Содержание
нейросетевой перевод видео, картинок и текста / Хабр
Недавно мы впервые показали прототип переводчика видео в Яндекс.Браузере. Прототип работал с ограниченным числом роликов, но даже в таком виде вызвал интерес у пользователей. Теперь мы переходим к следующему ключевому этапу: в новых версиях Браузера и приложения Яндекс перевод доступен для всех англоязычных роликов на YouTube, Vimeo, Facebook и других популярных платформах.
Сегодня я не только расскажу о том, как устроен новый переводчик видео и какие у нас планы, но и поделюсь предысторией. Потому что считаю, что контекст важен: мы шли к этому шагу более десяти лет. Но если история вам вдруг не интересна, то можете сразу переходить к разделу «Перевод видео», где я описал работу технологии (а точнее, целого комплекса наших технологий) по шагам.
Десятью годами ранее
В 2011 году в Яндексе решалась судьба собственного полноценного браузера. На тот момент браузеров на любой цвет и вкус уже хватало. Но почти все они создавались «где-то там»: без оглядки на рунет и потребности тех пользователей, для которых английский язык и латиница не были родными. Поэтому мы решили создать свой браузер, который бы в числе прочего более полно поддерживал русский язык и наши с вами «региональные» потребности. Уверен, эта фраза звучит непонятно, поэтому ниже вас ждут два моих любимых примера. Они не связаны с переводом, но показательны.
Но почти все они создавались «где-то там»: без оглядки на рунет и потребности тех пользователей, для которых английский язык и латиница не были родными. Поэтому мы решили создать свой браузер, который бы в числе прочего более полно поддерживал русский язык и наши с вами «региональные» потребности. Уверен, эта фраза звучит непонятно, поэтому ниже вас ждут два моих любимых примера. Они не связаны с переводом, но показательны.
Пример с поиском по странице
Русский язык отличается богатой морфологией. Падежи, род, бо́льшая свобода в построении предложений — всё это приводит к разнообразию форм одного и того же слова и способов написать одну и ту же фразу. При этом классический поиск по странице, который работает одинаково во всех известных мне браузерах, умеет искать только точные вхождения слов в тексте. Наш поиск работает гибче и учитывает морфологию русского языка. Наглядный пример:
Кстати, этой фиче был посвящён мой самый первый пост на Хабре в 2013-м. Как будто вчера это было.
Как будто вчера это было.
Пример с адресной строкой
Что будет, если ввести в адресную строку [ь]? Скорее всего, браузер предложит вам отправиться в поисковую систему и поискать там мягкий знак. Но чего на самом деле хотел человек, который набрал [ь]? Ответ: вероятно, он привык ходить на [m.habr.com] или [maps.yandex.ru], но забыл переключить раскладку на клавиатуре.
В отличие от англоязычной аудитории, нам с вами приходится жить в мире двух алфавитов и постоянно переключаться между ними. Это приводит к ошибкам. А ошибки приводят к выбору: или ввести адрес заново, или совершить лишний переход в поисковую систему. Мы — за экономию времени, поэтому учли подобные ошибки с раскладкой ещё в самой ранней версии 2012 года. В таких ситуациях Яндекс.Браузер исправляет раскладку «в уме» и предлагает перейти не в поиск, а сразу и в один клик — на нужный сайт.
Таких примеров много, но думаю, суть я передал. В любом случае все они меркнут на фоне главной проблемы, которой мы бросили вызов: проблемы языкового барьера.
В любом случае все они меркнут на фоне главной проблемы, которой мы бросили вызов: проблемы языкового барьера.
Перевод текста
В интернете более миллиарда сайтов, но лишь около 9% — на русском языке. Интернет быстро растёт, но опять же — в основном за счёт иностранных сайтов. Информация, которая создаётся там, недоступна для большинства наших пользователей здесь.
Ещё тогда — в 2011-м — мы решили изменить это и помочь распространению знаний между пользователями. К счастью, в том же году появился Яндекс.Переводчик (тогда он ещё назывался Яндекс.Перевод). В его основе была технология статистического машинного перевода собственной разработки. Мы применили её и в Яндекс.Браузере. Да, мы не были первыми: Chrome уже умел подобное. Но в нашем случае переводчик работал с одной актуальной для рунета особенностью.
Большинство из нас с детства учит английский язык. Кто-то овладел им в совершенстве, но многие знают его достаточно фрагментарно, на уровне «читаю и пишу со словарём». Поэтому для нас особенно полезна возможность переводить не только страницы целиком, но и отдельные фразы и слова. Так мы пополняем словарный запас, продолжаем совершенствовать знания. Так оно и работает в Яндекс.Браузере с первого дня его существования.
Поэтому для нас особенно полезна возможность переводить не только страницы целиком, но и отдельные фразы и слова. Так мы пополняем словарный запас, продолжаем совершенствовать знания. Так оно и работает в Яндекс.Браузере с первого дня его существования.
Перевод картинок
Перевод текста — это хорошо. Но мы не должны забывать, что текст встречается ещё и на изображениях. Например, заметная часть сайтов израильских государственных организаций предпочитает именно такой способ размещения информации. Похожую картину можно увидеть на корейских, китайских, арабских сайтах. Аналогичная ситуация с техническими характеристиками товаров в иностранных интернет-магазинах.
Особенность этой задачки в том, что для её решения нужно объединить три технологии, которые отрабатывают последовательно. Сначала с помощью компьютерного зрения найти текст на картинке и распознать его в текстовый формат (OCR), затем с помощью машинного перевода перевести текст на русский язык, ну а вишенка на торте — рендеринг перевода поверх оригинальной картинки. Тут на каждом шаге можно закопаться в самостоятельную статью, поэтому я расскажу про самое неочевидное: про то, как мы боролись за экономию ресурсов.
Тут на каждом шаге можно закопаться в самостоятельную статью, поэтому я расскажу про самое неочевидное: про то, как мы боролись за экономию ресурсов.
Итак, можно взять исходную картинку, отправить в оригинальном виде из Браузера к нам на сервер, там проделать всю-всю работу, затем вернуть вариант с уже отрисованным переводом. Это самый простой для нас вариант. Но самый плохой для пользователя. Потому что картинки в интернете могут весить очень много. Их пересылка туда-обратно — это не только трафик, но и время, а значит, тормоза в продукте.
Чтобы не раздражать пользователей, мы пошли другим, сложным путём. На стороне Яндекс.Браузера уменьшаем картинки и переводим их в чёрно-белое представление. Кроме того, формат картинки меняем на WebP, который в среднем весит на 15–20% меньше, чем JPEG. В совокупности эти меры снизили вес картинок в несколько раз. При этом качество распознавания и перевода ощутимо не упало.
Этап объединения исходной картинки с переводом мы тоже перенесли на устройство. И вот тут возникла сложность. У Браузера есть исходная, цветная картинка и текст перевода. Если просто взять и наложить чёрный (белый?) текст на цветную картинку, то в большинстве случаев получится жуть. А мы не для того длину текста и переносы строк подгоняем под оригинал, чтобы испортить всю магию цветом шрифта.
И вот тут возникла сложность. У Браузера есть исходная, цветная картинка и текст перевода. Если просто взять и наложить чёрный (белый?) текст на цветную картинку, то в большинстве случаев получится жуть. А мы не для того длину текста и переносы строк подгоняем под оригинал, чтобы испортить всю магию цветом шрифта.
Итак, нам нужно подогнать цвет перевода под цвет оригинала. Но Яндекс.Браузер не различает текст и фон на исходной картинке, а значит, не может выбрать цвет для перевода. Наш серверный OCR видит текст, но не видит цвета, которые были потеряны в результате конвертации в ч/б.
Придумали следующее. На стороне OCR выделяем ключевые точки на картинке для фона и текста. Отправляем их координаты Браузеру вместе с переводом. Браузер на своей стороне по этим координатам определяет цвета. И уже затем выбирает для перевода цвет, который накладывается на фон.
Получилось в целом неплохо:
Перевод картинок работает на десктопе и устройствах с Android. В ближайшем будущем добавим и iOS. Ну и конечно же, продолжим совершенствовать распознавание и перевод.
Ну и конечно же, продолжим совершенствовать распознавание и перевод.
Перевод видео
У нас была давняя мечта: научиться переводить ещё и видео. Люди всё чаще смотрят образовательные и научно-популярные ролики, интервью, репортажи и многое другое. Бо́льшая часть подобных видео создаётся не на русском языке. Профессиональный перевод — редкость для свежего контента в интернете. В лучшем случае пользователи получают автоматически сгенерированные субтитры. Мы же решились замахнуться на большее: на автоматический перевод и озвучку любого видео прямо в браузере.
Как и в случае с картинками, для решения этой задачи одного только машинного перевода недостаточно. Качество перевода видео сильно зависит от качества распознавания и синтеза речи. К счастью, запуск Алисы и наших умных колонок здорово подстегнул развитие этих технологий в Яндексе. Настолько, что в сентябре прошлого года мы решились запустить проект. Казалось бы, остаётся только соединить все технологии в общий процесс. Какие тут могут быть сложности, не правда ли? Сейчас расскажу какие, описав процесс по шагам (а в конце рассказа вас ждёт простая наглядная схема).
Какие тут могут быть сложности, не правда ли? Сейчас расскажу какие, описав процесс по шагам (а в конце рассказа вас ждёт простая наглядная схема).
Шаг 1. Распознавание речи и предобработка текста
Пользователь нажимает кнопку переводчика, и мы начинаем обрабатывать ролик.
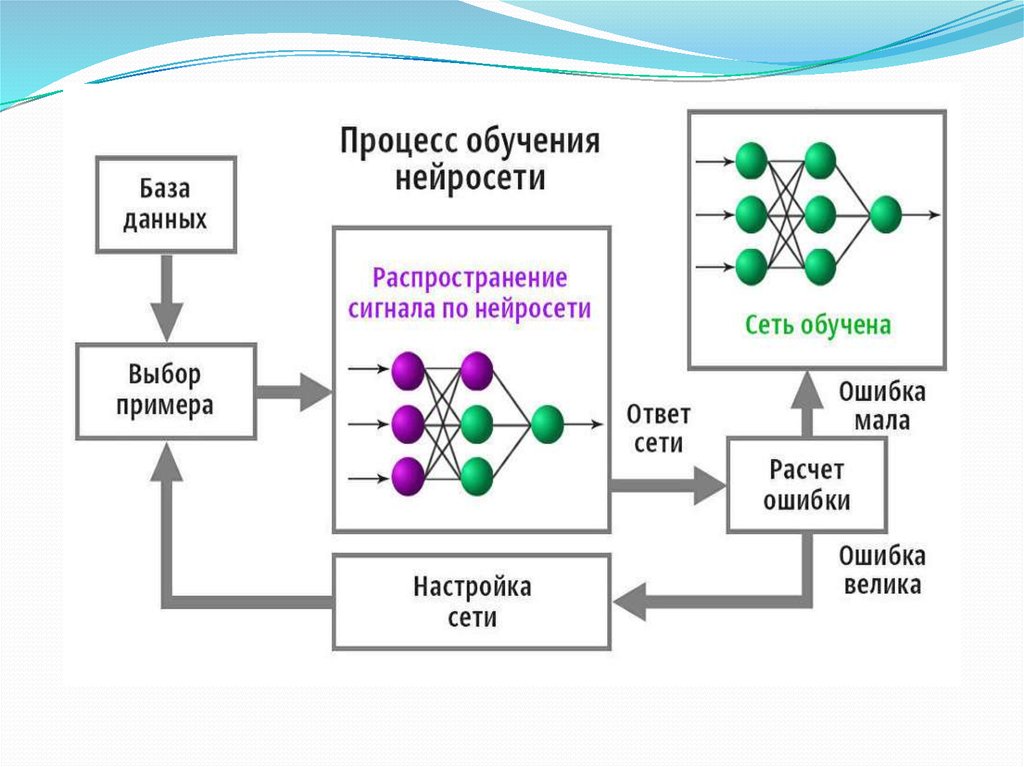
У нас на входе есть какое-то видео с какими-то голосами. Это может быть образовательный ролик с одним ведущим. Это может быть интервью из двух человек. А может быть и вовсе многоголосая дискуссия. Если просто перевести поток речи в текст, то получится сырой набор слов. Без запятых, без точек, без логической группировки слов в предложения, а предложений — в абзацы. И если прогнать такой текст через переводчик, то результат будет в полной мере соответствовать принципу GIGO. Поэтому мы не только превращаем аудио в текст, но и запускаем специальную нейросеть, которая вычищает мусор, группирует слова в смысловые сегменты и расставляет знаки препинания.
Кстати, мы опираемся не только на голос, но и на субтитры. Решили так: если человек загрузил к видео субтитры — то распознавание не используем: ведь тексты, написанные людьми, обычно более качественные, чем тексты на выходе у ASR. Но если субтитры сгенерированы автоматически, то игнорируем их и применяем свою технологию.
Решили так: если человек загрузил к видео субтитры — то распознавание не используем: ведь тексты, написанные людьми, обычно более качественные, чем тексты на выходе у ASR. Но если субтитры сгенерированы автоматически, то игнорируем их и применяем свою технологию.
При этом даже ручные субтитры нужно пропускать через ту самую нейросеть. Как минимум потому, что в них бывает много текста, который не нужен для синтеза голоса. Например, описание звуков (*аплодисменты*, *звук сирены* и т. д.) или указание имени спикера перед каждой фразой.
Кроме того, ручные субтитры могут быть нарезаны на строки не по границам фраз, а произвольно. Приходится пересобирать текст из разных строк. Покажу пример:
На скриншоте выше вы видите две строки субтитров. Раньше мы их так (построчно) и переводили. Но на самом деле это фрагменты двух предложений, начало и конец которых прячутся в соседних строках:
The output from my scanning electron microscope is than oscilloscope screen.
So I set that up and adjusted the contrast and everything.
И вот такие вещи надо уметь восстанавливать, иначе смысл перевода исказится до неузнаваемости.
Шаг 2. Биометрия
Итак, у нас на руках части неплохого текста и тайминги, которые нам ещё пригодятся. Что дальше? Перевод?
Нет: мы ещё больше усложнили себе задачку. Мы хотим, чтобы голоса у спикеров были разными: так проще воспринимать речь. Мы планируем адаптировать синтезированный голос к голосу спикера. Но на текущем этапе у нас более простое решение: мы определяем пол говорящего для каждой части текста, чтобы озвучивать их мужским или женским голосами.
Шаг 3. Машинный перевод
Теперь пора переводить. Тут в целом всё происходит достаточно стандартно, но с одной важной особенностью: мы передаём в модель переводчика ещё и информацию о спикерах, об их поле. Это нужно для того, чтобы в переводе разные спикеры говорили о себе или обращались к другим с корректным согласованием местоимений, глаголов и прилагательных.
Шаг 4. Синтез речи
Переходим к синтезу голоса. Сейчас у нас два голоса, дальше станет больше. Но самая большая сложность вовсе не в этом. Тексты на русском языке длиннее, чем на английском. Разница может составлять в среднем от 10 до 30%. Это значит, что при длительном воспроизведении мы рискуем словить существенный рассинхрон между тем, что говорит спикер на английском, и тем, что мы произносим на русском. Значит, нужно синхронизировать два потока речи. И нет, мы не стали фиксированно ускорять одну дорожку относительно другой.
Сейчас у нас два голоса, дальше станет больше. Но самая большая сложность вовсе не в этом. Тексты на русском языке длиннее, чем на английском. Разница может составлять в среднем от 10 до 30%. Это значит, что при длительном воспроизведении мы рискуем словить существенный рассинхрон между тем, что говорит спикер на английском, и тем, что мы произносим на русском. Значит, нужно синхронизировать два потока речи. И нет, мы не стали фиксированно ускорять одну дорожку относительно другой.
Помните, чуть выше я уже говорил про тайминги, которые мы получили после анализа исходной речи? Благодаря им мы знаем, какие фразы в какой момент должны произноситься. Это позволяет нам синхронизировать речь более гибко. Работает это так. Синтез речи — многоступенчатый процесс, в котором можно выделить два самых больших этапа. На первом мы с помощью нейросетей представляем текст в виде промежуточной спектрограммы. На втором с помощью других нейросетей превращаем спектрограммы в звук. Мы используем тайминги на первом этапе, чтобы сгенерировать спектрограмму нужной длительности. При этом ускорение в первую очередь достигается за счёт сокращения бесполезных пауз между фразами и словами. И только если этого недостаточно, алгоритм ускоряет сами фразы.
При этом ускорение в первую очередь достигается за счёт сокращения бесполезных пауз между фразами и словами. И только если этого недостаточно, алгоритм ускоряет сами фразы.
Шаг 5. Уведомления
Ура, у нас готов перевод, его можно включить в Яндекс.Браузере. Расходимся? А вот и нет. Мы выстроили целый каскад из тяжёлых технологий, которые последовательно сменяют друг друга. Требуется время на работу огромных нейросетей-трансформеров, даже с учётом их распараллеливания на GPU. К примеру, когда мы делали первый подход к снаряду и собрали быстрый внутренний прототип, то видео длиной в час переводили целых полчаса. Нам удалось оптимизировать всё это дело и ускорить переводчик в несколько раз, но это по-прежнему минуты, а не мгновения. Над мгновенным переводом мы продолжаем работать, а сейчас придумали такую схему: мы не только говорим пользователю, что нужно немного подождать, но и присылаем пуш-уведомление о готовности. Такое решение удобно: можно запросить перевод, закрыть вкладку и уйти заниматься своими делами. Браузер переведёт и напомнит.
Браузер переведёт и напомнит.
Вместо заключения
Вот наглядная схема всего процесса перевода видео:
Чуть ниже вас ждёт образец готового перевода на примере фрагмента лекции Джимми Уэйлса в Яндексе (оригинал тут). Этот фрагмент хорошо демонстрирует не только потенциал нашей технологии, но и проблемы, над которыми мы будем работать дальше.
Сейчас перевод видео доступен для английского языка и популярных сервисов. Он работает в Яндекс.Браузере для десктопа и Android, а также в приложении Яндекс для Android и iOS.
Хочется верить, что наше решение поможет пользователям хотя бы частично преодолеть языковой барьер и открыть для себя новый полезный контент, для которого ещё нет профессионального перевода. Мы продолжим совершенствовать перевод видео. У нас ещё очень много работы, поэтому любые идеи приветствуются.
«Яндекс» добавил в браузер закадровый перевод прямых трансляций на YouTube
- Технологии
- Ринат Таиров
Редакция Forbes
«Яндекс» создал технологию автоматического перевода прямых трансляций на YouTube. Нейросети умеют переводить трансляции на пяти языках и, как утверждает компания, начинают переводить предложение еще до того, как его закончили произносить. Дальше «Яндекс» планирует переводить стримы с других платформ, включая Twitch
«Яндекс» добавил в свой браузер технологию автоматического закадрового перевода прямых трансляций на YouTube, говорится в сообщении компании, которое поступило в Forbes.
Пока технология работает в режиме открытого бета-тестирования, поэтому работает с ограничениями и не на всех каналах. На сайте «Яндекса» в качестве примеров приведены каналы NASA и космической компании Илона Маска SpaceX, а также канала с записями речей на английском English Speeches и платформы для лекций TED, а также каналы Apple, Google и TechCrunch. Автоматический закадровый перевод дополнит технологии голосового перевода видео и интерактивных субтитров, которые компания запустила в прошлом году, говорится в сообщении.
На сайте «Яндекса» в качестве примеров приведены каналы NASA и космической компании Илона Маска SpaceX, а также канала с записями речей на английском English Speeches и платформы для лекций TED, а также каналы Apple, Google и TechCrunch. Автоматический закадровый перевод дополнит технологии голосового перевода видео и интерактивных субтитров, которые компания запустила в прошлом году, говорится в сообщении.
Материал по теме
Нейросети умеют синхронно переводить видео с пяти языков: английского, немецкого, французского, итальянского и испанского, заявил руководитель приложения «Яндекс» и «Яндекс Браузера» Дмитрий Тимко, его слова приводятся в сообщении. Дальше компания планирует расширить число доступных языков, в частности китайский и японский, а также переводить потоковые трансляции на других ресурсах, включая популярный у геймеров Twitch, сообщил Тимко. Нейросети «Яндекса» начинают переводить предложение еще до того, как его закончили произносить, для этого пришлось перестроить всю архитектуру закадрового перевода видео, добавил он. Одна нейросеть распознает аудио и превращает его в текст, другая — определяет пол говорящего по биометрии, третья — расставляет знаки препинания и выделяет из текста смысловые фрагменты, которые содержат законченную мысль, а четвертая — отвечает за перевод.
Одна нейросеть распознает аудио и превращает его в текст, другая — определяет пол говорящего по биометрии, третья — расставляет знаки препинания и выделяет из текста смысловые фрагменты, которые содержат законченную мысль, а четвертая — отвечает за перевод.
«Яндекс» представил прототип автоматического закадрового перевода видео в июле 2021 года, а в сентябре того же года запустил перевод видео на YouTube и другом популярном видеосервисе — Vimeo.
Российский сервис AllMyBlog в сентябре 2021 года подал в суд на «Яндекс», обвинив компанию в использовании его идеи при создании автоматического переводчика для видео. «Яндекс» возразил, что использовал только свои технологии, некоторые из которых были разработаны больше 10 лет назад. В октябре Арбитражный суд Москвы оставил иск без рассмотрения.
Ринат Таиров
Редакция Forbes
#Яндекс
#нейросети
Рассылка Forbes
Самое важное о финансах, инвестициях, бизнесе и технологиях
[PDF] Перевод видео на естественный язык с помощью глубоких рекуррентных нейронных сетей
title={Перевод видео на естественный язык с помощью глубоких рекуррентных нейронных сетей},
автор = {Субхашини Венугопалан, Хуэйцзюань Сюй, Джефф Донахью, Маркус Рорбах, Рэймонд Дж.
 Муни и Кейт Саенко},
Муни и Кейт Саенко},
название книги={NAACL},
год = {2015}
}
- Субхашини Венугопалан, Хуйцзюань Сюй, Кейт Саенко
- Опубликовано в NAACL 15 декабря 2014 г.
- Информатика
Решение проблемы заземления визуальных символов уже давно является целью искусственного интеллекта. Похоже, что эта область приближается к этой цели благодаря недавним прорывам в области глубокого обучения для естественного языка, основанного на статических изображениях. В этой статье мы предлагаем переводить видео непосредственно в предложения, используя единую глубокую нейронную сеть как со сверточной, так и с рекуррентной структурой. Описанных наборов видеоданных мало, и большинство существующих методов применялись к игрушечным доменам с…
Просмотреть в ACL
arxiv.org
Богатое визуальное и языковое представление с дополнительной семантикой для видеотитров естественные описательные предложения, основанные на видеоконтенте.
Система создания субтитров к видео на основе внимания для хинди
- Алок Сингх, Тудам Дорен Сингх, Шиваджи Бандйопадхьяй
Информатика
Мультимед.
 Сист.
Сист.- 2022
 Сист.
Сист.В этой работе используется гибридный механизм внимания, расширяющий механизм мягкого временного внимания семантическим вниманием, чтобы система могла решать, когда сосредоточить внимание на векторе визуального контекста и семантическом вводе.
SibNet: родственный сверточный кодировщик для видеотитров
- Sheng Liu, Zhou Ren, Junsong Yuan
Информатика
ACM Multimedia
- 2018
В этой работе представлен новый Sibling Convolutional Encoder (SibNet) для визуальных субтитров, который использует двухветвевую архитектуру для совместного кодирования видео и демонстрирует, что предлагаемый SibNet последовательно превосходит существующие методы по различным показателям оценки.
Иерархические и мультимодальные субтитры к видео: обнаружение и перенос мультимодальных знаний для зрения на язык
- Анан Лю, Н. Сюй, Юнкан Вонг, Джуннан Ли, Ютин Су, М. Канканхалли
Информатика
Вычисл. Вис. Изображение Понимание.
- 2017
 Сюй, Юнкан Вонг, Джуннан Ли, Ютин Су, М. Канканхалли
Сюй, Юнкан Вонг, Джуннан Ли, Ютин Су, М. КанканхаллиОбучение обобщению для новых композиций в понимании изображений
- Y. Atzmon, Jonathan Berant, Vahid Kezami, A. Globers Утверждается, что структурированные представления и композиционные разделения являются полезным эталоном для подписей к изображениям и поддерживают композиционные модели, которые отражают языковую и визуальную структуру.
Семантическая расширенная сеть кодировщика-декодера (SEN) для видеотитров
Семантическая расширенная сеть кодировщика-декодера, которая реализует стратегию слияния трех путей на стороне кодировщика, которая сочетает в себе дополнительные функции и использует идею обучения с подкреплением для расчета вознаграждения на основе семантические расчеты.
Обучение обобщенной видеопамяти для автоматического создания видеотитров
- Пу-Хи Чанг, А. Тан
Информатика
MIWAI
- 2018
Основанная на классе самоорганизующихся нейронных сетей, модель GVM способна постепенно изучать новые функции видео и демонстрирует свою конкурентоспособность по сравнению с другими современными методами.
Сверточные подписи к изображениям
В этом документе разрабатывается метод сверточных подписей к изображениям, который демонстрирует эффективность на сложном наборе данных MSCOCO и демонстрирует производительность на уровне базового уровня LSTM, но при этом имеет более быстрое время обучения по ряду параметров.
Описание видео на естественном языке с использованием NetVLAD и Attentional LSTM
С помощью достижений в области технологии глубокого обучения была разработана модель для создания описаний действий в видео на естественном языке путем извлечения ключевых функций для машинного понимания о видео.
видеоконтент с использованием 2D и 3D CNN.Моделирование иерархической памяти для видеотитров
- Джунбо Ван, Вэй Ван, Ян Хуан, Лян Ван, Т. Тан
Информатика
Мультимедиа ACM
- 2018
Предлагается модель иерархической памяти (HMM) — новая глубокая архитектура видеотитров, которая иерархически объединяет текстовую память, визуальную память и память атрибутов и может значительно уменьшить семантическое несоответствие между видео и предложением.
ПОКАЗАНЫ 1-10 ИЗ 49 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантность Наиболее влиятельные статьиНедавность
Покажи и расскажи: нейронный генератор подписей к изображениям
В этой статье представлена генеративная модель, основанная на глубоко рекуррентной архитектуре, которая сочетает в себе последние достижения в области компьютерного зрения и машинного перевода и может использоваться для создания естественных предложений, описывающих изображение.
Объединение визуально-семантических встроений с мультимодальными моделями нейронного языка
- Райан Кирос, Р. Салахтудинов, Р. Zemel
Компьютерная наука
ARXIV
- 2014
Эта работа по внедрению. который разделяет структуру предложения на его содержание, обусловленное представлениями, созданными кодировщиком, и показывает, что с линейными кодировщиками изученное пространство вложений фиксирует мультимодальные закономерности с точки зрения арифметики векторного пространства.
последовательность к изучению последовательности с нейронными сетями
- Ilya Sutskever, Oriol Vinyanals, Quoc V. LE
Компьютерная наука
NIPS
- 2014
Эта бумага ПРЕДОСТАВЛЯЕТСЯ. обучение, которое делает минимальные предположения о структуре последовательности и обнаруживает, что изменение порядка слов во всех исходных предложениях заметно улучшило производительность LSTM, поскольку это привело к появлению множества краткосрочных зависимостей между исходным и целевым предложением, что упростило задачу оптимизации.
.Integrating Language and Vision to Generate Natural Language Descriptions of Videos in the Wild
- Jesse Thomason, Subhashini Venugopalan, S. Guadarrama, Kate Saenko, R. Mooney
Computer Science
COLING
- 2014
В этой статье предлагается стратегия создания текстовых описаний видео с использованием графа факторов для объединения визуальных обнаружений с языковой статистикой, а также используются современные системы визуального распознавания для получения достоверной информации об объектах, действиях и сценах, присутствующих в видео. .
Перевод видеоконтента на естественный язык Описания
В этом документе представлено богатое семантическое представление визуального контента, включая, например. маркирует объект и деятельность и предлагает сформулировать генерацию естественного языка как задачу машинного перевода, используя семантическое представление в качестве исходного языка и сгенерированные предложения в качестве целевого языка.
Долговременные рекуррентные сверточные сети для визуального распознавания и описания. художественные модели для распознавания или генерации, которые определяются и/или оптимизируются отдельно.
Объясните изображения с мультимодальными рецидивирующими нейронными сетями
- Junhua Mao, W. Xu, Yi Yang, Jiang Wang, A. Yuille
Computer Science
Model распределения вероятностей генерации слова с учетом предыдущих слов и изображения, а также обеспечивает значительное улучшение производительности по сравнению с современными методами, которые напрямую оптимизируют целевую функцию ранжирования для поиска.
Тысяча кадров всего в нескольких словах: языковое описание видео с помощью скрытых тем и сшивки разреженных объектов
В этом документе предлагается гибридная система, состоящая из низкоуровневой мультимодальной модели скрытой темы для начальной аннотации ключевых слов и среднего уровня детекторов понятий.
и модуль высокого уровня для создания окончательных языковых описаний, который фиксирует наиболее релевантное содержание видео в описании на естественном языке.Совместное моделирование глубокого видео и композиционного текста для объединения видения и языка в единой структуре
- Ran Xu, Caiming Xiong, Wei Chen, Jason J. Corso
Компьютерные науки
AAAI
- 2015
- 2015
генерация триплетов и естественных предложений, и лучше, чем CCA, в задачах поиска видео и языкового поиска.
От надписей к визуальным понятиям и обратно
В этой статье используется множественное обучение для обучения визуальных детекторов словам, которые обычно встречаются в подписях, включая множество различных частей речи, таких как существительные, глаголы и прилагательные, и разрабатывается метод максимальной энтропии. языковая модель.
Как машинный перевод упрощает локализацию на Frazier
Помимо звукового описания, VIDEO TO VOICE активно участвует в других областях, связанных с доступностью цифровых медиа.
Чтобы сломать языковые барьеры, Frazier включает службу нейронного машинного перевода. Благодаря более низким затратам и меньшему количеству задержек этот вариант является популярным выбором для клиентов, желающих создавать видеоконтент на нескольких языках.Шутки об инструментах онлайн-перевода , так что последнее десятилетие. Когда в начале 2000-х появились первые службы машинного перевода в реальном времени, их высмеивали за сомнительные результаты. В лучшем случае забавные, а в худшем — дико оскорбительные переводы, созданные таким образом, часто были слишком буквальными и отклонялись от предполагаемого значения исходного текста.
Но по мере того, как в последние годы технологии совершенствовались, в социальных сетях стало заметно меньше мемов о неудачных переводах. Последние разработки в области машинного перевода включают нейронные сети . Это подмножества машинного обучения, которые пытаются имитировать работу человеческого мозга в процессе перевода.
Заинтригованы? Читайте дальше, чтобы узнать все, что вам нужно знать об индустрии лингвистических услуг, о том, где у провайдеров возникают проблемы, и о том, как машинный перевод упрощает локализацию.
Почему важен перевод?
Все просто: нам всем нужен доступ к контенту и информации, которые естественным образом передаются на нашем родном языке.
С точки зрения бизнеса, эффективное общение помогает компаниям улучшить имидж своего бренда, повысить удовлетворенность клиентов и повысить производительность труда персонала.
Помимо удовлетворения существующих клиентов, переведенный контент может помочь компаниям выйти на другие рынки. Это подтверждается выводами Консультативного отчета о здравом смысле за 2020 год «Не умею читать, не буду покупать»:
- 80% людей предпочитают совершать покупки на своем родном языке
- 85% людей решают совершить покупку, когда информация представлена на их родном языке
- 72% людей будут покупать только те товары, которые продаются на предпочитаемом ими языке
- 74% людей с большей вероятностью сделают повторную покупку, если послепродажное обслуживание будет на их родном языке
- 73% людей хотят, чтобы обзоры продуктов были на их родном языке
Каково текущее положение дел в отрасли лингвистических услуг?
Глобальная индустрия лингвистических услуг была оценена в 49 долларов США.
0,6 миллиарда в 2019 году. Прогнозируется, что к 2024 году рынок достигнет 77 миллиардов долларов, чему будет способствовать рост спроса на видеоконтент, в частности .К 2022 году 82% интернет-трафика будет составлять видеоконтент, что в 15 раз больше, чем в 2017 году. В настоящее время более 4 из 5 компаний используют видео как часть своих маркетинговых кампаний.
Чем больше видеоконтента, тем больше требуется переводов и локализаций . Но по мере роста производства локализуется все меньшая часть видео.
Почему недостаточно контента переводится или локализуется?
Поставщики языковых услуг не в состоянии справиться с нагрузкой.
В основном это связано с факторами времени и стоимости .
Традиционный рабочий процесс обычно имеет следующую структуру:
- клиент поручает переводчику выполнить перевод
- поставщик языковых услуг назначает переводчика для выполнения перевода
- готовый перевод рецензируется вторым переводчиком
- поставщик языковых услуг доставляет перевод клиенту
Сам перевод обычно занимает больше всего времени.
Если есть сжатые сроки, потенциальные клиенты могут вообще отказаться от перевода.Деньги — еще один важный фактор.
Средняя ставка переводчика варьируется от 0,07 до 0,15 доллара за слово, поэтому у потенциальных клиентов может не хватить бюджета для выполнения перевода.
Если необходимо перевести звук, клиент также должен учесть расходы на озвучку и студию для новой записи.
Вот почему поставщики лингвистических услуг должны использовать машинный перевод , чтобы удовлетворить спрос.
Что такое машинный перевод?
Машинный перевод автоматически преобразует исходный текст с одного языка в целевой текст на другом языке.
Зачем нужен машинный перевод?
Машинный перевод экономит время и деньги поставщика языковых услуг, повышая вероятность того, что потенциальные клиенты захотят перевести свой контент.
При машинном переводе целевой текст готов за секунд. Это также устраняет затраты, связанные с фактическим этапом перевода.
Процесс прост. После того, как перевод сгенерирован, постредактор просматривает текст.
Чем занимается постредактор?
Постредактирование — это этап, на котором лингвисты вносят необходимые изменения в перевод готового продукта.
Есть ли проблемы с качеством машинного перевода?
Первые технологии машинного перевода были разработаны с использованием системы, основанной на правилах. Это означает, что инструмент будет переводить предложения слово в слово на основе словарей и правил грамматики.
К сожалению, подход, основанный на правилах, часто не учитывал контекст и общий смысл текста. Эти ошибки часто высмеиваются в юмористических мемах с ошибками перевода, которые циркулируют на кликбейт-сайтах.
Система, основанная на правилах, с тех пор уступила место более совершенным моделям, таким как статистический машинный перевод и нейронный машинный перевод.
Что такое статистические и нейронные модели машинного перевода?
Как статистический машинный перевод (SMT), так и нейронный машинный перевод (NMT) основаны на искусственном интеллекте и используют корпусов .
Корпуса — это тексты, написанные и переведенные профессионалами на разные языки, которые можно сравнивать друг с другом.
Например, документы парламента ЕС должны быть переведены на язык каждого государства-члена. Таким образом, эти параллельные источники данных являются хорошим примером типов текстов, которые можно использовать в корпусах.
Как все это работает?
SMT сопоставляет эквивалентные слова и выражения в текстах, а NMT учится на них с помощью нейронных сетей .
Нейронные сети — это подмножество машинного обучения, которое пытается воспроизвести то, как работает мозг при переводе между двумя языками.
NMT учитывает контекст , в котором используется слово, вместо того, чтобы просто переводить каждое слово отдельно.
Например, технология распознает, используется ли в тексте формальный регистр или сленг. Если пользователь вносит какие-либо исправления, система также обновляет себя с новым переводом.
В результате эти сложные системы обеспечивают высокое качество результатов и с тех пор стали отраслевым стандартом .
Кто является основными игроками в машинном переводе?
В настоящее время на рынке доминируют следующие поставщики:
Переводчик Google:
- запущен в 2006 г.
- около 100 миллиардов слов переводится в день
- автоматическое определение для автоматического перевода веб-страниц
Amazon Translate:
- запущен в 2017 году
- настраиваемые параметры локализации веб-сайта
- Ограничение на 2 миллиона символов в месяц в бесплатной версии
Переводчик Microsoft:
- запущен в 2009 г.
- 58% клиентов находятся в США
- Ограничение на 2 миллиона символов в месяц в бесплатной версии
DeepL:
- запущен в 2017 году
- большой корпус предложений и идиом, переведенных человеком, для высокого качества
- Ограничение на 5000 символов на перевод в бесплатной версии
Какие языки обслуживаются?
DeepL недавно расширила свои услуги, чтобы поддерживать 23 языка, и обещает, что в будущем их станет больше.
Amazon Translate поддерживает 54 языка и диалекта, что составляет 2804 языковых пары.
Microsoft Translator поддерживает 90 языков и диалектов, доступных на платформе.
Что касается количества, Google Translate выходит на первое место со 109 языками на выбор.
Каковы показатели качества крупнейших поставщиков машинного перевода?
Трудно определить, какой поставщик обеспечивает наилучшие результаты.
Одним из ключевых факторов является качество обучающих данных, доступных для конкретной языковой пары. Обучающие данные — это большой набор данных, который используется для обучения моделей машинного обучения.
Штатные переводчики на веб-сайте фразы.com провели слепой тест, чтобы оценить целевые тексты, созданные поставщиками машинного перевода. У каждой пары было разное первое предпочтение:
Производительность машинного перевода
Языковая пара 1-е предпочтение 2-е предпочтение 3-е предпочтение 4-е предпочтение Английский на французский Майкрософт Глубокий Гугл Амазонка с английского на немецкий Глубокий Майкрософт Амазонка Гугл Английский на русский Гугл Амазонка Майкрософт Глубокий Как показывают результаты, очень важно внимательно изучить и прочитать отзывы, чтобы найти лучшего поставщика услуг для вашей языковой пары.
Не пропустите и подпишитесь на нашу рассылку сегодня.
Будьте первыми, кто получит свежий контент прямо из печати. Освойте аудиоописание, преобразующее текст в речь, узнайте, как его использовать, и поднимите свои навыки на новый уровень.
Вы можете отказаться от подписки в любое время неофициально (например, по ссылке в электронном письме).
Значит, ВИДЕО В ГОЛОС работает с нейронным машинным переводом?
Технология нейронного машинного перевода была интегрирована в Frazier.
Этот вариант особенно популярен среди клиентов, которым необходимо создавать многоязычные версии своих видео .
Например, швейцарские компании часто предоставляют контент на четырех национальных языках: немецком, французском, итальянском и ретороманском.
Во Frazier пользователи могут за считанные секунды создать версию видео на другом языке.
- Пу-Хи Чанг, А.
 Тан
Тан видеоконтент с использованием 2D и 3D CNN.
видеоконтент с использованием 2D и 3D CNN.
 .
.
 и модуль высокого уровня для создания окончательных языковых описаний, который фиксирует наиболее релевантное содержание видео в описании на естественном языке.
и модуль высокого уровня для создания окончательных языковых описаний, который фиксирует наиболее релевантное содержание видео в описании на естественном языке. Чтобы сломать языковые барьеры, Frazier включает службу нейронного машинного перевода. Благодаря более низким затратам и меньшему количеству задержек этот вариант является популярным выбором для клиентов, желающих создавать видеоконтент на нескольких языках.
Чтобы сломать языковые барьеры, Frazier включает службу нейронного машинного перевода. Благодаря более низким затратам и меньшему количеству задержек этот вариант является популярным выбором для клиентов, желающих создавать видеоконтент на нескольких языках.
 0,6 миллиарда в 2019 году. Прогнозируется, что к 2024 году рынок достигнет 77 миллиардов долларов, чему будет способствовать рост спроса на видеоконтент, в частности .
0,6 миллиарда в 2019 году. Прогнозируется, что к 2024 году рынок достигнет 77 миллиардов долларов, чему будет способствовать рост спроса на видеоконтент, в частности .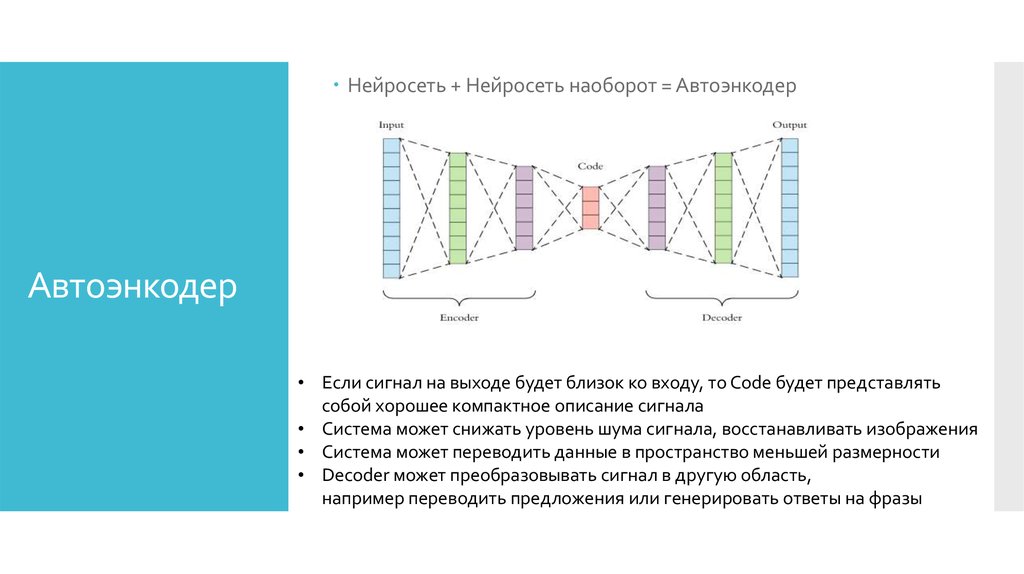 Если есть сжатые сроки, потенциальные клиенты могут вообще отказаться от перевода.
Если есть сжатые сроки, потенциальные клиенты могут вообще отказаться от перевода.