Содержание
Разбираемся с SOLID: Инверсия зависимостей / Хабр
Давайте глянем на определение принципа инверсии зависимостей из википедии:
Принцип инверсии зависимостей (англ. dependency inversion principle, DIP) — важный принцип объектно-ориентированного программирования, используемый для уменьшения связанности в компьютерных программах. Входит в пятёрку принципов SOLID.
Формулировка:
A. Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций.
B. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Большинство разработчиков, с которыми мне доводилось общаться, понимают только вторую часть определения. Мол «ну а что тут такого, надо завязывать классы не на конкретную реализацию а на интерфейс». И вроде бы верно, но только кому должен принадлежать интерфейс? Да и почему вообще этот принцип так важен? Давайте разбираться.
Модули
модуль — логически взаимосвязанная совокупность функциональных элементов.

Что бы не было недопонимания, введем немного терминологии. Под модулем мы будем понимать любую функционально связанную часть системы. Например фреймворк мы можем поместить как отдельный независимый модуль, а логику работы с пользователями — в другой.
Модуль, это ничто иное, как элемент декомпозиции системы. Модуль может включать в себя другие модули, формируя что-то вроде дерева. Соответственно можно выделить модули разных уровней:
Здесь стрелочки между модулями показывают кто что использует. Соответственно эти же стрелочки будут показывать нам направления зависимостей между нашими модулями.
И вот пришло время добавить «еще одну кнопочку». И мы понимаем что функционал этой кнопки реализован в модуле E. Мы не раздумывая полезли добавлять то что нам надо, и нам пришлось поменять интерфейс взаимодействия с нашим модулем.
Мы уже хотели закрыть задачу, закоммитить код… но мы же что-то поменяли… пойдем смотреть не сломали ли мы кого. И тут оказывается что из-за наших изменений сломался модуль B. Окей. Починили. А вдруг кто-то кто использует модуль B тоже сломался? И в правду! Модуль A тоже отвалился. Чиним… Коммитимся, пушим. Хорошо если есть тесты, тогда о проблемы мы узнаем быстро и быстро сможем исправить. Но давайте посмотрим правде в глаза, мало кто пишет тесты.
И тут оказывается что из-за наших изменений сломался модуль B. Окей. Починили. А вдруг кто-то кто использует модуль B тоже сломался? И в правду! Модуль A тоже отвалился. Чиним… Коммитимся, пушим. Хорошо если есть тесты, тогда о проблемы мы узнаем быстро и быстро сможем исправить. Но давайте посмотрим правде в глаза, мало кто пишет тесты.
А еще коллеге вашему прилетел баг от тестировщика, мол модуль C сломался. Оказалось что он по неосторожности завязался на ваш модуль E, а вам об этом не сказал. Да еще и модуль этот состоит из кучи файлов, и всем от модуля E что-то нужно. И вот теперь и он лазает по своей части графа зависимостей (потому что ему проще в нем ориентироваться чем вам, не ваша же часть системы) и проклинает вас.
На рисунке выше, оранжевый кружочек обозначает модуль, который мы хотели поправить. А красные — которые пришлось поправить. И не факт что каждый кружок — один класс. Это могут быть целые компоненты. И хорошо если модулей у нас не сильно много и они не сильно пересекаются между собой. А что если у нас каждый кружочек был бы связан с каждым? Это ж чинить все на любой чих. И в итоге простая задача «кнопочку добавить» превращается в рефакторинг куска системы. Как быть?
Это могут быть целые компоненты. И хорошо если модулей у нас не сильно много и они не сильно пересекаются между собой. А что если у нас каждый кружочек был бы связан с каждым? Это ж чинить все на любой чих. И в итоге простая задача «кнопочку добавить» превращается в рефакторинг куска системы. Как быть?
Интерфейсы и позднее связывание
Позднее связывание означает, что объект связывается с вызовом функции только во время исполнения программы, а не на этапе компиляции.
Как известно, интерфейсы определяют некий контракт. И каждый объект, реализующий этот контракт, обязан его соблюдать. Например пишем мы регистрацию пользователей. И вспоминаем требование — пароль пользователя должен быть надежно захэширован на случай утечки данных из базы. Предположим что в данный момент мы не знаем как правильно это делать. И предположим что мы еще не выбрали фреймворк или библиотек для того чтобы делать проект. Безумие, я знаю… Но давайте представим что у нас сейчас нет ничего, кроме логики приложения.
Мы вспоминаем о требовании, но не бросать же нам все? Давайте все же сначала закончим с регистрацией пользователя, а уж потом будем разбираться как чего делать. Надо все же последовательно подходить к работе. А потому вместо того чтобы гуглить «как правильно хэшировать пароль» или разбираться как это делать в нашем фреймворке, давайте сделаем интерфейс PasswordEncoder. Сделав это, мы создадим «контракт». Мол всякий кто решится реализовать этот интерфейс, обязан предоставить надежное и безопасное хэширование пароля. Сам же интерфейс будет до безумия простым:
interface PasswordEncoder
{
public function encode(string $password): string;
}Это именно то, что нам нужно для работы в данный момент времени. Мы не хотим знать как это будет происходить, мы еще не знаем про соль и медленное хэширование. Мы можем сделать сделать заглушку, которая будет на момент разработки возвращать то, что мы запихнули. А уж потом сделаем нормальную реализацию. Точно так же мы можем поступить с отправкой email-а о том что мы успешно зарегистрировали пользователя.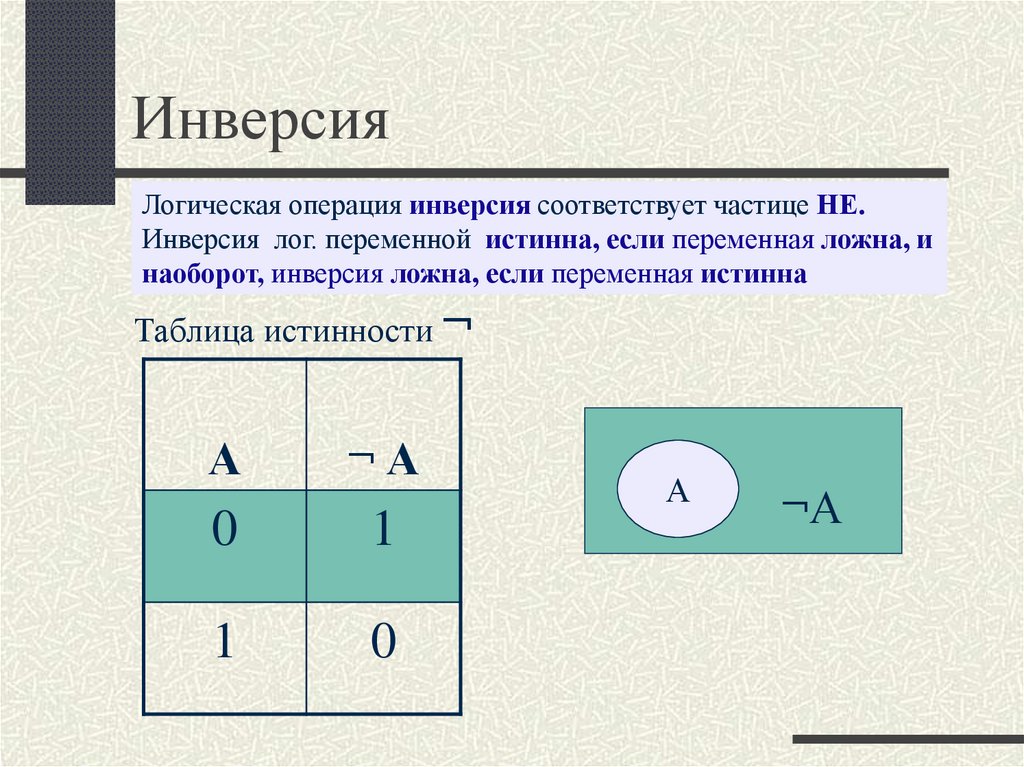 Мы можем даже параллельно посадить еще людей, которые будут эти интерфейсы реализовывать для нас, что бы дело быстрее шло. Красота.
Мы можем даже параллельно посадить еще людей, которые будут эти интерфейсы реализовывать для нас, что бы дело быстрее шло. Красота.
А прелесть в том, что мы можем динамически заменить реализацию. То есть непосредственно перед вызовом регистрации пользователя выбрать, какой энкодер паролей нам надо использовать. Именно это подразумевается под поздним связыванием. Возможность «выбрать» реализацию прямо перед использованием оной.
В языках с динамической системой типов, такой как в PHP, есть еще более простой способ добиться позднего связывания — не использовать тайп хинтинг. От слова совсем. Правда сделав это, мы полностью потеряем статическую (представленную явно в коде) информацию о том, кто что использует. И когда мы что-то поменяем, нам уже не выйдет так просто определить, не сломался ли код. Это как выключить свет и искать парные носки в горе из 99 одного левого и 1-ого правого.
Инверсия зависимостей
Итак, мы уже определились что модуль E все ломает. И ваш коллега захотел защититься от будущих изменений в «чужом» коде. Как никак, он из этого модуля использует только одну функцию.
И ваш коллега захотел защититься от будущих изменений в «чужом» коде. Как никак, он из этого модуля использует только одну функцию.
Для этого в своем модуле C он создал интерфейс, и написал простенький адаптер, который принимает зависимость из нужного модуля и предоставляет доступ только к нужному методу. Теперь если вы что-то поправите — исправить «поломку» можно будет в одном месте.
Причем этот интерфейс расположен на границе модуля C, когда адаптер — на границе модуля E. Мол когда разработчику модуля E взбредет в голову поправить свой код, ему придется починить наш адаптер.
Ну а мы решили что скоро вообще перепишем этот модуль и нам так же стоит защитить наш зависимый модуль. Поскольку мы то используем из модуля E побольше, то интерфейс вашего коллеги нам не годится. Нам нужно реализовать свой. Нам так-же придется реализовать этот интерфейс в рамках модуля E, дабы потом, когда мы будем переписывать его, не забыть подправить реализацию. Взглянем что у нас вышло:
Взглянем что у нас вышло:
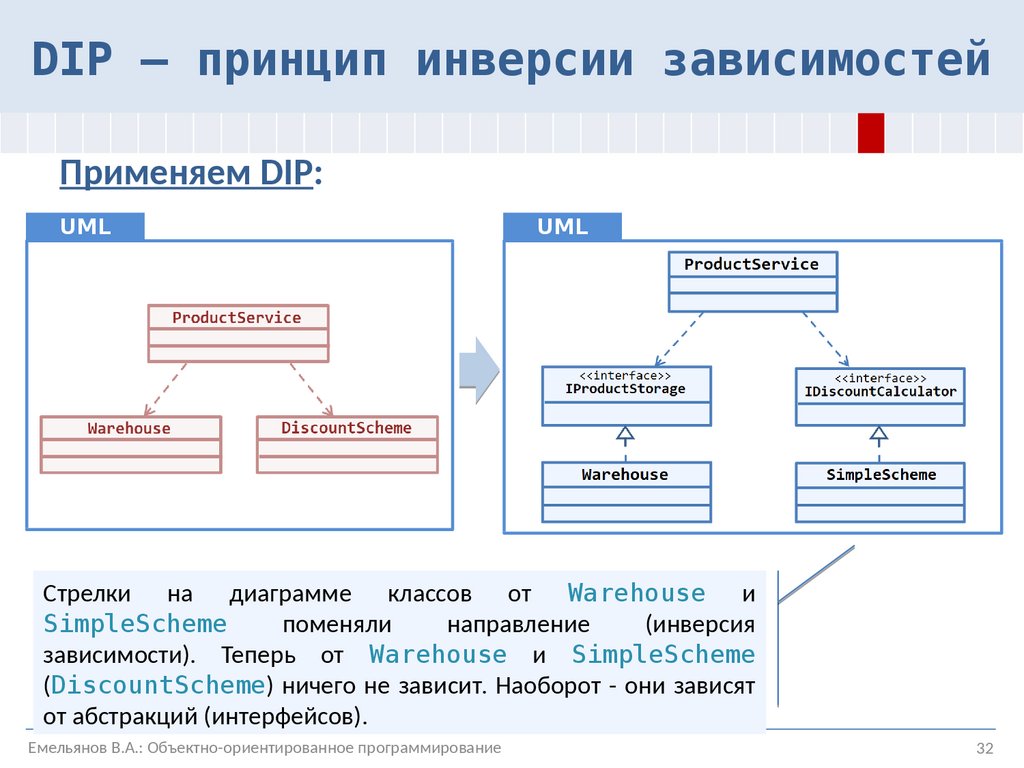
Очень важно то, что у нас два интерфейса, а не один. Если бы мы поместили интерфейс в модуль E, мы бы не устранили зависимости между модулями. Тем более, разным модулям требуются разные возможности. Наша задача изолировать ровно ту часть, которую мы собираемся использовать. Это значительно упростит поддержку.
Так же, если вы посмотрите на картинку выше, вы можете заметить, что поскольку реализация адаптеров лежит в модуле E, теперь этот модуль вынужден реализовывать интерфейсы из других модулей. Тем самым мы инвертировали направление стрелочки, указывающей зависимость. Мы инвертировали зависимости.
Не все зависимости стоят того, чтобы их инвертировать
Модули теперь меньше связаны между собой, чего мы собственно и добивались. Мы не стали делать это для всего, поскольку изменений в других модулях ближайшие пару лет не предвидится. Не стоит волноваться об изменениях в том, что редко меняется. А вот если у вас есть куски системы, которые меняются часто, или вы просто сейчас не знаете что там будет по итогу, имеет смысл защититься от возможных изменений.
А вот если у вас есть куски системы, которые меняются часто, или вы просто сейчас не знаете что там будет по итогу, имеет смысл защититься от возможных изменений.
К примеру, если нам понадобится логгер, мы всегда сможем использовать интерфейс PSR\Logger поскольку он стандартизирован, а такие вещи крайне редко меняются. Затем мы сможем выбрать любой логгер реализующий этот интерфейс на наш вкус:
Как вы можете видеть, благодаря этому интерфейсу, наше приложение все еще не зависит от конкретного логгера. Логгер же зависит от этой абстракции. Но оба «модуля» не зависят друг от друга.
Изоляция
Интерфейсы и позднее связывание позволяют нам «абстрагировать» реализацию логики от посторонних деталей. Мы должны стараться делать модули как можно более изолированными и самодостаточными. Когда все модули независимы, мы получаем возможность и независимо их развивать. А это может быть важно с точки зрения бизнеса.
Часто, когда речь заходит об абстракциях, люди любят доводить все до крайности, забывая зачем изначально все это нужно.
Когда проект планируется поддерживать намного дольше, нежели период поддержки вашего фреймворка, имеет смысл все используемые вещи завернуть в адаптеры. Это своего рода крайность, но в таких условиях она оправдана. Менять фреймворк мы врядли будем, а вот обновить мажорную версию в будущем без боли мы пожалуй бы хотели.
Или к примеру еще одно распространенное заблуждение — абстракция от хранилища. Возможность полной замены базы данных ни в коем случае не является целью реализации этой абстракции, это скорее критерий качества. Вместо этого мы просто должны дать такой уровень изоляции, чтобы наша логика не зависела от возможностей базы данных. Причем это не значит что мы не должны пользоваться этими возможностями.
К примеру мы реализовали поиск в нашей любимой MySQL, но в итоге потребовался более качественная реализация. И мы решили взять ElasticSearch для этого, просто потому, что с ним поиск делать быстрее. Отказываться от MySQL мы так же не можем, но благодаря выстроенной абстракции, мы можем добавить еще одну базу данных, чтобы эффективнее выполнить конкретную задачу.
Или мы делаем очередную соц сеть, и нам надо как-то трекать репосты. Да, мы можем сделать это на MySQL но выйдет неудобно. Тут напрашиваются графовые базы данных. И таких сценариев массы. Мы должны руководствоваться здравым смыслом в первую очередь а не догмами.
На этом пожалуй все. Я уверен что я не все сказал и могут остаться вопросы, потому не стесняемся задавать их в комментариях. Так же я уверен, что знаю отнюдь не все, и буду рад комментариям раскрывающих тему чуть глубже или примеры из жизни, когда инверсия зависимости помогла или могла бы помоч. Ну и если вы нашли опечатки/ошибки в статье — буду рад сообщениям в личку.
Принцип инверсии зависимостей — доходчивое объяснение
Наталия Ништа, PHP Developer, в своей статье на DOU.UA привела очень неординарное пояснение принципа инверсии зависимостей. Представляем его вашему вниманию.
Image by Peter Wolf from Pixabay
В этой статье я попытаюсь рассказать про принцип инверсии зависимостей (Dependency inversion principle, далее DIP). В статье будут упомянуты уровни абстракций, поэтому настоятельно рекомендую ознакомиться с этим понятием заблаговременно.
В статье будут упомянуты уровни абстракций, поэтому настоятельно рекомендую ознакомиться с этим понятием заблаговременно.
Завязка
Чтобы по-человечески разобраться в DIP, надо раскручивать историю с самого начала — с интерфейсов и принципа «проектируйте на уровне интерфейсов, а не реализаций». Не поленитесь, прочтите — это важно.
Вспоминаем, что интерфейс — это средство осуществления взаимного воздействия; общая граница двух отдельно существующих составных частей, посредством которой они обмениваются информацией (честно списала из Википедии). Короче говоря, вот у нас есть механические наручные часы. И все взрослые люди знают, как читать время, используя интерфейс «циферблат со стрелочками». Я понятия не имею, как оно устроено внутри, какие там шестерёнки-колёсики, пружинки и прочее барахло. Мне не надо знать о богатстве внутреннего мира этого чуда инженерии. Я лишь знаю, что все механические часы поддерживают интерфейс «циферблат со стрелочками», и пользуюсь этим. Происходит абстрагирование от деталей реализации.
То есть, интерфейс — это абстракция. Давайте взглянем на это как на концепцию. Когда мы что-то проектируем, по сути нам важно лишь знать составные части системы и что они умеют делать. Как именно они умеют это делать — в момент конструирования никого не колышет. Выражаясь более заумно, нас интересуют уровни абстракции (и перечень элементов, находящихся в каждом уровне), а также их интерфейсы.
Все классы надо рассматривать как абстракции, обладающие своими интерфейсами. Это и значит проектировать на уровне интерфейсов, а не реализаций. Какую именно конструкцию языка в дальнейшем мы используем, Abstract Class или Interface, — по сути также не важно.
Если желаете, можно взглянуть на этот принцип и под другим углом: нам не обязательно знать, с каким конкретным классом (реализацией) мы имеем дело (часы фирмы такой-то, модель такая-то). Достаточно знать, какой у него суперкласс, чтобы пользоваться его методами (Abstract Class или Interface, в нашем примере это циферблат со стрелочками).
Кульминация
А теперь настало время чудес: я приведу наглядный образчик проектирования с кусками кода. Так как моим основным языком программирования является PHP (простите, так вышло), то и примеры я адаптирую под особенности этого языка.
Итак, любой музыкальный инструмент производит звуки (не важно какой именно — шумит себе и всё). Конструируем:
Например, это может быть барабан:
Или гитара, или губная гармошка, да что угодно. Но вот когда мои друзья-хипстеры решают, что мне непременно в жизни не хватает чего-то эдакого и сообщают, что подарят мне неведомый музыкальный инструмент, — во мне пробуждается непоколебимая уверенность, что я таки смогу извлечь из него хоть какой-то звук. Хотя я и не знаю заранее, что же за инструмент это будет.
Вот мы и сконструировали ряд классов, акцентируясь на том, что они умеют (т.е. на интерфейсах).
А теперь давайте немного усложним наш пример и продолжим проектировать на уровне интерфейсов. Мои друзья решили сэкономить и взять, что там они выбрали, в магазине подержанных инструментов. В нём перед продажей все инструменты ремонтируются и натираются до блеска (repair), а также заворачиваются в упаковку индивидуальной формы (pack). Очевидно, что инструменты разных производителей будут по-разному чиниться и по-разному упаковываться. На одном дыхании пишем следующие классы для нашей задачи.
В нём перед продажей все инструменты ремонтируются и натираются до блеска (repair), а также заворачиваются в упаковку индивидуальной формы (pack). Очевидно, что инструменты разных производителей будут по-разному чиниться и по-разному упаковываться. На одном дыхании пишем следующие классы для нашей задачи.
Нам понадобится инструмент, из которого можно извлекать звук, его можно чинить и упаковывать:
Например вот такая губная гармошка фирмы Marys (только что придумала):
А также нам нужен магазин подержанных инструментов, который подготавливает инструменты к продаже:
Набор классов, мягко говоря, весёлый, но для примера нам подойдёт.
Мы не нарушали принципа «проектировать на уровне интерфейсов, а не реализаций». Мы создавали классы, концентрируясь на их способностях. Однако, давайте пристально взглянем на последний класс Pawnshop.
Допустим, по какой-то причине в будущем мы решим изменить интерфейс Instrument, в результате чего набор его методов станет другим. Или наш магазин решит вдобавок к подержанным балалайкам приторговывать ещё и абсолютно новыми инструментами, не нуждающимися ни в упаковке, ни в ремонте. Или ещё что-то произойдёт и конкретный музыкальный инструмент перестанет поддерживать знакомый нам интерфейс. Но в работе Pawnshop мы опираемся на надежду, что только что созданный конкретный объект гарантированно будет субклассом Instrument — это совершенно безрассудно. А сколько таких Pawnshop у нас по всему проекту — страшно даже представить.
Или наш магазин решит вдобавок к подержанным балалайкам приторговывать ещё и абсолютно новыми инструментами, не нуждающимися ни в упаковке, ни в ремонте. Или ещё что-то произойдёт и конкретный музыкальный инструмент перестанет поддерживать знакомый нам интерфейс. Но в работе Pawnshop мы опираемся на надежду, что только что созданный конкретный объект гарантированно будет субклассом Instrument — это совершенно безрассудно. А сколько таких Pawnshop у нас по всему проекту — страшно даже представить.
Почему плохо зависеть от конкретных реализаций? Да потому, что они слишком часто меняются. А концепции (абстракции и интерфейсы) гораздо более живучи.
Развязка
Настало время взглянуть на определение принципа инверсии зависимостей, формулировок которого в ассортименте и количестве:
— Код должен зависеть от абстракций, а не от конкретных классов;
— Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций;
— Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций.
Оба типа модулей должны зависеть от абстракций.
Данный принцип призывает не только проектировать на уровне интерфейсов, но и пресечь беспорядочное использование конструкции new, потому что она создаёт конкретную реализацию. Соответственно, класс, в котором используется new, автоматически становится зависимым от этой конкретной реализации, а не от абстракции. Не смотря даже на то, что мы проектировали на уровне интерфейсов.
Если всё так просто, то почему же этот принцип называется «инверсия зависимостей». Что инвертируется?
Вернёмся к нашим музыкальным инструментам. Хотя мы и строили классы, проектируя их на уровне интерфейсов, всё равно наш класс Pawnshop зависит от конкретных реализаций:
Если мы попытаемся применить DIP, нам нужно будет изолировать все new внутри некоторой ограниченной области — для этого надо использовать какой-то из порождающих паттернов или Dependency Injection. В результате мы можем получить совершенно другую картину.
Например, можем сделать так:
Или так:
Или ещё как-нибудь. Суть в том, что теперь мы получаем объекты гарантированного типа. Новая схема зависимостей будет выглядеть так:
Стрелки, идущие к конечным реализациям (MarysHarmonica, BillysDrum и др.), поменяли своё направление. Мы инвертировали зависимости. До применения принципа DIP у нас присутствовала зависимость Pawnshop от конкретных классов музыкальных инструментов. Теперь же ничто не зависит от конечных реализаций, всё зависит только от абстракций. За исключением наших «изоляторов», куда мы поместили new. Но изменить механизм создания экземпляров внутри этих ограниченных конструкций гораздо легче, чем рыскать по необъятным просторам кода, выискивая, где же мы наплодили наши вновь изменившиеся объекты.
Данный принцип (ограничение new) не применим к библиотечным классам. Потому что мы не будем их менять никогда. А раз эти классы «хронически неизменны», то и связанные с изменениями риски отпадают.
Итак, коротко говоря, принцип DIP призывает:
— проектировать на уровне интерфейсов;
— локализовать создание изменяемых классов (скажи нет беспорядочным new!).
И вот мы вновь убедились, что ООП — это до тошноты логическая и достаточно простая для понимания вещь.
P.S. Использовав конструкцию php <new $firmName . $instrumentName> я экономлю количество строк кода, акцентируя ваше внимание на происходящем внутри метода. Для дотошных: можете представить себе, что вместо этой строки там написано if-if-if.
P.P.S. Да, да «никто не будет писать такого в боевом проекте». Однако, используя упрощённые примеры, я полагаю, мне удалось продемонстрировать работу принципа DIP.
Принцип инверсии зависимостей | DevIQ
Принцип инверсии зависимостей (DIP) гласит, что модули высокого уровня не должны зависеть от модулей низкого уровня; оба должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций . Очень часто при написании программного обеспечения его реализуют таким образом, что каждый модуль или метод конкретно ссылается на своих соавторов, что делает то же самое. В этом типе программирования обычно отсутствуют достаточные уровни абстракции, и в результате получается очень тесно связанная система, поскольку каждый модуль напрямую ссылается на модули более низкого уровня.
Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций . Очень часто при написании программного обеспечения его реализуют таким образом, что каждый модуль или метод конкретно ссылается на своих соавторов, что делает то же самое. В этом типе программирования обычно отсутствуют достаточные уровни абстракции, и в результате получается очень тесно связанная система, поскольку каждый модуль напрямую ссылается на модули более низкого уровня.
Пример 1
Рассмотрим форму пользовательского интерфейса с кнопкой. При нажатии кнопки запускается событие. В рамках события создается новый экземпляр класса уровня бизнес-логики (BLL) и вызывается один из его методов. В методе класса BLL создается новый экземпляр класса уровня доступа к данным (DAL) и вызывается один из его методов. Этот метод, в свою очередь, делает запрос к базе данных.
Результатом такого подхода является то, что все в системе тесно связано с базой данных. Дерево зависимостей идет UI -> BLL -> DAL -> DB, и эти зависимости транзитивны. Все эти классы и методы тесно связаны друг с другом из-за того, что происходит прямое создание экземпляров (помните: New is Glue), хотя вы также увидите такое поведение, если будете использовать статические вызовы методов. Чтобы исправить эту проблему проектирования, нужно применить принцип инверсии зависимостей, который обычно начинается с введения новых интерфейсов.
Дерево зависимостей идет UI -> BLL -> DAL -> DB, и эти зависимости транзитивны. Все эти классы и методы тесно связаны друг с другом из-за того, что происходит прямое создание экземпляров (помните: New is Glue), хотя вы также увидите такое поведение, если будете использовать статические вызовы методов. Чтобы исправить эту проблему проектирования, нужно применить принцип инверсии зависимостей, который обычно начинается с введения новых интерфейсов.
Пример 2
Рассмотрим форму пользовательского интерфейса с кнопкой. При нажатии кнопки запускается событие. В ответ на это событие частный член формы, тип которого является просто интерфейсом, вызывает один из своих методов. Ключевое слово «новое» отсутствует в обработчике событий щелчка. Реализация интерфейса предоставляется при создании формы с помощью процесса, известного как внедрение зависимостей. Аналогичным образом, если этот метод обеспечивает ключевую бизнес-логику, но также требует доступа к системному уровню персистентности, он также может указывать (явно в своем конструкторе) один или несколько интерфейсов, от которых он зависит, которые могут включать реализации шаблона репозитория. В методе класса бизнес-логики также не будет вызовов статических методов или «новых» ключевых слов.
В методе класса бизнес-логики также не будет вызовов статических методов или «новых» ключевых слов.
Переход от традиционной N-уровневой архитектуры, ориентированной на данные, к N-уровневой архитектуре, в большей степени ориентированной на предметную область, и, возможно, к полному применению предметно-ориентированного проектирования может дать большие преимущества в плане удобства сопровождения проектов. Конечным результатом является слабосвязанная, модульная и легко тестируемая система.
См. также
Принцип явных зависимостей
Голливудский принцип
Ссылки
New is Glue
Архитектура N-уровневых решений на C# (Pluralsight)
Сплошные принципы объектно-ориентированного дизайна (Pluralsight)
Основы дизайна, управляемые доменом (Pluralsight)
Редактировать эту страницу на Github
Prev
Правило Бой Скаут
Следующая
Не повторяйте себя
000000 (ДИП) | by Kedren Villena
Когда я узнал о S. O.L.I.D. Принципы объектно-ориентированного программирования (ООП), инверсия зависимостей была для меня самой сложной для полного понимания. Что сбивает меня с толку, так это то, что гласит принцип:
O.L.I.D. Принципы объектно-ориентированного программирования (ООП), инверсия зависимостей была для меня самой сложной для полного понимания. Что сбивает меня с толку, так это то, что гласит принцип:
Модули высокого уровня не должны зависеть от модулей низкого уровня . Оба должны зависеть от абстракций.
Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Что такое модулей высокого уровня и что такое модулей низкого уровня ? Что такое абстракции и почему абстракции не должны зависеть от деталей?
Чтобы лучше объяснить это, давайте начнем с простого приложения. Приложение, которое мы собираемся создать, представляет собой простое приложение-калькулятор. (Код реализован на C#).
Базовая реализация Калькулятора может быть такой же простой, как приведенная ниже:
Приведенный выше простой класс Калькулятора с двумя операциями работает, но что, если мы хотим добавить новую операцию, скажем, Умножение? Добавление новой операции в наш текущий класс Calculator изменит текущий класс.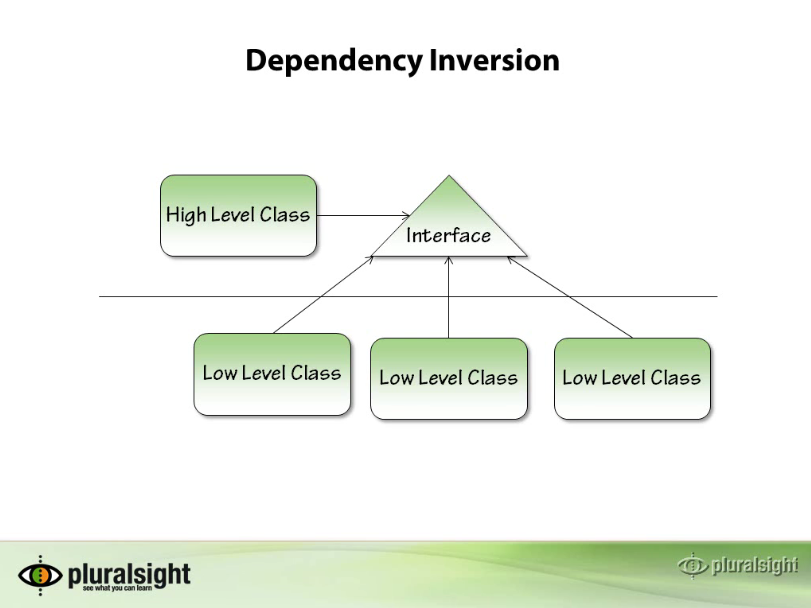 Эта модификация сломает букву «О» в S.O.L.I.D. который является принципом открытия-закрытия (OCP) . OCP утверждает, что:
Эта модификация сломает букву «О» в S.O.L.I.D. который является принципом открытия-закрытия (OCP) . OCP утверждает, что:
Объекты (или программные объекты) должны быть открыты для расширения, но закрыты для модификации.
Итак, как мы можем добавить новые операции (или «расширить») наш класс Calculator, фактически не внося в него изменений кода (или «модификаций»)? Вот где принцип инверсии зависимостей (DIP) вступает в игру.
Давайте поговорим о втором пункте, который гласит DIP:
Абстракции не должны зависеть от деталей . Детали должны зависеть от абстракций .
Прямо сейчас мы хотим добавить новую операцию в наш класс Calculator. Глядя на предыдущие методы Добавьте и Вычтите , мы можем с уверенностью сказать, что мы действительно можем создать интерфейс или контракт, который использует наш Калькулятор.
Приведенный выше интерфейс на самом деле является «абстракцией», которую использует наш Калькулятор. «Детали» — это фактическая реализация интерфейса.
Теперь давайте реорганизуем наш класс Calculator, чтобы фактически использовать ICalculatorOperation. Мы собираемся использовать технику Dependency Injection через Constructor Injection. Чтобы дать краткий обзор того, что такое внедрение зависимостей, это когда зависимости объекта предоставляются фреймворком или службой. Это реализация принципа инверсии зависимостей.
Чтобы лучше понять это, посмотрите приведенный ниже фрагмент кода после рефакторинга (прочитайте также комментарии в коде):
Чтобы добавить наши предыдущие операции «Добавить» и «Вычесть», нам просто нужно создать два объекта, которые реализуют нашу операцию ICalculatorOperation. interface/contract:
С нашим текущим кодом теперь легко «расширить» и добавить новые операции в наш класс Calculator, фактически не «модифицируя» его.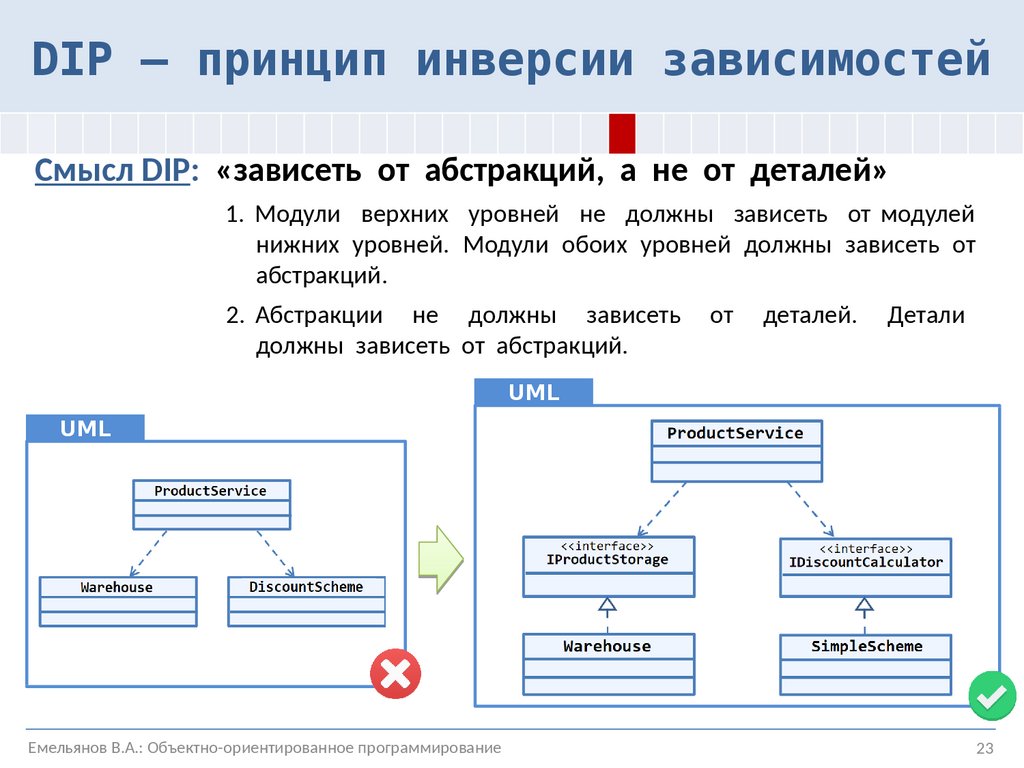 Давайте попробуем добавить две новые операции:
Давайте попробуем добавить две новые операции:
Вот пример кода, показывающего, как работает наше простое приложение:
С нашим текущим кодом теперь легче объяснить Принцип инверсии зависимостей (DIP) . Мы использовали метод Dependency Injection (DI) , который является реализацией DIP, чтобы фактически применить принцип Open-Close (OCP) . Наш класс Calculator теперь полагается на нашу абстракцию, которая является ICalculatorOperation, а не на конкретные реализации ICalculatorOperation.
Теперь поговорим о первом операторе в DIP:
Модули высокого уровня не должны зависеть от модулей низкого уровня . Оба должны зависеть от абстракций .
Применяя пример приложения выше, мы теперь знаем, что модуль высокого уровня , на который мы ссылаемся, является классом Calculator , а низкоуровневого модулями являются разные модули . классы ( AddCalculatorOperation , SubtractCalculatorOperation , MultiplyCalculatorOperation , DivideCalculatorOperation ), которые реализуют ICalculatorOperation , которая является нашей абстракцией .
классы ( AddCalculatorOperation , SubtractCalculatorOperation , MultiplyCalculatorOperation , DivideCalculatorOperation ), которые реализуют ICalculatorOperation , которая является нашей абстракцией .
Но почему они называются высокого уровня и низкого уровня ? Чтобы легко объяснить это, нам нужно создать диаграмму UML для этого:
Простой UML для нашего Калькулятора
Как вы можете видеть, Калькулятор находится на выше части диаграммы, в то время как Операции Калькулятора находятся на нижняя часть диаграммы. Для дальнейшего выделения:
Ключевые моменты:
- Внедрение зависимостей — это реализация принципа инверсии зависимостей.
- Одним из способов достижения принципа открытия-закрытия является использование принципа инверсии зависимостей.
- Модули высокого уровня в DIP — это модули, которые появляются в верхней части диаграммы UML и зависят от уровня абстракции.