Содержание
Что такое NoSQL? | Нереляционные базы данных, модели данных с гибкой схемой | AWS
Высокопроизводительные нереляционные базы данных с гибкими моделями данных
Базы данных NoSQL специально созданы для определенных моделей данных и обладают гибкими схемами, что позволяет разрабатывать современные приложения. Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Базы данных в AWS: подходящий инструмент для подходящей работы
Базы данных NoSQL используют разнообразные модели данных для доступа к данным и управления ими. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
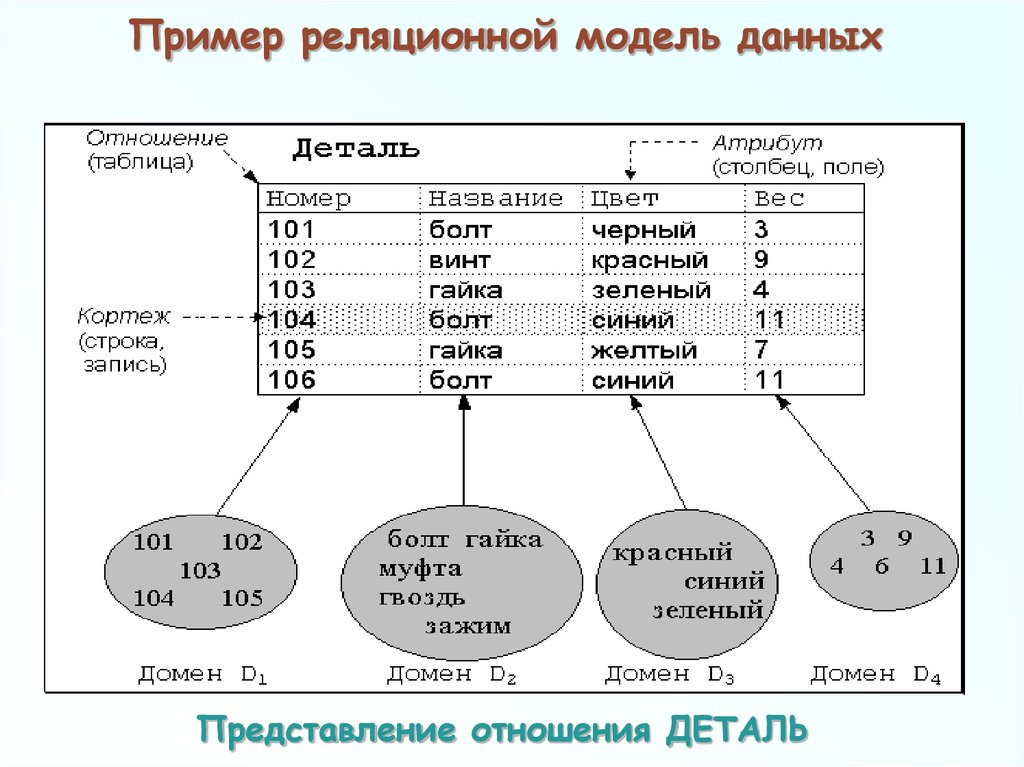
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе.
 В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
 В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации. Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
- Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.

БД на основе пар «ключ‑значение». Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT. Amazon DynamoDB обеспечивает стабильную работу БД с задержкой не более нескольких миллисекунд при любом масштабе. Такая устойчивая производительность послужила основной причиной переноса Snapchat Stories в сервис DynamoDB, поскольку эта возможность Snapchat связана с самой большой нагрузкой на запись в хранилище.
Документ В коде приложения данные часто представлены как объект или документ в формате, подобном JSON, поскольку для разработчиков это эффективная и интуитивная модель данных. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Графовые БД. Графовые базы данных упрощают разработку и запуск приложений, работающих с наборами сложносвязанных данных. Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний. Amazon Neptune – это полностью управляемый сервис графовых баз данных. Neptune поддерживает модель Property Graph и Resource Description Framework (RDF), предоставляя на выбор два графовых API: TinkerPop и RDF / SPARQL. К числу распространенных графовых БД относятся Neo4j и Giraph.
Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний. Amazon Neptune – это полностью управляемый сервис графовых баз данных. Neptune поддерживает модель Property Graph и Resource Description Framework (RDF), предоставляя на выбор два графовых API: TinkerPop и RDF / SPARQL. К числу распространенных графовых БД относятся Neo4j и Giraph.
БД в памяти. Часто в игровых и рекламных приложениях используются таблицы лидеров, хранение сессий и аналитика в реальном времени. Такие возможности требуют отклика в пределах нескольких микросекунд, при этом резкое возрастание трафика возможно в любой момент. Amazon MemoryDB для Redis – это совместимый с Redis надежный сервис базы данных в памяти, который уменьшает задержку чтения до миллисекунд и обеспечивает надежность в нескольких зонах доступности. MemoryDB специально создана для обеспечения сверхвысокой производительности и надежности, поэтому ее можно использовать как основную базу данных для современных приложений на базе микросервисов. Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Поисковые БД. Многие приложения формируют журналы, чтобы разработчикам было проще выявлять и устранять неполадки. Сервис Amazon OpenSearch – специально разработанный сервис для визуализации и аналитики автоматически генерируемых потоков данных в режиме, близком к реальному времени, путем индексирования, агрегации частично структурированных журналов и метрик и поиска по ним. Кроме того, сервис Amazon OpenSearch – это мощный, высокопроизводительный сервис для полнотекстового поиска.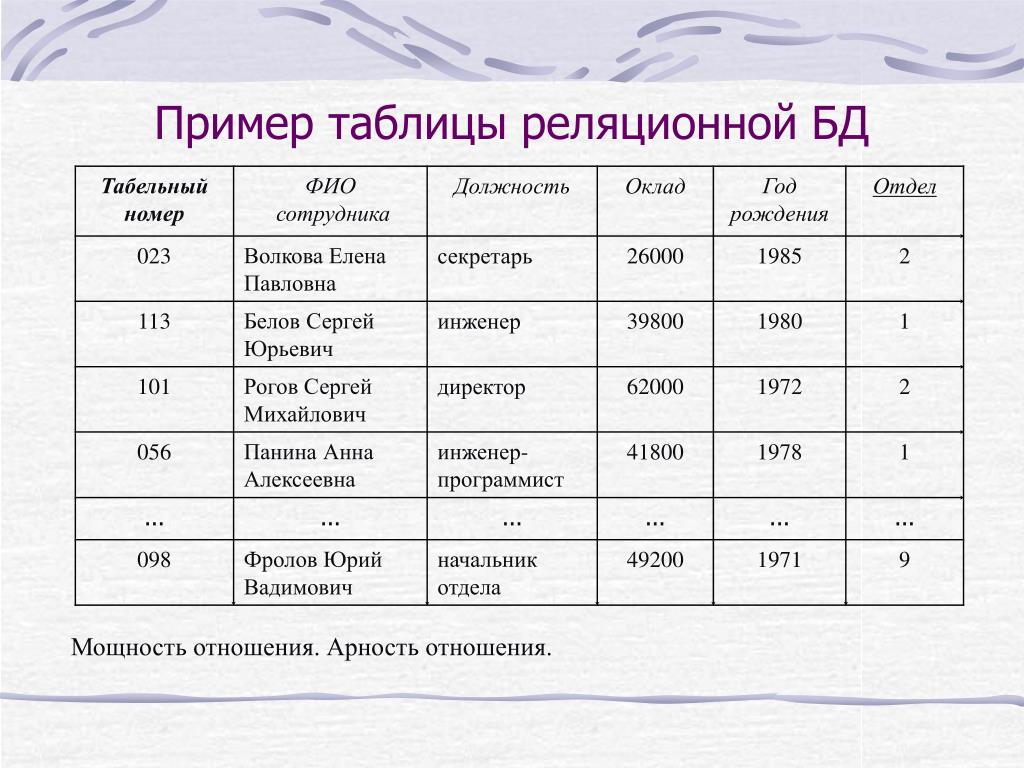 Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
В течение десятилетий центральное место в разработке приложений занимала реляционная модель данных, которая использовалась в реляционных базах данных, таких как Oracle, DB2, SQL Server, MySQL и PostgreSQL. Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Существует множество типов БД NoSQL с различными особенностями, но в таблице ниже приведены основные отличия баз данных NoSQL от SQL.
Начало работы с NoSQL
В следующей таблице приведено сравнение терминологии некоторых баз данных NoSQL с терминологией баз данных SQL.
| SQL | MongoDB | DynamoDB | Cassandra | Couchbase |
|---|---|---|---|---|
| Таблица | Коллекция | Таблица | Таблица | Корзина данных |
| Ряд | Документ | Элемент | Ряд | Документ |
| Столбец | Поле | Атрибут | Столбец | Поле |
| Первичный ключ | ObjectId | Первичный ключ | Первичный ключ | ИД документа |
| Индекс | Индекс | Вторичный индекс | Индекс | Индекс |
| Представление | Представление | Глобальный вторичный индекс | Материализованное представление | Представление |
| Вложенная таблица или объект | Встроенный документ | Карта | Карта | Карта |
| Массив | Массив | Список | Список | Список |
| Список |
| Список |
| Первичный ключ |
Начать работу с DynamoDB очень просто. Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Начать работу с Amazon DynamoDB
What is Amazon DynamoDB?
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- . NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
 NET на AWS
NET на AWSПоддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права
представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Подробнее »
Нереляционные СУБД обзор, сравнение, лучшие продукты, внедрения, поставщики.
Нереляционная база данных — это база данных, не включающая модель таблиц/ключей, которую продвигают системы управления реляционными базами данных (RDBMS). Для таких баз данных требуются методы и процессы манипулирования данными, предназначенные для решения проблем больших данных, с которыми сталкиваются крупные компании. Самая популярная новая нереляционная база данных называется NoSQL (не только SQL).
Для таких баз данных требуются методы и процессы манипулирования данными, предназначенные для решения проблем больших данных, с которыми сталкиваются крупные компании. Самая популярная новая нереляционная база данных называется NoSQL (не только SQL).
Большинство нереляционных баз данных включены в такие веб-сайты, как Google, Yahoo!, Amazon и Facebook. Эти веб-сайты представляют множество новых приложений каждый день с миллионами пользователей, поэтому они не смогут справиться с большими скачками трафика с помощью существующих решений RDBMS. Поскольку СУБД не могут справиться с этой проблемой, они переключились на новый тип СУБД, который способен обрабатывать данные веб-масштаба нереляционным способом.
Интересным аспектом нереляционной базы данных, такой как NoSQL, является масштабируемость. NoSQL использует систему BASE. Нереляционные базы данных отказываются от табличной формы строк и столбцов, которые реляционные базы данных используют в пользу специализированных сред для хранения данных, к которым могут обращаться специальные API-интерфейсы запросов. Постоянство является важным элементом в этих базах данных. Чтобы обеспечить высокую пропускную способность огромных объемов данных, лучшим вариантом для производительности является «в памяти», а не чтение и запись с дисков.
Постоянство является важным элементом в этих базах данных. Чтобы обеспечить высокую пропускную способность огромных объемов данных, лучшим вариантом для производительности является «в памяти», а не чтение и запись с дисков.
Реляционные базы данных используют систему ACID, которая обеспечивает непротиворечивость данных во всех ситуациях управления данными, но, очевидно, требует больше времени для обработки из-за всех этих отношений и ее разветвленной природы. Однако система BASE ослабила требования к согласованности для обеспечения лучшей доступности и разделения для лучшей масштабируемости.
Продукты
Сравнение
Поставщики
Производители
FAQ
Материалы
Производители
Нереляционные СУБД
IBM
Все страны
F.
 A.Q.
A.Q.
Нереляционные СУБД
Что такое базы данных NoSQL?
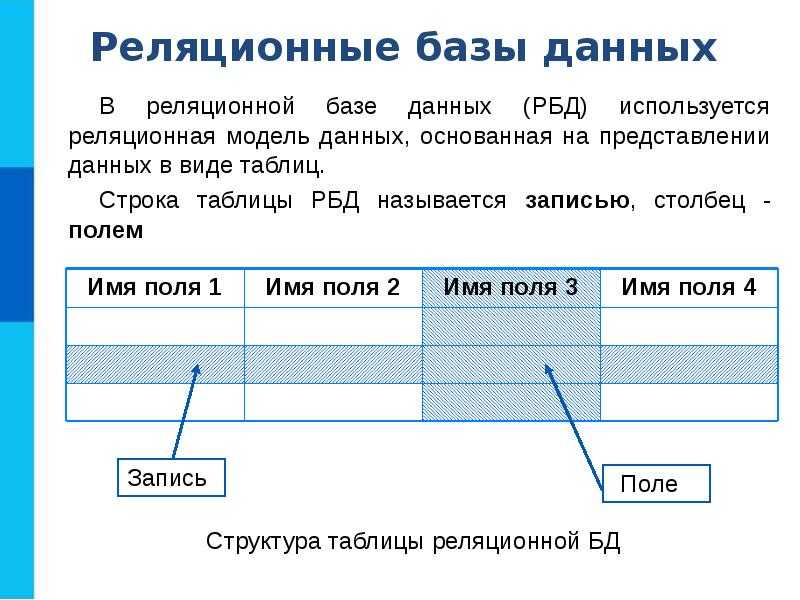
Базы данных NoSQL специально созданы для определенных моделей данных и обладают гибкими схемами, что позволяет разрабатывать современные приложения. Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. В них применяются различные модели данных, в том числе документные, графовые, поисковые, с использованием пар «ключ‑значение» и хранением данных в памяти. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Как работает база данных NoSQL (нереляционная БД)?
В базах данных NoSQL для доступа к данным и управления ими применяются различные модели данных, в том числе документная, графовая, поисковая, с использованием пар «ключ‑значение» и хранением данных в памяти. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
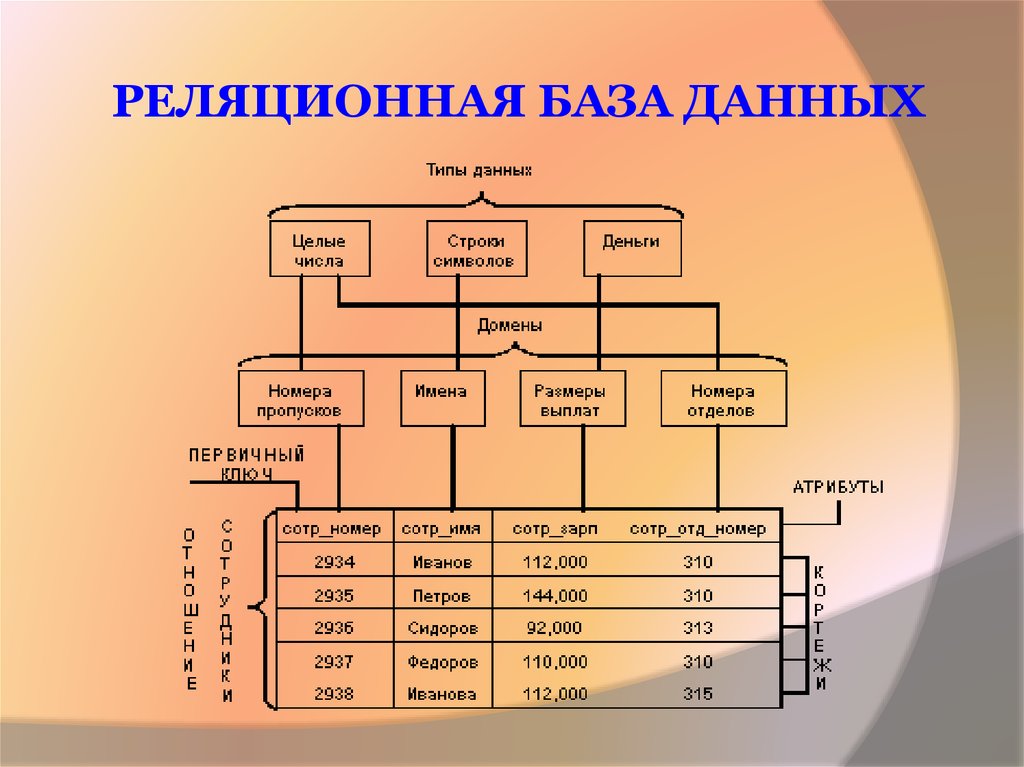
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе. В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
 В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.Для чего можно использовать базы данных NoSQL?
Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации. Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
- Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных (например, документной, графовой или с использованием пар «ключ‑значение») и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.

Каковы типы баз данных NoSQL?
- БД на основе пар «ключ‑значение». Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT.
- Документ. В коде приложения данные часто представлены как объект или документ в формате, подобном JSON, поскольку для разработчиков это эффективная и интуитивная модель данных. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
- Графовые БД. Графовые базы данных упрощают разработку и запуск приложений, работающих с наборами сложносвязанных данных. Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний.
- БД в памяти. Часто в игровых и рекламных приложениях используются таблицы лидеров, хранение сессий и аналитика в реальном времени. Такие возможности требуют отклика в пределах нескольких микросекунд, при этом резкое возрастание трафика возможно в любой момент.
- Поисковые БД. Многие приложения формируют журналы, чтобы разработчикам было проще выявлять и устранять неполадки.
 Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
Вы уверены что хотите удалить ?
Да
Нет
Что такое нереляционная база данных?
Обзор
- Что такое нереляционная база данных?
- Реляционные базы данных
- Нереляционные базы данных
- Преимущества нереляционных баз данных
- Нереляционные базы данных и разработка приложений
Большинство баз данных можно разделить на реляционные и нереляционные. Нереляционные базы данных иногда называют «NoSQL», что означает не только SQL. Основное различие между ними заключается в том, как они хранят свою информацию.
Нереляционная база данных хранит данные в нетабличной форме и имеет тенденцию быть более гибкой, чем традиционная структура реляционной базы данных на основе SQL. Он не следует реляционной модели, предоставляемой традиционными системами управления реляционными базами данных.
Чтобы более подробно объяснить нереляционные базы данных, давайте сначала рассмотрим, что такое традиционная реляционная база данных.
Реляционные базы данных
Реляционная база данных обычно хранит информацию в таблицах, содержащих определенные части и типы данных. Например, магазин может хранить информацию об именах и адресах своих клиентов в одной таблице, а информацию об их заказах — в другой. Эту форму хранения данных часто называют структурированными данными.
Пример таблицы реляционной базы данных клиентов.
Реляционные базы данных используют язык структурированных запросов (SQL). В реляционной базе данных база данных обычно содержит таблицы, состоящие из столбцов и строк. При добавлении новых данных новые записи вставляются в существующие таблицы или добавляются новые таблицы. Затем можно установить отношения между двумя или более таблицами.
Реляционные базы данных работают лучше всего, когда содержащиеся в них данные меняются не очень часто и когда важна точность. Реляционные базы данных, например, часто используются в финансовых приложениях.
Реляционные базы данных, например, часто используются в финансовых приложениях.
Нереляционные базы данных
Нереляционные базы данных (часто называемые базами данных NoSQL) отличаются от традиционных реляционных баз данных тем, что они хранят свои данные в нетабличной форме. Вместо этого нереляционные базы данных могут быть основаны на таких структурах данных, как документы. Документ может быть очень подробным, но содержать ряд различных типов информации в разных форматах. Эта способность усваивать и упорядочивать различные типы информации рядом друг с другом делает нереляционные базы данных гораздо более гибкими, чем реляционные базы данных.
Пример документа MongoDB для пациента в системе здравоохранения.
Нереляционные базы данных часто используются, когда необходимо организовать большие объемы сложных и разнообразных данных. Например, большой магазин может иметь базу данных, в которой у каждого покупателя есть собственный документ, содержащий всю его информацию, от имени и адреса до истории заказов и информации о кредитной карте.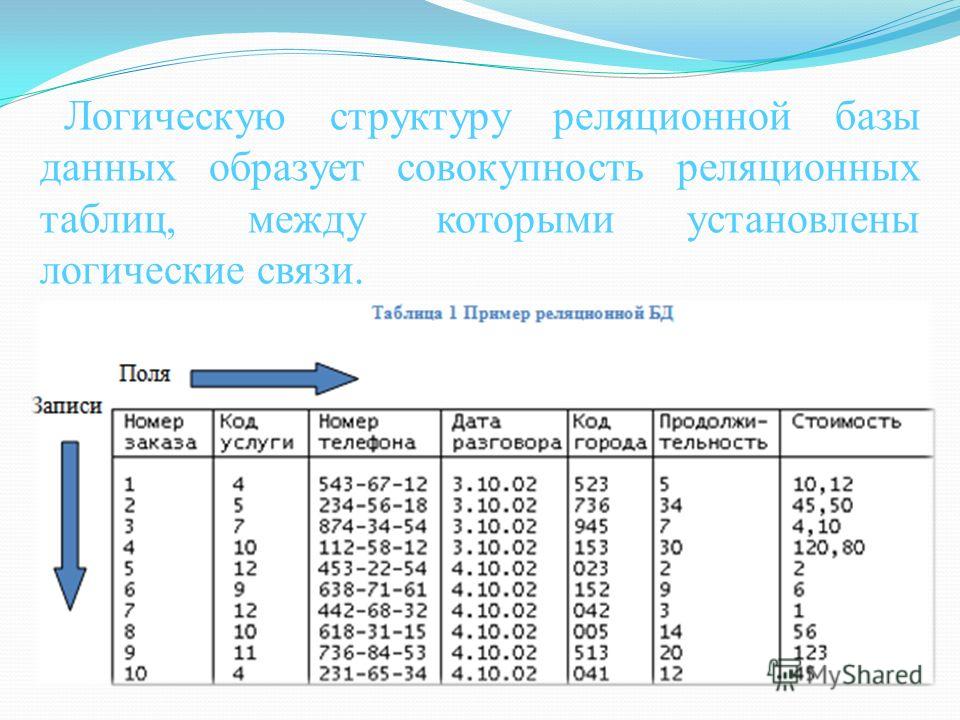 Несмотря на разные форматы, каждая из этих частей информации может храниться в одном и том же документе.
Несмотря на разные форматы, каждая из этих частей информации может храниться в одном и том же документе.
Нереляционные базы данных часто работают быстрее, потому что запросу не нужно просматривать несколько таблиц, чтобы получить ответ, как это часто бывает с реляционными наборами данных. Поэтому нереляционные базы данных идеально подходят для хранения данных, которые могут часто изменяться, или для приложений, обрабатывающих множество различных типов данных. Они могут поддерживать быстро развивающиеся приложения, требующие динамической базы данных, способной быстро изменяться и вмещать большие объемы сложных неструктурированных данных.
При запуске проекта стоит рассмотреть реляционные и нереляционные базы данных с точки зрения их различий, чтобы лучше понять правильное решение для проекта. Вы также можете рассмотреть различные примеры использования обоих, и когда вы можете выбрать один из них.
Преимущества нереляционной базы данных
Современные приложения собирают и хранят все больше и больше сложных данных о клиентах и пользователях. Преимущества этих данных для бизнеса, конечно же, заключаются в их потенциале для анализа. Использование нереляционной базы данных может выявить закономерности и ценность даже в массе разнородных данных.
Преимущества этих данных для бизнеса, конечно же, заключаются в их потенциале для анализа. Использование нереляционной базы данных может выявить закономерности и ценность даже в массе разнородных данных.
Существует несколько преимуществ использования нереляционных баз данных, в том числе:
Массивная организация набора данных
В эпоху больших данных нереляционные базы данных могут не только хранить огромные объемы информации, но и запрашивать эти наборы данных с легкостью. Масштаб и скорость являются решающими преимуществами нереляционных баз данных.
Гибкое расширение базы данных
Данные не статичны. По мере сбора дополнительной информации нереляционная база данных может поглощать эти новые точки данных, обогащая существующую базу данных новыми уровнями детализации, даже если они не соответствуют типам данных ранее существовавшей информации.
Несколько структур данных
Данные, которые теперь собираются от пользователей, принимают множество форм, от чисел и строк до фото- и видеоконтента и истории сообщений.
Базе данных необходима возможность хранить эти различные информационные форматы, понимать отношения между ними и выполнять подробные запросы. Независимо от того, в каком формате находится ваша информация, нереляционные базы данных могут сопоставлять различные типы информации в одном документе.Создано для облака
Нереляционная база данных может быть огромной. И поскольку в некоторых случаях они могут расти в геометрической прогрессии, им нужна среда хостинга, которая может расти и расширяться вместе с ними. Присущая облаку масштабируемость делает его идеальным домом для нереляционных баз данных.
 Базе данных необходима возможность хранить эти различные информационные форматы, понимать отношения между ними и выполнять подробные запросы. Независимо от того, в каком формате находится ваша информация, нереляционные базы данных могут сопоставлять различные типы информации в одном документе.
Базе данных необходима возможность хранить эти различные информационные форматы, понимать отношения между ними и выполнять подробные запросы. Независимо от того, в каком формате находится ваша информация, нереляционные базы данных могут сопоставлять различные типы информации в одном документе.Нереляционные базы данных и разработка приложений
Приложения должны иметь возможность эффективно запрашивать данные и практически мгновенно выдавать результаты. Нереляционные базы данных — естественный выбор для такой среды. Они обеспечивают как безопасность, так и гибкость, позволяя быстро разрабатывать приложения в гибкой среде. Более простые и менее сложные в управлении, чем реляционные базы данных, они также могут обеспечить более низкие затраты на управление данными, обеспечивая при этом превосходную производительность и скорость.
Более простые и менее сложные в управлении, чем реляционные базы данных, они также могут обеспечить более низкие затраты на управление данными, обеспечивая при этом превосходную производительность и скорость.
Нереляционные базы данных, естественно подходящие для гибкой разработки, могут более эффективно обрабатывать сложные входные данные, чем структурированные базы данных. В эпоху возрастающей сложности данных нереляционные базы данных обеспечивают гибкость проектирования баз данных, которая становится все более необходимой. Особенно в сочетании с облаком нереляционные базы данных снимают ограничения на сбор, организацию и анализ ваших данных, позволяя вам получить максимальную отдачу от ваших данных.
Начать бесплатноПодробнее
Что такое NoSQL и зачем он вам нужен?
NoSQL (не только SQL) — это любая система баз данных, которая не соответствует структуре таблиц и строк, образующей реляционные базы данных.
Они более гибкие, масштабируемые и часто разрабатываются с учетом облачных технологий. Чтобы узнать больше, есть статья, в которой обсуждаются преимущества NoSQL или нереляционных баз данных.
Чтобы узнать больше, есть статья, в которой обсуждаются преимущества NoSQL или нереляционных баз данных.
Реляционные базы данных и нереляционные базы данных
Я вижу много путаницы в отношении места и назначения многих новых решений для баз данных («баз данных NoSQL») по сравнению с решениями для реляционных баз данных, которые существуют уже много лет. Итак, позвольте мне попытаться объяснить различия и лучшие варианты использования для каждого из них.
Сначала давайте разделим эти решения для баз данных на две группы:
1) Реляционные базы данных , которые также можно назвать системами управления реляционными базами данных (RDBMS) или базами данных SQL. Наиболее популярными из них являются Microsoft SQL Server, Oracle Database, MySQL и IBM DB2. Эти СУБД в основном используются в сценариях крупных предприятий, за исключением MySQL, которая в основном используется для хранения данных для веб-приложений, как правило, как часть популярного стека LAMP (Linux, Apache, MySQL, PHP/Python/Perl).
2) Нереляционные базы данных , также называемые базами данных NoSQL, наиболее популярными из которых являются MongoDB, DocumentDB, Cassandra, Coachbase, HBase, Redis и Neo4j. Эти базы данных обычно группируются в четыре категории: хранилища ключей и значений, хранилища графов, хранилища столбцов и хранилища документов (см. Типы баз данных NoSQL).
Все реляционные базы данных можно использовать для управления приложениями, ориентированными на транзакции (OLTP), и большинство нереляционных баз данных, относящихся к категориям «Хранилища документов» и «Хранилища столбцов», также можно использовать для OLTP, что еще больше усугубляет путаницу. Базы данных OLTP можно рассматривать как «операционные» базы данных, характеризующиеся частыми короткими транзакциями, которые включают обновления и касаются небольшого объема данных, и где очень важно одновременное выполнение тысяч транзакций (примеры включают банковские приложения и онлайн-бронирование). Целостность данных очень важна, поэтому они поддерживают транзакции ACID (атомарность, согласованность, изоляция, надежность). Это отличается от хранилищ данных, которые считаются «аналитическими» базами данных, характеризующимися длинными и сложными запросами, затрагивающими большой объем данных и требующими много ресурсов. Обновления нечастые. Примером может служить анализ продаж за последний год.
Целостность данных очень важна, поэтому они поддерживают транзакции ACID (атомарность, согласованность, изоляция, надежность). Это отличается от хранилищ данных, которые считаются «аналитическими» базами данных, характеризующимися длинными и сложными запросами, затрагивающими большой объем данных и требующими много ресурсов. Обновления нечастые. Примером может служить анализ продаж за последний год.
Реляционные базы данных обычно работают со структурированными данными, а нереляционные базы данных обычно работают с полуструктурированными данными (например, XML, JSON).
Рассмотрим каждую группу более подробно:
Реляционные базы данных
Реляционная база данных организована на основе реляционной модели данных, предложенной Э. Ф. Коддом в 1970 году. Эта модель организует данные в одну или несколько таблиц (или » отношения») строк и столбцов с уникальным ключом для каждой строки. Как правило, каждый тип объекта, описанный в базе данных, имеет свою собственную таблицу со строками, представляющими экземпляры этого типа объекта, и столбцами, представляющими значения, атрибутированные этому экземпляру. Поскольку каждая строка в таблице имеет свой собственный уникальный ключ, строки в таблице могут быть связаны со строками в других таблицах путем сохранения уникального ключа строки, с которой она должна быть связана (где такой уникальный ключ известен как «внешний ключ»). »). Кодд показал, что отношения данных произвольной сложности могут быть представлены с помощью этого простого набора понятий.
Поскольку каждая строка в таблице имеет свой собственный уникальный ключ, строки в таблице могут быть связаны со строками в других таблицах путем сохранения уникального ключа строки, с которой она должна быть связана (где такой уникальный ключ известен как «внешний ключ»). »). Кодд показал, что отношения данных произвольной сложности могут быть представлены с помощью этого простого набора понятий.
Практически все системы реляционных баз данных используют SQL (язык структурированных запросов) в качестве языка запросов и обслуживания базы данных.
Причинами доминирования реляционных баз данных являются: простота, надежность, гибкость, производительность, масштабируемость и совместимость при управлении общими данными.
Но чтобы предложить все это, реляционные базы данных должны быть невероятно сложными внутри. Например, относительно простой оператор SELECT может иметь десятки потенциальных путей выполнения запроса, которые оптимизатор запросов будет оценивать во время выполнения. Все это скрыто от пользователей, но под капотом РСУБД определяет лучший «план выполнения» для ответа на запросы, используя такие вещи, как алгоритмы на основе затрат.
Все это скрыто от пользователей, но под капотом РСУБД определяет лучший «план выполнения» для ответа на запросы, используя такие вещи, как алгоритмы на основе затрат.
Для больших баз данных, особенно тех, которые используются для веб-приложений, основной проблемой является масштабируемость. Поскольку все больше и больше приложений создается в средах с большими рабочими нагрузками (например, Amazon), их требования к масштабируемости могут очень быстро меняться и становиться очень большими. Реляционные базы данных хорошо масштабируются, но обычно только тогда, когда это масштабирование происходит на одном сервере («масштабирование»). Когда мощность этого единственного сервера будет достигнута, вам необходимо «масштабировать» и распределять эту нагрузку между несколькими серверами, переходя к так называемым распределенным вычислениям. Это когда сложность реляционных баз данных начинает вызывать проблемы с их потенциалом масштабирования. Если вы попытаетесь масштабироваться до сотен или тысяч серверов, сложности станут огромными.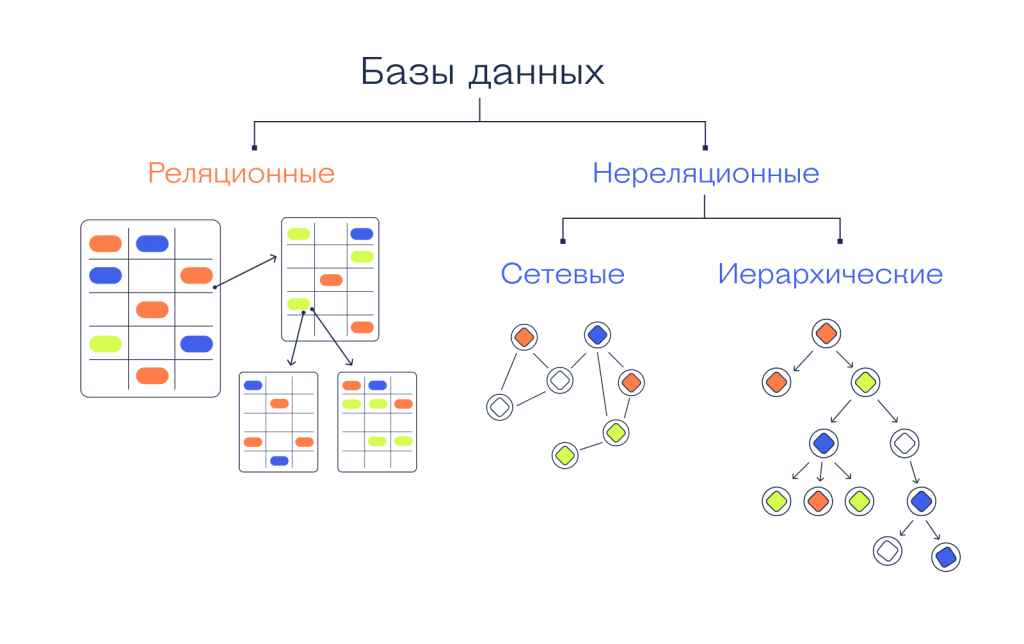 Характеристики, которые делают реляционные базы данных такими привлекательными, резко снижают их жизнеспособность в качестве платформ для больших распределенных систем.
Характеристики, которые делают реляционные базы данных такими привлекательными, резко снижают их жизнеспособность в качестве платформ для больших распределенных систем.
Нереляционные базы данных
База данных NoSQL предоставляет механизм для хранения и извлечения данных, которые моделируются средствами, отличными от табличных отношений, используемых в реляционных базах данных.
Мотивы для этого подхода включают:
- Простота конструкции . Отсутствие необходимости иметь дело с «несоответствием импеданса» между объектно-ориентированным подходом к написанию приложений и таблицами и строками на основе схемы реляционной базы данных. Например, хранение всей информации о заказах клиентов в одном документе вместо объединения множества таблиц вместе приводит к меньшему количеству кода для написания, отладки и обслуживания
- Улучшенное «горизонтальное» масштабирование до кластеров машин, что решает проблему резкого увеличения числа одновременных пользователей для приложений, доступных через Интернет и мобильные устройства. Использование документов значительно упрощает масштабирование, поскольку вся информация для этого заказа клиента содержится в одном месте, а не разбросана по нескольким таблицам. Базы данных NoSQL автоматически распределяют данные по серверам, не требуя внесения изменений в приложение (автоматическое сегментирование), что означает, что они естественным образом и автоматически распределяют данные по произвольному количеству серверов, даже не требуя, чтобы приложение знало о составе пула серверов. Загрузка данных и запросов автоматически распределяется между серверами, и когда сервер выходит из строя, его можно быстро и прозрачно заменить без прерывания работы приложений
- Более точный контроль доступности . Серверы можно добавлять или удалять без остановки приложений. Большинство баз данных NoSQL поддерживают репликацию данных, сохраняя несколько копий данных в кластере или даже в центрах обработки данных, чтобы обеспечить высокую доступность и аварийное восстановление
- Для простого захвата всех видов данных «больших данных» , включая неструктурированные и частично структурированные данные. Обеспечение гибкой базы данных, которая может легко и быстро вместить любой новый тип данных и не нарушается изменениями структуры содержимого. Это связано с тем, что база данных документов не имеет схемы, что позволяет свободно добавлять поля в документы JSON без необходимости предварительного определения изменений (схема при чтении вместо схемы при записи). У вас могут быть документы с другим количеством полей, чем в других документах. Например, запись пациента, которая может содержать или не содержать поля со списком аллергий
- Скорость. Структуры данных, используемые базами данных NoSQL (т. е. документы JSON), отличаются от структур данных, используемых по умолчанию в реляционных базах данных, что делает многие операции в NoSQL быстрее, чем в реляционных базах данных, благодаря отсутствию необходимости объединения таблиц (за счет увеличения объема памяти из-за дублирования данных — но место для хранения сейчас настолько дешевое, что обычно это не проблема). Фактически, большинство баз данных NoSQL даже не поддерживают соединения
- Стоимость . Базы данных NoSQL обычно используют кластеры дешевых серверов, в то время как РСУБД, как правило, полагаются на дорогие проприетарные серверы и системы хранения. Кроме того, лицензии для систем РСУБД могут быть довольно дорогими, в то время как многие базы данных NoSQL имеют открытый исходный код и, следовательно, бесплатны.0006
 Использование документов значительно упрощает масштабирование, поскольку вся информация для этого заказа клиента содержится в одном месте, а не разбросана по нескольким таблицам. Базы данных NoSQL автоматически распределяют данные по серверам, не требуя внесения изменений в приложение (автоматическое сегментирование), что означает, что они естественным образом и автоматически распределяют данные по произвольному количеству серверов, даже не требуя, чтобы приложение знало о составе пула серверов. Загрузка данных и запросов автоматически распределяется между серверами, и когда сервер выходит из строя, его можно быстро и прозрачно заменить без прерывания работы приложений
Использование документов значительно упрощает масштабирование, поскольку вся информация для этого заказа клиента содержится в одном месте, а не разбросана по нескольким таблицам. Базы данных NoSQL автоматически распределяют данные по серверам, не требуя внесения изменений в приложение (автоматическое сегментирование), что означает, что они естественным образом и автоматически распределяют данные по произвольному количеству серверов, даже не требуя, чтобы приложение знало о составе пула серверов. Загрузка данных и запросов автоматически распределяется между серверами, и когда сервер выходит из строя, его можно быстро и прозрачно заменить без прерывания работы приложений.
 Фактически, большинство баз данных NoSQL даже не поддерживают соединения
Фактически, большинство баз данных NoSQL даже не поддерживают соединения.
Конкретная пригодность данной базы данных NoSQL зависит от проблемы, которую она должна решить.
Базы данных NoSQL все чаще используются в больших данных и веб-приложениях реального времени. Они стали популярными с появлением Интернета, когда базы данных увеличились с нескольких сотен пользователей во внутреннем приложении компании до тысяч или миллионов пользователей в веб-приложении. Системы NoSQL также называют «не только SQL», чтобы подчеркнуть, что они также могут поддерживать языки запросов, подобные SQL.
Многие NoSQL хранят компромиссную согласованность (в смысле теоремы CAP) в пользу доступности и устойчивости к разделам.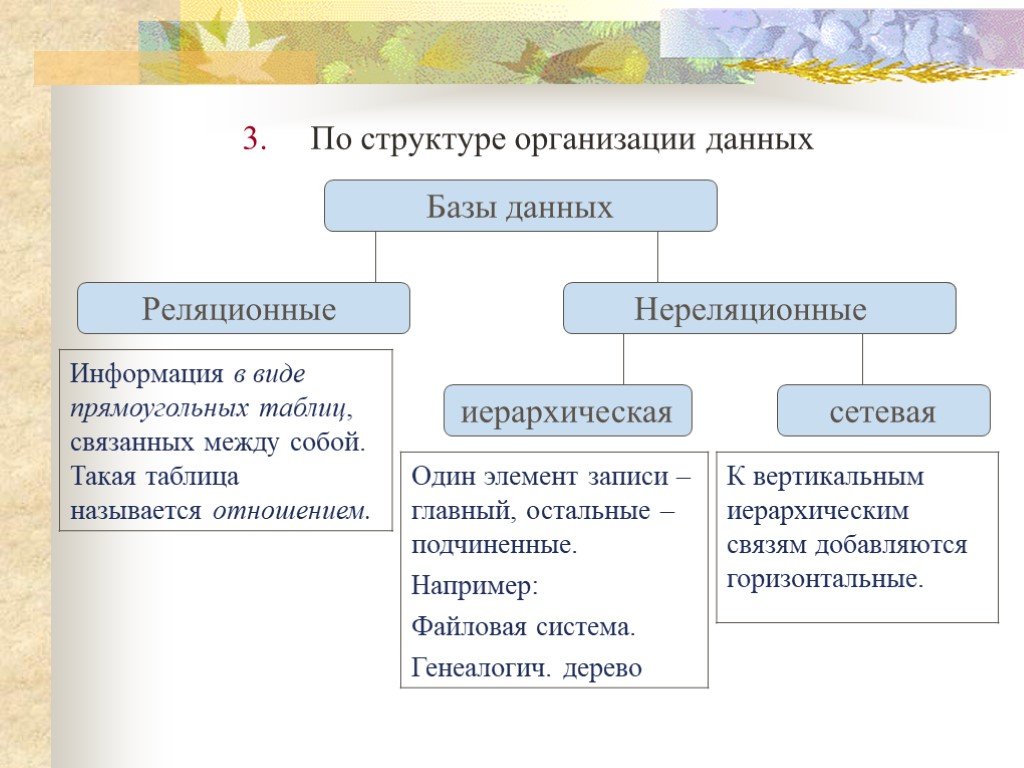 Некоторые причины, препятствующие внедрению хранилищ NoSQL, включают использование низкоуровневых языков запросов, отсутствие стандартизированных интерфейсов и огромные инвестиции в существующий SQL. Кроме того, в большинстве хранилищ NoSQL отсутствуют настоящие транзакции ACID или они поддерживают транзакции только при определенных обстоятельствах и на определенных уровнях (например, на уровне документов). Наконец, СУБД обычно намного проще в использовании, поскольку они имеют графический интерфейс, тогда как многие решения NoSQL используют интерфейс командной строки.
Некоторые причины, препятствующие внедрению хранилищ NoSQL, включают использование низкоуровневых языков запросов, отсутствие стандартизированных интерфейсов и огромные инвестиции в существующий SQL. Кроме того, в большинстве хранилищ NoSQL отсутствуют настоящие транзакции ACID или они поддерживают транзакции только при определенных обстоятельствах и на определенных уровнях (например, на уровне документов). Наконец, СУБД обычно намного проще в использовании, поскольку они имеют графический интерфейс, тогда как многие решения NoSQL используют интерфейс командной строки.
Сравнение двух
Одним из наиболее серьезных ограничений реляционных баз данных является то, что каждый элемент может содержать только один атрибут. Если мы возьмем пример с банком, каждый аспект отношений клиента с банком хранится в виде отдельных строк в отдельных таблицах. Таким образом, основные сведения о клиенте находятся в одной таблице, сведения о счете — в другой таблице, сведения о кредите — в еще одной, инвестиции — в другой таблице и так далее. Все эти таблицы связаны друг с другом с помощью таких отношений, как первичные и внешние ключи.
Все эти таблицы связаны друг с другом с помощью таких отношений, как первичные и внешние ключи.
Нереляционные базы данных, в частности хранилища базы данных «ключ-значение» или пары «ключ-значение», радикально отличаются от этой модели. Пары ключ-значение позволяют хранить несколько связанных элементов в одной «строке» данных в одной таблице. Мы поместили слово «строка» в кавычки, потому что строка здесь на самом деле не то же самое, что строка реляционной таблицы. Например, в нереляционной таблице для одного и того же банка каждая строка будет содержать данные клиента, а также данные его счета, кредита и инвестиций. Все данные, относящиеся к одному клиенту, удобно хранить вместе в виде одной записи.
Этот метод хранения данных кажется явно лучшим, но у него есть существенный недостаток: хранилища пар «ключ-значение», в отличие от реляционных баз данных, не могут обеспечивать связь между элементами данных. Например, в нашей базе данных «ключ-значение» сведения о клиенте (имя, социальное обеспечение, адрес, номер счета, номер обработки кредита и т. д.) будут храниться как одна запись данных (вместо хранения в нескольких таблицах, как в реляционная модель). Транзакции клиента (снятие средств со счета, пополнение счета, погашение кредита, банковские сборы и т. д.) также будут храниться в виде еще одной отдельной записи данных.
д.) будут храниться как одна запись данных (вместо хранения в нескольких таблицах, как в реляционная модель). Транзакции клиента (снятие средств со счета, пополнение счета, погашение кредита, банковские сборы и т. д.) также будут храниться в виде еще одной отдельной записи данных.
В реляционной модели имеется встроенный и надежный метод обеспечения и обеспечения соблюдения бизнес-логики и правил на уровне базы данных, например, снятие средств списывается с правильного банковского счета с помощью первичных и внешних ключей. В хранилищах «ключ-значение» эта ответственность полностью ложится на логику приложения, и многим людям очень неудобно возлагать эту важнейшую ответственность только на приложение. Это одна из причин, по которой реляционные базы данных будут продолжать использоваться.
Однако, когда речь идет о веб-приложениях, использующих базы данных, аспект строгого соблюдения бизнес-логики часто не является главным приоритетом. Наивысшим приоритетом является возможность обслуживания большого количества пользовательских запросов, которые обычно являются запросами только для чтения. Например, на таком сайте, как eBay, большинство пользователей просто просматривают размещенные элементы (операции только для чтения). Только часть этих пользователей фактически делает ставки или резервирует товары (операции чтения-записи). И помните, речь идет о миллионах, а иногда и миллиардах просмотров страниц в день. Администраторы сайта eBay больше заинтересованы в быстром времени отклика, чтобы обеспечить более быструю загрузку страниц для пользователей сайта, а не в традиционных приоритетах соблюдения бизнес-правил или обеспечения баланса между чтением и записью.
Например, на таком сайте, как eBay, большинство пользователей просто просматривают размещенные элементы (операции только для чтения). Только часть этих пользователей фактически делает ставки или резервирует товары (операции чтения-записи). И помните, речь идет о миллионах, а иногда и миллиардах просмотров страниц в день. Администраторы сайта eBay больше заинтересованы в быстром времени отклика, чтобы обеспечить более быструю загрузку страниц для пользователей сайта, а не в традиционных приоритетах соблюдения бизнес-правил или обеспечения баланса между чтением и записью.
Базы данных реляционной модели могут быть изменены и настроены для выполнения крупномасштабных операций только для чтения через хранилище данных и, таким образом, потенциально обслуживать большое количество пользователей, которые запрашивают большой объем данных, особенно при использовании реляционных архитектур MPP, таких как Analytics Platform System, Teradata, Oracle Exadata или IBM Netezza, которые поддерживают масштабирование.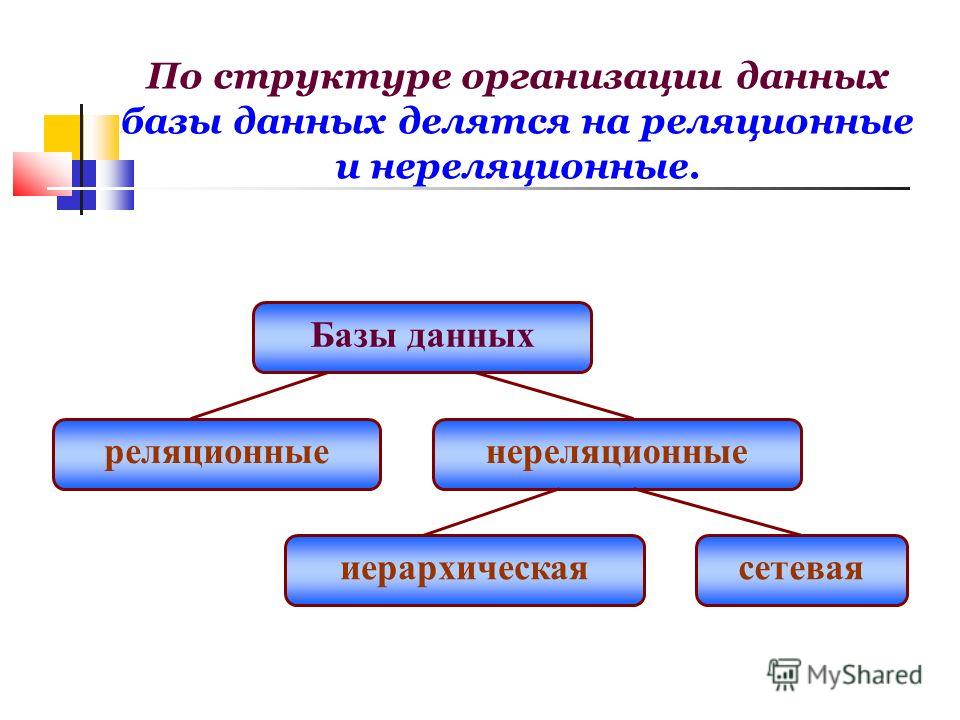 Как упоминалось ранее, хранилища данных отличаются от обычных баз данных тем, что они используются для более сложного анализа данных. Это отличается от базы данных транзакций (OLTP), которая в основном используется для поддержки операционных систем и предоставления повседневных отчетов небольшого масштаба.
Как упоминалось ранее, хранилища данных отличаются от обычных баз данных тем, что они используются для более сложного анализа данных. Это отличается от базы данных транзакций (OLTP), которая в основном используется для поддержки операционных систем и предоставления повседневных отчетов небольшого масштаба.
Однако реальная проблема заключается в недостаточной масштабируемости реляционной модели при работе с приложениями OLTP или любым решением с большим количеством отдельных операций записи, что является областью применения реляционных архитектур SMP. Вот где нереляционные модели действительно могут проявить себя. Они могут легко распределять свои данные по десяткам, сотням, а в крайних случаях (подумайте о поиске Google) даже по тысячам серверов. Поскольку каждый сервер обрабатывает лишь небольшой процент от общего числа запросов от пользователей, время отклика для каждого отдельного пользователя очень хорошее. Хотя эта модель распределенных вычислений может быть построена для реляционных баз данных, реализовать ее очень сложно, особенно при большом количестве операций записи (т. Это связано с тем, что реляционная модель настаивает на целостности данных на всех уровнях, которую необходимо поддерживать, даже если к данным обращаются и изменяют несколько разных серверов. Это причина выбора нереляционной модели в качестве архитектуры для веб-приложений, таких как облачные вычисления и социальные сети.
Это связано с тем, что реляционная модель настаивает на целостности данных на всех уровнях, которую необходимо поддерживать, даже если к данным обращаются и изменяют несколько разных серверов. Это причина выбора нереляционной модели в качестве архитектуры для веб-приложений, таких как облачные вычисления и социальные сети.
Таким образом, реляционные СУБД страдают от отсутствия горизонтального масштабирования при высоких транзакционных нагрузках (миллионы операций чтения-записи), в то время как базы данных NoSQL решают высокие транзакционные нагрузки, но за счет целостности данных и объединений.
Имейте в виду, что во многих решениях будет использоваться комбинация реляционных и нереляционных баз данных (см. Что такое постоянство Polyglot?).
Также имейте в виду, что вам может не понадобиться производительность нереляционной базы данных, и вместо этого будет достаточно просто хранить файлы в HDFS и использовать Apache Hive (Apache Hive — это инфраструктура хранилища данных, созданная поверх Hadoop для обеспечения обобщение данных, запрос и анализ, которые он обеспечивает с помощью SQL-подобного языка, называемого HiveQL).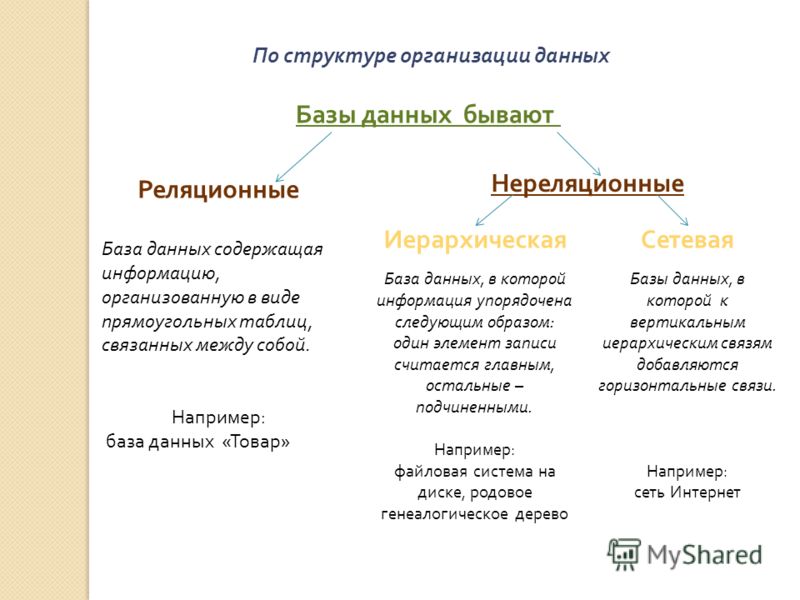
И в заключение примечание, которое добавляет путаницы, у нас есть еще одна формирующаяся категория, называемая NewSQL: NewSQL — это класс современных СУБД, которые стремятся обеспечить такую же масштабируемую производительность систем NoSQL для рабочих нагрузок чтения-записи OLTP, сохраняя при этом ACID гарантирует традиционную систему реляционных баз данных. Недостатком является то, что они не предназначены для запросов в стиле OLAP и не подходят для баз данных размером более нескольких терабайт. Примеры включают VoltDB, NuoDB, MemSQL, SAP HANA, Splice Machine, Clustrix и Altibase.
Рисунок, показывающий категории, к которым относятся многие продукты:
Отличный рисунок, показывающий, как все технологии подходят для облака Azure, взят из Understanding NoSQL on Microsoft Azure:
Суть использования решение NoSQL подходит, если у вас есть приложение OLTP с тысячами пользователей и очень большой базой данных, требующей масштабируемого решения, и/или использующее данные JSON, в частности, если эти данные JSON имеют различные структуры.