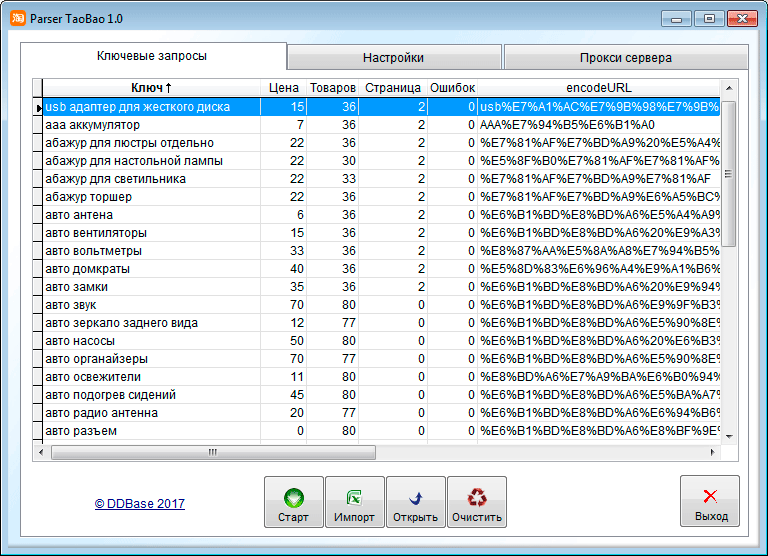
Содержание
Как пользоваться программами для парсинга контента и товаров, что такое парсер сайта
Чтобы поддерживать информацию на своем ресурсе в актуальном состоянии, наполнять каталог товарами и структурировать контент, необходимо тратить кучу времени и сил. Но есть утилиты, которые позволяют заметно сократить затраты и автоматизировать все процедуры, связанные с поиском материалов и экспортом их в нужном формате. Эта процедура называется парсингом.
Давайте разберемся, что такое парсер и как он работает.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен.
 Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков. - Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.
 Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.

Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Где найти парсер?
Добыть утилиту для поиска и преобразования информации с сайтов можно четырьмя путями.
- Использование сил своей команды разработчиков. Когда в штате есть программисты, способные создать парсер, адаптированный под задачи компании, то искать другие варианты не стоит. Этот будет оптимальным вариантом.
- Нанять команду разработчиков со стороны, чтобы те создали утилиту по вашим требованиям. В таком случае уйдет много ресурсов на создание ТЗ и оплату работы.
- Установить готовое приложение-парсер на компьютер. Да, оно тоже будет стоить денег, но зато им можно воспользоваться сразу. А настройки параметров в таких программах позволяют точно настроить схему парсинга.
- Воспользоваться веб-сервисом или браузерным плагином с аналогичной функциональностью. Встречаются бесплатные версии.

При отсутствии разработчиков в штате я бы советовал именно десктопную программу. Это идеальный баланс между эффективностью и затратами. Но если задачи стоят не слишком сложные, то может хватить и облачного сервиса.
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
- Программа работает самостоятельно. Не приходится тратить время на поиск и сортировку данных. К тому же собирает она информацию куда быстрее человека. Да еще и делает это 24 на 7, если понадобится.
- Парсеру можно «скормить» столько параметров, сколько потребуется, и идеально отстроить его для поиска только необходимого контента. Без мусора, ошибок и нерелеватной информации с неподходящих страниц.
- В отличие от человека, парсер не будет допускать глупых ошибок по невнимательности. И не устанет.
- Утилита для парсинга может подавать найденные данные в удобном формате по запросу пользователя.
- Парсеры умеют грамотно распределять нагрузку на сайт. Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
 Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
- либо заблокировать запросы со стороны, указав соотвествующие параметры в robots.txt;
- либо настроить капчу – обучить парсер разгадыванию картинок слишком затратно, никто не будет этим заниматься.
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Парсинг интернет-магазина
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов.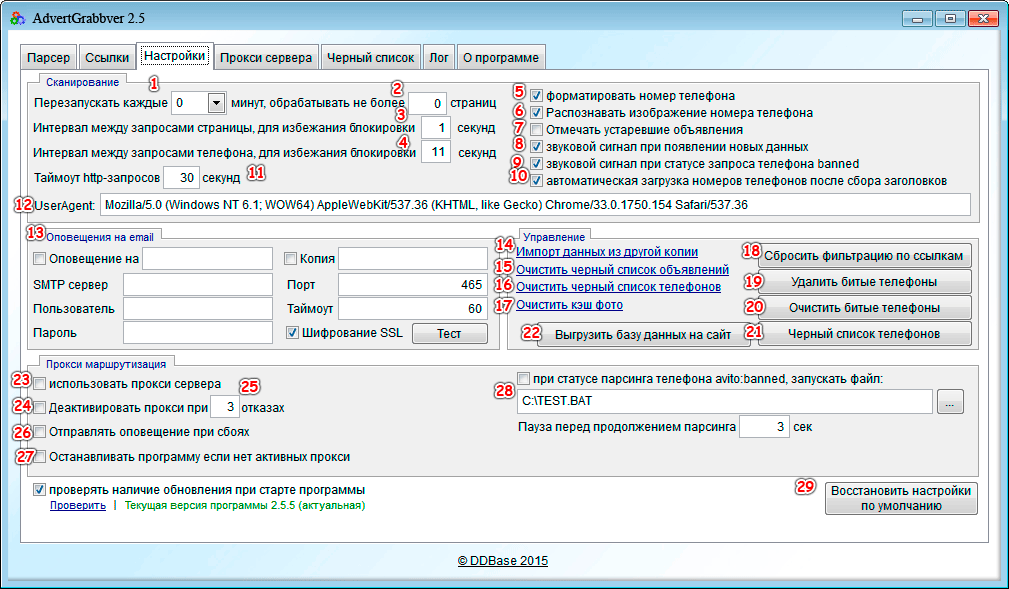 Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Во втором случае нужно разыскать код товара и указать его в программе-парсере. Упростить задачу помогают специальные приложения. Например, Catalogloader – парсер, специально созданный для автоматического сбора данных о товарах в интернет-магазинах.
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
- Import.io – востребованный набор инструментов для поиска информации на ресурсах. Позволяет парсить неограниченное количество страниц, поддерживает все популярные форматы вывода данных и автоматически создает удобную структуру для восприятия добытой информации.
- Mozenda – сайт для сбора информации с сайтов, которому доверяют крупные компании в духе Tesla. Собирает любые типы данных и конвертирует в необходимый формат (будь то JSON или XML). Первые 30 дней можно пользоваться бесплатно.
- Octoparse – парсер, главным преимуществом которого считается простота. Чтобы его освоить, не придется изучать программирование и хоть какое-то время тратить на работу с кодом. Можно получить необходимую информацию в пару кликов.
- ParseHub – один из немногих полностью бесплатных и довольно продвинутых парсеров.

Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
- ParserOK – приложение, сфокусированное на различных типах парсинга данных. Есть настройки для сбора данных о стоимости товаров, настройки для автоматической компиляции каталогов с товарами, номеров, адресов электронной почты и т.п.
- Datacol – универсальный парсер, который, по словам разработчиков, может заменить решения конкурентов в 99% случаев. А еще он прост в освоении.
- Screaming Frog – мощный инструмент для SEO-cпециалистов, позволяющий собрать кучу полезных данных и провести аудит ресурса (найти сломанные ссылки, структуру данных и т.п.). Можно анализировать до 500 ссылок бесплатно.
- Netspeak Spider – еще один популярный продукт, осуществляющий автоматический парсинг сайтов и помогающий проводить SEO-аудит.
 А еще он прост в освоении.
А еще он прост в освоении.
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
- Parsers – плагин для извлечения HTML-данных с веб-страниц и импорта их в формат XML или JSON. Расширение запускается на одной странице, автоматически разыскивает похожие страницы и собирает с них аналогичные данные.
- Scraper – собирает информацию в автоматическом режиме, но ограничивает количество собираемых данных.
- Data Scraper – дополнение, в автоматическом режиме собирающее данные со страницы и экспортирующее их в Excel-таблицу. До 500 веб-страниц можно отсканировать бесплатно. За большее количество придется ежемесячно платить.
- kimono – расширение, превращающее любую страницу в структурированное API для извлечения необходимых данных.

Вместо заключения
На этом и закончим статью про парсинг и способы его реализации. Этого должно быть достаточно, чтобы начать работу с парсерами и собрать информацию, необходимую для развития вашего проекта.
Парсинг: что это такое | Словарь маркетолога Roistat
Расскажем, что такое парсинг, что значит парсить данные, как правильно это делать и насколько законной является данная процедура. А также расскажем, какую информацию можно парсить на сайтах и какие есть виды парсинга.
Что такое парсинг
В переводе с английского слово парсинг означает структурирование.
Парсинг — это автоматизированный сбор и структурирование информации с сайтов при помощи программы или сервиса. Эта программа называется парсер и её задачей является сбор информации в соответствии с заданными параметрами.
Парсинг — автоматизированный сбор и структурирование информации с сайтов
Например, при помощи парсинга сайтов можно создать описание карточек товаров онлайн-магазина. Сотрудники не тратят время на их заполнение вручную, так как все данные собирает программа.
Сотрудники не тратят время на их заполнение вручную, так как все данные собирает программа.
Что значит «парсить сайт»
Парсинг сайта — это процесс сбора данных с сайтов. Вот как можно использовать такой тип парсинга:
- анализ собственного сайта — найти ошибки и внести изменения;
- анализ сайтов конкурентов — найти идеи для обновления собственного сайта, посмотреть описания товаров;
- анализ технической стороны сайта — поиск неработающих ссылок, повторяющихся страниц, оценка правильности работы robots.txt и других элементов;
- анализ сайта с точки зрения развития собственного бизнеса — анализ продуктов конкурентов, сбор информации по ценам, заголовкам, описаниям, оценка структуры сайтов.
Рассказали в блоге: как оптимизировать работу сайта.
Для чего нужен парсинг данных сайта
Большой объём данных непросто систематизировать вручную. Парсинг данных помогает:
Парсинг данных помогает:
- заполнить карточки товаров на новом сайте — на заполнение вручную уйдёт много времени;
- привести сайт в порядок — парсинг поможет найти страницы с ошибками, карточки товаров с неправильным описанием, повторы, ошибки в информации об оставшихся товарах на складе;
- оценить среднюю стоимость продукта, собрать информацию по другим компаниям на рынке;
- регулярно следить за изменениями — например, повышением цен или нововведениями у прямых конкурентов;
- собрать тексты с зарубежных сайтов и перевести их автоматически.
Плюсы парсинга
По сравнению со сбором данных, который бы делался вручную, с парсерами компании могут:
- собирать данные безошибочно;
- учитывать при поиске все заданные параметры;
- быстро собирать данные, 24 часа в сутки, регулярно — каждый месяц;
- собирать информацию в нужном формате: XLSX, XML, CSV, JSON;
- не нагружать сайт, чтобы не провоцировать эффект похожий на DDOS-атаку;
- выгружать данные на сайт.

Законно ли использовать парсинг
Иногда парсинг вызывает негативное отношение. Но в действительности парсинг не нарушает законодательных норм и юридическая ответственность за него не установлена.
Онлайн-обзор платформы Roistat
В прямом эфире расскажем, как сделать маркетинг эффективным
Подключиться
Вот что запрещает законодательство:
- собирать данные из личных кабинетов пользователей;
- DDOS-атаки (Distributed Denial of Service attack) — совокупность действий, которые могут вывести сайт из рабочего состояния;
- копирование контента: изображений, текстов.
Парсинг не нарушает закон, когда программы собирают данные из открытого доступа. Такую информацию можно собрать и вручную. Парсеры лишь ускоряют процесс и исключают неточности.
Незаконным может быть то, как владелец распоряжается собранной информацией — например, если бизнес полностью копирует статьи конкурентов.
Какой тип данных можно парсить с сайтов
Собирать разрешено информацию, которая находится в открытом доступе:
- характеристики товаров;
- названия продуктов;
- тексты для рерайта, например, для описания товаров;
- информацию о промоакциях и скидках;
- цены.

Как парсер собирает данные
Схематично алгоритм парсинга сайта можно представить так:
- по заданным параметрам программа ищет информацию на определённых сайтах или по всему интернету;
- данные собираются и систематизируются в зависимости от заданных настроек;
- создается отчёт в заданном формате. Как правило, парсеры поддерживают разные форматы и работают в том числе с PDF, RAR, TXT.
Виды парсинга
В зависимости от того, какие данные собираются, можно выделить несколько видов парсинга:
- Парсинг товаров — сбор данных о товарах из каталогов интернет-магазинов. Нужен, чтобы проанализировать ценовую политику конкурентов или заполнить описание собственных товаров.
- Парсинг цен — сбор данных о ценах конкурентов. На основе этой информации можно выстроить собственную ценовую политику и подобрать оптимальные цены для товаров.
- Парсинг в программировании — проводится с целью выявить проблем в производительности сайта или приложения, с кодом, найти другие недостатки в работе сайта.
- Парсинг слов — помогает проанализировать семантическое ядро сайта, разделить собранные ключевые слова на группы. Это помогает создавать рекламные объявления на Яндекс.Директ и Google Ads.
- Парсинг аудитории — поиск и сбор информации о пользователях соцсетей. Помогает найти целевую аудиторию, которой интересен продукт бизнеса. Для таргетинга рекламы можно указывать конкретные характеристики: пол, возраст, хобби, географическое положение, социальный статус аудитории. Компания предложит релевантный продукт аудитории и сократит затраты на рекламу.
- Парсинг выдачи — помогает определить сайты-лидеры поисковой выдачи и собрать важные для SEO данные о них: количество обратных ссылок, число индексируемых страниц по ключевой фразе и другое. Это поможет найти хорошие рекламные площадки и сайты для размещения ссылок.
Подключите сквозную аналитику Roistat
Получайте больше клиентов, не увеличивая рекламный бюджет
Подключить
Подпишись на Telegram
Подписаться
Что такое парсер? — Определение из Techopedia
Что означает парсер?
Синтаксический анализатор — это компонент компилятора или интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык. Синтаксический анализатор принимает входные данные в виде последовательности токенов, интерактивных команд или программных инструкций и разбивает их на части, которые могут использоваться другими компонентами в программировании.
Синтаксический анализатор принимает входные данные в виде последовательности токенов, интерактивных команд или программных инструкций и разбивает их на части, которые могут использоваться другими компонентами в программировании.
Синтаксический анализатор обычно проверяет все предоставленные данные, чтобы убедиться, что их достаточно для построения структуры данных в форме дерева разбора или абстрактного синтаксического дерева.
Реклама
Объяснения Techopedia Parser
Чтобы код, написанный в удобочитаемой форме, был понятен машине, он должен быть преобразован в машинный язык. Эту задачу обычно выполняет переводчик (интерпретатор или компилятор). Синтаксический анализатор обычно используется как компонент транслятора, который организует линейный текст в структуру, которой легко манипулировать (дерево синтаксического анализа). Для этого он следует набору определенных правил, называемых «грамматикой».
Общий процесс разбора состоит из трех этапов:
Лексический анализ: Лексический анализатор используется для создания токенов из потока входных строковых символов, которые разбиваются на небольшие компоненты для формирования осмысленных выражений.
Маркер — это наименьшая единица языка программирования, которая имеет какое-то значение (например, +, -, *, «функция» или «новый» в JavaScript).Синтаксический анализ: Проверяет, образуют ли сгенерированные токены осмысленное выражение. Это использует контекстно-свободную грамматику, которая определяет алгоритмические процедуры для компонентов. Они работают, чтобы сформировать выражение и определить конкретный порядок, в котором должны быть размещены токены.
Семантический анализ: Заключительный этап анализа, на котором определяются значение и последствия проверенного выражения и предпринимаются необходимые действия.
 Маркер — это наименьшая единица языка программирования, которая имеет какое-то значение (например, +, -, *, «функция» или «новый» в JavaScript).
Маркер — это наименьшая единица языка программирования, которая имеет какое-то значение (например, +, -, *, «функция» или «новый» в JavaScript).Основная цель синтаксического анализатора — определить, могут ли входные данные быть получены из начального символа грамматики. Если да, то каким образом можно получить эти входные данные? Это достигается следующим образом:
Анализ сверху вниз: Включает поиск в дереве анализа для нахождения самых левых производных входного потока с использованием расширения сверху вниз.
Синтаксический анализ начинается с начального символа, который преобразуется во входной символ до тех пор, пока все символы не будут переведены и не будет построено дерево разбора для входной строки. Примеры включают синтаксические анализаторы LL и синтаксические анализаторы рекурсивного спуска. Синтаксический анализ сверху вниз также называется прогнозирующим или рекурсивным анализом.Анализ снизу вверх: Включает перезапись ввода обратно к начальному символу. Он действует в обратном порядке, отслеживая самое правое происхождение строки до тех пор, пока дерево синтаксического анализа не будет построено до начального символа. Этот тип синтаксического анализа также известен как синтаксический анализ со сдвигом и уменьшением. Одним из примеров является синтаксический анализатор LR.
 Синтаксический анализ начинается с начального символа, который преобразуется во входной символ до тех пор, пока все символы не будут переведены и не будет построено дерево разбора для входной строки. Примеры включают синтаксические анализаторы LL и синтаксические анализаторы рекурсивного спуска. Синтаксический анализ сверху вниз также называется прогнозирующим или рекурсивным анализом.
Синтаксический анализ начинается с начального символа, который преобразуется во входной символ до тех пор, пока все символы не будут переведены и не будет построено дерево разбора для входной строки. Примеры включают синтаксические анализаторы LL и синтаксические анализаторы рекурсивного спуска. Синтаксический анализ сверху вниз также называется прогнозирующим или рекурсивным анализом.Парсеры широко используются в следующих технологиях:
Java и другие языки программирования.
HTML и XML.
Язык интерактивных данных и язык определения объектов.
Языки баз данных, такие как SQL.
Языки моделирования, такие как язык моделирования виртуальной реальности.
Языки сценариев.
Протоколы, такие как HTTP и удаленные вызовы функций через Интернет.
Реклама
Поделись этим термином
Связанные термины
- Компилятор
- Протокол передачи гипертекста
- Язык структурированных запросов
- Язык гипертекстовой разметки
- Расширяемый язык разметки
- Ява
- Сборщик
- Интерактивный язык данных
- SQL-сервер
Что такое синтаксический анализатор? Определение, типы и примеры
По
- Бен Луткевич,
Технический писатель
Что такое синтаксический анализатор?
В компьютерных технологиях синтаксический анализатор — это программа, которая обычно является частью компилятора. Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Парсеры разбивают входные данные на такие части, как существительные (объекты), глаголы (методы) и их атрибуты или параметры. Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Как работает синтаксический анализ?
Анализатор — это программа, входящая в состав компилятора, а анализ — часть процесса компиляции. Парсинг происходит на этапе анализа компиляции.
При синтаксическом анализе код берется из препроцессора, разбивается на более мелкие части и анализируется, чтобы другое программное обеспечение могло его понять. Синтаксический анализатор делает это, создавая структуру данных из входных данных.
Точнее говоря, человек пишет код на понятном человеку языке, таком как C++ или Java, и сохраняет его в виде набора текстовых файлов. Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Анализатор состоит из трех компонентов, каждый из которых обрабатывает разные этапы процесса анализа. Три этапа:
Учитывая набор символов x+z=11, лексический анализатор разделит его на серию токенов и классифицирует их, как показано.
Этап 1: Лексический анализ
Лексический анализатор — или сканер — берет код из препроцессора и разбивает его на более мелкие части. Он группирует входной код в последовательности символов, называемые лексемами, каждая из которых соответствует токену. Токены — это единицы грамматики языка программирования, понятные компилятору.
Лексические анализаторы также удаляют пробелы, комментарии и ошибки из ввода.
Этап 2: Синтаксический анализ
Синтаксический анализатор принимает (x+y)*3 в качестве входных данных и возвращает это дерево синтаксического анализа, которое позволяет синтаксическому анализатору понять уравнение.
На этом этапе синтаксического анализа проверяется синтаксическая структура ввода с использованием структуры данных, называемой деревом синтаксического анализа или деревом вывода. Анализатор синтаксиса использует маркеры для построения дерева синтаксического анализа, которое объединяет предопределенную грамматику языка программирования с маркерами входной строки. Синтаксический анализатор сообщает о синтаксической ошибке, если синтаксис неверен.
Этап 3: Семантический анализ
Семантический анализ сверяет дерево синтаксического анализа с таблицей символов и определяет, является ли оно семантически непротиворечивым. Этот процесс также известен как контекстно-зависимый анализ. Он включает проверку типов данных, проверку меток и проверку управления потоком.
Если предоставлен код:
с плавающей запятой а = 30,2; число с плавающей запятой b = a*20
, то анализатор будет рассматривать 20 как 20.0 перед выполнением операции.
В некоторых источниках этап синтаксического анализа упоминается как синтаксический анализ, поскольку он генерирует дерево синтаксического анализа.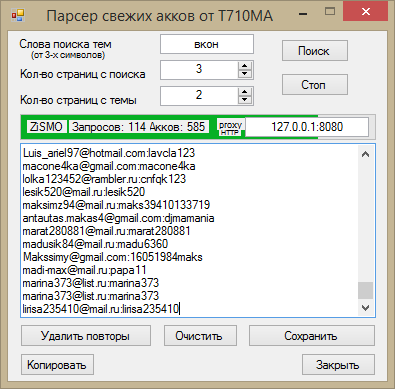 Они не учитывают лексический и семантический анализ.
Они не учитывают лексический и семантический анализ.
Синтаксический анализ происходит на первых трех этапах процесса компиляции — лексическом, синтаксисе и семантическом анализе.
Какие существуют основные типы парсеров?
При создании языка программного обеспечения его создатели должны указать набор правил. Эти правила обеспечивают грамматику, необходимую для построения правильных операторов языка.
Ниже приведен набор грамматических правил для простого вымышленного языка, который содержит всего несколько слов:
<предложение> ::= <субъект> <глагол> <объект>
<тема> ::= <статья> <существительное>
<статья> ::= the | a
<существительное> ::= собака | кошка | человек
<глагол> ::= домашние животные | fed
<объект> ::= <статья> <существительное>
В этом языке предложение должно содержать подлежащее, глагол и существительное в указанном порядке, а отдельные слова должны соответствовать частям речи. Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только pets или накормленный .
Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только pets или накормленный .
Синтаксический анализ проверяет оператор, предоставленный пользователем в качестве входных данных, на соответствие этим правилам, чтобы доказать, что оператор действителен. Разные алгоритмы парсинга проверяют в разном порядке. Существует два основных типа парсеров:
- Нисходящие парсеры. Они начинаются с правила вверху, например <предложение> ::= <субъект> <глагол> <объект>. Имея входную строку «Человек накормил кошку», синтаксический анализатор просматривает первое правило и просматривает все правила, проверяя их правильность. В этом случае первое слово — это
, оно следует правилу подлежащего, и синтаксический анализатор продолжит чтение предложения в поисках . - Парсеры «снизу вверх». Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
 Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать Проще говоря, нисходящие синтаксические анализаторы начинают свою работу с начального символа грамматики в верхней части дерева синтаксического анализа. Затем они продвигаются вниз от правила к предложению. Синтаксические анализаторы снизу вверх работают от предложения к правилу.
Помимо этих типов, важно знать два типа деривации. Вывод — это порядок, в котором грамматика согласовывает входную строку. Их:
- Парсеры LL . Они анализируют входные данные слева направо, используя крайнее левое производное, чтобы сопоставить правила грамматики с входными данными. Этот процесс выводит строку, которая проверяет ввод, расширяя крайний левый элемент дерева синтаксического анализа.
- Парсеры LR . Эти входные данные анализируются слева направо, используя крайний правый вывод. Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
 Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.Кроме того, существуют другие типы парсеров, в том числе следующие:
- Парсеры рекурсивного спуска. Парсеры рекурсивного спуска возвращаются после каждого решения, чтобы перепроверить точность. Парсеры рекурсивного спуска используют синтаксический анализ сверху вниз.
- Парсеры Эрли. Они анализируют все контекстно-свободные грамматики, в отличие от парсеров LL и LR. Большинство реальных языков программирования не используют контекстно-свободные грамматики.
- Парсеры Shift-reduce. Смещают и сокращают входную строку. На каждом этапе строки они сокращают слово до правила грамматики. Этот подход уменьшает строку до тех пор, пока она не будет полностью проверена.
Какие технологии используют синтаксический анализ?
Парсеры используются, когда необходимо абстрактно представить входные данные из исходного кода в виде структуры данных, чтобы их можно было проверить на правильность синтаксиса. Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
К технологиям, использующим синтаксический анализ для проверки входных данных кода, относятся следующие:
Языки программирования. Парсеры используются во всех языках программирования высокого уровня, включая следующие:
- С++
- Расширяемый язык разметки или XML
- Язык гипертекстовой разметки или HTML
- Препроцессор гипертекста или PHP
- Ява
- JavaScript
- Обозначение объекта JavaScript или JSON
- Перл
- Питон
Языки баз данных. Языки баз данных, такие как язык структурированных запросов, также используют синтаксические анализаторы.
Протоколы . Протоколы, такие как протокол передачи гипертекста и удаленные вызовы функций через Интернет, используют синтаксические анализаторы.
Генератор парсеров . Генераторы синтаксического анализа принимают грамматику в качестве входных данных и генерируют исходный код, который выполняет синтаксический анализ в обратном порядке. Они создают синтаксические анализаторы из регулярных выражений, которые представляют собой специальные строки, используемые для управления и сопоставления шаблонов в тексте.
Парсинг — это фундаментальная концепция разработки программного обеспечения и теории вычислений. Однако большинство ИТ-специалистов могут обойтись без глубокого понимания синтаксического анализа, используя платформы с низким кодом, которые позволяют пользователям создавать программы без написания тысяч строк кода. Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Последнее обновление: июль 2022 г.
Продолжить чтение О парсере
- Памятка Terraform: известные команды, HCL и многое другое
- Как стать хорошим Java-программистом без образования
- Интерпретируемые и компилируемые языки: в чем разница?
- Исправление 10 самых распространенных ошибок времени компиляции в Java
- 7 советов по выбору правильной библиотеки Java
Углубитесь в разработку и проектирование приложений
Надежная архитектура бизнес-процессов требует ключевых характеристик
командлет
Автор: Стивен Бигелоу
Тренировка против тренировки
Субъект – согласование глагола и фраза в скобках
ПоискSoftwareQuality
-
Инструменты Atlassian Open DevOps объединяют больше рабочих процессовAtlassian утверждает, что по мере роста числа поставщиков комплексных инструментов DevOps пользователям нужен выбор; клиенты говорят, что интеграция сторонних инструментов — это .
.. -
Инструмент управления API с низким кодом борется со сложностью с оговоркамиНовый инструмент управления API с низким кодом может принести такие преимущества, как повышенная скорость, меньшее количество ошибок кодирования и более широкий доступ. Но…
-
Обновления безопасности GitHub и расширение Copilot наделали много шумаНовые функции, представленные на GitHub Universe, включают частные каналы для решения проблем безопасности и Copilot для бизнеса, которые могут упасть …
 ..
..SearchCloudComputing
-
Эксперты по облачным технологиям и их прогнозы AWS re:Invent 2022Поскольку AWS готовится к своему крупнейшему событию года, наши участники прогнозируют, что поставщик облачных услуг представит на re:Invent 2022.
-
Сравните Amazon Lightsail и EC2 для нужд вашего веб-приложенияНе всем разработчикам нужны или нужны все возможности Amazon EC2.