| FATAL | |
| CONNECT_FAILED | Роботы не смогли посетить сайт. Ошибка может быть связана, например, с настройками сервера или высокой нагрузкой. |
| DISALLOWED_IN_ROBOTS | Сайт закрыт от индексирования в файле robots.txt. |
| DNS_ERROR | Не удалось подключиться к серверу из-за ошибки DNS. |
| MAIN_PAGE_ERROR | Главная страница сайта возвращает ошибку. |
| THREATS | Обнаружены нарушения или проблемы с безопасностью. |
| TURBO_FEED_BAN | Источник Турбо-страниц не соответствует требованиям: контент Турбо-страниц должен совпадать с контентом оригинальных страниц. Турбо-страницы пропадут из поиска в течение трех дней. Вместо них будут отображаться оригинальные версии страниц. |
| CRITICAL | |
| INSIGNIFICANT_CGI_PARAMETER | На вашем сайте некоторые страницы с GET-параметрами в URL дублируют содержимое других страниц (без GET-параметров). Подробно см. Дублирование страниц. |
| SLOW_AVG_RESPONSE_TIME | Долгий ответ сервера. Подробно см. в Справке. |
| SSL_CERTIFICATE_ERROR | Некорректная настройка SSL-сертификата. Подробно см. в Справке. Подробно см. в Справке. |
| TURBO_HOST_BAN | Турбо-страницы сайта не соответствуют требованиям: контент Турбо-страниц должен совпадать с контентом оригинальных страниц. |
| TURBO_INVALID_CART_URL | Переход с Турбо-страниц в корзину отключен, так как на сайте в настройках добавления товара в корзину обнаружена ошибка. |
| TURBO_RSS_ERROR | В вашем RSS-канале, используемом для формирования Турбо-страниц, обнаружены ошибки, которые мешают обновлению. Для формирования Турбо-страниц будет использоваться предыдущая версия канала. |
| TURBO_URL_ERRORS | Турбо-страницы вашего сайта не попали в поиск. Чтобы страницы смогли участвовать в поиске, исправьте ошибки. Подробно см. Часто встречающиеся ошибки. Подробно см. Часто встречающиеся ошибки. |
| TURBO_YML_ERROR | В вашем YML-файле, используемом для формирования Турбо-страниц, обнаружены ошибки, которые мешают обновлению. Для формирования Турбо-страниц будет использоваться предыдущая версия файла. |
| URL_ALERT_4XX | Некоторые страницы сайта отвечают роботу HTTP-кодом 4xx в течение часа. Подробно см. Коды 4xx (ошибка клиента). |
| URL_ALERT_5XX | Некоторые страницы сайта отвечают роботу HTTP-кодом 5xx в течение часа. Подробно см. Коды 5xx (ошибка сервера). |
| POSSIBLE_PROBLEM | |
| DISALLOWED_URLS_ALERT | Найдены полезные страницы, закрытые от индексирования. |
| DOCUMENTS_MISSING_DESCRIPTION | На многих страницах отсутствует метатег Description. |
| DOCUMENTS_MISSING_TITLE | На многих страницах отсутствует элемент title. |
| DUPLICATE_CONTENT_ATTRS | На некоторых страницах вашего сайта указаны одинаковые title и Description. |
| DUPLICATE_PAGES | Некоторые страницы вашего сайта содержат одинаковый контент. |
| ERROR_IN_ROBOTS_TXT | Ошибки в файле robots.txt. |
| ERRORS_IN_SITEMAPS | Обнаружены ошибки в файлах Sitemap. |
| FAVICON_ERROR | На сайте недоступен файл favicon. |
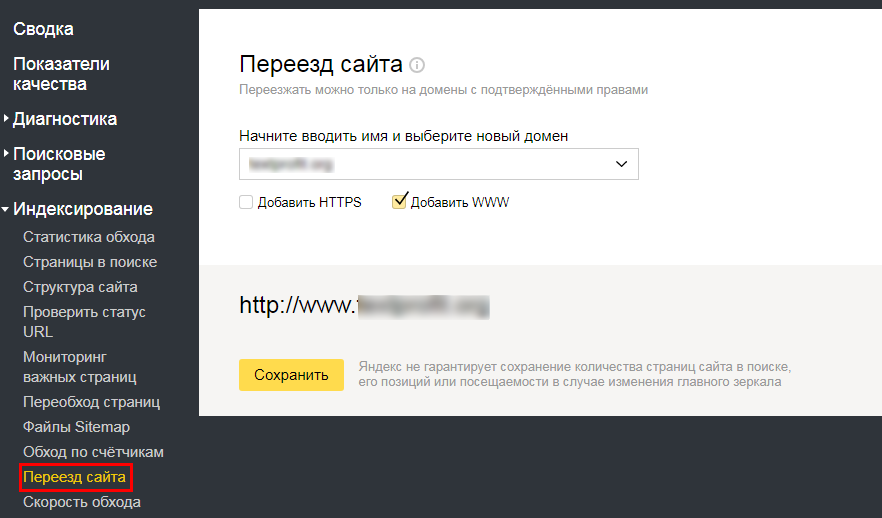
| MAIN_MIRROR_IS_NOT_HTTPS | Главное зеркало сайта не использует HTTPS-протокол. Рекомендуем использовать протокол HTTPS. Подробную информацию и инструкцию по переходу см. в Справке. |
| MAIN_PAGE_REDIRECTS | Главная страница перенаправляет на другой сайт. |
| NO_METRIKA_COUNTER_BINDING | К сайту не привязан счётчик Яндекс Метрики. |
| NO_METRIKA_COUNTER_CRAWL_ENABLED | Не включен обход по счетчикам Яндекс Метрики. Подробно об индексировании сайта с помощью счетчика читайте в Справке. |
| NO_ROBOTS_TXT | Не найден файл robots.txt. |
| NO_SITEMAPS | Нет используемых роботом файлов Sitemap. |
| NO_SITEMAP_MODIFICATIONS | Файлы Sitemap давно не обновлялись. |
| NON_WORKING_VIDEO | Робот не смог проиндексировать видео, размеченные на сайте. |
| SOFT_404 | Некорректно настроено отображение несуществующих файлов и страниц. |
| TOO_MANY_DOMAINS_ON_SEARCH | В результатах поиска найдены поддомены сайта. |
| TURBO_HOST_BAN_INFO | Турбо-страницы и оригинальные страницы сайта должны быть максимально близки по контенту. |
| TURBO_LISTING_ERROR | На сайте возникли ошибки при формировании листингов для Турбо-страниц. |
| TURBO_RSS_WARNING | В RSS-канале, используемом для создания Турбо-страниц, были найдены ошибки. Это может привести к неполному отображению Турбо-страниц в результатах поиска. |
| TURBO_YML_WARNING | В YML-файле, используемом для создания Турбо-страниц, были найдены ошибки. Это может привести к неполному отображению Турбо-страниц в результатах поиска. |
| VIDEOHOST_OFFER_FAILED | Добавленное в Вебмастер пользовательское соглашение для отображения видео отклонено. |
| VIDEOHOST_OFFER_IS_NEEDED | Для сайта отсутствует пользовательское соглашение для отображения видео. |
| VIDEOHOST_OFFER_NEED_PAPER | Для сайта необходимо заключить специальное соглашение для сотрудничества с Яндексом. |
| RECOMMENDATION | |
| BIG_FAVICON_ABSENT | Добавьте на сайт файл favicon в формате SVG или размером 120 × 120 пикселей. В таком формате логотип вашего сайта станет четче и заметнее на сервисах Яндекса, в том числе, в результатах поиска. |
| FAVICON_PROBLEM | Файл favicon не найден. Робот не смог загрузить файл с изображением, которое должно отображаться во вкладке браузера и может быть показано возле названия сайта в поиске. Подробнее о причинах и исправлении ошибки см. в Справке. |
| NO_METRIKA_COUNTER | Ошибка счетчика Яндекс Метрики. |
| NO_REGIONS | Не задана региональная принадлежность сайта. |
| NOT_IN_SPRAV | Сайт не зарегистрирован в Яндекс Справочнике. |
| NOT_MOBILE_FRIENDLY | Сайт не оптимизирован для мобильных устройств. |
| SPRAV_COMPANY_PROFILE_CREATED | Алгоритмы Яндекс Бизнеса посчитали, что ваш сайт очень похож на сайт компании, поэтому создали на его основе карточку организации. Проверьте, что данные заполнены корректно. После подтверждения данных карточка будет размещена в результатах поиска и на Яндекс Картах. |
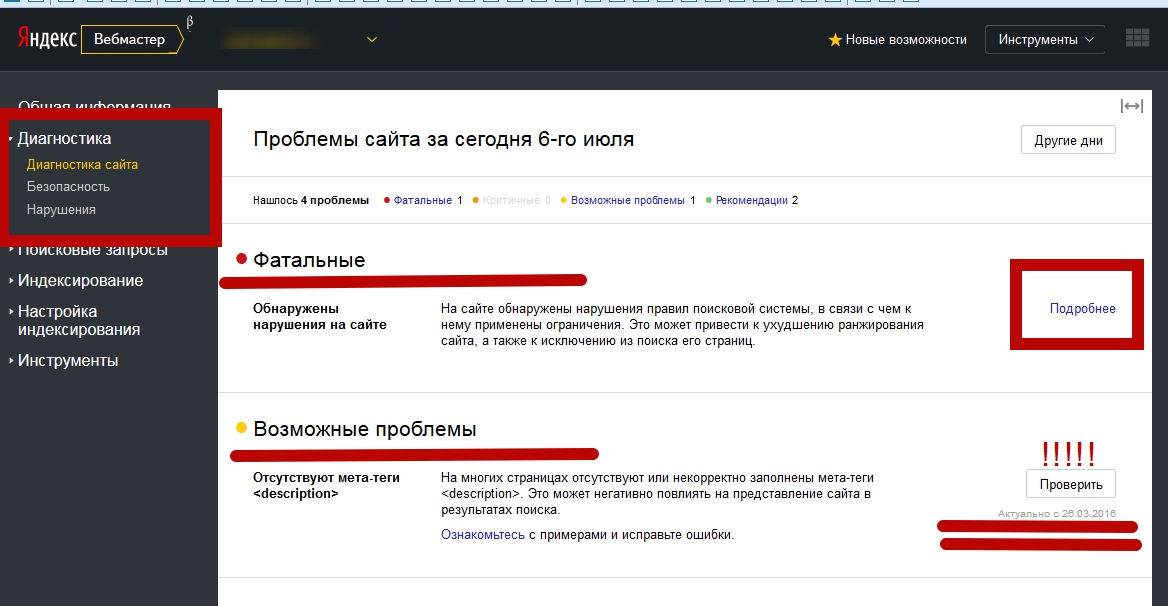
Возможные проблемы — Вебмастер. Справка
Раздел содержит решения часто встречающихся проблем категории «Возможные», выявленных при диагностике сайта в
Вебмастере. Проблемы этой группы могут влиять на качество и скорость индексирования страниц сайта.
Проблемы этой группы могут влиять на качество и скорость индексирования страниц сайта.
Совет. Настройте уведомления о результатах проверки сайта.
- Не найден файл robots.txt
- Обнаружены ошибки в файле robots.txt
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Некорректно настроено отображение несуществующих или удаленных файлов и страниц
- Отсутствуют элемент title и метатег description
- На страницах есть одинаковые заголовки и описания
- Файл favicon недоступен для робота
Несколько раз в сутки индексирующий робот запрашивает файл robots.txt и обновляет информацию о нем в своей базе. Если при очередном обращении робот не может загрузить файл, в
Вебмастере появляется соответствующее предупреждение.
В сервисе проверьте доступность файла robots.txt. Если файл по-прежнему недоступен, добавьте его. Если вы не можете сделать это самостоятельно, обратитесь к хостинг-провайдеру или регистратору доменного имени. После добавления файла данные в Вебмастере обновляются в течение нескольких дней.
После добавления файла данные в Вебмастере обновляются в течение нескольких дней.
Проверьте файл robots.txt вашего сайта. Чтобы исправить ошибки, посмотрите описания директив.
Файл Sitemap является вспомогательным инструментом при индексировании сайта, он позволяет регулярно сообщать роботу о появлении новых страниц на сайте. Данное предупреждение появляется, если робот не использует ни одного файла Sitemap для сайта.
Чтобы робот начал использовать созданный файл, добавьте его в Вебмастер и дождитесь обработки файла роботом. Обычно на это требуется до двух недель. После этого предупреждение пропадет.
Проверьте файл Sitemap вашего сайта. Проверка может выявить ошибку «Неизвестный тег». Она сообщает, что файл содержит неподдерживаемые Яндексом элементы. Такие элементы игнорируются роботом при обработке Sitemap, но данные из поддерживаемых элементов учитываются. Поэтому менять содержимое файла необязательно. Подробнее о поддерживаемых элементах Sitemap.
Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 (ресурс не найден/Not Found). В таком случае поисковый робот может при переходе на сайт по любой ссылке получить ответ 200 ОК и проиндексировать несуществующую страницу. Это приведет к большому количеству дублированных страниц, что усложнит и замедлит индексирование сайта и увеличит нагрузку на сервер.
В таком случае поисковый робот может при переходе на сайт по любой ссылке получить ответ 200 ОК и проиндексировать несуществующую страницу. Это приведет к большому количеству дублированных страниц, что усложнит и замедлит индексирование сайта и увеличит нагрузку на сервер.
Чтобы проверить ответ сервера, воспользуйтесь инструментом Проверка состояния страницы. Введите адрес несуществующей на вашем сайте страницы. Можно использовать произвольный набор букв и цифр, например https://example.com/kugbkkrfck.
Если настроить рекомендуемый код ответа 404 нет возможности:
Настройте любой другой код 4xx, кроме 429.
Не рекомендуем использовать коды ответа 429 и 5xx, так как они сообщают роботу, что сервер испытывает затруднения. Это может привести к замедлению индексирования сайта.
Используйте директиву noindex или настройте редирект 301.
При использовании
noindexи редиректа 301 уведомления об ошибке могут появляться в Вебмастере, но страницы в поиск не попадут и на позиции сайта это не повлияет. Эти способы наименее предпочтительны, так как увеличивают нагрузку на сервер и замедляют индексирование сайта.
Эти способы наименее предпочтительны, так как увеличивают нагрузку на сервер и замедляют индексирование сайта.
 Эти способы наименее предпочтительны, так как увеличивают нагрузку на сервер и замедляют индексирование сайта.
Эти способы наименее предпочтительны, так как увеличивают нагрузку на сервер и замедляют индексирование сайта.Элемент title и метатег description помогают сформировать корректное описание сайта в результатах поиска. Подробно см. раздел Отображение заголовка и описания сайта в результатах поиска.
Если элементы или один из них отсутствуют на вашем сайте, добавьте их в HTML-код страниц и сохраните изменения. Если элементы уже размещены, дождитесь, пока робот переобойдет страницы. После этого сообщение об ошибке исчезнет. Подробно
Эта проблема отображается, если заголовок или описание повторяется на значительной доле страниц сайта. Когда title и description отражают контент страницы, информативны и привлекательны, пользователям удобнее находить ответы в поисковой выдаче.
Посмотрите примеры страниц с повторяющимися заголовками или описаниями, которые обнаружил Вебмастер при обходе сайта роботом. Чтобы исправить их, следуйте рекомендациям по:
написанию title;
составлению description.
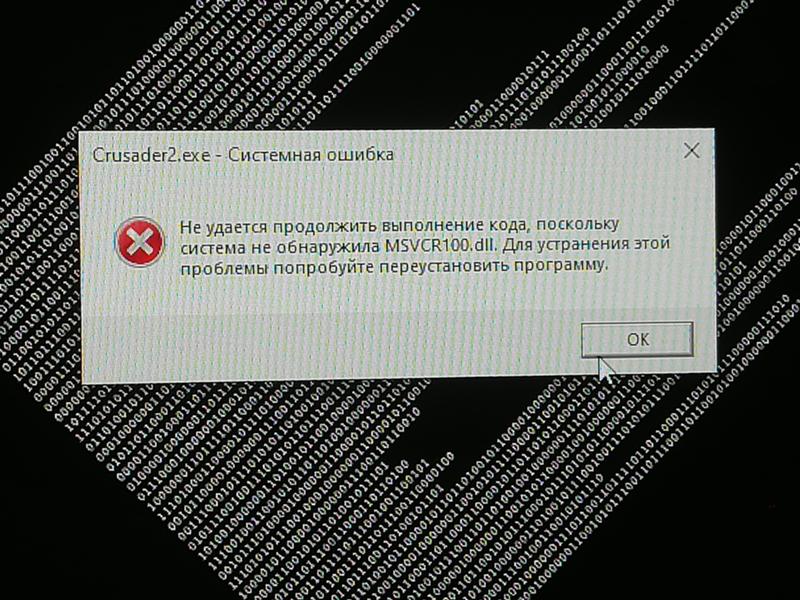
Проблема перестанет отображаться, когда робот узнает об изменениях на сайте. Чтобы это произошло быстрее, отправьте наиболее важные страницы на переобход или настройте обход страниц со счетчиком Метрики.
Если эта проблема отображается для вашего сайта, значит Небольшая картинка, которая отображается в сниппете в результатах поиска Яндекса, рядом с адресом сайта в адресной строке браузера, около названия сайта в Избранном или в Закладках браузера.»}}»> не отображается в результатах поиска. В Вебмастере на странице Диагностика → Диагностика сайта (блок Возможные проблемы) посмотрите причину, по которой робот не смог загрузить файл и следуйте указаниям:
| Ошибка | Решение |
|---|---|
| Файл отвечает HTTP-кодом, отличным от 200 OK | Проверьте ответ сервера. Ответ должен соответствовать 200 OK. Другие статусы ответа см. в разделе Проверка ответа сервера. Ответ должен соответствовать 200 OK. Другие статусы ответа см. в разделе Проверка ответа сервера. |
| Файл перенаправляет на другой адрес | |
| Неправильный тип данных | Проверьте значение параметра type в ссылке на файл. Он должен соответствовать формату файла. |
Как установить фавиконку
Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Посмотрите рекомендации. Если файл доступен для робота и загружается в Вебмастере, но проблема продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если файл добавлен больше 2 недель назад, но сообщение не пропадает, заполните форму:
Посмотрите рекомендации выше. Если ошибок в файле нет, но сообщение продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если ответ сервера соответствует 200 ОК и значение параметра type соответствует формату файла, но сообщение продолжает отображаться, заполните форму:
Тысячи ошибок 404 в Google Webmaster Tools
Задавать вопрос
спросил
Изменено
9 лет, 4 месяца назад
Просмотрено
5к раз
Из-за предыдущей ошибки в нашем приложении ASP. Net, созданной моим предшественником и долгое время не обнаруживаемой, тысячи неправильных URL-адресов создавались динамически. Обычный пользователь этого не замечал, но Google переходил по этим ссылкам и просматривал эти неправильные URL-адреса, создавая все больше и больше неправильных ссылок.
Net, созданной моим предшественником и долгое время не обнаруживаемой, тысячи неправильных URL-адресов создавались динамически. Обычный пользователь этого не замечал, но Google переходил по этим ссылкам и просматривал эти неправильные URL-адреса, создавая все больше и больше неправильных ссылок.
Чтобы было понятнее, рассмотрим URL
example.com/folder
должен создать ссылку
example.com/folder/subfolder
но создавал
example.com/subfolder
Вместо
. Из-за неправильной перезаписи URL это было принято и по умолчанию показывало индексную страницу для любого неизвестного URL, создавая все больше и больше таких ссылок.
example.com/subfolder/subfolder/….
К настоящему времени проблема решена, но теперь у меня есть тысячи ошибок 404, перечисленных в инструментах Google для веб-мастеров, которые были обнаружены 1 или 2 года назад, и продолжают появляться новые.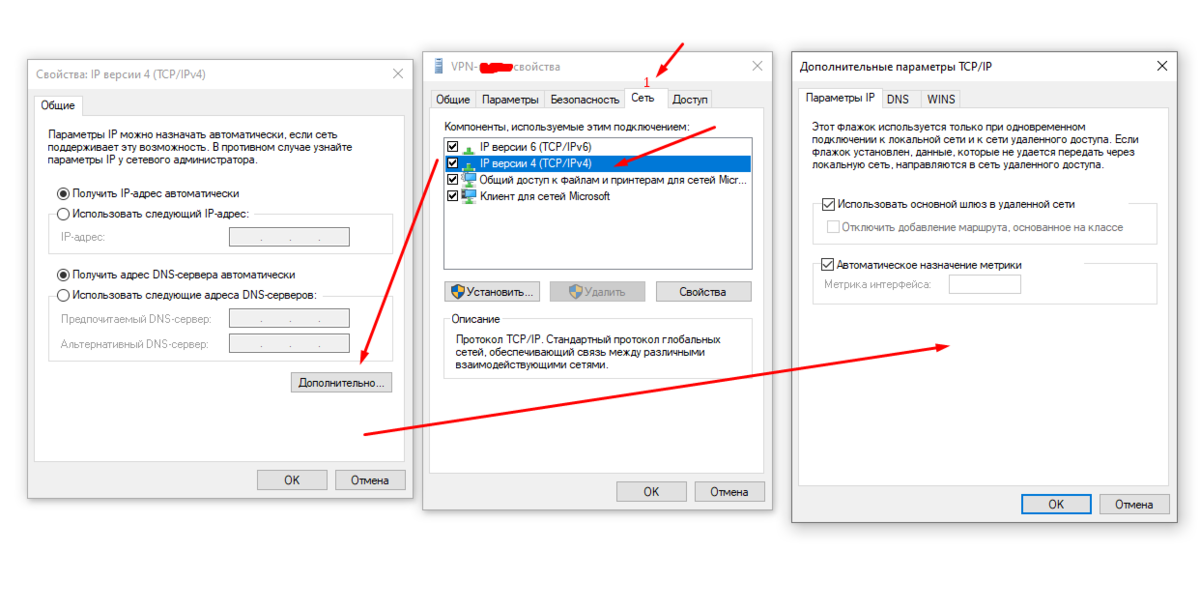
К сожалению, ссылки не соответствуют общему шаблону, который я мог бы отрицать из-за сканирования в файле robots.txt.
Могу ли я что-нибудь сделать, чтобы запретить Google пробовать эти очень старые ссылки и удалить уже перечисленные ошибки 404 из Инструментов для веб-мастеров?
- гугл
- гугл-поиск-консоль
- ссылки
- 404
1
Инструменты для веб-мастеров очень медленно обновляют страницу ссылок/ошибок. В частности, даже когда на страницу больше нет ссылки, робот Googlebot продолжает запрашивать страницу и сообщает, что ее невозможно найти.
Если какой-либо из URL-адресов соответствует общему шаблону, вы можете выполнить перенаправление 301 на правильную страницу, что должно ускорить удаление этих ошибок Google. (Примечание: я бы не рекомендовал добавлять тысячи строк в htaccess, потому что это может серьезно повлиять на производительность.)
Кроме этого, к сожалению, вы мало что можете сделать, кроме как переждать. Если точно нет ссылок, указывающих на несуществующие страницы, то раздел «Ошибки сканирования» со временем будет постепенно уменьшаться. По моему опыту это может занять до 3 месяцев.
Если точно нет ссылок, указывающих на несуществующие страницы, то раздел «Ошибки сканирования» со временем будет постепенно уменьшаться. По моему опыту это может занять до 3 месяцев.
Обратите внимание, что это не относится к внешним ссылкам — на моих сайтах у меня есть несколько ошибок 404, исходящих от внешних ссылок, которые я не могу контролировать, и я не думаю, что они когда-либо исчезнут.
6
Вот что говорит Джон Мюллер из Google (который работает над инструментами для веб-мастеров и картами сайта) об ошибках 404, которые появляются в инструментах для веб-мастеров:
ПОМОГИТЕ! МОЙ САЙТ ИМЕЕТ 939 ОШИБОК СКАНИРОВАНИЯ!! 1
Я вижу такие вопросы несколько раз в неделю; вы не одиноки — многие веб-сайты имеют ошибки сканирования.
- 404 ошибки на недействительных URL-адресах никоим образом не влияют на индексацию или ранжирование вашего сайта .
- В некоторых случаях ошибки сканирования могут возникать из-за законной структурной проблемы на вашем веб-сайте или CMS. Как вы говорите? Дважды проверьте источник ошибки сканирования. Если на вашем сайте есть неработающая ссылка в статическом HTML-коде вашей страницы, то это всегда стоит исправить. (спасибо +Мартино Мосна)
- Как насчет причудливых URL-адресов, которые «явно не работают»? Когда нашим алгоритмам нравится ваш сайт, они могут попытаться найти на нем больше полезного контента, например, пытаясь обнаружить новые URL-адреса в JavaScript. Если мы попробуем эти «URL» и найдем 404, это здорово и ожидаемо. Мы просто не хотим пропустить что-то важное (вставьте сюда чрезмерно прикрепленный мем Googlebot). http://support.google.com/webmasters/bin/answer.py?answer=1154698
- Вам не нужно исправлять ошибки сканирования в Инструментах для веб-мастеров.
http://support.google.com/webmasters/bin/answer.py?answer=2467403- Мы перечисляем ошибки сканирования в Инструментах для веб-мастеров по приоритету, который зависит от нескольких факторов. Если первая страница ошибок сканирования явно неактуальна, вы, вероятно, не найдете важных ошибок сканирования на следующих страницах.
http://googlewebmastercentral.blogspot.ch/2012/03/crawl-errors-next-generation.html- Нет необходимости «исправлять» ошибки сканирования на вашем сайте. Обнаружение ошибки 404 является нормальным явлением и ожидается от исправного, хорошо настроенного веб-сайта. Если у вас есть эквивалентный новый URL-адрес, перенаправление на него является хорошей практикой. В противном случае вы не должны создавать поддельный контент, вы не должны перенаправлять на свою домашнюю страницу, вы не должны блокировать эти URL-адреса в файле robots.
http://support.google.com/webmasters/bin/answer.py?answer=181708- Очевидно, что если эти ошибки сканирования появляются для URL-адресов, которые вас интересуют, например URL-адресов в файле Sitemap, вам следует немедленно принять меры. Если робот Googlebot не сможет просканировать ваши важные URL-адреса, они могут быть исключены из наших результатов поиска, и пользователи также не смогут получить к ним доступ.
 Неважно, 100 или 10 миллионов, они не повредят ранжированию вашего сайта. http://googlewebmastercentral.blogspot.ch/2011/05/do-404s-hurt-my-site.html
Неважно, 100 или 10 миллионов, они не повредят ранжированию вашего сайта. http://googlewebmastercentral.blogspot.ch/2011/05/do-404s-hurt-my-site.html Функция «отметить как исправленную» предназначена только для того, чтобы помочь вам, если вы хотите отслеживать свой прогресс там; он ничего не меняет в нашем конвейере веб-поиска, поэтому не стесняйтесь игнорировать его, если он вам не нужен.
Функция «отметить как исправленную» предназначена только для того, чтобы помочь вам, если вы хотите отслеживать свой прогресс там; он ничего не меняет в нашем конвейере веб-поиска, поэтому не стесняйтесь игнорировать его, если он вам не нужен. txt — все это затрудняет нам распознавание структуры вашего сайта и его правильную обработку. Мы называем эти ошибки «мягкими 404».
txt — все это затрудняет нам распознавание структуры вашего сайта и его правильную обработку. Мы называем эти ошибки «мягкими 404».Ваша страница 404 возвращает настоящий 404 или возвращает 200 с содержимым 404? Я вижу много пользовательских страниц 404, которые говорят «страница не найдена», но возвращают статус 200, поэтому Google считает, что они являются активными страницами, и сохраняет их в своем индексе.
Без доступа к страницам для их просмотра трудно точно сказать, что происходит, но, по моему опыту, это самая распространенная проблема.
1
Заблокируйте эти страницы с помощью robots.txt , это самый простой способ.
На моем сайте более 100 тыс. ошибок 404, которые, кажется, не исчезают. Иногда нужно просто оставить их в покое.
Если вы запустите сценарий для отображения страниц, вы можете определить, что это проблемная страница, и распечатать настоящую HTML-страницу с метатегом статуса 200 +:
Возможно, это было неправдой, когда изначально задавался вопрос, но теперь с помощью инструментов для веб-мастеров вы можете выбрать, какие URL-адреса, которые приводят к ошибке 404, должны Google удалить из его индекса и больше не пытаться сканировать. Вы можете сделать 25 за раз. Вы можете найти это средство в разделе «Здоровье» > «Ошибки сканирования».
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
htaccess — заставить Apache показывать 404 на отсутствующем URL-адресе страницы вместо перенаправления на URL-адрес страницы с ошибкой
спросил
Изменено
6 лет, 4 месяца назад
Просмотрено
10 тысяч раз
Предположим, что non-existent-page.html не существует, и пользователь пытается получить доступ к этой странице и вызывает ошибку 404.
Могу ли я показать запрошенный URL страницы:
http://www.example.com/non-existent-page.html
вместо URL страницы с ошибкой:
http://www.example.com/404.html
Решение:
Глядя на ответ Стивена Остермиллера , я знал, что использую относительный URL-адрес, но понял, что в конце отсутствует косая черта, потому что я указывал на каталог, а не на страницу. . В основном это происходит с некоторыми xSP с плохой конфигурацией.
. В основном это происходит с некоторыми xSP с плохой конфигурацией.
Проблема
ErrorDocument 404 /error/404 <-- без косой черты
Fix
ErrorDocument 404 /error/404/ <-- добавлена косая черта
- htaccess
- apache
- mod-rewrite
- url-rewrite
5
Сервер Apache можно настроить так, чтобы он отображал страницу с ошибкой по URL-адресу ошибки или перенаправлял на страницу с ошибкой. Почти лучше показывать страницу с ошибкой непосредственно по URL-адресу, а не перенаправлять на нее.
Директива Apache ErrorDocument объясняет, как реализовать ее в обоих направлениях:
URL-адреса
могут начинаться с косой черты (/) для локальных веб-путей (относительно DocumentRoot) или быть полным URL-адресом, который может разрешить клиент.
На практике это означает, что если вы укажете документ с ошибкой в виде абсолютного URL-адреса, это вызовет перенаправление на страницу с ошибкой:
ErrorDocument 404 http://www.
 example.com/404.html
example.com/404.html
, но если вы укажете документ об ошибке как относительный URL-адрес, начинающийся с косой черты, он покажет документ об ошибке по исходному URL-адресу, где произошла ошибка:
ОшибкаДокумент 404/404.html
Я предполагаю, что у вас есть директива ErrorDocument , настроенная как абсолютный URL либо в файле .htaccess , либо в файле httpd.conf . Вам нужно отредактировать его, чтобы изменить его на относительный URL-адрес.
2
Для этого вам нужно использовать RewriteEngine, добавив условие/правило, чтобы определить, заканчивается ли HTTP-запрос расширением html , а затем перенаправить на тот же URL-адрес без него, в 9ПОЛУЧИТЬ\ (.*)\.html\ HTTP
Правило перезаписи (.*)\.html$ $1 [R=301]
Каждый запрос, оканчивающийся на версию .html , будет перенаправлен на тот же URL-адрес без расширения. Если существует версия, отличная от .