Содержание
Python — это медленно. Почему? / Хабр
В последнее время можно наблюдать рост популярности языка программирования Python. Он используется в DevOps, в анализе данных, в веб-разработке, в сфере безопасности и в других областях. Но вот скорость… Здесь этому языку похвастаться нечем. Автор материала, перевод которого мы сегодня публикуем, решил выяснить причины медлительности Python и найти средства его ускорения.
Общие положения
Как Java, в плане производительности, соотносится с C или C++? Как сравнить C# и Python? Ответы на эти вопросы серьёзно зависят от типа анализируемых исследователем приложений. Не существует идеального бенчмарка, но, изучая производительность программ, написанных на разных языках, неплохой отправной точкой может стать проект The Computer Language Benchmarks Game.
Я ссылаюсь на The Computer Language Benchmarks Game уже больше десяти лет. Python, в сравнении с другими языками, такими, как Java, C#, Go, JavaScript, C++, является одним из самых медленных. Сюда входят языки, в которых используется JIT-компиляция (C#, Java), и AOT-компиляция (C, C++), а также интерпретируемые языки, такие, как JavaScript.
Сюда входят языки, в которых используется JIT-компиляция (C#, Java), и AOT-компиляция (C, C++), а также интерпретируемые языки, такие, как JavaScript.
Тут мне хотелось бы отметить, что говоря «Python», я имею в виду эталонную реализацию интерпретатора Python — CPython. В этом материале мы коснёмся и других его реализаций. Собственно говоря, здесь мне хочется найти ответ на вопрос о том, почему Python требуется в 2-10 раз больше времени, чем другим языкам, на решение сопоставимых задач, и о том, можно ли сделать его быстрее.
Вот основные теории, пытающиеся объяснить причины медленной работы Python:
- Причина этого — в GIL (Global Interpreter Lock, глобальная блокировка интерпретатора).
- Причина в том, что Python — это интерпретируемый, а не компилируемый язык.
- Причина — в динамической типизации.
Проанализируем эти идеи и попытаемся найти ответ на вопрос о том, что сильнее всего оказывает влияние на производительность Python-приложений.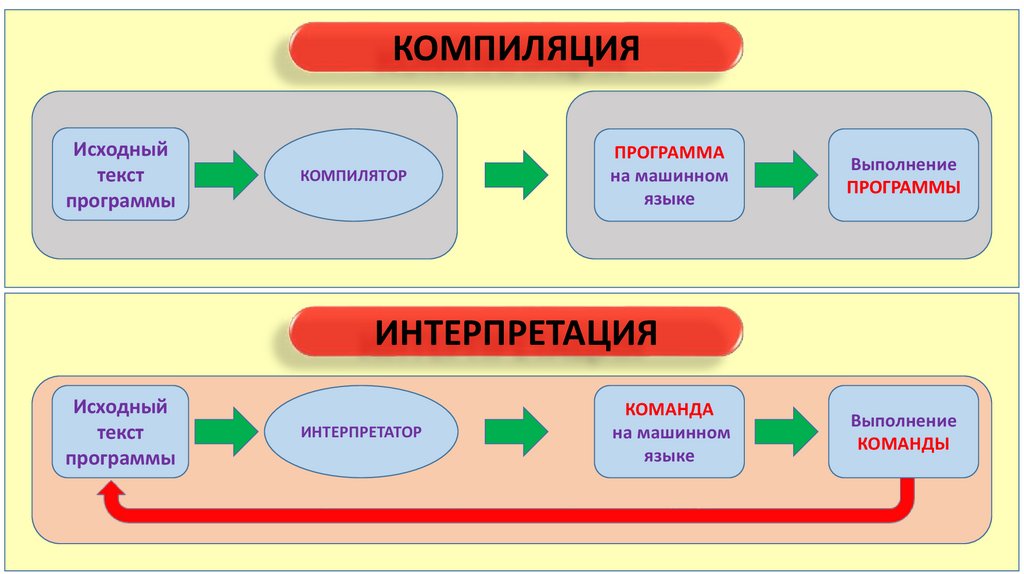
GIL
Современные компьютеры обладают многоядерными процессорами, иногда встречаются и многопроцессорные системы. Для того чтобы использовать всю эту вычислительную мощь, операционная система применяет низкоуровневые структуры, называемые потоками, в то время как процессы (например — процесс браузера Chrome) могут запускать множество потоков и соответствующим образом их использовать. В результате, например, если какой-то процесс особенно сильно нуждается в ресурсах процессора, его выполнение может быть разделено между несколькими ядрами, что позволяет большинству приложений быстрее решать встающие перед ними задачи.
Например, у моего браузера Chrome, в тот момент, когда я это пишу, имеется 44 открытых потока. Тут стоит учитывать то, что структура и API системы работы с потоками различается в операционных системах, основанных на Posix (Mac OS, Linux), и в ОС семейства Windows. Операционная система, кроме того, занимается планированием работы потоков.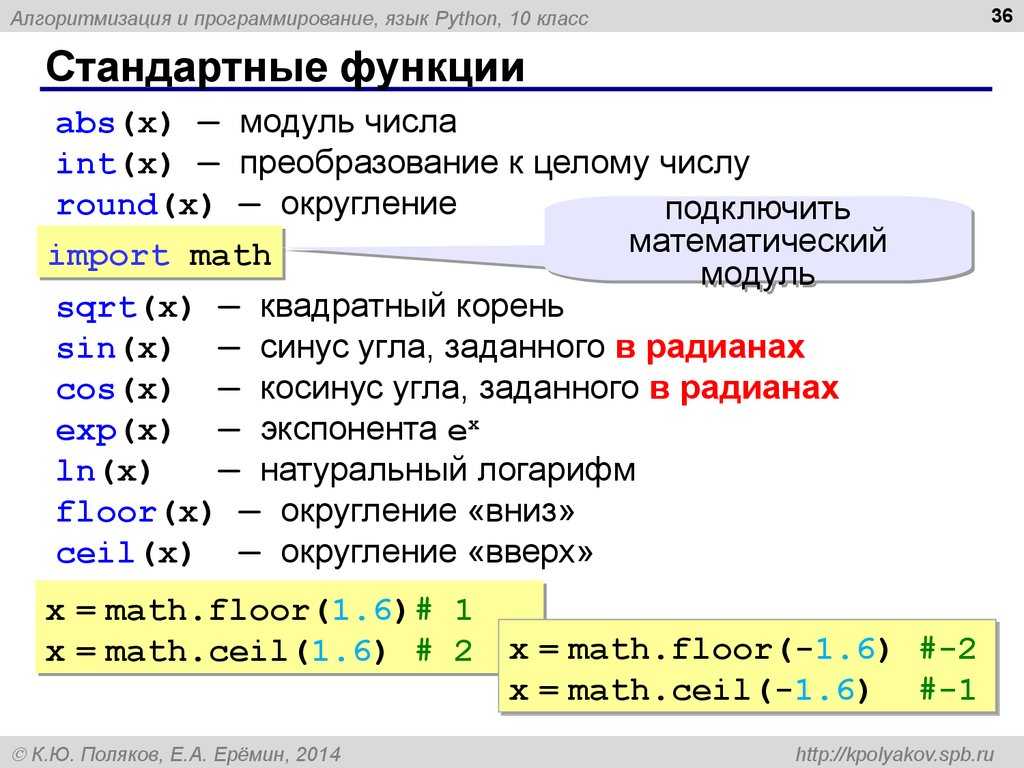
Если раньше вы не встречались с многопоточным программированием, то сейчас вам нужно познакомиться с так называемыми блокировками (locks). Смысл блокировок заключается в том, что они позволяют обеспечить такое поведение системы, когда, в многопоточной среде, например, при изменении некоей переменной в памяти, доступ к одной и той же области памяти (для чтения или изменения) не могут одновременно получить несколько потоков.
Когда интерпретатор CPython создаёт переменные, он выделяет память, а затем подсчитывает количество существующих ссылок на эти переменные. Эта концепция известна как подсчёт ссылок (reference counting). Если число ссылок равняется нулю, тогда соответствующий участок памяти освобождается. Именно поэтому, например, создание «временных» переменных, скажем, в пределах областей видимости циклов, не приводит к чрезмерному увеличению объёма памяти, потребляемого приложением.
Самое интересное начинается тогда, когда одними и теми же переменными совместно пользуются несколько потоков, а главная проблема тут заключается в том, как именно CPython выполняет подсчёт ссылок. Тут и проявляется действие «глобальной блокировки интерпретатора», которая тщательно контролирует выполнение потоков.
Тут и проявляется действие «глобальной блокировки интерпретатора», которая тщательно контролирует выполнение потоков.
Интерпретатор может выполнять лишь одну операцию за раз, независимо от того, как много потоков имеется в программе.
▍Как GIL влияет на производительность Python-приложений?
Если у нас имеется однопоточное приложение, работающее в одном процессе интерпретатора Python, то GIL никак на производительность не влияет. Если, например, избавиться от GIL, никакой разницы в производительности мы не заметим.
Если же, в пределах одного процесса интерпретатора Python, надо реализовать параллельную обработку данных с применением механизмов многопоточности, и используемые потоки будут интенсивно использовать подсистему ввода-вывода (например, если они будут работать с сетью или с диском), тогда можно будет наблюдать последствия того, как GIL управляет потоками. Вот как это выглядит в случае использования двух потоков, интенсивно нагружающих процессов.
Визуализация работы GIL (взято отсюда)
Если у вас имеется веб-приложение (например, основанное на фреймворке Django), и вы используете WSGI, то каждый запрос к веб-приложению будет обслуживаться отдельным процессом интерпретатора Python, то есть, у нас имеется лишь 1 блокировка на запрос. Так как интерпретатор Python запускается медленно, в некоторых реализациях WSGI имеется так называемый «режим демона», при использовании которого процессы интерпретатора поддерживаются в рабочем состоянии, что позволяет системе быстрее обслуживать запросы.
▍Как ведут себя другие интерпретаторы Python?
В PyPy есть GIL, он обычно более чем в 3 раза быстрее, чем CPython.
В Jython нет GIL, так как потоки Python в Jython представлены в виде потоков Java. Такие потоки используют возможности по управлению памятью JVM.
▍Как управление потоками организовано в JavaScript?
Если говорить о JavaScript, то, в первую очередь, надо отметить, что все JS-движки используют алгоритм сборки мусора mark-and-sweep. Как уже было сказано, основная причина необходимости использования GIL — это алгоритм управления памятью, применяемый в CPython.
Как уже было сказано, основная причина необходимости использования GIL — это алгоритм управления памятью, применяемый в CPython.
В JavaScript нет GIL, однако, JS — это однопоточный язык, поэтому в нём подобный механизм и не нужен. Вместо параллельного выполнения кода в JavaScript применяются методики асинхронного программирования, основанные на цикле событий, промисах и коллбэках. В Python есть нечто подобное, представленное модулем asyncio.
Python — интерпретируемый язык
Мне часто приходилось слышать о том, что низкая производительность Python является следствием того, что это — интерпретируемый язык. Подобные утверждения основаны на грубом упрощении того, как, на самом деле, работает CPython. Если, в терминале, ввести команду вроде python myscript.py, тогда CPython начнёт длительную последовательность действий, которая заключается в чтении, лексическом анализе, парсинге, компиляции, интерпретации и выполнении кода скрипта. Если вас интересуют подробности — взгляните на этот материал.
Если вас интересуют подробности — взгляните на этот материал.
Для нас, при рассмотрении этого процесса, особенно важным является тот факт, что здесь, на стадии компиляции, создаётся .pyc-файл, и последовательность байт-кодов пишется в файл в директории __pycache__/, которая используется и в Python 3, и в Python 2.
Подобное применяется не только к написанным нами скриптам, но и к импортированному коду, включая сторонние модули.
В результате, большую часть времени (если только вы не пишете код, который запускается лишь один раз) Python занимается выполнением готового байт-кода. Если сравнить это с тем, что происходит в Java и в C#, окажется, что код на Java компилируется в «Intermediate Language», и виртуальная машина Java читает байт-код и выполняет его JIT-компиляцию в машинный код. «Промежуточный язык» .NET CIL (это то же самое, что .NET Common-Language-Runtime, CLR), использует JIT-компиляцию для перехода к машинному коду.
В результате, и в Java и в C# используется некий «промежуточный язык» и присутствуют похожие механизмы. Почему же тогда Python показывает в бенчмарках гораздо худшие результаты, чем Java и C#, если все эти языки используют виртуальные машины и какие-то разновидности байт-кода? В первую очередь — из-за того, что в .NET и в Java используется JIT-компиляция.
Почему же тогда Python показывает в бенчмарках гораздо худшие результаты, чем Java и C#, если все эти языки используют виртуальные машины и какие-то разновидности байт-кода? В первую очередь — из-за того, что в .NET и в Java используется JIT-компиляция.
JIT-компиляция (Just In Time compilation, компиляция «на лету» или «точно в срок») требует наличия промежуточного языка для того, чтобы позволить осуществлять разбиение кода на фрагменты (кадры). Системы AOT-компиляции (Ahead Of Time compilation, компиляция перед исполнением) спроектированы так, чтобы обеспечить полную работоспособность кода до того, как начнётся взаимодействие этого кода с системой.
Само по себе использование JIT не ускоряет выполнение кода, так как на выполнение поступают, как и в Python, некие фрагменты байт-кода. Однако JIT позволяет выполнять оптимизации кода в процессе его выполнения. Хороший JIT-оптимизатор способен выявить наиболее нагруженные части приложения (такую часть приложения называют «hot spot») и оптимизировать соответствующие фрагменты кода, заменив их оптимизированными и более производительными вариантами, чем те, что использовались ранее.
Это означает, что когда некое приложение снова и снова выполняет некие действия, подобная оптимизация способна значительно ускорить выполнение таких действий. Кроме того, не забывайте о том, что Java и C# — это языки со строгой типизацией, поэтому оптимизатор может делать о коде больше предположений, способствующих улучшению производительности программ.
JIT-компилятор есть в PyPy, и, как уже было сказано, эта реализация интерпретатора Python гораздо быстрее, чем CPython. Сведения, касающиеся сравнения разных интерпретаторов Python, можно найти в этом материале.
▍Почему в CPython не используется JIT-компилятор?
У JIT-компиляторов есть и недостатки. Один из них — время запуска. CPython и так запускается сравнительно медленно, а PyPy в 2-3 раза медленнее, чем CPython. Длительное время запуска JVM — это тоже известный факт. CLR .NET обходит эту проблему, запускаясь в ходе загрузки системы, но тут надо отметить, что и CLR, и та операционная система, в которой запускается CLR, разрабатываются одной и той же компанией.
Если у вас имеется один процесс Python, который работает длительное время, при этом в таком процессе имеется код, который может быть оптимизирован, так как он содержит интенсивно используемые участки, тогда вам стоит серьёзно взглянуть на интерпретатор, имеющий JIT-компилятор.
Однако, CPython — это реализация интерпретатора Python общего назначения. Поэтому, если вы разрабатываете, с использованием Python, приложения командной строки, то необходимость длительного ожидания запуска JIT-компилятора при каждом запуске этого приложения сильно замедлит работу.
CPython пытается обеспечить поддержку как можно большего количества вариантов использования Python. Например, существует возможности подключения JIT-компилятора к Python, правда, проект, в рамках которого реализуется эта идея, развивается не особенно активно.
В результате можно сказать, что если вы, с помощью Python, пишете программу, производительность которой может улучшиться при использовании JIT-компилятора — используйте интерпретатор PyPy.
Python — динамически типизированный язык
В статически типизированных языках, при объявлении переменных, необходимо указывать их типы. Среди таких языков можно отметить C, C++, Java, C#, Go.
В динамически типизированных языках понятие типа данных имеет тот же смысл, но тип переменной является динамическим.
a = 1 a = "foo"
В этом простейшем примере Python сначала создаёт первую переменную a, потом — вторую с тем же именем, имеющую тип str, и освобождает память, которая была выделена первой переменной a.
Может показаться, что писать на языках с динамической типизацией удобнее и проще, чем на языках со статической типизацией, однако, такие языки созданы не по чьей-то прихоти. При их разработке учтены особенности работы компьютерных систем. Всё, что написано в тексте программы, в итоге, сводится к инструкциям процессора. Это означает, что данные, используемые программой, например, в виде объектов или других типов данных, тоже преобразуются к низкоуровневым структурам.
Python выполняет подобные преобразования автоматически, программист этих процессов не видит, и заботиться о подобных преобразованиях ему не нужно.
Отсутствие необходимости указывать тип переменной при её объявлении — это не та особенность языка, которая делает Python медленным. Архитектура языка позволяет сделать динамическим практически всё, что угодно. Например, во время выполнения программы можно заменять методы объектов. Опять же, во время выполнения программы можно использовать технику «обезьяньих патчей» в применении к низкоуровневым системным вызовам. В Python возможно практически всё.
Именно архитектура Python чрезвычайно усложняет оптимизацию.
Для того чтобы проиллюстрировать эту идею, я собираюсь воспользоваться инструментом для трассировки системных вызовов в MacOS, который называется DTrace.
В готовом дистрибутиве CPython нет механизмов поддержки DTrace, поэтому CPython нужно будет перекомпилировать с соответствующими настройками. Тут используется версия 3. 6.6. Итак, воспользуемся следующей последовательностью действий:
6.6. Итак, воспользуемся следующей последовательностью действий:
wget https://github.com/python/cpython/archive/v3.6.6.zip unzip v3.6.6.zip cd v3.6.6 ./configure --with-dtrace make
Теперь, пользуясь python.exe, можно применять DTRace для трассировки кода. Об использовании DTrace с Python можно почитать здесь. А вот тут можно найти скрипты для измерения с помощью DTrace различных показателей работы Python-программ. Среди них — параметры вызова функций, время выполнения программ, время использования процессора, сведения о системных вызовах и так далее. Вот как пользоваться командой dtrace:
sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’
А вот как средство трассировки py_callflow показывает вызовы функций в приложении.
Трассировка с использованием DTrace
Теперь ответим на вопрос о том, влияет ли динамическая типизация на производительность Python. Вот некоторые соображения по этому поводу:
Вот некоторые соображения по этому поводу:
- Проверка и конверсия типов — операции тяжёлые. Каждый раз, когда выполняется обращение к переменной, её чтение или запись, производится проверка типа.
- Язык, обладающей подобной гибкостью, сложно оптимизировать. Причина, по которой другие языки настолько быстрее Python, заключается в том, что они идут на те или иные компромиссы, выбирая между гибкостью и производительностью.
- Проект Cython объединяет Python и статическую типизацию, что, например, как показано в этом материале, приводит к 84-кратному росту производительности в сравнении с применением обычного Python. Обратите внимание на этот проект, если вам нужна скорость.
Итоги
Причиной невысокой производительности Python является его динамическая природа и универсальность. Его можно использовать как инструмент для решения разнообразнейших задач. Для достижения тех же целей можно попытаться поискать более производительные, лучше оптимизированные инструменты. Возможно, найти их удастся, возможно — нет.
Возможно, найти их удастся, возможно — нет.
Приложения, написанные на Python, можно оптимизировать, используя возможности по асинхронному выполнению кода, инструменты профилирования, и — правильно подбирая интерпретатор. Так, для оптимизации скорости работы приложений, время запуска которых неважно, а производительность которых может выиграть от использования JIT-компилятора, рассмотрите возможность использования PyPy. Если вам нужна максимальная производительность и вы готовы к ограничениям статической типизации — взгляните на Cython.
Уважаемые читатели! Как вы решаете проблемы невысокой производительности Python?
Почему Python не станет языком программирования будущего, даже если сейчас популярен — Разработка на vc.ru
Команда Mail.ru Cloud Solutions перевела колонку Rhea Moutafis «Why Python is not the programming language of the future». Автор перевода не всегда разделяет мнение автора статьи.
136 180
просмотров
Python появился в мире программирования довольно давно, но с начала 2010 годов переживает бум — он уже обогнал по популярности C, C#, Java и JavaScript. До каких пор будет сохраняться тенденция роста, когда Python заменит какой-то другой язык и почему?
До каких пор будет сохраняться тенденция роста, когда Python заменит какой-то другой язык и почему?
Автор колонки считает, что у Python есть несколько свойств, которые помогли ему стать популярным языком. Но есть и слабые места, которые уничтожат его в будущем.
Что делает Python популярным прямо сейчас
Популярность языка программирования можно отследить по динамике количества тегов на самом востребованном у разработчиков ресурсе — Stack Overflow. Так, судя по графику, рост Python начался с 2010 года, а стремительным он стал в 2015 году. В то время как R в течение последних нескольких лет находится на плато, а многие другие языки находятся в упадке. У такой популярности Python есть причины.
Популярность языков программирования на Stack Overflow
Время существования
Python можно смело назвать довольно старым языком — он появился в 1991 году, то есть практически 30 лет назад. За это время он постепенно собрал вокруг себя большое сообщество.
Если у вас появится какая-то проблема с этим языком, то решить ее, скорее всего, получится примитивным поиском в Google — наверняка кто-то уже опубликовал мануал с алгоритмом и примером кода.
Простота
Python можно смело рекомендовать как первый язык программирования. И дело не только в том, что он существует давно и поэтому по нему есть много хороших учебников. У него понятный синтаксис, похожий на обычный, «человеческий» язык. и еще он прощает ошибки.
Например, в нем не нужно указывать тип данных, достаточно просто объявить переменную. Из контекста Python поймет, является ли она целым числом, числом с плавающей запятой, логическим значением или чем-то еще. Это огромное преимущество для начинающих.
Если вам когда-либо приходилось программировать на C++, вы знаете, как это печально, когда программа не компилируется только потому, что вы где-то поменяли число с плавающей точкой на целое число.
Код Python довольно просто читать. Просто сравните синтаксис Python и C++.
Просто сравните синтаксис Python и C++.
Универсальность
Python существует так долго, что разработчики смогли сделать специальные библиотеки практически для любых целей. Например:
- Для многомерных массивов и высокоуровневых матриц используйте NumPy.
- Для расчетов в инженерном деле подойдет SciPy.
- Для исследования, анализа и манипулирования данными попробуйте Pandas.
- Для работы с искусственным интеллектом изучайте Scikit-Learn.
Если вам нужно решить какую-то вычислительную задачу, вероятно, что для нее уже есть специальная библиотека Python. Это позволяет языку оставаться в тренде последние годы, что видно по всплеску его использования в машинном обучении.
Недостатки Python, которые могут уничтожить этот язык
Вот недостатки, которые могут стать критичными для развития Python как самого популярного языка в будущем.
Скорость
Python медленный — в среднем, на операции на нем понадобится в два, а то и в десять раз больше времени, чем если бы вы выбрали другой язык. Для этого есть разные причины. Одна из них в том, что Python — язык с динамической типизацией. То есть на нем не нужно заранее определять тип данных, как в других языках. Конечно, это удобно разработчику, но такой подход требует большого резерва памяти для каждой переменной, чтобы она работала в любом случае. Соответственно, больше памяти означает больше времени на вычисления.
Python может выполнять только одну задачу за раз, как раз из-за того, что язык должен проверить тип данных. Параллельные процессы всё испортят. Для сравнения, обычный веб-браузер может запустить несколько десятков различных потоков одновременно.
Конечно, вы можете возразить — кого сейчас волнует эта скорость, ведь компьютеры и серверы стали такими мощными, что в итоге «медленно» означает выбор между загрузкой приложения за 0,01 секунды или 0,001 секунды.
Действительно, конечному пользователю нет разницы.
 Действительно, конечному пользователю нет разницы.
Действительно, конечному пользователю нет разницы.Области видимости
В Питоне используются динамические ограничения видимости. То есть для оценки выражения компилятор сначала ищет текущий блок, а затем последовательно все вызывающие функции.
Проблема такого подхода в том, что каждое выражение должно быть протестировано в каждом возможном контексте. Это, мягко говоря, утомительно и долго. Поэтому современные языки программирование используют в основном статическую область видимости.
Питон пытался перейти к статической области видимости, но ничего не вышло. Обычно внутренние области видимости — например, функции внутри функции — могут видеть и менять внешние области видимости. В Python внутренние области могут только видеть внешние области, но не менять их. Такой подход приводит к путанице.
Лямбда-функции
Несмотря на всю гибкость, использование лямбд в Python ограничено. Они могут быть только выражениями (expressions), но не инструкциями (statements). С другой стороны, объявления переменных и statements и есть инструкции. Проще говоря, добавление statements сделает лямбду многострочной, а синтаксис Python не позволяет так сделать.
С другой стороны, объявления переменных и statements и есть инструкции. Проще говоря, добавление statements сделает лямбду многострочной, а синтаксис Python не позволяет так сделать.
Это различие между expressions и statements довольно произвольно, и не встречается в других языках.
Пробелы
Питон хорошо подходит начинающим разработчикам — там используются пробелы и отступы для обозначения разных уровней кода. Это делает его визуально привлекательным и интуитивно понятным.
Другие языки, например C++, больше полагаются на фигурные скобки и точки с запятой. И пусть это не так визуально комфортно для новичков, зато делает код намного удобнее для поддержки. Для больших проектов это намного важнее.
Новые языки, например Haskell, так решают эту проблему — они полагаются на пробелы, но предлагают альтернативный синтаксис для тех, кто хочет обойтись без них.
Пробелы делают код более читаемым, но менее удобным в сопровождении Irvan Smith на Unsplash
Мобильная разработка
Сейчас мы наблюдаем массовый переход от компьютеров к смартфонам — уже понятно, что нам нужны языки, подходящие для мобильных приложений.
В Python такая возможность как бы есть — пакет под название Kivy. Но нужно учитывать, что Python не был создан для мобильных устройств. Использовать его можно, результат будет даже приемлемым, но зачем, когда можно взять более подходящий язык, созданный для разработки мобильных приложений. Например, фреймворки для кроссплатформенной мобильной разработки: React Native, Flutter, Iconic и Cordova.
Если вы планируете стать всесторонне развитым разработчиком, только знания Python недостаточно.
Ошибки во время выполнения (Runtime Errors)
Скрипты в Python компилируются каждый раз во время выполнения, вместо того, чтобы сначала компилироваться, а уже затем выполняться. Поэтому любая ошибка проявляется во время выполнения кода.
Это приводит к низкой производительности, временным затратам и большому количеству тестов. Тесты — это замечательно, особенно для новичков. Но для опытных разработчиков такая необходимость воспринимается как минус и приводит к нехватке производительности.
Что может заменить Python в будущем
На рынке языков программирования есть несколько его конкурентов:
- Rust — в нем так же, как и в Python, переменная не может быть случайно перезаписана. Но за счет концепции владения и заимствования в Rust решена проблема с производительностью. Кстати, именно Rust разработчики называют самым любимым языком.
- Go стоит рассматривать начинающим разработчикам. Он довольно прост в освоении, поддерживать код тоже не трудно. Плюс разработчики на GO сейчас одни из самых высокооплачиваемых.
- Julia подходит для крупномасштабных технических вычислений. Раньше для этого нужно было использовать Python или Matlab плюс библиотеки C++. После выхода Julia потребность в жонглировании языками отпала.
На рынке есть масса других полезных языков, но именно эти три закрывают слабые места Python. Rust, Go и Julia подходят для инновационных технологий, особенно для искусственного интеллекта. Сейчас их доля на рынке еще невелика, судя по тегам Stack Overflow, но тенденция роста уже есть.
Сейчас их доля на рынке еще невелика, судя по тегам Stack Overflow, но тенденция роста уже есть.
Динамика роста на Stack Overflow
Учитывая популярность Python в настоящее время, наверняка потребуется не меньше пяти, а то и десяти лет, чтобы любой из этих новых языков заменил его.
Какой из языков это будет — Rust, Go, Julia или новый язык будущего — пока трудно сказать Но учитывая проблемы с производительностью, которые являются основополагающими в архитектуре Python, каждый из новых языков найдет свое место.
Что еще почитать по теме:
- Язык Golang на пике популярности у IT-компаний.
- Необычный подход к автотестам для JavaScript и UI.
- Наш канал об IT в Телеграме.
Что мешает компилировать python?
спросил
Изменено
1 год, 7 месяцев назад
Просмотрено
9к раз
Я понимаю, что Python интерпретируемый язык, но производительность была бы намного выше, если бы он был скомпилирован.
- Что именно мешает компиляции python?
- Почему Python был разработан как интерпретируемый язык, а не компилируемый?
Примечание. Я знаю о файлах .pyc , но это байт-код, а не скомпилированные файлы.
- питон
6
Python, язык, как и любой язык программирования, сам по себе не компилируется и не интерпретируется. Стандартная реализация Python, называемая CPython, автоматически компилирует исходный код Python в байт-код и выполняет его через виртуальную машину, что обычно не подразумевается под «интерпретируемым».
Существуют реализации Python, которые компилируются в собственный код. Например, проект PyPy использует компиляцию JIT, чтобы получить преимущества простоты использования CPython в сочетании с производительностью собственного кода.
Cython — еще один гибридный подход, генерирующий и компилирующий код C на лету из диалекта Python.
Однако, поскольку Python является динамически типизированным, обычно нецелесообразно полностью предварительно компилировать все возможные пути кода, и он никогда не будет таким же быстрым, как основные языки со статической типизацией, даже если JIT-компилируется.
Python — это язык сценариев, часто используемый для таких вещей, как быстрое прототипирование или быстрая разработка, поэтому я предполагаю, что мыслительный процесс, лежащий в основе интерпретатора, а не компилятора, заключается в том, что он упрощает работу программиста в этих областях (за счет производительности). Однако ничто не мешает вам или другим писать компиляторы для Python; Facebook сделал что-то подобное для PHP, когда они написали HHVM для выполнения байт-кода скомпилированного Hack (их типизированный вариант PHP).
На самом деле, есть проекты, которые делают именно это с помощью Python. Cython — один из примеров, который приходит мне в голову (cython.org).
Я думаю, что код Python можно скомпилировать до некоторой степени, но мы не можем скомпилировать все в Python заранее. Это связано со слабо типизированным стилем Python, где вы можете изменить тип переменной в любом месте программы. Модификация Python, а именно Rpython, имеет более строгий стиль и, следовательно, может быть полностью скомпилирована.
Это связано со слабо типизированным стилем Python, где вы можете изменить тип переменной в любом месте программы. Модификация Python, а именно Rpython, имеет более строгий стиль и, следовательно, может быть полностью скомпилирована.
Python — это язык, созданный в первую очередь для написания читаемого и выразительного кода.
Python включает в себя многие функции всех своих соседей.
Давайте посмотрим, почему нам не нужен код Python для компиляции в сборку или машину.
Теперь давайте сравним родной язык с питоном. Возьмем С++.
Есть некоторые особенности python, например, вам не нужно делать какое-либо объявление типа в python. Это управляется интерпретатором Python. Но если вы попытаетесь реализовать ту же функцию на C++, это обременит компилятор. Он добавит код для проверки типа переменной каждый раз, прежде чем к ней будут обращаться для каких-либо целей. Даже компилятор Python выполняет ту же операцию. Это означает, что вы вообще не улучшаете производительность во время выполнения.
И большинство функций Python — это функции c, которые компилятор Python вызывает внутри, когда мы вызываем их в скрипте Python.
Основная причина, по которой нам не нужен компилятор Python, заключается в том, что он не повышает производительность в больших масштабах. Бесполезно писать программное обеспечение, которое увеличивает риск, а не снижает его. И Python чертовски быстр, когда весь его код находится в основной памяти.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Компиляция
— зачем компилировать код Python?
Плюсы:
Первое: мягкое, непреодолимое запутывание.
Во-вторых: если в результате компиляции получается значительно меньший файл, вы получите более быстрое время загрузки. Удобно для сети.
Третье: Python может пропустить этап компиляции. Быстрее при начальной загрузке. Хорошо для процессора и сети.
В-четвертых: чем больше вы комментируете, тем меньше будет файл .pyc или .pyo по сравнению с исходным файлом .py .
Пятое: конечный пользователь, имеющий в руках только файл .pyc или .pyo , с гораздо меньшей вероятностью представит вам ошибку, вызванную необратимым изменением, о котором он забыл вам сообщить.
Шестое: если вы нацелены на встроенную систему, получение меньшего размера
файл для встраивания может представлять собой значительный плюс, а архитектура стабильна, поэтому недостаток, описанный ниже, не вступает в игру.
Компиляция верхнего уровня
Полезно знать, что исходный файл Python верхнего уровня можно скомпилировать в файл . следующим образом: pyc
pyc
python -m py_compile myscript.py
Удаляет комментарии. Он оставляет нетронутыми строк документации . Если вы также хотите избавиться от строк документации (вы можете серьезно подумать о том, почему вы это делаете), то вместо этого скомпилируйте этот способ…
python -OO -m py_compile myscript.py
… и вы получите файл .pyo вместо файла .pyc ; одинаково распределяемый с точки зрения основной функциональности кода, но меньший по размеру урезанных строк документации (и менее понятный для последующего использования, если он изначально имел приличные строк документации ). Но см. недостаток три ниже.
Обратите внимание, что python использует дату файла .py , если она присутствует, чтобы решить, следует ли выполнять .py в отличие от .pyc или .pyo — поэтому отредактируйте файл . py, и
py, и .pyc или .pyo устаревают, и все преимущества, которые вы получили, теряются. Вам нужно перекомпилировать его, чтобы снова получить преимущества .pyc или .pyo , какими бы они ни были.
Недостатки:
Во-первых: в файлах .pyc и .pyo есть «волшебный файл cookie», который указывает системную архитектуру, в которой был скомпилирован файл python. Если вы распространяете один из этих файлов в среде другого типа, он сломается. Если вы раздаете .pyc или .pyo без связанного .py для перекомпиляции или touch , чтобы он заменял .pyc или .pyo , конечный пользователь также не может это исправить.
Второе: если строк документации пропущены с использованием параметра командной строки -OO , как описано выше, никто не сможет получить эту информацию, что может затруднить (или сделать невозможным) использование кода. )
)
Третий: Python -OO 9Параметр 0020 также реализует некоторые оптимизации в соответствии с параметром командной строки -O ; это может привести к изменениям в работе. Известные оптимизации:
-
sys.flags.optimize= 1 -
утверждениеоператоров пропущено -
__отладка__= Ложь
В-четвертых: если вы намеренно сделали исполняемый файл вашего скрипта Python с чем-то порядка #!/usr/bin/python в первой строке, это удаляется в .pyc и .pyo , и эта функциональность будет потеряна.
Пятое: с опцией -O, а также -OO, утверждения не компилируются, что устраняет источник проверки во время выполнения. Вы можете компенсировать это, используя try кроме , но это требует отказа от оператора assert для использования во всем, что будет компилироваться.
Шестое: несколько очевидно, но если вы скомпилируете свой код, это не только повлияет на его использование, но и уменьшит возможность для других учиться на вашей работе, часто сильно.