Содержание
примеры для различных CMS, правила, рекомендации
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года — robots.txt.
Что такое Robots.txt?
Robots.txt — текстовый файл на сайте, содержащий инструкции для роботов какие страницы разрешены для индексации, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировок
- страницы авторизации и регистрации
- сравнения товаров
Как создать и добавить Robots.
 txt на сайт?
txt на сайт?
Robots.txt обычный текстовый файл, который можно создать в блокноте, следуя синтаксису стандарта, который будет описан ниже. Для одного сайта нужен только один такой файл.
Файл нужно добавить в корневой каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Но если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной индексирующий робот;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.
 Картинок;
Картинок; - Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.Маркета;
- Googlebot-Mobile —индексатор мобильной версии.
 Картинок;
Картинок;Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow — директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
Примечание: Если данная директива будет указана пустой, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / — это закроет весь сайт от индексации.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site. com/sitemap1.xml
com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указания главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которым он доступен. Указывать Host необходимо в секции для роботов Яндекса:
User-agent: Yandex
Disallow: /site/
Host: site.ru
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param: p1[&p2&p3&p4&. .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (актуально для ресурсов с большим количеством страниц). Чтобы снизить нагрузку на сервер, можно воспользоваться директивой Crawl-delay.
Параметром для Crawl-delay является время в секундах, которое указывает роботам, что страницы следует скачивать с сайта не чаще одного раза в указанный период.
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: /site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- В директивах «Allow», «Disallow» можно указывать только 1 параметр
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.
 txt
txt
При указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*.php # запрещает ‘/store/ex.php’ и ‘/store/test/ex1.php’
Disallow: /*tpl # запрещает не только ‘/tpl’, но и ‘/tpl/user’
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: /site$ # запрещено для индексации ‘/site’, но не запрещено’/ex.css’
User-agent: *
Disallow: /site # запрещено для индексации и ‘/site’, и ‘/site.css’
User-agent: *
Disallow: /site$ # запрещен к индексации только ‘/site’
Disallow: /site*$ # так же, как ‘Disallow: /site’ запрещает и /site. css и /site
css и /site
Особенности настройки robots.txt для Яндекса
Особенностями настройки роботса для Яндекса является только наличие директории Host в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Yandex
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Disallow: */css
Host: www.site.com
В данном случаем директива Host указывает роботам Яндекса, что главным зеркалом сайта является www.site.com (но данная директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность лишь состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *. js
js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:
Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексацией сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те страницы, которые могут повредить хорошему ранжированию ресурса в выдаче.
Пример настройки роботс для WordPress
Правильный robots.txt для WordPress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots. txt для CMS 1C-Bitrix:
txt для CMS 1C-Bitrix:
User-Agent: Yandex
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo. png
png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site. ru
ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index. php
php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out. php
php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots. txt для Джумлы должен быть составлен таким образом:
txt для Джумлы должен быть составлен таким образом:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ru/sitemap.xml
site.ru/sitemap.xml
Как создать правильный файл robots.txt, настройка, директивы
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.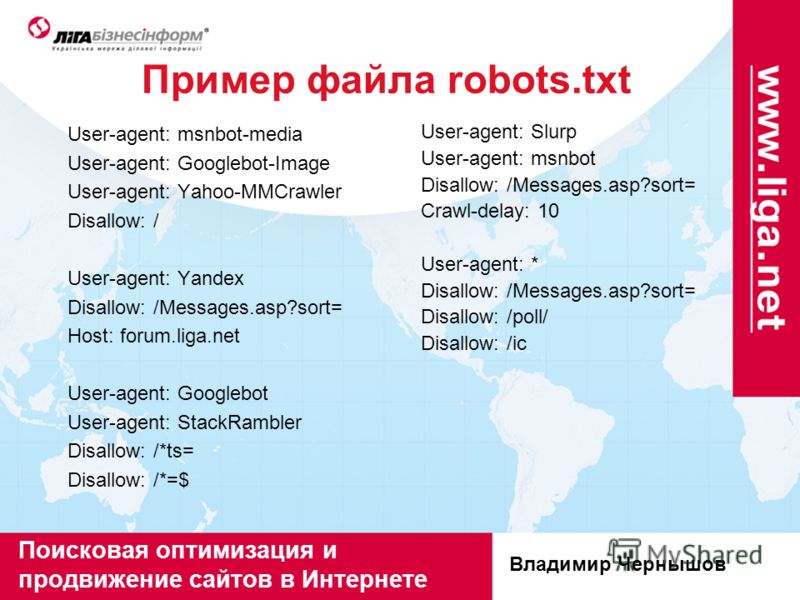
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots. txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots. txt:
txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots. txt в правильной сортировке:
txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots. txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots. txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
 txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]; txt может трактоваться как полностью разрешающий;
txt может трактоваться как полностью разрешающий;Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
«Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots. txt.
txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.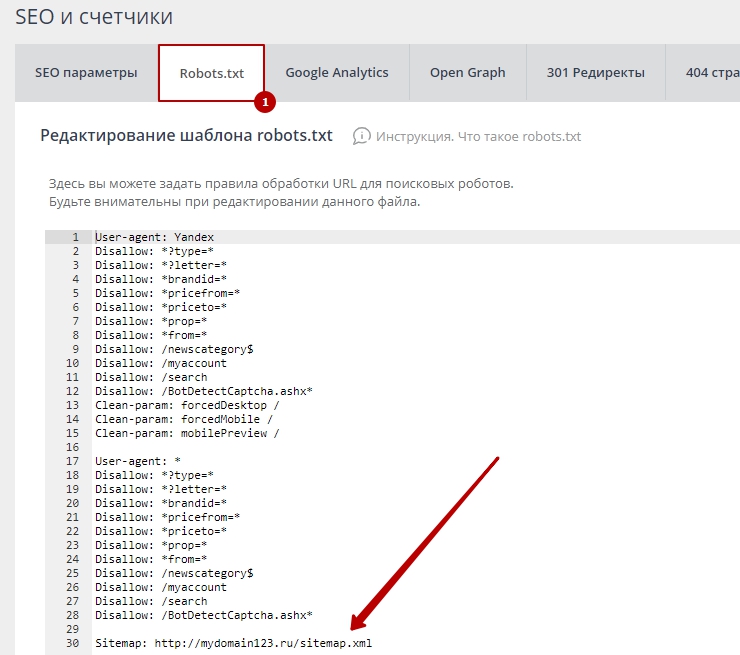
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots. txt запретить индексацию сайта кроме некоторых страниц:
txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.
 ru
www.mysite.ru
ru
www.mysite.ruРоботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.
 txt sitemap
txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..
 &parmn] [Путь]
&parmn] [Путь]Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Пример файла txt
Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.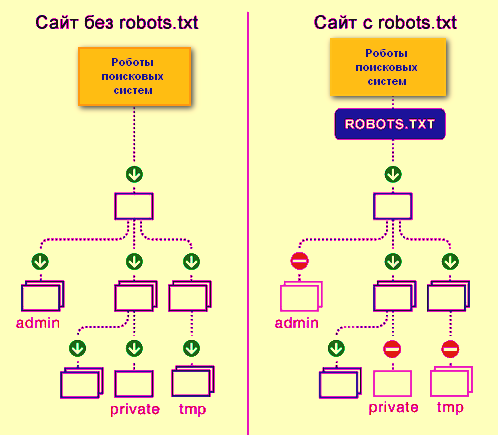
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду
.
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает все боты
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц
.
Что, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots. txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
.
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью
Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter
.
Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.
# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила. Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Пример файла txt
Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду
.
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает все боты
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц
 Установив значение
Установив значение .
Что, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
.
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example. com/users.xls
 com/users.xls
com/users.xls Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter
.
Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.
# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила.