Содержание
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python / Хабр
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.
Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга —
Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
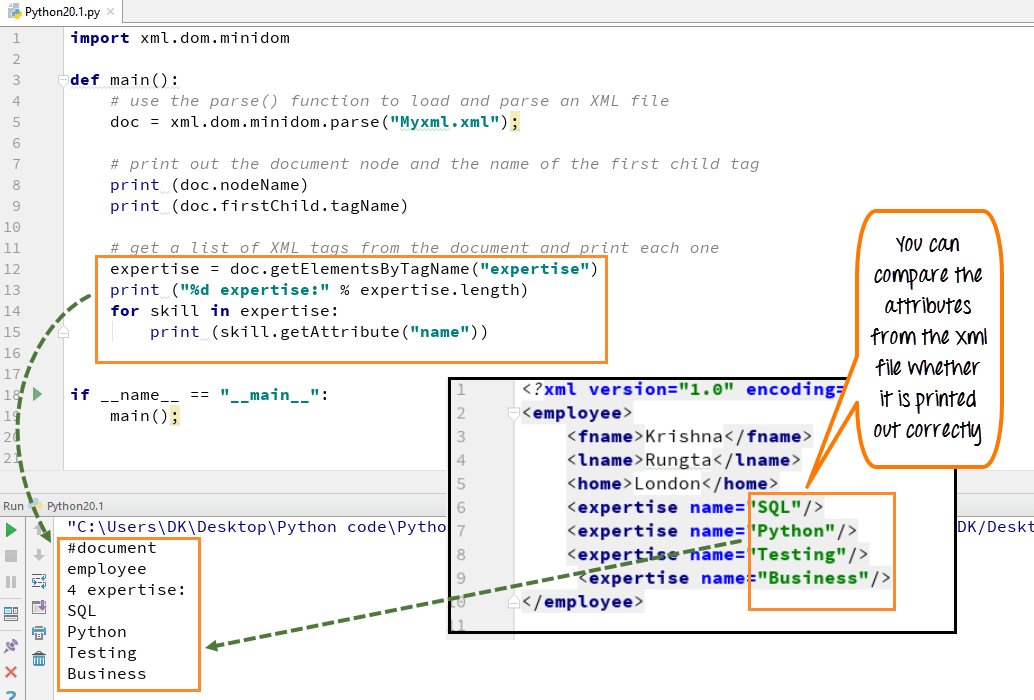
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга —
Извлечение информации.
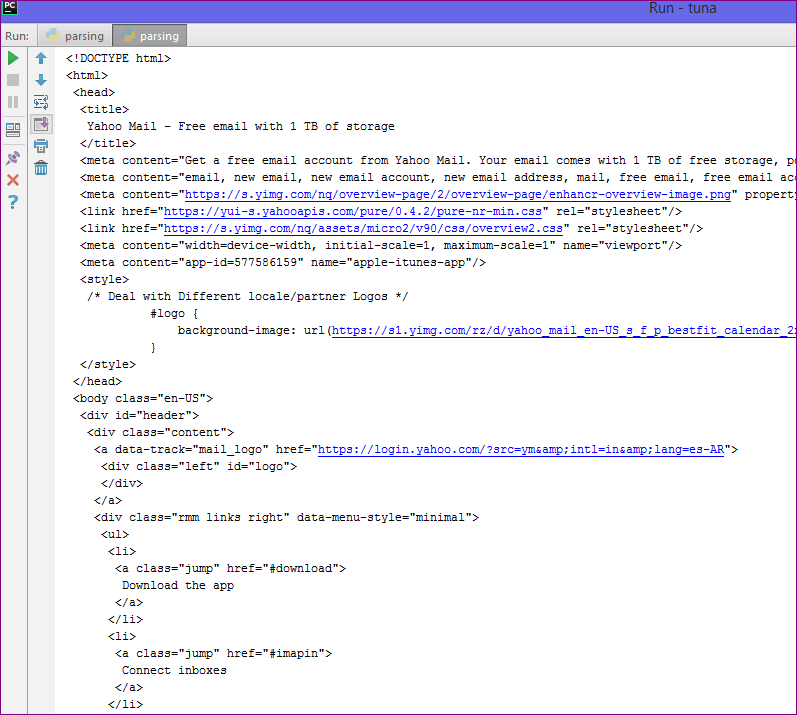
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
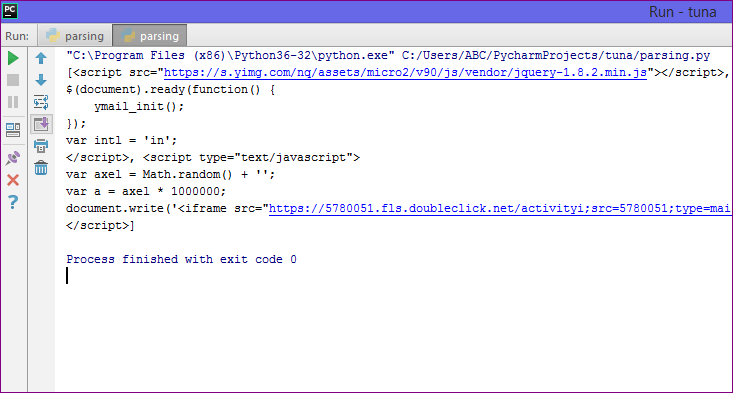
import requests from bs4 import BeautifulSoup as bs import pandas as pd
И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" r = requests.get(URL_TEMPLATE) print(r.status_code)
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text)
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
Для этого посмотрим в каком элементе html-кода хранится эта информация.
<h3><a href="/ru/jobs/3682040/" title="Комірник, вакансия от 5 ноября 2019">Комірник</a></h3>
У нас есть тег h3 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h3', class_='add-bottom-sm')
for name in vacancies_names:
print(name.a['title'])
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
<p>Some information about vacancy.</p>
Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
print('https://www.work.ua'+name.a['href'])
for info in vacancies_info:
print(info. text)
text)
 text)
text)
И последний этап парсинга —
Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
FILE_NAME = "test.csv"
def parse(url = URL_TEMPLATE):
result_list = {'href': [], 'title': [], 'about': []}
r = requests.get(url)
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h3', class_='add-bottom-sm')
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
result_list['href'].append('https://www.work.ua'+name.a['href'])
result_list['title'].append(name.a['title'])
for info in vacancies_info:
result_list['about'].append(info.text)
return result_list
df = pd.DataFrame(data=parse())
df.to_csv(FILE_NAME)
После запуска появится файл test. csv — с результатами поиска.
csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
пишем программу парсер веб-страниц с нуля с объяснениями
Что такое веб-парсинг в Python?
Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.
Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
Почему и зачем использовать веб-парсинг?
Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
- Динамический мониторинг цен
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
- Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
- Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
- Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
- Тренды в социальных сетях
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
- Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
- Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
- Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
- Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
- Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
- Сканер
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
- Selenium-Selenium – это библиотека автоматического тестирования с открытым исходным кодом. Она используется для проверки активности браузера. Чтобы установить эту библиотеку, введите в терминале следующую команду.

pip install selenium
Примечание. Рекомендуется использовать IDE PyCharm.
- Pandas – библиотека для обработки и анализа данных. Используется для извлечения данных и сохранения их в желаемом формате.
- BeautifulSoup
BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
pip install bs4
Установка парсера
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:
pip install html5lib
BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
- Ярлык
Объект Tag соответствует исходному документу XML или HTML.
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
Выход:
<class "bs4.element.Tag">
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
- Имя
У каждого тега есть имя, доступное как .name:
tag.name
- Атрибуты
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
tag[id]
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
# add the element tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # delete the tag del tag['id']
- Многозначные атрибуты
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- Навигационная строка
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
tag.string # u'Extremely bold' type(tag.string) #
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
tag.string.replace_with("No longer bold")
tag
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
- BeautifulSoup объект
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
doc=BeautifulSoup("INSERT FOOTER HERE","xml")
footer=BeautifulSoup("Here's the footer","xml")
doc.find(text="INSERT FOOTER HERE").replace_with(footer)
print(doc) Выход:
?xml version="1.0" encoding="utf-8"?> # Here's the footer
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests. get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
 get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
Выход:
The object type <class 'requests.models.Response'> Convert the object into: <class 'bs4.BeautifulSoup'>
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
Выход:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,Free and open-source software,Proprietary software with free and open-source editions,Proprietary software,Journals,Conferences,See also,References,Further reading,External links,
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.
В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.
Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
following code: # importing the libraries from bs4 import BeautifulSoup import requests url="https://www.javatpoint.com/" # Make a GET request to fetch the raw HTML content html_content = requests.get(url).text # Parse the html content soup = BeautifulSoup(html_content, "html5lib") print(soup.prettify()) # print the parsed data of html
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
- Напечатаем заголовок веб-страницы.
print(soup.title)
Выход даст следующий результат:
<title>Tutorials List - Javatpoint</title>
- В приведенных выше выходных данных тег HTML включен в заголовок. Если вам нужен текст без тега, вы можете использовать следующий код:
print(soup.title.text)
Выход: это даст следующий результат:
Tutorials List - Javatpoint
- Мы можем получить всю ссылку на странице вместе с ее атрибутами, такими как href, title и ее внутренний текст. Рассмотрим следующий код:
for link in soup.
 find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
href is: https://www.facebook.com/javatpoint Inner Text is: The title is: None href is: https://twitter.com/pagejavatpoint Inner Text is: The title is: None href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg Inner Text is: The title is: None href is: https://javatpoint.blogspot.com Inner Text is: Learn Java Title is: None href is: https://www.javatpoint.com/java-tutorial Inner Text is: Learn Data Structures Title is: None href is: https://www.javatpoint.com/data-structure-tutorial Inner Text is: Learn C Programming Title is: None href is: https://www.
 javatpoint.com/c-programming-language-tutorial
Inner Text is: Learn C++ Tutorial
javatpoint.com/c-programming-language-tutorial
Inner Text is: Learn C++ Tutorial
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup. find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container. find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
 find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.
find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container. find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
Выход:
Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.
Вы можете удалить эти комментарии и посмотреть результат.
Михаил Русаков
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Еще для изучения:
Парсер Python
| Работа синтаксического анализа Python с различными примерами
В этой статье синтаксический анализ определяется как обработка фрагмента программы Python и преобразование этих кодов в машинный язык. В общем, можно сказать, что parse — это команда для разделения заданного программного кода на небольшой кусок кода для анализа правильного синтаксиса. В Python есть встроенный модуль parse, который обеспечивает интерфейс между внутренним парсером Python и компилятором, где этот модуль позволяет программе Python редактировать небольшие фрагменты кода и создавать исполняемую программу из этого отредактированного дерева разбора Python. код. В Python есть еще один модуль, известный как argparse, для анализа параметров командной строки.
Работа Python Parse
В этой статье парсер Python в основном используется для преобразования данных в требуемый формат, этот процесс преобразования известен как синтаксический анализ. Поскольку во многих различных приложениях полученные данные могут иметь разные форматы данных, и эти форматы могут не подходить для конкретного приложения, здесь используется парсер, что означает, что в таких ситуациях необходим синтаксический анализ. Таким образом, синтаксический анализ обычно определяется как преобразование данных из одного формата в какой-либо другой формат, известный как синтаксический анализ. Парсер состоит из двух частей: лексера и парсера, а в некоторых случаях используются только парсеры.
Синтаксический анализ Python выполняется с использованием различных способов, таких как использование модуля синтаксического анализатора, синтаксический анализ с использованием регулярных выражений, синтаксический анализ с использованием некоторых строковых методов, таких как split() и strip(), синтаксический анализ с использованием панд, таких как чтение файла CSV в текст с помощью чтения . csv и т. д. Существует также концепция анализа аргументов, которая означает, что в Python у нас есть модуль с именем argparse, который используется для анализа данных с одним или несколькими аргументами из терминала или командной строки. Существуют и другие различные модули для работы с разбором аргументов, такие как модули getopt, sys и argparse. Теперь давайте рассмотрим демонстрацию парсера Python. В Python синтаксический анализатор также может быть создан с использованием нескольких инструментов, таких как генераторы синтаксических анализаторов, и существует библиотека, известная как комбинаторы синтаксических анализаторов, которые используются для создания синтаксических анализаторов.
csv и т. д. Существует также концепция анализа аргументов, которая означает, что в Python у нас есть модуль с именем argparse, который используется для анализа данных с одним или несколькими аргументами из терминала или командной строки. Существуют и другие различные модули для работы с разбором аргументов, такие как модули getopt, sys и argparse. Теперь давайте рассмотрим демонстрацию парсера Python. В Python синтаксический анализатор также может быть создан с использованием нескольких инструментов, таких как генераторы синтаксических анализаторов, и существует библиотека, известная как комбинаторы синтаксических анализаторов, которые используются для создания синтаксических анализаторов.
Примеры синтаксического анализатора Python
Теперь давайте посмотрим на приведенном ниже примере, как модуль синтаксического анализатора используется для анализа заданных выражений.
Пример #1
Код:
анализатор импорта
print("Программа для демонстрации модуля парсера в Python")
печать("\n")
ехр = "5 + 8"
print("Данное выражение для разбора выглядит следующим образом:")
печать (эксп)
печать("\n")
print("Синтаксический анализ данного выражения приводит к следующему результату: ")
ст = парсер. выражение (выражение)
печать (ст)
печать("\n")
print("Разобранный объект преобразуется в кодовый объект")
код = ст.компиляция()
распечатать (код)
печать("\n")
print("Результат вычисления данного выражения выглядит следующим образом:")
res = оценка (код)
печать (разрешение)  выражение (выражение)
печать (ст)
печать("\n")
print("Разобранный объект преобразуется в кодовый объект")
код = ст.компиляция()
распечатать (код)
печать("\n")
print("Результат вычисления данного выражения выглядит следующим образом:")
res = оценка (код)
печать (разрешение)
выражение (выражение)
печать (ст)
печать("\n")
print("Разобранный объект преобразуется в кодовый объект")
код = ст.компиляция()
распечатать (код)
печать("\n")
print("Результат вычисления данного выражения выглядит следующим образом:")
res = оценка (код)
печать (разрешение) Вывод:
В приведенной выше программе нам сначала нужно импортировать модуль анализатора, а затем мы объявили выражение для вычисления, и для анализа этого выражения мы должны использовать функцию parser.expr(). Затем мы можем оценить данное выражение, используя функцию eval().
В Python иногда мы получаем данные в формате даты и времени, которые могут быть в формате CSV или в текстовом формате. Таким образом, для анализа таких форматов в надлежащих форматах даты и времени Python предоставляет функцию parse_dates(). Предположим, у нас есть файл CSV, содержащий данные, а сведения о времени данных разделены запятой, что затрудняет чтение, поэтому для таких случаев мы используем parse_dates(), но перед этим мы должны импортировать pandas, поскольку эта функция предоставляется pandas .
В Python мы также можем анализировать параметры и аргументы командной строки, используя модуль argparse, который очень удобен для интерфейса командной строки. Предположим, у нас есть команды Unix для выполнения через интерфейс командной строки Python, такой как ls, в котором перечислены все каталоги на текущем диске, и также потребуется много разных аргументов, поэтому для создания такого интерфейса командной строки мы используем модуль argparse в Python. . Поэтому для создания интерфейса командной строки в Python нам нужно сделать следующее; во-первых, мы должны импортировать модуль argparse, затем мы создаем объект для хранения аргументов, используя ArgumentParser() через модуль argparse, позже мы можем добавить аргументы в объект ArgumentParser(), который будет создан, и мы можем запускать любые команды в команде Python линия. Обратите внимание, что запуск любых команд, кроме команды справки, не является бесплатным. Итак, вот небольшой фрагмент кода о том, как написать код Python для создания интерфейса командной строки с использованием модуля argparse.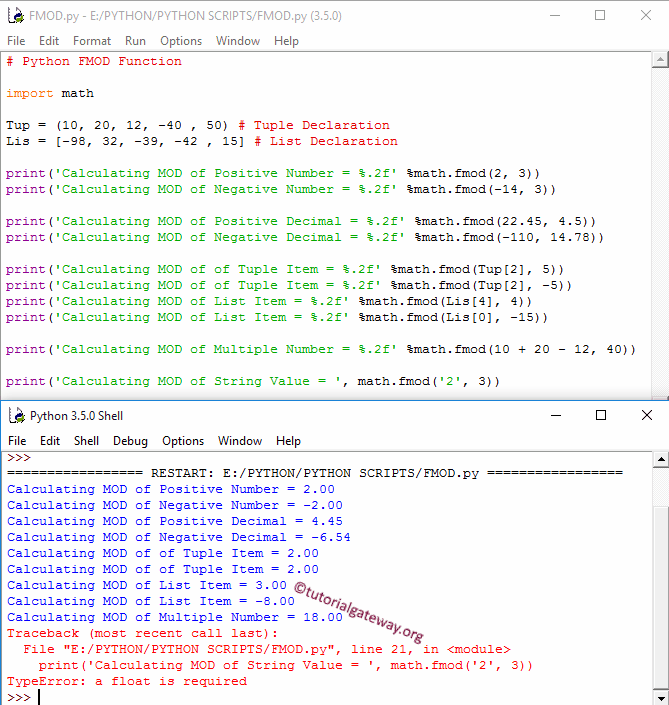
import argparse
Теперь мы создали объект с помощью ArgumentParser(), а затем можем проанализировать аргументы с помощью функции parser.parse_args().
парсер = argparse.ArgumentParser() parser.parse_args()
Чтобы добавить аргументы, мы можем использовать add_argument() вместе с передачей аргумента этой функции, такой как parser.add_argument(“ls”). Итак, давайте посмотрим на небольшой пример ниже.
Пример #2
Код:
import argparse
синтаксический анализатор = argparse.ArgumentParser()
parser.add_argument("ls")
аргументы = парсер.parse_args()
печать (args.ls) Вывод:
Таким образом, в приведенной выше программе мы можем видеть скриншот вывода, поскольку мы не можем использовать какие-либо другие команды, поэтому это выдаст ошибку, но когда у нас есть модуль argparse, мы можем запустить команды в оболочке Python следующим образом:
$ python ex_argparse.
 py --help
использование: ex_argparse.py [-h] echo
py --help
использование: ex_argparse.py [-h] echo Позиционные аргументы:
echo
Дополнительные аргументы:
-h, --helpпоказать это справочное сообщение и выйти $ python ex_argparse.py Обучение Эдукба
Заключение
В этой статье мы делаем вывод, что Python предоставляет концепцию синтаксического анализа. В этой статье мы увидели, что процесс синтаксического анализа очень прост, что в целом представляет собой процесс разделения большой строки одного типа формата для преобразования этого формата в другой требуемый формат, известный как синтаксический анализ. Это делается разными способами в Python, используя строковые методы Python, такие как split() или strip(), используя python pandas для преобразования файлов CSV в текстовый формат. Здесь мы увидели, что можем даже использовать модуль синтаксического анализатора для использования его в качестве интерфейса командной строки, где мы можем легко запускать команды с помощью модуля argparse в Python. Выше мы увидели, как использовать argparse и как мы можем запускать команды в терминале Python.
Выше мы увидели, как использовать argparse и как мы можем запускать команды в терминале Python.
Рекомендуемые статьи
Это руководство по Python Parser. Здесь мы также обсудим введение и работу синтаксического анализатора Python, а также различные примеры и реализацию его кода. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- Часовой пояс Python
- Ошибка имени Python
- Модуль ОС Python
- Цикл событий Python
анализатор — доступ к деревьям разбора Python — документация по Python 3.7.16
Модуль синтаксического анализатора предоставляет интерфейс для внутреннего синтаксического анализатора Python и
компилятор байт-кода. Основная цель этого интерфейса — позволить Python
код для редактирования дерева синтаксического анализа выражения Python и создания исполняемого кода
из этого. Это лучше, чем пытаться разобрать и изменить произвольный код Python.
фрагмент кода в виде строки, потому что синтаксический анализ выполняется способом, идентичным
код, формирующий приложение. Это также быстрее.
Это также быстрее.
Note
Начиная с Python 2.5 гораздо удобнее врезаться в Abstract
Стадия генерации и компиляции синтаксического дерева (AST) с использованием и
модуль.
Есть несколько вещей, на которые следует обратить внимание в отношении этого модуля, которые важны для создания
использование созданных структур данных. Это не учебник по редактированию синтаксического анализа
деревья для кода Python, но некоторые примеры использования модуля синтаксического анализатора :
представлены.
Самое главное, хорошее понимание грамматики Python, обрабатываемой
требуется внутренний парсер. Полную информацию о синтаксисе языка см.
к Справочнику по языку Python. Парсер
сам создается из спецификации грамматики, определенной в файле
Grammar/Grammar в стандартном дистрибутиве Python. Деревья синтаксического анализа
хранящиеся в объектах ST, созданных этим модулем, являются фактическими выходными данными из
внутренний синтаксический анализатор при создании функциями expr() или suite() ,
описано ниже. Объекты ST, созданные с помощью
Объекты ST, созданные с помощью sequence2st() точно
имитировать эти структуры. Имейте в виду, что значения последовательностей, которые
считается «правильным», будет варьироваться от одной версии Python к другой, поскольку
формальная грамматика языка пересмотрена. Однако перенос кода из одного
Версия Python на другую в качестве исходного текста всегда будет позволять правильные деревья синтаксического анализа
быть создан в целевой версии, с единственным ограничением, что
переход на более старую версию интерпретатора не будет поддерживать более новую
языковые конструкции. Деревья синтаксического анализа обычно несовместимы из одного
версию на другую, хотя исходный код обычно был совместим с предыдущими версиями в пределах
крупная серия релизов.
Каждый элемент последовательностей, возвращаемых st2list() или st2tuple()
имеет простую форму. Последовательности, представляющие нетерминальные элементы в грамматике
всегда имеют длину больше единицы.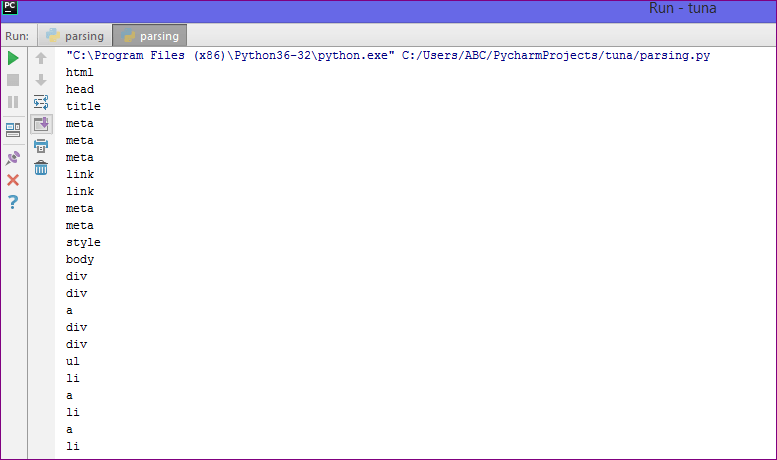 Первый элемент представляет собой целое число, которое
Первый элемент представляет собой целое число, которое
определяет произведение в грамматике. Этим целым числам даны символические имена
в заголовочном файле C Include/graminit.h и модуль Python
символ . Каждый дополнительный элемент последовательности представляет компонент
продукции, распознанной во входной строке: это всегда последовательности
которые имеют ту же форму, что и родитель. Важным аспектом этой структуры
следует отметить, что ключевые слова, используемые для идентификации типа родительского узла,
например ключевое слово если в if_stmt включены в
дерево узлов без какой-либо специальной обработки. Например, ключевое слово if
представлен кортежем (1, 'if') , где 1 — числовое значение
связан со всеми токенами NAME , включая имена переменных и функций
определяется пользователем. В альтернативной форме возвращается, когда информация о номере строки
запрашивается, тот же токен может быть представлен как (1, 'if', 12) , где
12 представляет собой номер строки, в которой был найден терминальный символ.
Терминальные элементы представлены почти так же, но без дочерних элементов.
элементы и добавление исходного текста, который был идентифицирован. Пример
из , если приведенное выше ключевое слово является репрезентативным. Различные типы
терминальные символы определены в заголовочном файле C Include/token.h и
токен модуля Python .
Объекты ST не требуются для поддержки функциональности этого модуля,
но предоставляются для трех целей: позволить приложению амортизировать
стоимость обработки сложных деревьев синтаксического анализа, чтобы обеспечить представление дерева синтаксического анализа
который экономит место в памяти по сравнению со списком или кортежем Python
представление и облегчить создание дополнительных модулей на C, которые
манипулировать деревьями синтаксического анализа. В Python можно создать простой класс-оболочку для
скрыть использование объектов ST.
Модуль анализатора определяет функции для нескольких различных целей.
наиболее важными целями являются создание объектов ST и преобразование объектов ST в
другие представления, такие как деревья синтаксического анализа и объекты скомпилированного кода, но
также являются функциями, которые служат для запроса типа дерева синтаксического анализа, представленного
СТ объект.
См. также
- Модуль
symbol Полезные константы, представляющие внутренние узлы дерева разбора.
- Модуль
токен Полезные константы, представляющие листовые узлы дерева синтаксического анализа и функции для
проверка значений узла.
Создание объектов ST
Объекты ST могут быть созданы из исходного кода или из дерева синтаксического анализа. При создании
объект ST из исходного кода, для создания 'eval' используются разные функции
и 'exec' форм.
-
парсер.выражение( источник ) Функция
expr()анализирует источник параметра , как если бы это был вход
вскомпилировать (источник, 'file.. Если синтаксический анализ успешен, объект ST py', 'eval')
создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае
возникает соответствующее исключение.
 py', 'eval')
py', 'eval') -
парсер.набор( источник ) Функция
suite()анализирует параметр источник как если бы это был ввод
вскомпилировать (источник, 'file.py', 'exec'). Если синтаксический анализ успешен, объект ST
создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае
возникает соответствующее исключение.
-
парсер.последовательность 2-я( последовательность ) Эта функция принимает дерево синтаксического анализа, представленное в виде последовательности, и строит
внутреннее представительство, если возможно. Если он может подтвердить, что дерево соответствует
к грамматике Python, и все узлы являются допустимыми типами узлов в основной версии
Python объект ST создается из внутреннего представления и возвращается
к вызываемому. Если возникла проблема с созданием внутреннего представления или
если дерево не может быть проверено,Возникает исключение ParserError. Ан
Объект ST, созданный таким образом, не должен считаться корректно компилируемым; нормальный
исключения, вызванные компиляцией, все еще могут быть инициированы, когда объект ST
передано вcompilest(). Это может указывать на проблемы, не связанные с синтаксисом
(например, исключениеMemoryError), но также может быть связано с такими конструкциями, как
в результате синтаксического анализаdel f(0), который ускользает от синтаксического анализатора Python, но
проверяется компилятором байт-кода.Последовательности, представляющие терминальные токены, могут быть представлены как двухэлементными
списки вида(1, 'имя')или трехэлементные списки вида(1, 'имя'). Если присутствует третий элемент, он считается допустимым.
'имя', 56)
номер строки. Номер строки может быть указан для любого подмножества терминала
символов во входном дереве.
 Если возникла проблема с созданием внутреннего представления или
Если возникла проблема с созданием внутреннего представления или
-
парсер.tuple2st( последовательность ) Это та же функция, что и
последовательность2st(). Эта точка входа
поддерживается для обратной совместимости.
Преобразование объектов ST
объекта ST, независимо от исходных данных, использованных для их создания, могут быть преобразованы в
деревья синтаксического анализа, представленные в виде деревьев списков или кортежей, или могут быть скомпилированы в
объекты исполняемого кода. Деревья синтаксического анализа могут быть извлечены со строкой или без нее.
информация о нумерации.
-
парсер.st2list( st , line_info=False , col_info = Ложь ) Эта функция принимает объект ST от вызывающего объекта в st и возвращает
Список Python, представляющий эквивалентное дерево синтаксического анализа. Полученный список
представление можно использовать для проверки или создания нового дерева синтаксического анализа в
форма списка. Эта функция не дает сбоев, пока доступна память для сборки
представление списка. Если дерево синтаксического анализа будет использоваться только для проверки,
st2tuple() Вместо этого следует использовать, чтобы уменьшить потребление памяти и
фрагментация. Когда требуется представление списка, эта функция
значительно быстрее, чем извлечение представления кортежа и преобразование этого
во вложенные списки.Если line_info истинно, информация о номере строки будет включена для всех
токены терминала в качестве третьего элемента списка, представляющего токен. Примечание
что предоставленный номер строки указывает строку, на которой маркер заканчивается .
Эта информация опускается, если флаг ложный или опущен.
 Эта функция не дает сбоев, пока доступна память для сборки
Эта функция не дает сбоев, пока доступна память для сборки-
парсер.st2tuple( st , line_info=False , col_info=False ) Эта функция принимает объект ST от вызывающего объекта в st и возвращает
Кортеж Python, представляющий эквивалентное дерево синтаксического анализа. Кроме возврата
кортеж вместо списка, эта функция идентичнаst2list().Если line_info истинно, информация о номере строки будет включена для всех
токены терминала в качестве третьего элемента списка, представляющего токен. Этот
информация опускается, если флаг ложен или опущен.
 Кроме возврата
Кроме возврата-
парсер.компилятор( st , имя_файла='<синтаксическое дерево>' ) Компилятор байтов Python может быть вызван для объекта ST для создания объектов кода
который можно использовать как часть вызова встроенной функцииexec()илиeval()
функции. Эта функция предоставляет интерфейс компилятору, передавая
внутреннее дерево синтаксического анализа от st до синтаксического анализатора, используя имя исходного файла
указывается параметром имени файла . Значение по умолчанию для имя файла
указывает, что источником был объект ST.Компиляция объекта ST может привести к исключениям, связанным с компиляцией; ан
примером может бытьSyntaxError, вызванная деревом синтаксического анализа дляdel f(0):
это утверждение считается допустимым в рамках формальной грамматики Python, но
не юридическая языковая конструкция. Синтаксическая ошибка
условие обычно генерируется байтовым компилятором Python, что
почему он может быть поднят в этот момент на 9Модуль парсера 0096 . Большинство причин
Ошибка компиляции может быть диагностирована программно путем проверки синтаксического анализа.
дерево.
 Синтаксическая ошибка
Синтаксическая ошибка Запросы к объектам ST
Предусмотрены две функции, которые позволяют приложению определить, было ли ЗБ
созданный как выражение или набор. Ни одна из этих функций не может быть использована для
определить, было ли ЗП создано из исходного кода с помощью expr() или
suite() или из дерева синтаксического анализа через sequence2st() .
-
парсер.isexpr( ст ) Когда st представляет форму
'eval', эта функция возвращаетTrue, в противном случае
он возвращаетFalse. Это полезно, поскольку объекты кода обычно не могут быть запрошены.
для получения этой информации с помощью существующих встроенных функций. Обратите внимание, что код
объекты, созданныеcompilest(), также не могут быть запрошены таким образом, и
идентичны созданным встроеннымифункция compile().
-
парсер.номер( ст ) Эта функция повторяет
isexpr()в том, что она сообщает, является ли объект ST
представляет собой форму'exec', широко известную как «набор». Это не безопасно
предположим, что эта функция эквивалентна, а не isexpr(st), как дополнительная
синтаксические фрагменты могут поддерживаться в будущем.
Исключения и обработка ошибок
Модуль синтаксического анализатора определяет одно исключение, но может также передавать другие встроенные
исключения из других частей среды выполнения Python. Посмотреть каждый
функцию для получения информации об исключениях, которые она может вызвать.
- исключение
парсер.Ошибка синтаксического анализа Исключение возникает при сбое в модуле анализатора. Это
обычно производится для ошибок проверки, а не для встроенного
Синтаксическая ошибкавозникает при обычном разборе. Аргумент исключения
либо строка, описывающая причину сбоя, либо кортеж, содержащий
последовательность, вызвавшая сбой, из дерева синтаксического анализа, переданного вsequence2st()
и поясняющая строка. Вызовыsequence2st()должны иметь возможность
обрабатывать любой тип исключения, в то время как вызовы других функций в модуле
нужно будет знать только простые строковые значения.
Обратите внимание, что функции compilest() , expr() и suite() может
вызывать исключения, которые обычно возникают при разборе и компиляции
процесс. К ним относятся встроенные исключения MemoryError ,
OverflowError , SyntaxError и SystemError . В этих
В этих
случаях эти исключения имеют все значения, обычно связанные с ними.
Подробную информацию см. в описаниях каждой функции.
СТ Объекты
Упорядоченные сравнения и сравнения на равенство поддерживаются между объектами ST. Маринование
ST-объекты (используя pickle модуль) также поддерживается.
-
парсер.STТип Тип объектов, возвращаемых
expr(),suite()и
последовательность2st().
Объекты ST имеют следующие методы:
-
СТ.компиляция( имя_файла=’<синтаксическое дерево>‘ ) То же, что и
compilest(st, имя файла).
-
СТ.isexpr() То же, что и
isexpr(st).
-
СТ.номер() То же, что и
issuite(st).

-
СТ.tolist( line_info=False , col_info=False ) То же, что и
st2list(st, line_info, col_info).
-
ст.totuple( line_info=False , col_info=False ) То же, что и
st2tuple(st, line_info, col_info).
Пример: Эмуляция
compile()
Хотя между синтаксическим анализом и байт-кодом может выполняться множество полезных операций.
генерации, самая простая операция — ничего не делать. С этой целью с помощью
модуль парсера для создания промежуточной структуры данных эквивалентен
к коду
>>> code = compile('a + 5', 'file.py', 'eval')
>>> а = 5
>>> оценка(код)
10
Эквивалентная операция с использованием модуля анализатора несколько длиннее, и
позволяет сохранить промежуточное внутреннее дерево синтаксического анализа как объект ST:
>>> парсер импорта
>>> st = parser.