического анализа HTML, прежде чем начать построение и компоновку дерева рендеринга. Он анализирует и отображает контент, полученный из сети, в то время как остальное содержимое продолжает поступать из сети.
Он анализирует и отображает контент, полученный из сети, в то время как остальное содержимое продолжает поступать из сети.
Ссылки: https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/#Resources
https://image.slidesharecdn.com/howbrowserwork-140714233410-phpapp01/95/how-browser-work-19 -638.jpg?cb=1405397055
Пошаговая инструкция работы веб-браузера [последняя] — этап навигации (часть 2) | Автор: Carson
В последнем посте мы знаем, что веб-браузер состоит из всевозможных процессов. Это было статическое представление архитектуры веб-браузера.
Однако браузер не является статическим. Это проактивный ответ на взаимодействие с пользователем. Когда мы взаимодействуем с браузером, разные процессы начинают работать вместе как одна команда и, наконец, отображают перед нами веб-страницу.
В этом посте мы увидим, как процессы работают вместе в навигации.
Навигация — это следующий черный ящик, в который мы углубимся. Ввод — это URL-адрес, а вывод — веб-страница.
Вкратце, 5 шагов:
- Обработка пользовательского ввода
- Отправка запроса URL
- Подготовка процесса рендеринга
- Выполнение навигации
- Рендеринг страницы
- Процесс браузера обрабатывает пользовательский ввод (шаг 1). Кроме того, он управляет другими процессами (шаг 3).
- Сетевой процесс обрабатывает запрос URL (шаг 2).
- Процесс рендеринга фокусируется на рендеринге страницы (этапы 4 и 5).
- поисковый запрос или
- URL-адрес
- Когда процесс рендеринга готов, он отправляет сообщение «фиксация навигации» процессу браузера. Сообщение уведомляет процесс браузера о том, что процесс визуализации готов к анализу данных документа.
- После получения сообщения процесс браузера начинает очистку старого документа.
- Затем процесс браузера отправляет подтверждение процессу визуализации, сообщая ему, что фиксация завершена.
- Тем временем процесс браузера обновляет статус пользовательского интерфейса.
- Процесс визуализации получает подтверждение и начинает получать документ от сетевого процесса.
- Процесс визуализации подтверждает с помощью процесса браузера, что документ зафиксирован.
- Навигация завершена.
- статус безопасности (значок замка рядом с URL-адресом)
- URL-адрес адресной строки
- состояние истории (кнопки «вперед» и «назад»)
- веб-страница (старая страница исчезла и стала белой)
- сохранить историю сеансов на диске, чтобы облегчить восстановление вкладки
- Процесс браузера **обрабатывает пользовательский ввод**, составляет запрос URL.
- Сетевой процесс **отправляет запрос URL**. Навигация запускается.
- Процесс браузера **создает процесс визуализации** после получения ответа сервера. Процесс визуализации находится в состоянии ожидания, а сетевой процесс получил документ.
- Процесс браузера **выполняет навигацию**.
3 900,11 Визуализация страницы В эти процессы браузер включает три этапа:
Навигация начинается с шага 2 к шагу 4.
Точнее, она начинается при отправке запроса URL и заканчивается, когда браузер начинает отображать страницу.
Перед началом навигации процесс браузера анализирует пользовательский ввод. В частности, это поток пользовательского интерфейса в процессе браузера, который выполняет эту работу.
Существуют две возможности, когда пользователь вводит что-либо в адресную строку:
URL с поисковым запросом, а затем инициализирует запрос URL.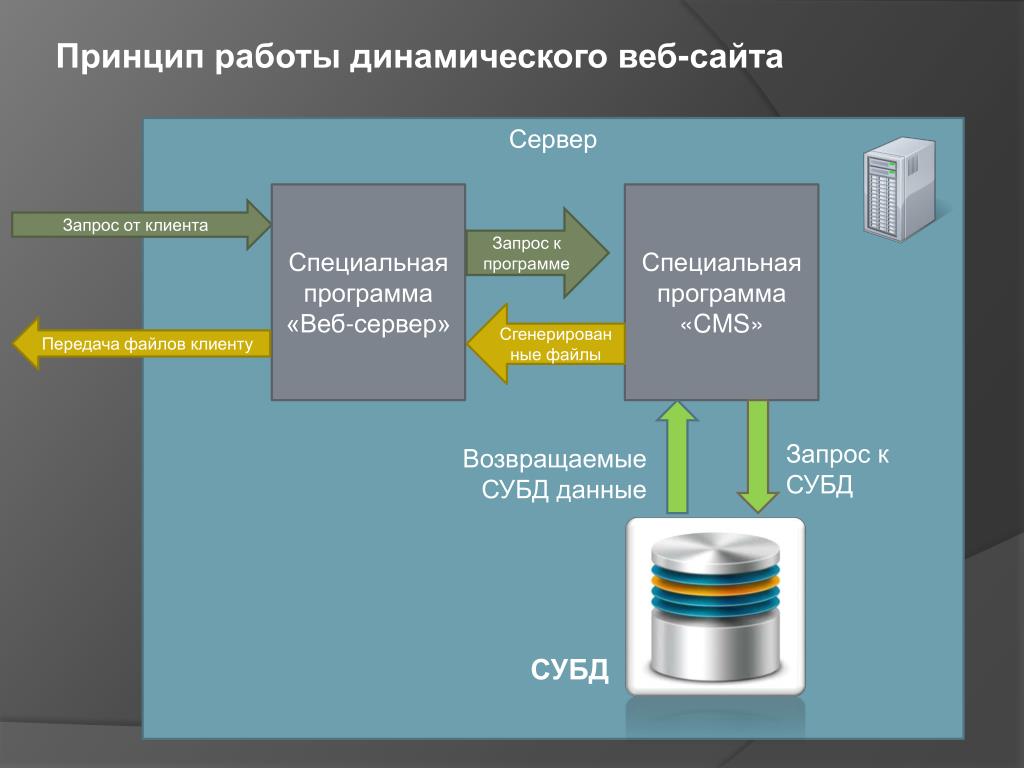
Если это URL, например, medium.com , адресная строка привязывает к нему протокол (HTTP или HTTPS) в зависимости от правил. С протоколом адресная строка теперь имеет заполненный URL-адрес https://medium.com .
Когда пользователь нажимает клавишу возврата, процесс браузера считывает URL-адрес из адресной строки. Он отправляет запрос URL-адреса сетевому процессу через межпроцессное взаимодействие (IPC).
В этот момент запускается событие « beforeunload ». Значок вкладки изменится на индикатор загрузки. Веб-страница остается прежней.
Теперь сетевой процесс получает команду от процесса браузера для обработки запроса URL.
Перед подключением к Интернету сетевой процесс сначала просматривает кэш браузера и проверяет, был ли запрошенный ресурс сохранен локально. Если это так, сетевой процесс возвращает кэшированный ресурс процессу браузера.
Если нет, он начинает подключение к Интернету, инициирует поиск DNS, получает IP-адрес и устанавливает соединение TLS (Transport Layer Security) на основе IP-адреса.
Наконец, он отправляет запрос URL на сервер.
При получении запроса сервер генерирует ответ на основе запроса, включая заголовки ответа, тело ответа и другую информацию. Наконец, сервер отправляет свой ответ сетевому процессу в нашем браузере.
Теперь сетевой процесс начинает разбор заголовков ответов.
Безопасный просмотр и CORB
В этот момент Chrome проверяет домен и данные ответа, пытаясь сопоставить их со своей базой данных вредоносных сайтов.
При совпадении сетевой процесс уведомляет браузер и отображает страницу с предупреждением.
Тем временем выполняется проверка блокировки чтения из разных источников (CORB) для предотвращения атак по сторонним каналам.
В этот момент сетевой процесс может столкнуться с различными случаями.
Случай 1 — перенаправление
В зависимости от разных кодов состояния сетевой процесс делает разные выборы. Один из них — перенаправление.
Если сетевой процесс увидит коды состояния 301 или 302 в заголовках ответов, он инициирует другой запрос URL-адреса на основе правильного адреса. Точный адрес находится в Location в заголовках ответа.
Точный адрес находится в Location в заголовках ответа.
Шаг будет повторен и снова начнется с поиска DNS.
Случай 2 — Content-Type не text/html
Content-Type существует в заголовках ответа, сообщая сетевому процессу тип данных данных в теле ответа.
Сетевой процесс решит, как реагировать на тело ответа.
Если Content-Type имеет значение text/html, он сообщает сетевому процессу, что данные представлены в формате HTML.
Если Content-Type имеет значение application/octet-stream, это означает, что данные представляют собой поток байтов. Обычно браузер воспринимает это как запрос на загрузку и отправляет его своему менеджеру загрузок.
Навигация завершена.
Вариант 3 — код состояния 200 и Content-Type — text/html
Сетевой процесс продолжает навигацию.
Сообщает процессу браузера, что все идет хорошо, и он начнет загрузку данных документа.
После получения этого сообщения процесс браузера переходит к следующему шагу и начинает подготовку процесса визуализации.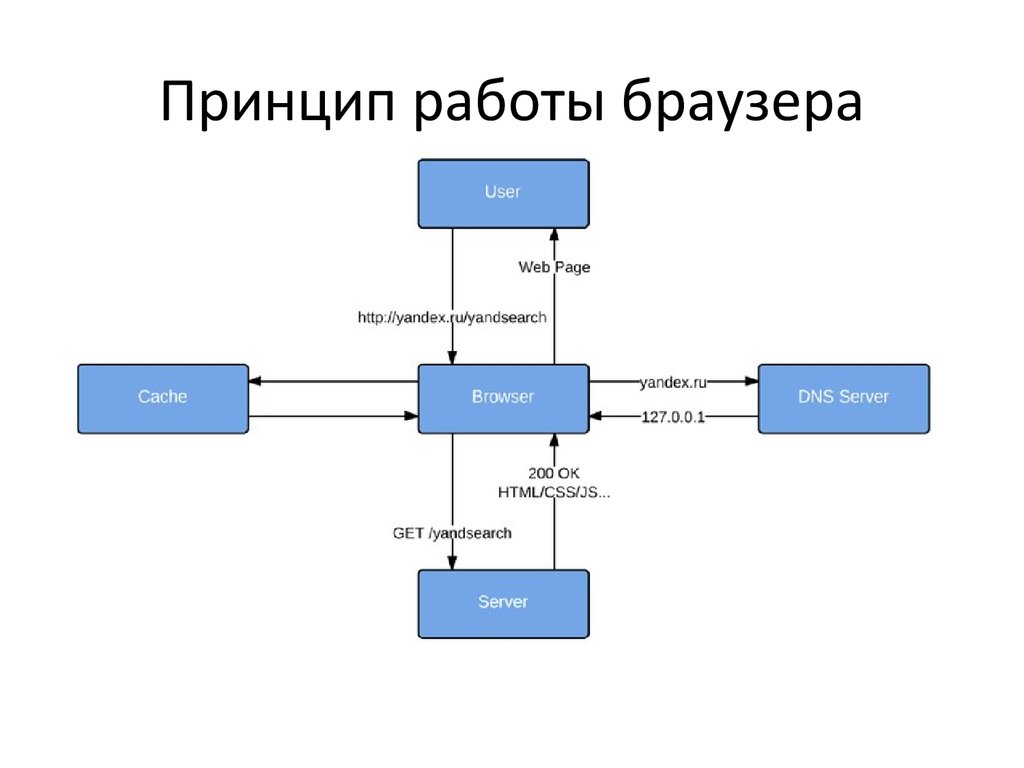
Процесс браузера создает процесс визуализации, ожидая сигнала готовности от процесса визуализации.
Тем временем сетевой процесс непрерывно загружает документ для процесса визуализации.
Когда процесс визуализации находится в состоянии ожидания, начинается следующий шаг.
Процесс браузера и процесс визуализации начинают работать вместе, чтобы заменить старый документ новым.
В частности, он состоит из следующих шагов.

Что касается обновления статуса в процессе браузера, он включает в себя:
Вот почему предыдущее содержимое страницы остается в течение бит, когда мы вводим URL-адрес в адресную строку. До этого момента последняя страница удаляется.
Когда процесс визуализации получает фиксацию, он начинает синтаксический анализ данных, запрашивает загрузку подресурсов и другие задачи. Навигация завершена, и начинается фаза рендеринга страницы.
Процесс визуализации получает подтверждение. Он продолжает синтаксический анализ данных документа, полученных из сетевого процесса, и отображает страницу перед вами.
В конце рендеринга процесс рендеринга сообщает процессу браузера, что рендеринг завершен.
Поток пользовательского интерфейса заменяет счетчик загрузки на своей вкладке значком веб-сайта. Запускается событие `unload`.
В сообщении Google потоки сети и хранилища выполнялись в процессе браузера в 2018 году.
На основании документации Chromium оба были разделены и теперь работают как процессы.
Только когда в среде недостаточно ресурсов, браузер изящно деградирует до предыдущей архитектуры, в которой сеть и хранилище работают как потоки.
Есть пять шагов для отображения страницы:
