Содержание
Python — базы данных NoSQL
Поскольку все больше и больше данных становятся доступными как неструктурированные или полуструктурированные, потребность в управлении ими через базу данных NoSql возрастает. Python также может взаимодействовать с базами данных NoSQL аналогично взаимодействию с реляционными базами данных. В этой главе мы будем использовать python для взаимодействия с MongoDB в качестве базы данных NoSQL. Если вы новичок в MongoDB, вы можете узнать об этом в нашем уроке здесь.
Чтобы подключиться к MongoDB, python использует библиотеку, известную как pymongo . Вы можете добавить эту библиотеку в свою среду Python, используя приведенную ниже команду из среды Anaconda.
conda install pymongo
Эта библиотека позволяет Python подключаться к MOngoDB с помощью клиента db. После подключения мы выбираем имя БД, которое будет использоваться для различных операций.
Вставка данных
Для вставки данных в MongoDB мы используем метод insert (), который доступен в среде базы данных. Сначала мы подключаемся к базе данных, используя код Python, показанный ниже, а затем предоставляем детали документа в виде серии пар ключ-значение.
Сначала мы подключаемся к базе данных, используя код Python, показанный ниже, а затем предоставляем детали документа в виде серии пар ключ-значение.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to the test db
db=client.test
# Use the employee collection
employee = db.employee
employee_details = {
'Name': 'Raj Kumar',
'Address': 'Sears Streer, NZ',
'Age': '42'
}
# Use the insert method
result = employee.insert_one(employee_details)
# Query for the inserted document.
Queryresult = employee.find_one({'Age': '42'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
{u'Address': u'Sears Streer, NZ',
u'Age': u'42',
u'Name': u'Raj Kumar',
u'_id': ObjectId('5adc5a9f84e7cd3940399f93')}Обновление данных
Обновление существующих данных MongoDB похоже на вставку. Мы используем метод update (), который является родным для mongoDB. В приведенном ниже коде мы заменяем существующую запись новыми парами ключ-значение. Обратите внимание, как мы используем критерии условия, чтобы решить, какую запись обновить.
В приведенном ниже коде мы заменяем существующую запись новыми парами ключ-значение. Обратите внимание, как мы используем критерии условия, чтобы решить, какую запись обновить.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to db
db=client.test
employee = db.employee
# Use the condition to choose the record
# and use the update method
db.employee.update_one(
{"Age":'42'},
{
"$set": {
"Name":"Srinidhi",
"Age":'35',
"Address":"New Omsk, WC"
}
}
)
Queryresult = employee.find_one({'Age':'35'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
{u'Address': u'New Omsk, WC',
u'Age': u'35',
u'Name': u'Srinidhi',
u'_id': ObjectId('5adc5a9f84e7cd3940399f93')}Удаление данных
Удаление записи также просто, когда мы используем метод удаления. Здесь также упоминается условие, которое используется для выбора записи, которая будет удалена.
Здесь также упоминается условие, которое используется для выбора записи, которая будет удалена.
# Import the python libraries
from pymongo import MongoClient
from pprint import pprint
# Choose the appropriate client
client = MongoClient()
# Connect to db
db=client.test
employee = db.employee
# Use the condition to choose the record
# and use the delete method
db.employee.delete_one({"Age":'35'})
Queryresult = employee.find_one({'Age':'35'})
pprint(Queryresult)Когда мы выполняем приведенный выше код, он дает следующий результат.
None
Итак, мы видим, что конкретная запись больше не существует в БД.
NoSQL база данных MongoDB: работа на Python (pymongo)
Сегодня познакомимся с интересным инструментом — NoSQL базой данных. Ранее мы мучали MySQL и подобные базы, которые требуют много внимания к SQL-запросам и структуре таблицы. Теперь мы познакомимся с идеальной базой данных для не структурированной информации. То есть мы избавимся от строгого синтаксиса и сможем легко дополнять записи новой информацией. В этом огромный плюс NoSQL-базы для написания различных ботов, которые в дальнейшем будут масштабироваться.
В этом огромный плюс NoSQL-базы для написания различных ботов, которые в дальнейшем будут масштабироваться.
Подготовка
Сначала установим саму MongoBD: переходим на официальный сайт Mongo по ссылке и скачиваем сервер версии 6.0.3 под вашу операционную систему.
Для корректной установки следуйте примерам на скриншотах:
Важно тут выбрать пункт “Complete”. Этот пункт поставит все стандартные настройки и модули, что для начала нам подойдет. Потом, если будете изучать эту БД, сможете настраивать под себя:
В этом пункте важно поставить галочку на “Install MongoDB Compass” — на компьютер установится графический интерфейс для взаимодействия с СУБД.
После установки нам открывается программа MongoDB Compass, где уже вставлены данные для подключения к установленному серверу. Нажимаем кнопку «connect», и мы в нем:
Ниже пример как можно создать базу данных и коллекцию. Коллекции – это аналог таблиц в SQL-базах. В них мы храним информацию, которая нам нужна.
Установка MongoClient и код на Python
Для Windows:
pip install pymongo faker
Для MacOS:
python pip install pymongo faker
Для знакомства с СУБД MongoDB нам хватит сделать несколько методов, таких как: добавление пользователя, получить всю коллекцию, изменить какое-то значение, поиск, по заданным критериям и на этом все. Если вам будет интересна эта СУБД, вы сможете самостоятельно ознакомиться с другими её возможностями.
У нас будет два файла — pymongoAPI.py и main.py (призываю вас всегда разделять проект на логические модули – это правильный тон в мире программистов Python). Первый файл будет отвечать за взаимодействие с БД, а во втором мы будем пытаться добавлять новые значения и что-то менять.
Импорты:
from pymongo import MongoClient
Для всего взаимодействия с MongoDB потребуется только сам клиент, который и импортируем.
Класс взаимодействия с MongoDB:
class MongoDB(object):
def __init__(self, host: str = 'localhost',
port: int = 27017,
db_name: str = None,
collection: str = None):
self. _client = MongoClient(f'mongodb://{host}:{port}')
self._collection = self._client[db_name][collection]
def create_user(self, user: dict):
try:
if self._collection.find_one({"username": user.get('username')}) == None:
self._collection.insert_one(user)
print(f"Added New user: {user.get('username')}")
else:
print(f"User: {user.get('username')} in collection")
except Exception as ex:
print("[create_user] Some problem...")
print(ex)
def get_all_users(self):
try:
data = self._collection.find()
print("Get all users")
return data
except Exception as ex:
print("[get_all] Some problem...")
print(ex)
def find_by_username(self, username: str):
try:
data = self. _collection.find_one({"username": username})
print("Get user by username")
return data
except Exception as ex:
print("[find_by_username] Some problem...")
print(ex)
def change_user(self, username: str, key: str, value: str):
try:
if self._collection.find_one({"username": user.get('username')}) is not None:
self._collection.update_one({"username": username}, {"$set": {key: value}})
else:
print(f'User: {username} not find')
except Exception as ex:
print("[change_user] Some problem...")
print(ex)
_client = MongoClient(f'mongodb://{host}:{port}')
self._collection = self._client[db_name][collection]
def create_user(self, user: dict):
try:
if self._collection.find_one({"username": user.get('username')}) == None:
self._collection.insert_one(user)
print(f"Added New user: {user.get('username')}")
else:
print(f"User: {user.get('username')} in collection")
except Exception as ex:
print("[create_user] Some problem...")
print(ex)
def get_all_users(self):
try:
data = self._collection.find()
print("Get all users")
return data
except Exception as ex:
print("[get_all] Some problem...")
print(ex)
def find_by_username(self, username: str):
try:
data = self. _collection.find_one({"username": username})
print("Get user by username")
return data
except Exception as ex:
print("[find_by_username] Some problem...")
print(ex)
def change_user(self, username: str, key: str, value: str):
try:
if self._collection.find_one({"username": user.get('username')}) is not None:
self._collection.update_one({"username": username}, {"$set": {key: value}})
else:
print(f'User: {username} not find')
except Exception as ex:
print("[change_user] Some problem...")
print(ex) _client = MongoClient(f'mongodb://{host}:{port}')
self._collection = self._client[db_name][collection]
def create_user(self, user: dict):
try:
if self._collection.find_one({"username": user.get('username')}) == None:
self._collection.insert_one(user)
print(f"Added New user: {user.get('username')}")
else:
print(f"User: {user.get('username')} in collection")
except Exception as ex:
print("[create_user] Some problem...")
print(ex)
def get_all_users(self):
try:
data = self._collection.find()
print("Get all users")
return data
except Exception as ex:
print("[get_all] Some problem...")
print(ex)
def find_by_username(self, username: str):
try:
data = self.
_client = MongoClient(f'mongodb://{host}:{port}')
self._collection = self._client[db_name][collection]
def create_user(self, user: dict):
try:
if self._collection.find_one({"username": user.get('username')}) == None:
self._collection.insert_one(user)
print(f"Added New user: {user.get('username')}")
else:
print(f"User: {user.get('username')} in collection")
except Exception as ex:
print("[create_user] Some problem...")
print(ex)
def get_all_users(self):
try:
data = self._collection.find()
print("Get all users")
return data
except Exception as ex:
print("[get_all] Some problem...")
print(ex)
def find_by_username(self, username: str):
try:
data = self. _collection.find_one({"username": username})
print("Get user by username")
return data
except Exception as ex:
print("[find_by_username] Some problem...")
print(ex)
def change_user(self, username: str, key: str, value: str):
try:
if self._collection.find_one({"username": user.get('username')}) is not None:
self._collection.update_one({"username": username}, {"$set": {key: value}})
else:
print(f'User: {username} not find')
except Exception as ex:
print("[change_user] Some problem...")
print(ex)
_collection.find_one({"username": username})
print("Get user by username")
return data
except Exception as ex:
print("[find_by_username] Some problem...")
print(ex)
def change_user(self, username: str, key: str, value: str):
try:
if self._collection.find_one({"username": user.get('username')}) is not None:
self._collection.update_one({"username": username}, {"$set": {key: value}})
else:
print(f'User: {username} not find')
except Exception as ex:
print("[change_user] Some problem...")
print(ex)Разберёмся что за чем идет.
__init__ — это конструктор, он принимает в себя ip адрес сервера, порт, название базы данных и название коллекции. Он создает подключение к серверу и записывает в отдельную внутреннюю переменную. Дальше отдельно вытягивает в переменную нашу базу данных. Часто спрашивают зачем ставить нижней прочерк перед полем – это нужно, чтобы показать другим разработчикам, который показывает, что его трогать не надо (так принято показывать в Python приватные переменные).
Дальше отдельно вытягивает в переменную нашу базу данных. Часто спрашивают зачем ставить нижней прочерк перед полем – это нужно, чтобы показать другим разработчикам, который показывает, что его трогать не надо (так принято показывать в Python приватные переменные).
Create_user – «кушает» словарь, это связанно с тем, что мы будем сразу передавать нового пользователя. Можно формировать его и внутри метода, но так проще. Сразу скажу, что все запросы к базам данных следует оборачивать в try… except, потому что в случае ошибки у нас не будет «падать» программа. В реальной жизни если из-за этой ошибки пользователи не смогу воспользоваться функциями, у вас могут быть проблемы.
Теперь переходим к сути. Обращаемся к методу find_one для проверки, существует ли пользователь в коллекции. Внутрь мы передаем словарь ключ (искомое поле) и значение. Если нам в ответ вернется None, то значит такого значения не существует, ну и если словарь, то значит пользователь существует (сразу отмечу, что username у нас будут индивидуальным значением, то есть не будет повторяться).
Дальше обращаемся к insert_one и передаем словарь пользователя. Чтобы видеть ошибки, мы делаем выводы в консоль о выполненном действии и в случае ошибки показываем модуль с ошибкой.
Get_all_users – с помощью этого метода будем выводить все записи в коллекции. Обращаемся к объекту коллекции и применяем метод find, без каких-либо значений. В ответ мы получаем массив значений и возвращаем его из метода.
Find_by_username – теперь будем искать по уникальному значению в виде username. Принимаем искомого пользователя и обращаемся к методу коллекции find_one. Он будет выводить первое совпадение и возвращать его словарем, если пользователя не существует, то вернется None.
Change_user – последний метод на сегодня, он будет менять значение. Принимает в себя username, key (изменяемое значение) и value (новое значение). В начале идет проверка на наложение пользователя в коллекции, потом используется update_one.
Что же это такое, метод, предоставляемый объектом коллекции для обновления записи? Первым значением идет словарь для поиска по значение, потом второй с служебным оператором $set с вложенным вторым словарем, внутри которого находится ключ и его новое значение (подробнее об служебных операторах по ссылке).
Main.py
Теперь идем проверять наш класс. Будем рассматривать код по строчкам, чтобы можно было посмотреть все по очереди и отслеживать, что меняется в БД. Импортируем наш MongoDB из файла mongoAPI. Так же библиотеку для создания несуществующих пользователей.
from mongoAPI import MongoDB import faker
Дальше создаем объект dbase на основе нашего класса, передаем в него название БД и коллекции с которой будем работать:
dbase = MongoDB(db_name='article', collection='user')
Так же не стоит забывать про объект для создание «фейковых» пользователей:
faker_obj = faker.Faker()
Создаем наш фейковый профиль и посмотрим вывод в консоль:
user_profile = faker_obj.
 simple_profile()
user_profile['birthdate'] = user_profile['birthdate'].strftime('%d/%m/%Y')
print(user_profile)
simple_profile()
user_profile['birthdate'] = user_profile['birthdate'].strftime('%d/%m/%Y')
print(user_profile)Словарь состоит из логина, имени, пола, адреса, почты и даты рождения:
{‘username’: ‘dparker’, ‘name’: ‘Megan Morris’, ‘sex’: ‘F’, ‘address’: ‘15074 Conner Lane\nDavidshire, ME 67230’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’24/04/2017′}
Пробуем добавить его в коллекцию:
dbase.create_user(user_profile)
Выводы в консоль:
{‘username’: ‘ronald44’, ‘name’: ‘Carrie Armstrong’, ‘sex’: ‘F’, ‘address’: ‘0829 Cook Key Apt. 678\nKatherinestad, CA 73382’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’24/08/1998′}
Added New user: ronald44
Как выглядит все в коллекции:
Тут может возникнуть вопрос, что за значение _id? Это уникальный ID, который автоматически создает MongoDB. Можно провести аналогию с Primary Key в MySQL.
Давайте добавим пару случайных пользователей с помощью библиотеки faker и цикла for. Выглядит все так:
Выглядит все так:
for _ in range(3):
user_profile = faker_obj.simple_profile()
user_profile['birthdate'] = user_profile['birthdate'].strftime('%d/%m/%Y')
dbase.create_user(user_profile)Добавили пользователей: xwilliams, kylewilliams и obrowning. Так это выглядит в коллекции:
Чтобы посмотреть полную сводку из коллекции надо будет воспользоваться циклом for. Это связано с тем, что в ответ нам идет объект Cursor:
result = dbase.get_all_users()
for i in result:
print(i)Вывод в консоль:
Get all users
{‘_id’: ObjectId(‘63790f4edc6a4ce30ed44398’), ‘username’: ‘ronald44’, ‘name’: ‘Carrie Armstrong’, ‘sex’: ‘F’, ‘address’: ‘0829 Cook Key Apt. 678\nKatherinestad, CA 73382’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’24/08/1998′}
{‘_id’: ObjectId(‘637910f07d126aae084a4310’), ‘username’: ‘xwilliams’, ‘name’: ‘Erin Simmons’, ‘sex’: ‘F’, ‘address’: ‘PSC 0729, Box 2069\nAPO AP 14417’, ‘mail’: ‘suzanne49@hotmail.
{‘_id’: ObjectId(‘637910f07d126aae084a4311’), ‘username’: ‘kylewilliams’, ‘name’: ‘Jeffrey Miller’, ‘sex’: ‘M’, ‘address’: ‘977 Santos Turnpike Apt. 039\nNew Cynthia, FM 81301’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’16/06/2016′}
{‘_id’: ObjectId(‘637910f07d126aae084a4312’), ‘username’: ‘obrowning’, ‘name’: ‘Amy Thompson’, ‘sex’: ‘F’, ‘address’: ‘041 Leah Locks Suite 280\nReedport, MI 56259’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’25/08/1915′}
 com’, ‘birthdate’: ’05/04/1918′}
com’, ‘birthdate’: ’05/04/1918′}Поиск человека по логину:
print(dbase.find_by_username('username'))Вывод в консоль:
Get user by username
{‘_id’: ObjectId(‘63790f4edc6a4ce30ed44398’), ‘username’: ‘ronald44’, ‘name’: ‘Carrie Armstrong’, ‘sex’: ‘F’, ‘address’: ‘0829 Cook Key Apt. 678\nKatherinestad, CA 73382’, ‘mail’: ‘[email protected]’, ‘birthdate’: ’24/08/1998′}
Теперь изменим пользователю имя на «тест»:
dbase.change_user('ronald44', 'name', 'test')После запуска мы увидим в коллекции следующее:
Заключение
Сегодня мы тестировали СУБД MongoDB — сделали тестовое добавление коллекции и попробовали вносить в базу изменения.
Как вы видите, Mongo очень удобна и гибка, что позволяет легко масштабировать из маленького проекта в большой. Советую вам изучить её более подробно.
Полезные ссылки
Документации библиотеки pymongo: https://pymongo.readthedocs.io/en/stable/
Подробный курс на ютубе: https://www.youtube.com/playlist?list=PL6plRXMq5RABbVCM0dn23PTKO13WcXnbf
баз данных Python 101: что выбрать?
Науку о данных невозможно написать без данных. Ладно, это банально, но это правда! Большую часть времени (если не все) необходимые вам данные хранятся в СУБД (системе управления базами данных) на удаленном сервере или на вашем жестком диске.
Это означает, что вам необходимо взаимодействовать и взаимодействовать с этой СУБД для хранения и извлечения данных, но для взаимодействия с СУБД вам необходимо говорить на ее языке: SQL (язык структурированных запросов). (Примечание: с годами люди сами стали называть базы данных SQL.)
Недавно появился еще один термин: базы данных NoSQL. Если вы только начинаете заниматься наукой о данных или уже некоторое время работаете в этой области, вы, вероятно, слышали как о базах данных SQL, так и о базах данных NoSQL.
Если вы только начинаете заниматься наукой о данных или уже некоторое время работаете в этой области, вы, вероятно, слышали как о базах данных SQL, так и о базах данных NoSQL.
Использование баз данных SQL или NoSQL зависит от ваших данных и целевого приложения. Но, допустим, вы используете Python и уже знаете, какую схему базы данных вы собираетесь использовать. Теперь вопрос в том, какую библиотеку Python вы используете?
В этой статье я расскажу о наиболее известных, используемых и разработанных библиотеках баз данных Python. Мы поговорим о каждой библиотеке и о лучших причинах для использования каждой из них.
The Skinny на SQLSQLZoo — лучший способ попрактиковаться в SQL
Мы используем библиотеки SQL с реляционными базами данных (RDBMS). Реляционные базы данных хранят данные в разных таблицах, и каждая таблица содержит несколько записей. Эти таблицы связаны с помощью одного или нескольких отношений.
SQLite
SQLite изначально была библиотекой на языке C, созданной для реализации небольшого, быстрого, автономного, бессерверного и надежного ядра базы данных SQL. Теперь SQLite встроен в ядро Python, а это значит, что вам не нужно его устанавливать. Вы можете использовать его прямо сейчас. В Python эта библиотека связи с базой данных называется sqlite3.
Теперь SQLite встроен в ядро Python, а это значит, что вам не нужно его устанавливать. Вы можете использовать его прямо сейчас. В Python эта библиотека связи с базой данных называется sqlite3.
Используйте SQLite, когда…
вы новичок, только начинаете изучать базы данных и способы взаимодействия с ними.
вы используете встроенные приложения. Если вашему приложению требуется переносимость, используйте SQLite, потому что SQLite занимает мало места и очень легкий.
ваши данные хранятся в файле на вашем жестком диске. Вы можете использовать SQLite в качестве параллельного решения для клиент-серверной СУБД в целях тестирования.
вам нужно быстрое подключение к вашим данным. Вам не нужно подключаться к серверу, чтобы использовать SQLite, что также означает, что библиотека имеет низкую задержку.
SQLite — не лучший вариант, если параллелизм представляет большую проблему для вашего приложения, поскольку операции записи сериализуются.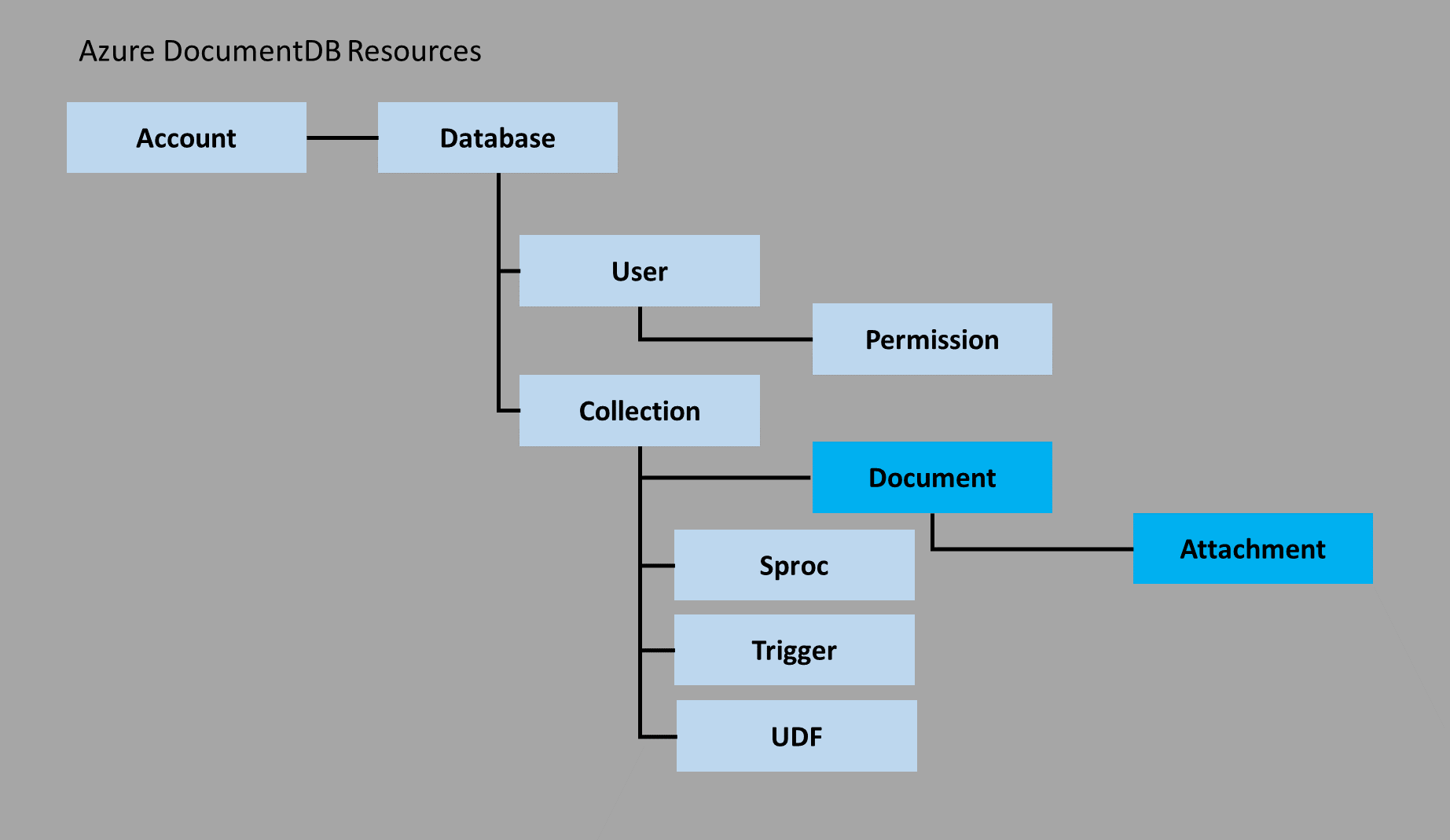 Кроме того, SQLite слаб, когда речь идет о многопользовательских приложениях».
Кроме того, SQLite слаб, когда речь идет о многопользовательских приложениях».
Еще от Sara A. MetwalliКак написать псевдокод
Произошла ошибка.
Невозможно выполнить JavaScript. Попробуйте посмотреть это видео на сайте www.youtube.com или включите JavaScript, если он отключен в вашем браузере.
Базы данных SQLite с Python
MySQL
MySQL является одним из наиболее широко используемых и известных коннекторов СУБД с открытым исходным кодом. Он использует архитектуру сервер/клиент, состоящую из многопоточного SQL-сервера. Это позволяет MySQL работать хорошо, потому что он легко использует несколько процессоров. Первоначально MySQL был написан на C/C++, а затем расширен для поддержки различных платформ. Ключевыми особенностями MySQL являются масштабируемость, безопасность и репликация.
Чтобы использовать MySQL, вам необходимо установить его коннектор. В командной строке вы можете сделать это, запустив:
python -m pip install mysql-connector-python
Используйте MySQL, когда. ..
..
вам нужна дополнительная безопасность. Благодаря преимуществам безопасности MySQL он оптимален для приложений, требующих аутентификации пользователя или пароля.
вам нужна многопользовательская поддержка. В отличие от SQLite, MySQL поддерживает многопользовательские приложения и является хорошим выбором для распределенных систем.
вам нужны расширенные возможности резервного копирования и взаимодействия, но с простым синтаксисом и легкой установкой.
MySQL плохо работает, когда вы выполняете массовые операции INSERT или хотите выполнять операции полнотекстового поиска.
PostgreSQL
PostgreSQL — это еще один соединитель РСУБД с открытым исходным кодом, ориентированный на расширяемость и использующий структуру базы данных клиент/сервер. В PostgresSQL мы называем обмен данными, управляющий файлами и операциями базы данных, «процессом Postgres», откуда библиотека и получила свое название.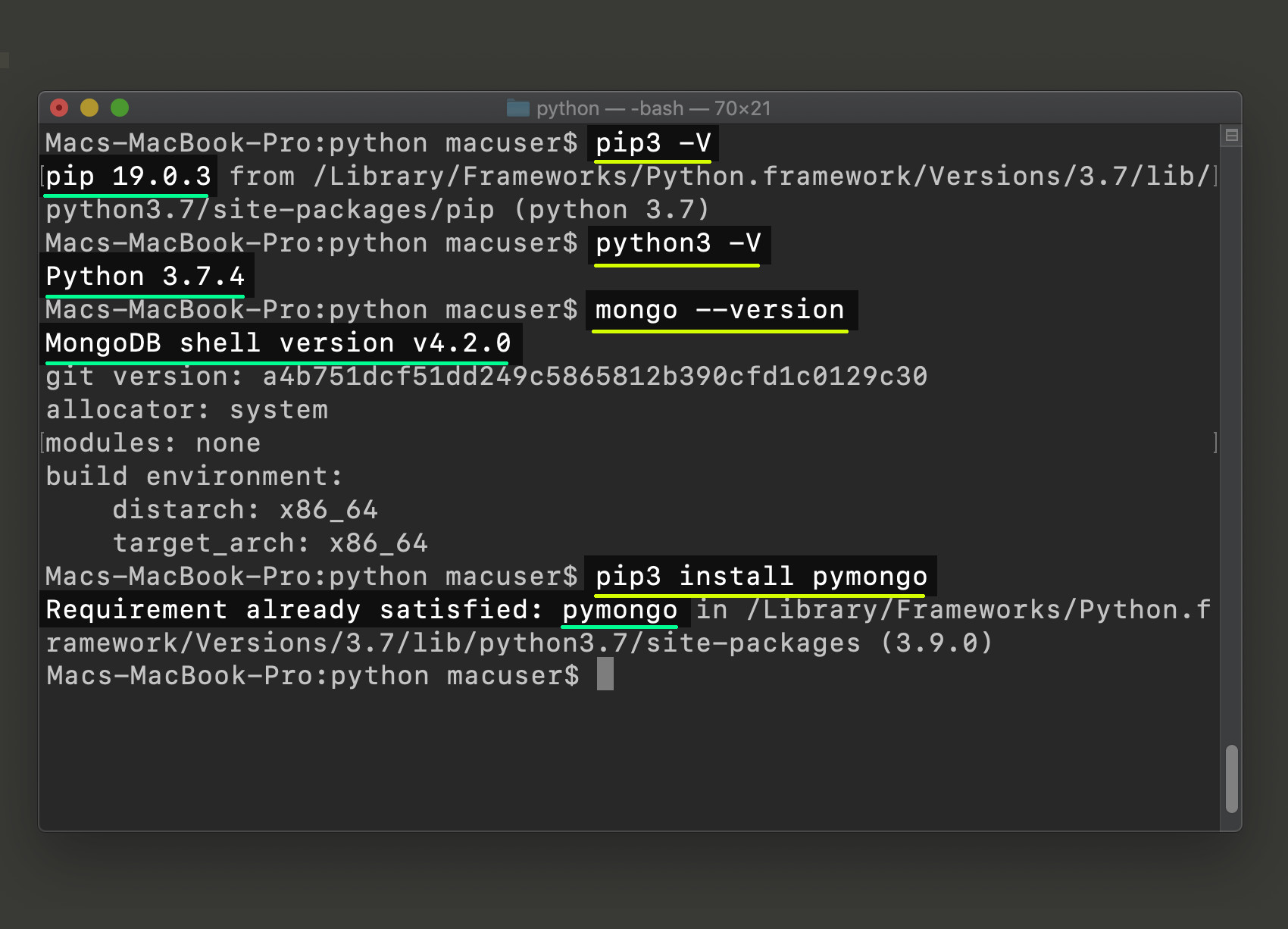
Для связи с базой данных PostgresSQL вам необходимо установить драйвер, который позволяет Python делать это. Одним из часто используемых драйверов является psycopg2. Вы можете установить его, выполнив следующую инструкцию командной строки:
pip install psycopg2
Используйте PostgreSQL, когда…
вы запускаете хранилище данных аналитических приложений. PostgresSQL обладает выдающимися возможностями параллельной обработки.
ваша база данных должна соответствовать модели ACID (A: атомарность; C: согласованность; I: изоляция; D: надежность) (в основном финансовые приложения). В этом случае PostgresSQL предоставляет для этого оптимальную платформу.
вам нужны базы данных исследований и научных проектов.
PostgresSQL немного сложнее установить и начать работу, чем MySQL. Тем не менее, это стоит хлопот, учитывая бесчисленные расширенные функции, которые он предоставляет.
Нужна консультация по приложениям для работы? We Got You.4 Типы проектов, которые вам нужны в вашем портфолио Data Science
Библиотеки Python NoSQL
Библиотеки Python NoSQL
- MongoDB
- Redis
- Cassandra
- Neo4j
Базы данных NoSQL более гибкие, чем реляционные базы данных. В этих типах баз данных структура хранения данных разработана и оптимизирована для конкретных требований. Существует четыре основных типа библиотек NoSQL:
Документо-ориентированные
Пара ключ-значение
Столбчатые
Граф 90 003
MongoDB
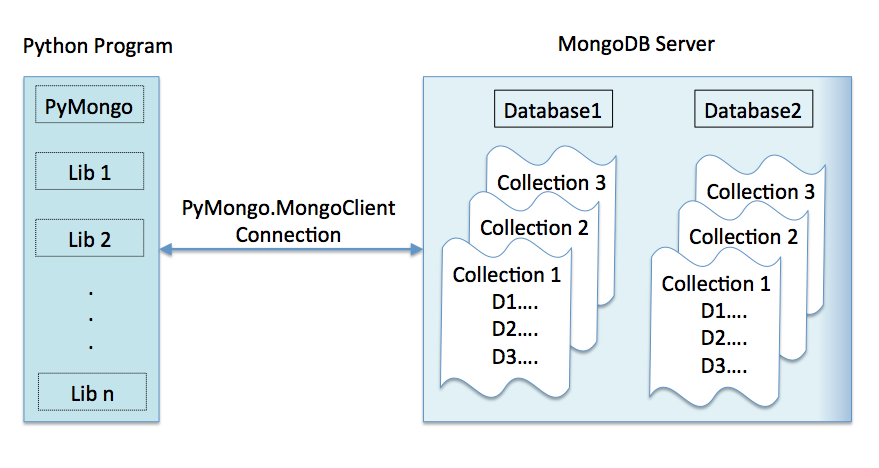
MongoDB — хорошо известное среди современных разработчиков хранилище данных базы данных. Это система хранения данных с открытым исходным кодом, ориентированная на документы. Обычно мы используем PyMongo, чтобы обеспечить взаимодействие между одним или несколькими экземплярами MongoDB через код Python. MongoEngine — это Python ORM, написанный для MongoDB поверх PyMongo.
MongoEngine — это Python ORM, написанный для MongoDB поверх PyMongo.
Чтобы использовать MongoDB, вам необходимо установить механизм и актуальные библиотеки MongoDB.
pip установить пимонго == 3.4.0 pip install mongodb
Использовать MongoDB, когда…
вы хотите создавать легко масштабируемые приложения, которые можно легко развернуть.
ваши данные структурированы в виде документов, но вы хотите использовать возможности реляционных баз данных.
у вас есть приложение с переменными структурами данных, например приложения IoT.
вы работаете с приложениями реального времени, такими как приложения электронной коммерции и системы управления контентом.
Готово3 шага к завершению вашего приложения. Подсказка: начните с конца.
Redis
Redis — это хранилище структур данных в памяти с открытым исходным кодом. Он поддерживает структуры данных, такие как строки, хеш-таблицы, списки, наборы и многое другое. Redis обеспечивает высокую доступность с помощью Redis Sentinel и автоматическое разделение с помощью Redis Cluster. Redis также считается самой быстрой базой данных в мире.
Он поддерживает структуры данных, такие как строки, хеш-таблицы, списки, наборы и многое другое. Redis обеспечивает высокую доступность с помощью Redis Sentinel и автоматическое разделение с помощью Redis Cluster. Redis также считается самой быстрой базой данных в мире.
Вы можете настроить Redis, выполнив следующие инструкции из командной строки:
wget http://download.redis.io/releases/redis-6.0.8.tar.gz смола xzf redis-6.0.8.tar.gz компакт-диск редис-6.0.8 делать
Используйте Redis, когда…
скорость является приоритетом в ваших приложениях.
у вас хорошо спланированный дизайн. Redis имеет много определенных структур данных и дает вам возможность явно указать, как вы хотите, чтобы ваши данные хранились.
ваша база данных имеет стабильный размер. Redis может увеличить скорость поиска конкретной информации в ваших данных.

Cassandra
Apache Cassandra — это хранилище данных NoSQL, ориентированное на столбцы, предназначенное для приложений хранения с большим количеством операций записи. Cassandra обеспечивает масштабируемость и высокую доступность без ущерба для производительности. Cassandra также обеспечивает меньшую задержку для многопользовательских приложений. Cassandra немного сложна в установке и запуске. Однако вы можете сделать это, следуя руководству по установке на официальном сайте Cassandra.
Используйте Cassandra, когда…
у вас есть огромные объемы данных. Cassandra обладает большой гибкостью и мощностью для работы с невероятными объемами данных, поэтому большинство приложений для работы с большими данными — хороший вариант использования Cassandra.
вам нужна надежность. Cassandra обеспечивает стабильную производительность в режиме реального времени для приложений потоковой передачи и онлайн-обучения.
безопасность превыше всего. Cassandra имеет мощное управление безопасностью, что делает ее идеальной для приложений по обнаружению мошенничества.
Neo4j
Neo4j — это графовая база данных NoSQL, созданная с нуля для использования данных и взаимосвязей данных. Neo4j соединяет данные по мере их хранения, позволяя выполнять запросы с высокой скоростью. Первоначально Neo4j был реализован на Java и Scala, а затем расширен для использования на других платформах, таких как Python.
Neo4j, по сути, является библиотекой базы данных графов и имеет один из лучших веб-сайтов и систем технической документации. Он четкий, лаконичный и охватывает все вопросы, которые могут возникнуть у вас по поводу установки, начала работы и использования библиотеки.
Используйте Neo4j, когда…
вам необходимо визуализировать и анализировать сети и их характеристики.
вы разрабатываете и анализируете системы рекомендаций.
вы анализируете связи в социальных сетях и извлекаете информацию на основе существующих связей.
вы собираетесь выполнять операции по управлению идентификацией и доступом.
вам нужно выполнить различные оптимизации цепочки поставок.

Что нужно, чтобы стать специалистом по данным?4 Основные навыки, необходимые каждому специалисту по данным
Выводы
Выбор правильной базы данных для вашей структуры данных и приложения может сократить время разработки вашего приложения при одновременном повышении эффективности твоя работа. Развитие способности выбирать правильный тип базы данных на лету может занять некоторое время, но как только вы это сделаете, большая часть утомительной работы над вашим проектом станет намного проще, быстрее и эффективнее. Единственный способ развить любой навык — это практика. Другой способ исследовать — методом проб и ошибок (обычно мой метод). Пробуйте разные варианты, пока не найдете тот, который лучше всего вам подходит и подходит для вашего приложения.
Единственный способ развить любой навык — это практика. Другой способ исследовать — методом проб и ошибок (обычно мой метод). Пробуйте разные варианты, пока не найдете тот, который лучше всего вам подходит и подходит для вашего приложения.
Хранилища данных NoSQL — Full Stack Python
В реляционных базах данных хранится подавляющее большинство веб-приложений
постоянные данные. Однако существует несколько альтернативных классификаций
представления хранения.
- Пара «ключ-значение»
- Документоориентированный
- Таблица семейства столбцов
- График
Эти представления постоянного хранилища данных обычно используются для расширения,
а не полностью заменить реляционные базы данных. лежащий в основе
тип сохраняемости, используемый базой данных NoSQL, часто дает ей разные
характеристики производительности, чем у реляционной базы данных, с лучшими результатами
на одних типах чтения/записи и худшая производительность на других.
Пара «ключ-значение»
Хранилища данных пар «ключ-значение» основаны
на структурах данных хэш-карты.
Хранилища данных пар «ключ-значение»
Redis — это хранящиеся в памяти парные данные с открытым исходным кодом.
магазин. Redis часто называют «швейцарским армейским ножом веб-приложений».
разработки.» Его можно использовать для кэширования, постановки в очередь и хранения данных сеанса.
для более быстрого доступа, чем традиционная реляционная база данных, среди многих других
случаи использования. Узнайте больше на странице Redis.Memcached — еще один широко используемый in-memory
система хранения пар ключ-значение.
Ресурсы пары «ключ-значение»
- Что такое база данных хранилища «ключ-значение»?
— это вопросы и ответы по переполнению стека, которые прямо отвечают на эту тему.
Ресурсы Redis
Как использовать Redis с Python 3 и redis-py в Ubuntu 16.
04
содержит подробные инструкции по установке и началу использования Redis в Python.«Как установить и использовать Redis»
представляет собой руководство по работе с чрезвычайно полезным хранилищем данных в памяти.Это видео на
Масштабирование Redis в Twitter
подробный взгляд за кулисы массового развертывания Redis.Морж
представляет собой оболочку Python более высокого уровня для Redis с некоторым кэшированием, запросами
и компоненты структуры данных встроены в библиотеку.Реальные советы Redis
предоставляет некоторые рекомендации от инженеров Heroku по развертыванию Redis в
шкала. Советы включают в себя установку явного тайм-аута простоя соединения,
используя пул соединений и избегая использованияКЛЮЧИв пользуСКАН.Написание Redis на Python с помощью Asyncio
показывает подробный пример того, как использовать новую стандартную библиотеку Asyncio в
Python 3. 4+ для работы с Redis.Как собирать метрики Redis
показано, как использовать клиент Redis CLI для получения ключевых показателей задержки.Вам следует пересмотреть настройку максимального количества подключений к Redis.
это ретроспектива серьезного сбоя веб-приложения из-за Redis
максимальное количество подключений на Heroku, и как этого избежать
приложений, изменивнастройки redis.conf.
 04
04 4+ для работы с Redis.
4+ для работы с Redis.Ориентированная на документы
База данных, ориентированная на документы, обеспечивает полуструктурированное представление
вложенные данные.
Документоориентированные хранилища данных
MongoDB — это документно-ориентированная система с открытым исходным кодом.
хранилище данных с форматом хранения Binary Object Notation (BSON), который
JSON-стиль, знакомый веб-разработчикам.
ПиМонго — это
обычно используемый клиент для взаимодействия с одной или несколькими MongoDB
экземпляры через код Python. MongoEngine
это Python ORM, специально написанный для MongoDB, построенный поверх
из ПиМонго.Riak — это распределенное хранилище данных с открытым исходным кодом.
сосредоточены на доступности, отказоустойчивости и крупномасштабных развертываниях.Apache CouchDB также является проектом с открытым исходным кодом.
где основное внимание уделяется использованию HTTP-доступа в стиле RESTful для работы с
сохраненные данные JSON.
 MongoEngine
MongoEngineРесурсы хранилища данных, ориентированные на документы
Создатель и сопровождающие PyMongo пересматривают четыре решения, о которых сожалеют
от создания широко используемого драйвера Python MongoDB.- start_request
- use_greenlets
- копия_базы_данных
- Монгорепликасетклиент
Python и MongoDB
В подкасте Talk Python to Me есть отличное интервью с сопровождающим
Драйвер Python для MongoDB.Запросы MongoDB не всегда возвращают все соответствующие документы!
представляет собой пошаговое руководство по изучению того, как на самом деле работают запросы MongoDB, и
показывает некоторые потенциальные ловушки, связанные с использованием технологий там, где вы
не совсем понимаю, как они работают.Введение в MongoDB и Python
показывает, как использовать Python для взаимодействия с MongoDB через PyMongo и MongoEngine.

Таблица семейства столбцов
Класс таблицы семейства столбцов хранилищ данных NoSQL строится на основе пары «ключ-значение».
парный тип. Каждая пара ключ-значение считается строкой в хранилище, в то время как
семейство столбцов похоже на таблицу в модели реляционной базы данных.
Хранилища данных таблицы семейства столбцов
Апач Кассандра
Апач HBase
Граф
База данных графа представляет и хранит данные в трех аспектах: узлы, ребра
и свойства.
Узел — это сущность, например физическое или юридическое лицо.
Ребро — это связь между двумя объектами. Например,
ребро может представлять, что узел для объекта-человека является сотрудником
бизнес лицо.
Свойство представляет информацию об узлах. Например, сущность
Например, сущность
представляющий лицо, может иметь свойство «женский» или «мужской».
Хранилища графических данных
Neo4j является одним из наиболее широко используемых графических
базы данных и работает в стеке виртуальной машины Java.Cayley — графические данные с открытым исходным кодом.
store, написанный Google, в основном написанный на Go.Titan представляет собой распределенный граф
база данных, построенная для многоузловых кластеров.
Ресурсы хранилища графических данных
Введение в базы данных графов
охватывает тенденции в хранилищах данных NoSQL и сравнивает графические базы данных с другими
типы хранилища данных.Основы алгоритма поиска по графу
объясняет методы поиска узлов для данных в базе данных графа.
Сторонние службы NoSQL
- Compose предоставляет MongoDB как услугу. Его
легко настроить как со стандартным стеком LAMP, так и с Heroku.

Ресурсы хранилища данных NoSQL
- Базы данных
NoSQL: обзор
объясняет, что означает NoSQL, как данные хранятся иначе, чем в
реляционных систем и что такое непротиворечивость, доступность и
Теорема о толерантности к разделению (CAP) означает. Объяснение NoSQL — это хорошо
общий обзор соображений и особенностей при выборе типа
базы данных NoSQL по сравнению с реляционной базой данных.Обзор теоремы CAP
представляет основные ограничения, с которыми должны справляться все базы данных в процессе работы.Серия Теорема CAP
объясняет концепции, связанные с NoSQL, например, что такое ACID по сравнению с CAP, CP
по сравнению с CA и высокой доступностью в крупномасштабных развертываниях.NoSQL Weekly — бесплатная кураторская электронная почта
информационный бюллетень, в котором собраны статьи, учебные пособия и видеоролики о
нереляционные хранилища данных.- Сравнение
NoSQL
представляет собой большой список популярных, основанных на BigTable, специальных и других
хранилища данных с атрибутами и лучшими вариантами использования для каждого из них. В реляционных базах данных, таких как MySQL и PostgreSQL, добавлены функции в
более поздние версии, которые имитируют некоторые возможности данных NoSQL.
магазины. Например, посмотрите этот пост в блоге на
хранение данных JSON в PostgreSQL.

Контрольный список обучения хранилищ данных NoSQL
Поймите, почему хранилища данных NoSQL лучше подходят для некоторых случаев использования, чем
реляционные базы данных. Как правило, эти преимущества видны только на больших
масштабировать, поэтому они могут быть неприменимы к вашему веб-приложению.Интегрируйте Redis в свой проект для повышения скорости по сравнению с более медленным постоянным
хранилище. Хранение данных сеанса в памяти, как правило, намного быстрее, чем
сохранение этих данных в традиционной реляционной базе данных, которая использует постоянный
хранилище. Обратите внимание, что когда память сбрасывается, данные удаляются, поэтому все
которые должны быть постоянными, должны по-прежнему создавать резервные копии на диске на регулярной основе.
