Содержание
Как получить все ссылки на HTML-странице? — efim360.ru
Все ссылки на HTML-странице
document.getElementsByTagName("a")Вернёт объект-прототип класса HTMLCollection с объектами ссылок (HTML-элементами <a>). Эта команда для разработчиков, которые понимают, что делать дальше.
Все ссылки на HTML-странице из консоли браузера, работающего на Chrome
$x("//a")$x(path) возвращает массив элементов DOM, соответствующих заданному выражению XPath.
Все ссылки на HTML-странице с выводом результатов на текущую страницу (в эту же вкладку браузера)
document.write(((Array.from(document.getElementsByTagName("a"))).map(i => {return i.href})).join("<br>"))
или
document.write(([...document.getElementsByTagName("a")].map(i=>i.href)).join("<br>"))Получение всех ссылок на HTML-странице при помощи JavaScript и консоли браузера
Для удобства. Выведет в столбик все адреса из ссылок в текущий документ. Разметка страницы перезапишется, результат легко закинуть в EXCEL или WORD или туда, куда тебе это нужно.
Разметка страницы перезапишется, результат легко закинуть в EXCEL или WORD или туда, куда тебе это нужно.
Куда вводить эти команды?
Открываете HTML-страницу, с которой хотите получить все веб-ссылки. Включаете «Инструменты разработчика» в браузере (CTRL + SHIFT + i). Находите вкладку «Console«. Тыкаете курсор в белое поле справа от синей стрелочки. Вставляете команду. Жмёте клавишу ENTER.
Для тех кто не понял длинную строчку кода выше, предлагаю упрощённую для понимания версию. Пошаговая инструкция по извлечению ссылок со страницы, и видео ниже.
Может ты хочешь знать как получить ВСЕ ССЫЛКИ САЙТА?
Специально для тебя написана статья «JavaScript | Список ссылок сайта». Она о том, каким образом ты можешь собрать все ссылки любого сайта при помощи JavaScript, который работает на ЧПУ-адресах.
Видео инструкция по получению всех ссылок на HTML-странице
 youtube.com/embed/5Llhbe5rZMU» frameborder=»0″ allowfullscreen=»allowfullscreen»>
youtube.com/embed/5Llhbe5rZMU» frameborder=»0″ allowfullscreen=»allowfullscreen»>
Этот метод также работает и с XML-документами.
Пошаговая инструкция — для тех кто хочет разобраться в вопросе сбора ссылок
1. Открываем страницу сайта в браузере
Для примера возьмём страницу любого интернет-магазина с товарами. Пусть это будут фены. На странице со списком фенов будет большое количество ссылок, как на сами товары, так и на пункты навигации по сайту.
Страница интернет-магазина с фенами
2. Открываем инструменты разработчика
Включаете «Инструменты разработчика» в браузере (CTRL + SHIFT + i). Мы не будем использовать редакторы кода т. к. задача очень примитивная. С редактором кода нужно постоянно прыгать из окна в окно — это неудобно. Мы будем пользоваться консолью браузера для ввода команд JavaScript.
Инструменты разработчика в браузере (CTRL + SHIFT + i)
3.
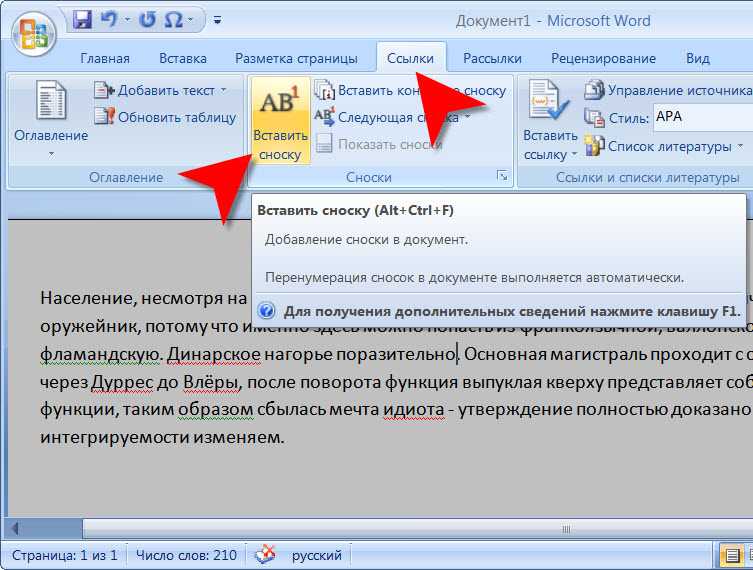 Находим в инструментах вкладку Console
Находим в инструментах вкладку Console
Ввод команд осуществляется в белое поле справа от синей стрелочки в форме уголка 90 градусов. Иногда, при вводе команд, будут ошибки самого ввода. Любые ошибки ввода команд легко исправлять простым нажатием клавиши «вверх» на клавиатуре (стрелочка вверх) и исправлением команды. Опечатки возможны и неизбежны.
В консоли мы сразу будем видеть результат своей работы.
4. Получаем HTML-коллекцию элементов A
Вводим команду для получения всех HTML-элементов <a> с текущий страницы (с текущего документа) в браузере:
var a = document.getElementsByTagName("a")В результате мы получим объект HTMLCollection который будет состоять из узлов (HTML-элементов <a>). Это массиво-подобный объект, но он не умеет работать с методами массивов.
Выводим переменную a в консоль:
HTML-коллекция элементов A
5. Преобразовываем HTML-коллекцию в Массив
Используем метод from() конструктора Array, чтобы получить массив:
var b = Array.from(a)
 from(a)
from(a)Выводим переменную a в консоль:
Массив HTML-элементов (объектов)
Эта операция необходима для того, чтобы иметь возможность трансформировать элементы массива при помощи метода прототипов объекта Array — map()
С коллекций HTML мы не сможем так работать.
6. Достаём из элементов массива значения ключа href
Из «грязного» массива получаем «чистый». Очищаем элементы массива от лишнего при помощи метода прототипов объекта Array — map(). Нас интересуют только ссылки. Задача такая. Ключ «href» вернёт нам полный URI — это значит что все относительные ссылки будут преобразованы в абсолютные.
var c = b.map(i => {return i.href})Если бы нас интересовали относительные ссылки, то мы бы собирали новый массив из ключей «pathname«.
Выводим переменную a в консоль:
Массив со строковыми элементами в виде готовых ссылок
7. Массив перегоняем в строку и добавляем разделитель между элементами
Нам нужно просто слепить все элементы массива в одну длинную строку, которая будет на странице переноситься в столбец при помощи HTML-элемента <br>. Для этой цели мы используем метод прототипов объекта Array — join().
Для этой цели мы используем метод прототипов объекта Array — join().
var d = c.join("<br>")Выводим переменную a в консоль:
Строка с элементом переноса
8. Выводим строку на страницу текущего документа
Эта операция очистит содержимое страницы и выведет список. При обновлении страницы в браузере можно будет вернуться к оригинальной странице с фенами.
document.write(d)
Результат вывода:
Выведенный список ссылок на страницу
Что дальше?
Теперь можно пользоваться результатом вывода и скопировать список себе в эксель таблицу, например. Потом можно почистить дубли до получения уникальных ссылок. Можно попробовать отделить ссылки по типу «внешние/внутренние».
Можно поискать применение «фрагмента» URI (это решётка #) на предмет качественной разметки страницы. Как правило большие страницы, в которых много контента имеют дополнительную семантическую разметку при помощи фрагмента URI. То есть любой пользователь может получить ссылку на конкретный фрагмент текста в документе. (как правило это будет текст на HTML-странице)
(как правило это будет текст на HTML-странице)
Можно понять правильно ли оформлены ссылки на изображения. Можно поискать ссылки с «запросами» URI (это знак вопроса ?), которые могут транслироваться в рекламные сети. Можно поискать «корявые» ЧПУ для SEO.
Можно поискать «непопрятанные» ссылки на технические разделы сайта, которыми пользуются разработчики. Из них можно «подолбить» админ-панели на попытку входа в систему. Ну и т.д.. Информация о ссылочном профиле страницы может оказаться полезной.
Для кого эта статья?
Эта статья создана в образовательных целях, чтобы укрепить навыки программирования на JavaScript, а также поработать с готовыми API. Статья будет очень полезна тем людям, которые никогда не слышали слово JavaScript и которые ищут способы «Как собрать все ссылки со страницы?» или «Как извлечь все ссылки из HTML?». Эти люди знают свои потребности, но не знают о способах их реализации.
Ссылки
JavaScript | Как узнать количество ссылок на HTML-странице?
JavaScript | Как получить все внутренние ссылки на HTML-странице?
JavaScript | Как получить все внешние(исходящие) ссылки на HTML-странице?
JavaScript | Как получить все ссылки с запросами на HTML-странице?
JavaScript | Как получить все ссылки с фрагментами на HTML-странице?
JavaScript | Как очистить ссылки от запросов и фрагментов?
DOM стандарт — https://efim360. ru/dom/
ru/dom/
DOM
Читайте перевод полной версии стандарта «объектной модели документа», чтобы ознакомиться со всеми концепциями и интерфейсами.
DOM — Living Standard — https://dom.spec.whatwg.org
Читайте официальную документацию живого стандарта «объектной модели документа», чтобы быть в курсе последних изменений.
https://dom.spec.whatwg.org/#dom-document-getelementsbytagname
JavaScript | Массивы (Array)
ECMAScript — Living Standard — https://tc39.es/ecma262/#sec-array.prototype.map
Поиск исходящих ссылок — SEO на vc.ru
{«id»:13760,»url»:»\/distributions\/13760\/click?bit=1&hash=3388ba15c914e93bf42e7b84a842bfb878869a35e460a86df78995d13819ad04″,»title»:»\u041f\u0440\u043e\u0434\u044e\u0441\u0435\u0440\u044b vc.ru \u043f\u0440\u043e\u0432\u0435\u0440\u044f\u044e\u0442 \u0448\u0443\u043c\u043e\u0434\u0430\u0432 \u0432 \u0422\u0431\u0438\u043b\u0438\u0441\u0438″,»buttonText»:»\u042d\u0442\u043e \u043a\u0430\u043a?»,»imageUuid»:»bf749ef5-3154-5029-a8d8-4dcbcbfac3ff»,»isPaidAndBannersEnabled»:false}
SEO
SEO блиц
 date» data-date=»1548407254″ data-type=»default» title=»25.01.2019 12:07:34 (Europe/Moscow)»>25 янв 2019
date» data-date=»1548407254″ data-type=»default» title=»25.01.2019 12:07:34 (Europe/Moscow)»>25 янв 2019
О том, вредны ли исходящие ссылки для продвижения, написано много статей и мнения по этому поводу разнятся. Одни говорят, что по внешним ссылкам уходит ′вес′ с сайта, другие, что тематичные ссылки на полезный контент наоборот повышают ценность страницы. Мы больше склонны ко второму варианту. Но в любом случае нужно следить за исходящей ссылочной массой.
4983
просмотров
Найти исходящие ссылки с сайта можно несколькими способами:
- Поиск ссылок в коде страницы. Подходит в том случае, если необходимо проверить исходящие ссылки на одной странице. Для этого необходимо перейти в режим просмотра исходного кода через контекстное меню браузера или сочетанием клавиш Ctrl+U. И далее в ручном режиме искать ссылки на сторонние домены. Данный способ не очень удобен, т.к. не всегда код страницы визуально красиво оформлен и поиск внешних ссылок может быть затруднен.
 Данный способ не очень удобен, т.к. не всегда код страницы визуально красиво оформлен и поиск внешних ссылок может быть затруднен.
Данный способ не очень удобен, т.к. не всегда код страницы визуально красиво оформлен и поиск внешних ссылок может быть затруднен.- Использование расширений для браузера. Упростить поиск исходящих ссылок помогут специальные расширения. В качестве примера возьмем RDS bar для Mozilla Firefox. В нем можно добавить подсветку внешних ссылок или определить их количество при помощи сервисов.
- Сервисы по поиску внешних ссылок. Данный способ был частично затронут в предыдущем пункте. RDS bar показывает внешние ссылки страницы по данным сервиса linkpad. Узнать общее количество исходящих ссылок с домена можно используя сервис Megaindex.com (Необходима регистрация).
- Букмарклеты. Представляют собой небольшой скрипт, который покажет список исходящих ссылок со страницы. Достаточно сохранить его как закладку в браузере, и при нажатии будет отображаться список исходящих ссылок. Букмарклеты можно найти здесь.
 Букмарклеты можно найти здесь.
Букмарклеты можно найти здесь.- Screaming Frog SEO Spider — многофункциональная программа для сканирования сайта, предназначена для оценки технического состояния ресурса. Чтобы найти исходящие ссылки сначала необходимо добавить адрес сайта, нажать start и просканировать сайт. После завершения сканирования список исходящих ссылок будет во вкладке External. О том, как закрыть исходящие ссылки от поисковых систем, читайте в другом нашем материале.
Ждите новые заметки в блоге или ищите на нашем сайте.
веб-сканер — Получить список URL-адресов с сайта
спросил
Изменено
4 года, 4 месяца назад
Просмотрено
492k раз
Закрыто. Этот вопрос не соответствует правилам переполнения стека. В настоящее время ответы не принимаются.
Этот вопрос не соответствует правилам переполнения стека. В настоящее время ответы не принимаются.
Мы не принимаем вопросы с рекомендациями по книгам, инструментам, программным библиотекам и т. д. Вы можете отредактировать вопрос, чтобы на него можно было ответить фактами и цитатами.
Закрыта 7 лет назад.
Улучшить этот вопрос
Я развертываю новый сайт для клиента, но он не хочет, чтобы все его старые страницы заканчивались ошибкой 404. Сохранить старую структуру URL было невозможно, потому что она была отвратительной.
Итак, я пишу обработчик 404, который должен искать запрашиваемую старую страницу и выполнять постоянное перенаправление на новую страницу. Проблема в том, что мне нужен список всех старых URL-адресов страниц.
Я мог бы сделать это вручную, но мне было бы интересно, есть ли какие-либо приложения, которые предоставили бы мне список только что заданных относительных (например, /page/path, а не http:/. ../page/path) URL-адресов домашняя страница. Как паук, но тот, кто не заботится о содержании, кроме поиска более глубоких страниц.
../page/path) URL-адресов домашняя страница. Как паук, но тот, кто не заботится о содержании, кроме поиска более глубоких страниц.
- поисковый робот
1
Я не хотел отвечать на свой вопрос, но я просто подумал о запуске генератора карты сайта. Первый, который я нашел, http://www.xml-sitemaps.com имеет хороший текстовый вывод. Идеально подходит для моих нужд.
6
do wget -r -l0 www.oldsite.com
Тогда просто find www.oldsite.com покажет все URL-адреса, я полагаю.
В качестве альтернативы, просто обслуживайте эту пользовательскую ненайденную страницу при каждом запросе 404!
т.е. если кто-то использовал неправильную ссылку, он получал сообщение о том, что страница не найдена, и делал некоторые подсказки о содержании сайта.
8
Вот список генераторов карты сайта (из которых, очевидно, вы можете получить список URL-адресов с сайта): http://code. google.com/p/sitemap-generators/wiki/SitemapGenerators
google.com/p/sitemap-generators/wiki/SitemapGenerators
Генераторы карты сайта
Ниже приведены ссылки на инструменты, которые создают или поддерживают файлы в
формат XML Sitemaps, открытый стандарт, определенный на sitemaps.org и
поддерживается поисковыми системами, такими как Ask, Google, Microsoft Live
Поиск и Yahoo!. Файлы Sitemap обычно содержат набор
URL-адреса на веб-сайте вместе с некоторыми метаданными для этих URL-адресов.
следующие инструменты обычно генерируют «веб-тип» XML Sitemap и список URL-адресов
файлы (некоторые могут также поддерживать другие форматы).Обратите внимание: Google не тестировал и не проверял функции или
безопасности стороннего программного обеспечения, указанного на этом сайте. Пожалуйста
любые вопросы, касающиеся программного обеспечения, направляйте автору программного обеспечения.
Надеемся, вам понравятся эти инструменты!Серверные программы
- Энарион phpSitemapsNG (PHP)
- Генератор карт сайта Google (Linux/Windows, 32/64 бит, с открытым исходным кодом)
- Outil en PHP (французский язык, PHP)
- Perl Генератор карты сайта (Perl)
- Генератор карты сайта Python (Python)
- Простые файлы Sitemap (PHP)
- SiteMap XML Генератор динамической карты сайта (PHP) $
- Генератор карты сайта для OS/2 (REXX-скрипт)
- XML Генератор карты сайта (PHP) $
CMS и другие плагины:
- ASP.
- DotClear (испанский)
- ДотКлеар (2)
- Друпал
- шаблонов электронной коммерции (PHP) $
- шаблонов электронной коммерции (PHP или ASP) $
- LifeType
- Генератор карты сайта MediaWiki
- mnoGoSearch
- ОС Коммерция
- phpWebSite
- Плон
- РапидВивер
- Шаблон текста
- бюллетень
- Вики Вики (PHP)
- WordPress
Загружаемые инструменты
- GSiteCrawler (Windows)
- GWebCrawler и создатель карты сайта (Windows)
- G-Mapper (Windows)
- Inspyder Sitemap Creator (Windows) $
- IntelliMapper (Windows) $
- Генератор карты сайта Microsys A1 (Windows) $
- Rage Google Sitemap Automator $ (OS-X)
- Screaming Frog SEO Spider и генератор Sitemap (Windows/Mac) $
- Карта сайта Pro (Windows) $
- Модуль записи карты сайта (Windows) $
- Генератор карты сайта от DevIntelligence (Windows)
- Инструменты карты сайта Sorrowmans (Windows)
- TheSiteMapper (Windows) $
- Вигос Gsitemap (Windows)
- Visual SEO Studio (Windows)
- Генератор карты сайта WebDesignPros (приложение Java Webstart)
- Weblight (Windows/Mac) $
- Генератор карты сайта WonderWebWare (Windows)
Онлайн-генераторы/услуги
- AuditMyPc.
- Автокарта
- Автокарта сайта $
- Энарион phpSitemapsNG
- Бесплатный генератор карты сайта
- Neuroticweb.com Генератор карты сайта
- ROR Генератор карты сайта
- Генератор карты сайта ScriptSocket
- Генератор карты сайта SeoUtility (итальянский)
- Карта сайтаDoc
- Карта сайтаpal
- Карта сайтаОтправить
- Smart-IT-Consulting Google Sitemaps XML Validator
- Генератор XML-карты сайта
- Генератор XML-карт сайта
CMS со встроенными генераторами Sitemap
- Бетон5
Google News Sitemap Generators Следующие плагины позволяют
издателям обновлять файлы Sitemap для Новостей Google, вариант
sitemaps.org, который мы описываем в нашем Справочном центре. Кроме того
к обычным свойствам файлов Sitemap, файлы Sitemap для Новостей Google позволяют
издателям для описания типов публикуемого ими контента, а также
определение уровней доступа для отдельных статей.
о новостях Google можно найти в нашем справочном центре и на справочных форумах.
- Плагин Новостей Google для WordPress
Фрагменты кода/библиотеки
- Сценарий ASP
- Сценарий Emacs Lisp
- Библиотека Java
- Perl-скрипт
- PHP-класс
- Скрипт генератора PHP
Если вы считаете, что инструмент должен быть добавлен или удален для законного
причину, оставьте комментарий на справочном форуме для веб-мастеров.
 NET — Sitemaps.Net
NET — Sitemaps.Net com Генератор карты сайта
com Генератор карты сайта Дополнительная информация
Дополнительная информация2
Лучшее, что я нашел, это http://www.auditmypc.com/xml-sitemap.asp, который использует Java, не имеет ограничений на количество страниц и даже позволяет экспортировать результаты в виде необработанного списка URL-адресов.
Он также использует сеансы, поэтому, если вы используете CMS, убедитесь, что вы вышли из системы перед запуском сканирования.
1
Итак, в идеальном мире у вас должна быть спецификация для всех страниц вашего сайта. У вас также будет тестовая инфраструктура, которая сможет протестировать все ваши страницы.
Вероятно, вы живете не в идеальном мире. Почему бы не сделать это…?
Создать сопоставление между скважиной
известные старые URL-адреса и новые.
Перенаправление, когда вы видите старый URL.
Я бы, возможно, подумал о представлении
«эта страница была перемещена, это новый адрес
XXX, вы будете перенаправлены
скоро».Если у вас нет карты, предъявите
«извините — эта страница переехала. Вот
сообщение со ссылкой на главную страницу» и
перенаправьте их, если хотите.Регистрировать все перенаправления, особенно
те, у которых нет карт. Со временем добавить
сопоставления для страниц, которые
важный.
wget из Linux также может быть хорошим вариантом, так как есть переключатели для паука и изменения его вывода.
РЕДАКТИРОВАТЬ: wget также доступен в Windows: http://gnuwin32.sourceforge.net/packages/wget.htm
Напишите паука, который читает каждый html с диска и выводит каждый атрибут «href» «a» элемент (можно сделать с помощью парсера). Имейте в виду, какие ссылки относятся к определенной странице (это обычная задача для структуры данных MultiMap). После этого вы можете создать файл сопоставления, который действует как вход для обработчика 404.
Я бы рассмотрел любое количество онлайн-инструментов для создания карты сайта. Лично я использовал этот (основанный на Java) в прошлом, но если вы выполните поиск в Google по запросу «конструктор карты сайта», я уверен, что вы найдете множество различных вариантов.
Очень активный вопрос . Заработайте 10 репутации (не считая бонуса ассоциации), чтобы ответить на этот вопрос. Требование к репутации помогает защитить этот вопрос от спама и отсутствия ответа.
beautifulsoup — Как получить все ссылки на веб-страницу, прямо или косвенно связанные с веб-страницей, используя python?
спросил
Изменено
3 года, 4 месяца назад
Просмотрено
466 раз
Мне нужно получить все ссылки, связанные с URL-адресом домашней страницы веб-сайта, что все ссылки означают ссылку, которая присутствует на домашней странице, а также ссылки, которые являются новыми и достигаются с помощью ссылки в ссылках на домашней странице.
Я использую библиотеку Python BeautifulSoup. Я также думаю использовать Scrapy.
Этот код ниже извлекает ссылки, связанные только с домашней страницей.
из импорта bs4 BeautifulSoup
запросы на импорт
URL-адрес = "https://www.dataquest.io"
деф ссылки (url):
html = запросы.get(url).content
bsObj = BeautifulSoup(html, 'lxml')
ссылки = bsObj.findAll('a')
окончательные ссылки = установить ()
для ссылки в ссылках:
finalLinks.add(ссылка)
вернуть окончательные ссылки
распечатать(ссылки(url))
linklis = список (ссылки (url))
для л в линклис:
печать (л)
печать("\n")
Мне нужен список, который включает все URL-адреса/ссылки, которые могут быть доступны через URL-адрес домашней страницы (могут быть прямо или косвенно связаны с домашней страницей).
- питон
- красивый суп
0
Этот скрипт распечатает все ссылки, найденные по URL-адресу https://www. : dataquest.io
dataquest.io
из bs4 import BeautifulSoup
запросы на импорт
URL-адрес = "https://www.dataquest.io"
деф ссылки (url):
html = запросы.get(url).content
bsObj = BeautifulSoup(html, 'lxml')
ссылки = bsObj.select('a[href]')
final_links = установить ()
для ссылки в ссылках:
url_string = ссылка['href'].rstrip('/')
если 'javascript:' в url_string или url_string.startswith('#'):
Продолжить
elif 'http' не в url_string и не url_string.startswith('//'):
url_string = 'https://www.dataquest.io' + url_string
elif 'dataquest.io' отсутствует в url_string:
Продолжить
final_links.add(url_string)
вернуть final_links
для l в отсортированном (ссылки (url)):
печать (л)
Печать:
http://app.dataquest.io/login
http://app.dataquest.io/signup
https://app.dataquest.io/signup
https://www.dataquest.io
https://www.dataquest.io/about-us
https://www.dataquest.io/блог
https://www.
https://www.dataquest.io/blog/learn-python-the-right-way
https://www.dataquest.io/blog/the-perfect-data-science-learning-tool
https://www.dataquest.io/blog/topics/студенческие истории
https://www.dataquest.io/чат
https://www.dataquest.io/курс
https://www.dataquest.io/course/algorithms-and-data-structures
https://www.dataquest.io/course/apis-and-scraping
https://www.dataquest.io/course/building-a-data-pipeline
https://www.dataquest.io/course/calculus-for-machine-learning
https://www.dataquest.io/course/элементы командной строки
https://www.dataquest.io/course/command-line-intermediate
https://www.dataquest.io/course/data-exploration
https://www.dataquest.io/course/data-structures-algorithms
https://www.dataquest.io/course/decision-trees
https://www.dataquest.io/course/deep-learning-fundamentals
https://www.dataquest.io/course/exploratory-data-visualization
https://www.dataquest.io/course/exploring-topics
https://www.dataquest.io/course/git-and-vcs
https://www.
https://www.dataquest.io/course/intermediate-r-programming
https://www.dataquest.io/course/intro-to-r
https://www.dataquest.io/course/kaggle-fundamentals
https://www.dataquest.io/course/linear-алгебра-для-машинного обучения
https://www.dataquest.io/course/linear-regression-for-machine-learning
https://www.dataquest.io/course/machine-learning-fundamentals
https://www.dataquest.io/course/machine-learning-intermediate
https://www.dataquest.io/course/machine-learning-project
https://www.dataquest.io/course/natural-language-processing
https://www.dataquest.io/course/optimizing-postgres-databases-data-engineering
https://www.dataquest.io/course/pandas-fundamentals
https://www.dataquest.io/course/pandas-large-datasets
https://www.dataquest.io/course/postgres-for-data-engineers
https://www.dataquest.io/course/probability-fundamentals
https://www.dataquest.io/course/probability-statistics-intermediate
https://www.dataquest.io/course/python-data-cleaning-advanced
https://www.
https://www.dataquest.io/course/python-for-data-science-fundamentals
https://www.dataquest.io/course/python-for-data-science-intermediate
https://www.dataquest.io/course/python-programming-advanced
https://www.dataquest.io/course/r-data-cleaning
https://www.dataquest.io/course/r-data-cleaning-advanced
https://www.dataquest.io/course/r-data-viz
https://www.dataquest.io/course/recursion-and-tree-structures
https://www.dataquest.io/course/spark-map-reduce
https://www.dataquest.io/course/sql-databases-advanced
https://www.dataquest.io/course/sql-основы
https://www.dataquest.io/course/sql-fundamentals-r
https://www.dataquest.io/course/sql-intermediate-r
https://www.dataquest.io/course/sql-joins-отношения
https://www.dataquest.io/course/statistics-fundamentals
https://www.dataquest.io/course/statistics-intermediate
https://www.dataquest.io/course/сторителлинг-данные-визуализация
https://www.dataquest.io/course/text-processing-cli
https://www.dataquest.
 dataquest.io/blog/learn-data-science
dataquest.io/blog/learn-data-science dataquest.io/course/improving-code-performance
dataquest.io/course/improving-code-performance dataquest.io/course/python-очистка данных
dataquest.io/course/python-очистка данных