Содержание
HighLoad Junior Блог
Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно
появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.
Немного расскажу о себе – я работаю в компании WebAPI в 2GIS-е, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых
мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка – 25 млн. активных пользователей в месяц, и в среднем
нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем – это большое количество данных. Когда вы разрабатываете тот или иной проект,
у вас в любой момент времени может случиться так, что данных становится очень много. Если бизнес работает, он приносит деньги. Соответственно, данных
Если бизнес работает, он приносит деньги. Соответственно, данных
больше, денег больше, и с этими данными что-то нужно делать, потому что эти запросы очень долго начинают выполняться, и у нас сервер начинает не вывозить.
Одно из решений, что с этими данными делать – это масштабирование базы данных.
Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад «Как устроена MySQL репликация» Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?
У нас есть большая таблица, например, с пользователями – у нас очень много пользователей. Партицирование – это когда мы одну большую таблицу разделяем на
много маленьких по какому-либо принципу.
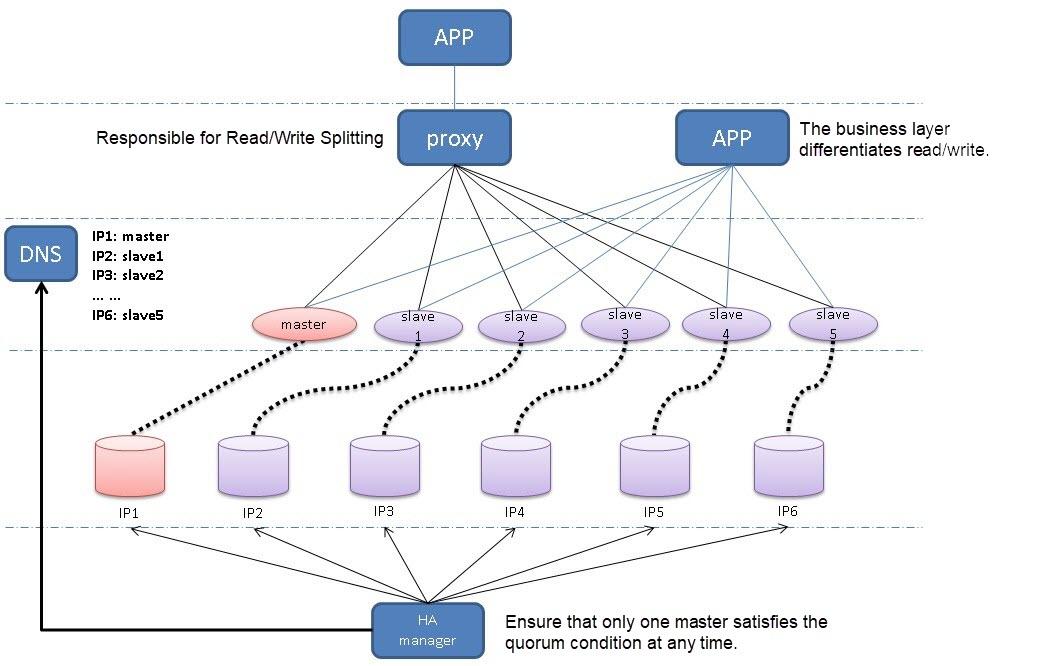
С горизонтальным шардингом все примерно так же, но при этом у нас таблички лежат в разных базах на других инстансах.
Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а.
Давайте рассмотрим простую табличку, наверняка, практически в 99% проектов такая табличка есть – это новости.
У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок – совершенно
стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
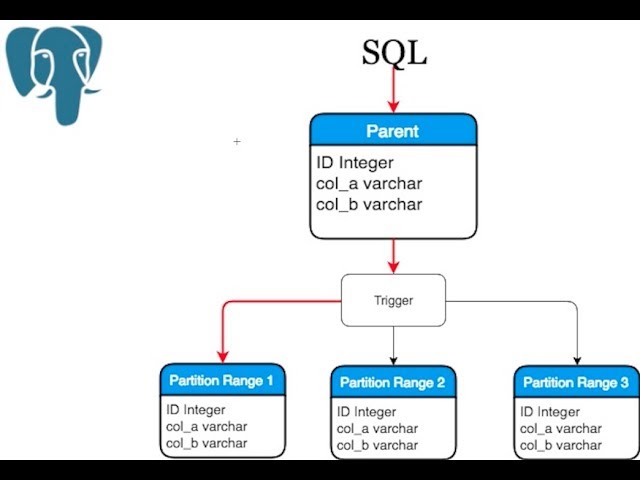
Всего нужно будет сделать 2 действия над табличкой – это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News
будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей. Наследованная
таблица будет иметь все колонки родителя – той базовой таблицы, которую мы указали, а также она может иметь свои колонки, которые мы дополнительно туда
добавим. Она будет полноценной таблицей, но унаследованной от родителя, и там не будет ограничений, индексов и триггеров от родителя – это очень важно.
Если вы на базовой таблице насоздаете индексы и унаследуете ее, то в унаследованной таблице индексов, ограничений и триггеров не будет.
2-ое действие, которое нужно сделать – это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.
Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.
В данном случае признак – это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу.
Какие типы проверок бывают для партицированных таблиц?
Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений – это вхождение в список, например, у нас может быть 3
автора новости именно в этой партиции, и бывает диапазон значений – это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.
И так просто его сделать можно. Но нельзя.
Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое.
Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую – между 200 и 300.
В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет.
Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во
вторую больше 200, но не 200, и меньше либо равно 300.
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия
проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую – с рейтингом 100.
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись.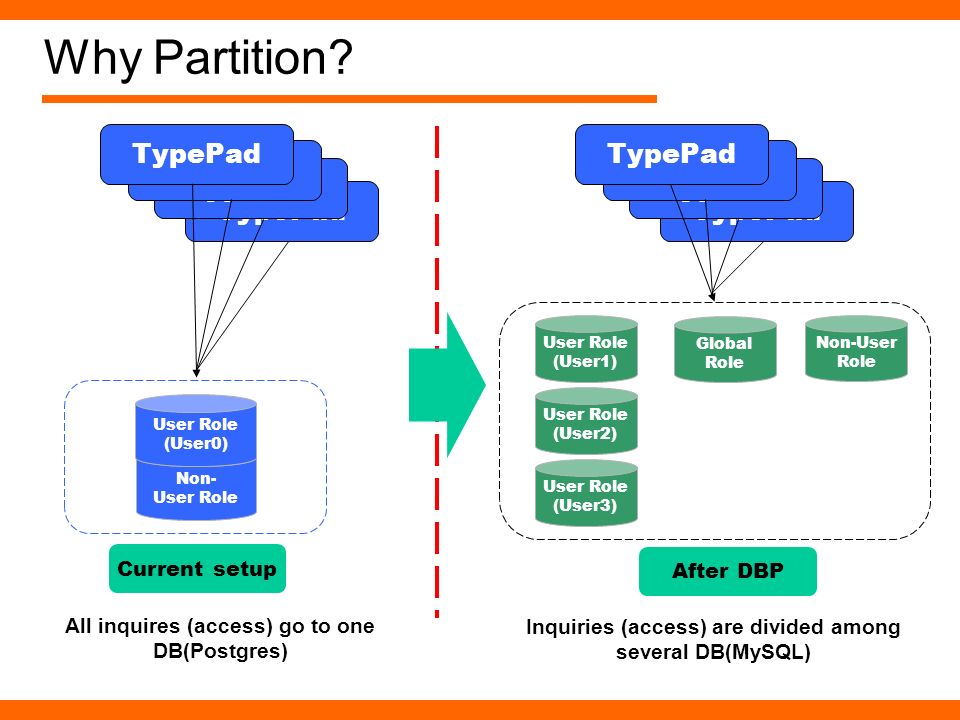 Партицировать стоит
Партицировать стоит
по одному признаку, по какому-то одному полю – это очень важно.
Давайте рассмотрим нашу партицию целиком:
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта
таблица будет унаследована от базовой таблицы news – все очень просто.
Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1
попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с
category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это
Это
правило создается на базовой таблице.
Таким образом мы заводим нужное нам количество партиций.
Для примера я буду использовать 2 партиции, чтобы было проще. Т.е. у нас все одинаково, кроме наименований этой таблицы и условия, по которому данные будут
туда попадать. Мы также заводим соответствующие правила по шаблону на каждую из таблиц.
Давайте рассмотрим пример вставки данных:
Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже
вставить данные с category_id=3.
Вот мы выбираем данные, у нас они все есть.
Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.
Мы можем выбирать данные напрямую из партиций – это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас
стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у
нас нет 3-ей партиции, а данные попадут в основную таблицу.
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью
Она настоящая таблица, она может хранить данные, и с помощью
оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.
Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму
партицию.
Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя
вставлять» – это тоже очень удобно – мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не
так, мы на уровне базы все это отловим.
Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной
партиции.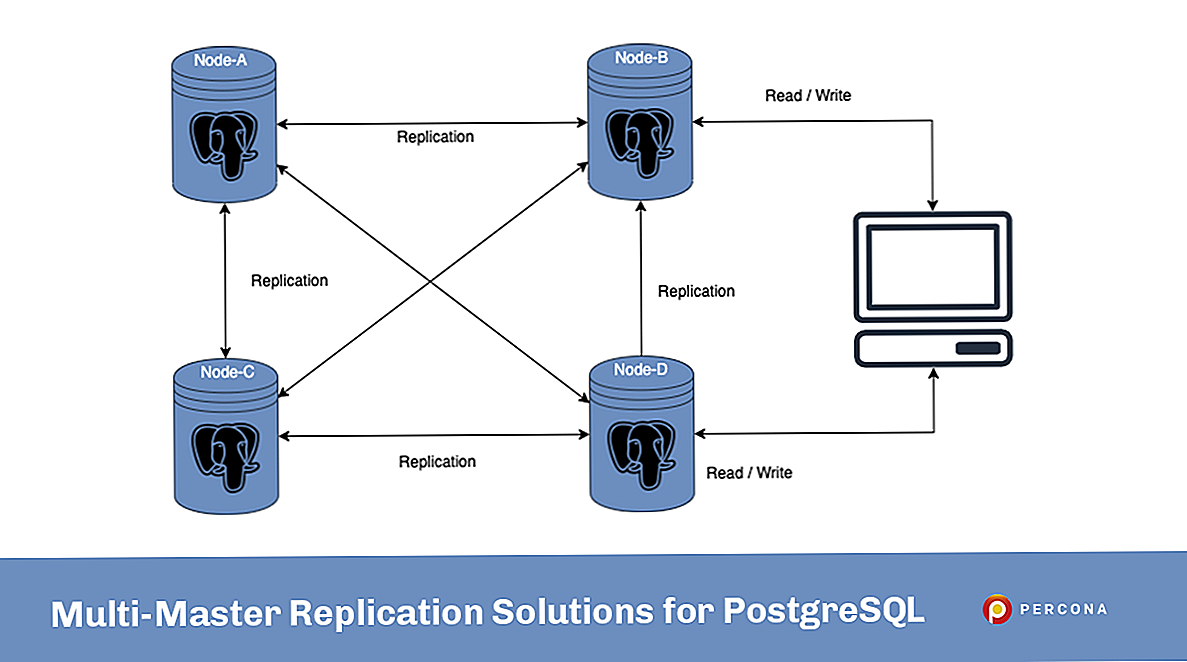 Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом
Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом
данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.
Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это
выглядит со стороны explain’а:
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия
нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает
оптимизатор – это правильно, и так действительно быстрее.
Мы можем посмотреть, как будет выглядеть explain на самой партиции.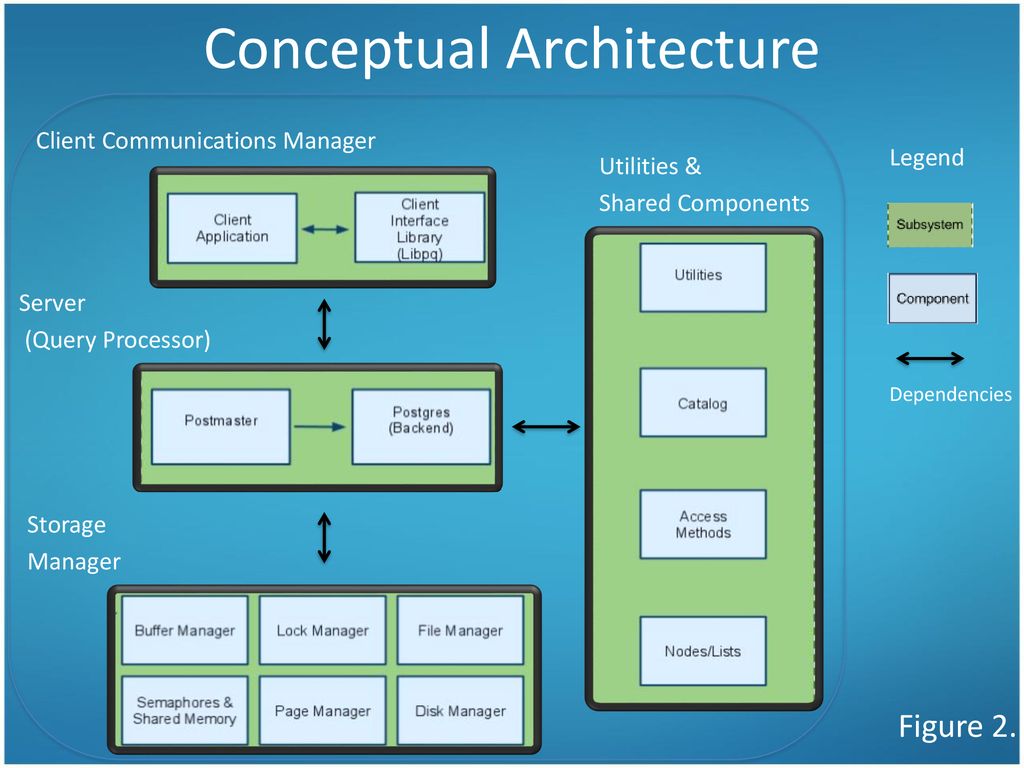
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного.
Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы
будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы.
Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на
всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не
заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная,
Эта утилита open source’ная,
ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension’ов, никаких
расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.
Как же нам запартицировать ее? А просто вот так:
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не
нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.
После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.
Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает.
Какие мы получаем за счет этого преимущества:
· при вставке мы автоматически создаем партицию, если ее еще нет;
· поддерживаем актуальную структуру, можем управлять просто базовой таблицей, навешивая на нее индексы, проверки, триггеры, добавлять колонки, и они
автоматически будут попадать во все партиции после вызова этой процедуры еще раз.
Мы получаем действительно большое преимущество в этом. Вот ссылочка: https://github.com/2gis/partition_magic.
На этом первая часть доклада закончена. Мы научились партицировать данные. Напомню, что партицирование применяется на одном инстансе – это тот же самый
инстанс базы, где у вас лежала бы большая толстая таблица, но мы ее раздробили на мелкие части. Мы можем совершенно не менять наше приложение – оно точно
Мы можем совершенно не менять наше приложение – оно точно
так же будет работать с основной таблицей – вставляем туда данные, редактируем, удаляем. Так же все работает, но работает быстрее. Приблизительно, в
среднем, в 3-4 раза быстрее.
Перейдем ко второй части доклада – это горизонтальный шардинг.
Напомню, что горизонтальный шардинг – это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это
настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами – news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы
будем работать:
Та же самая таблица:
Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но
Так же, как в предыдущем примере, но
это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно
запомнить. Единственное, что нужно сделать – это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
Несмотря на то, что у нас стоит check – проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных
может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как
foreign data wrapper.![]()
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign
data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды
хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный)
и базу, которую мы завели.
Далее мы создаем маппинг для пользователя – по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет
пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет
указать, чтобы все работало.
Далее мы заводим табличку на основном сервере
Это будет табличка с такой же структурой, но единственное, что будет отличаться – это префикс того, что это будет foreign table, т.е. она какая-то
иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту – это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем
сервер, добавляем маппинг, создаем таблицу. Все, что осталось – это завести нашу основную таблицу.
Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news
из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее – никаких
переписываний, ничего в приложении не делать.
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD
NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т.е. category_id=1 и таблицу, в которую данные вместо этого
будут попадать.
Т.е. единственное отличие – это в category_id мы будем указывать имя таблицы.
Также посмотрим на вставку данных.
Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т. е. у нас указано, что мы ничего не будем делать, если
е. у нас указано, что мы ничего не будем делать, если
не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут
вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные,
если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные.
Обратите внимание на сортировку идентификаторов – у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что
postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет – посылает запросы на удаленные машины, собирает
эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую
обращаемся в шард.
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.
У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan – это удаленный
скан, который выполняется на другом сервере.
Партицирование – это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет
просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию,
готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у
Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у
нас объем данных в таблице сокращается, т.к. это разные таблицы.
Шардинг – лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем
просто бесконечное количество серверов добавлять, и все будет замечательно работать.
← Производительность запросов в PostgreSQL – шаг за шагом
Sharding – patterns and antipatterns →
PostgreSQL 12. Секционирование теперь быстрее — Толмачев Павел Владимирович
Давненько я ничего не переводил. Решил вспомнить, каково это. Сегодня решил перевести статью из блога компании 2ndquadrant «PostgreSQL 12: Partitioning is now faster».
Статья посвящена секционированию PostgreSQL 12 версии.
Секционирование таблиц в PostgreSQL появилось в 10-й версии и постоянно развивается. В 11-й версии появилось секционирование по хэшу, секции по умолчанию, автоматическое перемещение записи в нужную секцию после UPDATE’a, исключение ненужных секций во время SELECT’a и некоторые другие возможности.
В 11-й версии появилось секционирование по хэшу, секции по умолчанию, автоматическое перемещение записи в нужную секцию после UPDATE’a, исключение ненужных секций во время SELECT’a и некоторые другие возможности.
В PostgreSQL 12 большое внимание уделено масштабированию секционирования, чтобы оно работало с большим числом разделов (тысячами). Посмотрим, что было улучшено.
Производительность копирования (COPY)
Загрузка данных в секционированную таблицу с использование COPY теперь позволяет использовать массовые вставки (bulk-inserts). Ранее, за один раз добавлялась только одна строка.
Скорость COPY, по-видимому, замедляется при увеличении количества секций, но, в действительности, она уменьшается с меньшим количеством строк на раздел. В этом тесте с увеличением количества разделов, количество строк на раздел сокращается. Причина замедления заключается в том, что код COPY составляет до 1000 слотов для каждой строки на секцию. В действительности такого снижения производительности, скорее всего, не произойдет, поскольку у вас может быть более 12,2 тыс. строк на секцию.
строк на секцию.
Производительность вставки (INSERT)
В PostgreSQL 11, при вставке записей в секционированную таблицу, каждый раздел блокировался, независимо от того, добавлялась ли запись в него или нет. При большем количестве разделов и меньшем количестве строк в INSERT, эти издержки могут стать значительными.
В PostgreSQL 12 секция блокируется непосредственно перед первой вставкой строки. Это означает, что если вставляем только 1 строку, то блокируется только 1 секция. Это приводит к гораздо лучшей производительности при большем количестве секций, особенно при вставке только 1 строки за раз. Это изменение в поведении блокировки также было объединено с полной перепиской кода маршрутизации строки секции. Благодаря этому, значительно снижаются накладные расходы на настройку структур данных маршрутизации кортежей во время запуска исполнителя планов (executer’a).
Можно видеть, что производительность в PostgreSQL 12 достаточно стабильна независимо от того, на сколько секций разделена таблица.
Производительность выборки (SELECT)
В PostgreSQL 10 планировщик последовательно проверяет ограничения каждой секции чтобы выяснить, нужно ли брать информации из нее для запроса. Это приводило к увеличению накладных расходов на планирование при увеличении количества секций. В PostgreSQL 11 улучшили эту работу за счет исключения ненужных секций (partition pruning), с помощью которого можно намного быстрее найти подходящие секции. Тем не менее, PostgreSQL 11 все еще выполнял некоторую ненужную обработку и по-прежнему загружал метаданные для каждой секции, независимо от того, была ли она исключена или нет.
В PostgreSQL 12 исправили данное поведение – загрузка метаданных выполняется после исключения секций. Это приводит к значительному повышению производительности в планировщике запросов при исключении многих секций.
Приведенная ниже диаграмма показывает производительность запроса отдельной строки из хэш-секционной таблицы, разбитой по столбцу BIGINT, который также является первичным ключом таблицы. В данном случае, могут быть удалены все секции, кроме единственной (необходимой).
В данном случае, могут быть удалены все секции, кроме единственной (необходимой).
По диаграмме отлично видно, что PostgreSQL 12 значительно улучшает ситуацию. При увеличении количества разделов, производительность немного падает. Но она все еще на несколько световых лет опережает PostgreSQL 11 в этом тесте 🙂
Другие улучшения производительности секционирования
Упорядоченное сканирование разделов:
Планировщик теперь может использовать неявный порядок секционированных таблиц по методу списка (LIST) и диапазона (RANGE). Это позволяет использовать оператор Append вместо оператора MergeAppend, когда требуемым порядком сортировки является порядок, определенный ключом секции. Это невозможно для хэш-секционированных таблиц, так как различные неупорядоченные значения могут совместно использовать один и тот же раздел. Эта оптимизация уменьшает бесполезные сравнения сортировки и обеспечивает хороший задел для запросов, использующих предложение LIMIT.
Избавьтесь от отдельных вложенных планов Append и MergeAppend:
Это довольно тривиальное изменение, которое устраняет узлы Append и MergeAppend, когда планировщик видит, что у него есть только один подузел. В этом случае было совершенно бесполезно сохранять узел Append/MergeAppend, поскольку они предназначены для добавления нескольких результатов подплана вместе. Делать особо нечего, когда уже есть только 1 подплан. Удаление их также дает небольшой прирост производительности для запросов, поскольку извлечение строк через ноды executor’a, независимо от того, насколько они тривиальны, не является бесплатным. Это изменение также позволяет распараллеливать некоторые запросы к секционированным таблицам, которые ранее не могли быть распараллелены.
Различные улучшения производительности для исключения секций во время выполнения:
Значительная часть оптимизационной работы была также проделана вокруг исключения разделов во время выполнения (run-time), чтобы уменьшить накладные расходы при запуске exectutor’a. Кроме того, была проделана определенная работа, позволившая PostgreSQL использовать расширенные инструкции по манипулированию битами, что повысило производительность типа Bitmapset. Это позволяет поддерживать процессоры для выполнения различных 64-х битных операций одновременно в единственной операции. Ранее все эти операции проходили через Bitmapset по 1 байту за раз. Эти Bitmapsets также были изменены с 32-битных на 64-битные на 64-разрядных машинах. Это эффективно удваивает производительность работы с большими Bitmapsets.
Кроме того, была проделана определенная работа, позволившая PostgreSQL использовать расширенные инструкции по манипулированию битами, что повысило производительность типа Bitmapset. Это позволяет поддерживать процессоры для выполнения различных 64-х битных операций одновременно в единственной операции. Ранее все эти операции проходили через Bitmapset по 1 байту за раз. Эти Bitmapsets также были изменены с 32-битных на 64-битные на 64-разрядных машинах. Это эффективно удваивает производительность работы с большими Bitmapsets.
Некоторые изменения были также внесены в executor, чтобы таблицы диапазонов (для хранения метаданных отношений) можно было найти в O(1), а не O(N) времени, где N-количество таблиц в списке таблиц диапазонов. Это особенно полезно, поскольку каждый раздел в плане имеет запись таблицы диапазонов, поэтому поиск данных таблицы диапазонов для каждого раздела был дорогостоящим, когда план содержал много разделов.
Благодаря этим улучшениям и использованию метода RANGE, с секционированием по столбцу timestamp, где каждая секция хранит 1 месяц данных, производительность выглядит следующим образом:
Здесь можно увидеть, что выигрыш PostgreSQL 12 становится больше с большим количеством разделов. Однако, высота столбцов уменьшается при увеличении количества секций. Это происходит потому, что сформирован запрос таким образом, что в плане исключение секций невозможно. Выражение WHERE имеет STABLE-функцию (стабильную функцию, гарантированно возвращающую одинаковый результат), планировщик не знает её возвращаемого значения, поэтому не может исключить какие-либо секции. Возвращаемое значение вычисляется во время запуска executor’a, а исключение раздела выполняется во время выполнения. К сожалению, это означает, что executor должен заблокировать все разделы плана, даже те, которые будут исключены во время выполнения. Так как этот запрос выполняется быстро, накладные расходы на эту блокировку можно увидеть только при большом количестве секций. Но исправлять это будут только в следующей версии.
Однако, высота столбцов уменьшается при увеличении количества секций. Это происходит потому, что сформирован запрос таким образом, что в плане исключение секций невозможно. Выражение WHERE имеет STABLE-функцию (стабильную функцию, гарантированно возвращающую одинаковый результат), планировщик не знает её возвращаемого значения, поэтому не может исключить какие-либо секции. Возвращаемое значение вычисляется во время запуска executor’a, а исключение раздела выполняется во время выполнения. К сожалению, это означает, что executor должен заблокировать все разделы плана, даже те, которые будут исключены во время выполнения. Так как этот запрос выполняется быстро, накладные расходы на эту блокировку можно увидеть только при большом количестве секций. Но исправлять это будут только в следующей версии.
Хорошая новость заключается в том, что если мы изменим предложение WHERE, заменив вызов STABLE-функции на константу, планировщик сможет позаботиться об исключении секций:
Накладные расходы на планирование показывают, что здесь, как и в случае с несколькими секциями, производительность PostgreSQL 12 не так высока, как в случае с общим планом и исключением секций во время выполнения. При большем количестве секций производительность не так сильно снижается, когда планировщик может выполнить исключение. Это происходит потому, что план запроса имеет только 1 секцию для блокировки и разблокировки executor’ом.
При большем количестве секций производительность не так сильно снижается, когда планировщик может выполнить исключение. Это происходит потому, что план запроса имеет только 1 секцию для блокировки и разблокировки executor’ом.
Резюме
Из приведенных выше графиков видно, что было много сделано для улучшения секционирования в PostgreSQL 12. Однако, пожалуйста, не поддавайтесь соблазну приведенных выше графиков и разработайте свои стратегии секционирования с большим количеством секций. Имейте в виду, что всё еще есть случаи, когда слишком много секций может привести к тому, что планировщик запросов будет использовать больше оперативной памяти и станет медленным. Когда производительность имеет значение (а это обычно всегда так) мы настоятельно рекомендуем Вам запустить моделирование рабочей нагрузки. Это следует делать не на рабочем сервере, с различным количеством разделов, чтобы увидеть, как это влияет на производительность. Прочтите раздел документации, посвященный лучшим практикам, для получения дальнейших указаний.
Тестовая среда:
Все тесты были выполнены на экземпляре Amazon AWS m5d.large с использованием pgbench. Количество операций в секундах (transactions per seconds) тестов измерялось в течение 60 секунд.
Были изменены следующие настройки:
shared_buffers = 1GB work_mem = 256MB checkpoint_timeout = 60min max_wal_size = 10GB max_locks_per_transaction = 256Всё количество транзакций в секунду измерялось с помощью одного соединения PostgreSQL.
И еще раз — ссылка на оригинал: «PostgreSQL 12: Partitioning is now faster».
Разделение таблицы PostgreSQL. 🎃 Я всегда хотел учиться у… | Али Мохаммад | Октябрь 2022 г.
🎃 Я всегда хотел учиться вместе с другими людьми, и, поскольку я не специалист по базам данных, давайте вместе рассмотрим эту статью, чтобы узнать о секционировании таблиц в PostgreSQL ❤️!
Разделение таблицы — это разделение логически одной большой таблицы на более мелкие физические части.
Когда одна таблица не может обеспечить большинство преимуществ секционирования, эти преимущества можно использовать. Пользователям требуется секционирование, если в какой-то момент большой объем данных будет записан в одну таблицу. В дополнение к данным могут быть и другие элементы, которые должны учитывать пользователи, такие как частота обновления данных, использование данных во времени, степень детализации диапазона данных и т. д. Разделение таблиц может обеспечить значительный выигрыш в скорости и позволяют расширить PostgreSQL до больших наборов данных при надлежащем планировании и учете всех соображений.
Разбиение по хэшу
При указании значения условия для каждой секции таблица секционируется. Каждая секция содержит строки, для которых хеш-значение ключа секции при делении на указанный модуль дает указанный остаток.
Вместо этого можно использовать альтернативные стратегии, такие как наследование и представления UNION ALL. Такие подходы обеспечивают гибкость, но лишены некоторых преимуществ производительности встроенного декларативного секционирования.
Секционирование по хешу позволяет равномерно распределить строки по набору таблиц; например, мы можем построить две секции для нашей таблицы и выбрать секцию для каждой строки, используя хэш и язык города:Разбиение списка
Разбиение таблицы на разделы выполняется путем перечисления конкретных значений ключей, существующих в каждом сегменте.
Разделение списка позволяет указать список значений для раздела; например, мы можем хранить небольшую часть данных в разделе is_activeРазделение диапазона
Между диапазонами значений, присвоенных различным разделам, нет перекрытия. Например, можно разделить по периодам дат или по диапазонам идентификаторов для конкретных бизнес-объектов. Нижняя граница каждого диапазона считается включающей, а верхняя – исключающей. Например, если диапазон одного раздела — от 2000 до 2010, а диапазон следующего раздела — от 2010 до 2020, то значение 2010 принадлежит второму разделу, а не первому.
Разделение по диапазону позволяет указать диапазон значений для раздела, например, мы можем хранить данные за каждый месяц в отдельном разделе:
PostgreSQL позволяет объявлять разделы в таблице.
Многораздельная таблица представляет собой « виртуальный », что не имеет собственного хранилища . Вместо этого хранилище выделено разделам, которые в остальном являются стандартными таблицами, связанными с секционированной таблицей. В соответствии с границами разделов каждый раздел содержит подмножество данных. В соответствии со значениями столбца ключа раздела все строки, помещаемые в секционированную таблицу, будут направляться в соответствующий раздел (разделы). Если строка больше не соответствует границам своего исходного раздела, обновление ключа раздела приведет к ее переносу в другой раздел.
Разделы могут быть определены как сами таблицы с разделами, что приводит к разделению на подразделы. Все секции должны иметь те же столбцы, что и их родительские секции, хотя секции могут иметь свои собственные индексы, ограничения и значения по умолчанию.Невозможно преобразовать обычную таблицу в секционированную или наоборот. Однако можно добавить существующую обычную или многораздельную таблицу в качестве раздела многораздельной базы данных или удалить раздел из многораздельной таблицы, тем самым преобразовав ее в автономную таблицу; это может упростить и ускорить многочисленные задачи обслуживания.
Разделы также могут быть внешними таблицами, хотя требуется крайняя осторожность, поскольку пользователь обязан убедиться, что содержимое внешней таблицы соответствует правилу разделения. Кроме того, существуют некоторые другие ограничения.Несмотря на то, что встроенного декларативного разделения достаточно для большинства частых случаев использования, существуют ситуации, когда более гибкий подход может быть полезен. Использование наследования таблиц для выполнения секционирования позволяет использовать различные возможности, недоступные при декларативном секционировании, в том числе:

 Разделенная таблица называется секционированной таблицей. Объявление также предоставляет список столбцов или выражений, которые будут использоваться в качестве ключа раздела, в дополнение к ранее рассмотренному механизму разделения.
Разделенная таблица называется секционированной таблицей. Объявление также предоставляет список столбцов или выражений, которые будут использоваться в качестве ключа раздела, в дополнение к ранее рассмотренному механизму разделения. 
- При декларативном секционировании секции должны содержать тот же набор столбцов, что и секционированная таблица, однако при наследовании таблиц дочерние таблицы могут содержать дополнительные столбцы, отсутствующие в родительской таблице.
- Наследование таблиц допускает множественное наследование.
- Декларативное секционирование допускает секционирование только по диапазонам, спискам и хеш-функциям, тогда как наследование таблиц позволяет пользователю делить данные так, как он считает нужным. (Однако, если исключение по ограничению не может правильно удалить дочерние таблицы, производительность запросов может снизиться.)

Исключение по ограничению — это метод оптимизации запросов, связанный с сокращением секций. Обычно он используется для разделения, реализованного с помощью старого метода наследования, хотя его также можно использовать с декларативным разделением.
Функция исключения ограничений аналогична сокращению секций, за исключением того, что оно использует ограничения каждой таблицы, тогда как сокращение секций использует границы секций таблицы, которые присутствуют только в случае декларативного секционирования. Еще одно отличие заключается в том, что исключение ограничений реализуется только во время планирования; удаление раздела не предпринимается во время выполнения.
Использование ограничений при исключении ограничений, которое делает его более медленным, чем отсечение секций, иногда может быть преимуществом: поскольку ограничения могут быть определены для декларативно секционированных таблиц в дополнение к их внутренним границам секций, исключение ограничений может позволить исключить дополнительные секции из запроса. план.
По умолчанию (и рекомендуемый) выбор исключения ограничения — разделение, которое применяет подход исключительно к запросам, которые, вероятно, будут работать с таблицами с разделением по наследству. Параметр on заставляет планировщик анализировать ограничения во всех запросах, включая базовые, которые вряд ли получат какое-либо преимущество.
Ограничения исключения ограничения:
- В отличие от сокращения секций, которое также может быть реализовано во время выполнения запроса, исключение ограничения применяется только во время планирования запроса.
- Исключение ограничений работает только в том случае, если предложение WHERE запроса содержит константы (или внешние параметры). Сравнение с неизменяемой функцией, такой как CURRENT TIMESTAMP, например, не может быть оптимизировано, потому что планировщик не может предсказать, в какую дочернюю таблицу может попасть значение функции во время выполнения.
- Минимальные ограничения разделения; в противном случае планировщик не сможет продемонстрировать, что доступ к дочерним таблицам не требуется. Как показано в предыдущих примерах, используйте базовые условия равенства для разделения списка и простые проверки диапазона для разделения диапазона.
- Ограничения секционирования должны сравнивать столбцы секционирования только с константами, используя операторы индексации B-дерева, поскольку в ключе секционирования разрешены только индексируемые столбцы B-дерева.
- Во время исключения ограничения проверяются все ограничения для всех дочерних элементов родительской таблицы, поэтому большое количество дочерних элементов может значительно увеличить время планирования запроса. Следовательно, секционирование на основе наследования будет эффективно работать примерно с сотней дочерних таблиц; избегать использования многих тысяч детей.
 Сравнение с неизменяемой функцией, такой как CURRENT TIMESTAMP, например, не может быть оптимизировано, потому что планировщик не может предсказать, в какую дочернюю таблицу может попасть значение функции во время выполнения.
Сравнение с неизменяемой функцией, такой как CURRENT TIMESTAMP, например, не может быть оптимизировано, потому что планировщик не может предсказать, в какую дочернюю таблицу может попасть значение функции во время выполнения.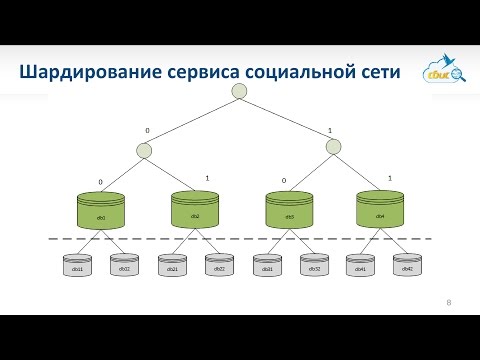
Столбец или столбцы, по которым вы сегментируете данные, будут одним из наиболее важных проектных решений. Секционирование по столбцу или набору столбцов, которые чаще всего появляются в предложениях WHERE запросов, выполняемых к секционированной таблице, часто является оптимальной стратегией. Ненужные разделы можно исключить с помощью предложений WHERE, соответствующих ограничениям, связанным с разделами. Однако потребность в PRIMARY KEY или ограничении UNIQUE может вынудить вас сделать альтернативный выбор. При разработке подхода к разделению следует также рассмотреть возможность удаления ненужных данных. Поскольку весь раздел может быть отсоединен относительно быстро, может оказаться выгодным разработать стратегию разделения таким образом, чтобы все данные, подлежащие одновременному удалению, находились в одном разделе.
Выбор целевого количества разделов, на которые должна быть разбита таблица, является еще одним важным соображением. Несоответствующие разделы могут привести к тому, что индексы останутся чрезмерно большими, а локальность данных останется плохой, что приведет к низкому коэффициенту попаданий в кэш. Однако чрезмерное разбиение таблицы также может вызвать проблемы. Слишком большое количество разделов может привести к увеличению продолжительности планирования запросов и увеличению использования памяти как во время планирования, так и во время выполнения запросов, как будет более подробно описано ниже. При принятии решения о том, как разделить вашу таблицу, также важно учитывать любые будущие корректировки.
Однако чрезмерное разбиение таблицы также может вызвать проблемы. Слишком большое количество разделов может привести к увеличению продолжительности планирования запросов и увеличению использования памяти как во время планирования, так и во время выполнения запросов, как будет более подробно описано ниже. При принятии решения о том, как разделить вашу таблицу, также важно учитывать любые будущие корректировки.
Разбиение на подразделы полезно для разделов, которые, как ожидается, станут больше других разделов. В качестве альтернативы используйте разбиение по диапазону с большим количеством столбцов в ключе секции. Оба могут легко привести к чрезмерному количеству разделов, поэтому рекомендуется модерация.
При планировании и выполнении запросов очень важно учитывать накладные расходы на секционирование. Как правило, планировщик запросов может относительно легко управлять иерархиями разделов, содержащими до нескольких тысяч разделов, при условии, что общие запросы позволяют планировщику сократить все разделы, кроме небольшого числа. Когда планировщик выполняет сокращение разделов и остается больше разделов, время планирования увеличивается, а потребление памяти увеличивается. Еще одна причина для беспокойства по поводу большого количества разделов заключается в том, что использование памяти сервером может значительно увеличиться со временем, особенно если несколько сеансов обращаются к большому количеству разделов. Это связано с тем, что метаданные каждого раздела должны быть загружены в локальную память каждого сеанса, который с ним взаимодействует.
Когда планировщик выполняет сокращение разделов и остается больше разделов, время планирования увеличивается, а потребление памяти увеличивается. Еще одна причина для беспокойства по поводу большого количества разделов заключается в том, что использование памяти сервером может значительно увеличиться со временем, особенно если несколько сеансов обращаются к большому количеству разделов. Это связано с тем, что метаданные каждого раздела должны быть загружены в локальную память каждого сеанса, который с ним взаимодействует.
- Когда большинство часто посещаемых строк в таблице расположены в одном разделе или в ограниченном числе разделов, при определенных обстоятельствах скорость выполнения запросов может быть значительно увеличена.
- Секционирование эффективно заменяет верхние уровни дерева индексов, увеличивая вероятность того, что часто используемые части индексов будут помещаться в памяти.
- Когда запросы или изменения достигают значительной части одного раздела, производительность можно повысить за счет использования последовательного сканирования этого раздела, а не индекса, что потребовало бы чтения с произвольным доступом, распределенного по всей базе данных.
- Добавление или удаление разделов может облегчить массовую загрузку и удаление, если при проектировании разделов учитывается шаблон использования.
- Удаление отдельных разделов с помощью DROP TABLE или ALTER TABLE DETACH PARTITION выполняется значительно быстрее, чем массовое удаление. Кроме того, эти процедуры полностью устраняют затраты на ВАКУУМ, связанные с массовым УДАЛЕНИЕМ.
- Данные, к которым редко обращаются, могут быть перемещены на более дешевые и медленные носители.
- Чтобы создать ограничение уникальности или первичного ключа для секционированной таблицы, ключи секций не могут содержать никаких выражений или вызовов функций, а все столбцы ключей секций должны быть включены в столбцы ограничения. Следовательно, структура разделов должна обеспечивать отсутствие дубликатов между разделами.
- Невозможно определить ограничение исключения, охватывающее всю секционированную таблицу. Это ограничение может быть наложено только на каждый конечный раздел отдельно. Эта проблема возникает еще раз из-за невозможности применить межраздельные ограничения.
Триггеры BEFORE ROW команды INSERT не могут изменить раздел, для которого предназначена новая строка. - Временные и постоянные связи не могут сосуществовать в одном дереве разделов. Следовательно, если многораздельная таблица является постоянной, ее разделы также должны быть постоянными, и наоборот, если многораздельная таблица является временной.
- При использовании временных отношений все элементы дерева разделов должны быть из одного сеанса.
 Эта проблема возникает еще раз из-за невозможности применить межраздельные ограничения.
Эта проблема возникает еще раз из-за невозможности применить межраздельные ограничения. Для получения дополнительной информации о секционировании таблиц см. официальную документацию по разделам таблиц postgresql https://www.postgresql.org/docs/current/ddl-partitioning.html
Надеюсь, эта статья оказалась для вас полезной и интересной ❤️
Сокращение затрат на ввод-вывод AWS Aurora за счет секционирования таблиц и понимания сокращения секций
Сегодня мы поговорим об использовании секционирования для снижения затрат на ввод-вывод AWS Aurora, pg_partman и о том, как сокращение секций повышает производительность запросов.
Поделиться этим выпуском: Нажмите здесь, чтобы поделиться этим выпуском в Twitter и подписаться на наш канал YouTube.
Использование сокращения разделов Postgres для снижения затрат на ввод-вывод AWS Aurora
- Повышение производительности запросов Postgres и снижение затрат на ввод-вывод за счет сокращения секций
Отсечение разделов в PostgreSQL
Исправление ошибки CREATED INDEX CONCURRENTLY или REINDEX CONCURRENTLY в POstgres 14
То, что мы обсуждали в этом выпуске 5 минут Postgres
Стенограмма
Давайте приступим.
Использование сокращения разделов Postgres для снижения затрат на ввод-вывод AWS Aurora
они использовали сокращение разделов, чтобы снизить затраты на чтение операций ввода-вывода в Aurora.
Возможно, вы не знакомы, но Aurora взимает дополнительную плату за операции ввода-вывода . Это означает, что на самом деле это может быть довольно дорого, если вы используете базу данных неэффективно. Если вы выполняете все последовательные сканирования или выполняете много дорогостоящих сканирований индексов, то может довольно быстро стоить вам реальных денег на Aurora .
Это означает, что на самом деле это может быть довольно дорого, если вы используете базу данных неэффективно. Если вы выполняете все последовательные сканирования или выполняете много дорогостоящих сканирований индексов, то может довольно быстро стоить вам реальных денег на Aurora .
Объем данных, которые они просматривают в своем блоге, составляет около 33 терабайт данных. Довольно большая база данных, и они потребляют около 46 гигабайт в день.
Они используют pg_partman для управления разделами — вам не обязательно использовать pg_partman — вы можете просто использовать обычные операторы SQL для управления разделами в Postgres. Но pg_partman — это один из способов упростить создание новых разделов или истечение срока действия старых разделов . Вы можете прочитать эту статью в документации AWS об управлении разделами PostgreSQL с расширением pg_partman.
Они также описали созданный ими симулятор нагрузки. Этот симулятор нагрузки имитирует около тысячи операций записи в секунду, вставок и обновлений, а также имитирует около 10 000 операций чтения в секунду. Он имеет циклический характер, поэтому каждый день в рабочее время он будет более загружен, ночью он будет менее загружен.
Он имеет циклический характер, поэтому каждый день в рабочее время он будет более загружен, ночью он будет менее загружен.
Повышение производительности запросов Postgres и снижение затрат на ввод-вывод за счет сокращения секций
Затем они рассказывают, как можно разделить такую рабочую нагрузку. Очевидно, что такая большая таблица без секционирования в любом случае вызовет пару проблем в Postgres, с вакуумом и тому подобным, но здесь они просто сосредоточены на производительности запросов и связанных с этим затратах ввода-вывода.
Когда вы секционируете таблицы в Postgres, вы всегда будете принимать решение о том, что вы хотите секционировать и какой метод секционирования использовать. Здесь они используют разбиение по диапазонам и разбивают на created_at столбец.
Когда вы секционируете таблицы в Postgres, вы всегда будете принимать решение о том, что вы хотите секционировать и какой метод секционирования использовать.

Чтобы обновить свою существующую таблицу для использования секционирования, они создают новую секционированную таблицу и присоединяют существующую таблицу как дочернюю секцию к секционированной таблице.
Теперь, после того, как они сделали это обновление здесь, они действительно могут видеть довольно заметные улучшения производительности. Думаю, это самое впечатляющее число здесь:
- .
До того, как они применили секционирование к этой рабочей нагрузке: , у них было 17 000 долларов США на ввод-вывод. Это хорошая сумма денег.
После применения этих оптимизаций: они сэкономили около 12 000 долларов США, доведя затраты на ввод-вывод до 5 600 долларов США.
Вам будет нелегко найти такое хорошее улучшение для вашей собственной базы данных, но, безусловно, если у вас действительно большая таблица, в которой еще не используется секционирование, вы можете получить такие преимущества.
Сокращение разделов в PostgreSQL
Еще одна вещь, о которой я хочу упомянуть, это сокращение разделов. Сокращение разделов — это действительно то, на чем построена эта оптимизация, это снижение затрат. Сокращение разделов является частью планировщика Postgres . Когда вы запрашиваете таблицу разделов и указываете ключ раздела в запросе, планировщик Postgres может избежать большого количества дополнительной работы, определяя, что определенные разделы не нужно просматривать.
Пример, который у нас есть здесь, в документации Postgres, есть таблица измерений, в таблице измерений есть столбец logdate , а таблица измерений разделена по столбцу logdate. Когда вы выполняете запрос с включенной обрезкой разделов, Postgres сможет не просматривать разделы, которые не соответствуют этой дате журнала.
При отключении сокращения разделов, которое можно выполнить с помощью локальной команды подключения SET . Когда вы запускаете команду EXPLAIN , в этом случае мы запрашиваем все, что новее, чем 1 января 2008 года, , но мы получаем все эти старые разделы из 2006 года 9. 0028 , потому что Postgres на самом деле не выполняет обрезку разделов, поэтому ему приходится загружать все эти дополнительные данные.
0028 , потому что Postgres на самом деле не выполняет обрезку разделов, поэтому ему приходится загружать все эти дополнительные данные.
Если вы включите сокращение разделов, Postgres сможет сказать, что мне нужно только просмотреть разделы, отмеченные 2008 годом и позже. Это может сэкономить вам много времени. Это не имеет ничего общего с индексацией, это просто сосредоточено на самих ограничениях раздела.
Если вы включите обрезку разделов, Postgres сможет сказать, что мне нужно только просмотреть разделы, помеченные как 2008 и более поздние.
Это то, что я сам много раз использовал с секционированными таблицами. Если вы используете функции, связанные с этим, если вы используете что-то now() или выполняете какую-то математику на основе дат, всегда полезно проверить EXPLAIN план , потому что иногда вы думаете эта обрезка разделов применяется, но обрезка разделов на самом деле не применяется из-за того, что функции нестабильны или нестабильны. Всегда полезно проверить с помощью плана EXPLAIN, действительно ли вы видите, что разделы удаляются из плана, как и ожидалось.
Всегда полезно проверить с помощью плана EXPLAIN, действительно ли вы видите, что разделы удаляются из плана, как и ожидалось.
Исправление ошибки CREATED INDEX CONCURRENTLY или REINDEX CONCURRENTLY в POstgres 14
Последнее, что я хочу упомянуть, сегодня выпущен Postgres 14.4. В этом новом выпуске патча, предназначенном только для Postgres 14, исправлена важная ошибка, связанная с повреждением индекса. Мы уже говорили об этом ранее, но если вы использовали CREATE INDEX CONCURRENTLY или REINDEX CONCURRENTLY в Postgres 14, то возможны редкие, но, безусловно, возможные случаи, когда ваши индексы B-Tree и другие типы индексов могут отсутствовать. записи. Используйте расширение amcheck, чтобы проверить, есть ли эта проблема в вашей базе данных.
Большое спасибо за внимание. Это было 5 минут Postgres. Подпишитесь на наш канал на YouTube, чтобы узнавать о выпусках на следующей неделе, следите за нами в Twitter и общайтесь с вами на следующей неделе.