Содержание
Используем rel=nofollow и noindex для Yandex » WPbloging
В апреле, поисковик Yandex, обрадовал рунетовских веб-мастеров, включением поддержки атрибута rel=»nofollow» в ссылках. Какую пользу это нам — блоггерам принесет? Как правильно прописать атрибут rel=»nofollow» в ссылках и что теперь будет с <noindex>?
Давайте попробуем разобраться в этих новинках Яндекса .
Небольшая предыстория атрибута rel=nofollow
Что такое rel=nofollow?
Rel=» « — атрибут в ссылке <a>, указывающий отношение ссылки к целевой странице. Также, есть еще атрибут Rev=» «, указывающий отношение целевой страницы к ссылке, например (ссылка с rev=»sponsor» указывает, что это спонсорская ссылка). Но об этом в следующей статье.
Nofollow — статус, говорящий о том,что вы не одобряете данную ссылку.
Исходя из вышесказанного:
Rel=nofollow — определяет отношение вашей ссылки к целевой странице как не одобряемое. Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Rel=nofollow был введен и стандартизирован в 2005 году, в ответ на многочисленный ссылочный спам, присутствующий в блогах. Инициатором введения была поисковая система Google, источник.
Google, встречая ссылку с данным атрибутом, не следует по данной ссылке и не передает вес PR целевым страницам. Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Но эта статья не о Google, вернемся к Яндексу.
Yandex, до апреля месяца 2010г., не учитывал данный статус. В рекомендациях Яндекса находим нашумевший тег <noindex>, который позволял сделать тоже самое и больше. Теперь там и nofollow.
В чем разница rel=nofollow и <noindex>
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
Все дело в том, что тег <noindex> это личная инициатива Yandex. Данный тег нигде в мире, кроме самого Яндекс, не поддерживается и не стандартизирован. При проверке ресурса на ошибки в коде и поддержке web-стандартов, веб-мастера всегда получали «не валидный» код. То есть, ваш ресурс содержит ошибки. Но, спешу вас успокоить, это не критическая ошибка и практически ни на что не влияет. Для тех кому важен валидный код, вот структура, рекомендованная самим Yandex для валидности вашего кода:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->
Еще одна проблема тега <noindex> в том, что зарубежные веб-мастера, не ведая о данном теге, не используют его в разработках своих плагинов к WordPress. Приходится данные плагины адаптировать под Яндексовскую реальность.
Приходится данные плагины адаптировать под Яндексовскую реальность.
Если в комментариях блога ссылки были закрыты атрибутом rel=»nofollow», то для Яндекса эти ссылки были открыты. Это означало, что роботу приходилось путешествовать по всем ссылкам указанным в комментариях.
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow».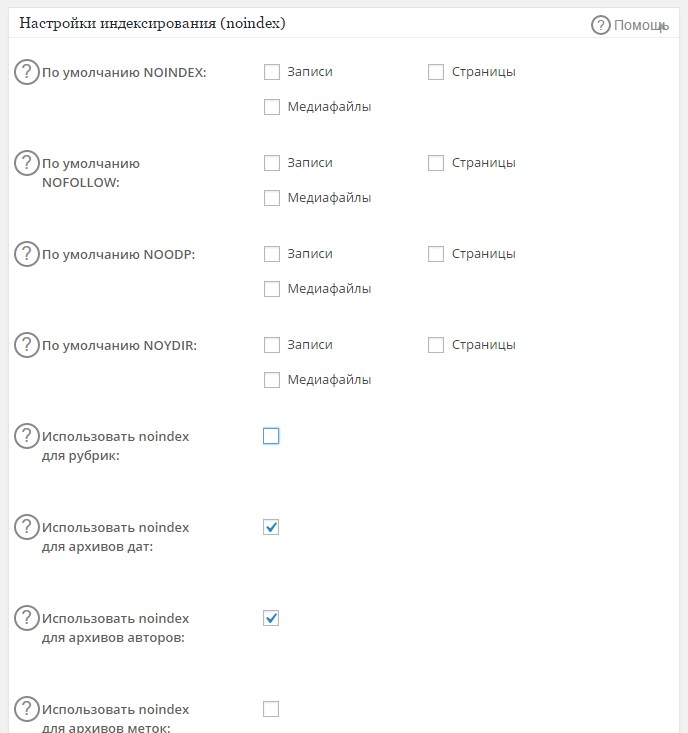 Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Зачем нужен <noindex>?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует. Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент.
Как правильно прописать rel=nofollow и <noindex>
- Для закрытия ссылок от индексации, с помощью rel=»nofollow», используется простая схема:
<a rel=»nofollow» href=»http://www. site.com» title=»Подсказка»>Ссылка на сайт</a>
site.com» title=»Подсказка»>Ссылка на сайт</a>
перехода по ссылке не будет. - Для закрытия блока текста тегом <noindex>, со всем содержимым, в том числе и с анкорами ссылок, используется схема:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->данный текстовый блок не будет проиндексирован в Яндекс, со всеми текстами ссылок. - Для закрытия блока текста тегом и ссылок в блоке, используется схема:
<!--noindex-->Блок вашего закрываемого текста <a rel="nofollow" href="http://www.site.com" title="Подсказка">Текст анкор ссылки</a> Блок вашего закрываемого текста<!--/noindex-->данный блок не будет проиндексирован в Яндекс, со всеми ссылками содержащимся в данном блоке.
 site.com» title=»Подсказка»>Ссылка на сайт</a>
site.com» title=»Подсказка»>Ссылка на сайт</a>Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
 Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».Источник
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.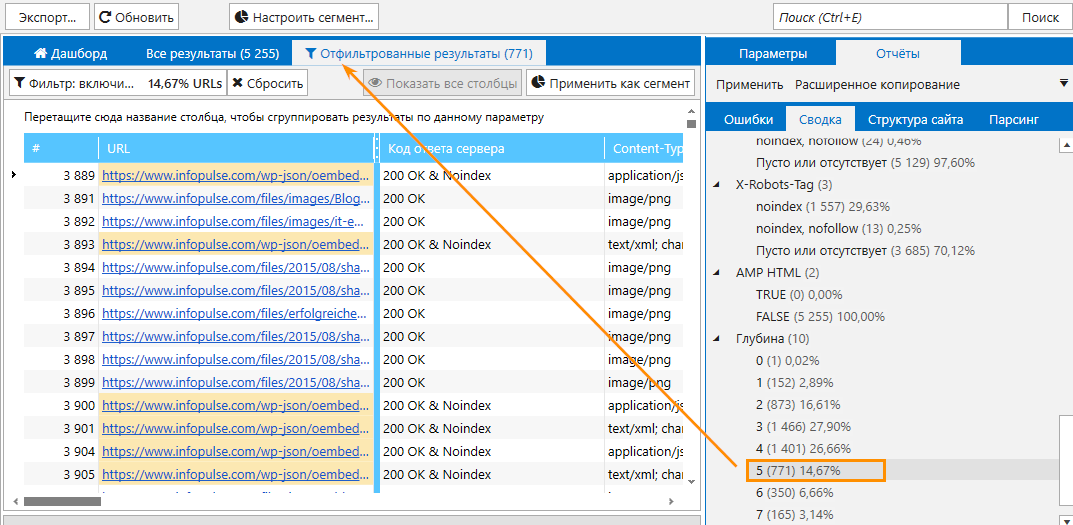
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Нашел ошибку в тексте? Выдели ее мышкой и нажми
Как использовать NOINDEX и NOFOLLOW?
СТАТЬИ → Как использовать NOINDEX и NOFOLLOW?
Общаясь с клиентами и посещая тематические форумы по SEO не редко можно встретить вопрос, как, каким образом и в каких случаях использовать запрет индексации, «NOINDEX» и «NOFOLLOW»?
Прежде чем погрузиться в эту тему полностью уточним синтаксис, как объявляются эти правила.
«NOINDEX» можно объявить как HTML-тег:
<noindex>текст или код, запрещаемый для индексирования</noindex>
Но, написав код именно так, вы получите ошибку валидатора, потому что такой синтаксис не валиден. Если вы стремитесь к валидному коду, следует написать так:
<!-- noindex -->текст или код, запрещаемый для индексирования<!--/ noindex -->
Если вы хотите запретить индексировать всю страницу, можно использовать META-тег:
<meta name="robots" content="noindex"/>
Теперь рассмотрим синтаксис объявления «NOFOLLOW».
«NOFOLLOW» можно объявить как содержимое атрибута REL – (relationship) дословно-отношения. Атрибут указывает на отношение текущего документа к документу, на который ведёт ссылка, указанная в атрибуте «HREF» тега «A»:
<a href=”” rel="nofollow">анкор</a>
или как META-тег:
<meta name="robots" content="nofollow"/>
Как именно использовать эти инструкции, решать вам. А вот разницу давайте рассмотрим вместе.
- <NOINDEX> и REL=»NOFOLLOW»
- Какой смысл у тега «NOINDEX»?
- Как закрыть ссылку? Используем «NOFOLLOW».
- META-теги NOINDEX и NOFOLLOW
- Итого
<NOINDEX> и REL=»NOFOLLOW»
HTML-тег «NOINDEX» запрещает поисковой системе «Яндекс», только «Яндекс» поймёт эту инструкцию, и не будет индексировать выделенную этим тегом часть кода HTML-страницы. Только в Яндексе, потому что в поисковой системе «Google» возможность исключения части страницы не предусмотрена, что и указано в хелпе (помощи) поисковой системы.
Существует заблуждение, что если часть текста или кода страницы выделить тегом «NOINDEX», то Яндекс пропустит этот кусок кода при обходе роботом. Нет, не пропустит. Часть кода будет прочитана роботом и проанализирована поисковой системой, но не будет появляться и учитываться в поисковой выдаче системы. Чтобы лучше понять, почему так, поясним работу поисковых роботов, краулеров. Робот заходит на страницу вашего сайта и начинает её сканировать, читать. В какой-то момент обнаруживается объявление, открытие тега «NOINDEX». Так как страница роботом читается так же, как и людьми, слева направо и сверху вниз, разница в том, что робот читает не видимую часть, а код страницы, то краулер должен увидеть закрытие тега, то есть в какой точке страницы заканчивается отрывок кода, который вы запрещаете для индексации, значит, страница будет прочитана полностью. А значит, всё её содержимое будет известно поисковой системе. В связи с этим можно утверждать, что скрывать тегом «NOFOLLOW» часть неуникального текста – бессмысленно. Поисковая система поймёт и просчитает уникальность текста на вашей странице.
Поисковая система поймёт и просчитает уникальность текста на вашей странице.
Встречается ещё один миф об этом теге. Если в тег «NOINDEX» поместить ссылку, то она не будет проиндексирована, а значит, не будет передавать свой «вес». Будет. Но в поисковую выдачу не попадёт текст, указанный в этой ссылке, сам анкор.
Какой смысл у тега «NOINDEX»?
Возникает резонный вопрос. А для чего нужен тег «NOINDEX»?
Тег «NOINDEX» предназначен для скрытия информации именно в поисковой выдаче, например, текст на странице посвящён описанию какой-либо одной характеристике товара, которая встречается у очень многих позиций вашего интернет-магазина, и вы в качестве примеров приводите описания этих товаров для сравнения и вам не нужно, чтобы в поиске всплывали эти второстепенные описания. Вот в этом случае ненужные подробные описания товаров и заключаются в тег «NOINDEX». Или ещё вариант, если на многих страницах повторяется один и тот же кусок текста. Конечно же, он может попасть в поисковую выдачу на всех этих страницах. Чтобы этого не произошло, используется тег «NOINDEX».
Чтобы этого не произошло, используется тег «NOINDEX».
Как закрыть ссылку? Используем «NOFOLLOW».
С тегом «NOINDEX» разобрались. А для чего нужен «NOFOLLOW»?
Иногда нужно сослаться на информацию на другом интернет-ресурсе, но по каким-то причинам очень не хочется отдавать «вес» своей страницы. Вот в таких случаях и применяется атрибут отношения страницы-донора к акцептору (странице принимающей вес) – «NOFOLLOW».
Содержимое атрибута REL «NOFOLLOW» понимается обоими флагманами поиска, «Яндексом» и «Google». При указании «NOFOLLOW» роботы обойдут, прочитают и проанализируют сами ссылки, содержащиеся анкоры (текстовое содержание ссылки) и страницы, на которые идут ссылки, но вес вашей страницы передан не будет.
Синтаксис использования «NOINDEX» «NOFOLLOW» следующий:
Передаётся вес и индексируется анкор ссылки.
<a href=”http://reg50.ru/”> Поддержка и продвижение сайтов</a>
Вес страницы передаётся, но Яндекс не индексирует текстовое содержимое ссылки, анкор.
<!-- noindex --><a href=”http://reg50.ru/”> Поддержка и продвижение сайтов</a><!--/ noindex -->
Вес страницы не передаётся и Яндекс не индексирует текстовое содержимое ссылки, анкор.
<!-- noindex --><a href=”http://reg50.ru/” rel="nofollow"> Поддержка и продвижение сайтов</a><!--/ noindex -->
META-теги NOINDEX и NOFOLLOW
В начале статьи мы указали, что кроме тега «NOINDEX» и содержимого атрибута REL «NOFOLLOW» (rel=”nofollow”) есть ещё и META-теги с такими же именами. А зачем нужны они, если имеющегося функционала и так достаточно? Для чего используются<meta name="robots" content="noindex"/>
и<meta name="robots" content="nofollow"/>?
META-тег «NOINDEX», как и в случае с HTML-тегом запрещает индексирование только поисковой системе «Яндекс», всей страницы. То есть, в поисковую выдачу не попадёт только текстовая составляющая всей страницы, но страница будет прочтена и проанализирована, ссылки передадут «вес» страницам на которые ссылаются.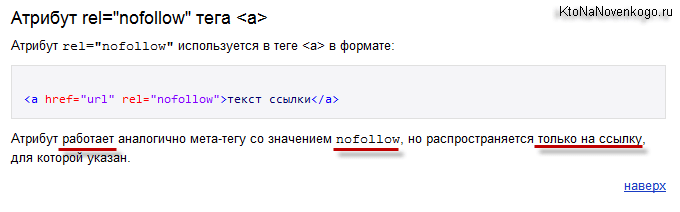
При наличии META-тега «NOFOLLOW» поисковые системы не будут индексировать ссылки, переходить по ним на акцепторы и передачи веса страниц не будет. Но, если на других страницах вашего сайта имеются такие же ссылки и они не закрыты META-тегом или атрибутом, то вес будет передан.
Итого
Теперь подведём итоги об использовании и значении «NOINDEX» и «NOFOLLOW».
Если нам нужно исключить какую-либо информацию из поисковой выдачи, используем «NOINDEX».
Если нам нужно сослаться на источник или материал на нашем сайте, но не нужно передавать вес страницы-донора, используем «NOFOLLOW».
При объявлении этих инструкций не забываем об описанных выше нюансах и принципах обработки этих команд поисковыми системами.
Успешного Вам продвижения!
#оптимизация сайта, #продвижение сайта, #техническая оптимизация
Метатег Robots и HTTP-заголовок X-Robots-Tag
Вы можете указать для роботов правила загрузки и индексации определенных страниц сайта одним из следующих способов:
Поместить метатег robots внутрь элемента head HTML-код страницы.
Настройте HTTP-заголовок X-Robots-Tag для определенного URL-адреса на сервере вашего сайта.

Примечание. Если страница запрещена в файле robots.txt, директива метатега или заголовка не применяется.
По умолчанию поисковые роботы учитывают метатег и заголовок. Вы можете указать директивы для определенных роботов.
- Directives supported by Yandex
- Specifying multiple directives
- Instructions for specific robots
| Directive | Description | Robots meta tag | X-Robots-Tag header |
|---|---|---|---|
| без индекса | Запрещает индексацию текста страницы. Страница не будет включена в результаты поиска. | ||
| nofollow | Запрет перехода по ссылкам на странице. Робот не будет переходить по ссылкам при сканировании сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. Робот не будет переходить по ссылкам при сканировании сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. | ||
| нет | Аналогично директивам noindex и nofollow. | ||
| noarchive | Запрещает показ ссылки на сохраненную копию на странице результатов поиска. | ||
| noyaca | Запрещает использование автоматически сгенерированного описания. | — | |
| Индекс | следовать | архив | Отключает соответствующие запрещающие директивы. | — | |
| все | Позволяет индексировать текст и ссылки на странице, аналогично индексу и следуя директивам. | — |
По умолчанию робот использует директивы allow, поэтому их можно не указывать, если нет других директив. Разрешающие директивы имеют приоритет над запрещающими директивами, если есть комбинация обоих. Пример.
Роботы из других поисковых систем и сервисов могут по-разному интерпретировать директивы.
Пример:
Элемент, отключающий индексацию страницы.
<голова>
<тело>...
HTTP-ответ с заголовком, запрещающим индексирование страницы.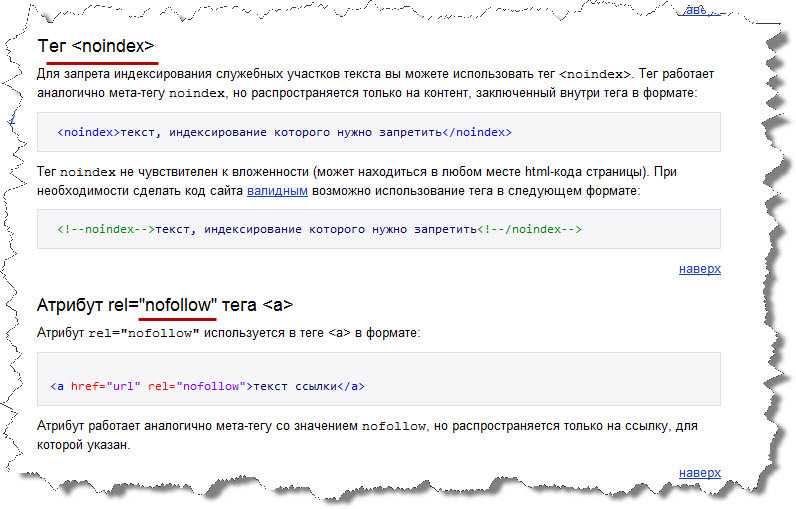
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу X-Robots-Tag: noindex
Вы можете указать несколько директив, разделенных запятыми.
В одном ответе можно передать несколько заголовков и список директив, разделенных запятыми.
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
Если для робота Яндекса указаны противоречивые директивы, он будет считать положительное значение. Пример директив метатега:
С помощью метатега robots можно дать указание только роботам Яндекса. Пример:
Если перечислить общие директивы и директивы для роботов Яндекса, поисковик учтет их все.
Робот Яндекса будет интерпретировать эти директивы как noindex, nofollow .
Если страницы долгое время не появляются в результатах поиска или были исключены из них, укажите в форме примеры таких страниц.
Может ли категория noindex запретить индексацию других страниц на Яндексе?
спросил
Изменено
6 лет, 1 месяц назад
Просмотрено
93 раза
На своем веб-сайте я помещаю noindex на страницы своих категорий, но не на страницы под ним. Несмотря на то, что прошло две недели, единственная проиндексированная страница — это моя домашняя страница, которая не входит ни в одну из категорий.
Несмотря на то, что прошло две недели, единственная проиндексированная страница — это моя домашняя страница, которая не входит ни в одну из категорий.
Когда я смотрю на yandex webmasters, в разделе индексация>статистика>исключенные страницы я вижу как www.example.com/category , так и www.example.com/category/. Интересно, означает ли www.example.com/category/ (косая черта в конце) «Я не индексирую никакие страницы под ним» и www.example.com/category означает, что я не индексирую категорию.
- поисковая-индексация
- noindex
- yandex
- yandex-webmaster-tools
1
страницы индексируются, если:
- их нет
noindex, - у них есть входящие ссылки (внутренние и/или внешние),
- входящие ссылки на них не являются
nofollow. - бот имеет непрерывный путь URL-адреса от точки входа до страницы, которая должна быть проиндексирована, например: URL-адрес входа ссылается на url1 (нет
nofollow) -> url1 ссылается на url2 (нетnofollow) -> url2 ссылки на URL должны быть проиндексирован (нетnofollow) -> URL, который должен быть проиндексирован (
0
Бот не может понять, какой каталог является каталогом, а какой нет, из-за множества конфигураций на стороне сервера, позволяющих использовать конечную косую черту или нет, по желанию веб-мастера.