Содержание
PostgreSQL — популярная свободная объектно-реляционная система управления базами данных
PostgreSQL — это популярная свободная объектно-реляционная система управления базами данных. PostgreSQL базируется на языке SQL и поддерживает многочисленные возможности.
Преимущества PostgreSQL:
- поддержка БД неограниченного размера;
- мощные и надёжные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования и поддержка загрузки C-совместимых модулей;
- наследование;
- легкая расширяемость.
Текущие ограничения PostgreSQL:
- Нет ограничений на максимальный размер базы данных
- Нет ограничений на количество записей в таблице
- Нет ограничений на количество индексов в таблице
- Максимальный размер таблицы — 32 Тбайт
- Максимальный размер записи — 1,6 Тбайт
- Максимальный размер поля — 1 Гбайт
- Максимум полей в записи250—1600 (в зависимости от типов полей)
Особенности PostgreSQL:
Функции в PostgreSQL являются блоками кода, исполняемыми на сервере, а не на клиенте БД. Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием различных языков программирования. PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса. Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя. Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие.
Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием различных языков программирования. PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса. Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя. Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие.
Триггеры в PostgreSQL определяются как функции, инициируемые DML-операциями. Например, операция INSERT может запускать триггер, проверяющий добавленную запись на соответствия определённым условиям. При написании функций для триггеров могут использоваться различные языки программирования. Триггеры ассоциируются с таблицами. Множественные триггеры выполняются в алфавитном порядке.
Механизм правил в PostgreSQL представляет собой механизм создания пользовательских обработчиков не только DML-операций, но и операции выборки. Основное отличие от механизма триггеров заключается в том, что правила срабатывают на этапе разбора запроса, до выбора оптимального плана выполнения и самого процесса выполнения. Правила позволяют переопределять поведение системы при выполнении SQL-операции к таблице.
Индексы в PostgreSQL следующих типов: B-дерево, хэш, R-дерево, GiST, GIN. При необходимости можно создавать новые типы индексов, хотя это далеко не тривиальный процесс.
Многоверсионность поддерживается в PostgreSQL — возможна одновременнуя модификация БД несколькими пользователями с помощью механизма Multiversion Concurrency Control (MVCC). Благодаря этому соблюдаются требования ACID, и практически отпадает нужда в блокировках чтения.
Расширение PostgreSQL для собственных нужд возможно практически в любом аспекте. Есть возможность добавлять собственные преобразования типов, типы данных, домены (пользовательские типы с изначально наложенными ограничениями), функции (включая агрегатные), индексы, операторы (включая переопределение уже существующих) и процедурные языки.
Есть возможность добавлять собственные преобразования типов, типы данных, домены (пользовательские типы с изначально наложенными ограничениями), функции (включая агрегатные), индексы, операторы (включая переопределение уже существующих) и процедурные языки.
Наследование в PostgreSQL реализовано на уровне таблиц. Таблицы могут наследовать характеристики и наборы полей от других таблиц (родительских). При этом данные, добавленные в порождённую таблицу, автоматически будут участвовать (если это не указано отдельно) в запросах к родительской таблице.
Использование в веб-проектах
В разработке простых сайтов PostgreSQL используется несколько реже, чем MySQL / MariaDB, но всё же эта пара с заметным отрывом опережает по частоте использования остальные системы управления базами данных. При этом в разработке сложных сайтов и веб-приложений PostgreSQL опережает по использованию MySQL и MariaDB. Большинство фреймворков (например, Ruby on Rails, Yii, Symfony, Django) поддерживают использование PostgreSQL в разработке.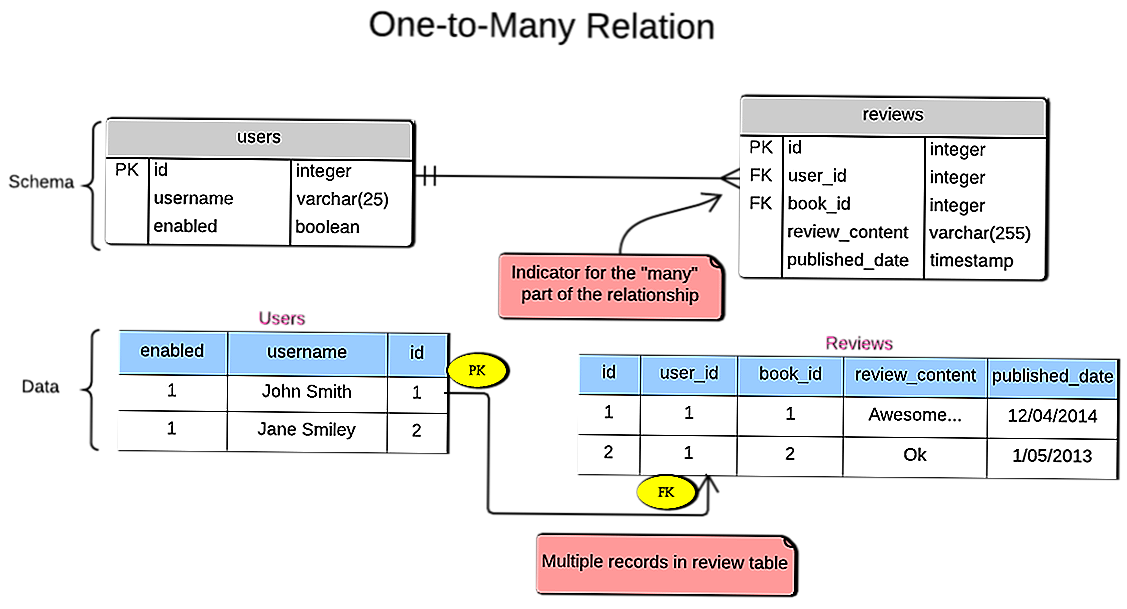
PostgreSQL : Документация: 9.6: 65.6. Компоновка страницы базы данных : Компания Postgres Professional
В данном разделе рассматривается формат страницы, используемый в таблицах и индексах PostgreSQL.[15] Последовательности и таблицы TOAST форматируются как обычные таблицы.
В дальнейшем подразумевается, что байт содержит 8 бит. В дополнение, термин элемент относится к индивидуальному значению данных, которое хранится на странице. В таблице элемент — это строка; в индексе — элемент индекса.
Каждая таблица и индекс хранятся как массив страниц фиксированного размера (обычно 8 kB, хотя можно выбрать другой размер страницы при компиляции сервера). В таблице все страницы логически эквивалентны, поэтому конкретный элемент (строка) может храниться на любой странице. В индексах первая страница обычно резервируется как метастраница, хранящая контрольную информацию, а внутри индекса могут быть разные типы страниц, в зависимости от метода доступа индекса.
Таблица 65.2 показывает общую компоновку страницы. Каждая страница имеет пять частей.
Таблица 65.2. Общая компоновка страницы
| Элемент | Описание |
|---|---|
| Данные заголовка страницы | Длина — 24 байта. Содержит общую информацию о странице, включая указатели свободного пространства. |
| Данные идентификаторов элементов | Массив идентификаторов, указывающих на фактические элементы. Каждый идентификатор представляет собой пару «смещение, длина» и занимает 4 байта. |
| Свободное пространство | Незанятое пространство. Новые идентификаторы элементов размещаются с начала этой области, сами новые элементы — с конца. |
| Элементы | Сами элементы данных как таковые. |
| Специальное пространство | Специфические данные метода доступа. Для различных методов хранятся различные данные. Для обычных таблиц таких данных нет. Для обычных таблиц таких данных нет. |
Первые 24 байта каждой страницы образуют заголовок страницы (PageHeaderData). Его формат подробно описан в Таблице 65.3. В первом поле отслеживается самая последняя запись в WAL, связанная с этой страницей. Второе поле содержит контрольную сумму страницы, если включён режим data checksums. Затем идёт двухбайтовое поле, содержащее биты флагов. За ним следуют три двухбайтовых целочисленных поля (pd_lower, pd_upper и pd_special). Они содержат смещения в байтах от начала страницы до начала незанятого пространства, до конца незанятого пространства и до начала специального пространства. В следующих 2 байтах заголовка страницы, в поле pd_pagesize_version, хранится размер страницы и индикатор версии. Начиная с PostgreSQL 8.3, используется версия 4; в PostgreSQL 8.1 и 8.2 использовалась версия 3; в PostgreSQL 8.0 — версия 2; в PostgreSQL 7.3 и 7.4 — версия 1; в предыдущих выпусках — версия 0. (Основная структура страницы и формат заголовка почти во всех этих версиях одни и те же, но структура заголовка строк в куче изменялась.) Размер страницы присутствует в основном только для перекрёстной проверки; возможность использовать в одной инсталляции разные размеры страниц не поддерживается. Последнее поле подсказывает, насколько вероятна возможность получить выигрыш, произведя очистку страницы: оно отслеживает самый старый XMAX на странице, не подвергавшийся очистке.
(Основная структура страницы и формат заголовка почти во всех этих версиях одни и те же, но структура заголовка строк в куче изменялась.) Размер страницы присутствует в основном только для перекрёстной проверки; возможность использовать в одной инсталляции разные размеры страниц не поддерживается. Последнее поле подсказывает, насколько вероятна возможность получить выигрыш, произведя очистку страницы: оно отслеживает самый старый XMAX на странице, не подвергавшийся очистке.
Таблица 65.3. Данные заголовка страницы (PageHeaderData)
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| pd_lsn | PageXLogRecPtr | 8 байт | LSN: Следующий байт после последнего байта записи xlog для последнего изменения на этой странице |
| pd_checksum | uint16 | 2 байта | Контрольная сумма страницы |
| pd_flags | uint16 | 2 байта | Биты признаков |
| pd_lower | LocationIndex | 2 байта | Смещение до начала свободного пространства |
| pd_upper | LocationIndex | 2 байта | Смещение до конца свободного пространства |
| pd_special | LocationIndex | 2 байта | Смещение до начала специального пространства |
| pd_pagesize_version | uint16 | 2 байта | Информация о размере страницы и номере версии компоновки |
| pd_prune_xid | TransactionId | 4 байта | Самый старый неочищенный идентификатор XMAX на странице или ноль при отсутствии такового |
Всю подробную информацию можно найти в src/include/storage/bufpage.. h
h
За заголовком страницы следуют идентификаторы элемента (ItemIdData), каждому из которых требуется 4 байта. Идентификатор элемента содержит байтовое смещение до начала элемента, его длину в байтах и несколько битов атрибутов, которые влияют на его интерпретацию. Новые идентификаторы элементов размещаются по мере необходимости от начала свободного пространства. Количество имеющихся идентификаторов элементов можно определить через значение pd_lower, которое увеличивается при добавлении нового идентификатора. Поскольку идентификатор элемента никогда не перемещается до тех пор, пока он не освобождается, его индекс можно использовать в течение длительного периода времени, чтобы ссылаться на элемент, даже когда сам элемент перемещается по странице для уплотнения свободного пространства. Фактически каждый указатель на элемент (ItemPointer, также известный как CTID), созданный PostgreSQL, состоит из номера страницы и индекса идентификатора элемента.
Сами элементы хранятся в пространстве, выделяемом в направлении от конца к началу незанятого пространства. Точная структура меняется в зависимости от того, каким будет содержание таблицы. Как таблицы, так и последовательности используют структуру под названием HeapTupleHeaderData, которая описывается ниже.
Последний раздел является «особым разделом», который может содержать всё, что необходимо методу доступа для хранения. Например, индексы-B-деревья хранят ссылки на страницы слева и справа, равно как и некоторые другие данные, соответствующие структуре индекса. Обычные таблицы не используют особый раздел вовсе (что указывается установкой значения pd_special равным размеру страницы).
Все строки таблицы имеют одинаковую структуру. Они включают заголовок фиксированного размера (занимающий 23 байта на большинстве машин), за которым следует необязательная битовая карта пустых значений, необязательное поле идентификатора объекта и данные пользователя. Подробное описание заголовка представлено в Таблице 65.4. Актуальные пользовательские данные (столбцы строки) начинаются после смещения, заданного в
Подробное описание заголовка представлено в Таблице 65.4. Актуальные пользовательские данные (столбцы строки) начинаются после смещения, заданного в t_hoff, которое должно всегда быть кратным величине MAXALIGN для платформы. Битовая карта пустых значений имеется тогда, когда бит HEAP_HASNULL установлен в значении t_infomask. В случае наличия, она начинается сразу после фиксированного заголовка и занимает достаточно байтов, чтобы иметь один бит на столбец (т. е. t_natts битов всего). В этом списке битов установленный в единицу бит означает непустое значение, а установленный в ноль соответствует пустому значению. Когда битовая карта отсутствует, все столбцы считаются непустыми. Идентификатор объекта присутствует, если только бит HEAP_HASOID установлен в значении t_infomask. Если он есть, он расположен сразу перед началом t_hoff. Любое заполнение, необходимое для того, чтобы сделать t_hoff кратным MAXALIGN, будет расположено между битовой картой пустых значений и идентификатором объекта. (Это в свою очередь гарантирует, что идентификатор объекта будет правильно выровнен.)
(Это в свою очередь гарантирует, что идентификатор объекта будет правильно выровнен.)
Всю подробную информацию можно найти в src/include/access/htup_details.h.
Интерпретировать текущие данные можно только с использованием информации, полученной из других таблиц, в основном из pg_attribute. Ключевыми значениями, необходимыми для определения расположения полей, являются attlen и attalign. Не существует способа непосредственного получения заданного атрибута, кроме случая, когда имеются только поля фиксированной длины и при этом нет значений NULL. Все эти особенности учитываются в функциях heap_getattr, fastgetattr и heap_getsysattr.
Чтобы прочитать данные, необходимо просмотреть каждый атрибут по очереди. В первую очередь нужно проверить, является ли значение поля пустым согласно битовой карте пустых значений. Если это так, можно переходить к следующему полю. Затем следует убедиться, что выравнивание является верным. Если это поле фиксированной ширины, берутся просто все его байты. Если это поле переменной длины (attlen = -1), всё несколько сложнее. Все типы данных с переменной длиной имеют общую структуру заголовка
Если это поле фиксированной ширины, берутся просто все его байты. Если это поле переменной длины (attlen = -1), всё несколько сложнее. Все типы данных с переменной длиной имеют общую структуру заголовка struct varlena, которая включает общую длину сохранённого значения и некоторые биты флагов. В зависимости от установленных флагов, данные могут храниться либо локально, либо в таблице TOAST. Также, возможно сжатие данных (см. Раздел 65.2).
[15] Фактически индексные методы доступа не нуждаются в этом формате страниц. Все существующие индексные методы в действительности используют этот основной формат, но данные, хранящиеся в индексных метастраницах обычно не следуют правилам компоновки.
postgresql — Очень большой размер таблицы, но с несколькими строками
У меня есть эта таблица только с 1 миллионом строк, но размер 49 ГБ
Я запустил pg_column_size для каждого столбца и получил это
Размер индекса Uniq:
- index_items_on_profile_id_and_code_and_sku: 2,64 ГБ 9001 4
- unique_null_sku_code: 6,36 МБ
Как я могу понять причину такого большого размера?
PG STAT USER TABLE
выберите * из pg_stat_user_tables;
SCHEMA DB
create_table "items", force: :cascade do |t|
t. bigint "profile_id", ноль: ложь
t.bigint "идентификатор_категории"
t.string "название"
t.string "изображение"
t.string "код"
t.string "артикул"
t.string "родительский_код"
t.datetime "created_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.datetime "updated_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.string "бренд"
t.decimal "цена"
t.string "статус сканирования"
t.decimal "расходовать", по умолчанию: "0.0"
t.decimal "продажи", по умолчанию: "0.0"
t.string "производитель"
t.string "статус", по умолчанию: "", ноль: ложь
t.string "изображения", массив: true
t.string "соответствие_соответствию"
t.json "список_приемлемости"
t.boolean "активный", по умолчанию: true, null: false
t.index "profile_id, code, ((sku IS NULL))", name: "unique_null_sku_code", уникальный: true, где: "(sku IS NULL)"
t.index ["profile_id", "code", "sku"], name: "index_items_on_profile_id_and_code_and_sku", уникально: true
конец
bigint "profile_id", ноль: ложь
t.bigint "идентификатор_категории"
t.string "название"
t.string "изображение"
t.string "код"
t.string "артикул"
t.string "родительский_код"
t.datetime "created_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.datetime "updated_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.string "бренд"
t.decimal "цена"
t.string "статус сканирования"
t.decimal "расходовать", по умолчанию: "0.0"
t.decimal "продажи", по умолчанию: "0.0"
t.string "производитель"
t.string "статус", по умолчанию: "", ноль: ложь
t.string "изображения", массив: true
t.string "соответствие_соответствию"
t.json "список_приемлемости"
t.boolean "активный", по умолчанию: true, null: false
t.index "profile_id, code, ((sku IS NULL))", name: "unique_null_sku_code", уникальный: true, где: "(sku IS NULL)"
t.index ["profile_id", "code", "sku"], name: "index_items_on_profile_id_and_code_and_sku", уникально: true
конец
 bigint "profile_id", ноль: ложь
t.bigint "идентификатор_категории"
t.string "название"
t.string "изображение"
t.string "код"
t.string "артикул"
t.string "родительский_код"
t.datetime "created_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.datetime "updated_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.string "бренд"
t.decimal "цена"
t.string "статус сканирования"
t.decimal "расходовать", по умолчанию: "0.0"
t.decimal "продажи", по умолчанию: "0.0"
t.string "производитель"
t.string "статус", по умолчанию: "", ноль: ложь
t.string "изображения", массив: true
t.string "соответствие_соответствию"
t.json "список_приемлемости"
t.boolean "активный", по умолчанию: true, null: false
t.index "profile_id, code, ((sku IS NULL))", name: "unique_null_sku_code", уникальный: true, где: "(sku IS NULL)"
t.index ["profile_id", "code", "sku"], name: "index_items_on_profile_id_and_code_and_sku", уникально: true
конец
bigint "profile_id", ноль: ложь
t.bigint "идентификатор_категории"
t.string "название"
t.string "изображение"
t.string "код"
t.string "артикул"
t.string "родительский_код"
t.datetime "created_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.datetime "updated_at", по умолчанию: -> { "CURRENT_TIMESTAMP" }, ноль: ложь
t.string "бренд"
t.decimal "цена"
t.string "статус сканирования"
t.decimal "расходовать", по умолчанию: "0.0"
t.decimal "продажи", по умолчанию: "0.0"
t.string "производитель"
t.string "статус", по умолчанию: "", ноль: ложь
t.string "изображения", массив: true
t.string "соответствие_соответствию"
t.json "список_приемлемости"
t.boolean "активный", по умолчанию: true, null: false
t.index "profile_id, code, ((sku IS NULL))", name: "unique_null_sku_code", уникальный: true, где: "(sku IS NULL)"
t.index ["profile_id", "code", "sku"], name: "index_items_on_profile_id_and_code_and_sku", уникально: true
конец
ЗАПРОС РАЗМЕРА КОЛОНЦЫ PG
выбрать
pg_size_pretty(pg_relation_size('items')) как pg_relation_size,
pg_size_pretty(pg_total_relation_size('items')) как pg_total_relation_size,
pg_size_pretty (pg_indexes_size('items')) как pg_indexes_size,
pg_size_pretty (pg_tablespace_size («элементы»)) как pg_tablespace_size
ОТ (
выбирать
pg_size_pretty (сумма (pg_column_size (profile_id))) как profile_id,
pg_size_pretty(sum(pg_column_size(category_id))) как category_id,
pg_size_pretty(sum(pg_column_size(title))) как заголовок,
pg_size_pretty(sum(pg_column_size(image))) как изображение,
pg_size_pretty(sum(pg_column_size(code))) как код,
pg_size_pretty(sum(pg_column_size(sku))) as sku,
pg_size_pretty(sum(pg_column_size(parent_code))) как parent_code,
pg_size_pretty (сумма (pg_column_size (created_at))) как created_at,
pg_size_pretty (сумма (pg_column_size (updated_at))) как updated_at,
pg_size_pretty(sum(pg_column_size(brand))) как бренд,
pg_size_pretty(sum(pg_column_size(price))) как цена,
pg_size_pretty(sum(pg_column_size(crawling_status))) как crawling_status,
pg_size_pretty(sum(pg_column_size(spend))) как потратить,
pg_size_pretty(sum(pg_column_size(sales))) как продажи,
pg_size_pretty(sum(pg_column_size(производитель))) как производитель,
pg_size_pretty(sum(pg_column_size(status))) как статус,
pg_size_pretty(sum(pg_column_size(images))) как изображения,
pg_size_pretty(sum(pg_column_size(eligibility_status))) as eligibility_status,
pg_size_pretty(sum(pg_column_size(eligibility_list))) as eligibility_list,
pg_size_pretty(sum(pg_column_size(active))) как активный
из предметов
) я
Конфигурация POSTGRES
https://pastebin. com/9Z2nwBLy
com/9Z2nwBLy
Расчет размера таблицы в PostgreSQL
Знание того, сколько дискового пространства занимают отдельные таблицы, важно для обслуживания и отладки БД, и это можно выполнить с помощью одного запроса в PostgreSQL.
Сначала запрос, затем мы объясним его части:
SELECT n.nspname AS имя_схемы
, c.relname AS имя_таблицы
, pg_size_pretty(pg_total_relation_size(c.oid)) AS total_size
, pg_size_pretty(pg_table_size(c.oid)) КАК table_size
, pg_size_pretty(pg_indexes_size(c.oid)) КАК index_size
ОТ pg_class c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ pg_namespace n ON n.oid = c.relnamespace
ГДЕ c.relkind IN ('r', 'm')
И n.nspname НЕ В ('pg_catalog', 'information_schema')
И n.nspname НЕ НРАВИТСЯ 'pg_toast%'
ПОРЯДОК ПО 1, 2; Объяснение столбцов:
-
total_size— общее дисковое пространство, используемое таблицей, включая ее данные TOAST и индексы -
table_size— дисковое пространство, используемое таблицей и ее данными TOAST 90 014 -
размер_индекса— дисковое пространство, используемое индексами таблицы.

Используемые таблицы (из схемы pg_catalog ): es, последовательности, представления, материализованные представления, составные типы и таблицы TOAST)
-
pg_class.relkind:rобычные таблицы иmматериализованные представления — сюда не входят индексы (i), последовательности (S), представления (v 9005 1), составные типы (c), таблицы TOAST (t) и внешние таблицы (f)
pg_namespace : каталоги пространств имен (схемы)900 02 См. «Вычисление размера таблицы в MySQL» для версии MySQL этот запрос.
Вычисление размера таблицы в MySQL
15 сентября 2022 г. · 2 мин чтения
Знание того, сколько дискового пространства занимают отдельные таблицы, важно для обслуживания и отладки БД, и это можно выполнить с помощью одного запроса в MySQL.
Поиск самых больших таблиц
Достаточно просто изменить приведенный выше запрос, чтобы упорядочить по наибольшему общему размеру:
SELECT n.
 nspname AS имя_схемы
, c.relname AS имя_таблицы
, pg_size_pretty(pg_total_relation_size(c.oid)) AS total_size
, pg_size_pretty(pg_table_size(c.oid)) КАК table_size
, pg_size_pretty(pg_indexes_size(c.oid)) КАК index_size
ОТ pg_class c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ pg_namespace n ON n.oid = c.relnamespace
ГДЕ c.relkind IN ('r', 'm')
И n.nspname НЕ В ('pg_catalog', 'information_schema')
И n.nspname НЕ НРАВИТСЯ 'pg_toast%'
ЗАКАЗАТЬ ПО pg_total_relation_size(c.oid) DESC
ПРЕДЕЛ 10;
nspname AS имя_схемы
, c.relname AS имя_таблицы
, pg_size_pretty(pg_total_relation_size(c.oid)) AS total_size
, pg_size_pretty(pg_table_size(c.oid)) КАК table_size
, pg_size_pretty(pg_indexes_size(c.oid)) КАК index_size
ОТ pg_class c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ pg_namespace n ON n.oid = c.relnamespace
ГДЕ c.relkind IN ('r', 'm')
И n.nspname НЕ В ('pg_catalog', 'information_schema')
И n.nspname НЕ НРАВИТСЯ 'pg_toast%'
ЗАКАЗАТЬ ПО pg_total_relation_size(c.oid) DESC
ПРЕДЕЛ 10; Это может быть использовано для отладки БД, которой не хватает места, или для аналогичных административных задач.
Поиск самых больших схем
Если вы агрегируете по nspname , вы можете найти, какие схемы являются самыми большими:
SELECT n.nspname AS имя_схемы
, pg_size_pretty(sum(pg_total_relation_size(c.oid))) AS total_size
, pg_size_pretty(sum(pg_table_size(c.oid))) AS table_size
, pg_size_pretty(sum(pg_indexes_size(c.oid))) AS index_size
ОТ pg_class c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ pg_namespace n ON n.
