Содержание
Sphinx — Система полнотекстового поиска / Хабр
Система полнотекстового поиска
Статьи
Посты
Авторы
Компании
Сначала показывать
Порог рейтинга
Уровень сложности
ManticoreSearch
Время на прочтение
53 мин
Количество просмотров
17K
Поисковые технологии *Sphinx *Администрирование баз данных *
5 лет назад мы форкнули Manticore из open source версии некогда популярного open source поискового движка Sphinx 2.3.2. У нас было два пакетика травы, семьдесят пять ампул мескалина, три C++ разработчика, один саппорт-инженер, опытный пользователь, менеджер, мать пятерых детей, помогающая нам на полставки и гора багов, крэшей и технических долгов. И вот, по прошествии 5 лет и сотен новых пользователей мы готовы сказать, что Manticore можно использовать как альтернативу Elasticsearch и для полнотекстового поиска и для аналитики данных.
И вот, по прошествии 5 лет и сотен новых пользователей мы готовы сказать, что Manticore можно использовать как альтернативу Elasticsearch и для полнотекстового поиска и для аналитики данных.
В этой статье хочется: вспомнить как всё начиналось и что было до SOLR и Elasticsearch, максимально объективно обрисовать текущую ситуацию, попытаться понять куда нам двигаться дальше.
Читать далее
Всего голосов 117: ↑117 и ↓0 +117
Комментарии
83
YARUSru
Время на прочтение
3 мин
Количество просмотров
9K
Поисковые технологии *Sphinx *
Recovery mode
Каждый разработчик приложения рано или поздно сталкивается с таким важным вопросом, как выбор поискового движка. Мы рассмотрели два популярных, но принципиально разных варианта – Sphinx и Elasticsearch – и объяснили, почему сделали выбор в пользу первого для своего приложения.
Читать далее
Всего голосов 11: ↑3 и ↓8 -5
Комментарии
11
kalaverin
Время на прочтение
13 мин
Количество просмотров
2K
Блог компании Lesta Studio Sphinx *
Автобиографический трактат о кардинальном обновлении версии поисковой системы, увлекательном приготовлении оного и ожидаемо скучный эпилог о том, как всё хорошо получилось: у нас был Sphinx Search 2.0.9, мы вовремя спохватились (посмотрев на календарь) и повезли актуальную версию.
Сделать что-нибудь — это полдела, сопровождать что-либо весь жизненный цикл — действительный путь настоящего уважающего себя самурая. Касается чего угодно — от проведения полноформатных ивентов с тысячами посетителей, до проектирования, запуска, серийного производства, обслуживания и выведения из эксплуатации с утилизацией пассажирских и грузовых авиалайнеров.
Проследовать в длиннопост
Всего голосов 12: ↑12 и ↓0 +12
Комментарии
6
velon
Время на прочтение
9 мин
Количество просмотров
2.7K
Поисковые технологии *Open source *Sphinx *Алгоритмы *Регулярные выражения *
Это продолжение публикации «Интернационализация поиска по городским адресам. Реализуем русскоязычный Soundex на Sphinx Search», в которой я разбирал, как реализовать поддержку фонетических алгоритмов Soundex в Sphinx Search, для текста написанного кириллицей. Для текста на латинице поддержка Soundex уже есть. С Metphone аналогично, для латиницы есть, для кириллицы не очень, но попытаемся исправить этот досадный факт с помощью транслитерации, регулярных выражений и напильника.
Это прямое продолжение, в котором разберём как реализовать оригинальный Metaphone, русский Metaphone (в том смысле что транслитерация не понадобится), Caverphone, и не сможем сделать Double Metaphone.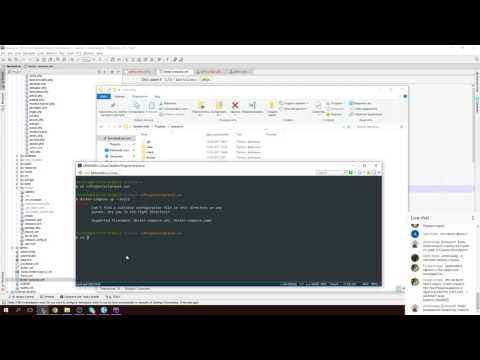
Реализация подойдёт как для использования на платформе Sphinx Search, так и Manticore Search.
В конце, посмотрим как Metaphone воспримет «ракомакофон«.
Продолжаем…
Всего голосов 1: ↑1 и ↓0 +1
Комментарии
2
velon
Время на прочтение
14 мин
Количество просмотров
2.2K
Поисковые технологии *Open source *Sphinx *Алгоритмы *Регулярные выражения *
Как много в вашем городе иностранных туристов? В моём мало, но встречаются, как правило стоят потерянные посреди улицы и повторяют одно единственное слово – название чего бы то ни было. А прохожие пытаются им на пальцах объяснить куда пройти, а когда «моя твоя не понимать» – берут за руку и ведут к пункту назначения. Как это не удивительно, обычно цель в пяти минутах ходьбы, т. е. какое-то примерное представление о городе эти туристы всё же имели. Может по бумажной карте ориентировались.
е. какое-то примерное представление о городе эти туристы всё же имели. Может по бумажной карте ориентировались.
А как часто лично вы оказывались в такой ситуации, в незнакомом городе в другой стране?
Появление смартфонов и приложений для навигации решило много проблем. Ура, можно посмотреть свою геолокацию, можно найти куда идти, прикинуть в каком направлении и даже проложить маршрут.
Осталась одна проблема: все улицы в приложении подписаны местными иероглифами на местном наречии, и ладно если в стране пребывания принята латиница, клавиатура на латинице есть во всех смартфонах и мир к ней привык, и то я испытывал дискомфорт, из-за диакритических знаков, принятых в чешском алфавите. А боль и страдания иностранцев, видящих кириллицу, могу только представить, посмотрите псевдокириллицу и поймёте. Если бы я оказался на их месте, я бы писал названия и адреса латиницей, пытаясь воспроизвести звучание — фонетический поиск.
В публикации опишу как реализовать фонетические алгоритмы поиска Soudex на движке Sphinx Search. Одной транслитерацией здесь не обойдётся, хотя и без неё никуда. Получившийся конфигурационный файл, доступен на GitHub Gist.
Одной транслитерацией здесь не обойдётся, хотя и без неё никуда. Получившийся конфигурационный файл, доступен на GitHub Gist.
Длиннопост
Всего голосов 8: ↑8 и ↓0 +8
Комментарии
6
ManticoreSearch
Время на прочтение
12 мин
Количество просмотров
13K
Поисковые технологии *Open source *Sphinx *
В мае 2017 мы, команда Manticore Software, сделали форк Sphinxsearch, который назвали Manticore Search. Ниже вы найдёте краткий отчёт о проделанной работе за три с половиной года, прошедших с момента форка.
Читать далее
Всего голосов 56: ↑56 и ↓0 +56
Комментарии
39
aszhitarev
Время на прочтение
5 мин
Количество просмотров
7. 9K
9K
.NET *Sphinx *
В стародавние времена я работал айтишником в одной фирме и в какое-то время возникла задача поиска по локальному хранилищу документов. Искать желательно было не только по названию файла, но и по содержанию. Тогда ещё были популярны локальные поисковые механизмы типа архивариуса и даже от Яндекса был отдельностоящий поисковик. Но это были не корпоративные решения их нельзя было развернуть централизовано для совместного использования. Яндекс, честности ради начал делать что-то похожее, но потом забросил.
Но у всех этих решений не было того, что мне нужно:
- Централизованная установка
- Поисковая выдача с учётом прав доступа
- Поиск по содержимому документа
- Морфология
И я решил сделать своё.
Читать дальше →
Всего голосов 15: ↑13 и ↓2 +11
Комментарии
19
ready_for_sky_team
 000Z» title=»2020-07-09, 11:12″>9 июл 2020 в 11:12
000Z» title=»2020-07-09, 11:12″>9 июл 2020 в 11:12
Время на прочтение
6 мин
Количество просмотров
2.3K
Блог компании Ready for Sky C++ *Sphinx *
В процессе разработки проекта «голосовой помощник» одним из требований была возможность распознавания управляющих команд в оффлайн режиме. Это было нужно, так как в противном случае пришлось бы постоянно слушать и посылать поток с аудиоданными на распознавание, получать ответ и анализировать его.
Это весьма накладное решение, которое сложно реализовать из-за постоянной нагрузки на сервер, большого объема трафика и увеличенного время отклика всей системы. Для распознавания управляющих команд в режиме оффлайн мы выбрали Pocketsphinx.
Читать дальше →
Рейтинг 0
Комментарии
8
matvey_travkin
 000Z» title=»2019-05-24, 17:27″>24 мая 2019 в 17:27
000Z» title=»2019-05-24, 17:27″>24 мая 2019 в 17:27
Время на прочтение
1 мин
Количество просмотров
3.1K
Блог компании SuperJob Поисковые технологии *MySQL *Sphinx *
28 февраля мы провели SphinxSearch-meetup SuperJob. Рассказываем, что обсуждали участники, делимся видео и презентациями.
Всего голосов 14: ↑13 и ↓1 +12
Комментарии
2
narkq
Время на прочтение
13 мин
Количество просмотров
4K
Блог компании SuperJob Поисковые технологии *Sphinx *Go *
28 февраля я выступал с докладом на SphinxSearch-meetup, который проходил в нашем офисе. Рассказывал о том, как мы пришли от регулярного перестроения индексов для полнотекстового поиска и отправки обновлений в коде «по месту» к рейлтайм-индексам и автоматической синхронизации состояния индекса и базы данных MariaDB. По ссылке доступна видеозапись моего доклада, а для тех, кто предпочитает чтение просмотру видео, я написал эту статью.
По ссылке доступна видеозапись моего доклада, а для тех, кто предпочитает чтение просмотру видео, я написал эту статью.
Читать дальше →
Всего голосов 11: ↑11 и ↓0 +11
Комментарии
1
Egor812
Время на прочтение
5 мин
Количество просмотров
36K
Sphinx *Разработка под e-commerce *
Из песочницы
Информации по Sphinx не так много, как хотелось бы. Лишняя статья не помешает.
Первые шаги в освоении Sphinx мне помогли сделать статьи Создание ознакомительного поискового движка на Sphinx + php и Пример Sphinx поиска на реальном проекте — магазин автозапчастей Tecdoc Советую начать с них.
Некоторое время на моем сайте работал поиск через LIKE по каждому слову запроса. Хотелось большего, и вот какие случаи теперь будут обрабатываться правильно:
- Словоформы.
 Выдача по «винты» и «винтов» должна быть одинаковой.
Выдача по «винты» и «винтов» должна быть одинаковой. - Поиск по фрагменту слова.
- Поиск нецелых чисел. Разделитель точка и запятая.
- Буква Ё
- Типичные ошибки. Например «Аммортизатор».
- Синонимы. Регулятор и ESC.
- Язык. mAh и мАч, В и V, AAA латиницей и кириллицей.
- Слово из букв и цифр. 10х15х4, 6000mAh
 Выдача по «винты» и «винтов» должна быть одинаковой.
Выдача по «винты» и «винтов» должна быть одинаковой.
Читать дальше →
Всего голосов 18: ↑17 и ↓1 +16
Комментарии
8
matvey_travkin
Время на прочтение
2 мин
Количество просмотров
1.2K
Блог компании SuperJob Поисковые технологии *Sphinx *Поисковая оптимизация *IT-компании
28 февраля в офисе SuperJob состоится встреча разработчиков, посвящённая системе полнотекстового поиска Sphinx.
Специалисты Avito и SuperJob поделятся своим опытом использования технологии. Участники встречи смогут задать свои вопросы автору Sphinx Андрею Аксёнову. Традиционно в программе бургеры и неформальное общение.
Дата и время: 28 февраля c 19:00 до 21:30
Адрес: Москва, Малая Дмитровка, дом 20
Регистрация: superjob-meetup.timepad.ru/event/894409
Читать дальше →
Всего голосов 14: ↑12 и ↓2 +10
Комментарии
0
qsoft
Время на прочтение
8 мин
Количество просмотров
9.8K
Поисковые технологии *Sphinx *1С-Битрикс *Разработка под e-commerce *
Все мы совершаем ошибки: в данном случае речь идет о поисковых запросах. Количество сайтов для продажи товаров и услуг растет наряду с потребностями пользователей, однако не всегда они могут найти то, что ищут – только потому, что неправильно вводят название необходимого товара. Решение данной проблемы достигается путем реализации нечеткого поиска, то есть использования алгоритма поиска наиболее близких значений с учетом возможных ошибок или опечаток пользователя. Область применения такого поиска достаточно широка – нам же удалось поработать над поиском для крупного интернет-магазина в фудритейл-сегменте.
Решение данной проблемы достигается путем реализации нечеткого поиска, то есть использования алгоритма поиска наиболее близких значений с учетом возможных ошибок или опечаток пользователя. Область применения такого поиска достаточно широка – нам же удалось поработать над поиском для крупного интернет-магазина в фудритейл-сегменте.
Читать дальше →
Всего голосов 6: ↑6 и ↓0 +6
Комментарии
2
vkrukov
Время на прочтение
9 мин
Количество просмотров
13K
Блог компании AvitoTech Поисковые технологии *Sphinx *
Раньше на Авито можно было найти нужный товар, используя фильтрацию по ключевым словам или навигацию по дереву категорий. Этот способ, хоть и казался привычным, был не всегда удобен — чтобы найти товар или услугу, нужно было сделать большое количество кликов. Более года назад у нас появилась релевантность, благодаря которой поиск стал лучше, и найти товар или услугу теперь проще и удобнее даже на главной странице. С этим нововведением в выдачу перестали попадать неподходящие, откровенно «мусорные» товары. И это только один из шагов, чтобы сделать поиск лучше. Мы постепенно изменяем инфраструктуру, что позволяет нам работать над качеством поиска более интенсивно, быстрее улучшать его и выкатывать новые фичи, приносящие пользу продавцам и покупателям на Авито.
Более года назад у нас появилась релевантность, благодаря которой поиск стал лучше, и найти товар или услугу теперь проще и удобнее даже на главной странице. С этим нововведением в выдачу перестали попадать неподходящие, откровенно «мусорные» товары. И это только один из шагов, чтобы сделать поиск лучше. Мы постепенно изменяем инфраструктуру, что позволяет нам работать над качеством поиска более интенсивно, быстрее улучшать его и выкатывать новые фичи, приносящие пользу продавцам и покупателям на Авито.
В статье я расскажу, как менялся поиск на Авито: с чего начинали и как мы сейчас движемся по пути к улучшению жизни наших пользователей, поделюсь нашими нововведениями как в продукте, так и в его начинке — технической части. Совсем хардкорного мяса здесь не будет, но, надеюсь, вам понравится.
Читать дальше →
Всего голосов 27: ↑27 и ↓0 +27
Комментарии
18
dimv36
 000Z» title=»2018-01-31, 10:50″>31 янв 2018 в 10:50
000Z» title=»2018-01-31, 10:50″>31 янв 2018 в 10:50
Время на прочтение
3 мин
Количество просмотров
11K
PostgreSQL *Sphinx *
Добрый день, хаброжители!
Представляю вашему вниманию расширение для PostgreSQL, позволяющее отправлять поисковые запросы на Sphinx из PostgreSQL и получать результаты этих запросов.
Подробности реализации и ссылка на репозиторий под катом.
Читать дальше →
Всего голосов 11: ↑11 и ↓0 +11
Комментарии
2
Andrey2008
Время на прочтение
9 мин
Количество просмотров
11K
Блог компании PVS-Studio Open source *C++ *Sphinx *C *
Мои читатели попросили сравнить проекты Manticore и Sphinx с точки зрения качества кода. Я могу сделать это только одним освоенным мною способом — проверить проекты с помощью статического анализатора PVS-Studio и посчитать плотность ошибок в коде. Итак, я проверил C и C++ код в этих проектах и, на мой взгляд, качество кода Manticore выше, чем качество кода Sphinx. Естественно, это очень узкий взгляд, и я не претендую на достоверность своего исследования. Однако меня попросили, и я сделал сравнение так, как умею.
Я могу сделать это только одним освоенным мною способом — проверить проекты с помощью статического анализатора PVS-Studio и посчитать плотность ошибок в коде. Итак, я проверил C и C++ код в этих проектах и, на мой взгляд, качество кода Manticore выше, чем качество кода Sphinx. Естественно, это очень узкий взгляд, и я не претендую на достоверность своего исследования. Однако меня попросили, и я сделал сравнение так, как умею.
Читать дальше →
Всего голосов 31: ↑22 и ↓9 +13
Комментарии
7
SolarSecurity
Время на прочтение
6 мин
Количество просмотров
7.6K
Блог компании Ростелеком-Солар Информационная безопасность *Oracle *PostgreSQL *Sphinx *
В ходе работы DLP-система ежедневно перехватывает огромные массивы информации – это и письма сотрудников, и информация о действиях пользователей на рабочих станциях, и сведения о хранящихся в сети организации файловых ресурсах, и оповещения о несанкционированном выводе данных за пределы организации. Но полезной эта информация будет только в случае, если в DLP реализован качественный механизм поиска по всему массиву перехваченных коммуникаций. С тех пор, как в 2000 году увидела свет первая версия нашего DLP-решения, мы несколько раз меняли механизм поиска по архиву. Сегодня мы хотим рассказать о том, какие технологии мы использовали, какие видели в них преимущества и недостатки, и почему мы от них в итоге отказывались. Возможно, кому-то наш опыт окажется полезен.
Но полезной эта информация будет только в случае, если в DLP реализован качественный механизм поиска по всему массиву перехваченных коммуникаций. С тех пор, как в 2000 году увидела свет первая версия нашего DLP-решения, мы несколько раз меняли механизм поиска по архиву. Сегодня мы хотим рассказать о том, какие технологии мы использовали, какие видели в них преимущества и недостатки, и почему мы от них в итоге отказывались. Возможно, кому-то наш опыт окажется полезен.
Читать дальше →
Всего голосов 23: ↑21 и ↓2 +19
Комментарии
1
lencom
Время на прочтение
6 мин
Количество просмотров
18K
LaTeX *Sphinx *PDF
Туториал
Когда мы полтора года назад внедряли у себя генератор документаций Sphinx, перед нами стояла задача генерировать PDF. Дело оказалось весьма непростое. Готовых инструкций “бери и делай” на ресурсах не было. Мы пошли методом проб и ошибок. Через 3 дня мучений мы умели генерить PDF с нужным нам оформлением.
Дело оказалось весьма непростое. Готовых инструкций “бери и делай” на ресурсах не было. Мы пошли методом проб и ошибок. Через 3 дня мучений мы умели генерить PDF с нужным нам оформлением.
Сделали и забыли — работает же. Пока не случилась проблема со шрифтами. Снова намучились и снова решили. Но что примечательно — с тех пор готовой инструкции по генерации в PDF на просторах интернета не появилось. Поэтому выкладываю нашу. Внутри алгоритм с комментариями и файлами шаблона, особенностями ReST для LaTeX, которые мы собрали опытным путём.
Статья для тех, кто уже использует Sphinx, но имеет проблемы с LaTeX или PDF. Если вы только рассматривает Sphinx как инструмент документирования, будет полезно представлять, как готовить и подавать документацию в этих форматах.
Читать дальше →
Всего голосов 17: ↑16 и ↓1 +15
Комментарии
9
temujin
 000Z» title=»2016-12-07, 21:10″>7 дек 2016 в 21:10
000Z» title=»2016-12-07, 21:10″>7 дек 2016 в 21:10
Время на прочтение
7 мин
Количество просмотров
21K
Open source *Python *Sphinx *Разработка под Linux *
Linux ядро на сегодняшний день — самый динамичный, сложный, крупный проект с открытым кодом. Как же обстоят дела с его документацией? Существует прямая связь: чем качественнее и доступнее документация проекта, тем проще для посторонних изучить основы дела, освоиться и стать полноправным участником.
На семинаре Kernel Recipies мейнтейнер документации Linux ядра Jonathan Corbet рассказал о нынешнем положении дел с документацией и о том, как будет совершаться переход от анархии к порядку. Первые успехи в этом начинании уже есть. Некоторые документы были недавно конвертированы в ReStructuredText с помощью питоновского Сфинкса. О том как это было рассказано внутри.
Читать дальше →
Всего голосов 47: ↑45 и ↓2 +43
Комментарии
14
olegbunin
 000Z» title=»2016-09-16, 19:23″>16 сен 2016 в 19:23
000Z» title=»2016-09-16, 19:23″>16 сен 2016 в 19:23
Время на прочтение
28 мин
Количество просмотров
33K
Блог компании Конференции Олега Бунина (Онтико) Высокая производительность *Разработка веб-сайтов *Поисковые технологии *Sphinx *
Андрей Аксенов (shodan, Разработчик поискового движка Sphinx)
Поиск устроен вот так:
Индексация – по большому счету, ничего сложного. Понятное дело, что по малому счету, там в каждой из трех «деталей» спрятан не то, что демон, а целое где-то стадо, где-то легион, не совсем понятно. Но концепция всегда простая. Все начинается с маленького простенького патчика к Многосерчу, а потом 15 лет этой херней занимаешься.
Берешь документы, разваливаешь их на ключевые слова. И просто взять и развалить документ на ключевые слова «мама, мыла, раму» – это ты не далеко ушел от grep’а, потому что потом все равно эти ключевые слова перебирать. Надо строить некую спец. структуру – полнотекстовый индекс. Вариантов для его построения человечество придумало в свое время довольно много, но, слава Богу, от всех отказалось и в нормальных продакшн системах, по большому счету, победил на данный момент вариант ровно один. Про него и буду рассказывать. Все остальные имеют скорее историческое значение, что ли, и практического интереса не представляют.
структуру – полнотекстовый индекс. Вариантов для его построения человечество придумало в свое время довольно много, но, слава Богу, от всех отказалось и в нормальных продакшн системах, по большому счету, победил на данный момент вариант ровно один. Про него и буду рассказывать. Все остальные имеют скорее историческое значение, что ли, и практического интереса не представляют.
Всего голосов 64: ↑53 и ↓11 +42
Комментарии
22
Elasticsearch vs Sphinx — Разработка на vc.ru
993
просмотров
Каждый разработчик приложения рано или поздно сталкивается с таким важным вопросом, как выбор поискового движка. Можно сказать, что поисковый движок – это сердце API и главный элемент системы доступности контента, благодаря ему поиск и фильтрация происходят в разы быстрее, чем в реляционных базах данных.
Такие системы позволяют юзать много полезных функций поиска. К примеру, учитывают морфологию языка, осуществляют фасетный поиск, работают со стоп-словами, а также позволяют настраивать формулы определения релевантности документов.
Но на каком остановиться? В блогах разработчиков нет единого мнения. Мы рассмотрим два популярных, но принципиально разных поисковых движка – Sphinx и Elasticsearch – и объясним, почему сделали выбор в пользу первого при разработке приложения ЯRUS, и к чему это в итоге привело. Но сначала составим портрет каждого движка.
Sphinx – система полнотекстового поиска. Из плюсов – наличие лемматизаторов ru, en, du, большое количество стеммеров индексации и поиска: full-text, фасетный, geo. Нет ничего лишнего, лишь поисковый движок с быстрой индексацией и своим индексером. При правильной конфигурации RT индексов можно достичь real time indexing. В отличие от Elasticsearch наблюдаем умеренное использование памяти.
Что касается минусов, то главный из них – необходимость самому просчитывать всю структуру индексов, а значит, масштабирование проходит не так просто. Также у системы скудный API, нет возможности для визуализации, отсутствует fuzzy-поиск по дефолту (но можно реализовать свой) и скудное community.
Sphinx написан на C++. Им пользуются такие мастодонты, как Habr, Викимапия, Craigslist, поддерживается 1С-Битрикс.
Теперь несколько слов про Elasticsearch. Поисковая система проводит всю индексацию внутри себя, при этом управление индексами через RESTful API. Плюсы ElasticSearch – это фасетный поиск, легкое и мощное API, большое количество стеммеров, гибкая структура индексов и создание индексов постфактум. С техниками поиска тут тоже все хорошо: Full-text search, а также алгоритмы Geo и Fuzzy.
В Elasticsearch тоже много готовых реализованных модулей для ES, есть возможность хранить данные, Real Time индексация, достаточно легко масштабируется, ETL-механизмы, и что немаловажно – обширное community. Elasticsearch написан на Java и используется в Wikimedia, Mozilla, SoundCloud, GitHub и других площадках.
Что касается минусов Elasticsearch, то в их числе отсутствие своего индексера (необходимо реализовать свой или logstash в ELK), съедает много памяти, а лемматизаторы русского текста ставятся отдельно плагином.
Если бы нас попросили описать Sphinx и Elasticsearch одним выражением, то первую систему поиска мы бы охарактеризовали словами «быстрая индексация», а вторую – «мощный API».
При разработке приложения ЯRUS мы отдали предпочтение Sphinx. Требования к поиску были ниже, а поисковый движок подкупил прозрачной настройкой индексов в виде конфигурационных файлов и быстротой индексации. Но в последнее время мы задумываемся о смене Sphinx на Elasticsearch. Объясним, почему.
Сейчас запрос в API по поиску проходит в несколько этапов: сначала идет запрос в поисковый движок, после полученный результат поискового движка обогащается данными из баз данных. Нам бы хотелось перестать дергать БД (использовать лишь как холодное хранилище) и отдавать готовый модели напрямую из поискового движка. Elasticsearch (как мы уже писали ранее в плюсах) может в Data storage, поэтому ничего не мешает хранить нужные поля в Elastic.
Кроме того, объемы данных в приложении растут, а управление поиском на Sphinx через конфигурационные файлы усложняется (необходимо самому думать о шардах и репликах, на каждую ноду раскидывать свой конфиг), поэтому необходимо упростить управление поиском (отдать все управление данными и индексами сервису). Кроме того, для нас необходима Near Real Time индексация из коробки.
Кроме того, для нас необходима Near Real Time индексация из коробки.
Что касается преимуществ, то мы отгородили разработчиков от сложного управления конфигурациями индексов like Sphinx, а также использовали облачное решение (MCS), из-за чего практически полностью забыли об администрировании. Надеемся, что наш опыт будет полезным для других разработчиков.
Начало работы с поисковой системой Sphinx
В этой статье мы поговорим о поисковой системе Sphinx и о том, как с ее помощью установить ее в операционной системе Windows.
Это первая статья из серии «Поисковая система Sphinx», в которой мы объясним, как установить и использовать эту поисковую систему для создания полнотекстовых индексов в реляционных базах данных (SQL Server).
Введение
Сфинкс ( S QL Ph rase In de x ) — автономная система полнотекстового поиска, обеспечивающая эффективные функции поиска для сторонних приложений, особенно для баз данных SQL. Эта поисковая система была разработана в 2001 году российским разработчиком по имени Андрей Аксенов, чтобы гарантировать (1) хорошее качество поиска, (2) высокую скорость работы (3) с низким потреблением ресурсов (дисковый ввод-вывод, ЦП). Его можно интегрировать с такими языками сценариев, как Python и Java.
Эта поисковая система была разработана в 2001 году российским разработчиком по имени Андрей Аксенов, чтобы гарантировать (1) хорошее качество поиска, (2) высокую скорость работы (3) с низким потреблением ресурсов (дисковый ввод-вывод, ЦП). Его можно интегрировать с такими языками сценариев, как Python и Java.
Поисковая система Sphinx имеет собственные драйверы источников данных, которые используются для взаимодействия с различными системами управления базами данных. Мы должны указать нужный нам драйвер в конфигурационных файлах.
В исследовательской статье, опубликованной в 2017 году группой исследователей Московского технологического университета, проводится быстрое сравнение четырех популярных поисковых систем (Sphinx, Apache Solr, ElasticSearch и Xapian). Результат (приведенный в таблице ниже) показывает, что поисковая система Sphinx имеет самую высокую скорость индексации (4,5 Мб/с) и очень высокую скорость поиска (7/75 мс).
Сфинкс | Солер | Эластичный поиск | Хапиан | |
Скорость индексирования (Мбит/с) | 4,5 | 2,75 | 3,8 | 1,36 |
Скорость поиска (мс) | 7/75 | 25/212 | 10/212 | 14/135 |
Размер индекса (%) | 30 | 20 | 20 | 200 |
Реализация | Сервер | Сервер | Библиотека | Библиотека |
Интерфейс | API, SQL | Веб-сервис | API | API |
Операторы поиска | Логический, префиксный поиск, точная фраза, слова рядом, диапазоны, порядок слов, зоны | Логический поиск, поиск по префиксу (+ подстановочные знаки), точная фраза, слова рядом, диапазоны, приблизительный поиск | Логический поиск, поиск по префиксу (+ подстановочные знаки), точная фраза, слова рядом, диапазоны, приблизительный поиск | Логический, поиск по префиксу, точная фраза, слова рядом, диапазоны, приблизительный поиск |
Таблица 1 – Сравнение поисковых систем
Загрузка поисковой системы Sphinx
Прежде всего, мы должны скачать последнюю версию (на данный момент последняя версия 3. 2.1) поисковой системы Sphinx по следующей ссылке.
2.1) поисковой системы Sphinx по следующей ссылке.
Рисунок 1 – Ссылка для скачивания Sphinx
После загрузки пакета двоичных файлов мы должны извлечь его содержимое (как показано на изображении ниже, мы использовали 7zip в качестве инструмента для извлечения).
Рисунок 2 – Извлечение бинарного пакета
Настройка Sphinx
После извлечения пакета мы должны добавить папку с именем «данные» в извлеченный каталог для хранения индексов. Затем мы должны создать три папки с именами «index», «log» и «binlog» в созданном каталоге «data».
Рисунок 3 – Извлеченный каталог
Рисунок 4 – Добавление каталога «data»
Рисунок 5 – создание папок index, log и binlog
Полезно знать, что у Sphinx есть два основных сервиса:
- Индексатор : Эта служба используется для создания полнотекстовых индексов. По умолчанию Sphinx считывает исходные таблицы из файла конфигурации, расположенного в «<каталог установки>\etc\sphinx.conf».
- Searchd : Это демон, используемый для поиска созданных индексов. Требуется клиент для доступа к Sphinx API
 По умолчанию Sphinx считывает исходные таблицы из файла конфигурации, расположенного в «<каталог установки>\etc\sphinx.conf».
По умолчанию Sphinx считывает исходные таблицы из файла конфигурации, расположенного в «<каталог установки>\etc\sphinx.conf».Во-первых, мы должны создать службу Windows для запуска демона Searchd. Для этого мы можем использовать следующую команду из командной строки Windows:
E:\Sphinx\sphinx-3.2.1\bin\searchd –install –config
E:\Sphinx\sphinx-3.2.1\etc\sphinx.conf –название службы SphinxSearch
Рисунок 6 – Создание службы Windows через командную строку
Чтобы убедиться, что служба Windows создана успешно, мы можем перейти в Службы и проверить, добавлена ли служба SphinxSearch .
Рисунок 7 – Созданная служба Windows SphinxSearch
Обратите внимание, что до настройки файла конфигурации Sphinx нельзя запускать эту службу Windows.
Чтобы настроить Sphinx, мы должны создать файл «Sphinx.conf» в каталоге «E:\Sphinx\sphinx-3.2.1\etc». Затем мы должны сначала добавить следующие строки:
поиск
{
слушать = 9306:mysql41
pid_file = E:/sphinx/sphinx-3.2.1/data/searchd.pid
журнал = E:/sphinx/sphinx-3.2.1/data/log/log.txt
query_log = E:/sphinx/sphinx-3.2.1/data/log/query_log.txt
binlog_path = E:/sphinx/sphinx-3.2.1/data/binlog/
}
Опция listen указывает, что Sphinx будет использовать порт 9306 и протокол MySQL. Использование протокола MySQL позволяет подключаться к Sphinx как к обычной базе данных MySQL. Параметр pid_file указывает расположение файла .pid, который используется внутри. Настройка log и query_log указывают расположение файлов журнала, в которых записываются все события. Параметр binlog_path указывает расположение файлов, которые можно использовать для восстановления данных индекса в реальном времени после сбоя.
Чтобы запустить Sphinx, мы должны создать хотя бы один индекс в файле конфигурации. В этой статье мы определим поддельный индекс реального времени, добавив следующие строки:
индекс поддельный_индекс
{
тип = rt
путь = E:/sphinx/sphinx-3.2.1/data/index/fake_index
rt_field = фальшивое_поле
}
Теперь давайте попробуем использовать службу индексатора для построения индексов с помощью следующей команды:
E:\Sphinx\sphinx-3.2.1\bin\indexer –все –config
E:\sphinx\sphinx-3.2.1\etc\sphinx.conf –rotate –print-queries
Если вы используете Sphinx версии 3.2.1 при выполнении вышеуказанной команды, вы можете столкнуться со следующей ошибкой:
«Выполнение кода не может быть продолжено, поскольку ssleay32.dll не найден»
Рисунок 8. Служба индексатора выдает исключение
Причина этой ошибки в том, что в этом выпуске отсутствуют три сборки. Чтобы решить эту проблему, вы можете скачать предыдущую версию (3.1.1) и скопировать следующие сборки из каталогов bin:
Чтобы решить эту проблему, вы можете скачать предыдущую версию (3.1.1) и скопировать следующие сборки из каталогов bin:
- libeay32.dll
- msvcr120.dll
- ssleay32.dll
После копирования этих сборок, если мы попытаемся повторно выполнить команду выше, мы получим следующее сообщение (как показано на изображении ниже)
«FATAL: индексы не найдены в файле конфигурации»
Это означает, что индексатор успешно запущен, но не нашел реального индекса.
Рисунок 9 – Выходное сообщение службы индексатора
Теперь, если мы попытаемся запустить службу Windows SphinxSearch, она запустится успешно.
Некоторые полезные команды
Следующая таблица содержит некоторые важные команды:
Команда | Описание |
E:\Sphinx\sphinx-3. | Команда справки инструмента Searchd используется для просмотра всех доступных параметров. |
E:\Sphinx\sphinx-3.2.1\searchd.exe –config E:\Sphinx\sphinx-3.2.1\etc\sphinx.conf | Запустите демон Searchd, используя указанный файл конфигурации. |
E:\Sphinx\sphinx-3.2.1\bin\searchd.exe –config E:\Sphinx\sphinx-3.2.1\sphinx.conf –logdebug | Запустите демон Searchd, используя указанный файл конфигурации с включенным ведением журнала. |
E:\Sphinx\sphinx-3.2.1\bin\searchd —servicename SphinxSearch —удалить | Удалите существующую службу Windows SphinxSearch. |
 2.1\bin\searchd -h
2.1\bin\searchd -h
Таблица 2 – Важные команды Sphinx
Подключение к Sphinx с помощью клиента консоли MySQL
Поскольку Sphinx поддерживает протокол MySQL, мы можем использовать консольный клиент MySQL для подключения к Sphinx и выполнения команд.
Во-первых, нам нужно загрузить и установить движок базы данных MySQL на локальный компьютер. Вы можете загрузить сервер сообщества MySQL по следующей ссылке.
После установки MySQL Server откройте командную строку Windows и перейдите в каталог двоичных файлов MySQL (в этом примере это «C:\Program Files\MySQL\MySQL Server 8.0\bin») и используйте клиент MySQL для подключения к локальному хосту. порт 9306 (указанный в конфигурационном файле Sphinx) с помощью следующей команды:
mysql -h 127.0.0.1 -P 9306
Рисунок 10 – Подключение к Sphinx с помощью клиента MySQL
Как показано на изображении выше, версия сервера, указанная в выводе командной строки, — это версия поисковой системы Sphinx (3.2.1-dev (commit f152e0b8)), что означает, что соединение установлено успешно.
Теперь давайте попробуем выполнить команду «show status», чтобы просмотреть состояние сервера; результат показан на изображении ниже:
Рисунок 11 – Выполнение команды show status
Интернет-ресурсы
Недостатком Sphinx является то, что у него недостаточно онлайн-ресурсов. Есть два основных ресурса, где можно получить полезную информацию:
Есть два основных ресурса, где можно получить полезную информацию:
- Официальная документация: где объясняются все функции и инструменты Sphinx
- SphinxWiki: эта страница содержит множество тем и ресурсов, связанных со Sphinx.
- Введение в поиск с помощью книги Sphinx: краткое введение в Sphinx, в котором показано, как использовать этот инструмент для индексации данных и предоставления быстрых результатов как для простого, так и для сложного поиска.
Заключение
В этой статье мы рассказали о поисковой системе Sphinx и для чего она разработана. Затем мы объяснили, как загрузить и настроить этот инструмент в Windows. Наконец, мы показали, как использовать клиентскую консоль MySQL для подключения к движку Sphinx.
В следующей статье этой серии мы подробно поговорим о конфигурационных файлах Sphinx и объясним, как использовать его для создания полнотекстовых каталогов из баз данных SQL Server.
Содержание
| Начало работы с поисковой системой Sphinx |
| Создание полнотекстовых индексов с помощью поисковой системы Sphinx |
| Поиск Мантикоры: продолжение поисковой системы Sphinx |
- Автор
- Последние сообщения
Хади Фадлаллах
Хади — профессионал SQL Server с более чем 10-летним опытом. Его основная специализация — интеграция данных. Он является одним из ведущих участников ETL и SQL Server Integration Services на Stackoverflow.com. Кроме того, он опубликовал несколько серий статей о Biml, функциях SSIS, поисковых системах, Hadoop и многих других технологиях.
Его основная специализация — интеграция данных. Он является одним из ведущих участников ETL и SQL Server Integration Services на Stackoverflow.com. Кроме того, он опубликовал несколько серий статей о Biml, функциях SSIS, поисковых системах, Hadoop и многих других технологиях.
Помимо работы с SQL Server, он работал с различными технологиями обработки данных, такими как базы данных NoSQL, Hadoop, Apache Spark. Он сертифицированный профессионал MongoDB, Neo4j и ArangoDB.
На академическом уровне Хади имеет две степени магистра в области компьютерных наук и бизнес-вычислений. В настоящее время он является доктором философии. кандидат наук о данных, специализирующийся на методах оценки качества больших данных.
Хади действительно любит узнавать что-то новое каждый день и делиться своими знаниями. Вы можете связаться с ним на его личном сайте.
Просмотреть все сообщения Хади Фадлаллы
Последние сообщения Хади Фадлаллаха (посмотреть все)
Создание полнотекстовых индексов с помощью поисковой системы Sphinx
В ранее опубликованной статье Начало работы с поисковой системой Sphinx мы говорили о поисковой системе Sphinx и о том, как ее установить в операционной системе Windows. В этой статье мы поговорим о построении полнотекстовых индексов с помощью Sphinx. Мы рассмотрим семь тем:
В этой статье мы поговорим о построении полнотекстовых индексов с помощью Sphinx. Мы рассмотрим семь тем:
- Конфигурационный файл Sphinx.
- Определение источников данных
- Определение полнотекстовых индексов
- Варианты служб Indexer и Searchd
- Подготовка базы данных
- Индексация
- Использование связанных серверов для доступа к индексам
Конфигурационный файл Sphinx
Как мы упоминали в предыдущей статье, полнотекстовый индекс определяется в конфигурационном файле Sphinx.conf, который состоит из трех основных разделов:
- Определения источника данных: где мы должны указать данные, которые нам нужно индексировать; система управления базой данных, строка подключения, исходная таблица или команда SQL
- Определения полнотекстовых индексов : где мы должны определить полнотекстовые индексы, которые нам нужно построить
- Общепрограммные настройки : этот раздел посвящен службам индексатора и searchd
Определение источников данных
Каждый источник должен быть объявлен в файле конфигурации с помощью исходного блока, как показано ниже:
источник source_example
{
тип = …
sql_host = …
sql_user = …
sql_pass = …
sql_db = …
mssql_winauth = …
mssql_unicode = …
}
После ключевого слова «источник» вы должны написать имя источника (мы использовали source_example), затем в блоке источника вы должны определить следующие параметры:
- Тип : Тип источника данных. Известные типы: odbc, mssql (Microsoft SQL Server), mysql
- SQL_хост : Хост/экземпляр источника данных
- Sql_user : пользователь аутентификации
- Sql_pass : пароль аутентификации
- Sql_db : Имя базы данных
- Mssql_winauth : Использовать аутентификацию Windows?
- Mssql_unicode : Использовать Юникод?
 Известные типы: odbc, mssql (Microsoft SQL Server), mysql
Известные типы: odbc, mssql (Microsoft SQL Server), mysqlМы можем определить источник данных в одном блоке (классе) или вы можете написать несколько классов и использовать наследование, как мы будем делать в этой статье.
Во-первых, мы добавим «базовый» исходный блок, чтобы определить параметры строки подключения следующим образом:
исходная база
{
тип = MSSQL
sql_host = MyPC\SQLDATA
sql_пользователь =
sql_pass =
sql_db = AdventureWorks2017
mssql_winauth = 1
mssql_unicode = 1
}
Так как мы будем использовать аутентификацию Windows, то нет необходимости указывать параметры пользователя и пароля.
После определения класса строки подключения мы создадим еще один класс, наследуемый от «базового» класса, где мы укажем структуру данных. Каждый столбец может быть определен как атрибут или как поле.
Атрибуты используются для фильтрации; нет полнотекстовой индексации. Кроме того, поля имеют полнотекстовую индексацию и могут использоваться для фильтрации. Для каждого столбца мы должны указать тип данных, используя ключевые слова поисковой системы Sphinx.
В этом примере мы будем считывать название, цену и дату изменения из таблицы [Производство].[Продукт].
источник product_base: база
{
sql_field_string = имя
sql_attr_float = цена
sql_attr_timestamp = дата
}
Столбец имени определяется как поле, а цена и дата определяются как атрибуты.
После определения структуры данных мы должны определить команду SQL, используемую в качестве источника данных, используя параметр «sql_query» следующим образом:
исходный продукт : product_base
{
sql_query=\
Выберите \
ProductID как «id», \
Имя как «имя», \
ListPrice как «цена», \
ModifiedDate_TS как «дата» \
От Производство. Товар
Товар
}
Необходимо обязательно выбрать первичный ключ (ProductID) в качестве первого столбца в команде SQL, даже если он не определен в блоке структуры данных (столбец Id, как и определенные атрибуты, не индексируется в полнотекстовом режиме). Обратите внимание, что в полнотекстовом индексе можно определить только один основной запрос.
Как мы упоминали ранее, мы можем поместить весь блок кода ниже в один блок следующим образом:
исходный продукт
{
тип = MSSQL
sql_host = MyPC\SQLDATA
sql_пользователь =
sql_pass =
sql_db = AdventureWorks2017
mssql_winauth = 1
mssql_unicode = 1
sql_field_string = имя
sql_attr_float = цена
sql_attr_timestamp = дата
sql_query = \
Выберите \
ProductID как «id», \
Имя как «имя», \
ListPrice как «цена», \
ModifiedDate_TS как «дата» \
От Производство. Товар
Товар
}
Определение полнотекстовых индексов
Чтобы определить полнотекстовый индекс с помощью Sphinx, мы должны указать следующие свойства в блоке кода «индекс».
- Источник : класс источника данных, определенный в файле конфигурации.
- Путь : путь к каталогу, в котором будут храниться индексные файлы (этот путь должен существовать)
- Charset_type : Используемый индексный набор символов
Блок индексного кода должен выглядеть следующим образом:
Индекс продукта
{
источник = продукт
путь = E:/sphinx/sphinx-3.2.1/data/index/product
charset_type = utf-8
}
Обратите внимание, что в блоках индекса и источника данных можно использовать больше атрибутов. Мы можем узнать больше об этих атрибутах из официальной документации sphinx.
Опции служб индексатора и поиска
Как мы упоминали в предыдущей статье, у Sphinx есть два основных сервиса:
- Индексатор : служба, используемая для создания полнотекстовых индексов.
- Searchd : демон, используемый для поиска в созданных полнотекстовых индексах.
Как мы также упоминали, параметры службы Searchd должны быть определены в файле конфигурации следующим образом.
поиск
{
слушать = 9306:mysql41
pid_file = E:/sphinx/sphinx-3.2.1/data/searchd.pid
журнал = E:/sphinx/sphinx-3.2.1/data/log/log.txt
query_log = E:/sphinx/sphinx-3.2.1/data/log/query_log.txt
binlog_path = E:/sphinx/sphinx-3.2.1/data/binlog/
}
Эти параметры были объяснены в предыдущей статье в разделе «Настройка Sphinx».
Кроме того, мы можем настроить службу индексатора, используя исходный блок индексатора. Можно установить некоторые важные свойства, такие как:
- mem_limit : Лимит использования ОЗУ для индексации. Необязательно, по умолчанию 128M. Принудительный лимит использования памяти, который индексатор не превысит.
- max_iops : Максимальное количество операций ввода-вывода в секунду для регулирования ввода-вывода. Необязательно, по умолчанию 0 (неограниченно)

Индексатор
{
mem_limit = 520M
}
Подготовка базы данных
Стоит отметить, что Sphinx не может обрабатывать типы данных date и DateTime. Все поля даты должны быть преобразованы в UNIX_Timestamp (целочисленное значение). Мы можем использовать следующую функцию SQL для преобразования дат в Unix_Timestamp.
1 2 3 4 5 6 7 8 0 1 0 3 0 9 3 002 11 | CREATE FUNCTION [dbo].[UNIX_TIMESTAMP] ( @ctimestamp DATETIME ) ВОЗВРАЩАЕТ ЦЕЛОЕ ЧИСЛО AS BEG DECLARE @return INTEGERSELECT @return = DATEDIFF(SECOND, {D ‘1970-01-01’}, @ctimestamp) ВОЗВРАТ @return КОНЕЦ |
Чтобы использовать ModifiedDate в качестве атрибута в индексе поисковой системы Sphinx, мы должны создать новое поле типа integer (ModifiedDate_TS) и заполнить его с помощью функции, которую мы создали выше:
ALTER TABLE [Production]. ADD ModifiedDate_TS INT NULL
UPDATE [Production].[Product] SET ModifiedDate_TS = [dbo].[UNIX_TIMESTAMP](9ModifiedDate)0003 |
 [Product]
[Product]Результат должен быть следующим:
Рисунок 1. Преобразование столбца datetime в метку времени Unix
Индексация
Теперь мы должны открыть утилиту командной строки и использовать следующую команду, чтобы начать создание полнотекстовых индексов:
E:\Sphinx\sphinx-3.2.1\bin\indexer –all –config E:\sphinx\sphinx-3.2.1\etc\sphinx.conf –rotate –print-queries
Служба индексатора формирует следующие выходные данные:
Рисунок 2 – Создание полнотекстового индекса Sphinx
Если сообщения об ошибках не отображаются, полнотекстовый индекс создан успешно (рекомендуется проверять предупреждающие сообщения).
Чтобы проверить созданный индекс, мы можем открыть утилиту командной строки MySQL, используя следующую команду:
mysql -h 127. 0.0.1 -P 9306
0.0.1 -P 9306
Когда командная строка MySQL открыта, мы можем запросить созданный индекс, используя следующую команду:
Выберите * из продукта; |
Результат должен быть следующим:
Рисунок 3 – Запрос созданного полнотекстового индекса
Подключение к поисковой системе Sphinx с использованием объекта связанного сервера SQL Server
Последнее, что мы объясним в этой статье, — как использовать объект связанного сервера для подключения к поисковой системе Sphinx и выполнения запросов.
Чтобы установить соединение со Sphinx из студии управления SQL Server, мы должны сначала установить соединитель MySQL ODBC по следующей ссылке.
После завершения установки используйте следующие строки кода для создания связанного сервера со Sphinx:
EXEC master. GO EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N’SPHINX_SEARCH’, @useself=N’False’,@locallogin= NULL,@rmtuser=NULL,@rmtpassword=NULL GO |
 dbo.sp_addlinkedserver @server=N’SPHINX_SEARCH’, @srvproduct=N», @provider=N’MSDASQL’, @provstr=N’Driver={Драйвер ANSI ODBC 8.0 MySQL};Сервер=127.0.0. 0.1;Порт=9306,кодировка=UTF8;Пользователь=;Пароль=;OPTION=3′
dbo.sp_addlinkedserver @server=N’SPHINX_SEARCH’, @srvproduct=N», @provider=N’MSDASQL’, @provstr=N’Driver={Драйвер ANSI ODBC 8.0 MySQL};Сервер=127.0.0. 0.1;Порт=9306,кодировка=UTF8;Пользователь=;Пароль=;OPTION=3′После создания связанного сервера мы можем использовать опцию OPENQUERY() для отправки запросов движку Sphinx следующим образом:
SELECT * FROM OPENQUERY(SPHINX_SEARCH,’SELECT * from product’) |
Мы можем получить следующую ошибку:
Поставщик OLE DB «MSDASQL» для связанного сервера «SPHINX_SEARCH» вернул сообщение «[MySQL] [Драйвер ODBC 8.0 (a)] Драйвер не поддерживает версии сервера ниже 4.1.1».
Как упоминалось на официальном форуме поисковой системы Sphinx, эта ошибка возникает, поскольку версия сервера MySQL не указана в файле конфигурации, а значение по умолчанию ниже версии 4. 4.1. Чтобы решить эту проблему, мы добавили следующую строку в часы кода «searchd» в файле конфигурации:
4.1. Чтобы решить эту проблему, мы добавили следующую строку в часы кода «searchd» в файле конфигурации:
Рисунок 4 – Ошибка связанного сервера
mysql_version_string = 8.0.20
Весь блок должен выглядеть следующим образом:
поиск
{
слушать = 9306:mysql41
pid_file = E:/sphinx/sphinx-3.2.1/data/searchd.pid
журнал = E:/sphinx/sphinx-3.2.1/data/log/log.txt
query_log = E:/sphinx/sphinx-3.2.1/data/log/query_log.txt
binlog_path = E:/sphinx/sphinx-3.2.1/data/binlog/
mysql_version_string = 8.0.20
}
Обратите внимание, что мы можем использовать команду «mysql -V» , чтобы установить версию сервера MySQL на вашем компьютере.
Теперь мы должны перезапустить службу SphinxSearch и попытаться повторно запустить запрос. Результат должен выглядеть так:
Рисунок 5 – Запрос Sphinx с использованием связанного объекта сервера
Зачем подключаться к Sphinx через связанные серверы SQL Server? Ответ заключается в том, что во многих случаях нам нужно использовать полнотекстовые индексы Sphinx и интегрировать результат с другими данными, хранящимися в SQL Server. Обратите внимание, что подобный сценарий может быть отличным выбором, когда нам нужно свести к минимуму обработку баз данных SQL Server, а индексы хранятся на отдельной машине.
Обратите внимание, что подобный сценарий может быть отличным выбором, когда нам нужно свести к минимуму обработку баз данных SQL Server, а индексы хранятся на отдельной машине.
Заключение
В этой статье мы предоставили пошаговое руководство по созданию полнотекстовых индексов в базах данных SQL Server с помощью поисковой системы Sphinx. Мы рассмотрели несколько тем, таких как настройка файла конфигурации Sphinx, подготовка базы данных перед индексированием, построение полнотекстовых индексов и использование объекта связанного сервера SQL Server для подключения к Sphinx и выполнения запросов.
В следующей статье этой серии мы поговорим о поисковой системе Manticore, которая представляет собой отдельный продукт, созданный на основе второго релиза Sphinx (2.x).
Содержание
| Начало работы с поисковой системой Sphinx |
| Создание полнотекстовых индексов с помощью поисковой системы Sphinx |
| Поиск Мантикоры: продолжение поисковой системы Sphinx |
- Автор
- Последние сообщения
Хади Фадлаллах
Хади — профессионал SQL Server с более чем 10-летним опытом.