Содержание
что это и как работает. Преимущества
#SEO
#Контекстная реклама
Слово «парсер» (с английского «parse» — «разбор») означает программное обеспечение для парсинга — процесса, выполняющего синтаксический анализ данных. При парсинге содержимое веб-страницы «разбирается» на определенные составляющие. Подобный процесс можно выполнять вручную или при помощи специального программного обеспечения — парсеров.
В качестве объекта парсинга могут рассматриваться самые разнообразные сайты и их контент:
- интернет-магазины;
- блоги;
- социальные сети;
- форумы;
- справочники и т. д.
Хороший пример программы-парсера — любой робот (краулер) поисковой системы. Каждый такой ресурс обрабатывает данные с разных веб-сайтов и сохраняет их в своей базе. А после ввода в строку поиска определенного запроса, система выдает пользователю соответствующий результат (результат парсинга).
А после ввода в строку поиска определенного запроса, система выдает пользователю соответствующий результат (результат парсинга).
Применение парсинга в маркетинге и SEO
Парсинг сайтов используется для того, чтобы автоматизировать процессы анализа, сбора и хранения определенных данных. С помощью этого процесса можно автоматизировать даже создание и обновление сайтов.
Цели парсинга могут быть самыми разнообразными:
- сбор контактов определенной группы пользователей;
- копирование конкретных статей из Википедии;
- сбор определенных публикаций на сайте с объявлениями и т. д.
Если говорить о SEO-оптимизации сайтов и маркетинге, то в этих отраслях парсинг чаще всего используется для сбора текстового контента с целью его рерайта («уникализации») или для поиска электронных адресов руководителей предприятий, например, для предложения им своих услуг, для подбора ключевых запросов или сбора ключей конкурентов.
Выгоды от применения парсинга
Используя программное обеспечение для парсинга, можно значительно увеличить скорость работы с ключевыми запросами. Правильно настроив такое ПО, можно быстро собрать ключевые слова конкурентов или запросы для продвижения веб-ресурса.
Правильно настроив такое ПО, можно быстро собрать ключевые слова конкурентов или запросы для продвижения веб-ресурса.
А после того, как парсер закончит сбор ключевых слов, с помощью другого ПО можно выполнить их кластеризацию (распределение по группам) и выбор тех запросов, которые подходят для продвижения конкретного сайта.
Также парсер помогает выполнить технический анализ веб-ресурса и выявить:
- битые ссылки;
- технические ошибки;
- некорректный html-код;
- неисправные редиректы;
- уровни вложенности страниц;
- правильность настройки файла robots.txt и т. д.
Многие онлайн-магазины применяют парсинг на начальном этапе наполнения своего ассортимента. Работает такая схема по принципу:
- Загрузка в парсер каталога товаров поставщика.
- Выгрузка товаров парсером с определенной площадки (например, из Яндекс.Маркета).
- Выполнение анализа и сравнение товаров из каталога поставщика и Яндекс.Маркета.

- Добавление идентифицированных товаров в базу данных парсера.
- На последнем этапе эти товары загружаются на новый интернет-магазин.
Парсеры могут быть написаны на любом языке программирования (Delphi, PHP, C++ и т. д.), который поддерживает регулярные выражения — наборы мета-символов, которые могут применяться в процессе поиска данных. Сохранение результатов парсинга обычно происходит в файлы формата *.txt, *.sql, *.xml.
Как пользоваться программами для парсинга контента и товаров, что такое парсер сайта
Чтобы поддерживать информацию на своем ресурсе в актуальном состоянии, наполнять каталог товарами и структурировать контент, необходимо тратить кучу времени и сил. Но есть утилиты, которые позволяют заметно сократить затраты и автоматизировать все процедуры, связанные с поиском материалов и экспортом их в нужном формате. Эта процедура называется парсингом.
Давайте разберемся, что такое парсер и как он работает.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Кажется, этого определения достаточно.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен. Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
- Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.
 Не придется копировать данные о каждой товарной единице вручную.
Не придется копировать данные о каждой товарной единице вручную.
Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.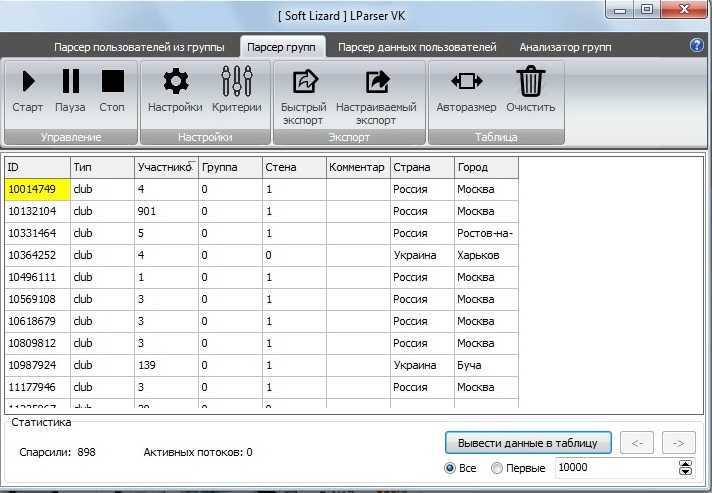
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Где найти парсер?
Добыть утилиту для поиска и преобразования информации с сайтов можно четырьмя путями.
- Использование сил своей команды разработчиков. Когда в штате есть программисты, способные создать парсер, адаптированный под задачи компании, то искать другие варианты не стоит. Этот будет оптимальным вариантом.
- Нанять команду разработчиков со стороны, чтобы те создали утилиту по вашим требованиям. В таком случае уйдет много ресурсов на создание ТЗ и оплату работы.
- Установить готовое приложение-парсер на компьютер. Да, оно тоже будет стоить денег, но зато им можно воспользоваться сразу. А настройки параметров в таких программах позволяют точно настроить схему парсинга.
- Воспользоваться веб-сервисом или браузерным плагином с аналогичной функциональностью. Встречаются бесплатные версии.
 Да, оно тоже будет стоить денег, но зато им можно воспользоваться сразу. А настройки параметров в таких программах позволяют точно настроить схему парсинга.
Да, оно тоже будет стоить денег, но зато им можно воспользоваться сразу. А настройки параметров в таких программах позволяют точно настроить схему парсинга.
При отсутствии разработчиков в штате я бы советовал именно десктопную программу. Это идеальный баланс между эффективностью и затратами. Но если задачи стоят не слишком сложные, то может хватить и облачного сервиса.
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
- Программа работает самостоятельно. Не приходится тратить время на поиск и сортировку данных. К тому же собирает она информацию куда быстрее человека. Да еще и делает это 24 на 7, если понадобится.
- Парсеру можно «скормить» столько параметров, сколько потребуется, и идеально отстроить его для поиска только необходимого контента. Без мусора, ошибок и нерелеватной информации с неподходящих страниц.
- В отличие от человека, парсер не будет допускать глупых ошибок по невнимательности. И не устанет.
- Утилита для парсинга может подавать найденные данные в удобном формате по запросу пользователя.
- Парсеры умеют грамотно распределять нагрузку на сайт. Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
- либо заблокировать запросы со стороны, указав соотвествующие параметры в robots. txt;
- либо настроить капчу – обучить парсер разгадыванию картинок слишком затратно, никто не будет этим заниматься.
 txt;
txt;
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах.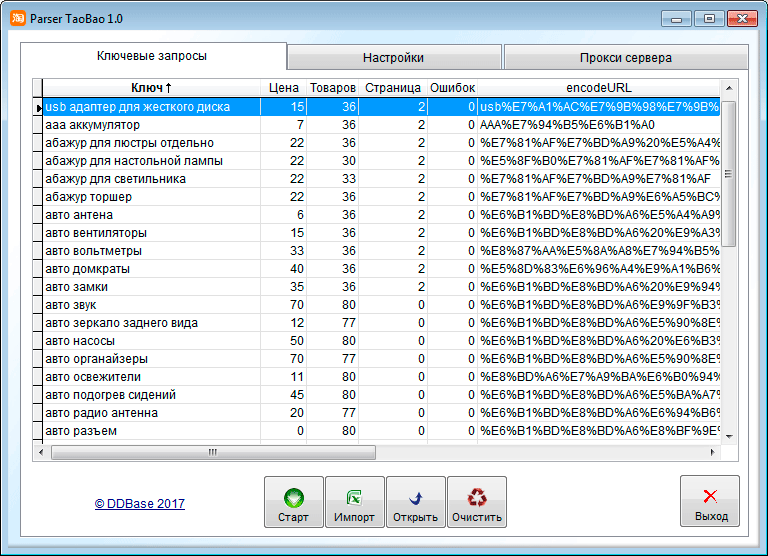 Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Парсинг интернет-магазина
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.

В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Во втором случае нужно разыскать код товара и указать его в программе-парсере. Упростить задачу помогают специальные приложения. Например, Catalogloader – парсер, специально созданный для автоматического сбора данных о товарах в интернет-магазинах.
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
- Import.io – востребованный набор инструментов для поиска информации на ресурсах. Позволяет парсить неограниченное количество страниц, поддерживает все популярные форматы вывода данных и автоматически создает удобную структуру для восприятия добытой информации.
- Mozenda – сайт для сбора информации с сайтов, которому доверяют крупные компании в духе Tesla. Собирает любые типы данных и конвертирует в необходимый формат (будь то JSON или XML). Первые 30 дней можно пользоваться бесплатно.
- Octoparse – парсер, главным преимуществом которого считается простота. Чтобы его освоить, не придется изучать программирование и хоть какое-то время тратить на работу с кодом. Можно получить необходимую информацию в пару кликов.
- ParseHub – один из немногих полностью бесплатных и довольно продвинутых парсеров.

Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
- ParserOK – приложение, сфокусированное на различных типах парсинга данных. Есть настройки для сбора данных о стоимости товаров, настройки для автоматической компиляции каталогов с товарами, номеров, адресов электронной почты и т. п.
- Datacol – универсальный парсер, который, по словам разработчиков, может заменить решения конкурентов в 99% случаев. А еще он прост в освоении.
- Screaming Frog – мощный инструмент для SEO-cпециалистов, позволяющий собрать кучу полезных данных и провести аудит ресурса (найти сломанные ссылки, структуру данных и т.п.). Можно анализировать до 500 ссылок бесплатно.
- Netspeak Spider – еще один популярный продукт, осуществляющий автоматический парсинг сайтов и помогающий проводить SEO-аудит.
 п.
п.
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
- Parsers – плагин для извлечения HTML-данных с веб-страниц и импорта их в формат XML или JSON. Расширение запускается на одной странице, автоматически разыскивает похожие страницы и собирает с них аналогичные данные.
- Scraper – собирает информацию в автоматическом режиме, но ограничивает количество собираемых данных.
- Data Scraper – дополнение, в автоматическом режиме собирающее данные со страницы и экспортирующее их в Excel-таблицу. До 500 веб-страниц можно отсканировать бесплатно. За большее количество придется ежемесячно платить.
- kimono – расширение, превращающее любую страницу в структурированное API для извлечения необходимых данных.
 За большее количество придется ежемесячно платить.
За большее количество придется ежемесячно платить.
Вместо заключения
На этом и закончим статью про парсинг и способы его реализации. Этого должно быть достаточно, чтобы начать работу с парсерами и собрать информацию, необходимую для развития вашего проекта.
c++ — Что должен делать парсер для языка программирования?
спросил
Изменено
11 лет, 7 месяцев назад
Просмотрено
198 раз
Я уже написал лексер, возвращающий токены, и сейчас работаю над парсером. У меня есть одна проблема.
Представьте себе этот пример кода:
print("Привет, мир!")
Лексер возвращает четыре токена ( print , ( , "Hello, world!" и ) ).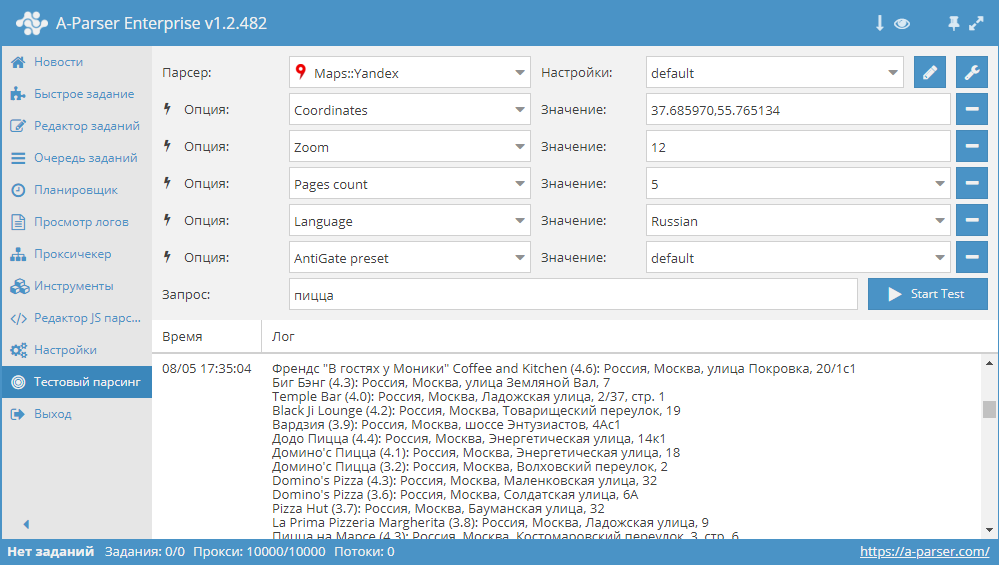 Конечная программа должна напечатать строку «Hello, world!».
Конечная программа должна напечатать строку «Hello, world!».
Но что должен делать синтаксический анализатор? Должен ли синтаксический анализатор уже выполнить код, должен ли он вернуть что-то (и что), что обрабатывается другим объектом?
- c++
- синтаксический анализ
- языки программирования
Анализатор должен сгенерировать абстрактное синтаксическое дерево, которое является представлением программы в памяти. Это дерево можно пройти после синтаксического анализа, чтобы выполнить генерацию кода. Я бы порекомендовал прочитать какую-нибудь хорошую книгу на эту тему, может быть, о драконах.
0
Что должен делать синтаксический анализатор?
Типичная роль синтаксического анализатора заключается в чтении потока токенов и построении из него дерева синтаксического анализа или абстрактного синтаксического дерева.
Если синтаксический анализатор уже выполнил код
Нет. Это не синтаксический анализ.
Это не синтаксический анализ.
Обычно анализатор ничего не выполняет. Парсеры обычно берут входные данные (текстовые или бинарные) и производят представление в памяти, не более того… но это уже много!
Если у вас уже есть лексер, то вторым шагом обычно является выполнение семантического анализа для создания абстрактного синтаксического дерева.
Это означает создание чего-либо вида:
(FunctionCall "печать" [
(StringLiteral «Привет, мир!»)
]
)
Должно возвращаться абстрактное синтаксическое дерево.
Синтаксический анализатор должен в основном делать две вещи:
- Создавать форму промежуточного текста, как правило, в виде дерева или обратного польского языка, который может использовать генератор кода.
- Четко и точно сообщать обо всех обнаруженных ошибках, указывая номер ошибочной строки, точную причину ошибки (в разумном нетехническом языке) и, насколько это возможно, положение в строке или идентификатор элемента, вызвавшего ошибку. парсер «захлебнуться».
 парсер «захлебнуться».
парсер «захлебнуться».Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Разбор
— А как насчет этих грамматик и минимального парсера для их распознавания?
Я пытаюсь научиться делать компилятор. Для этого я много читал о контекстно-свободном языке. Но есть некоторые вещи, которые я пока не могу получить сам.
Для этого я много читал о контекстно-свободном языке. Но есть некоторые вещи, которые я пока не могу получить сам.
Так как это мой первый компилятор, есть некоторые приемы, о которых я не знаю. Мои вопросы задаются с целью создания генератора парсеров, а не компилятора или лексера. Некоторые вопросы могут быть очевидными.
Среди моих прочтений: Анализ снизу вверх, Анализ сверху вниз, Формальные грамматики. Показанная картинка взята из: Разного разбора. Все происходит из класса Stanford CS143.
Вот точки:
0) Как (неоднозначно/однозначно) и (лево-рекурсивно/право-рекурсивно) влияют на потребность в том или ином алгоритме? Существуют ли другие способы квалифицировать грамматику?
1) Неоднозначная грамматика — это грамматика, имеющая несколько деревьев синтаксического анализа. Но разве выбор самого левого или самого правого вывода не должен приводить к уникальности дерева синтаксического анализа?
[EDIT: Ответил здесь]
2.1) Но все же, связана ли неоднозначность грамматики с k? Я имею в виду предоставление грамматики LR (2), является ли она неоднозначной для парсера LR (1) и не двусмысленной для парсера LR (2)?
[РЕДАКТИРОВАТЬ: Нет, грамматика LR(2) означает, что синтаксическому анализатору потребуются два токена просмотра вперед, чтобы выбрать правильное правило для использования. С другой стороны, неоднозначная грамматика — это грамматика, которая может привести к нескольким деревьям синтаксического анализа. ]
С другой стороны, неоднозначная грамматика — это грамматика, которая может привести к нескольким деревьям синтаксического анализа. ]
2.2) Таким образом, синтаксический анализатор LR(*), насколько вы можете себе это представить, вообще не будет иметь двусмысленной грамматики и сможет затем анализировать весь набор контекстно-свободных языков?
[EDIT: Отвечает Айра Бакстер, LR(*) менее мощен, чем GLR, поскольку он не может обрабатывать несколько деревьев синтаксического анализа. ]
3) В зависимости от предыдущих ответов последующие могут быть противоречивыми. Учитывая синтаксический анализ LR, вызывают ли неоднозначные грамматики конфликт сдвиг-уменьшение? Может ли однозначная грамматика вызвать его тоже? Точно так же как насчет конфликтов уменьшения-уменьшения?
[РЕДАКТИРОВАТЬ: вот и все, неоднозначные грамматики приводят к конфликтам сдвига-уменьшения и сокращения-уменьшения. Противоположно, если нет конфликтов, грамматика однозначна. ]
4) Возможность разбора леворекурсивной грамматики является преимуществом парсера LR(k) перед LL(k), единственное ли различие между ними?
[РЕДАКТИРОВАТЬ: да.