Содержание
Как спарсить любой сайт? / Хабр
Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте.
Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
 Пример: http://techcrunch.com/sitemap.xml
Пример: http://techcrunch.com/sitemap.xmlПоищите XHR запросы в консоли разработчика
Кабина моего самолета
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Кнопка, которую я искал месяцы
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get.Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана.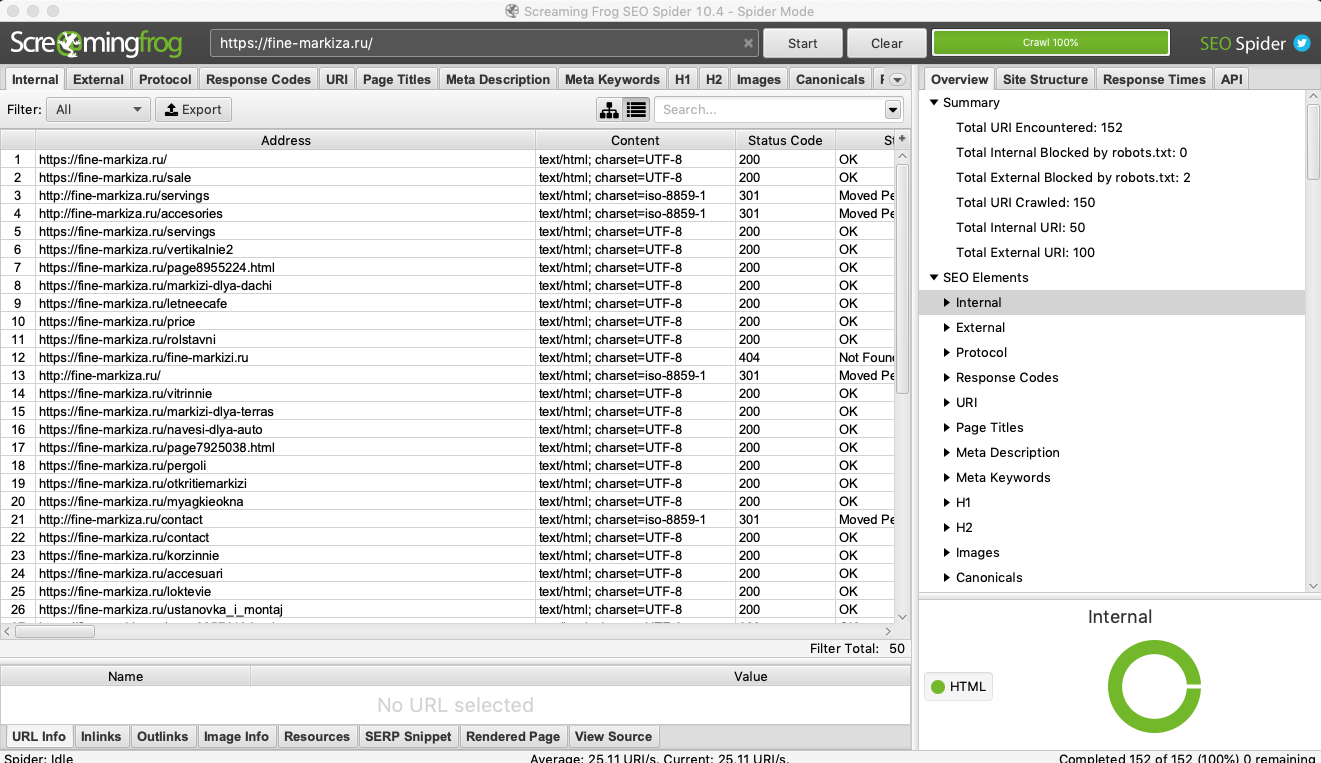 Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_source
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile. password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver
password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driverЗаметьте фложок enableVNC. Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
Как быстро собрать данные с сайтов
Что такое парсеры и как они работают
Для сбора контента
Для мониторинга конкурентов
Для парсинга SEO-параметров
Для сбора контактных данных
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Парсинг помогает быстро собрать, обработать и проанализировать большие объёмы информации на различных сайтах. Это полезно при изучении целевой аудитории, анализе конкурентов, исследовании рынка и не только. Однако важно выбрать подходящий инструмент с учётом конкретной задачи.
Сделали подборку парсеров для сбора данных с сайтов и разобрались, для каких целей они подходят.
Что такое парсеры и как они работают
Парсеры — это специальные программы, которые собирают различные данные с сайтов по заданным критериям. Общий принцип работы всех парсеров примерно одинаков:
- переход на нужный ресурс и копирование его кода;
- анализ кода и нахождение необходимой информации;
- структуризация и сохранение данных.
Работу парсера можно представить так, как будто человек ходит по разным сайтам и копирует нужные данные. В случае с парсингом по сайтам ходит робот, который выполняет нужные задачи в десятки раз быстрее.
Вид информации, которую собирает парсер, зависит от его исходной функции и настроек. Можно собирать самые разные данные: цены конкурентов, товарные позиции, характеристики и описания товаров, контактные данные, контент определённых тематики и формата.
После анализа и обработки парсер сохраняет все данные в определённом формате — например, в таблице Excel, документах PDF или TXT.
Насколько законно применение парсеров
О законности использования парсеров много спорят. Есть мнение, что автоматический сбор данных нарушает сразу несколько законов — о защите персональных данных, об охране конфиденциальной информации, об авторском праве и т.д. Это не совсем так.
Согласно Конституции РФ каждый человек может «свободно искать, получать, передавать, производить и распространять информацию любым законным способом». То есть теоретически ручной или автоматический сбор информации, выложенной в общий доступ, преступлением не является. Но есть нюансы.
То есть теоретически ручной или автоматический сбор информации, выложенной в общий доступ, преступлением не является. Но есть нюансы.
Для законного использования парсеров важно соблюдать три основных условия:
- Все данные, которые собирает сервис, должны находиться в открытом доступе и не попадать под закон об авторском праве.
- Сбор информации не должен негативно влиять на анализируемый сайт и вызывать сбои в его работе.
- Собирать данные можно только законными способами, без взлома сайта.
Если кратко, то парсинг любых данных, которые можно найти в открытом доступе и скопировать вручную — это законная деятельность.
Программу для парсинга можно разработать с нуля специально под конкретную задачу. Но такое решение будет дороже в использовании. В большинстве случаев можно обойтись готовыми инструментами. Рассмотрим парсеры для разных задач.
Для сбора контента
Под сбором контента подразумевают парсинг новостей и заголовков, описаний к товарам, комментариев, любых публикаций по ключевым словам, видеоматериалов, картинок, постов в соцсетях.
При парсинге контента важно учитывать один важный нюанс , который касается последующего использования данных. Если вы собираете информацию, например, для отслеживания ситуации в нише или поиска актуальных идей, то вы не совершаете ничего противозаконного. Если же планируете публикацию собранных данных, то не забывайте об авторском праве. При размещении спарсенного материала в исходном виде обязательно указывайте источник и/или запрашивайте согласие автора на публикацию.
Примеры парсеров для сбора контента:
X-Parser Light. Собирает тематический контент по списку ключевых слов или ссылок. Кроме текстовых данных парсит видео и изображения. Поддерживает любые поисковые системы и практически любой язык. Работает в формате десктопного приложения. Стоимость — 4 100 ₽ единоразово (периодически бывают скидки).
Catalogloader. Умеет парсить информацию с сайтов интернет-магазинов — описания товаров, фото, характеристики, артикулы и пр. Можно самостоятельно настраивать критерии сбора. Весомый плюс — парсер работает в облаке, без скачивания на ПК. Есть бесплатная версия. Платные тарифы начинаются от 5 400 ₽/мес.
Весомый плюс — парсер работает в облаке, без скачивания на ПК. Есть бесплатная версия. Платные тарифы начинаются от 5 400 ₽/мес.
XMLDATAFEED. Сервис позиционирует себя как инструмент для парсинга любой информации, которую можно собрать законным способом. Например, можно искать товарные описания, тексты, фото и изображения, ассортимент и характеристики. Особенность сервиса — в отсутствии готовых решений. Под каждый запрос команда разработчиков создаёт уникальный парсер для нужной задачи. Стоимость — индивидуально.
Диггернаут. Облачный сервис, предлагающий платные и бесплатные парсеры. Стоимость платных решений — от 700 ₽/мес. С помощью специальных инструментов пользователь может создать собственный парсер (диггер) под нужный запрос. Можно заказать разработку сложных решений.
Примеры парсеров для мониторинга конкурентов:
Marketparser. Сервис мониторит цены в интернет-магазинах и на маркетплейсах. Достаточно загрузить список товаров, и в течение 3–20 минут по ним будет составлен актуальный отчёт. Можно использовать функцию автоматического ценообразования — на основе собранных данных сервис определит оптимальную стоимость товаров. Стоимость парсера зависит от количества проверок и начинается от 4 500 ₽/мес.
Можно использовать функцию автоматического ценообразования — на основе собранных данных сервис определит оптимальную стоимость товаров. Стоимость парсера зависит от количества проверок и начинается от 4 500 ₽/мес.
ALL RIVAL. Этот парсер собирает цены конкурентов по указанным ссылкам. Из преимуществ — есть бесплатное автосопоставление результатов. Сервис доступен на бесплатном тарифе с ограничением до двух сайтов. Стоимость платного тарифа начинается от 5 099 ₽/мес.
Priceva. С помощью этого сервиса можно собирать цены конкурентов. Есть функция автоматической переоценки товаров пользователя. Все собранные цены конвертируются в валюту аккаунта на любом тарифе. Стоимость от 7 000 ₽/мес. Есть бесплатный тариф с мониторингом до десяти сайтов.
uXprice. Это SaaS-решение. Программа собирает цены из рекламных объявлений, по ссылкам на конкретные товары и на указанных сайтах. Есть возможность сравнительного анализа цен конкурентов. Можно использовать функции конкурентного ценообразования для определения оптимальной стоимости своих товаров.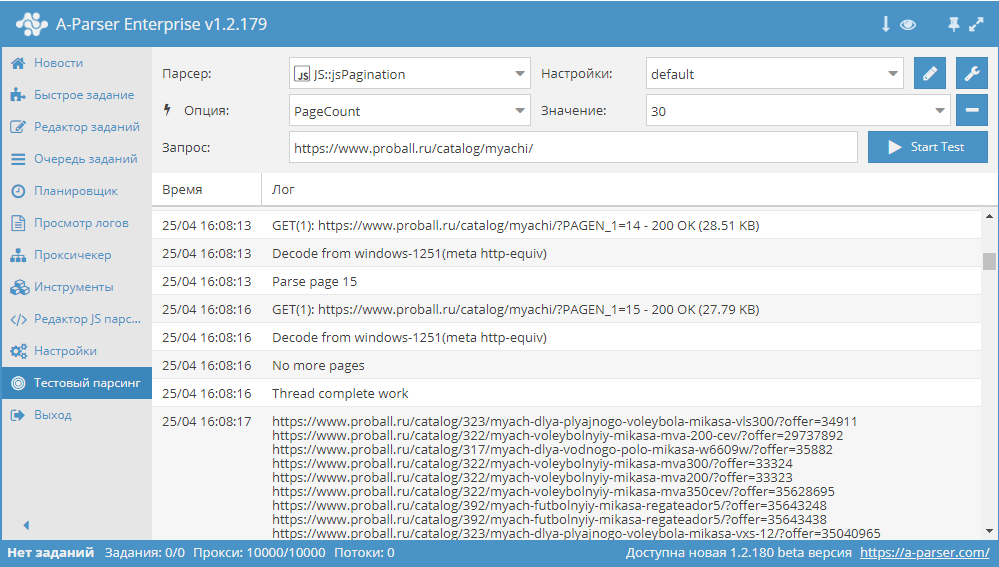 Сервис умеет мониторить цены конкурентов в 36 странах. Стоимость парсера — от $99/мес. Есть бесплатная версия на 7 дней.
Сервис умеет мониторить цены конкурентов в 36 странах. Стоимость парсера — от $99/мес. Есть бесплатная версия на 7 дней.
Для парсинга SEO-параметров
Сбор SEO-данных полезен при внутренней, технической и внешней оптимизации. Парсеры помогают быстро осуществить комплексный анализ ресурса. Некоторые инструменты имеют узкий функционал, другие умеют собирать самые разные параметры.
SEO-парсеры можно применять как для анализа собственного ресурса, так и для отслеживания конкурентов.
Примеры парсеров для сбора SEO-данных:
Screaming Frog SEO Spider. Многофункциональный парсер-сканер, который умеет собирать огромное количество разных данных — метатеги, XML-карты, битые ссылки, атрибуты Alt у картинок, дублированный контент, сведения о технической оптимизации и многое другое. Бесплатно можно проверить до 500 URL-адресов. Платная версия — $209/год. SEO Spider работает в формате приложения для ПК.
PR-CY. Сервис позволяет в режиме онлайн выполнить SEO-аудит сайта. Можно искать позиции ресурса в поиске, мета-теги, коды ответов сервера, заголовки, внешние исходящие ссылки, проблемные страницы. Стоимость — от 990 ₽/месяц. Есть бесплатный доступ на 7 дней.
Можно искать позиции ресурса в поиске, мета-теги, коды ответов сервера, заголовки, внешние исходящие ссылки, проблемные страницы. Стоимость — от 990 ₽/месяц. Есть бесплатный доступ на 7 дней.
Xenu’s Link Sleuth. Бесплатный парсер для поиска неработающих ссылок. Список собранных URL можно сортировать по любым критериям. Отчёт можно запросить в любое время. Работает как декстопное приложение.
A-Parser. Многофункциональный инструмент для профессионального использования. Умеет парсить любые данные в неограниченном объёме: ссылки, анкоры, сниппеты, позиции в поиске, рекламные блоки, ключевые слова и многое другое. Всего в сервисе доступно 90+ разных парсеров. Стоимость от $179 за пожизненную лицензию. При необходимости здесь можно заказать индивидуальную разработку парсеров по нужным параметрам.
Для сбора контактных данных
Больше всего сомнений в законности парсинга возникает при сборе контактных данных — телефонов, email-адресов, контактных лиц. Здесь важно понимать разницу между персональными и общедоступными данными. Кроме того, имеет значение способ использования собранной информации.
Кроме того, имеет значение способ использования собранной информации.
Например, собрать базу контактов потенциальных партнёров или поставщиков — это законно. А вот автоматический сбор email-адресов для рассылки нарушает закон о персональных данных. А за массовую рассылку по адресам, собранным из открытых источников, можно улететь в спам.
Примеры парсеров для сбора контактных данных:
ZoomInfo. Собирает контактные данные B2B — номера телефонов, email-адреса, ссылки на профили в соцсетях. Дополнительно можно парсить и другие важные данные о клиентах и партнёрах — веб-упоминания, должностные обязанности и иную информацию из публичного доступа. Стоимость сервиса — по запросу. Есть бесплатная пробная версия.
Hunter. Парсер для поиска людей, работающих в определённой компании, с их именем и адресом электронной почты. Дополнительное преимущество — бесплатный сервис для рассылки «холодных» писем. Стоимость парсера — от $49/мес. Есть бесплатный тариф с ограничениями.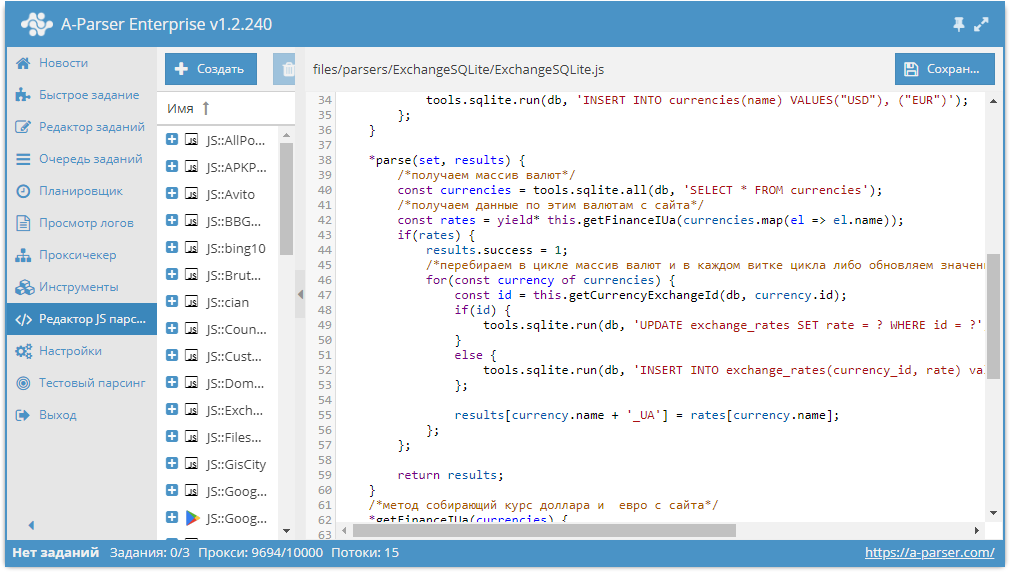
Scrapebox Email Scraper. Собирает email-адреса в разных поисковых системах, на разных сайтах и из локальных файлов. При экспорте можно сохранять URL-адрес, с которого получен email. Стоимость приложения для парсинга — $97 за лицензию (цена без скидки $197).
Выбирая подходящий парсер, учитывайте ваши задачи и периодичность использования. Часто за один раз можно собрать определённый тип данных — для этого хватит бесплатного инструмента или триал-версии платного сервиса. Для регулярного сбора данных выбирайте парсер, который настроен на работу с нужным вам типом данных. Если планируете собирать большое количество разной информации и в приоритете гибкие настройки парсинга, то, вероятно, стоит заказать индивидуальное решение.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Web Scraper — расширение №1 для парсинга веб-страниц
Больше, чем
500 000 пользователей гордятся тем, что используют наши решения!
 youtube.com/embed/aViWT-WpzYI?vq=highres&enablejsapi=true» allowfullscreen=»» frameborder=»0″ data-video-id=»main» title=»Web Scraper introduction video»>
youtube.com/embed/aViWT-WpzYI?vq=highres&enablejsapi=true» allowfullscreen=»» frameborder=»0″ data-video-id=»main» title=»Web Scraper introduction video»>
Укажи и щелкни
интерфейс
Наша цель — максимально упростить извлечение веб-данных.
Настройте парсер, просто указывая и нажимая на элементы.
Кодирование не требуется.
Web Scraper может извлекать данные с сайтов с несколькими уровнями навигации. Он может перемещаться по
сайт на всех уровнях.
- Категории и подкатегории
- Пагинация
- Страницы продукта
Создан для современного Интернета
Современные веб-сайты строятся на базе фреймворков JavaScript, которые упрощают использование пользовательского интерфейса, но
менее доступны для скребков. Web Scraper решает эту проблему:
- Полное выполнение JavaScript
- Ожидание запросов Ajax
- Обработчики разбиения на страницы
- Прокрутка страницы вниз
Модульная система выбора
Web Scraper позволяет создавать карты сайта из разных типов селекторов.
Эта система позволяет адаптировать извлечение данных к различным структурам сайта.
Экспорт данных в CSV, XLSX и JSON
форматы
Создавайте парсеры, парсите сайты и экспортируйте данные в формате CSV прямо из вашего браузера.
Используйте Web Scraper Cloud для экспорта данных в форматах CSV, XLSX и JSON, доступа к ним через API, веб-хуки или
экспортируйте его через Dropbox, Google Sheets или Amazon S3.
Начните использовать Web Scraper прямо сейчас!
Установить Web Scraper
Расширение Chrome
надстройка для файрфокса
Соскоблить
первый сайт
Необходимо автоматизировать извлечение данных?
Запуск заданий Web Scraper в нашем
Облако . Настроить
запланированный сбор данных и доступ к данным через
API или получить его в
ваш Dropbox
Планировщик
Scrapape a сайт по часовой, ежедневной или еженедельной базис
API
Управление скребками через API
Proxy
Ведение IP через тысячи IP -адресов
PARSER
Строительные поты
бесплатная пробная версия
Диего Кремер
Просто ПОТРЯСАЮЩЕ. Думал написать себе простой парсер для проекта
Думал написать себе простой парсер для проекта
а затем нашел этот супер простой в использовании и очень мощный скребок. Работал
отлично со всеми сайтами, которые я пробовал. Экономит много времени. Спасибо
что!
Карлос Фигероа
Мощный инструмент, превосходящий все остальные. Имеет кривую обучения, но
как только вы победите, это небо предел. Определенно инструмент стоит сделать
пожертвование и поддержка для дальнейшего развития. Способ пойти на
команда разработчиков этого инструмента.
Джонатан Х.
Это фантастика! Я экономлю часы, возможно дни. Я пытался слом и старый
сайт, плохо сделанный, без правильных разделов или разметки.
Используя магию WebScraper, он каким-то образом «знал» шаблон после того, как я выбрал 2
элементы. Удивительный.
Да, это кривая обучения, и вы ДОЛЖНЫ смотреть видео и читать документы.
Не снижайте рейтинг только потому, что вам неинтересно его изучать. Если вы положите
усилие, это спасет вашу задницу в один прекрасный день!
Продукты
- Браузерное расширение Web Scraper
- Облако веб-парсера
Компания
- Контакт
- Политика конфиденциальности веб-сайта
- Политика конфиденциальности расширения для браузера
- Медиа-кит
- Вакансии
Ресурсы
- Блог
- Документация
- Видеоуроки
- Скриншоты
- Тестовые площадки
- Форум
Copyright © 2023
Веб-парсер | Все права
зарезервировано | Сделано в zoom59
Соберите данные с любого веб-сайта в 1 клик
Недавно выпущенная версия 5. 7!
7!
добавить в
Хром
Это бесплатно
Data Miner — это расширение Google Chrome и расширение браузера Edge, которое помогает вам сканировать и очищать данные с веб-страниц.
и в файл CSV или электронную таблицу Excel.
Data Miner — это расширение Google Chrome и расширение браузера Edge, которое помогает вам сканировать и очищать данные с веб-страниц и
в файл CSV или электронную таблицу Excel.
Простой в использовании инструмент для автоматизации извлечения данных.
Интуитивно понятный пользовательский интерфейс и рабочий процесс.
Всего несколькими щелчками мыши вы можете запустить любое из более чем 60 000 правил извлечения данных в инструменте или создать свое собственное.
настраиваемые правила извлечения, чтобы получать с веб-страницы только те данные, которые вам нужны.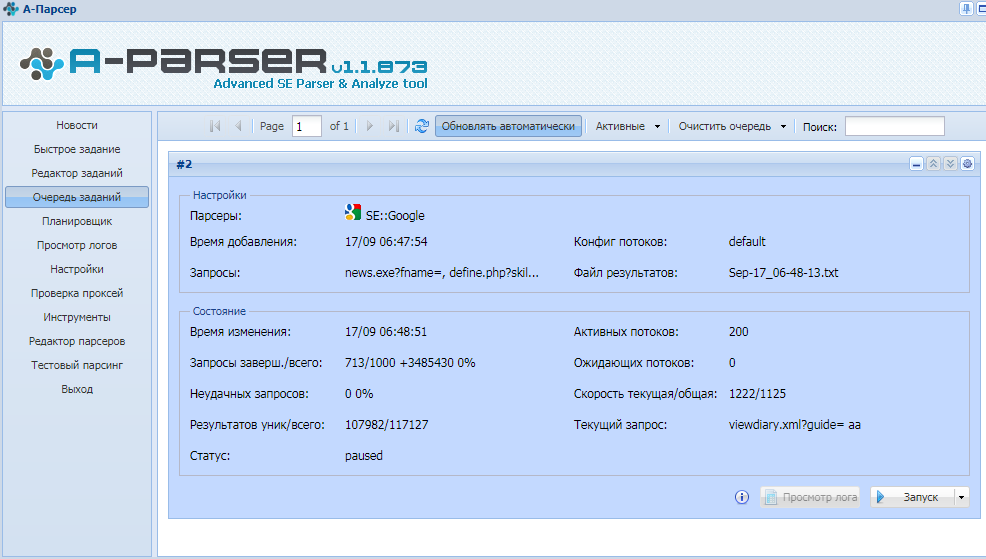
Одна страница или
многостраничный
автоматизированный парсинг
Data Miner может очищать одну страницу или сканировать сайт и извлекать данные с нескольких страниц, такие как результаты поиска, сведения о продуктах.
и цены, контактная информация, электронная почта, номера телефонов и многое другое. Затем Data Miner преобразует извлеченные данные в чистый
Формат файла CSV или Microsoft Excel для загрузки.
Data Miner поставляется с богатым набором функций, которые помогут вам извлечь любой текст на странице, которую вы видите в своем браузере. Это
может автоматически нажимать на кнопки и ссылки, переходить на подстраницы, открывать всплывающие окна и собирать из них данные.
Новые возможности Data Miner 5.0
Быстрый и простой сбор данных
Сотрите одним щелчком мыши.
Использование
50 000+
бесплатные готовые запросы, сделанные для
15 000+
популярные сайты.
Упрощенный рабочий процесс
Сканирование URL-адресов, разбивка на страницы и сбор данных с одной страницы в одном месте.
Кодирование не требуется
Новый инструмент Easy Finder помогает находить селекторы CSS и создавать собственные рецепты
Безопасное веб-сканирование и парсинг
Безопасное и надежное использование
Data Miner ведет себя так, как если бы вы сами нажимали на страницу в своем браузере.
Соскоблить без забот
Data Miner — это не бот.
Вас не заблокируют.
Сохраняйте конфиденциальность ваших данных
Data Miner никогда не продает ваши данные.
Data Miner никогда не разглашает ваши данные.
Data Miner — самый мощный парсер около
Парсинг в один клик
Используйте один из 50 000 общедоступных запросов на извлечение для извлечения данных одним щелчком мыши.
Пользовательский сбор данных
Создавайте собственные запросы на извлечение данных для сбора любых данных с любого сайта.
Автоматизация очистки
Запуск массовых операций очистки на основе списка URL-адресов.
Быстросъемные скобы для стола
Извлечь основные данные таблицы
правой кнопкой мыши на странице.
Разбиение на страницы
Автоматически переходить на следующую страницу и очищать с помощью автоматического разбиения на страницы.
Автоматизация заполнения форм
Data Miner может автоматически заполнять формы для вас, используя предварительно заполненный CSV.
Посмотрите, как работает Data Miner
Посмотрите, как легко вы можете преобразовать страницу в CSV
Отличная команда поддержки, которая поможет вам на каждом этапе
Мы здесь, чтобы помочь вам добиться успеха
Мы живем и работаем в Сиэтле, штат Вашингтон, США.