Содержание
Python — базы данных NoSQL
Поскольку все больше и больше данных становятся доступными как неструктурированные или полуструктурированные, потребность в управлении ими через базу данных NoSql возрастает. Python также может взаимодействовать с базами данных NoSQL аналогично взаимодействию с реляционными базами данных. В этой главе мы будем использовать python для взаимодействия с MongoDB в качестве базы данных NoSQL. Если вы новичок в MongoDB, вы можете узнать об этом в нашем уроке здесь.
Чтобы подключиться к MongoDB, python использует библиотеку, известную как pymongo . Вы можете добавить эту библиотеку в свою среду Python, используя приведенную ниже команду из среды Anaconda.
conda install pymongo
Эта библиотека позволяет Python подключаться к MOngoDB с помощью клиента db. После подключения мы выбираем имя БД, которое будет использоваться для различных операций.
Вставка данных
Для вставки данных в MongoDB мы используем метод insert (), который доступен в среде базы данных. Сначала мы подключаемся к базе данных, используя код Python, показанный ниже, а затем предоставляем детали документа в виде серии пар ключ-значение.
Сначала мы подключаемся к базе данных, используя код Python, показанный ниже, а затем предоставляем детали документа в виде серии пар ключ-значение.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to the test db
db=client.test
# Use the employee collection
employee = db.employee
employee_details = {
'Name': 'Raj Kumar',
'Address': 'Sears Streer, NZ',
'Age': '42'
}
# Use the insert method
result = employee.insert_one(employee_details)
# Query for the inserted document.
Queryresult = employee.find_one({'Age': '42'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
{u'Address': u'Sears Streer, NZ',
u'Age': u'42',
u'Name': u'Raj Kumar',
u'_id': ObjectId('5adc5a9f84e7cd3940399f93')}Обновление данных
Обновление существующих данных MongoDB похоже на вставку. Мы используем метод update (), который является родным для mongoDB. В приведенном ниже коде мы заменяем существующую запись новыми парами ключ-значение. Обратите внимание, как мы используем критерии условия, чтобы решить, какую запись обновить.
В приведенном ниже коде мы заменяем существующую запись новыми парами ключ-значение. Обратите внимание, как мы используем критерии условия, чтобы решить, какую запись обновить.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to db
db=client.test
employee = db.employee
# Use the condition to choose the record
# and use the update method
db.employee.update_one(
{"Age":'42'},
{
"$set": {
"Name":"Srinidhi",
"Age":'35',
"Address":"New Omsk, WC"
}
}
)
Queryresult = employee.find_one({'Age':'35'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
{u'Address': u'New Omsk, WC',
u'Age': u'35',
u'Name': u'Srinidhi',
u'_id': ObjectId('5adc5a9f84e7cd3940399f93')}Удаление данных
Удаление записи также просто, когда мы используем метод удаления. Здесь также упоминается условие, которое используется для выбора записи, которая будет удалена.
Здесь также упоминается условие, которое используется для выбора записи, которая будет удалена.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to db
db=client.test
employee = db.employee
# Use the condition to choose the record
# and use the delete method
db.employee.delete_one({"Age":'35'})
Queryresult = employee.find_one({'Age':'35'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
None
Итак, мы видим, что конкретная запись больше не существует в БД.
Краткое руководство. Клиентская библиотека Azure Cosmos DB для NoSQL для Python
-
Статья -
- Чтение занимает 10 мин
-
ОБЛАСТЬ ПРИМЕНЕНИЯ: NoSQL
Начните работу с клиентской библиотекой Azure Cosmos DB для Python, чтобы создавать базы данных, контейнеры и элементы в вашей учетной записи.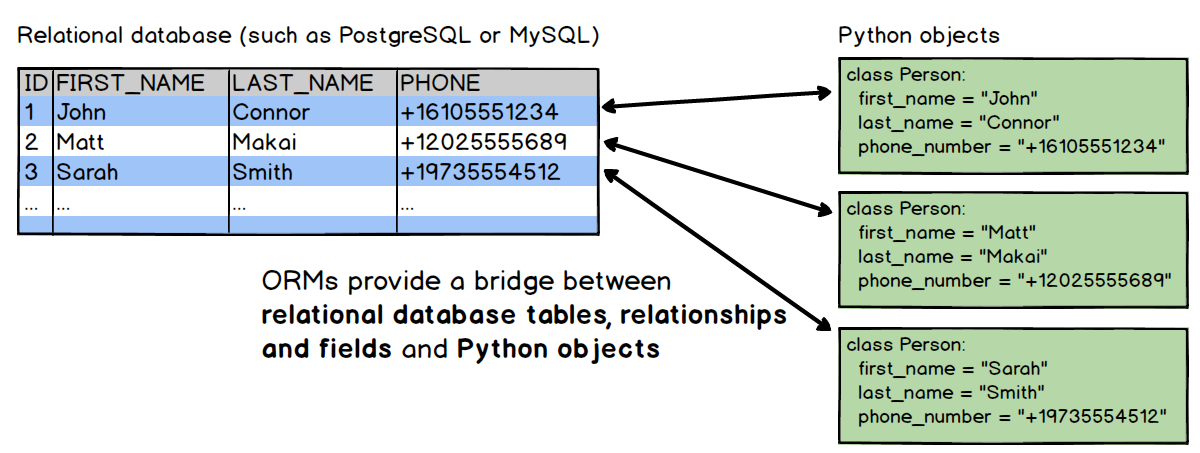 Выполните приведенные здесь действия, чтобы установить пакет и протестировать пример кода для выполнения базовых задач.
Выполните приведенные здесь действия, чтобы установить пакет и протестировать пример кода для выполнения базовых задач.
Примечание
Примеры фрагментов кода доступны на GitHub в виде проекта .NET.
Справочная документация по | API Исходный код | библиотеки Пакет (PyPI) | Образцы
Предварительные требования
- Учетная запись Azure с активной подпиской.
- Нет подписки Azure? Вы можете попробовать Azure Cosmos DB бесплатно без кредитной карты.
- Python версии 3.7 или выше
- Убедитесь, что исполняемый
pythonфайл находится в .PATH
- Убедитесь, что исполняемый
- Интерфейс командной строки (CLI) Azure или Azure PowerShell
Проверка предварительных условий
- В окне терминала или командной строки выполните
python --versionкоманду , чтобы убедиться, что пакет SDK для .NET версии 3.7 или более поздней. - Запустите
az --version(Azure CLI) илиGet-Module -ListAvailable AzureRM(Azure PowerShell), чтобы убедиться, что соответствующие средства командной строки Azure установлены.

Настройка
В этом разделе описывается создание учетной записи Azure Cosmos DB и настройка проекта, использующего клиентская библиотека Azure Cosmos DB для NoSQL для .NET для управления ресурсами.
Создание учетной записи Azure Cosmos DB
Совет
Нет подписки Azure? Вы можете попробовать Azure Cosmos DB бесплатно без кредитной карты. Если вы создаете учетную запись с помощью бесплатной пробной версии, вы можете спокойно перейти к разделу Создание приложения Python .
В этом кратком руководстве будет создана одна учетная запись Azure Cosmos DB с помощью API для NoSQL.
- Портал
- Azure CLI
- PowerShell
Совет
В этом кратком руководстве рекомендуется использовать для группы ресурсов имя msdocs-cosmos-quickstart-rg.
Войдите на портал Azure.
На домашней странице или в меню портала Azure выберите Создать ресурс.
На странице Создание найдите и выберите Azure Cosmos DB.
На странице Выбор параметра API выберите параметр Создать в разделе NoSQL . Azure Cosmos DB имеет шесть API: NoSQL, MongoDB, PostgreSQL, Apache Cassandra, Apache Gremlin и Table. Дополнительные сведения об API для NoSQL.
На странице Создание учетной записи Azure Cosmos DB введите следующие сведения:
Параметр Значение Описание Подписка имя подписки; Выберите подписку Azure, которую нужно использовать для этой учетной записи Azure Cosmos. Группа ресурсов Имя группы ресурсов Выберите группу ресурсов или Создать, затем введите уникальное имя для новой группы ресурсов. Имя учетной записи Уникальное имя Введите имя для идентификации учетной записи Azure Cosmos. Имя будет использоваться как часть полного доменного имени (FQDN) с суффиксом documents.azure.com и поэтому должно быть глобально уникальным. Имя может содержать только строчные буквы, цифры и знак дефиса (-). Имя должно содержать от 3 до 44 символов.Расположение Ближайший к пользователям регион Выберите географическое расположение для размещения учетной записи Azure Cosmos DB. Используйте ближайшее к пользователям расположение, чтобы предоставить им максимально быстрый доступ к данным. Режим емкости «Подготовленная пропускная способность» или «Бессерверный» Выберите Подготовленная пропускная способность, чтобы создать учетную запись в режиме подготовленной пропускной способности. Выберите Бессерверный, чтобы создать учетную запись в режиме Бессерверный. Применение скидки на основе категории «Бесплатный» для Azure Cosmos DB Применить или не применять Включите уровень «Бесплатный» в Azure Cosmos DB. В категории «Бесплатный» Azure Cosmos DB для учетной записи бесплатно предоставляются первые 1000 единиц запросов в секунду и 25 ГБ свободного места. Ознакомьтесь с дополнительными сведениями о категории «Бесплатный».Примечание
Вы можете использовать не более одной учетной записи Azure Cosmos DB категории «Бесплатный» на подписку Azure. При создании учетной записи нужно зарегистрироваться. Если параметр подачи заявки на скидку на основе категории «Бесплатный» не отображается, это означает, что в подписке уже включена другая учетная запись категории «Бесплатный».
Выберите Review + create (Просмотреть и создать).
Просмотрите предоставленные параметры и щелкните Создать. Создание учетной записи занимает несколько минут. Прежде чем продолжить, дождитесь, пока на странице портала появится сообщение Развертывание выполнено.
Выберите Перейти к ресурсу, чтобы перейти на страницу учетной записи Azure Cosmos DB.
На странице учетной записи API для NoSQL выберите пункт меню навигации Ключи .
Запишите значения полей URI и PRIMARY KEY. Эти значения вам понадобятся позже.
 Имя будет использоваться как часть полного доменного имени (FQDN) с суффиксом documents.azure.com и поэтому должно быть глобально уникальным. Имя может содержать только строчные буквы, цифры и знак дефиса (-). Имя должно содержать от 3 до 44 символов.
Имя будет использоваться как часть полного доменного имени (FQDN) с суффиксом documents.azure.com и поэтому должно быть глобально уникальным. Имя может содержать только строчные буквы, цифры и знак дефиса (-). Имя должно содержать от 3 до 44 символов. В категории «Бесплатный» Azure Cosmos DB для учетной записи бесплатно предоставляются первые 1000 единиц запросов в секунду и 25 ГБ свободного места. Ознакомьтесь с дополнительными сведениями о категории «Бесплатный».
В категории «Бесплатный» Azure Cosmos DB для учетной записи бесплатно предоставляются первые 1000 единиц запросов в секунду и 25 ГБ свободного места. Ознакомьтесь с дополнительными сведениями о категории «Бесплатный».
Создание приложения Python
Создайте файл кода Python (app.py) в пустой папке с помощью предпочтительной интегрированной среды разработки (IDE).
Установка пакета
azure-cosmos Добавьте пакет PyPI в приложение Python. Используйте команду , pip install чтобы установить пакет.
pip install azure-cosmos
Настройка переменных среды
Чтобы использовать значения URI и PRIMARY KEY в коде, сохраните их в новых переменных среды на локальном компьютере, на котором выполняется приложение. Чтобы задать переменную среды, используйте предпочтительный терминал для выполнения следующих команд:
- Windows
- Linux / macOS
$env:COSMOS_ENDPOINT = "<cosmos-account-URI>" $env:COSMOS_KEY = "<cosmos-account-PRIMARY-KEY>"
Объектная модель
Прежде чем приступить к созданию приложения, рассмотрим иерархию ресурсов в Azure Cosmos DB. У Azure Cosmos DB есть объектная модель, используемая для создания ресурсов и доступа к ним. Azure Cosmos DB создает ресурсы с использованием иерархии, состоящей из учетных записей, баз данных, контейнеров и элементов.
У Azure Cosmos DB есть объектная модель, используемая для создания ресурсов и доступа к ним. Azure Cosmos DB создает ресурсы с использованием иерархии, состоящей из учетных записей, баз данных, контейнеров и элементов.
Иерархическая схема с учетной записью Azure Cosmos DB в верхней части. У учетной записи есть два дочерних узла базы данных. Один из узлов базы данных содержит два дочерних узла контейнера. Другой узел базы данных содержит один дочерний узел контейнера. У этого одного узла контейнера есть три дочерних узла.
Дополнительные сведения об иерархии различных ресурсов см. в статье Работа с базами данных, контейнерами и элементами в Azure Cosmos DB.
Для взаимодействия с этими ресурсами вы будете использовать следующие классы Python:
CosmosClient. Этот класс является логическим представлением службы баз данных Azure Cosmos DB на стороне клиента. Этот клиентский объект позволяет настраивать и выполнять запросы к службе.DatabaseProxy— этот класс является ссылкой на базу данных, которая может еще не существовать в службе. База данных проверяется на стороне сервера при попытке доступа к ней или выполнении операции с ней.ContainerProxy— этот класс представляет собой ссылку на контейнер, который тоже может еще не существовать в службе. Контейнер проверяется на стороне сервера при попытке работы с ним.
 База данных проверяется на стороне сервера при попытке доступа к ней или выполнении операции с ней.
База данных проверяется на стороне сервера при попытке доступа к ней или выполнении операции с ней.Примеры кода
- аутентификация клиента;
- Создание базы данных
- Создание контейнера
- Создание элемента
- Получение элемента
- Элементы запроса
В этой статье описан пример кода, где создается база данных adventureworks с контейнером products. Таблица products предназначена для хранения сведений о продукте, таких как имя, категория, количество и индикатор продаж. Каждый продукт также содержит уникальный идентификатор.
В этом примере кода контейнер будет использовать категорию в качестве ключа логического раздела.
Аутентификация клиента
В каталоге проекта откройте файл app.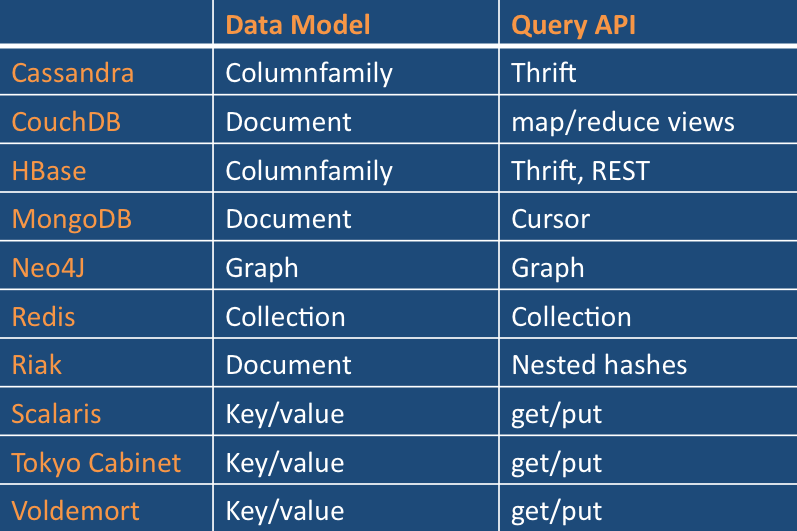 py . В редакторе импортируйте
py . В редакторе импортируйте os модули и json . Затем импортируйте классы CosmosClient и PartitionKey из azure.cosmos модуля.
import os import json from azure.cosmos import CosmosClient, PartitionKey
Создайте переменные для COSMOS_ENDPOINT переменных среды и COSMOS_KEY с помощью os.environ.
endpoint = os.environ["COSMOS_ENDPOINT"] key = os.environ["COSMOS_KEY"]
Создайте новый экземпляр клиента с помощью конструктора CosmosClient класса и двух переменных, созданных в качестве параметров.
client = CosmosClient(url=endpoint, credential=key)
Создание базы данных
Используйте метод CosmosClient.create_database_if_not_exists, чтобы создать новую базу данных, если она еще не существует. Этот метод возвращает ссылку DatabaseProxy на существующую или вновь созданную базу данных.
database = client.
 create_database_if_not_exists(id="cosmicworks")
create_database_if_not_exists(id="cosmicworks")
Создание контейнера
Класс PartitionKey определяет путь к ключу секции, который можно использовать при создании контейнера.
partitionKeyPath = PartitionKey(path="/categoryId")
Метод Databaseproxy.create_container_if_not_exists создаст новый контейнер, если он еще не существует. Этот метод также возвращает ссылку ContainerProxy на контейнер.
container = database.create_container_if_not_exists( , partition_key=partitionKeyPath, offer_throughput=400 )
Создание элемента
Создайте новый элемент в контейнере, сначала создав новую переменную (newItem) с определенным примером элемента. В этом примере уникальный идентификатор этого элемента — 70b63682-b93a-4c77-aad2-65501347265f. Значение ключа секции является производным /categoryId от пути, поэтому оно будет иметь значение 61dba35b-4f02-45c5-b648-c6badc0cbd79.
newItem = {
"id": "70b63682-b93a-4c77-aad2-65501347265f",
"categoryId": "61dba35b-4f02-45c5-b648-c6badc0cbd79",
"categoryName": "gear-surf-surfboards",
"name": "Yamba Surfboard",
"quantity": 12,
"sale": False,
}
Совет
Остальные поля являются гибкими, и вы можете определить любое количество или меньшее количество. Можно даже объединить разные схемы элементов в одном контейнере.
Создайте элемент в контейнере с помощью метода , ContainerProxy.create_item передавая уже созданную переменную.
container.create_item(newItem)
Получение элемента
В Azure Cosmos DB можно выполнить операцию точечного чтения, используя поля уникального идентификатора (id) и ключа раздела. В пакете SDK вызовите ContainerProxy.read_item передачу обоих значений, чтобы вернуть элемент в виде словаря строк и значений (dict[str, Any]).
existingItem = container.read_item(
item="70b63682-b93a-4c77-aad2-65501347265f",
partition_key="61dba35b-4f02-45c5-b648-c6badc0cbd79",
)
В этом примере результат словаря сохраняется в переменной с именем existingItem.
Элементы запроса
После вставки элемента можно выполнить запрос, чтобы получить все элементы, соответствующие определенному фильтру. В этом примере выполняется запрос SQL: SELECT * FROM products p WHERE p.categoryId = "61dba35b-4f02-45c5-b648-c6badc0cbd79". В этом примере используется параметризация запроса для создания запроса. Запрос использует строку SQL-запроса и словарь параметров запроса.
QUERY = "SELECT * FROM products p WHERE p.categoryId = @categoryId" CATEGORYID = "61dba35b-4f02-45c5-b648-c6badc0cbd79" params = [dict(name="@categoryId", value=CATEGORYID)]
Этот пример словаря включал @categoryId параметр запроса и соответствующее значение 61dba35b-4f02-45c5-b648-c6badc0cbd79.
После определения запроса вызовите ContainerProxy.query_items , чтобы выполнить запрос и вернуть результаты в виде страничного набора элементов (ItemPage[Dict[str, Any]]).
items = container.query_items(
query=QUERY, parameters=params, enable_cross_partition_query=False
)
Наконец, используйте цикл for для итерации результатов на каждой странице и выполнения различных действий.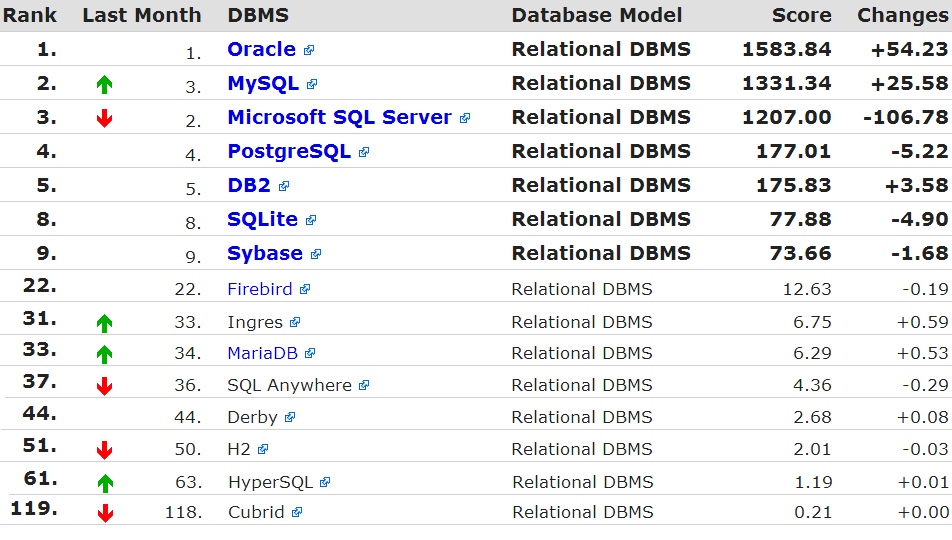
for item in items:
print(json.dumps(item, indent=True))
В этом примере json.dumps используется для вывода элемента в консоль понятным для человека способом.
Выполнение кода
Это приложение создает базу данных и контейнер API для NoSQL. Затем в примере создается элемент, после чего тот же элемент считывается обратно. Наконец, в примере выдается запрос, который должен возвращать только один этот элемент. На последнем шаге пример выводит последний элемент в консоль.
Используйте терминал для перехода в каталог приложения и запуска приложения.
python app.py
Выходные данные приложения должны выглядеть следующим образом:
{
"id": "70b63682-b93a-4c77-aad2-65501347265f",
"categoryId": "61dba35b-4f02-45c5-b648-c6badc0cbd79",
"categoryName": "gear-surf-surfboards",
"name": "Yamba Surfboard",
"quantity": 12,
"sale": false,
"_rid": "yzN6AIfJxe0BAAAAAAAAAA==",
"_self": "dbs/yzN6AA==/colls/yzN6AIfJxe0=/docs/yzN6AIfJxe0BAAAAAAAAAA==/",
"_etag": "\"2a00ccd4-0000-0200-0000-63650e420000\"",
"_attachments": "attachments/",
"_ts": 16457527130
}
Примечание
Поля, назначенные Azure Cosmos DB, будут отличаться от этого примера выходных данных.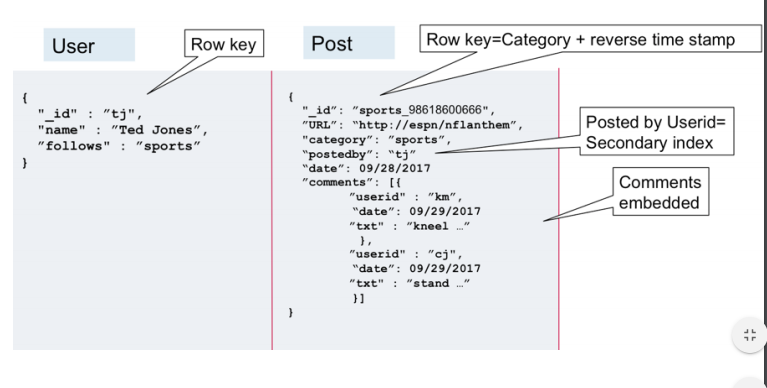
Очистка ресурсов
Если учетная запись API для NoSQL больше не нужна, можно удалить соответствующую группу ресурсов.
- Портал
- Azure CLI
- PowerShell
На портале Azure перейдите к ранее созданной группе ресурсов.
Совет
В этом кратком руководстве рекомендуется использовать имя
msdocs-cosmos-quickstart-rg.Выберите Удалить группу ресурсов.
В диалоговом окне Вы действительно хотите удалить введите имя группы ресурсов и выберите Удалить.
Дальнейшие действия
В этом кратком руководстве вы узнали, как создать учетную запись Azure Cosmos DB для NoSQL, создать базу данных и контейнер с помощью пакета SDK для Python. Теперь вы можете подробнее изучить рекомендации по импорту данных в API для NoSQL.
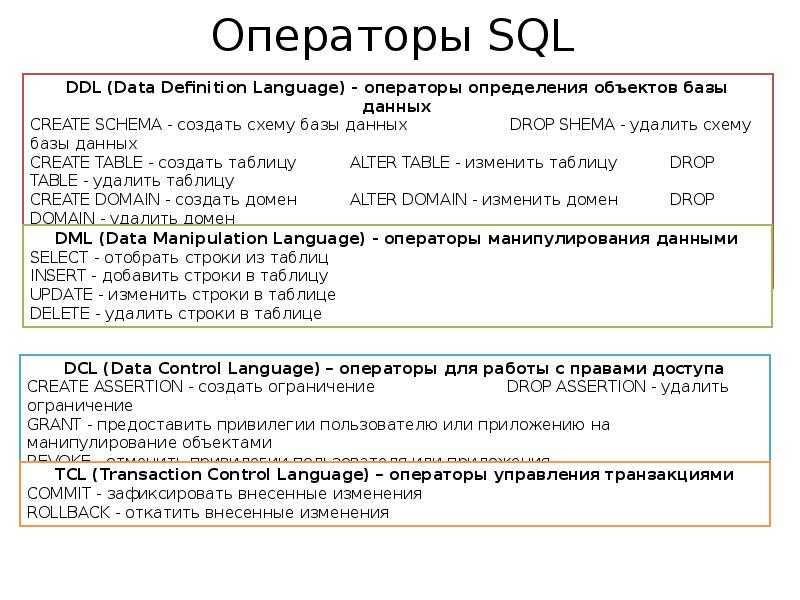
баз данных Python 101: что выбрать?
Науку о данных невозможно написать без данных.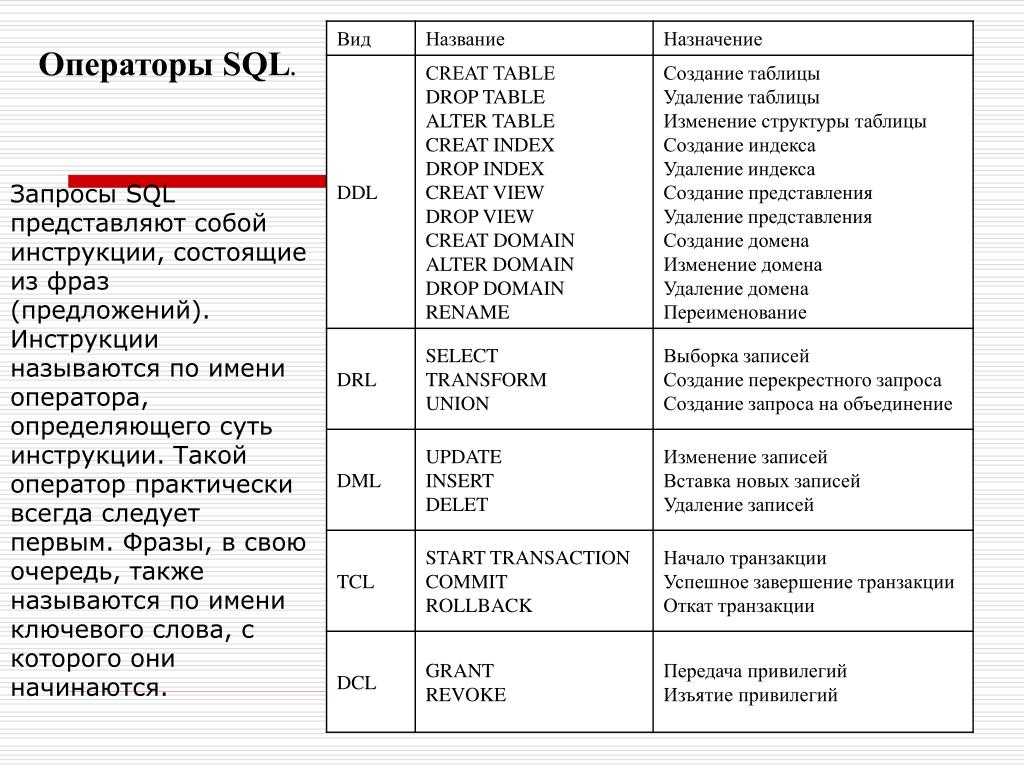 Ладно, это банально, но это правда! Большую часть времени (если не все) необходимые вам данные хранятся в СУБД (системе управления базами данных) на удаленном сервере или на вашем жестком диске.
Ладно, это банально, но это правда! Большую часть времени (если не все) необходимые вам данные хранятся в СУБД (системе управления базами данных) на удаленном сервере или на вашем жестком диске.
Это означает, что вам необходимо взаимодействовать и взаимодействовать с этой СУБД для хранения и извлечения данных, но для взаимодействия с СУБД вам необходимо говорить на ее языке: SQL (язык структурированных запросов). (Примечание: с годами люди сами стали называть базы данных SQL.)
Недавно появился еще один термин: базы данных NoSQL. Если вы только начинаете заниматься наукой о данных или уже некоторое время работаете в этой области, вы, вероятно, слышали как о базах данных SQL, так и о базах данных NoSQL.
Использование баз данных SQL или NoSQL зависит от ваших данных и целевого приложения. Но, допустим, вы используете Python и уже знаете, какую схему базы данных вы собираетесь использовать. Теперь вопрос в том, какую библиотеку Python вы используете?
В этой статье я расскажу о наиболее известных, используемых и разработанных библиотеках баз данных Python.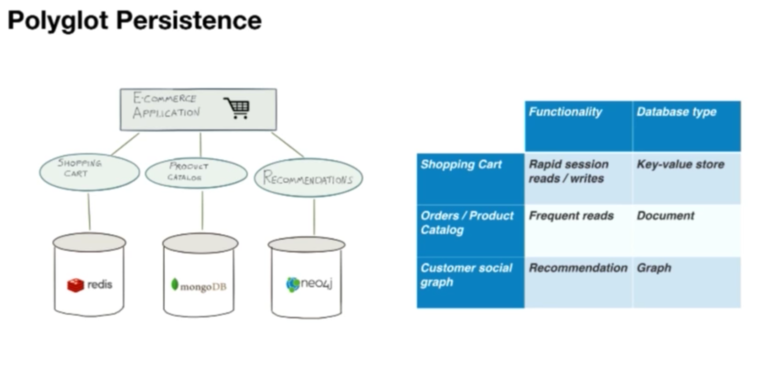 Мы поговорим о каждой библиотеке и о лучших причинах для использования каждой из них.
Мы поговорим о каждой библиотеке и о лучших причинах для использования каждой из них.
Skinny on SQLSQLZOO — лучший способ практиковать SQL
Python SQL Libraries
Python SQL Libraries
- SQLITE
- SQL
- DATGRESL
- SQL
- DATGRESL
- SQL
- DATGRESL
- . Реляционные базы данных хранят данные в разных таблицах, и каждая таблица содержит несколько записей. Эти таблицы связаны с помощью одного или нескольких отношений.
SQLite
SQLite изначально была библиотекой на языке C, созданной для реализации небольшого, быстрого, автономного, бессерверного и надежного ядра базы данных SQL. Теперь SQLite встроен в ядро Python, а это значит, что вам не нужно его устанавливать. Вы можете использовать его прямо сейчас. В Python эта библиотека связи с базой данных называется sqlite3.
Используйте SQLite, когда.
.. вы новичок, только начинаете изучать базы данных и способы взаимодействия с ними.
вы используете встроенные приложения. Если вашему приложению требуется переносимость, используйте SQLite, потому что SQLite занимает мало места и очень легкий.
ваши данные хранятся в файле на вашем жестком диске. Вы можете использовать SQLite в качестве параллельного решения для клиент-серверной СУБД в целях тестирования.
вам нужно быстрое подключение к вашим данным. Вам не нужно подключаться к серверу, чтобы использовать SQLite, что также означает, что библиотека имеет низкую задержку.
SQLite — не лучший вариант, если параллелизм представляет большую проблему для вашего приложения, поскольку операции записи сериализуются. Кроме того, SQLite слаб, когда речь идет о многопользовательских приложениях».
Еще от Сары А.
Базы данных SQLite с помощью Python МетваллиКак написать псевдокодMySQL
MySQL — один из наиболее широко используемых и известных коннекторов СУБД с открытым исходным кодом. Он использует архитектуру сервер/клиент, состоящую из многопоточного SQL-сервера. Это позволяет MySQL работать хорошо, потому что он легко использует несколько процессоров. Первоначально MySQL был написан на C/C++, а затем расширен для поддержки различных платформ. Ключевыми особенностями MySQL являются масштабируемость, безопасность и репликация.
Чтобы использовать MySQL, вам необходимо установить его коннектор. В командной строке вы можете сделать это, запустив:
python -m pip установить mysql-connector-python
Используйте MySQL, когда…
вам нужна дополнительная безопасность.
Благодаря преимуществам безопасности MySQL он оптимален для приложений, требующих аутентификации пользователя или пароля.вам нужна многопользовательская поддержка. В отличие от SQLite, MySQL поддерживает многопользовательские приложения и является хорошим выбором для распределенных систем.
вам нужны расширенные возможности резервного копирования и взаимодействия, но с простым синтаксисом и легкой установкой.
Однако MySQL плохо работает, когда вы выполняете массовые операции INSERT или хотите выполнять операции полнотекстового поиска.
PostgreSQL
PostgreSQL — это еще один соединитель РСУБД с открытым исходным кодом, ориентированный на расширяемость и использующий структуру базы данных клиент/сервер. В PostgresSQL мы называем обмен данными, управляющий файлами и операциями базы данных, «процессом Postgres», откуда библиотека и получила свое название.
Для связи с базой данных PostgresSQL вам необходимо установить драйвер, который позволяет Python делать это. Одним из часто используемых драйверов является psycopg2. Вы можете установить его, выполнив следующую инструкцию командной строки:
pip install psycopg2
Используйте PostgreSQL, когда…
вы запускаете хранилище данных аналитических приложений. PostgresSQL обладает выдающимися возможностями параллельной обработки.
ваша база данных должна соответствовать модели ACID (A: атомарность; C: согласованность; I: изоляция; D: надежность) (в основном финансовые приложения). В этом случае PostgresSQL предоставляет для этого оптимальную платформу.
вам нужны базы данных исследований и научных проектов.
PostgresSQL немного сложнее установить и начать работу, чем MySQL. Тем не менее, это стоит хлопот, учитывая бесчисленные расширенные функции, которые он предоставляет.
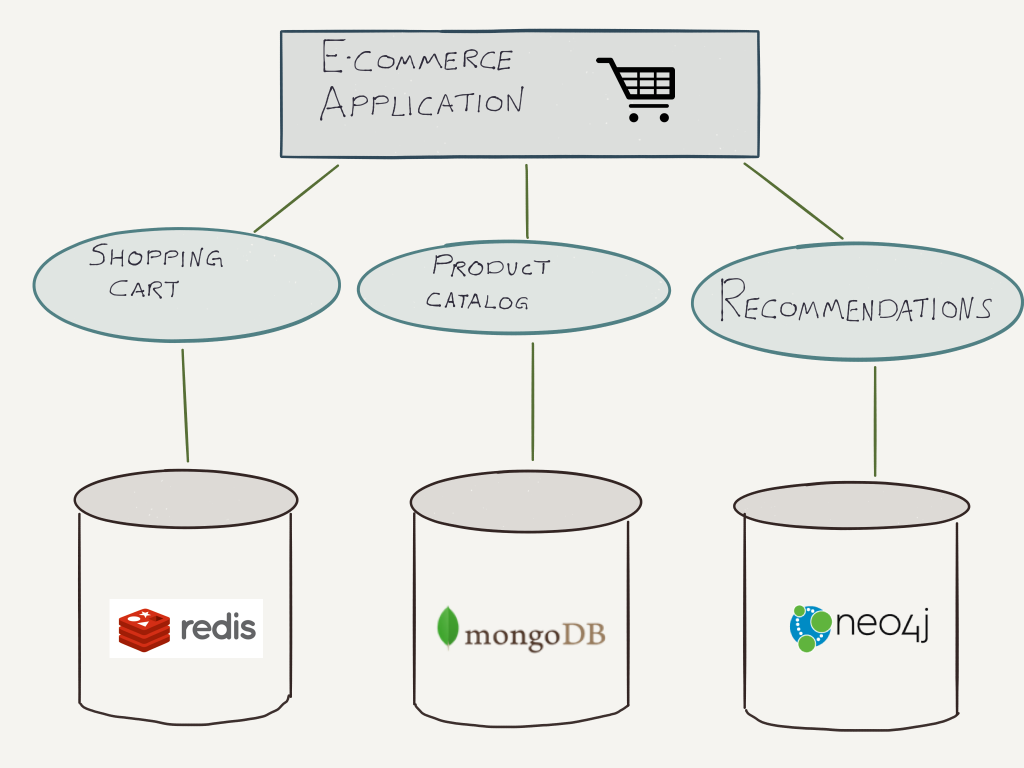
Нужна консультация по приложениям для работы? Мы получили вас. базы данных. В этих типах баз данных структура хранения данных разработана и оптимизирована для конкретных требований. Существует четыре основных типа библиотек NoSQL:
, ориентированный на документ
Пара ключевых значений
, ориентированные на столбцы
График
Mongodb
9
 ..
..  МетваллиКак написать псевдокод
МетваллиКак написать псевдокод Благодаря преимуществам безопасности MySQL он оптимален для приложений, требующих аутентификации пользователя или пароля.
Благодаря преимуществам безопасности MySQL он оптимален для приложений, требующих аутентификации пользователя или пароля.

. Это система хранения данных с открытым исходным кодом, ориентированная на документы. Обычно мы используем PyMongo, чтобы обеспечить взаимодействие между одним или несколькими экземплярами MongoDB через код Python. MongoEngine — это Python ORM, написанный для MongoDB поверх PyMongo.
Чтобы использовать MongoDB, вам необходимо установить движок и актуальные библиотеки MongoDB.
pip установить пимонго == 3.
 4.0
pip install mongodb
4.0
pip install mongodb Используйте MongoDB, когда…
вы хотите создавать легко масштабируемые приложения, которые можно легко развернуть.
ваши данные структурированы в виде документов, но вы хотите использовать возможности реляционных баз данных.
у вас есть приложение с переменными структурами данных, например приложения IoT.
вы работаете с приложениями реального времени, такими как приложения электронной коммерции и системы управления контентом.
Готово3 шага к завершению вашего приложения. Подсказка: начните с конца.
Redis
Redis — это хранилище структур данных в памяти с открытым исходным кодом. Он поддерживает структуры данных, такие как строки, хеш-таблицы, списки, наборы и многое другое. Redis обеспечивает высокую доступность с помощью Redis Sentinel и автоматическое разбиение на разделы с помощью Redis Cluster. Redis также считается самой быстрой базой данных в мире.
Redis также считается самой быстрой базой данных в мире.
Вы можете настроить Redis, выполнив следующие инструкции из командной строки:
wget http://download.redis.io/releases/redis-6.0.8.tar.gz смола xzf redis-6.0.8.tar.gz компакт-диск редис-6.0.8 делать
Используйте Redis, когда…
скорость является приоритетом в ваших приложениях.
у вас хорошо спланированный дизайн. Redis имеет много определенных структур данных и дает вам возможность явно указать, как вы хотите, чтобы ваши данные хранились.
ваша база данных имеет стабильный размер. Redis может увеличить скорость поиска конкретной информации в ваших данных.
Cassandra
Apache Cassandra — это хранилище данных NoSQL, ориентированное на столбцы, предназначенное для приложений хранения с большим количеством операций записи. Cassandra обеспечивает масштабируемость и высокую доступность без ущерба для производительности. Cassandra также обеспечивает меньшую задержку для многопользовательских приложений. Cassandra немного сложна в установке и запуске. Однако вы можете сделать это, следуя руководству по установке на официальном сайте Cassandra.
Cassandra обеспечивает масштабируемость и высокую доступность без ущерба для производительности. Cassandra также обеспечивает меньшую задержку для многопользовательских приложений. Cassandra немного сложна в установке и запуске. Однако вы можете сделать это, следуя руководству по установке на официальном сайте Cassandra.
Используйте Cassandra, когда…
у вас есть огромные объемы данных. Cassandra обладает большой гибкостью и мощностью для работы с невероятными объемами данных, поэтому большинство приложений с большими данными — хороший вариант использования Cassandra.
вам нужна надежность. Cassandra обеспечивает стабильную производительность в режиме реального времени для приложений потоковой передачи и онлайн-обучения.
безопасность превыше всего. Cassandra имеет мощное управление безопасностью, что делает ее идеальной для приложений по обнаружению мошенничества.
Neo4j
Neo4j — это графовая база данных NoSQL, созданная с нуля для использования данных и взаимосвязей данных. Neo4j соединяет данные по мере их хранения, позволяя выполнять запросы с высокой скоростью. Первоначально Neo4j был реализован на Java и Scala, а затем расширен для использования на других платформах, таких как Python.
Neo4j, по сути, является библиотекой базы данных графов и имеет один из лучших веб-сайтов и систем технической документации. Он четкий, лаконичный и охватывает все вопросы, которые могут возникнуть у вас по поводу установки, начала работы и использования библиотеки.
Используйте Neo4j, когда…
вам необходимо визуализировать и анализировать сети и их характеристики.
вы разрабатываете и анализируете системы рекомендаций.
вы анализируете связи в социальных сетях и извлекаете информацию на основе существующих связей.
вы собираетесь выполнять операции по управлению идентификацией и доступом.
вам нужно выполнить различные оптимизации цепочки поставок.
Что нужно, чтобы стать специалистом по данным?4 Основные навыки, необходимые каждому специалисту по данным
Выводы
Выбор правильной базы данных для вашей структуры данных и приложения может сократить время разработки вашего приложения при одновременном повышении эффективности твоя работа. Развитие способности выбирать правильный тип базы данных на лету может занять некоторое время, но как только вы это сделаете, большая часть утомительной работы над вашим проектом станет намного проще, быстрее и эффективнее. Единственный способ развить любой навык — это практика. Другой способ исследовать — методом проб и ошибок (обычно мой метод). Пробуйте разные варианты, пока не найдете тот, который лучше всего вам подходит и подходит для вашего приложения.
Практическая демонстрация баз данных SQL и NoSQL в Python | Мэтт Сосна
Произведите впечатление на своих друзей с помощью SQLAlchemy и PyMongo
Художественная интерпретация базы данных MongoDB. Фото Джоэла Филипе на Unsplash
От древних правительственных, библиотечных и медицинских записей до современных потоков видео и IoT нам всегда были нужны способы эффективного хранения и извлечения данных. Вчерашние картотеки превратились в современные компьютеры баз данных с двумя основными парадигмами наилучшей организации данных: реляционный (SQL) и нереляционный подход (NoSQL).
Базы данных важны для любой организации, поэтому полезно разобраться, где полезен каждый тип. Мы начнем с краткого введения в историю и теорию SQL и NoSQL. Но запоминание абстрактных фактов может только продвинуть вас вперед — затем мы фактически создадим каждый тип базы данных в Python, чтобы интуитивно понять, как они работают. Давай сделаем это!
Давай сделаем это!
Базы данных SQL
Базы данных появились вскоре после того, как предприятия начали внедрять компьютеры в 1950-х годах, но только в 1970 году появилось реляционных баз данных . Основная идея реляционной базы данных состоит в том, чтобы избежать дублирования данных, сохраняя их только один раз , при этом различные аспекты этих данных хранятся в таблицах с формальными отношениями. Соответствующие данные затем могут быть извлечены из разных таблиц, отфильтрованы и переупорядочены с помощью запросов в SQL или язык структурированных запросов.
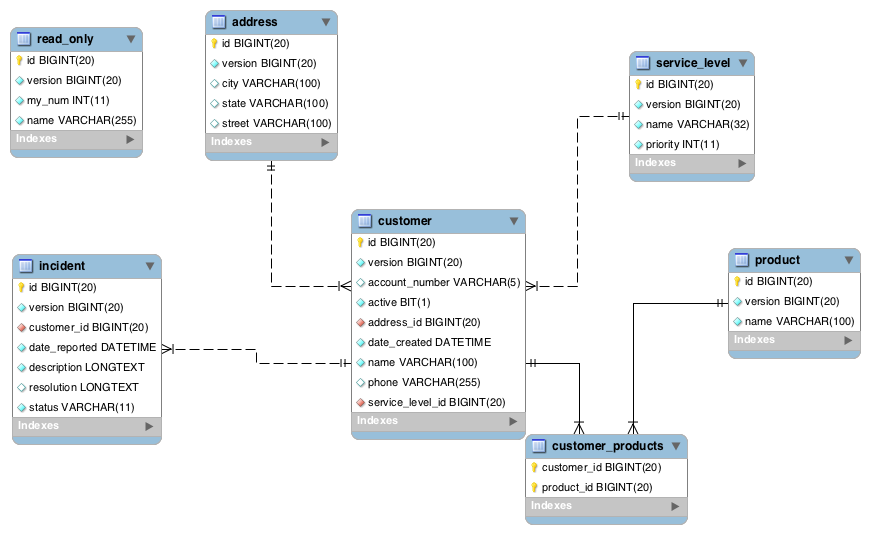
Предположим, что мы школа и систематизируем данные об учащихся, оценках и классах. Мы могли бы иметь одну гигантскую таблицу, которая выглядит так:
Скриншот автора
Однако это довольно неэффективный способ хранения данных. Поскольку у студентов несколько экзаменационных баллов, для хранения всех данных в одной таблице требуется дублирование информации, которую нам нужно перечислить только один раз, , например, хобби Джерри, идентификатор класса и учитель. Если у вас всего несколько учеников, ничего страшного. Но по мере роста объема данных все эти повторяющиеся значения в конечном итоге требуют места для хранения и затрудняют извлечение данных, которые вам действительно нужны, из вашей таблицы.
Если у вас всего несколько учеников, ничего страшного. Но по мере роста объема данных все эти повторяющиеся значения в конечном итоге требуют места для хранения и затрудняют извлечение данных, которые вам действительно нужны, из вашей таблицы.
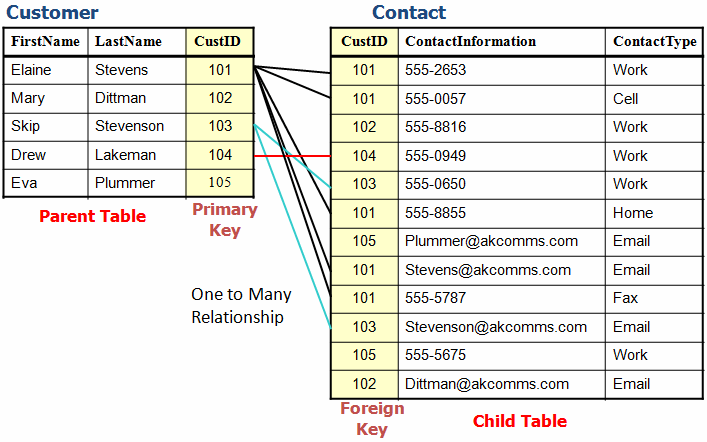
Вместо этого было бы намного эффективнее разбить эту информацию на отдельные таблицы , затем связать информацию в таблицах друг с другом. Вот как будут выглядеть наши таблицы:
Скриншот автора
Всего 30 ячеек по сравнению с 42 в основной таблице — улучшение на 28,5%! Для этого конкретного набора полей и таблиц, когда мы увеличиваем количество студентов, скажем, до 100, 1000 или 1 000 000, улучшение фактически стабилизируется на уровне 38%. Это более чем на треть меньше места для хранения только за счет переупорядочения данных!
Но недостаточно просто хранить данные в отдельных таблицах; нам все еще нужно смоделировать их отношения. Мы можем визуализировать нашу схему базы данных с помощью диаграммы сущность-связь, как показано ниже.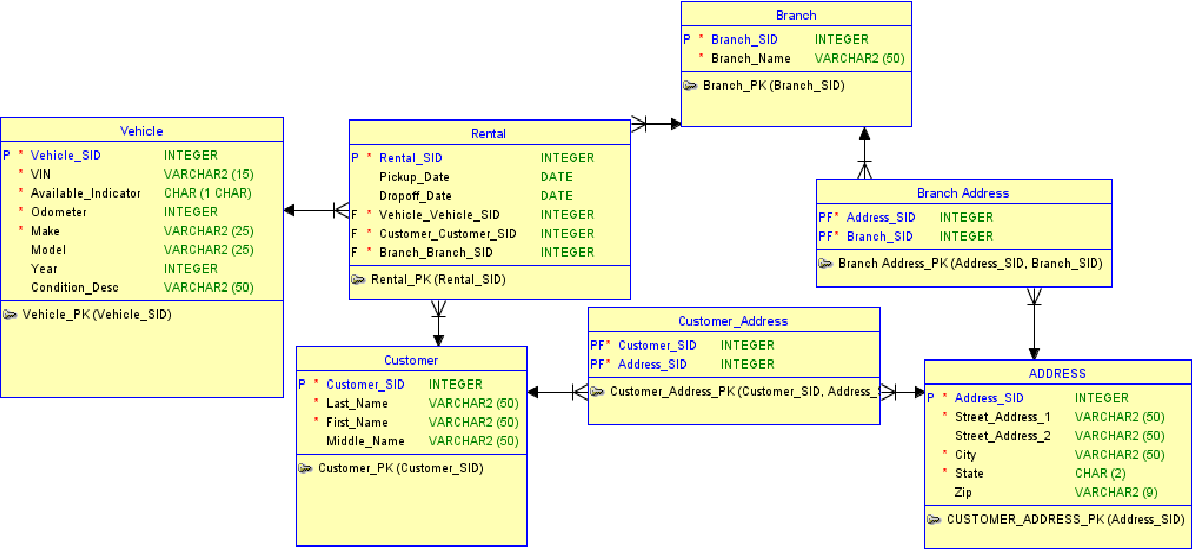
Скриншот автора
На этой диаграмме показано, что один класс состоит из нескольких учеников, и каждый ученик имеет несколько оценок. Мы можем использовать эту схему для создания реляционной базы данных в системе управления реляционными базами данных (RDBMS), такой как MySQL или PostgreSQL, а затем продолжить наш веселый и эффективный способ хранения.
Итак, мы придумали, как решить все проблемы с хранением данных, верно? Ну, не совсем. Реляционные базы данных отлично подходят для данных, которые можно легко хранить в таблицах, таких как строки, числа, логические значения и даты. В нашей базе данных выше, например, хобби каждого ученика можно легко сохранить в одной ячейке в виде строки.
Но что, если у студента больше одного хобби? Или что, если мы хотим отслеживать 90 299 подкатегорий 90 300 хобби, таких как упражнения, искусство или игры? Другими словами, что, если мы хотим хранить такие значения:
хобби_лист = ['садоводство', 'чтение']
хобби_дикт = {'упражнения': ['плавание', 'бег'],
'игры': ['шахматы']}
Чтобы учесть списков хобби, мы могли бы создать промежуточную таблицу «многие ко многим», чтобы позволить учащимся иметь несколько хобби (и чтобы несколько учеников имели одно и то же хобби).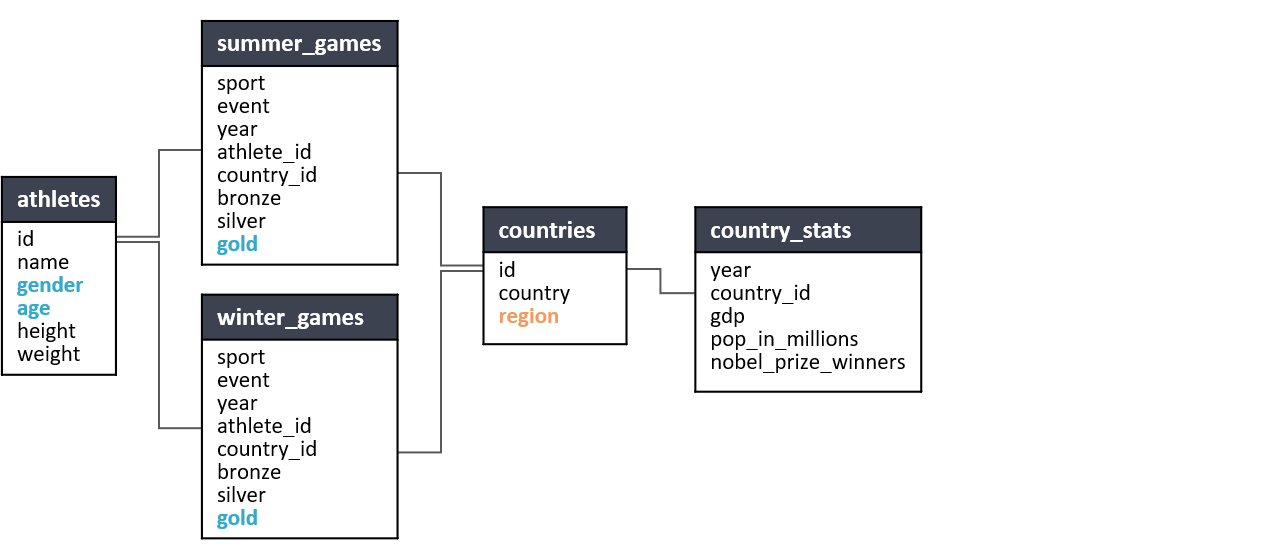 Но со словарем для хобби все становится сложнее… нам, вероятно, потребуется хранить наш словарь в виде строки JSON, для чего реляционные базы данных на самом деле не созданы. [1]
Но со словарем для хобби все становится сложнее… нам, вероятно, потребуется хранить наш словарь в виде строки JSON, для чего реляционные базы данных на самом деле не созданы. [1]
Еще одна проблема с реляционными базами данных возникла в 90-х годах, когда популярность Интернета росла: как обрабатывать терабайты и петабайты данных (часто JSON) только на одной машине. Реляционные базы данных были разработаны для масштабирования по вертикали : при необходимости настройте больше оперативной памяти или процессоров для сервера, на котором размещена база данных.
Но наступает момент, когда даже самая дорогая машина не может работать с базой данных. Лучшим подходом может быть масштаб по горизонтали: 9От 0037 до добавьте больше машин вместо того, чтобы пытаться сделать вашу машину сильнее . Это не только дешевле, но и обеспечивает устойчивость в случае отказа одной машины. (Действительно, распределенные вычисления с дешевым оборудованием — это стратегия, которую Google использовал с самого начала. )
)
Шедевр Google Slides от автора
Базы данных NoSQL удовлетворяют эти потребности, позволяя использовать вложенные или переменные данные и работая на распределенных кластерах машин. [2] Такой дизайн позволяет им легко хранить и запрашивать большие объемы неструктурированных данных (т. е. нетабличных), даже если записи имеют совершенно разные формы. У Мухаммеда есть 50-страничный JSON с аккуратно организованными хобби и подхобби, а Джерри любит только садоводство? Без проблем.
Но, конечно, у этой конструкции есть и недостатки, иначе мы бы все перешли. Отсутствие схемы базы данных означает, что ничто не мешает пользователю писать мусор (например, случайно записать строку «имя» в поле «оценка»), и может быть сложно объединить данные между различными коллекциями в базе данных. Использование распределенных серверов также означает, что запросы могут возвращать устаревшие данные до того, как обновления будут синхронизированы. [3] Таким образом, правильный выбор между базой данных SQL и NoSQL зависит от того, с какими недостатками вы готовы иметь дело.
Достаточно теории; давайте на самом деле создадим каждый тип базы данных в Python. Мы будем использовать библиотеку sqlalchemy для создания простой базы данных SQLite и pymongo для создания базы данных MongoDB NoSQL. Обязательно установите sqlalchemy и pymongo , чтобы запустить приведенный ниже код, а также запустите сервер MongoDB.
SQL
В профессиональном контексте мы, вероятно, захотим создать базу данных с помощью специальной СУБД с реальным кодом SQL. Но для нашего простого доказательства концепции здесь мы будем использовать SQLAlchemy.
SQLAlchemy позволяет создавать, изменять и взаимодействовать с реляционными базами данных в Python с помощью реляционного преобразователя объектов . Основная идея заключается в том, что SQLAlchemy использует классов Python для представления таблиц базы данных . Экземпляры класса Python можно рассматривать как строк таблицы .
Начнем с загрузки необходимых классов sqlalchemy . Импорт в строке 1 предназначен для установления соединения с базой данных ( create_engine ) и определение схемы наших таблиц ( Column , String , Integer , ForeignKey ). Следующий импорт, Session , позволяет нам читать и писать в нашу базу данных. Наконец, мы используем declarative_base для создания шаблонного класса Python, дочерние элементы которого будут сопоставлены с таблицами SQLAlchemy.
Теперь мы создаем таблицы классов, учеников и оценок как классы Python Classroom , Student и класса . Обратите внимание, что все они наследуются от класса Base SQLALchemy. Наши классы просты: они определяют только соответствующее имя таблицы и ее столбцы.
Теперь мы создаем нашу базу данных и таблицы. create_engine запускает базу данных SQLite [4], которую мы затем включаем. Строка 4 запускает наш сеанс, а строка 7 создает таблицы базы данных из наших классов Python.
Строка 4 запускает наш сеанс, а строка 7 создает таблицы базы данных из наших классов Python.
Теперь мы генерируем наши данные. Экземпляры Classroom , Студент и Класс служат строками в каждой таблице.
Теперь мы, наконец, записываем наши данные в базу данных. Как и в Git, мы используем session.add для добавления каждой строки в промежуточную область и session.commit для фактической записи данных.
Отличная работа! Давайте завершим этот раздел воссозданием первой таблицы в этом посте.
NoSQL
Теперь давайте переключимся на MongoDB. Обязательно установите MongoDB и запустите локальный сервер. Ниже мы импортируем pymongo , подключитесь к нашему локальному серверу, а затем создайте базу данных с именем classDB .
В реляционной базе данных мы создаем таблиц с записями . В базе данных NoSQL мы создаем коллекций с документами . Ниже мы создаем коллекцию под названием
Ниже мы создаем коллекцию под названием класс и вставляем словари с информацией о каждом ученике.
Обратите внимание, как типы данных в хобби разные: это строка для Джерри и словарь для Мухаммеда. (И даже в словаре hobbies значения представляют собой как списки, так и строки.) MongoDB все равно — нет схемы для принудительного применения типов данных или структуры данных.
Мы можем просматривать наши данные, перебирая объекты, возвращенные из db.classroom.find . Мы используем pprint , чтобы упростить чтение вывода. Обратите внимание, как MongoDB добавляет уникальный идентификатор объекта в каждый документ.
Мы можем легко добавить документ с новыми полями.
Наконец, давайте выполним два запроса, которые действительно подчеркнут, чем наша база данных MongoDB отличается от SQLite. Первый запрос учитывает отсутствие схемы базы данных, находя все документы, содержащие поле рождения . Второй запрос ищет документы, в которых
Второй запрос ищет документы, в которых выполняет во вложенном поле упражнение в пределах хобби .
В этом посте рассказывается об истории баз данных SQL и NoSQL, их относительных преимуществах и недостатках. Затем мы сделали вещи более конкретными, создав базы данных каждого типа на Python с помощью SQLAlchemy и MongoDB. Я настоятельно рекомендую вам запачкать руки довольно теоретическими концепциями, такими как битва между SQL и NoSQL. Я многому научился, написав код для этого поста! Ждите будущих постов с некоторыми ляпами кодирования, где я рассмотрю некоторые ограничения SQLite и MongoDB.
Best,
Matt
1. Базы данных NoSQL
Этот отличный ответ на Stack Overflow объясняет, что реляционные базы данных борются с JSON по двум основным причинам:
- Реляционные базы данных предполагают, что данные в них хорошо нормализованы. Планировщик запросов лучше оптимизирован при просмотре столбцов, чем ключей JSON.
- Внешние ключи между таблицами не могут быть созданы на ключах JSON. Чтобы связать две таблицы, вы должны использовать значения в столбце, который здесь будет полным JSON в строке, а не ключами в JSON.

2. Базы данных NoSQL
Мне было трудно составить краткое и четкое описание того, как базы данных NoSQL хранят данные, поскольку существует несколько типов баз данных NoSQL. База данных типа «ключ-значение» может практически не иметь ограничений на свои данные, база данных документов имеет базовые предположения относительно формата своего содержимого (например, XML или JSON), в то время как графовая база данных может быть строгой в отношении того, как хранятся узлы и ребра. Между тем база данных, ориентированная на столбцы, фактически состоит из таблиц, но данные в них организованы по столбцам, а не по строкам.
3. Базы данных NoSQL
Поскольку база данных NoSQL распределена по нескольким серверам, возникает небольшая задержка перед тем, как изменение в базе данных на одном сервере отразится на всех остальных серверах.