Содержание
Что такое неуникальный контент?
Что такое неуникальный контент?
Неуникальный контент — это текстовый материал, который скопирован с одного или нескольких ресурсов. Поисковые системы строго относятся к содержимому сайтов и если замечают копипаст, то могут понизить в ранжировании страницы с размещенным скопированным материалом или вовсе исключить их из индекса. Проверить контент на уникальность помогают специальные сервисы.
Можно ли размещать неуникальный текст в карточке товара, если сайт продвигается SEO-специалистом?
Нет, неуникальный текст не рекомендуется размещать в карточке товара. Такой текст будет иметь низкую релевантность для поисковых систем, что может привести к понижению рейтинга сайта. Вместо этого рекомендуется использовать уникальный и информативный текст, который будет соответствовать запросам пользователя.
Рекомендуется требовать от копирайтера минимум 80% уникальности текста. Это позволит избежать проблем с поисковыми системами и увеличить шансы на получение высокого рейтинга сайта.
Почему контент на сайте для SEO должен быть уникальным на 80 или 100 процентов?
Когда речь идет о поисковой оптимизации (SEO), уникальный контент является ключевым фактором, который может помочь в повышении рейтинга сайта в поисковой выдаче.
Поисковые системы, такие как Google, стремятся предоставлять пользователям наиболее релевантный и качественный контент в ответ на их запросы. Как часть своего алгоритма они используют показатели уникальности контента, чтобы определить, насколько информация на сайте полезна и интересна для пользователей.
Если контент на сайте полностью скопирован с другого сайта или имеет высокую долю дубликатов, поисковые системы могут решить, что он не представляет ценности для пользователей и снизить рейтинг вашего сайта в поисковой выдаче.
Поэтому рекомендуется, чтобы уникальность контента на сайте была не менее 80-90%, хотя лучше всего стремиться к 100% уникальности. Это позволит поисковым системам увидеть ваш сайт как источник оригинальной и полезной информации, что в свою очередь может увеличить его рейтинг в поисковых результатах.
СПАСИБО, ЧТО ДОВЕРИЛИСЬ НАМ!
Мы вас не подведём! Наш менеджер перезвонит в течение часа, чтобы обсудить всё, что вам интересно. Не бойтесь
спрашивать, мы не кусаемся!
СПАСИБО, ЧТО ДОВЕРИЛИСЬ НАМ!
Мы вас не подведём! Наш менеджер перезвонит в течение часа, чтобы обсудить всё, что вам интересно. Не бойтесь
спрашивать, мы не кусаемся!
СПАСИБО, ЧТО ДОВЕРИЛИСЬ НАМ!
Мы вас не подведём! Наш менеджер перезвонит в течение часа, чтобы обсудить всё, что вам интересно. Не бойтесь
спрашивать, мы не кусаемся!
Беларусь
Россия
Другие
СПАСИБО, ЧТО ДОВЕРИЛИСЬ НАМ!
Мы вас не подведём! Наш менеджер перезвонит в течение часа, чтобы обсудить всё, что вам интересно. Не бойтесь
спрашивать, мы не кусаемся!
Беларусь
Россия
Другие
При нахождении на сайте Вы соглашаетесь с политикой обработки персональных данных.
Всё понятно!
Ворованный уникальный и неуникальный контент
Значимость контента сложно переоценить. Если на сайте размещено большое количество качественного контента, то сайт обречен на успех. Но все было бы хорошо, если бы не одно но: контент должен быть свой. Свой, уникальный, интересный и полезный. И вот на слове «уникальный» срезается 90% тех, кто открыл для себя всю прелесть контента.
Если на сайте размещено большое количество качественного контента, то сайт обречен на успех. Но все было бы хорошо, если бы не одно но: контент должен быть свой. Свой, уникальный, интересный и полезный. И вот на слове «уникальный» срезается 90% тех, кто открыл для себя всю прелесть контента.
И правда, зачем что-то придумывать, если все уже придумано? Интернет большой, и там все уже написано, зачем изобретать велосипед? Берем кусочек текста из Википедии, пучок абзацев с сайта конкурентов, щепотку красивых фраз с сайтов из топа поисковой выдачи и украшаем фотографиями из Google Картинок. Ссылки на источники? Не-не, слышал. Вот и все, статья готова. Добро пожаловать, в мир современного копирайтинга!
Уникальный контент
Уникальный контент — основа интернета. Есть еще коммуникация, но эта тема выходит за рамки части SEO. То есть пользователи интернета, не считая возможность пообщаться, заходят в интернет, чтобы получить доступ к какому-то интересующей их информации. Поиск контента — это именно то, для чего существуют поисковые системы, и то, что поисковые системы ценят превыше всего. Яндекс открыто говорит, что главное для Яндекса — контент. Аналогия для Google — «Content is King». Соответственно, поисковые системы больше всего ценят тех, кто регулярно поставляет уникальный и актуальный контент.
Поиск контента — это именно то, для чего существуют поисковые системы, и то, что поисковые системы ценят превыше всего. Яндекс открыто говорит, что главное для Яндекса — контент. Аналогия для Google — «Content is King». Соответственно, поисковые системы больше всего ценят тех, кто регулярно поставляет уникальный и актуальный контент.
Вопрос, что считать уникальным контентом, уже давно будоражит фантазии людей, которые хотят защитить свои интеллектуальные права или хотят нажиться на чужих трудах. Не хочу влезать в полемику, но создать что-то с нуля практически невозможно. Чтобы что-то создать, нужно создать это из чего-то. То есть, в любом случае, новое появляется на базе чего-то уже существующего, и заявлять: «Это создал Я!», по меньшей мере странно.
Однако это совсем не значит, что труд, время и силы не должны вознаграждаться и тем более заимствоваться. Поэтому вопрос стоит не столько в защите прав и даже не в создании сложностей для использования чужого контента, а в ускорении и упрощении его индексации, то есть в признании контента за вами как за первоисточником.
Неуникальные тексты
Контент оценивается с точки зрения потенциальной применимости и пользы, которую этот контент может принести. Но если мы говорим о контенте с точки зрения поисковых систем, то к потенциальной применимости контента добавляется еще и УНИКАЛЬНОСТЬ контента. Следовательно, напрашивается вопрос, кто определяет уникальность контента? Действительно, ведь уникальность контента — понятие сравнительное.
Так кто же, как, что и с чем сравнивает? Сравнивают поисковые системы, сравнивают новый контент с уже проиндексированным. Грубо говоря, у кого текст проиндексировался первым, у того он и оригинален. Повторюсь, грубо говоря, первоисточником контента считается тот ресурс, на котором этот контент был впервые обнаружен. Грубо потому, что к различным видам контента применяются различные способы анлиза для определения первоисточника. Можно допустить, что первоисточник контента может меняться в зависимости от накопленных о контенте и источниках контента данных и состояния этих источников.
Неуникальные картинки
Возьмем, к примеру, изображения. Сегодня поисковая система нашла новую картинку с разрешением 640х480 на одном сайте, а завтра ту же самую картинку с большим разрешением 800х600 на другом сайте. Кто первоисточник? Это зависит от огромного числа факторов и, собственно, самой поисковой системы, которая нашла эти картинки.
Контент в интернете выкладывается в свободное пользование, и все пользователи могут делать с этим контентом все, что им захочется. Это так, по сути. Конечно, кто-то может заявить, что это его картинка, и начать разбирательство по поводу неправомерного использования авторского материала. Но сама возможность пользоваться этим контентом никуда не денется.
Потому никто не может быть уверен в том, что за 100% контента, который он создает, будет признано 100% его авторства. И значок © не поможет.
Ворованый контент
Тексты воруют. Фотографии, картинки и все виды изображений тоже воруют. Видео воруют. Музыку воруют. Еще воруют нефть, газ, лес, людей, морских котиков, любовь, свободу и независимость. Все воруют. Это нужно понять, принять и подумать, как этому противостоять, тем более, что тут за вас уже действительно подумали и придумали. Почему бы не воспользоваться? 🙂
Все воруют. Это нужно понять, принять и подумать, как этому противостоять, тем более, что тут за вас уже действительно подумали и придумали. Почему бы не воспользоваться? 🙂
Не буду перечислять все возможные способы борьбы с воровством контента (если очень хотите, пишите в комментариях, можно написать об этом отдельную статью). Я постараюсь объяснить общие принципы размещения и первичной защиты контента в интернете.
Основные принципы
Первый и самый важный принцип — это максимальная уникальность контента. Понятно, что букв в алфавите ограниченное количество, а цвета всего три (ок, еще есть черный и белый). Но, в каждом тексте есть уникальная логическая структура и, если текст пишет человек, то логическая структура и манера написания становятся уникальным отпечатком. А создать две абсолютно идентичные фотографи невозможно.
Вывод: создавая контент самостоятельно, вероятность существенных совпадений стремится к нулю.
Второй важный принцип — скорость индексации. Чем быстрее поисковая система найдет и проиндексирует контент, тем быстрее будет определен его источник. Например, вы активно ведете блог, но поисковые системы по тем или иным причинам плохо индексируют ваш сайт. Кто то, у кого сайт индексируется лучше (быстрее) начинает банальным копипастом воровать ваш контент и размещать на своем сайте. Если ваш контент проиндексируется быстрее на чужом сайте — это не ваш контент. С точки зрения поисковых систем, первоисточником будет считаться тот сайт, на котором впервые будет найдена ваша статья. А вы, получается, украли статью.
Чем быстрее поисковая система найдет и проиндексирует контент, тем быстрее будет определен его источник. Например, вы активно ведете блог, но поисковые системы по тем или иным причинам плохо индексируют ваш сайт. Кто то, у кого сайт индексируется лучше (быстрее) начинает банальным копипастом воровать ваш контент и размещать на своем сайте. Если ваш контент проиндексируется быстрее на чужом сайте — это не ваш контент. С точки зрения поисковых систем, первоисточником будет считаться тот сайт, на котором впервые будет найдена ваша статья. А вы, получается, украли статью.
Вывод: высокая скорость индексации — ваш лучший друг.
Яндекс.Вебмастер — Оригинальные тексты
Это сервис, с помощью которого можно сообщить Яндексу о появлении оригинального текста на сайте.
Цитата: Если вы публикуете на своем сайте оригинальные тексты, а их перепечатывают другие интернет-ресурсы, предупредите Яндекс о скором выходе текста. Мы будем знать, что оригинальный текст впервые появился именно на вашем сайте, и попробуем использовать это в настройке поисковых алгоритмов.

Существует множество способов воспрепятствовать неправомерному использованию вашего контента. Но на каждый из них есть несколько способов их обойти. И если известно, что кто-то систематически ворует ваш контент, вы можете потребовать удалить ваш контент со стороннего сайта или начать разбирательство. Но практика показывает, что если сторонний ресурс не удалит контент добравольно, то попытка добиться этого через суд, может стоить дороже, чем ущерб от кражи котнтета.
Размещайте собственный уникальный контент. Думайте, как, когда и где размещать контент. И будет вам счастье 🙂
Дублированный контент: почему это происходит и как устранить проблемы
Что такое дублированный контент?
Дублированное содержимое — это содержимое, которое появляется в Интернете более чем в одном месте. Это «одно место» определяется как местоположение с уникальным адресом веб-сайта (URL), поэтому, если один и тот же контент появляется более чем на одном веб-адресе, у вас есть дублированный контент.
Технически это не является наказанием, но дублированный контент иногда может влиять на рейтинг в поисковых системах. Когда есть несколько фрагментов, как это называет Google, «заметно похожего» контента в более чем одном месте в Интернете, поисковым системам может быть трудно решить, какая версия более релевантна данному поисковому запросу.
Почему дублированный контент имеет значение?
Для поисковых систем
Дублированный контент может представлять три основные проблемы для поисковых систем:
Они не знают, какую версию (версии) включить или исключить из своих индексов.
Они не знают, следует ли направлять показатели ссылок (доверие, авторитетность, анкорный текст, вес ссылок и т. д.) на одну страницу или хранить их отдельно для нескольких версий.
Они не знают, какие версии ранжировать для результатов запроса.
Для владельцев сайтов
При наличии дублированного контента владельцы сайтов могут пострадать в рейтинге и потерять трафик. Эти потери часто возникают из-за двух основных проблем:
Эти потери часто возникают из-за двух основных проблем:
Чтобы обеспечить наилучшее качество поиска, поисковые системы редко показывают несколько версий одного и того же контента и, таким образом, вынуждены выбирать, какая версия с наибольшей вероятностью даст наилучший результат. Это снижает видимость каждых дубликатов.
Капитал ссылок может быть еще больше разбавлен, поскольку другим сайтам также приходится выбирать между дубликатами. вместо того, чтобы все входящие ссылки указывали на один фрагмент контента, они ссылаются на несколько фрагментов, распределяя вес ссылок среди дубликатов. Поскольку входящие ссылки являются фактором ранжирования, это может повлиять на видимость контента в поиске.
Чистый результат? Фрагмент контента не обеспечивает видимость в поиске, как это было бы в противном случае.
Как возникают проблемы с дублированием содержимого?
В подавляющем большинстве случаев владельцы веб-сайтов не создают дублирующийся контент намеренно. Но это не значит, что его там нет. На самом деле, по некоторым оценкам, до 29% веб-сайтов на самом деле является дублирующимся контентом!
Но это не значит, что его там нет. На самом деле, по некоторым оценкам, до 29% веб-сайтов на самом деле является дублирующимся контентом!
Давайте рассмотрим некоторые из наиболее распространенных способов непреднамеренного создания дублированного контента:
1. Варианты URL
Параметры URL, такие как отслеживание кликов и некоторый код аналитики, могут вызывать проблемы с дублированием контента. Это может быть проблемой, вызванной не только самими параметрами, но и порядком, в котором эти параметры появляются в самом URL-адресе.
Например:
- www.widgets.com/blue-widgets?c… является дубликатом www.widgets.com/blue-widgets?c…&cat=3″>www.widgets .com/blue-widgets является дубликатом www.widgets.com/blue-widgets?cat=3&color=blue
Точно так же идентификаторы сеансов являются общим создателем дублирующегося контента. Это происходит, когда каждому пользователю, посещающему веб-сайт, назначается другой идентификатор сеанса, хранящийся в URL-адресе.
Версии содержимого для печати также могут вызывать проблемы с дублированием содержимого при индексировании нескольких версий страниц.
Один урок здесь заключается в том, что, когда это возможно, часто полезно избегать добавления параметров URL или альтернативных версий URL (содержащаяся в них информация обычно может быть передана через сценарии).
2. HTTP против HTTPS или WWW против не WWW страниц
Если ваш сайт имеет отдельные версии на «www.site.com» и «site.com» (с префиксом «www» и без него), и один и тот же контент присутствует в обеих версиях, вы фактически создали дубликаты каждой из этих страниц. То же самое относится к сайтам, которые поддерживают версии как на http://, так и на https://. Если обе версии страницы активны и видны поисковым системам, вы можете столкнуться с проблемой дублирования контента.
3. Вычищенный или скопированный контент
Контент включает не только сообщения в блогах или редакционный контент, но и страницы с информацией о продукте. Парсеры, повторно публикующие содержимое вашего блога на своих сайтах, могут быть более привычным источником дублированного контента, но есть и общая проблема для сайтов электронной коммерции: информация о продукте. Если много разных веб-сайтов продают одни и те же товары, и все они используют описания этих товаров, предоставленные производителем, идентичный контент оказывается в нескольких местах в Интернете.
Парсеры, повторно публикующие содержимое вашего блога на своих сайтах, могут быть более привычным источником дублированного контента, но есть и общая проблема для сайтов электронной коммерции: информация о продукте. Если много разных веб-сайтов продают одни и те же товары, и все они используют описания этих товаров, предоставленные производителем, идентичный контент оказывается в нескольких местах в Интернете.
Как исправить проблемы с дублированием контента
Исправление проблем с дублированием контента сводится к одной и той же центральной идее: указать, какой из дубликатов является «правильным».
Всякий раз, когда контент на сайте можно найти по нескольким URL-адресам, он должен быть канонизирован для поисковых систем. Давайте рассмотрим три основных способа сделать это: с помощью перенаправления 301 на правильный URL-адрес, атрибута rel=canonical или с помощью инструмента обработки параметров в Google Search Console.
301 перенаправление
Во многих случаях лучший способ борьбы с дублирующимся контентом — настроить переадресацию 301 с «дублированной» страницы на исходную страницу с контентом.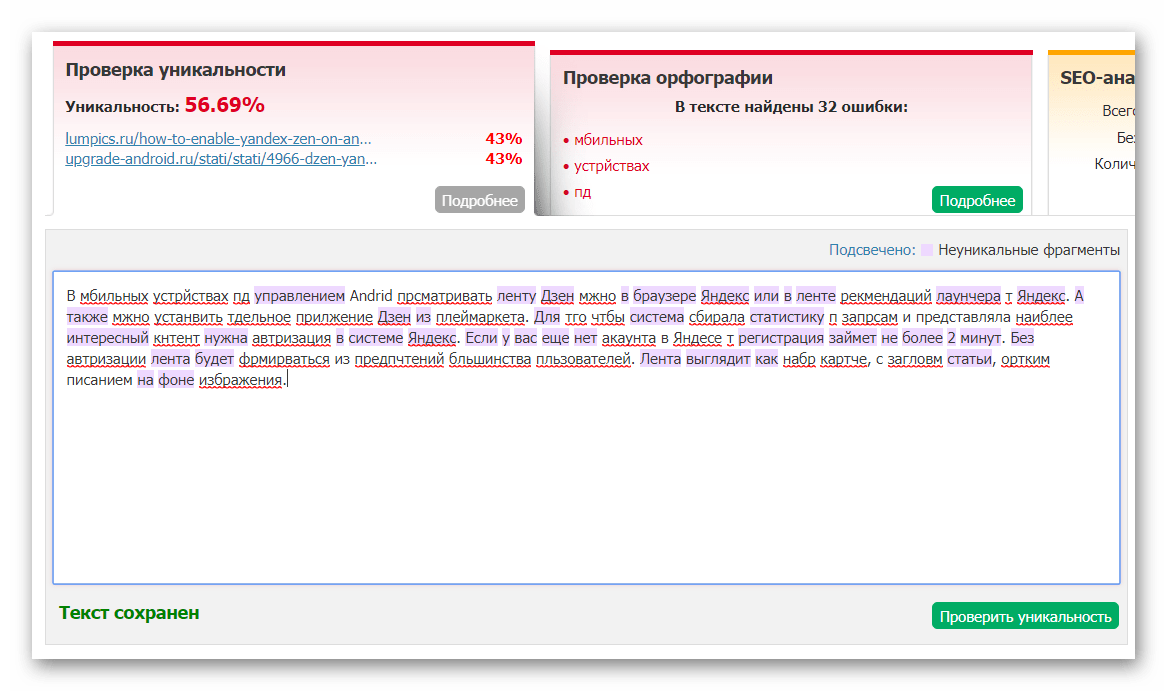
Когда несколько страниц с потенциалом высокого рейтинга объединяются в одну страницу, они не только перестают конкурировать друг с другом; они также создают более сильный сигнал релевантности и популярности в целом. Это положительно повлияет на способность «правильной» страницы занимать высокие позиции.
Rel=»canonical»
Другой способ борьбы с дублирующимся содержимым — использование атрибута rel=canonical. Это сообщает поисковым системам, что данная страница должна рассматриваться как копия указанного URL-адреса, и что все ссылки, метрики контента и «мощность ранжирования», которые поисковые системы применяют к этой странице, должны фактически относиться к указанному адресу. URL.
Атрибут rel=»canonical» является частью заголовка HTML веб-страницы и выглядит следующим образом:
Общий формат:
...[другой код, который может быть в заголовке HTML вашего документа ]....
 ..[другой код, который может быть в заголовке HTML вашего документа]...
..[другой код, который может быть в заголовке HTML вашего документа]... Атрибут rel=canonical должен быть добавлен в заголовок HTML каждой дублированной версии страницы, при этом указанная выше часть «URL ИСХОДНОЙ СТРАНИЦЫ» должна быть заменена ссылкой на исходную (каноническую) страницу. (Убедитесь, что вы сохранили кавычки.) Атрибут передает примерно такое же количество ссылок (мощность ранжирования), что и перенаправление 301, и, поскольку он реализован на уровне страницы (а не сервера), часто требуется меньше времени на разработку. осуществлять.
Ниже приведен пример того, как канонический атрибут выглядит в действии:
Использование MozBar для идентификации канонических атрибутов.
Здесь мы видим, что BuzzFeed использует атрибуты rel=canonical для согласования использования параметров URL (в данном случае для отслеживания кликов). Хотя эта страница доступна по двум URL-адресам, атрибут rel=canonical гарантирует, что все показатели ссылочного веса и содержания относятся к исходной странице (/no-one-does-this-anymore).
Мета-роботы Noindex
Одним из метатегов, который может быть особенно полезен при работе с дублирующимся контентом, является метатег robots, когда он используется со значениями «noindex, follow». Обычно называемый Meta Noindex,Follow и технически известный как content=”noindex,follow”, этот метатег robots может быть добавлен в заголовок HTML каждой отдельной страницы, которая должна быть исключена из индекса поисковой системы.
Общий формат:
...[другой код, который может быть в заголовке HTML вашего документа]......[other код, который может находиться в заголовке HTML вашего документа]...
Мета-тег robots позволяет поисковым системам сканировать ссылки на странице, но не позволяет им включать эти ссылки в свои индексы. Важно, чтобы повторяющаяся страница по-прежнему могла быть просканирована, даже если вы просите Google не индексировать ее, потому что Google явно предостерегает от ограничения доступа сканирования к дублирующемуся контенту на вашем веб-сайте. (Поисковикам нравится иметь возможность видеть все, если вы допустили ошибку в своем коде. Это позволяет им сделать [вероятно автоматический] «вынесение суждения» в неоднозначных ситуациях.)
(Поисковикам нравится иметь возможность видеть все, если вы допустили ошибку в своем коде. Это позволяет им сделать [вероятно автоматический] «вынесение суждения» в неоднозначных ситуациях.)
Использование мета-роботов — особенно хорошее решение проблем с дублированием контента, связанных с нумерацией страниц.
Предпочтительный домен и обработка параметров в Google Search Console
Google Search Console позволяет вам установить предпочтительный домен вашего сайта (т. е. http://yoursite.com вместо http://www.yoursite.com) и указать, следует ли Googlebot должен по-разному сканировать различные параметры URL (обработка параметров).
В зависимости от структуры вашего URL-адреса и причины проблем с дублирующимся содержимым, настройка предпочтительного домена или обработки параметров (или того и другого!) может обеспечить решение.
Основным недостатком использования обработки параметров в качестве основного метода работы с дублирующимся содержимым является то, что вносимые вами изменения работают только для Google. Любые правила, установленные с помощью Google Search Console, не повлияют на то, как поисковые роботы Bing или любой другой поисковой системы интерпретируют ваш сайт; вам нужно будет использовать инструменты для веб-мастеров для других поисковых систем в дополнение к изменению настроек в Search Console.
Любые правила, установленные с помощью Google Search Console, не повлияют на то, как поисковые роботы Bing или любой другой поисковой системы интерпретируют ваш сайт; вам нужно будет использовать инструменты для веб-мастеров для других поисковых систем в дополнение к изменению настроек в Search Console.
Дополнительные методы борьбы с дублирующимся контентом
Поддерживайте согласованность при размещении внутренних ссылок на веб-сайте. Например, если веб-мастер определяет, что каноническая версия домена — www.example.com/, то все внутренние ссылки должны вести на http://www. example.co… вместо http:// example.com/pa… (обратите внимание на отсутствие www).
При синдикации контента убедитесь, что синдицирующий веб-сайт добавляет ссылку на исходный контент, а не вариант URL-адреса. (Дополнительную информацию см. в выпуске «Белая доска в пятницу» о работе с дублирующимся содержимым.)
Чтобы добавить дополнительную защиту от парсеров контента, похищающих рейтинг SEO для вашего контента, разумно добавить самореферентную ссылку rel=canonical на ваши существующие страницы.
Это канонический атрибут, который указывает на URL-адрес, на котором он уже находится, и цель состоит в том, чтобы помешать усилиям некоторых парсеров.Самореферентная ссылка rel=canonical: URL-адрес, указанный в теге rel=canonical, совпадает с URL-адресом текущей страницы.
Хотя не все парсеры будут переносить полный HTML-код исходного материала, некоторые будут. Для тех, кто это делает, самореферентный тег rel=canonical гарантирует, что версия вашего сайта будет признана «оригинальной» частью контента.
 Это канонический атрибут, который указывает на URL-адрес, на котором он уже находится, и цель состоит в том, чтобы помешать усилиям некоторых парсеров.
Это канонический атрибут, который указывает на URL-адрес, на котором он уже находится, и цель состоит в том, чтобы помешать усилиям некоторых парсеров.Продолжайте учиться
- Дублированный контент в мире после Panda
- Дублированный контент — Служба технической поддержки Google
- Обработка дублирующегося контента, созданного пользователями и требуемого производителем, на большом количестве URL-адресов
9001 7 Не 301, 302 , а каноники все в принципе одинаковые?
Примените свои навыки на практике
Сканирование сайта Moz Pro может помочь выявить дублированный контент на веб-сайте. Попробуй >>
Попробуй >>
Remove Duplicate Lines — Средство для удаления дубликатов текста — Онлайн
Самое простое в мире онлайн-удаление дубликатов текста для веб-разработчиков и программистов. Просто вставьте свой текст в форму ниже, нажмите кнопку «Удалить дубликаты», и вы получите уникальные текстовые строки. Нажми кнопку — получи уникальный текст. Никакой рекламы, ерунды и мусора.
Объявление : Мы только что запустили SCIURLS — удобный агрегатор научных новостей. Проверьте это!
(отменить)
Средство удаления повторяющихся строк текста может быть полезно, если вы проводите кросс-браузерное тестирование. Например, если вы пишете браузерные тесты для многострочной текстовой формы и у вас есть требование, чтобы одна и та же строка в форме не появлялась дважды, то с помощью этой программы вы можете быстро создать тестовые примеры для этого сценария. Вы можете написать два набора тестов: первый набор тестов проверяет правильность ввода без повторяющихся строк, а второй набор тестов гарантирует, что если во входных данных есть повторяющиеся строки, то этот случай обрабатывается правильно, и этот ввод не допускается в приложении. В другом варианте использования предоставляется список имен, мест или телефонных номеров, фильтрация и печать только уникальных. И еще один вариант использования — сравнение двух списков данных на наличие повторяющихся записей.
В другом варианте использования предоставляется список имен, мест или телефонных номеров, фильтрация и печать только уникальных. И еще один вариант использования — сравнение двух списков данных на наличие повторяющихся записей.
Ищете дополнительные инструменты веб-разработчика? Попробуйте эти!
Кодировщик URL
Декодер URL
Анализатор URL
Кодировщик HTML
Декодер HTML
Кодировщик Base64
Декодер Base64
HTML Prettifier
HTML Minifier
JSON Prettifier
JSON Minifier
JSON Escaper
JSON Unescaper
JSON Validator
JS Prettifier
JS Minifier
JS Validator
CSS Prettify
CSS Minifier
XML Prettifier
XML Minifier
Преобразователь XML в JSON
Преобразователь JSON в XML
Преобразователь XML в CSV
Преобразователь CSV в XML
Преобразователь XML в YAML
Преобразователь YAML в XML преобразователь
YAML в TSV Converter
TSV в YAML Converter
XML в TSV Converter
TSV в XML Converter
XML в текстовый конвертер
JSON TO CSV Converter
. 0005
0005
Конвертер CSV в JSON
Конвертер JSON в YAML
Конвертер YAML в JSON
Конвертер JSON в TSV
Конвертер TSV в JSON
Конвертер JSON в текст 9000 5
Конвертер CSV в YAML
Конвертер YAML в CSV
Конвертер TSV в CSV
Конвертер CSV в TSV
Конвертер CSV в текстовые столбцы
Конвертер текстовых столбцов в CSV
Конвертер TSV в текстовые столбцы
Конвертер текстовых столбцов в TSV
Преобразователь CSV
Преобразователь столбцов в строки CSV
Преобразователь строк в столбцы CSV
Преобразователь столбцов CSV
Экспортер столбцов CSV
Заменить столбец CSV r
Устройство для добавления столбцов CSV
Устройство для добавления столбцов CSV
Устройство для вставки столбцов CSV
Средство удаления столбцов CSV
Средство смены разделителей CSV
Транспозитор TSV
Преобразователь столбцов в строки TSV
Преобразователь строк в столбцы TSV
Преобразователь столбцов TSV
TSV Column Exporter
TSV Column Replacer
TSV Column Prepender
TSV Column Appender
TSV Column Inserter
TSV Column Deleter
Средство смены разделителей TSV
Средство экспорта столбцов с разделителями
Средство удаления столбцов с разделителями
Средство замены столбцов с разделителями
Преобразователь текста
Преобразователь текстовых столбцов в строки
Преобразователь текстовых строк в столбцы
Преобразователь текстовых столбцов
Преобразователь разделителей текстовых столбцов
Преобразователь HTML в Markdown
Преобразователь Markdown в HTML
Преобразователь HTML в Jade
Преобразователь Jade в HTML
Преобразователь BBCode в HTML
Преобразователь BBCode в Jade
Преобразователь BBCode в текст
HTML Преобразователь времени в текст
HTML Stripper
Преобразователь объектов текста в HTML
Преобразователь времени UNIX в время UTC
Преобразователь времени UTC в время UNIX
Преобразователь IP в двоичный
Преобразователь двоичного в IP
Преобразователь IP в десятичный
Преобразователь восьмеричного в IP
Преобразователь IP в восьмеричный
Преобразователь десятичного в IP
Преобразователь Hex в IP
IP Сортировщик адресов
Генератор паролей MySQL
Генератор паролей MariaDB
Генератор паролей Postgres
Генератор паролей Bcrypt
Средство проверки паролей Bcrypt
Генератор паролей Scrypt
Проверка паролей Scrypt
Кодер/декодер ROT13
Кодер/декодер ROT47
Кодер Punycode
Декодер Punycode
Кодировщик Base32
Декодер Base32
Кодировщик Base58
Декодер Base58
Кодировщик Ascii85
Декодер Ascii85
Кодировщик UTF8
Декодер UTF8
Кодировщик UTF16
Декодер UTF16
Кодировщик Uuencoder
Декодер Uude
Кодировщик азбуки Морзе
Декодер азбуки Морзе
Шифровщик XOR
Дешифратор XOR
Шифровщик AES
Дешифратор AES 9 0005
шифратор RC4
шифратор RC4
шифратор DES
шифратор DES
шифратор Triple DES
Triple DES Decryptor
Rabbit Encryptor
Rabbit Decryptor
NTLM Hash Calculator
MD2 Hash Calculator
Калькулятор хешей MD4
Калькулятор хэшей MD5
Калькулятор хэшей MD6
Калькулятор хэшей RipeMD128
Калькулятор хэшей RipeMD160
Калькулятор хэшей RipeMD256
Калькулятор хэша RipeMD320
Калькулятор хэша SHA1
Калькулятор хэша SHA2
Калькулятор хэша SHA224
Калькулятор хэша SHA256
Калькулятор хэша SHA384
Калькулятор хэша SHA512
Калькулятор хэша SHA3
CRC16 Hash Calculator
CRC32 Hash Calculator
Adler32 Hash Calculator
Whirlpool Hash Calculator
All Hash Calculator
Конвертер секунд в H:M:S 9000 5
Конвертер H:M:S в секунды
Перевод секунд в человекочитаемый Время
Преобразователь двоичного кода в восьмеричный
Преобразователь двоичного кода в десятичный
Преобразователь двоичного кода в шестнадцатеричный
Преобразователь двоичного кода в двоичный
Преобразователь двоичного кода в десятичный
Преобразователь восьмеричного в шестнадцатеричный
Преобразователь десятичного в двоичный
Преобразователь десятичного в восьмеричный
Преобразователь десятичного в шестнадцатеричный
Преобразователь шестнадцатеричного в двоичный
Преобразователь шестнадцатеричного в восьмеричный
Преобразователь шестнадцатеричных чисел в десятичные
Преобразователь десятичных чисел в двоично-десятичные
BCD
Преобразователь восьмеричных чисел в двоично-десятичные
Преобразование двоично-десятичных чисел в восьмеричные
Преобразование шестнадцатеричных чисел в двоично-десятичные
Преобразование двоично-десятичных чисел в шестнадцатеричные
Преобразование двоичных чисел в серые
Преобразователь серого в двоичный
Преобразователь восьмеричный в серый
Преобразователь серый в восьмеричный
Преобразователь десятичного в серый
Преобразователь серого в десятичный
Преобразователь шестнадцатеричный в серый
900 04 Преобразователь Грея в шестнадцатеричный
Калькулятор двоичной суммы
Двоичный Калькулятор продукта
Калькулятор двоичного побитового И
Калькулятор двоичного побитового И-НЕ
Калькулятор двоичного побитового ИЛИ
Калькулятор двоичного побитового НЕ-ИЛИ
Двоичный побитовый калькулятор XOR
Двоичный побитовый калькулятор XNOR
Двоичный побитовый калькулятор NOT
Двоичный битовый инвертор
Двоичный битовый реверс
Двоичный вращатель чисел
Двоичный поворотник влево
Двоичный поворотник вправо
Преобразователь числовой базы
Преобразователь римских чисел в десятичные
Преобразователь десятичных чисел в римские
Преобразователь чисел в слова
Преобразователь слов в числа
Округление чисел вверх
Округление чисел вниз
Преобразователь UTF8 в шестнадцатеричный код
Преобразователь шестнадцатеричного кода в UTF8
Преобразователь текста в коды ASCII
Преобразователь кода ASCII в текст
9000 4 Преобразователь текста в двоичный код
Преобразователь двоичного кода в текст
Текст
Преобразователь восьмеричного в текст
Преобразователь текста в десятичный
Преобразователь десятичного в текст
Преобразователь текста в шестнадцатеричный
Преобразователь шестнадцатеричного в текст
Преобразователь текста в нижний регистр
Преобразователь текста в верхний регистр
Преобразователь текста в случайный регистр
Преобразователь текста в регистр заголовков
Преобразование слов в тексте с заглавной буквы
Преобразователь регистра текста
Trun cate Текстовые строки
Обрезать текстовые строки
Пробелы для вкладок Конвертер
Преобразователь табуляции в пробелы
Преобразователь пробелов в символы новой строки
Преобразователь новой строки в пробелы
Преобразователь символьного акцента
Удаление лишних пробелов
Удаление всех пробелов
Удаление знаков препинания
Средство добавления разделителей тысяч
Средство удаления обратной косой черты
Средство добавления обратной косой черты
Преобразователь текста 9 0005
Повторитель текста
Заменитель текста
Реверс текста
Поворот текста
Текст Вращатель символов влево
Вращатель текстовых символов вправо
Калькулятор длины текста
Сортировщик текста по алфавиту
Числовой сортировщик текста
Сортировщик текста по длине
Текст из генератора регулярных выражений
Текст по центру
Текст с выравниванием по правому краю
Текст с левой стороны
Текст с правой стороны
Выравнивание текста по ширине
Средство форматирования текстовых столбцов
Regex Match Extractor
Regex Match Replacer
Email Extractor
URL Extractor
Number Extractor
List Merger
List Zipper
List Intersection
Разность списков
Средство форматирования Printf
Text Grep
Text Head
Text Tail
Извлечение диапазона строк
Word Sorter
Word Wrap
Разделитель слов
Добавить номера строк
Добавить префиксы строк
Добавить Суффиксы строк
Добавление префикса и суффикса
Поиск самой длинной текстовой строки
Поиск самой короткой текстовой строки
Удаление повторяющихся строк
Удаление пустых строк
Рандомизатор строк текста
Рандомизатор букв
Соединение строк текста
Разделитель строк
Реверсивное преобразование строк текста
Фильтр строк текста
Счетчик количества букв в тексте 9000 5
Количество слов в счетчике текста
Количество строк в Счетчик текста
Счетчик количества абзацев в тексте
Калькулятор частоты букв
Калькулятор частоты слов
Калькулятор частоты фраз
Текстовая статистика
Средство выбора случайных элементов
Генератор случайных JSON
Генератор случайных XML
Генератор случайных YAML
Генератор случайных CSV
Генератор случайных TSV
Генератор случайных паролей
Генератор случайных строк
Генератор случайных чисел
Генератор случайных дробей
Генератор случайных интервалов
Генератор случайных чисел
Генератор случайных чисел
Генератор случайных шестнадцатеричных чисел
Генератор случайных байтов
Генератор случайных IP-адресов
Генератор случайных MAC-адресов
Генератор случайных UUID
Генератор случайных GUID
Генератор случайных дат
900 04 Генератор случайного времени
Генератор простых чисел
Генератор чисел Фибоначчи
Генератор числа Пи
E Генератор цифр
Преобразователь десятичных чисел в научные
Преобразователь научных чисел в десятичные
Преобразователь JPG в PNG
Конвертер PNG в JPG
Конвертер GIF в PNG
Конвертер GIF в JPG
Конвертер BMP в PNG
Конвертер BMP в JPG
Конвертер изображения в Base64
Преобразователь Base64
Преобразователь JSON в Base64
Преобразователь XML в Base64
Преобразователь Hex в RGB
Преобразователь RGB в Hex
Преобразователь CMYK в RGB
Преобразователь RGB в CMYK
Преобразователь CMYK в Hex
Конвертер Hex в CMYK
Кодировщик IDN
Декодер IDN
Конвертер миль в километры
Конвертер километров в мили
Конвертер градусов Цельсия в Фаренгейты
900 04 Конвертер градусов по Фаренгейту в градусы Цельсия
Конвертер градусов в градусы
Конвертер градусов в радианы
Конвертер фунтов в килограммы
Конвертер килограммов в фунты
Мой IP-адрес
Все инструменты
Совет: вы можете использовать аргумент запроса ?input=text для передачи текста в инструменты.