Содержание
Rel Nofollow и Noindex или Как закрыть внешние ссылки ссылки
Добрый день! Сегодня мы поговорим о том, как закрыть внешние ссылки от индексация. Сегодняшний урок будет написан на эту тему, так как мне на почту, да и в комментариях начали идти вопросы про Noindex и Nofollow.
Для чего нужно закрывать внешние ссылки от индексации
Многие вебмастера (в том числе и опытные “сеошники” (люди, которые занимаются продвижениями сайтов))закрывают от индексации ненужные ссылки (в частности внешние). Все это делается для того, чтобы не передавать вес страницы на другие сайты. Напомню, что каждая страница имеет определенный вес, который распределяется (“отдается”) другим страницам при простановке ссылок.
То есть, если в Вашем посте стоит одна единственная ссылка и ведет она на главную, то вес будет равняться, к примеру, 1. Получается, Вы сами же продвигаете свою главную страницу и увеличиваете ее вес. Поэтому, я Вам настоятельно рекомендую, чтобы у Вас на блоге была грамотная внутренняя перелинковка.
Смотрите: если у Вас в той же статье будет к примеру 2 ссылки, одна из которых ведет на site1.ru, а другая на site2.ru, то в таком случае вес им будет передаваться по 0.5 (это грубое значение, привел Вам пример, чтобы Вы поняли. На самом деле вес ссылки зависит от многих факторов: релевантность, использование ключевых слов, ссылка расположена ближе к началу документа или в конце и т.п.).
Именно поэтому, следует закрыть внешние ссылки, то есть для того, чтобы вес Вашей страницы никуда не “утекал”, а оставался на Вашем же блоге, что сильно поможет Вам при продвижении. Также, если Вас интересует продажа постовых (вернее заработок на нем), то заказчики требуют, чтобы количество внешних ссылок не превышал числа n (обычно они хотят, чтобы на странице было не более 4-7 внешних ссылок). К примеру, если на странице очень многих исходящих внешних ссылок, то вес каждой ссылки будет мизерным, то есть те сайты, которые получили ссылки с этой страницы получат очень маленький (а может даже и отрицательный) эффект.
Если Вы не закрывали внешние ссылки от индексации, настоятельно рекомендую прочесть то, что написано ниже.
Noindex и Nofollow
Nofollow
Самый лучший способ закрытия ссылки от индексации поисковыми системами это использование тега Nofollow. Работать с ним очень просто: всего лишь нужно добавить нужной ссылке, как говорится, rel=”nofollow”. Смотрите пример ниже.
Пример: обычная ссылка в php (в шаблоне темы, к примеру, sidebar.php, indesx.php) имеет следующий вид:
<a href=”https://wpnew.ru”>Текст ссылки</a>
Допустим wpnew.ru (см. выше) – это сайт, на который мы не хотим, чтобы передавался вес нашей страницы. Для этого просто нужно добавить rel=”nofollow”. И окончательная ссылка будет выглядит так:
<a href=”https://wpnew.ru” rel="nofollow">Текст ссылки</a>
Вот и все, нужная нам ссылка закрыта от индексации.
Это был пример того, как закрывать ссылки от индексации в шаблоне. Если Вы пишите статью, и хотите непосредственно в самой статье поставить Nofollow, то Вам в админке WordPress нужно перейти в HTML режим и добавить уже там rel=”nofollow”:
Если Вы пишите статью, и хотите непосредственно в самой статье поставить Nofollow, то Вам в админке WordPress нужно перейти в HTML режим и добавить уже там rel=”nofollow”:
В моем же любимом редакторе для написание постов (Live Writer) все это дело еще проще. Когда ставлю ссылку, я выбираю «Элемент записи” – nofollow и rel=”nofollow” автоматически присваивается данной ссылке:
Таким же образом Вы можете закрыть от индексации всякие счетчики от LiveInternet (даже если ссылка идет в виде картинки) и т.п.:
Noindex
Тег Noidex был придуман Яндексом. Яндекс раньше “не понимал” rel=”nofollow”, и все вебмастера, чтобы закрыть ссылку от индексации для Яндекса, использовали noindex. Но после того, как Яндекс стал учитывать nofollow (мы все благодарны ему за это 🙂 ), популярность noindex резко упала. Сейчас он очень редко применяется. Я обычно ставлю noindex в местах, где выводится реклама через скрипты и т. п.
п.
Использование Noindex.
Тег Noindex нужно использовать немного по-другому. Он закрывает от индексации (напомню, закрывает только (!) для Яндекса) не конкретную ссылку, а определенный участок. Приведу тот же пример.
<a href=”https://wpnew.ru">Текст ссылки</a>
А вот с noindex от Яндекса:
<noindex><a href=”https://wpnew.ru">Текст ссылки</a></noindex>
Вот пример того, где я использую noindex (на примере кода для вывода баннера от Rotaban):
Учтите, что тег noindex нужно ставить правильно. Если он стоит, например, ПЕРЕД <div> (начало какого-нибудь стиля), от он должен стоять после конца этого “стиля”, то есть после </div>.
Проверка
Чтобы узнать, все ли ненужные ссылки у Вас закрыты в nofollow, Вы можете использовать SEObar для Opera. А также рекомендую проверить свой блог с помощью http://be1. ru/stat/. Там показано количество исходящих внешних ссылок, а те ссылки, которые взяты в nofollow отмечены красным восклицательным знаком. Таким образом, Вы сможете найти ссылки, которые не закрыты с помощью rel=”nofollow”. Также данный сервис покажет ошибки при использовании noindex.
ru/stat/. Там показано количество исходящих внешних ссылок, а те ссылки, которые взяты в nofollow отмечены красным восклицательным знаком. Таким образом, Вы сможете найти ссылки, которые не закрыты с помощью rel=”nofollow”. Также данный сервис покажет ошибки при использовании noindex.
Думаю, на сегодня все. Будут вопросы, задавайте в комментариях. До скорой встречи, друзья!
Вы хотите купить перила? Ознакомьтесь с ценами на перила в Украине на http://metkov.com.ua — они вас приятно удивят.
Теги nofollow noindex — оптимизация ссылок и текста
Главная Статьи Оптимизация Многие оптимизаторы знают, что показатели ТИЦ и PR зависят в первую очередь от количества и качества ссылок на сайт. Но если ваш ресурс ссылается на другие, особенно не подходящие по тематике, то его вес падает. В этой статье будет рассказано, как правильно закрыть ненужные внешние ссылки и текст от индексации с помощью тегов nofollow noindex. NoindexТег noindex используется, чтобы запретить индексацию какой-то определенной части текста. Noindex запрещает индексацию части кода, находящуюся между открывающим и закрывающим тегами. Вот пример:
Естественно, его не стоит путать с мета-тегом ноиндекс, который прописывается вначале страницы, они имеют различные задачи. Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены. Валидный noindexНекоторые HTML-редакторы noindex не воспринимают, поскольку он не является валидным. К примеру, в WordPress визуальный редактор его попросту удаляет.
Если в HTML-редакторе прописать тег в такой форме, то он будет абсолютно валиден и можно не бояться, что он исчезнет. Тег noindex воспринимает только поисковый бот Яндекса, робот Гугла на него абсолютно не реагирует. Некоторые оптимизаторы допускают ошибку, когда советуют закрыть все ссылки такими тегами noindex и nofollow, но об этом будет рассказано ниже. Что касается работы тега ноиндекс, то она безотказна. Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается. А это все потому, что Yandex изначально индексирует полностью весь html-код страницы, даже находящийся внутри noindex, но затем происходит фильтрация. Поэтому вначале действительно проиндексирована вся страница, но через некоторое время html-код срабатывает и тест, заключенный в этот тег «вылетает» из индексации. Можно даже не соблюдать вложенность тега noindex – он все равно сработает (об этом рассказывается в справочной Яндекса). Не забывайте, используя, открывающий <noindex> в конце исключаемого текста поставить закрывающий </noindex>, а то весь текст, идущий после тега не проиндексируется. NofollowАтрибут rel=»nofollow» имеет задачу закрывать от поисковиков ссылки, расположенные в тексте. Он используется оптимизаторами для исключения передачи веса со ссылающегося ресурса на ссылаемый. Яндексу об этом атрибуте прекрасно известно. Необходимо знать, что nofollow вес на странице не сохраняет – если ссылка заключена в этот тег. Вес ресурса по ней не переходит, а наоборот «сгорает» или при присутствии на странице других не закрытых атрибутом ссылок, вес будет распределяться между ними. И если на странице сайта присутствует хотя бы одна внешняя активная ссылка, то вес страницы будет уходить. Даже если вы закроете все внешние ссылки атрибутом nofollow – то вес все равно сохранен не будет – он «сгорит». Основным отличием между nofollow и noindex является то, что нофоллоу – атрибут для тега <a>, который запрещает передачу веса по ссылке, а ноиндекс – это тег, который закрывает от индексации нужный вам текст. Вот пример использования атрибута nofollow:
Естественно, в ссылках, которые ведут на внутренние странички блога атрибут nofollow ставить бессмысленно, хотя бывают исключения. В тех случаях, когда вес со страницы нужно передать по выбранным внутренним ссылкам, все остальные можно закрыть. Пример совместного использования nofollow и noindexПрекрасно себя чувствуют оба тега nofollow и noindex, когда они находятся в непосредственной близости. Вот пример их использования:
Оформление ссылки, таким образом, поможет вам удержать вес страницы и к тому же поисковый бот Яндекса анкор не увидит.
Автор: stingervx888
|
Разделы статей
Новости
Объявления
Популярные статьи
|
 Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс.
Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс. Но валидность тегу все же придать можно:
Но валидность тегу все же придать можно:
 Поэтому все внешние ссылки закрывать не имеет смысла.
Поэтому все внешние ссылки закрывать не имеет смысла. В заключении нужно сказать, что не нужно закрывать тегом ноиндекс ссылки, таким образом, вы запрещаете индексацию только анкора, но не самой ссылки. Для нее будет достаточно одного атрибута нофоллоу.
В заключении нужно сказать, что не нужно закрывать тегом ноиндекс ссылки, таким образом, вы запрещаете индексацию только анкора, но не самой ссылки. Для нее будет достаточно одного атрибута нофоллоу.Основы тега Noindex — все, что вам нужно знать
Тег noindex используется для предотвращения индексации данной страницы поисковыми системами.
Вы можете подумать, что все страницы вашего сайта должны быть проиндексированы, но это не так. На самом деле, p предотвращение появления определенных страниц в результатах поиска является неотъемлемой частью вашей стратегии индексации.
Что такое тег noindex?
Тег noindex — это HTML-тег, используемый для управления тем, как боты обрабатывают определенную страницу или файл на вашем сайте, и запрещает им индексировать эту страницу или файл.
Вы можете указать поисковым системам не индексировать страницу , добавив директиву noindex в метатег robots — просто добавьте следующий код в раздел
HTML:В качестве альтернативы, тег noindex может быть добавлен как x-robots-tag в HTTP-заголовок :
x-robots-tag: noindex
Когда бот поисковой системы, такой как Googlebot, сканирует страницу с тегом noindex он не будет его индексировать. Если страница ранее была проиндексирована, а тег был добавлен позже, Google удалит ее из результатов поиска, даже если на нее ссылаются другие сайты.
Если страница ранее была проиндексирована, а тег был добавлен позже, Google удалит ее из результатов поиска, даже если на нее ссылаются другие сайты.
Как правило, сканеры поисковых систем не обязаны следовать метадирективам , поскольку они служат скорее предложениями, чем правилами, которые они должны соблюдать. Некоторые сканеры поисковых систем могут по-разному интерпретировать мета-значения роботов.
Однако большинство сканеров поисковых систем, таких как Googlebot, подчиняются директиве noindex.
Noindex vs nofollow
Существуют и другие директивы мета-роботов, которые поддерживает Google — самые популярные из них включают nofollow и follow. Однако тег Follow является настройкой по умолчанию, если метатеги robots не добавлены, поэтому Google считает его ненужным.
Тег nofollow не позволяет поисковым системам сканировать ссылки на странице. В результате ранжирующие сигналы этой страницы не будут передаваться страницам, на которые она ссылается.
Директиву noindex можно использовать отдельно, но ее также можно комбинировать с другими директивами. Например, вы можете добавить тег noindex и nofollow , если вы не хотите, чтобы роботы поисковых систем индексировали страницу и переходили по ссылкам на ней.
Если вы внедрили тег noindex, но ваша страница по-прежнему отображается в результатах поиска, вероятно, Google просто не сканировал страницу с момента добавления тега. Чтобы запросить у Google повторное сканирование страницы, вы можете использовать инструмент проверки URL.
Когда следует использовать тег noindex?
Вы должны использовать тег noindex, чтобы Google не индексировал страницы.
Запрещение индексации менее важных страниц имеет решающее значение, поскольку у Google недостаточно ресурсов для сканирования и индексации каждой страницы, которую он находит в Интернете. В то же время вам необходимо определить свои ценные страницы, которые следует проиндексировать, и расставить приоритеты в их оптимизации.
Давайте посмотрим, на какие типы страниц следует добавить тег noindex, чтобы сделать их неиндексируемыми.
Поместите тег noindex на:
- Страницы для товаров, которых нет в наличии и которые больше не будут доступны.
- Страницы, которые не должны быть доступны в результатах поиска, например, промежуточные среды или защищенные паролем страницы.
- Страницы, ценные для поисковых систем, но не для пользователей, например страницы, содержащие ссылки, которые помогают ботам находить другие страницы.
- Страницы с дублирующимся содержимым, которые часто преобладают на веб-сайтах электронной коммерции. Также рекомендуется использовать канонические теги, чтобы указать поисковым системам на основные версии ваших страниц и предотвратить дублирование контента.
Консоль поиска Google уведомила вас о проблемах с индексацией из-за дублирования контента? Прочтите наши руководства и исправьте:
- статус «Дубликат, Google выбрал другой канонический, чем пользовательский»,
- статус «Дублировать без выбранного пользователем канонического».


Запрещение индексации страниц должно быть частью хорошо зарекомендовавшей себя стратегии индексации.
Никогда не добавляйте noindex на ценные страницы, например:
- Самые популярные страницы продуктов,
- Статьи блога (если они не устарели),
- Страницы обо мне и контакты,
- Страницы с описанием предлагаемых вами услуг.
Как правило, никогда не размещайте noindex на страницах, которые, как вы ожидаете, будут генерировать значительный органический трафик.
Ваша страница «исключена тегом noindex» в Google Search Console?
Прочтите нашу статью о том, как решить эту проблему, чтобы раскрыть свой потенциал индексации.
Как реализовать тег noindex
Тег noindex можно поместить в HTML-код сайта или в заголовки ответа HTTP.
Некоторые плагины CMS, такие как Yoast, позволяют автоматически не индексировать публикуемые вами страницы.
Давайте шаг за шагом рассмотрим два основных метода реализации и проанализируем их плюсы и минусы.
Вставка тега noindex в HTML-код страницы
Тег noindex может быть реализован как метатег robots в HTML-кода страницы.
Метатеги роботов — это коды, используемые для управления сканированием и индексированием веб-сайта. Пользователи их не видят, но боты находят их при сканировании страницы.
Вот как реализовать код:
<голова> <тело>
Давайте поясним, как устроен метатег robots.
Внутри метатега есть пары атрибутов и значений:
Метатег Robots имеет два атрибута:
- имя — указывает имя бота поисковой системы,
- content — содержит директивы для ботов.
Для обоих атрибутов требуются разные значения в зависимости от того, что вы хотите, чтобы боты делали. Кроме того, атрибуты name и content не чувствительны к регистру.
Атрибут имени обычно принимает значение «роботы», , указывая, что директива нацелена на всех ботов.
Вместо этого также можно использовать имя определенного бота, например, «googlebot», хотя такое встречается гораздо реже. Если вы хотите обращаться к разным ботам, вам нужно будет создать отдельные метатеги для каждого из них.
Имейте в виду, что поисковых систем имеют разные краулеры для разных целей – ознакомьтесь со списком краулеров Google.
Между тем, атрибут содержимого содержит директиву для ботов. В нашем случае это «noindex». Вы можете поместить туда более одного значения и разделить атрибуты запятыми.
Плюсы и минусы метатегов robots
Метод HTML легче реализовать и изменить, чем метод заголовка HTTP. Это также не требует, чтобы у вас был доступ к вашему серверу.
Однако реализация тега noindex в вашем HTML может занять много времени — вам придется добавлять его вручную на каждую страницу, которую вы хотите запретить индексировать.
Добавить тег noindex в заголовки HTTP
Другим решением является указание директивы noindex в теге x-robots.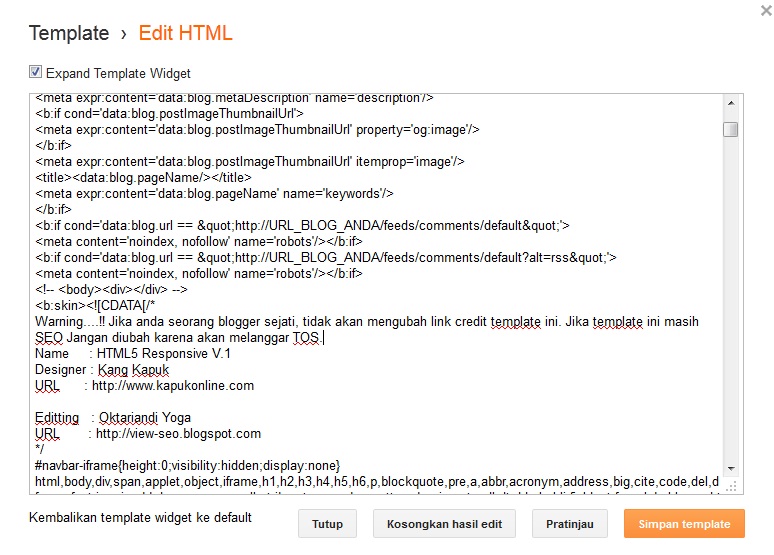
Это элемент ответа заголовка HTTP. Заголовки HTTP используются для связи между сервером и клиентом (браузером или ботом поисковой системы).
Вы можете настроить его на веб-сервере HTTP. Код будет выглядеть немного по-разному в зависимости от того, какой сервер вы используете — например, Apache, Nginx или другие.
Вот пример того, как может выглядеть ответ HTTP с тегом x-robots:
HTTP/1.1 200 OK (…) тег x-роботов: noindex (…)
Сервер Apache
Если у вас есть сервер на основе Apache и вы хотите не индексировать все файлы, которые заканчиваются на «.pdf», вы должны добавить директиву к файлу .htaccess .
Вот пример кода:
<Файлы ~ "\.pdf$"> В заголовке установлен x-robots-tag "noindex"
Сервер Nginx
Если у вас есть сервер на основе Nginx , внедрите директиву в файл .conf :
location ~* \.pdf$ {
add_header x-robots-tag "noindex";
} Плюсы и минусы использования HTTP-заголовков
Одним из существенных преимуществ использования noindex в HTTP-заголовках является то, что вы можете использовать его в веб-документах, которые не являются HTML-страницами , например в файлах PDF, видео или изображениях. Кроме того, этот метод позволяет настроить таргетинг на определенную часть страницы.
Кроме того, этот метод позволяет настроить таргетинг на определенную часть страницы.
Кроме того, тег x-robots поддерживает использование регулярных выражений (RegEx). Другими словами, вы можете настроить таргетинг на страницы, которые не должны индексироваться, указав, что у них общего. Например, вы можете настроить таргетинг на страницы с URL-адресами, которые содержат определенные параметры или символы.
С другой стороны, вам нужен доступ к вашему серверу для реализации тега x-robots.
Добавление тега также требует технических навыков и является более сложным, чем добавление метатегов robots в HTML-код веб-сайта.
Как проверить реализацию тега noindex?
Если вы хотите проверить, реализованы ли noindex или другие метадирективы robots, вы можете сделать это в зависимости от того, как они были добавлены на страницу.
Таким образом, если тег noindex был добавлен в HTML-код страницы, вы можете проверить ее исходный код, а для заголовков HTTP вы можете использовать параметр Inspect в Chrome . Эти инструменты покажут вам, какие директивы были распознаны на данной странице.
Эти инструменты покажут вам, какие директивы были распознаны на данной странице.
Другие варианты включают ввод URL-адреса в инструмент проверки URL-адресов Google Search Console или использование расширения Link Redirect Trace.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем с индексацией.
- Наслаждайтесь своим контентом в индексе Google!
Все еще не уверены, стоит ли писать нам? Узнайте, как услуги технического SEO могут помочь вам улучшить ваш сайт.
Дополнительная информация об использовании тега noindex
Вот некоторые дополнительные рекомендации по использованию тега noindex и подробности о его характеристиках:
- Всякий раз, когда вы не включаете noindex в свой код, параметр по умолчанию — это то, что боты могут индексировать вашу страницу .
- Следите за любыми ошибками в коде, такими как запятые в нужных местах — боты не поймут ваши команды, если синтаксис неправильный.
- Добавьте теги в код HTML или заголовки ответа HTTP, но не в оба вместе. Это может иметь преимущественно негативные последствия, если директивы в соответствующих местах противоречат друг другу. В этом случае Робот Google выберет директиву, ограничивающую индексацию.
- Вы можете использовать директиву noimageindex, которая будет работать аналогично noindex, но только предотвратит индексацию изображений на данной странице.
- Через некоторое время боты начинают рассматривать noindex как nofollow. Многие люди отключают индексирование страниц с помощью noindex, но комбинируют его с директивой follow, чтобы роботы по-прежнему сканировали ссылки на странице. Но Google объяснил , что директива noindex, follow в конечном итоге будет рассматриваться как noindex, nofollow 9.0008, потому что в какой-то момент они перестают сканировать ссылки на непроиндексированных страницах. В результате страницы назначения ссылок могут не индексироваться и получать сигналы пониженного ранжирования, что может негативно сказаться на их ранжировании.
- Не используйте noindex в файлах robots.txt. Хотя это и некоторые другие правила официально не поддерживались, поисковые роботы следовали директивам noindex в файлах robots.txt. Однако в сентябре 2019 года Google объявил об удалении кода, который обрабатывал неподдерживаемые и неопубликованные правила в файлах robots.txt, таких как noindex, в сентябре 2019 года..


Сравнение тегов noindex, файлов robots.txt и канонических тегов
тегов noindex, файлов robots.txt и канонических тегов связаны — они могут использоваться для управления сканированием и/или индексированием страницы .
Однако у них есть некоторые отличительные характеристики, которые делают их пригодными для использования в различных ситуациях.
Мы установили, что теги noindex определяют, следует ли индексировать определенные страницы веб-сайта, и они действуют на уровне страниц.
Давайте посмотрим, как это соотносится с файлами robots. txt и каноническими тегами.
txt и каноническими тегами.
Файлы Robots.txt
Файлы Robots.txt могут использоваться для управления тем, как роботы поисковых систем сканируют части вашего веб-сайта на уровне каталогов.
В частности, файлы robots.txt содержат директивы для ботов поисковых систем, в которых основное внимание уделяется либо «запрещению», либо «разрешению» их поведения. Если боты будут следовать директиве, они не будут сканировать запрещенные страницы, и страницы не будут проиндексированы.
Директивы robots.txt широко используются для экономии краулингового бюджета веб-сайта.
Будьте осторожны при реализации тегов noindex и настройке правил в файлах robots.txt. Чтобы директива noindex была эффективной, данная страница должна быть доступна для сканирования, а это означает, что она не может быть заблокирована файлом robots.txt.
Ваша страница заблокирована файлом robots.txt в Google Search Console?
Прочтите нашу статью, чтобы узнать, как решить эту проблему и раскрыть свой потенциал сканирования.
Если сканер не может получить доступ к странице, он не увидит тег noindex и не будет его учитывать. Затем страницу можно просканировать и она появится в результатах поиска, например, если на нее ссылаются другие страницы.
Чтобы запретить индексацию страницы, разрешите ее сканирование в файле robots.txt и используйте метатег noindex , чтобы заблокировать ее индексацию — тогда Googlebot будет следовать директиве noindex.
Канонические теги
Канонические теги — это элементы HTML, которые сообщают поисковым системам, какая страница из нескольких похожих является основной версией и должна быть проиндексирована. Они размещаются на второстепенных страницах и указывают канонический URL — в результате эти второстепенные страницы не должны включаться в индекс.
Канонические теги могут ограничивать индексирование неканонических страниц, но Google не всегда будет учитывать эти теги . Например, если Google находит больше ссылок на другую страницу, он может рассматривать ее как более важную, чем указанный канонический URL-адрес, и считать ее основной версией.
Кроме того, канонические теги могут быть обнаружены ботами только во время сканирования. В отличие от файлов robots.txt, их нельзя использовать для остановки сканирования страницы.
Существенное различие между каноническими тегами и тегами без индекса заключается в том, что канонизированных страниц объединяют сигналы ранжирования под одним URL-адресом. Между тем, непроиндексированных страниц не будут передавать сигналы ранжирования , что очень важно для внутренних ссылок — они не будут передавать сигналы ранжирования URL-адресам, на которые они ссылаются.
Подведение итогов
Запрещение индексации низкокачественных страниц — один из лучших методов SEO для оптимизации вашей стратегии индексации, а использование метатега noindex — один из наиболее оптимальных способов не допустить попадания страницы в индекс Google .
Используя этот тег, вы можете заблокировать индексацию неважных страниц и впоследствии помочь роботам поисковых систем сфокусироваться на наиболее ценном контенте.
Это делает тег noindex одним из важнейших инструментов SEO, и именно поэтому мы проверяем все ваши теги noindex в рамках наших технических услуг SEO.
Эффективное сканирование и индексация вашего веб-сайта являются ключом к максимальному использованию органического трафика, который ценные страницы могут привести на ваш сайт. Чтобы узнать больше о процессе индексации, обязательно прочитайте наше руководство по индексации SEO дальше!
Что это такое и как им пользоваться?
Главная / Блог Lumar / Передовой опыт / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексирования для улучшения поисковой оптимизации. Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и контент-менеджер
Давайте делиться
| 9 минут чтения
Три приведенных выше слова могут звучать как SEO-тарабарщина, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Googlebot. Что весело.
Итак, давайте начнем с основ: есть три способа сообщить, какие части вашего сайта поисковые системы должны сканировать и индексировать:
- Noindex : сообщает поисковым системам, чтобы они не включали ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : указывает поисковым системам не сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : сообщает поисковым системам не переходить по ссылкам на вашей странице.
Что такое метатег
noindex ?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — добавить тег в раздел заголовка HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть содержимого тег здесь указывает, что все ссылки на этой странице должны быть пройдены, что мы обсудим ниже.
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ?
Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц. Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Disallow: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Завершите правило символом /, чтобы это вступило в силу:
Disallow: /directory/
Агент пользователя должен быть указан где-то над этой строкой. Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Агент пользователя: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не должны сочетаться с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.
Что такое тег nofollow?
Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форуме, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
Nofollow не препятствует полному сканированию связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, где спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, который использовался ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование. Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые нужно знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса, — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли отдавать приоритет правильной версии для каждой аудитории. Все эти версии останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования. Хотя общепринятой практикой является запрет и неиндексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью Lumar
Отчет о неиндексируемых страницах содержит сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
Этот отчет покажет вам все страницы, которые содержат тег noindex в метаинформации, заголовке HTTP или файле robots.txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots.txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по поисковой оптимизации
Мы надеемся, что этот пост был полезен для вас, чтобы узнать больше о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.