Содержание
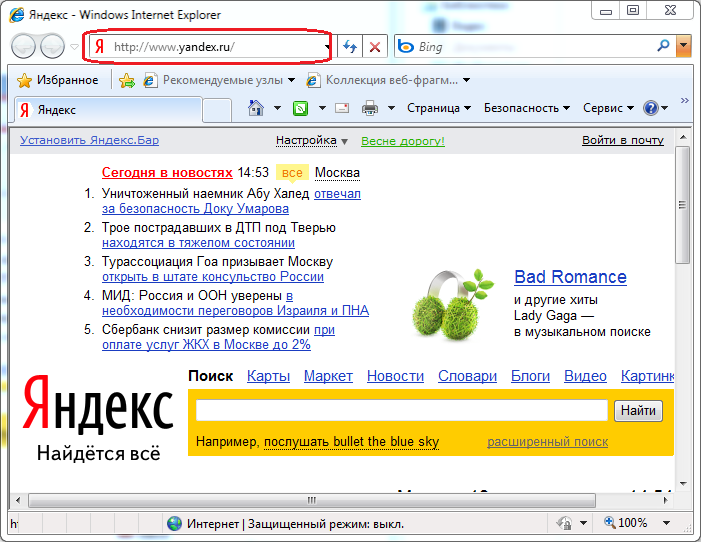
Поисковые технологии или в чем загвоздка написать свой поисковик / Хабр
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик. Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Здесь я в первый раз, публично, опишу то, что было сделано лично мной. Думаю, многим будет интересно как же работают Яндекс, Google и почти все мне известные поисковики изнутри.
Есть много задач при построении таких систем, которые почти нереально решить в общем случае, однако с помощью некоторых ухищрений, придумок и хорошего понимания как работает железячная часть Вашего компьютера можно серьезно упростить. Как пример – пересчет PR, который в случае нескольких десятков миллионов страниц уже невозможно поместить в самой большой оперативной памяти, особенно если Вы, как и я, жадны до информации, и хотите кроме 1 цифры хранить еще много полезностей. Другая задача – хранение и обновление индекса, как минимум двумерной базы данных, в которой конкретному слову сопоставляется список документов, на которых оно встречается.
Другая задача – хранение и обновление индекса, как минимум двумерной базы данных, в которой конкретному слову сопоставляется список документов, на которых оно встречается.
Просто вдумайтесь, Google хранит, по одной из оценок, более 500 миллиардов страниц в индексе. Если бы каждое слово встречалось на 1 странице только 1 раз, и на хранение этого надо было 1 байт – что невозможно, т.к. надо хранить хотя бы id страницы – уже от 4 байт, так вот тогда объем индекса бы был 500гб. В реальности одно слово встречается на странице в среднем до 10 раз, объем информации на вхождение редко когда меньше 30-50 байт, весь индекс увеличивается в тысячи раз… Ну и как прикажите это хранить? А обновлять?
Ну вот, как это все устроено и работает, я буду рассказывать планомерно, так же как и про то как считать PR быстро и инкрементально, про то как хранить миллионы и миллиарды текстов страниц, их адреса и быстро искать по адресам, как организованы разные части моей базы данных, как инкрементально обновлять индекс на много сотен гигов, ну и наверное расскажу как сделать обучающийся алгоритм ранжирования.
На сегодня объем только индекса, по которому происходит поиск — 57Gb, увеличивается каждый день примерно на 1Gb. Объем сжатых текстов – 25Gb, ну и я храню кучу другой полезной инфы, объем которой очень трудно посчитать из-за ее обилия.
Вот полный список статей которые относятся к моему проекту и описаны здесь:
0. Поисковые технологии или в чем загвоздка написать свой поисковик
1. С чего начинается поисковик, или несколько мыслей про crawler
2. Общие слова про устройство поиска в Web
3. Dataflow работы поисковой машины
4. Про удаление малозначимых частей страниц при индексации сайта
5. Методы оптимизации производительности приложения при работе с РБД
6. Немного про проектирование баз данных для поисковой машины
7. AVL деревья и широта их применения
8. Работа с URL и их хранение
9. Построение индекса для поисковой машины
Как создать свой поисковик и возможно ли это сделать самостоятельно?
Каждый пользователь в интернете может назвать несколько популярных поисковых систем.
Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Свой поисковик может быть двух типов:
большая поисковая система, которая будет работать по всему интернету и составлять конкуренцию Google, Яндекс, Bing и др.;
небольшой поисковик, организованный на своем сайте с различными свойства поиска.
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Создать свой поисковик наподобие Гугла и Яндекса, на самом деле, не так сложно. Любой более-менее уверенный в себе разработчик сможет это сделать. Любой поисковик состоит из 3-х основных элементов:
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять/добавлять информацию о них в базу данных.
Техническая реализация поисковой системы не так сложна, как кажется. Плюс в сети есть уже много готовых скриптов как платных, так и бесплатных, с помощью которых вы сможете реализовать свою идею. Создать свой поисковик можно самостоятельно или в небольшой команде. В принципе, если найти соратников в команду, которые готовы поработать на голом энтузиазме, создать свой поисковик можно практически бесплатно.
Но проблема в другом. Сможете ли вы создать действительно конкурирующий программный продукт? Ведь для того, чтобы конкурировать с известными поисковиками, вам нужно будет:
нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
И при этом никто не даст гарантий, что ваш поисковик станет популярным и вы сможете его монетизировать. Потому что пока вы будете развивать свой продукт, Гугл с Яндексом также будут развиваться. А чтобы их «переплюнуть», вам нужно будет внедрить в свой продукт какую-нибудь «фишку» или ноу-хау, чтобы переманить к себе пользователей — это что касается функционала. А с технической стороны ваш поиск должен быть точнее, быстрее и эффективнее, чем у ваших конкурентов, чтобы пользователи это «почувствовали» и перешли на вашу сторону.
Почему люди в основном пользуются Гуглом или Яндексом (или другими)? Потому что им там комфортно и им там нравится. Поэтому, чтобы пользователи перешли именно к вашему поисковику, вы должны стать лучше.
Вот и получается, что создать свой поисковик нетрудно, но вот развивать его и сделать конкурентоспособным — на это потребуется немало усилий и финансовых вложений. Но с другой стороны, Гугл тоже когда-то был в позиции «новичка», а в кого он превратился спустя годы упорного труда — мы все прекрасно видим.
Другое дело с локальными поисковиками, которые вы можете организовать на собственном сайте.
Как создать небольшой локальный поисковик на своем сайте
Небольшой локальный поисковик — это более «приземленная» идея поисковой системы. И в некоторых ситуациях подобный поисковик будет работать эффективнее, чем глобальный Гугл с Яндексом. Например, когда вам нужно ограничить объем поиска. Допустим, у вас есть некий веб-ресурс, который ведет взаимоотношения с 500 поставщиками и 400 различными партнерами, плюс в качестве дополнительной информации вы используете еще 900 разных источников. Вы можете организовать собственную поисковую систему на 1000+ источников, чтобы вашим клиентам было проще искать нужную информацию, касающуюся ваших услуг или товаров. Если они будут это делать через глобальную поисковую систему, то в выдаче у них будет очень много «мусора», который, по сути, им никогда не пригодится. А ваша ПС даст именно те результаты, которые нужны вашим клиентам.
В качестве дополнения собственная тематическая ПС — это:
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Что самое интересное — подобные локальные системы организовать довольно просто. В сети есть масса готовых решений по этому поводу. Самое узнаваемое решение — это создать свой поисковик, используя поисковый потенциал Google. Для этого пройдите по ссылке.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовиться финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.
 Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.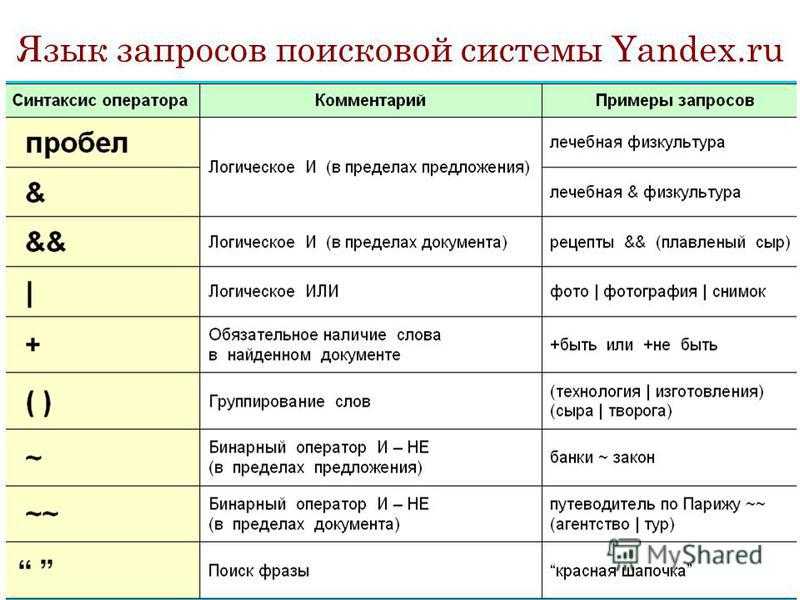




Что нужно знать при создании собственной поисковой системы
Итак, вы хотите создать собственную поисковую систему. Мы хотели бы избавить вас от хлопот. А это есть беда, как вы, без сомнения, знаете.
Конечно, можно заняться проектом поисковой системы своими руками. Существуют мощные стартовые наборы — например, Solr. Вы можете создать прекрасную поисковую систему с помощью Solr, если у вас есть нужные люди, достаточно времени и достаточно денег.
Но вам также нужна терпимость к риску и альтернативным издержкам. Создание собственного поиска по сайту требует времени, а это означает, что вы, скорее всего, теряете доход при разработке, создании и настройке поисковой системы сайта.
По мере устранения ошибок и по мере того, как система, которую вы построили, будет работать, вполне вероятно, что предлагаемый вами поисковый опыт будет неудовлетворительным, что означает неудовлетворенных клиентов и необходимость возвращать их обратно, когда ваша поисковая система работает на пределе своих возможностей. приемлемый уровень.
приемлемый уровень.
Короче говоря, вот все, что вам нужно знать перед созданием собственной поисковой системы:
Создание мозга поисковой системы вручную требует времени вы получаете готовые решения. Конечно, Solr можно масштабировать прямо с полки. Это также проверенный исполнитель.
Но подумайте о поиске и о том, что нужно для получения релевантных и персонализированных результатов вплоть до индивидуального уровня. Для достижения оптимального уровня обслуживания клиентов требуется:
Сложные алгоритмы
Огромные объемы данных
Облачная инфраструктура, настроенная для вашей конкретной поисковой системы
Знаешь, чего ты не найдешь на дне своей большой новой коробки Solr? Сложные алгоритмы, огромные объемы данных и инфраструктура, необходимые для создания мощной поисковой системы сайта.
На самом деле, разработка алгоритмов, сбор данных и проектирование системы для их эффективного использования для прогнозирования намерений цифровых потребителей — это то, что делает самостоятельную поисковую систему Solr.
Solr сам по себе не оптимизирован для ранжирования по доходу. Он не может ранжироваться с помощью персонализации, основанной на намерениях, поведении и предпочтениях клиентов. Он не предназначен для предоставления информации, выходящей за рамки поиска по сайту. Он не загружается данными о продуктах, синонимах или намерениях покупателя. И он не может извлечь контент. На самом деле справедливо будет сказать, что готовый к использованию Solr проведет вас примерно на 20 % пути туда, где вам нужно быть, чтобы правильно выполнять поиск.
Если вы хотите, чтобы поисковая система Solr выполняла все необходимые действия — ранжирование по доходам, персонализацию, достижение семантического понимания, понимание поведения пользователей — вы должны сказать ей, как это сделать. Вам нужно построить мозг двигателя. Или, что более вероятно, команде людей нужно построить мозг двигателя.
Вам нужно построить мозг двигателя. Или, что более вероятно, команде людей нужно построить мозг двигателя.
И это делается с помощью алгоритмов. Создание мозга поисковой системы вручную требует времени — очень много времени.
Создание вашей поисковой системы может быстро исчерпать все ваши ресурсы
Возьмем, к примеру, синонимы. Очевидно, что надежный тезаурус синонимов является ключом к поиску по сайту. Когда потребитель вводит «малиновое вечернее платье длиной до колен из спандекса» в поле поиска на сайте, система должна знать, что для этого человека платье Herve Leger с тонкими бретельками и кожаным ремнем является одним из
На самом деле, когда мы попросили потребителей описать это самое платье, 500 человек придумали умопомрачительную серию комбинаций, включающую 129 комбинаций.слов для «красного», 275 различных описаний пояса, 105 описаний длины и 216 слов для обозначения случая, по которому можно надеть платье.
И знаете, как поисковая система Solr узнает об этом? Вы говорите ему .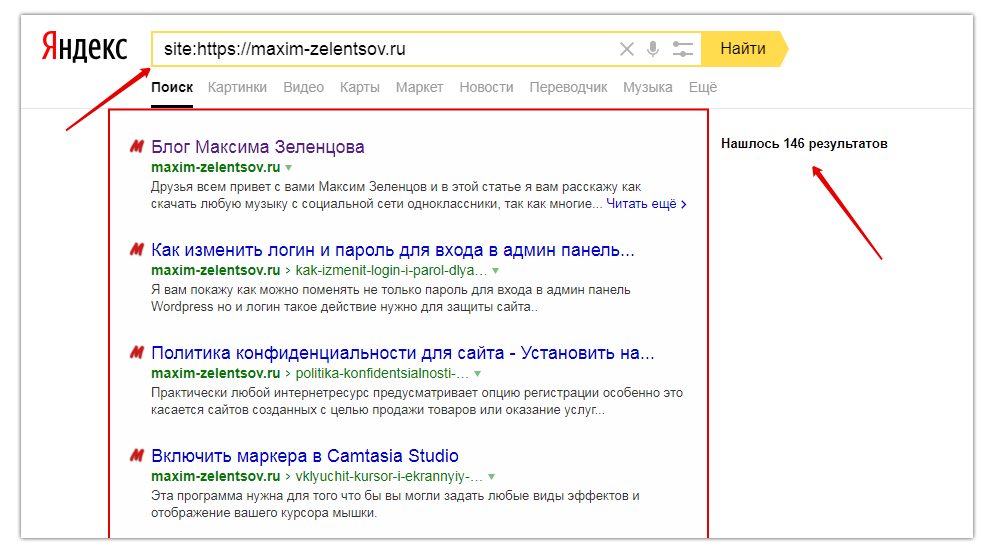 Или команда людей, которых вы нанимаете, обучает машину тому, что «глубокий румянец» может означать красный цвет, а «корсетный пояс» — кожаный ремень с ремнями.
Или команда людей, которых вы нанимаете, обучает машину тому, что «глубокий румянец» может означать красный цвет, а «корсетный пояс» — кожаный ремень с ремнями.
Неважно, что в сутках не хватает часов, чтобы люди могли придумать сотни вариантов полудюжины слов, которые потребители могли бы использовать для описания платья — разве вы не предпочли бы, чтобы они лучше использовали свое время?
Мы тоже так думаем.
Персонализированные результаты поиска — ключ к успеху
Solr — это впечатляющая, масштабируемая платформа поиска по сайту — насколько она способна. Проблема с его использованием в качестве основы самодельной поисковой системы заключается в том, что этого недостаточно.
В частности, Solr из коробки не включает алгоритмы, данные и инфраструктуру, необходимые для построения поиска, который сегодня востребован потребителями. Сегодняшние цифровые потребители хотят персонализированных и релевантных результатов поиска. Они ожидают от Google опыта на каждом сайте: введите то, что вы ищете, используя свои собственные слова, чтобы описать что-то, что можно описать миллионом разных способов, и вуаля — именно то, что вы искали.
Теперь давайте взглянем на данные, которые необходимы лучшей в своем классе поисковой системе, чтобы обеспечить то качество обслуживания клиентов, которого ожидают потребители.
В отчете Internet Retailer за 2018 г. было обнаружено, что проблема номер один, с которой столкнулись при текущем поиске по сайту, заключалась в том, что «клиенты часто видят нерелевантные результаты или результаты в неправильном порядке», и указал «персонализированные результаты» в качестве главной функции, необходимой в современном поисковом решении.
Чтобы предоставить каждому отдельному пользователю персонализированные и релевантные результаты, поисковая система должна понимать намерения пользователя, данные о продукте и поведение пользователя . Лучшие поисковые системы приходят к такому пониманию, постоянно изучая данные в каждой из этих трех категорий.
Поисковая система должна понимать синонимы, потому что потребители используют разные слова для описания одного и того же товара, и они часто используют слова, которые отличаются от описаний продуктов розничного продавца.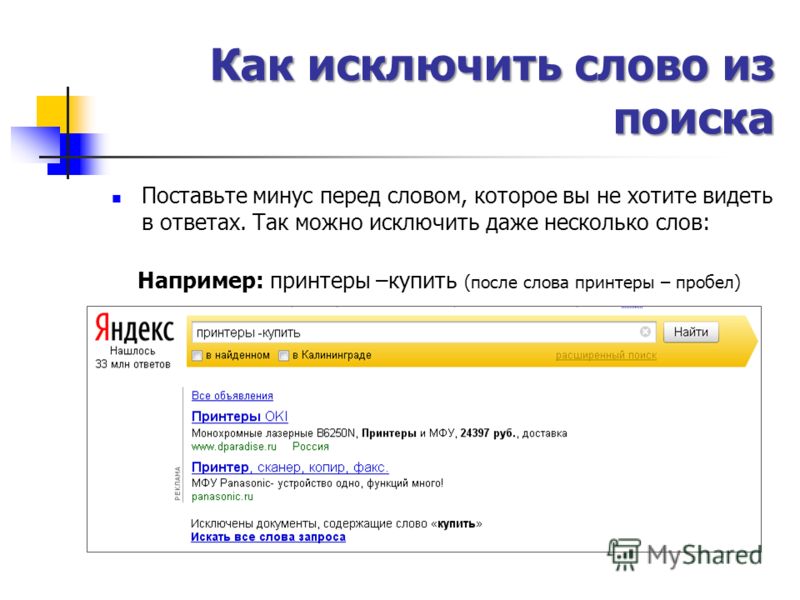 Обувью, например, могут быть «ботфорты с низким вырезом» или «высокие кроссовки».
Обувью, например, могут быть «ботфорты с низким вырезом» или «высокие кроссовки».
Движок должен знать, что основы слов могут иметь всевозможные дополнения — «ing», «ed», «s», — которые могут резко изменить их значение. «Полотно», например, — это не два «полотна». По сути, белье — это товар, а белье — атрибут товара. Он также должен понимать все способы поиска ваших клиентов, включая числовой поиск.
А как насчет акронимов, сленга и орфографических ошибок, определения которых зависят от контекста? Вы ищете «платье», «рубашку» или «платье-рубашку» (которое также пишется как «платье-рубашка»)?
Это подводит нас к важности коммерческих данных. Готовый Solr не особо разбирается в брендах, цветах и размерах. Когда клиент ищет «красное платье валентино», красный цвет? Валентино это стиль? Или Red Valentino — это бренд?
Это имеет значение. А учитывая ценовой диапазон продуктов Red Valentino, вы хотите, чтобы ваша поисковая система знала, что это бренд.
И вот почему: оказывается, потребители, которые используют поиск по сайту, особенно те, кто ищет Red Valentino, входят в число самых ценных клиентов предприятия. Но они не останутся, если будут разочарованы плохим поиском по сайту, согласно RealDecoy в своем отчете Endeca vs. Bloomreach: увеличение конверсий с помощью поиска по сайту.
В отчете цитируется исследование Forrester, которое показало, что 90 % искателей сайта не читают дальше первой страницы результатов — и что искатели часто просто сдаются, если их разочаровывают плохие результаты.
Прочтите следующее: Что такое многоканальная коммерция?
Вам нужен самообучающийся поиск по сайту
Даже если поисковая система на полную мощность работает с данными о намерениях пользователей и данными о продуктах, вы все равно даже близко не приблизитесь к пиковой производительности, если ваша поисковая система также не обрабатывает поведенческие данные. данные, которые дают представление о производительности продукта и персонализации опыта.
Знание того, как посетители взаимодействуют с вашим сайтом, имеет решающее значение для понимания того, как лучше их обслуживать. Они просматривают или используют поиск по сайту? Как они вообще попали на ваш сайт? Какие поисковые запросы они используют? Какие продукты они рассматривают? Какие еще продукты они просматривают в рамках одного сеанса? Что они добавляют в свои корзины? Что они покупают?
Ответы на эти вопросы начинают формировать кучу информации, например:
Самые популярные запросы — на вашем сайте, в Интернете, на мобильных устройствах и в социальных сетях.
Самые популярные товары, снова с разбивкой по каналам.
Эффективность каждого отдельного продукта в ваших цифровых ресурсах.
То, как продукт выполняет заданный запрос.
Список товаров, похожих друг на друга. Это помогает сайту обслуживать рекомендации, включая продукты, которые слишком новы, чтобы иметь цифровой послужной список.
Товары, популярные в определенных категориях.
Наиболее часто переписываемые запросы.
Самые посещаемые ссылки на сайте.
Без возможности собирать и обрабатывать данные, которые предоставляют эту подробную информацию, ваша поисковая система не сможет постоянно учиться и постоянно совершенствоваться. Цель – непревзойденная релевантность для поиска, и без всей этой информации вы застрянете на некачественной поисковой системе.
Прочтите это далее: Как Jenson USA использовала персонализированные результаты поиска для увеличения RPV на 8,5 % [кейс]
Для превосходного поиска по сайту требуется превосходная инфраструктура того, что лучше построить или купить, чтобы преобразовать поиск по сайту в нынешнюю цифровую эпоху.
Solr никогда не задумывался как система поиска по сайту — по крайней мере, без большой работы и ряда дополнительных модулей. В чем, если подумать, и заключается смысл этой статьи: вам нужна правильная инфраструктура, чтобы ваша поисковая система работала. Потому что поисковая система сайта живет не только на такой платформе, как Solr.
Потому что поисковая система сайта живет не только на такой платформе, как Solr.
Мы уже говорили о необходимости добавления алгоритмов и данных в ваш новый готовый Solr. Но еще один важный элемент в создании поисковой системы сайта, которая сделает ваших клиентов счастливыми и вернет их, — это добавление модулей — систем, которые помогут вам правильно индексировать, настраивать и ранжировать результаты поиска, чтобы обеспечить превосходное качество обслуживания клиентов.
Представьте себе готовый Solr как элегантный дом с красивым каркасом, но без основных систем или последних штрихов. В доме нужны комнаты — кухня, санузлы, спальни. Может быть, вы занимаетесь кабинетом, винным погребом и домашним кинотеатром. Если да, то они тоже понадобятся.
Если оставить в стороне ваш уровень роскоши, суть в том, что, как этому великолепному дому нужны комнаты, так и Солру нужны модули.
Корпоративный поиск требует гораздо большего, чем предлагает только Solr. Solr сам по себе не является системой управления кластером. Это не система управления конфигурацией. Он не обеспечивает базовую релевантность из коробки. И это те инструменты, которые делают поиск по сайту действительно блестящим.
Это не система управления конфигурацией. Он не обеспечивает базовую релевантность из коробки. И это те инструменты, которые делают поиск по сайту действительно блестящим.
Прочтите следующее: Как Boden персонализирует качество обслуживания клиентов с помощью цифрового мерчендайзинга [пример из практики]
Вы не можете масштабировать и управлять своим поиском без мерчендайзинговой аналитики
Поисковая система должна иметь возможность масштабироваться вместе с вашим бизнесом и оттачивать свои возможности для предоставления более качественных и значимых результатов, что невозможно сделать без мерчандайзинговой аналитики. У Solr нет этих возможностей с самого начала, и он не предоставляет интерфейс для продвижения и захоронения продуктов — важные шаги, которые предпринимают мерчендайзеры для улучшения поиска по сайту, полагаясь на свои знания, опыт и интуицию.
Все эти функции должны быть спроектированы и реализованы. В случае создания собственного с помощью Solr вам нужны эксперты, которые разбираются в инфраструктуре — эксперты, которые понимают, что Solr требует много усилий для масштабирования.
Чтобы сделать это самостоятельно, вам нужна команда инженеров для создания модулей, которые перемещают, хранят и обрабатывают все те данные, о которых мы говорили ранее.
Один из способов подумать о необходимых модулях — разбить их функции на три основные области: наука о данных, мерчандайзинг и инвентаризация.
Наука о данных охватывает все возможности обучения и улучшения результатов поисковой системы, которые можно получить, только опираясь на аналитику. Поисковые системы полагаются на данные и модели поведения пользователей. Ваш движок должен сделать вывод из всех исторических поисков и результатов предыдущих запросов, действительно ли пользователи, ищущие «обувь», ищут сандалии или вместо этого они ищут насосы или кроссовки.
Движку нужны модели обработки естественного языка, чтобы он мог понимать бизнес, которым занимается сайт, и понимать ленту продуктов, с которыми он работает. Помимо Solr, требуется ряд машин для хранения и обработки всей этой, казалось бы, случайной, но жизненно важной информации.
Чтобы понять намерение пользователя и создать сайт, который может реагировать на это намерение, требуется способ сбора информации о посещениях в режиме реального времени. И никакие данные не годятся, если нет эффективного способа загрузить их в систему, чтобы система могла извлечь из них уроки.
Команде мерчандайзинга нужны правильные инструменты для работы
Две другие общие функции модулей — мерчандайзинг и инвентаризация — столь же важны для вашей поисковой системы.
Мерчандайзинг — одна из самых важных стратегий электронной коммерции, и вы должны инвестировать в нее, чтобы добиться успеха. Команде мерчандайзинга, отвечающей за продвижение конверсий на цифровом сайте, нужны правильные инструменты для воплощения своих стратегий в жизнь. Им нужна система для написания динамических бизнес-правил, которые они могут быстро изменять при необходимости. Им нужны средства тестирования, которые помогут им определить, являются ли шаги, которые они делают, правильными. И им нужны диагностические инструменты для мониторинга производительности сайта и определения основных причин проблем и тенденций.
И им нужны диагностические инструменты для мониторинга производительности сайта и определения основных причин проблем и тенденций.
Также необходимо создать системы для управления колебаниями посещаемости сайта. Подумайте о сайте электронной коммерции во время сезона праздничных покупок — инфраструктура, поддерживающая цифровые сайты, должна иметь возможность быстро масштабироваться и уменьшаться, когда дополнительные мощности больше не требуются.
Модули инвентаризации так же важны для ваших отделов мерчандайзинга. Без самых последних и релевантных данных о ваших запасах они не могут оптимизировать рекламные акции или пути клиентов с какой-либо степенью уверенности.
Если вы создаете свой собственный движок с такой платформой, как Solr, ему нужна система ETL (извлечение, преобразование и загрузка) для сбора данных из источников, таких как каталог розничного продавца, и ввода их в поисковую систему в процессе. называется поеданием корма. Также потребуется масштабируемая система хранения данных, способная справиться с постоянно меняющимися потоками данных из-за постоянно меняющихся каталогов. Кроме того, это должна быть распределенная система, способная автоматически справляться с потребностями динамично развивающегося рынка, на котором, например, розничный торговец может внезапно обнаружить, что ему необходимо в одночасье утроить размер своего каталога.
Кроме того, это должна быть распределенная система, способная автоматически справляться с потребностями динамично развивающегося рынка, на котором, например, розничный торговец может внезапно обнаружить, что ему необходимо в одночасье утроить размер своего каталога.
Поисковику сайта также нужна система индексации, которая может работать на максимальной скорости. Природа цифровой коммерции сегодня означает, что детали продукта, такие как цены и уровни запасов, постоянно меняются. Чтобы идти в ногу с потребителями и конкуренцией, сайт должен иметь возможность быстро реагировать на изменение ассортимента, чтобы оставаться актуальным.
Создать такую систему можно, но это сложная задача. По нашим подсчетам, среднему и крупному ритейлеру, пытающемуся создать собственную высококачественную поисковую систему на базе Solr, потребуется от 30 до 40 инженеров в течение двух лет.
Очевидно, что это огромные затраты времени и денег. Но это также представляет собой огромные альтернативные издержки. В то время как работа по созданию высококачественной поисковой системы продолжается, клиенты компании страдают от низкого качества поиска. И поисковая система не может полностью учиться на взаимодействиях с клиентами, пока она не запущена и не работает.
В то время как работа по созданию высококачественной поисковой системы продолжается, клиенты компании страдают от низкого качества поиска. И поисковая система не может полностью учиться на взаимодействиях с клиентами, пока она не запущена и не работает.
Все это не тривиально, особенно когда до 30% потребителей используют поиск по сайту. И эти потребители являются одними из самых ценных клиентов предприятия, учитывая их более высокую склонность к конверсии. С другой стороны, клиенты, которые не получают результатов по своим поисковым запросам на сайте, в три раза чаще покидают сайт, чем другие.
Неудивительно, что команды, отвечающие за продажу продуктов и предоставление контента в Интернете, мучаются из-за серьезных изменений в поиске по сайту, и особенно из-за принятия решения о создании или покупке, когда приходит время капитального ремонта.
Bloomreach завершает работу с коммерцией
Если вы все еще думаете о создании своей поисковой системы, позвольте Bloomreach избавить вас от проблем. Bloomreach Discovery предлагает мощную комбинацию поиска по сайту на основе ИИ, SEO, рекомендаций и мерчендайзинга продуктов, чтобы вы могли предоставлять своим клиентам идеальные результаты — и все это без необходимости создавать это самостоятельно.
Bloomreach Discovery предлагает мощную комбинацию поиска по сайту на основе ИИ, SEO, рекомендаций и мерчендайзинга продуктов, чтобы вы могли предоставлять своим клиентам идеальные результаты — и все это без необходимости создавать это самостоятельно.
Если вы хотите узнать больше, запланируйте индивидуальную демонстрацию сегодня.
Создание собственной поисковой системы с нуля | Дэвид Ястремский
Сколько раз в день вы просматриваете Интернет? 5, 20, 50? Если Google является вашей предпочтительной поисковой системой, вы можете просмотреть свою историю поиска здесь.
Несмотря на то, насколько глубоко поиск лежит в основе нашей повседневной деятельности и взаимодействия с миром, немногие из нас понимают, как он работает. В этом посте я работаю, чтобы осветить основы поиска. Это от реализации поисковой системы, основанной на оригинальной реализации Google.
Photo by Benjamin Dada on Unsplash
Сначала мы рассмотрим предварительный шаг: понимание веб-серверов . Что такое клиент-сервер инфраструктура ? Как ваш компьютер подключается к веб-сайту?
Что такое клиент-сервер инфраструктура ? Как ваш компьютер подключается к веб-сайту?
Вы увидите, что происходит, когда поисковая система подключается к вашему компьютеру, веб-сайту или чему-либо еще.
Затем мы рассмотрим три основные части поисковой системы: сканер, индексатор и алгоритм PageRank . Каждый из них даст вам глубокое понимание связей, составляющих паутина это интернет.
Наконец, мы рассмотрим, как эти компоненты объединяются, чтобы получить наш финальный приз: поисковую систему ! Готовы погрузиться? Пойдем!
Мощный веб-сервер! Веб-сервер — это то, с чем ваш компьютер связывается каждый раз, когда вы ищете URL-адрес в своем браузере. Ваш браузер действует как клиент, отправляя запрос, подобно бизнес-клиенту. Сервер — это торговый представитель, который принимает все эти запросы и обрабатывает их параллельно.
Запросы являются текстовыми. Сервер знает, как их читать, поскольку ожидает их в определенной структуре (самый распространенный протокол/структура сейчас — HTTP/1. 1).
1).
Пример запроса:
GET /hello HTTP/1.1
Агент пользователя: Mozilla/4.0 (совместимый; MSIE5.01; Windows NT)
Хост: www.sample-why-david-y.com
Accept-Language : en-us
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: user=why-david-y
Запрос может иметь аргументы, заданные его списком файлов cookie. У него может быть тело с дополнительной информацией. Ответ следует аналогичному формату, позволяя серверу возвращать аргументы и тело для чтения клиентами. Интернет становится все более интерактивным, вся тяжелая работа по созданию контента выполняется на сервере.
Если вы когда-нибудь захотите запрограммировать веб-сервер или клиент, вам доступно множество библиотек для выполнения большей части синтаксического анализа и низкоуровневой работы. Просто имейте в виду, что запросы клиентов и ответы сервера — это всего лишь способ структурирования текста. Это значит, что мы все говорим на одном языке!
Если вы создаете поисковую систему, поисковый робот — это то, на что вы тратите большую часть времени. Сканер просматривает открытый Интернет, начиная с предопределенного списка сидов (например, Wikipedia.com, WSJ.com, NYT.com). Он прочитает каждую страницу, сохранит ее и добавит новые ссылки в свою границу URL-адресов, которая представляет собой очередь ссылок для сканирования.
Сканер просматривает открытый Интернет, начиная с предопределенного списка сидов (например, Wikipedia.com, WSJ.com, NYT.com). Он прочитает каждую страницу, сохранит ее и добавит новые ссылки в свою границу URL-адресов, которая представляет собой очередь ссылок для сканирования.
Фото Кевина Грива на Unsplash google.com/robots.txt. На этой странице указаны правила, которые должен соблюдать сканер, чтобы не нарушать какие-либо законы и не считаться спамером. Например, некоторые поддомены не могут быть просканированы, и между каждым сканированием может пройти минимальное время.
Почему здесь так много времени? Интернет очень неструктурирован, мечта анархиста. Конечно, у нас могут быть некоторые нормы, с которыми мы согласны, но вы никогда не поймете, насколько они нарушены, пока не напишете сканер .
Например, ваш поисковый робот читает HTML-страницы, поскольку они имеют структуру. Автор все еще может, например, поместить не-ссылки в теги ссылок, которые нарушат некоторую неявную логику в вашей программе. Это могут быть электронные письма ([email protected]), предложения и другой текст, который может быть пропущен при проверке.
Это могут быть электронные письма ([email protected]), предложения и другой текст, который может быть пропущен при проверке.
Возможно, вы сканируете страницу, которая каждый раз выглядит по-разному, но на самом деле генерирует динамическое содержимое, например включая текущее время? Что, если страница A перенаправляет на B, B перенаправляет на C, а C перенаправляет на A? Что, если в календаре есть бесчисленные ссылки на будущие годы или дни?
Это некоторые из многих случаев, которые могут возникнуть при сканировании миллионов страниц , и каждый пограничный случай должен быть покрыт или устранен .
После того, как вы сохранили просканированный контент в базе данных, наступает очередь индексации! Когда пользователь ищет термин, он хочет получить точные результаты быстро. Вот где индексация так важна. Вы сами решаете, какие показатели для вас наиболее важны, а затем извлекаете их из просканированного документа. Вот некоторые из них:
- Прямой индекс : Это структура данных, содержащая список документов со связанными с ними словами по порядку. Например:
 Например:
Например:документ1, <слово1, слово2, слово3>
документ2, <слово2, слово3>
- Инвертированный индекс : Это структура данных, содержащая список слов с документами с этим словом. Например:
слово1, <документ2, документ3, документ4>
слово2, <документ1, документ2>
- Частота терминов (TF) : это показатель, сохраняемый для каждого уникального слова в каждом документе. Обычно он рассчитывается как количество вхождений этого слова, деленное на количество слов в документе, в результате чего получается значение от 0 до 1. Некоторые слова могут иметь больший вес (например, специальные теги), и TF может быть нормализован. предотвращение экстремальных значений.
- Обратная частота документа (IDF) : Это показатель, сохраняемый для каждого уникального слова. Обычно он рассчитывается делением количества документов с этим словом на общее количество документов. Учитывая, что для этого требуется количество документов, оно обычно рассчитывается после сканирования или во время запроса. Это может быть нормализовано, чтобы предотвратить экстремальные значения.
 Это может быть нормализовано, чтобы предотвратить экстремальные значения.
Это может быть нормализовано, чтобы предотвратить экстремальные значения.С помощью этих четырех значений вы можете разработать индексатор, который позволит вам возвращать точные результаты. Благодаря оптимизации текущих баз данных результаты также будут достаточно быстрыми . Используя MongoDB, наш проект использовал их для возврата результатов примерно за 2 секунды даже для более длинных запросов. С помощью этих четырех метрик можно сделать еще больше — например, разрешить запросы на точное соответствие.
Это были основные показатели, используемые поисковыми системами в первые дни. Теперь поисковые системы используют их и многое другое для дальнейшей точной настройки своих результатов.
Как их объединить для получения результатов? Мы обсудим это в разделе интеграции.
PageRank — это алгоритм, определяющий авторитет страницы в Интернете. Скажем, кто-то ищет «День Земли». Нам нужно посмотреть, насколько надежна страница. Если мы этого не сделаем, наша поисковая система может отправить их на случайную страницу блога, на которой снова и снова написано «День Земли», а не на страницу Википедии или EarthDay.org. При распространении SEO и маркетологов, пытающихся привлечь трафик на страницу, как мы можем гарантировать, что пользователи получат качественные результаты?
Если мы этого не сделаем, наша поисковая система может отправить их на случайную страницу блога, на которой снова и снова написано «День Земли», а не на страницу Википедии или EarthDay.org. При распространении SEO и маркетологов, пытающихся привлечь трафик на страницу, как мы можем гарантировать, что пользователи получат качественные результаты?
PageRank просматривает ссылки между страницами, рассматривая их как граф (набор узлов и вершин) . Каждая вершина представляет собой соединение между двумя узлами в том направлении, в котором она указывает (URL-адрес источника к URL-адресу назначения)
На каждой итерации алгоритм просматривает все URL-адреса, указывающие на страницу, скажем, Google.com. Он дает Google некоторый процент от PageRank своих рефереров в зависимости от того, сколько других URL-адресов также указывают эти страницы. После нескольких итераций значения PageRank становятся относительно стабильными, и алгоритм завершает работу.
Источник: https://en.wikipedia.org/wiki/PageRank#/media/File:PageRanks-Example.jpg
Используются и другие уловки, такие как случайный просмотр, который предполагает, что некоторый процент времени пользователь получает скучно и переходит на новую страницу. Эти уловки направлены на то, чтобы избежать угловых случаев с PageRank. Например, приемники — это страницы, которые могут поглотить весь PageRank из-за отсутствия исходящих ссылок.
Теперь у вас есть основные части для поисковой системы.
Когда пользователь выполняет поиск по фразе, вы ищете, в каких документах содержится каждое из условий запроса. Ваша база данных возвращает документы, которые соответствуют всем терминам.
Для каждого документа вы можете взять TFIDF (TF * IDF) для каждого термина запроса и суммировать их вместе. Затем объедините сумму с PageRank этой страницы (например, перемножив их вместе) . Это больше искусство, чем наука, так что оставьте время, чтобы увидеть, что работает, настраивая по ходу дела .