Содержание
Теги nofollow noindex — оптимизация ссылок и текста
Главная Статьи Оптимизация Многие оптимизаторы знают, что показатели ТИЦ и PR зависят в первую очередь от количества и качества ссылок на сайт. Но если ваш ресурс ссылается на другие, особенно не подходящие по тематике, то его вес падает. В этой статье будет рассказано, как правильно закрыть ненужные внешние ссылки и текст от индексации с помощью тегов nofollow noindex. NoindexТег noindex используется, чтобы запретить индексацию какой-то определенной части текста. Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс. Noindex запрещает индексацию части кода, находящуюся между открывающим и закрывающим тегами. Вот пример:
Естественно, его не стоит путать с мета-тегом ноиндекс, который прописывается вначале страницы, они имеют различные задачи. Валидный noindexНекоторые HTML-редакторы noindex не воспринимают, поскольку он не является валидным. К примеру, в WordPress визуальный редактор его попросту удаляет. Но валидность тегу все же придать можно:
Если в HTML-редакторе прописать тег в такой форме, то он будет абсолютно валиден и можно не бояться, что он исчезнет. Тег noindex воспринимает только поисковый бот Яндекса, робот Гугла на него абсолютно не реагирует. Некоторые оптимизаторы допускают ошибку, когда советуют закрыть все ссылки такими тегами noindex и nofollow, но об этом будет рассказано ниже. Что касается работы тега ноиндекс, то она безотказна. А это все потому, что Yandex изначально индексирует полностью весь html-код страницы, даже находящийся внутри noindex, но затем происходит фильтрация. Поэтому вначале действительно проиндексирована вся страница, но через некоторое время html-код срабатывает и тест, заключенный в этот тег «вылетает» из индексации. Можно даже не соблюдать вложенность тега noindex – он все равно сработает (об этом рассказывается в справочной Яндекса). Не забывайте, используя, открывающий <noindex> в конце исключаемого текста поставить закрывающий </noindex>, а то весь текст, идущий после тега не проиндексируется. NofollowАтрибут rel=»nofollow» имеет задачу закрывать от поисковиков ссылки, расположенные в тексте. Он используется оптимизаторами для исключения передачи веса со ссылающегося ресурса на ссылаемый. Необходимо знать, что nofollow вес на странице не сохраняет – если ссылка заключена в этот тег. Вес ресурса по ней не переходит, а наоборот «сгорает» или при присутствии на странице других не закрытых атрибутом ссылок, вес будет распределяться между ними. И если на странице сайта присутствует хотя бы одна внешняя активная ссылка, то вес страницы будет уходить. Даже если вы закроете все внешние ссылки атрибутом nofollow – то вес все равно сохранен не будет – он «сгорит». Поэтому все внешние ссылки закрывать не имеет смысла. Основным отличием между nofollow и noindex является то, что нофоллоу – атрибут для тега <a>, который запрещает передачу веса по ссылке, а ноиндекс – это тег, который закрывает от индексации нужный вам текст. Вот пример использования атрибута nofollow:
Естественно, в ссылках, которые ведут на внутренние странички блога атрибут nofollow ставить бессмысленно, хотя бывают исключения. Пример совместного использования nofollow и noindexПрекрасно себя чувствуют оба тега nofollow и noindex, когда они находятся в непосредственной близости. Вот пример их использования:
Оформление ссылки, таким образом, поможет вам удержать вес страницы и к тому же поисковый бот Яндекса анкор не увидит. В заключении нужно сказать, что не нужно закрывать тегом ноиндекс ссылки, таким образом, вы запрещаете индексацию только анкора, но не самой ссылки. Для нее будет достаточно одного атрибута нофоллоу.
Автор: stingervx888
|
Разделы статей
Новости
Популярные статьи
|
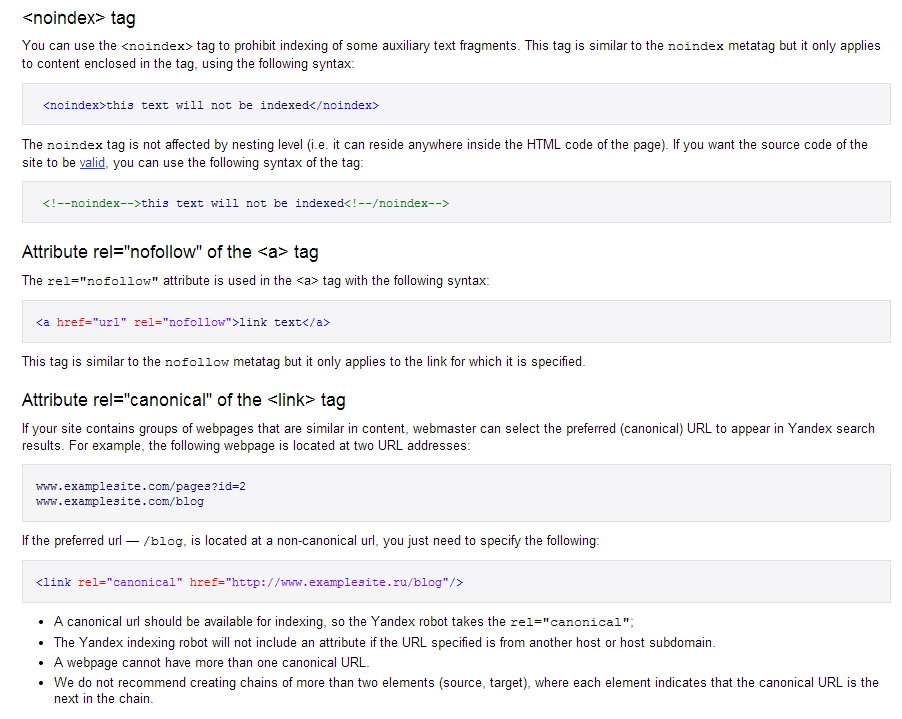
 Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены.
Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены.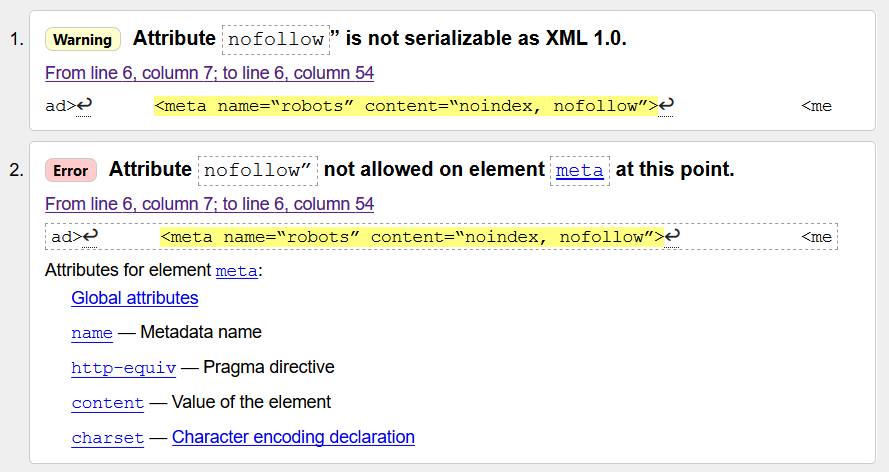 Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается.
Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается.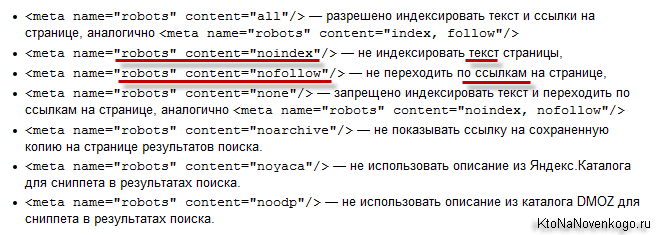 Яндексу об этом атрибуте прекрасно известно.
Яндексу об этом атрибуте прекрасно известно. В тех случаях, когда вес со страницы нужно передать по выбранным внутренним ссылкам, все остальные можно закрыть.
В тех случаях, когда вес со страницы нужно передать по выбранным внутренним ссылкам, все остальные можно закрыть. 11.22 / Обновлен инструмент:
11.22 / Обновлен инструмент: nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex – любимые персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.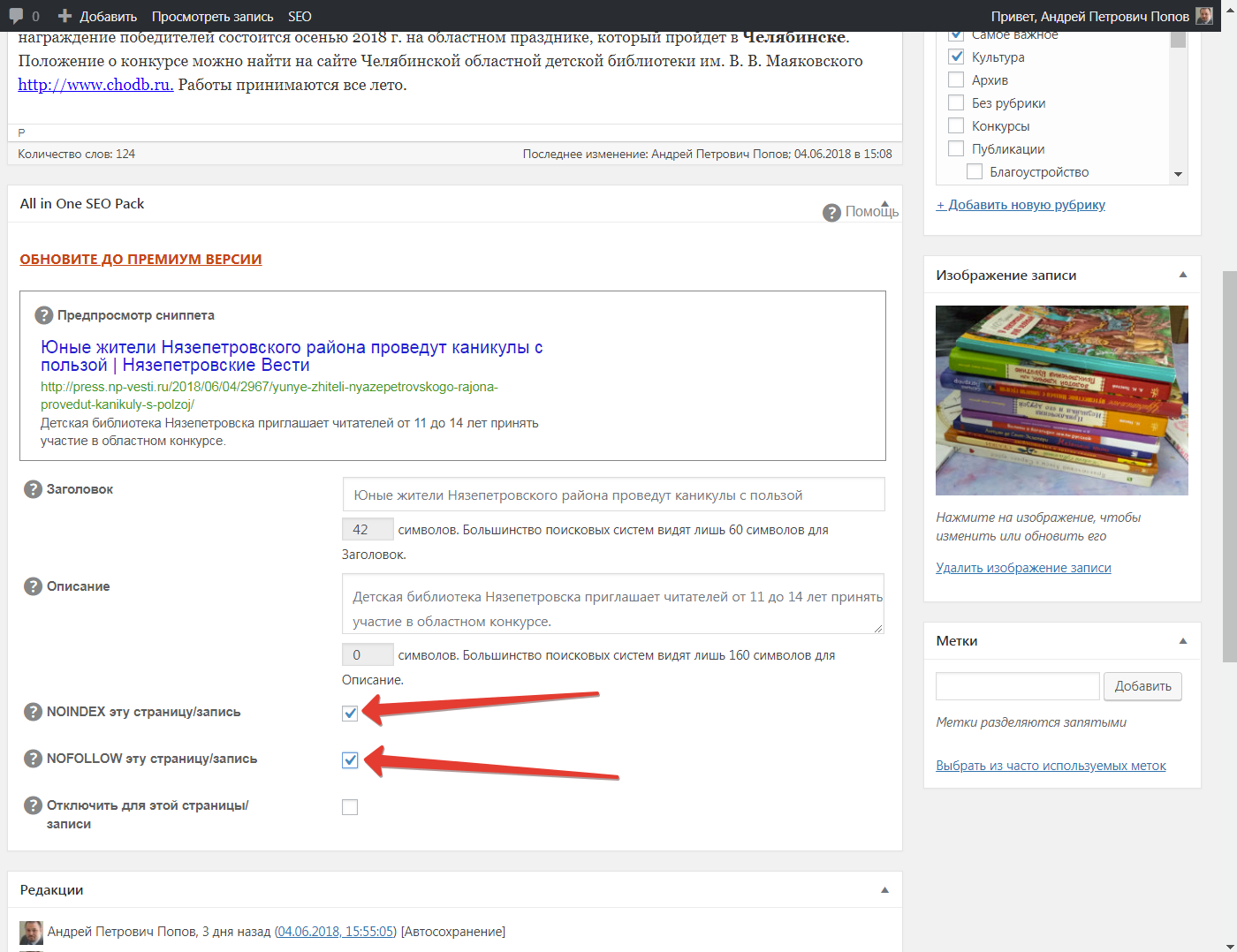
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.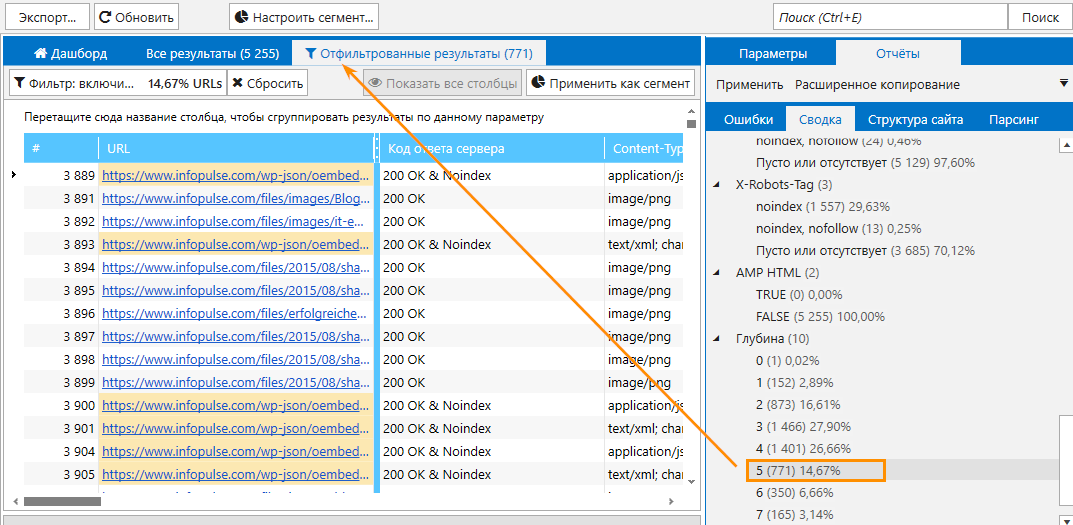 ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор).
 Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом:
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
 Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»: Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example. ru» rel=»nofollow»><noindex>Анкор</noindex></a>
 ru» rel=»nofollow»><noindex>Анкор</noindex></a>
ru» rel=»nofollow»><noindex>Анкор</noindex></a>Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
nofollow и noindex | Закрываемся от индексации на tehnopost. info
info
- nofollow (Яндекс & Google)
- rel=»nofollow» – не переходить по ссылке
- content=»nofollow» – не переходить по всем ссылкам
- Действие rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
- noindex – не индексировать текст
(тег и значение только для Яндекса)- Тег <noindex> – не признанное изобретение Яндекса
- Тег <noindex> – не индексировать кусок текста
- Метатег noindex – не индексировать текст всей страницы
- Разница в действии тега и метатега noindex
- Особенности метатега noindex
- Тег и метатег noindex для Google
- Универсальный метатег (Яндекс & Google)
Тег noindex в теле вашей страницы приведет к тому, что Google не будет индексировать страницу!
Мари Хейнс | 19 июня 2015 г. |
SEO
Сегодня я получил электронное письмо от владельца сайта с вопросом, могу ли я проконсультироваться с ним, чтобы помочь ему понять, почему они не могут повысить рейтинг своей домашней страницы в Google. Ранее у них были некоторые проблемы с пенальти, но они были устранены. Остальная часть сайта хорошо ранжировалась, но домашняя страница, похоже, была оштрафована. Я решил поделиться этой крутой историей детективной работы и сотрудничества, которая заканчивается тем, что мы находим причину и радуемся!
Ранее у них были некоторые проблемы с пенальти, но они были устранены. Остальная часть сайта хорошо ранжировалась, но домашняя страница, похоже, была оштрафована. Я решил поделиться этой крутой историей детективной работы и сотрудничества, которая заканчивается тем, что мы находим причину и радуемся!
Страница не проиндексирована
Первое, что я сделал, это сделал поиск по сайту в Google. Сайт конечно присутствовал, но я не смог найти домашнюю страницу сайта в результатах Google. Затем я проверил файл robots.txt сайта, введя www.sitename.com/robots.txt. Хотя многие каталоги сайта были заблокированы, у Google не было очевидной причины не видеть домашнюю страницу.
Мне, наверное, стоило сначала зайти на сайт, чтобы сэкономить время. Когда я зашел на сайт, я увидел этот большой сияющий маяк в правом нижнем углу экрана:
Что ж, это определенно сработает. (Кстати, это было создано с помощью расширения Nofollow Chrome). Я собирался написать владельцу сайта и сказать ему, чтобы он просто удалил тег noindex с сайта, но я проверил исходный код и был сбит с толку, когда CTRL-F вообще не обнаружил в исходном коде «noindex».
Спасибо, Твиттер!
Итак, я обратился к Твиттеру. Я люблю задавать вопросы своим коллегам по SEO в Twitter. Я твитнул свой вопрос, и несколько человек высказали свое мнение. Спасибо Майку Высоцке, Роуи и Томасу Хейнсу, у которых были отличные идеи, включая проверку того, не заблокирована ли страница тегом x-robots в заголовке, но это было не так.
Дженни Халаш попросила меня поделиться ссылкой, и она потратила немало времени, копаясь в этой загадке. И в конце концов она решилась! Она решила просмотреть страницу с помощью инструментов разработчика Chrome. Это можно сделать, нажав Вид —> Разработчик —> Инструменты разработчика.
Затем она нажала CTRL-F и БУМ! Посмотрите, что было спрятано в div:
Ничего себе. Также был второй тег noindex в другом div на странице.
Время для этого было невероятным, так как ранее на этой неделе Гэри Иллиес из Google написал в Твиттере предупреждение о том, что добавление тега noindex в тело вашей страницы (в отличие от заголовка) приведет к тому, что Google не будет индексировать страницу
Будьте внимательны с директивами noindex: большинство поисковых систем будут учитывать их, даже если они находятся в элементе BODY. https://t.co/Q2OVA6peow
— Гэри Иллиес (@methode) 17 июня 2015 г.
 https://t.co/Q2OVA6peow
https://t.co/Q2OVA6peowИсправление
Нарушающий код был удален с сайта. Владелец сайта будет использовать выборку Google в качестве робота Google в консоли поиска Google, чтобы быстро попросить Google проиндексировать страницу. Я ожидаю, что домашняя страница должна вернуться в ранжирование довольно быстро.
Обновление: Потребовалось около 24 часов, чтобы страница снова начала ранжироваться. Все было хорошо, когда этот код был удален.
✕
Будьте в курсе последних новостей SEO и AI
Я буду присылать вам электронное письмо каждую неделю, как только опубликую информационный бюллетень.
Все, что я нашел интересным на этой неделе. Отписаться в любое время.
Работает на ConvertKit
Доктор Мари Хейнс является основателем и генеральным директором Marie Haynes Consulting (MHC). Она известна тем, что разбирается в алгоритмах поиска Google. Мари является лидером в области SEO с более чем 14-летним опытом работы в области SEO. Она известна своим опытом работы с алгоритмами поиска Google, вопросами E-A-T, штрафов Google и обновлений алгоритмов Google. Google сослался на работу Мари в своей статье о том, что владельцы сайтов должны знать об основных обновлениях. Мари пишет для Search Engine Land, Search Engine Watch и Moz, ее часто упоминают в Search Engine Roundtable и цитируют Forbes и Inc. Мари регулярно выступает на SEO-конференциях, таких как Pubcon, SMX и Brighton SEO. Ее SEO-подкаст и информационный бюллетень информируют отрасль о SEO-темах.
Мари является лидером в области SEO с более чем 14-летним опытом работы в области SEO. Она известна своим опытом работы с алгоритмами поиска Google, вопросами E-A-T, штрафов Google и обновлений алгоритмов Google. Google сослался на работу Мари в своей статье о том, что владельцы сайтов должны знать об основных обновлениях. Мари пишет для Search Engine Land, Search Engine Watch и Moz, ее часто упоминают в Search Engine Roundtable и цитируют Forbes и Inc. Мари регулярно выступает на SEO-конференциях, таких как Pubcon, SMX и Brighton SEO. Ее SEO-подкаст и информационный бюллетень информируют отрасль о SEO-темах.
Вы можете найти Мари, выступающую на конференциях, на справочных форумах и активную в ее аккаунте в Твиттере и на YouTube.
Noindex, Nofollow и Disallow: что это такое? | by Calistus Mbachu
5 минут чтения
·
19 ноября 2018 г.
Вы владеете сайтом или управляете им для компании? Вы когда-нибудь использовали поисковую систему в определенное время, пытаясь проверить индекс вашего сайта, а затем поняли, что есть страница, которую вы не хотите отображать в поисковых системах?
«Как же так?» — возможно, воскликнули бы вы!
Если вы когда-нибудь окажетесь в такой непреднамеренной ситуации, есть способ написать инструкцию для поисковых роботов (также известных как веб-боты или поисковые роботы), которые не позволят им сканировать и индексировать ваши веб-страницы или ссылки.
Noindex, nofollow и disallow — это три атрибута, которые используются для предоставления инструкций поисковым роботам о том, как обрабатывать веб-страницы. Все они выполняют схожие функции, но в разных форматах. Более того, они являются частью Стандарта исключения роботов, установленного в 1994.
Теперь я объясню, что означают эти три атрибута один за другим, и объясню, почему они полезны.
Это атрибут метатега, используемый в разделе заголовка HTML-разметки, чтобы дать роботам поисковых систем указание не индексировать веб-страницу, на которой указан тег. Указание этого атрибута означает, что боты могут сканировать страницу, но не будут индексировать ее для отображения в результатах поиска.
Использование noindex дает владельцам сайтов право блокировать определенные страницы на своих сайтах, чтобы они не были частью страниц результатов поисковых систем.
Вот некоторые из причин использования noindex: это помогает предотвратить дублирование содержимого; запрещает ботам индексировать приватные страницы; запрещает ботам доступ к индексным страницам клиентов/клиентов; запрещает поисковым роботам индексировать страницу «спасибо», страницу конфиденциальности или страницу условий и положений.
Отправка файла Sitemap в Google Search Console
При размещении этой строки кода на раздел head исходного кода вашего сайта, поисковые роботы немедленно воздерживаются от размещения страницы в индексе поисковых систем.
Этот атрибут также используется для предоставления инструкций ботам поисковых систем, но его можно использовать для двух целей. Первая цель — отклонить определенные ссылки на веб-странице. И второй — указать ботам не переходить по определенным ссылкам на веб-странице.
Например, если на вашей веб-странице есть несколько ссылок, указывающих на другие сайты, боты увидят эти ссылки как достоверный источник информации, поэтому отдадут должное этим ссылкам. Таким образом, один из способов отключить вашу веб-страницу с любыми ссылками — установить атрибут nofollow.
Этот атрибут используется против спам-ссылок, размещенных в разделе комментариев на вашей веб-странице. Еще одна веская причина — запретить ботам индексировать такие страницы, как: платные ссылки, страница клиентов/покупателей, страница персонала или страница входа/регистрации и т. д., которые отображаются как ссылки на вашей веб-странице.
Еще одна веская причина — запретить ботам индексировать такие страницы, как: платные ссылки, страница клиентов/покупателей, страница персонала или страница входа/регистрации и т. д., которые отображаются как ссылки на вашей веб-странице.
Отправка карты сайта в Google Search Console
В качестве альтернативы можно использовать этот пример.
Текст ссылки здесь
Первый приведенный выше пример означает, что все ссылки на веб-странице должны обрабатываться директивой nofollow. . И второй пример конкретно указывает на ссылку, где должен применяться nofollow, но не на все ссылки на этой странице.
Получите дополнительную информацию от Google о том, где и как использовать этот атрибут.
Эта функция используется в файле robots.txt, чтобы указать роботам поисковых систем не индексировать определенные папки или файлы на сайте.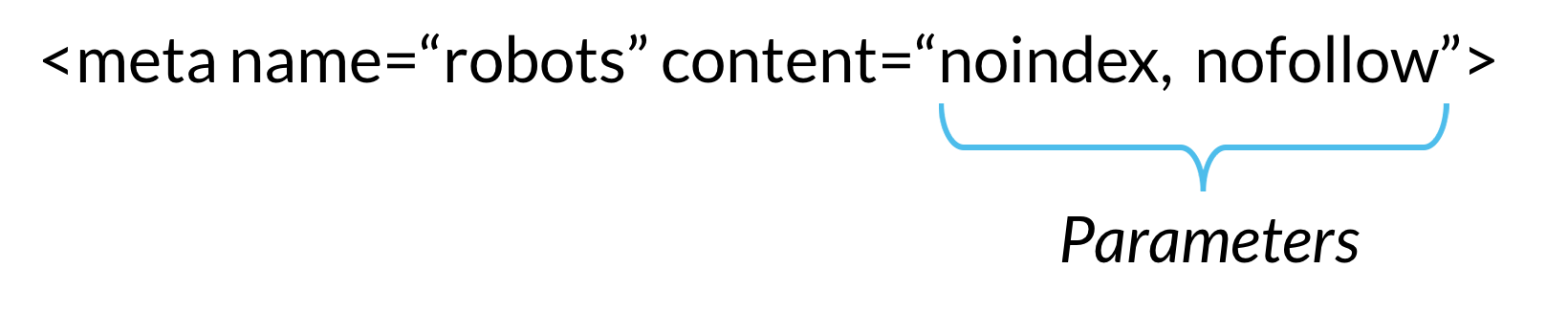 Везде, где боты видят disallow, они немедленно отказываются от индексации этой папки/файла.
Везде, где боты видят disallow, они немедленно отказываются от индексации этой папки/файла.
Причина аналогична noindex. Единственная разница заключается в формате, используемом при даче инструкций. Это также может помочь предотвратить дублирование содержимого, предотвратить индексацию частных страниц, предотвратить индексацию клиентов или страниц клиентов.
Чтобы отдать любую инструкцию с запретом, необходимо создать текстовый файл с именем файла robots.txt. Затем инструкция будет передана через файл.
Чтобы создать этот тип файла, откройте текстовый редактор и введите соответствующие директивы. Когда закончите, сохраните файл как robots.txt. Имя и расширение файла сообщают поисковым роботам тип документа.
Затем войдите в свою учетную запись cpanel и загрузите файл в корневой каталог вашего сайта. Ниже приведены примеры того, как можно передавать инструкции.
Предоставляет доступ каждому боту для сканирования и индексации всех страниц вашего сайта.
User-agent: *
Disallow:
Указывает ботам не индексировать ни одну страницу на всем сайте.
User-agent: *
Disallow: /
Запрещает ботам индексировать все страницы в указанных папках.
Агент пользователя: *
Запретить: /cgi-bin/
Запретить: /tmp/
Запретить: /pages/
Запрещает ботам индексировать определенную страницу в определенной папке.
User-agent: *
Disallow: /pages/staff.html
Чтобы просмотреть файл robots.txt вашего сайта, используйте этот пример.
http://www.calistus.net/robots.txt
ПРИМЕЧАНИЕ. при использовании этого файла будьте предельно осторожны. Убедитесь, что вы понимаете инструкции, которые вы передаете. В противном случае вы можете случайно заблокировать свой сайт, чтобы он не отображался в поисковых системах.
Дополнительные сведения о веб-роботах и принципах их работы см. на сайте Robotstxt. Если у вас есть учетная запись Google Search Console, вы можете протестировать предоставленные вами инструкции по этой ссылке.