Содержание
Урок 1. Пишем парсер каталога товаров на Python
Всем привет! В данном уроке мы займемся разработкой парсера каталога товаров.
Код будем писать на языке программирования Python в среде разработки Python IDLE. В рамках данной статьи не рассматривается установка и настройка последних. Для получения подробной информации вы можете посетить официальный сайт Python.
Собирать данные о товарах будем со специального сервиса на нашем сайте – тестового каталога, где к каждому полю подписан CSS-селектор, по которому можно найти элемент на странице – это нам пригодится в процессе парсинга. Сохранять результат будем в файл формата JSON.
Библиотеки, используемые в данной статье:
1. requests – официальную страница.
2. beautifulsoup4 – ссылка на документацию.
3. json – является частью стандартной библиотеки python.
По любым возникающим в ходе урока вопросам оставляйте комментарии ниже.
Ссылка на полный текст исходного кода находится в конце статьи.
Шаг 1. Подготовка
Предварительно проанализируем наш каталог товаров: видим 10 страниц, 117 товаров. Каждая карточка содержит поля: название, цена, артикул, таблица характеристик, изображение и описание. Выберем для парсинга название, цену и характеристики.
Алгоритм на поверхности:
1. Пройтись по страницам с 1 по 10 и собрать ссылки на страницы с товарами.
2. Зайти на страницу каждого из товаров и спарсить интересующие нас данные.
3. Сохранить полученные данные в файл формата JSON.
Шаг 2. Установка зависимостей
Использовать мы будем две сторонние библиотеки:
1. requests – для загрузки HTML-кода страниц по URL.
2. beautifulsoup4 – для парсинга данных с HTML, поиска элементов на странице.
Установим зависимости командами:
pip install requests pip install beautifulsoup4
Также мы будем использовать стандартную библиотеку json для записи результата в файл JSON формата.
Шаг 3. Программирование
Приступим к написанию кода – создадим основной скрипт main.py.
Объявим функцию crawl_products, которая будет принимать на вход количество страниц с карточками товаров, а на выходе возвращать список ссылок на товары с этих страниц.
Объявим вторую функцию parse_products, которая принимает список URL-адресов, парсит необходимую информацию по каждому товару и добавляет её в общий массив data, который и возвращает
Нам известно, что всего 10 страниц с карточками товаров, объявим глобальную переменную PAGES_COUNT – количество страниц.
# -*- coding: utf-8 -*-
PAGES_COUNT = 10
def crawl_products(pages_count):
urls = []
return urls
def parse_products(urls):
data = []
return data
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
if __name__ == '__main__':
main()
Для парсинга страницы нам необходимо получить HTML-код страницы с помощью библиотеки requests и создать объект BeautifulSoup на основе этого кода.
Создадим метод get_soup, который принимает на вход URL-адрес страницы и возвращает объект BeautifulSoup, который мы будем использовать для поиска элементов на странице по CSS-селекторам. Если не удалось загрузить страницу по переданному URL, метод возвращает None.
def get_soup(url, **kwargs):
response = requests.get(url, **kwargs)
if response.status_code == 200:
soup = BeautifulSoup(response.text, features='html.parser')
else:
soup = None
return soup
Приступим к реализации функции crawl_products. Смотрим, как формируется URL-адрес конкретной страницы, на примере страницы с номером 2:
https://parsemachine.com/sandbox/catalog/?page=2
Видим GET-параметр page=2, который является номером страницы. Объявим переменную fmt, которая будет шаблоном URL-адреса страницы с товарами. Пройдемся по страницам с 1 по pages_count.
Cформируем URL-адрес страницы с номером page_n и получим для него объект BeautifulSoup, используя метод get_soup. Если soup страницы является None, то произошла ошибка при получении HTML-кода страницы, поэтому мы прерываем обработку с помощью оператора break.
Если soup страницы является None, то произошла ошибка при получении HTML-кода страницы, поэтому мы прерываем обработку с помощью оператора break.
Если soup получен, то нас интересует элемент «Название товара», который является ссылкой на товар. Копируем CSS-селектор .product-card .title и передаем его аргументов в метод soup.select(), который вернет множество найденных на странице элементов. Для каждого из них мы получим атрибут href, а затем сформируем URL и добавим его в общий массив. Ниже приведен полный текст данной функции.
def crawl_products(pages_count):
urls = []
fmt = 'https://parsemachine.com/sandbox/catalog/?page={page}'
for page_n in range(1, 1 + pages_count):
print('page: {}'.format(page_n))
page_url = fmt.format(page=page_n)
soup = get_soup(page_url)
if soup is None:
break
for tag in soup.select('.product-card .title'):
href = tag. attrs['href']
url = 'https://parsemachine.com{}'.format(href)
urls.append(url)
return urls
attrs['href']
url = 'https://parsemachine.com{}'.format(href)
urls.append(url)
return urls
 attrs['href']
url = 'https://parsemachine.com{}'.format(href)
urls.append(url)
return urls
attrs['href']
url = 'https://parsemachine.com{}'.format(href)
urls.append(url)
return urls
Переходим к реализации parse_products. Пройдемся по каждому товару и получим soup аналогично предыдущей функции.
Первое поле, которое мы парсим – «Название товара». Вызываем метод select_one у объекта soup, который аналогичен методу select за исключением, что возвращает один элемент, найденный на странице. В качестве аргумента передаем CSS-селектор #product_name. Получаем видимый текст и очищаем от пробельных символов с обеих сторон.
Аналогично получаем поле «Цена» по CSS-селектору #product_amount.
Переходим к парсингу характеристик товара. Найдем строки по CSS-селектору #characteristics tbody tr и для каждой из них получим значения ячеек, которые сохраним в переменную techs. Данные по товару мы спарсили, теперь сохраним их в переменую item и добавим в массив data. Ниже представлен полный код функции.
def parse_products(urls):
data = []
for url in urls:
print('product: {}'.format(url))
soup = get_soup(url)
if soup is None:
break
name = soup.select_one('#product_name').text.strip()
amount = soup.select_one('#product_amount').text.strip()
techs = {}
for row in soup.select('#characteristics tbody tr'):
cols = row.select('td')
cols = [c.text.strip() for c in cols]
techs[cols[0]] = cols[1]
item = {
'name': name,
'amount': amount,
'techs': techs,
}
data.append(item)
return data
Осталось добавить запись в файл и парсер будет готов!
Импортируем библиотеку json для записи данных в JSON-файл. Объявляем глобальную переменную OUT_FILENAME – имя файла для записи результата.
Переходим к сохранению. Вызовем метод json.dump() с передачей аргументов:
1. Сохраняемый объект – у нас это data.
2. Файл.
Также передадим ensure_ascii=False, чтобы символы кириллицы не экранировались при записи в файл. И зададим отступ в 1 символ indent=1.
Итог
Все, сохранение в файл готово, и разработка парсера завершена!
import json
...
OUT_FILENAME = 'out.json'
...
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
with open(OUT_FILENAME, 'w') as f:
json.dump(data, f, ensure_ascii=False, indent=1)
Ссылка на полный текст исходного кода – catalog.py
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!
Q-Parser — как появился сервис для парсинга товаров — Трибуна на vc.
 ru
ru
Как из простенького скрипта «для своих» появился сервис по парсингу и выгрузке товаров.
879
просмотров
Идея
Почти четыре года назад нам с женой захотелось сделать собственный интернет-проект, который был бы полезен людям и, само-собой, приносил бы прибыль. Было время, были возможности и желание «что-нибудь небольшое, но свое».
На тот момент мы развивали сайт совместных покупок СП-Юга (который, увы, ушел на дно из-за самой концепции СП) и основной проблемой было наполнение каталога товаров актуальной информацией.
Оптовые поставщики обычно имеют свой сайт, но не имеют больше ничего. Хорошо, если есть хоть какой-то файл с товарами (иногда нет ничего). Его нужно привести к определенному формату, скачать фото товаров и т.д. и т.п. А если файла нет, то товары переносились вручную. Это занимает просто огромную кучу времени.
Чтобы оптимизировать этот процесс я писал парсеры товаров для популярных сайтов поставщиков. Товары парсились и формировался файл нужного формата со всеми данными. Процесс занимал от нескольких минут до пары часов (в зависимости от числа товаров), но не требовал ничего — нужно просто подождать. Жутко удобно.
Процесс занимал от нескольких минут до пары часов (в зависимости от числа товаров), но не требовал ничего — нужно просто подождать. Жутко удобно.
Именно тогда на участке дороги Краснодар — Ейск родилась идея сделать парсинг услугой в виде отдельного сервиса. И в мае 2017 года мы приступили к реализации, чтобы уже 6 ноября запустить первую версию Q-Parser.
Первая версия самопального дизайна (из веб-архива 2018). Очень цветасто.
6 месяцев разработки
Начали в мае, а закончили уже в ноябре. 6 ноября сайт стал публичным и появились первые пользователи.
Быстро? Медленно? Не знаю. Для одного разработчика и его второй половинки, думаю, вышло неплохо.
Инвестиции в проект составили ужасающие 199 руб за домен и 800 руб за первую VDS в месяц. Это действительно весь список затрат. Реклама появилась чуть позже, но и по сей день она занимает небольшое место в бюджете.
Вся разработка и первое наполнение — своими силами.
Название? Вот у меня буква Q на клавиатуре первая, пусть будет.
Дизайн? Я всю жизнь в вебе, сайтов что-ли не видел. Что-то накидал и пойдет.
И оно пошло. Скоро будет 2 миллиона парсингов.
Так сейчас выглядит страница со списком товаров. Номер парсинга настоящий.
Q-Parser — сервис с душой
Техническая реализация и эволюция сервиса по парсингу и выгрузке товаров — это отдельная история взлетов (в основном нагрузки) и падений. Если вам интересно как развить сервис с одной VDS за 800 руб до kubernetes кластера на десятке машин, обязательно напишите: будет заинтересованность, будут и статьи.
Фишкой Q-Parser изначально было (и остается сейчас) отношение к клиентам и поддержка. Не просто «парсим товары». Сервис решает проблемы.
Оказалось, что чат на сайте подобного сервиса — это кладезь идей. Поначалу использовался Carrotquest, но наплыв в чат был настолько большой, что стоимость «морковки» выросла выше стоимости основных серверов (в итоге сделал собственный чат. Он, кстати, доступен бесплатно всем желающим).
Он, кстати, доступен бесплатно всем желающим).
Сделать универсальный сервис для каждого оказалось противоречащей самой-себе задачей. «Универсально для каждого» — не бывает. На старте брался за реализацию буквально каждой «хотелки» пользователей, что доставляло много технических проблем, но в итоге привело к появлению основных фишек парсера. Например:
- Парсинг по расписанию. Попросили примерно через месяц после запуска. Юлии понадобились постоянные ссылки на файлы для загрузки товаров в Яндекс.Маркет. Теперь у нас есть парсинг по расписанию с постоянными, обновляемыми ссылками на файлы.
- Скачивание фото товаров. Необходимо было скачать фото с одного сайта электроинструментов. В итоге на Q-Parser появилась возможность скачивать фото любых товаров, которые мы парсим.
- Редактирование фото. Кто-то захотел покрутить и обрезать фото товаров. Хотели? Готово. Теперь можно крутить-вертеть, резать и даже накладывать на фото товаров свои вотермарки.
- Фильтры и сортировки. Часто просили не просто спарсить «втупую», но еще и убрать ненужные товары или оставить только товары определенного бренда или с определенной ценой. Сказано — сделано. Фильтрация миллионов товаров в реал-тайме — задачка не из легких.
Спустя все эти года стало ясно, что универсальность для каждого — все же возможна. Q-Parser сейчас работает как конструктор: вы можете просто парсить товары «как есть» и ничего с ними не делать, а можете автоматически создать полноценный каталог со своими ценами, описаниями и характеристиками товаров.
Текущая версия дизайна. Тоже есть «свои» изменения по сравнению с разработанным макетом
Аудитория
Идея парсера родилась из совместных покупок и основная аудитория должна была быть именно оттуда: организаторы совместных покупок.
Но реальность оказалась иной. «Орги» СП — очень своеобразная аудитория (не хочу никого обидеть, честно). Совместные покупки построены на принципе экономии, а платить за сервис, чтобы сэкономить — такое себе.
Совместные покупки построены на принципе экономии, а платить за сервис, чтобы сэкономить — такое себе.
Сейчас аудитория проекта почти полностью состоит из владельцев небольших интернет-магазинов. Работать с такими магазинами через парсер — очень удобно.
Есть и недовольные, без этого никуда. Парсинг — сам по себе не может что-то гарантировать. Сайты меняются, перестают работать или ставят защиту от ботов, которую за адекватные цены не обойти. Редко, но случается. С этим приходится мириться, либо уходить на фриланс разработку парсеров (но и цены там в десятки раз выше, плюс никакой поддержки).
Продвижение
Парсинг — как ни крути, довольно узко-специализорованная штука. Кому-то действительно проще тратить кучу времени на наполнение каталогов, а кто-то просто ничего не обновляет.
Продвигать парсинг на старте было достаточно просто. У нас уже была стартовая аудитория организаторов СП. Из контекстной рекламы потянулись пользователи. Хорошо работает сарафанное радио: люди любят Q-Parser.
В целом парсить сайты за 400 руб в месяц без особых ограничений — это практически бесплатно. Некоторые парсят миллионы товаров в месяц за все ту же цену.
До недавнего времени было много пользователей из стран СНГ и, особенно, из Украины. Кто-то даже остался.
Но с определенного этапа, которого проект уже достиг, сделать рывок по размеру аудитории становится сложно. Контекстная реклама уперлась в размер аудитории (просто некуда тратить деньги в Директе), а другая реклама либо не эффективна, либо слишком уж дорогая.
Во время короно-пандемии люди массово кинулись в онлайн и это было хорошо заметно и в посещаемости и в прибыли.
При этом проект все же постепенно развивается, даже не смотря на события последних лет.
А минусы?
Куда же без минусов. Универсальность сервиса накладывает свои ограничения.
За годы работы реализованы десятки форматов выгрузки товаров: от обычного YML до форматов для Insales или там Storeland (их много разных). И проблема в том, что невозможно «любые» данные о товарах поместить в «любой» формат.
И проблема в том, что невозможно «любые» данные о товарах поместить в «любой» формат.
Как это работает технически. Берем страницу каждого товара и приводим ее к «голым» данным: название, артикул, цена, характеристики и т.п.
В итоге получается, что из какой-то абстрактной массы данных нужно получить довольно стандартизированный файл с данными, что не всегда возможно. Например, на каких-то сайтах есть информация об остатках, а на других ее просто нет и в форматах, где обязательно указание остатков будет просто какое-то число (обычно 999 для товаров в наличии и 0 для отсутствующих)
Тем не менее, в целом идея очень даже работает. Пользователи постоянно пишут благодарности: переносить каталоги из тысяч товаров вручную — очень сложно, а мы делаем это быстро и за пару чашек кофе.
Что дальше?
Q-Parser постоянно развивается и никто не планирует останавливаться. И хоть внешне это может быть не слишком заметно, но обновления выходят практически каждый день: на данный момент в основном репозитории 3659 коммитов (а всего там 11 отдельных репозиториев).
Буду рад новым идеям и комментариям, а для новых пользователей: ловите промокод на подключение тарифов -15% VCRU
P.S. Если кто-то знает адекватный способ приема платежей из СНГ (кроме крипты), поделитесь.
разбор данных и фото товаров
Получение каталога товаров с ценами, описанием и фото.
Все интернет-магазины создаются с использованием языка HTML, это стандартизированный язык разметки страниц во всемирной паутине, поэтому все сайты используют одни и те же элементы для разных блоков, парсер E-Trade Jumper использует этот стандарт для получения данных от интернет-магазина сайт.
Список наиболее часто используемых HTML-тегов, которые есть на страницах интернет-магазинов:
- тег div. Универсальный блочный элемент, позволяющий выделить на сайте раздел с визуальным контентом. Это может быть список продуктов.
- Тег а. Отображает ссылку на страницу. Это могут быть ссылки на товары в определенной категории.
- Тег h2. Выводит заголовок первого уровня (есть еще h3, h4, h5, h5, h6). Это может быть название продукта.
- тег p. Отображает текстовый абзац. Это может быть описание товара.
- тег таблицы. Отображает таблицу. Это может быть таблица атрибутов продукта.
- ул тег. Отображает маркированный список. Это может быть краткое описание предмета.
- тег изображения. Предназначен для отображения на странице изображения. Это могут быть фотографии товара.
Теги могут содержать название стиля для визуального отображения информации на сайте, например, указанный блочный стиль позволяет отображать жирным шрифтом или зеленым цветом любой элемент. На основе этих стандартизированных данных в системе E-Trade Jumper можно настроить парсер для любого интернет-магазина для получения необходимой вам информации, парсер E-Trade Jumper использует селекторы CSS (стили дизайна сайта) или XPath (язык запросов для сайта). элементы) для получения данных.
элементы) для получения данных.
Для настройки парсера выполните следующие операции:
- Открытие прайс-листов.
- Нажмите кнопку Добавить контрагента.
- Укажите имя сайта.
- Выберите вкладку Парсер.
- Нажмите кнопку «Добавить сайт».
- Укажите ссылку на главную страницу сайта.
- Укажите селекторы тегов.
Для добавления нового парсера сайта откройте окно «Прайс-листы», нажмите кнопку «+» и выберите «Добавить контрагента»
Укажите наименование контрагента (интернет-магазина) и выберите группу, по умолчанию доступны следующие группы: Поставщик, Конкурент, Клиент.
После добавления контрагента вам будет предложено выбрать откуда вы хотите скачать данные, в этом списке выберите пункт «Парсер сайтов» и нажмите кнопку «Добавить сайт»
Укажите адрес онлайн хранилище для парсинга данных
Настройка парсера для получения данных из интернет-магазина
Заказ парсера для скачивания товаров из интернет-магазина:
- Получить ссылки на категории товаров
- Получить ссылки на продукты
- Получить карточки товаров и сохранить необходимую информацию
После добавления парсера интернет-магазина откроется окно настроек
Таблица настройки содержит типы операций и список полей для хранения в них данных. Типы операций — это этапы парсера для получения данных с сайта.
Типы операций — это этапы парсера для получения данных с сайта.
Например, чтобы получить список товаров с сайта, нужно получить ссылки на категории товаров, чтобы парсер мог открыть страницу для получения информации о каждом товаре, поэтому первая операция, которую выполнит парсер, это «Список ссылок на категории товаров».
Типы операций:
- Список ссылок на категории товаров. Используется для получения ссылок на категории товаров.
- Список ссылок на товары. Используется для получения ссылок на продукты.
- Карточный продукт. Используется для получения информации о продукте. При выполнении данной операции вы можете получить наименование товара, артикул производителя, модель, гарантию, наименование производителя, фотографии, видеообзоры и другую информацию с сайта.
- Атрибуты продукта. Используется для получения атрибутов продукта.
Описание столбцов сетки для настройки парсера
- Селектор операций. Признак главного селектора получения данных с сайта для выполнения данной операции.
- Имя поля. Имя операции или поля для хранения данных.
- Селектор #1-4. Парсер E-Trade Jumper использует селекторы CSS (стили сайта) или XPath (язык запросов для элементов сайта) для получения данных со страниц сайта. В полях селектора указаны условия поиска нужных вам блоков на сайте и получения информации из них.
- Ссылка для тестирования. Ссылка на страницу сайта для тестирования сбора данных. Для каждой операции указывается ссылка на отдельный раздел сайта, например, для операции «Список ссылок на категории товаров» указывается ссылка на главную страницу сайта, где есть список всех Категории продукта. Для проверки получения реквизитов товаров для операции «Карточка товара» указывается ссылка на товары.
- Текст для очистки. Ключевые слова для очистки при получении данных. Например, в названии товара на сайте есть лишний текст, который вы не хотите получать с сайта, вы можете установить этот текст в поле «Текст для очистки», чтобы убрать его.
- Найти. Поиск текста.
- Заменить. Текст для замены (на основе найденного текста).
- Получить HTML. Если необходимо сохранить форматирование текста, полученного со страницы сайта с помощью html-тегов, то установите этот флаг.
- Регулярное выражение. Можно использовать регулярное выражение для получения нужного значения на основе текста, полученного через селектор, то есть более детально разобрать строку на составляющие и получить в итоге то, что нужно.
- XPath. Активация селектора режима языка запросов XPath.
- Максимальное количество результатов. Позволяет ограничить загрузку данных для тестирования загрузки, чтобы не ждать, пока скачается весь сайт, можно настроить получать только 1 ссылку на категорию и получать, например, 2 ссылки на товары, для этого вы можно установить количество результатов для каждой операции.
- Товар в данной операции. Вы можете получать товары, не открывая карточки товаров на сайте. Этот режим будет полезен, если вы хотите получить только цены на товары и другие значения, которые доступны при перечислении товаров в категории.
- Примечание. Примечание для строки настройки, например, вы можете сохранить себе напоминание о том, что означает эта настройка.
 Признак главного селектора получения данных с сайта для выполнения данной операции.
Признак главного селектора получения данных с сайта для выполнения данной операции.

Селекторы могут быть в виде html-тегов и стилей CSS (стилей оформления сайта), а также в виде языка запросов для элементов сайта XPath. Чтобы активировать режим XPath в сетке, установите этот флаг для нужного поля или операции
Этап №1. Получение списка ссылок на категории товаров
Для получения списка ссылок на категории товаров необходимо найти селектор ссылок, который ведет на категорию, для этого скопируйте ссылку с сайта (обычно это главная страница сайта) в поле «Ссылка для тестирования» и нажмите кнопку «Т»
Откроется вкладка «Скачать тестирование», в которой отобразится страница по указанной вами ссылке , на нем должны быть видны категории товаров.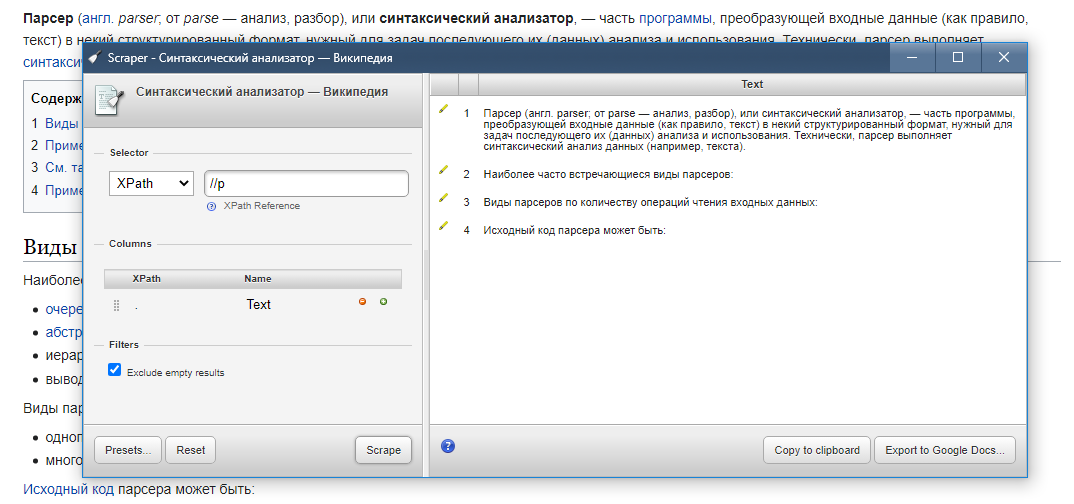 Результаты работы парсера отображаются слева. Ваша задача — получить список ссылок на категории товаров с сайта; если парсер успешно настроен, вы увидите список ссылок на категории в левой части экрана.
Результаты работы парсера отображаются слева. Ваша задача — получить список ссылок на категории товаров с сайта; если парсер успешно настроен, вы увидите список ссылок на категории в левой части экрана.
Внимание! Тестирование загрузки возможно только для сайтов, использующих защищенный протокол https, только для таких сайтов можно визуально проверить получение данных во вкладке «Тестирование загрузки», при этом еще можно настроить парсинг таких сайтов (используя незащищенный http), но визуально проверить получение данных не получится, то есть все теги и селекторы нужно вводить «вслепую» (наугад).
Для поиска селектора ссылок по категориям товаров нажмите правой кнопкой мыши на название любой категории и выберите «Просмотреть код», после чего откроется окно браузера с исходным кодом сайта. Вы можете расположить его как угодно, например, слева или внизу экрана
Вы также можете открыть ссылку в отдельной вкладке браузера, если вам нужно больше места на экране для поиска селектора ссылок на продукты и сделать то же самое там.
Ищем блоки товарных категорий и ссылку в них
Ваша задача — найти блоки ссылок на категории товаров. После того, как вы выбрали пункт «Просмотреть код», в браузере откроется исходный код сайта в том месте, где была нажата правая кнопка мыши, в данном примере мы нажали на название категории и видим, что ссылки на категории находятся в тегах «div» и «a» (изображение ниже кликабельно для увеличения).
Как видите, каждая категория товаров имеет блок «div» и содержит ссылки «a», в то время как блок «div» имеет название стиля links-list (class=»links-list») и ссылку «a» имеет имя стиля link() .
Напишем селекторы в настройках парсера в таком виде: через пробел указать имена тегов и через точку указать имена стилей. Можно просто указать тег «а» и его стиль, если он уникален в пределах страницы для ссылки, ведущей на категорию товара (тогда 1-й абзац не обязателен).
Проверяем результат, для этого нажимаем кнопку «Т». Как видно на примере мы получили 74 ссылки на категории товаров, то есть наш парсер уже умеет искать категории на стороннем сайте
Этап №2.
 Получение списка ссылок на товары
Получение списка ссылок на товары
В чтобы получить список ссылок на товары, необходимо найти селектор ссылок на товары на странице со списком товаров в категории, открыть любую категорию товаров на сайте и скопировать ссылку в поле «Ссылка для тестирования», затем нажать кнопку « кнопка «Т»
Откроется вкладка «Скачать тестирование», в которой будет отображаться страница по указанной Вами ссылке, на ней должен быть виден список товаров. Результаты работы парсера отображаются слева. Ваша задача — получить список ссылок на товары с сайта; если парсер успешно настроен, вы увидите список ссылок в левой части экрана.
Для поиска селектора ссылок на товары нажмите правой кнопкой мыши на название любого товара и выберите «Просмотреть код», после чего откроется окно браузера с исходным кодом сайта.
Ищем блоки товаров и ссылку в них
Ваша задача — найти блоки товаров со ссылками на карточку товара. После того, как вы выбрали пункт «Просмотреть код», в браузере откроется исходный код сайта в том месте, где была нажата правая кнопка мыши, в данном примере мы нажали на название товара и видим, что ссылки на товар расположены в тегах «div» и «a».
То есть каждый товар в результатах поиска имеет блок «div» и содержит в себе ссылку «a», а блок «div» имеет имя стиля плитки (class=»tile»).
То есть каждый товар в списке имеет один и тот же стиль, называемый тайлом, и мы будем использовать эту информацию для получения ссылок на каждый товар.
Напишем селекторы в настройках парсера в таком виде: указываем название стиля через точку и тег «а» через пробел
Проверяем результат, для этого нажимаем кнопку «Т». Как видно на примере, у нас получилось 28 ссылок на товары, то есть наш парсер уже умеет находить товары на стороннем сайте
Настройка навигации по страницам (пагинация)
При открытии категории товаров обычно отображаются не все товары, например, может отображаться только 28 товаров, следующие товары находятся на странице №2, такой режим называется pagination (пагинация). Чтобы получить ссылки на товары на других страницах, вам нужно найти селектор ссылок, который ведет на следующую страницу, вам нужно найти на странице блок навигации для перехода на другие страницы (paginator), в примере ниже этот блок выглядит так это и имеет такой селектор
ul[name=»paginator»] ли
Найденный селектор для пагинации товаров указывается в поле «Селектор №2»
Есть сайты, на которых ссылки на пагинацию не содержат текущую ссылку на страницу (ссылку на категорию товара), тогда пагинация может определяться некорректно, пример некорректного определения, когда ссылка содержит только номер страницы, в итоге ссылка будет вести на главную страницу сайта
Для решения этой задачи необходимо знать текущий адрес страницы. Вам нужно открыть исходный код сайта и попытаться найти адрес на текущую страницу, если таковая будет найдена, то нужно указать в поле Селектор №3 теги, как ее получить, например, из Блок «Хлебные крошки» (хлебные крошки): разд. панировочные сухари а. активный
Вам нужно открыть исходный код сайта и попытаться найти адрес на текущую страницу, если таковая будет найдена, то нужно указать в поле Селектор №3 теги, как ее получить, например, из Блок «Хлебные крошки» (хлебные крошки): разд. панировочные сухари а. активный
Этап 2 можно использовать для получения только списка товаров, этот режим будет полезен, когда нужно получить только цены на товары, без описаний, технических характеристик. характеристики и фотографии, при этом скорость получения данных с сайта будет в разы выше (нет необходимости переходить в карточки товаров на сайте). Для активации этого режима установите флаг «Товары в этой операции» для типа операции «Список ссылок на товары», затем укажите селекторы для полей, которые необходимо заполнить с сайта. Соответственно, вам не нужно заливать лектор, чтобы получить ссылки на товары, только получая «пагинацию».
Этап №3. Получение данных из карточки товара.
По аналогии с поиском селектора ссылок на товары, вам необходимо найти селекторы для нужных вам полей в карточке товара, для этого в поле «Ссылка для тестирования» прописываем ссылку на тестовый товар и открываем ее
Необходимо нажать правой кнопкой мыши на название товара и выбрать пункт «Просмотреть код», после чего откроется окно браузера с исходным кодом сайта.
Например, название товара находится в теге h2 9.0005
Пропишем в таблице настроек селектор h2
Далее ищем селектор на цену товара
Напишите селектор вот так
разд. основной ценовой диапазон. price-number span
Далее ищем селектор по описанию товара
Напишите селектор вот так
div[itemrop=»описание»]
Для ссылок на фото прописываем такой селектор
разд. image img::attr(src)
Проверка результата
Этап №4. Получение атрибутов товара.
Для получения атрибутов товара необходимо указать селектор для блока атрибута (таблицы) и строковый селектор, содержащий имя и значение атрибута.
Процедура:
- В поле «Селектор №1» указать селектор для блока атрибутов
- В поле «Селектор №2» указать селектор для блока, содержащего имя и значение атрибута (то есть для строки таблицы атрибутов)
- В поле «Имя атрибута» укажите селектор, где находится имя атрибута
- В поле «Значение атрибута» укажите селектор, где находится значение атрибута
Пример настройки
Пример настройки на основе исходного кода сайта
Результат проверки получения атрибутов товара (характеристик, свойств)
Если атрибуты находятся на отдельной странице.
Если атрибуты находятся на отдельной странице, например, при нажатии на вкладку «Характеристики» открывается новая страница, то тут есть два решения, все они сводятся к получению ссылки на страницу, где находятся атрибуты товара, чтобы программа может пройти через него и получить данные.
Вариант №1. Ссылка есть в исходнике html.
Селектор №3 необходимо настроить для типа операции «Атрибуты товара», чтобы получить ссылку (или часть ссылки на страницу атрибута).
Например, при нажатии на вкладку на сайте есть такой html код, то селектор для получения ссылки будет: а. nav-tabs-link
Вариант №2. К ссылке на товар добавляется префикс, которого нет явно в исходнике html.
Необходимо для типа операции «Атрибуты товара» прописать префикс ссылки в селекторе №4 для добавления его в ссылку товара.
Например, вы можете написать: tab=характеристики, тогда программа откроет ссылку на товар + префикс, тем самым парсер перейдет на страницу атрибутов товара. Что именно прописывать в приставке определяется опытным путем после тщательного анализа сайта.
Что именно прописывать в приставке определяется опытным путем после тщательного анализа сайта.
Запуск парсинга с загрузкой каталога товаров со стороннего сайта.
Загрузка товаров с сайта интернет-магазина будет производиться в следующем порядке:
- Получение ссылок на категории товаров
- Получение ссылок на товары
- Получаем карточки товаров и сохраняем необходимую информацию
Для тестирования загрузки установите максимальное количество результатов для этапов, чтобы быстро проверить парсинг данных с сайта интернет-магазина. В данном примере будет загружена одна ссылка на категорию товаров со списком товаров, из которых будут получены три ссылки на товары
Как получить опции продукта
В программе E-Trade Jumper опционные товары — это виртуальные товары, которые привязаны к одному основному товару, тогда как на исходном сайте это одна карточка товара с набором опций. Для получения опций необходимо зарегистрировать селектор для получения названий опций, указать разделитель-запятую и установить флаг «Опция товара»
При тестировании значения будут отображаться через запятую
После загрузки товаров с сайта для каждого значения, указанного на сайте, будет создан 1 основной товар и несколько дополнительных товаров.
Платформа Parse
Справка и связь
Наши предпочтительные каналы связи для помощи, проблем и обсуждений.
Тег parse-platform переполнения стекаИспользуйте для любых вопросов на уровне кода, связанных с платформой Parse. При необходимости используйте и другие теги, такие как parse-server, parse-dashboard, parse-cloud-code, parse-javascript-sdk, parse-ios-sdk, parse-android-sdk, parse-dotnet-sdk, parse- rest-api и parse-live-query. |
Форум сообществаИспользуйте для вопросов и обсуждений на высоком уровне о платформе Parse. |
Проблемы с GitHubИспользуйте для сообщения об ошибках и создания запросов на включение для определенных репозиториев. |
Сервер синтаксического анализа и панель мониторинга
REST-сервер и панель управления для управления вашими данными.
Документация
Узнайте больше о развертывании собственного сервера Parse или ознакомьтесь с нашими подробными руководствами по SDK для клиентов.
SDK и библиотеки
Версии наших SDK с открытым исходным кодом с соответствующими ссылками, чтобы узнать больше.
Объектив-C
Справочник API
Последняя версия
Андроид
Направляющая
Справочник API
Последняя версия
JavaScript
Направляющая
Справочник API
Последняя версия
Руководство
Справочник API
Последняя версия
Флаттер
Направляющая
Справочник API
Последняя версия
Направляющая
Справочник API
Последняя версия
Направляющая
Справочник API
Последняя версия
.
