Содержание
Как провести конкурс в Telegram — Соцсети на vc.ru
Привет, друзья!
Сегодня команда SharkSale расскажет Вам о способах проведения конкурсов в Telegram.
88 569
просмотров
Когда вы ведёте свой канал, то по любому сталкиваетесь с такой проблемой как просадка активности аудитории. Конечно, если вы делаете регулярные закупы, то проблем с просмотрами у вас не будет. Но что делать тем, у кого бюджет не резиновый и кто не ставит себе цель заработать на телеграм? Правильно можно провести конкурс. Итак теперь давайте подумаем что дарить, как разыгрывать, как вручать. Мы думаем здесь полёт фантазии просто космический. Можно подарить что угодно, начиная от книги и заканчивая банальным iPhone 12. Всё зависит от тематики вашего канала.
Например, если вы ведёте канал о кино, то разыграть можно билеты в кино, купить и вручить их удалённо не составит труда, если у вас канал об адвокатском деле, то вы можете разыграть бесплатную консультацию у юриста, если ваш канал это мемчики то аудитория будет соревноваться за какие-то ценные призы.
Другое дело это механика конкурса, как сделать всё прозрачно, честно и не обломаться. Для начала поставьте перед собой цель. Для чего нужен этот конкурс? Увеличить количество подписчиков, или вы хотите поднять активность подписчиков, или же вам требуется продвинуть узнаваемость вашего бренда? Давайте разбираться, заодно мы приведём примеры нескольких вспомогательных сервисов и ботов.
Google Forms
Разобраться с Гугл формами сможет любой админ, а подписчикам будет удобно их заполнять.
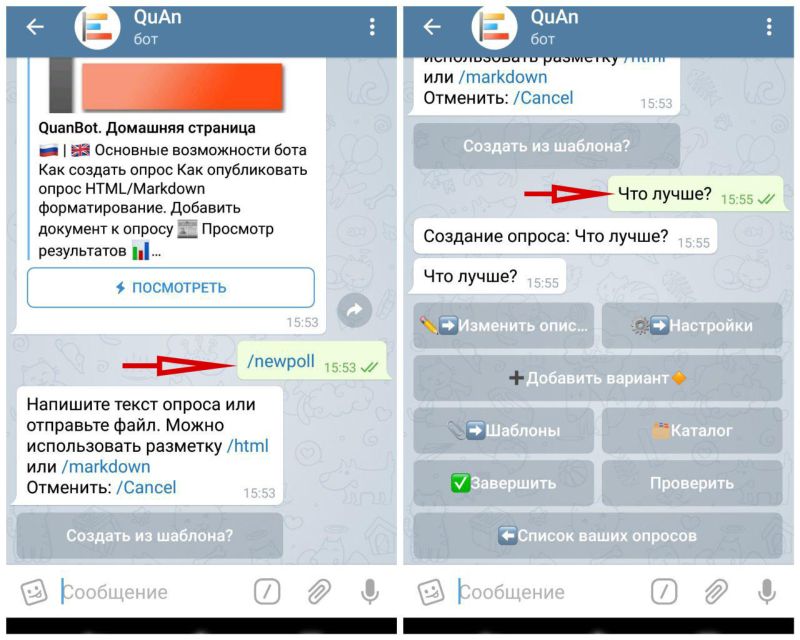
- Для начала идём на https://www.google.com/intl/ru_ua/forms/about/ авторизуемся и создаём свою анкету.
- Нужно в форме прописать дополнительно условия конкурса и спросить у подписчика только то, что корректно спрашивать. Например страну и город проживания, пол, возраст и пр. вопросы, которые вам будет интересно узнать о вашей аудитории.
- Далее делаем анонс конкурса у вас на канале, прописываем все условия, не забываем о ссылке на форму, рассказываем о подарке и датах проведения.

- После того как подписчики начнут заполнять форму вы можете уже отслеживать статистику в виде таблиц и графиков, а по истечению срока вы собираете результаты и начинаете самый интересный этап для участников.
- Берём таблицу, заходим на random.org, записываем видео, определяем победителя.
- Публикуем результаты на канале, связываемся со счастливчиком, вручаем подарок.
В чём польза этого вида конкурса? Вы получаете статистику вашего канала, конкурс максимально прозрачный и удобный в использовании.
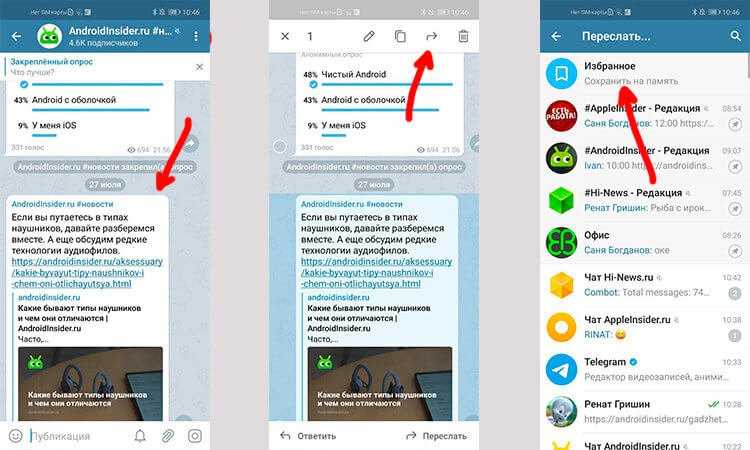
Конкурс с помощью комментариев
В Telegram появились комментарии, так почему бы нам не воспользоваться этим?
- Открываем комментарии на канале (в случае если они закрыты)
— Заходим в настройки канала: 3 точки — «Управление каналом».
— Спускаемся во вкладку «Обсуждение — добавить группу».
— Можно создать новую или добавить существующую.
— Перед привязкой всплывает подсказка, что изменится после — подключения группы — подписчики каналов смогут видеть все обсуждения в группе, а участники группы, соответственно, комментарии с каналов.
— Если у вас уже была ранее привязана группа к каналу, и в ней велись обсуждения, появление в общем чате веток комментариев может сбить с толку завсегдатаев чата. В таком случае, лучше создать новую группу для комментариев, а старую оставить в описании в виде ссылки.
— Чтобы отвязать группу, нужно снова зайти в управление каналом, во вкладке «Обсуждение» нажать на название группы и затем кликнуть «Отвязать группу». - Создаём конкурс и в условии пишем например «напишите под новыми постами …»
- Таким образом каждый Ваш новый пост будет собирать комментарии до момента пока конкурс не подойдёт к концу (некоторые участники будут продолжать писать комментарии ибо привыкнут к этому)
- Заходим на любой пост новый
- Заходим в комментарии
- Заходим на random.org и включаем рандомайзер
- Ищем в комментах участника под таким номером и проверяем его комментарии под другими постами (например выпало число 26, ищем в комментариях 26-го комментатора)
- Участник всё выполнил? — вручаем приз.

Конкурс с помощью бота VoterBi
Ещё один удобный инструмент для проведения конкурсов это бот @VoterBiBot. Что вы сможете получить, используя его. На канале создаётся небольшой пост с кнопкой и таймером. Вы самостоятельно задаёте количество времени, отведённого на конкурс, а также количество победителей.
Как выглядит пост на канале:
На канале будет также показываться кол-во участников.
Также вам в бота будет приходить оповещение с победителем.
Таким образом вы можете провести небольшой конкурс с моментальным и честным определением победителя практически в пару кликов.
Способ с чатами
Также можно воспользоваться одним из проверенных способов для проведения конкурсов и увеличения активности с помощью чатов. Здесь важно придумать что-то интересное. Миниквест, задачки или пасхалки в постах. Мы наблюдали интересную механику конкурса от Samsung. Они разыгрывают у себя на YouTube канале свой смартфон и по условиям конкурса нужно собрать номер телефона из элементов, которые спрятаны у них в роликах и позвонить на него, кто первый это сделает тот получит новенький гаджет.
- Почему бы не внедрить это в телеграм канал? Размещаете элементы ссылки чата у себя в постах, люди читают, собирают их в кучу и кто первый вступит в чат того и приз.
- Либо другой вариант, вы анонсируете конкурс, анонсируете чат и говорите людям, что самый активный участник чата получит подарок, активность можно узнать с помощью @combot (должен быть заранее подключён).
- А как вам такой вариант — «мы выберем победителя случайным образом из всех участников чата, подписывайтесь и ждите розыгрыша»
В каждом из способов есть свои минусы, но они в принципе рабочие.
Конкурс по итогам голосования
Если у вас канал с контентом который присылают подписчики, сделайте возможность наградить их за это. Вы можете поощрить каждого, кто присылает пост, а можете выбирать одного победителя по итогам недельного голосования. Люди будут стремиться к вашему каналу, будут звать друзей голосовать за них. Но главный минус этого способа — накрутчики.
Но главный минус этого способа — накрутчики.
Итог
По сути идей для проведения конкурсов огромное множество, мы вам рассказали только об основных способах, но зачем вас ограничивать в креативности. Придумайте что-то интересное, поэкспериментируйте, проведите свой первый конкурс и пишите нам, делитесь результатами. Если у вас есть ещё какие-либо интересные идеи для конкурсов — присылайте, будем дополнять нашу статью.
________________________________________
Спасибо за прочтение!
Сохраняйте, лайкайте статью и подписывайтесь на аккаунт чтобы не забыть важные моменты и не пропустить новые полезные статьи 🙂
________________________________________
С ув. SharkSale 🦈
Как провести конкурс в Telegram канале и чате? — Евгения Гончаренко на vc.ru
Провести конкурс в Telegram на своем канале очень просто, представляю Вам телеграм бота @Random_KZ_bot, который имеет открытый исходный код и поможет провести любой конкурс рандомно.
4807
просмотров
Вы можете добавлять до 100 победителей, выбирать дату и время начала и конца конкурса, оформлять розыгрыш гиф-анимацией и завлекающей кратинкой.
Бот опубликует победителей рандомно в момент окончания конкурса.
Так же для Вас публикуем инструкцию по работе с ботом, он простой в управлении, но вдруг Вам она понадобится.
В данном руководстве будет продемонстрирован процесс создания гивов, проверка подписки и другие функции бота.
Для начала пишем стандартную команду «/start»
Далее мы видим меню бота, оно не сложное.
Раздел меню «Создать розыгрыш»
для добавления конкурса на канал нам понадобится данный раздел, но сперва рассмотрим и другие кнопки в меню:
«Мои розыгрыши» — тут Вы можете посмотреть текущие созданные конкурсы, где либо еще не было постинга на канале (допустим Вы запланировали начало конкурса через 3 дня), либо постинг о конкурсе уже был, но победитель будет обьявлен позже.
«Мои каналы» — список ваших каналов, в которые вы добавили нашего бота для розыгрышей.
«Создать розыгрыш» — то о чем пойдёт речь ниже.
Нажимаем кнопку «Создать конкурс»
Уп-с.. у нас не добавлен канал, давай добавим его вместе.
Нажимаем «Мои каналы», «Добавить новый канал»
Собственно в пояснении всё написано:
Нам нужно добавить бота в качестве администратора канала с возможностью отправлять сообщения. Я захожу в свой канал, в раздел «Добавить администратора» и вписываю url.
Оставляю ему такие права
После добавления бота в качестве администратора у вас появится вот такое уведомление.
Внимание, на данном этапе происходит проверка, Вы должны быть админом канала, на котором будет происходить розыгрыш (конкурс). Так же бот должен быть в списке админов данного канала, чтобы осуществить постинг в заданное время.
Переходим к процессу Создания розыгрыша.
Как указано в сообщении на картинке мы можем добавить не просто текст для розыгрыша, но и фото к этому тексту. Вы должны описать что именно Вы разыгрываете, обязательно укажите на какие каналы необходимо подписаться для участия. Используйте гиперссылку, чтобы можно было нажать на нее и сразу перейти в нужный канал. Так же обязательно укажите сколько будет победителей, что они выиграют, не забудьте указать дату окончания конкурса
Вы должны описать что именно Вы разыгрываете, обязательно укажите на какие каналы необходимо подписаться для участия. Используйте гиперссылку, чтобы можно было нажать на нее и сразу перейти в нужный канал. Так же обязательно укажите сколько будет победителей, что они выиграют, не забудьте указать дату окончания конкурса
После отправки вы увидите это
✅Фото добавлено
✅Текст добавлен
Осталось выбрать текст на кнопке. Я выберу 1 вариант.
А теперь внимание! Все каналы, которые будут принимать участие в конкурсе должны добавить наш бот в качестве администратора, чтобы бот мог сравнивать аудиторию, и правильно выбрать победителя. Но если розыгрыш подходит без обязательных подписок, то вы должны нажать на соответствующую кнопку.
Я выбрал один канал, нажал на кнопку «Достаточно», и бот сохранил эти функции.
Далее я указываю сколько будет победителей и выбираю канал из списка.
Теперь я планирую публикацию. В примерах вы можете увидеть, как правильно оформлять конкурс.
После выбора даты проведения конкурса бот запросит условия по завершению (время или количество участников). По времени или по количеству
Я указываю когда он будет завершен.
Мой выбор по времени. Я указываю время его завершения.
Сохраняем розыгрыш и ждем когда он будет опубликован.
Это дополнительная рекомендация, а не наставление. Я использую функцию «подписывать сообщения», чтобы люди видели, кто писал этот текст.
И так, вот опубликованное сообщение (подписанное ботом)
И вот наши заветные победители, и сообщение подписано ботом.
Любой пользователь может проверить результаты на честность, нажав на кнопку «Проверить результаты»
Я покажу несколько примеров конкурсов, чтобы Вы наглядно увидели как другие админы оформляют свои гивы в телеграм на примере популярного канала «MDK», где иногда проходят подобные гивы.
Итак, мы разобрались теперь как можно использовать бота @Random_KZ_bot для проведения гивов на каналах. Данный бот имеет честный открытый код, представленный на github.
Данный бот имеет честный открытый код, представленный на github.
Если у Вас остались вопросы по использованию бота, Вы можете задать все возникшие вопросы чат боту сапорту @Random_KZ_feedback_bot
Удачных Вам конкурсов!
Теги для поиска:
Как провести конкурс в телеграмме?
Как провести конкурс в чате телеграмм?
Как провести конкурс в телеграмм канале?
Как провести конкурс в Telegram канале?
Как провести конкурс в Telegram чате?
Продвигайте свои розыгрыши и конкурсы в WhatsApp, Telegram и Line
- 2023-02-13
Whatsapp, Telegram и Line, эталонные приложения для обмена мгновенными сообщениями, стали предпочтительным средством связи для миллионов пользователей по всему миру. Whatsapp является одним из самых популярных, с более чем 600 миллионами пользователей. Его оперативность, простота использования и совместимость с операционными системами всех смартфонов сделали его одним из самых популярных приложений для обмена, распространения и обмена информацией.
- Как делиться конкурсами и розыгрышами в Whatsapp, Telegram и Line
- Розыгрыш WhatsApp: когда запускать акцию для пользователей Whatsapp, Telegram или Line
- Особенности интеграции WhatsApp с Easypromos страница
- Поделитесь розыгрышем в Whatsapp, Telegram или на странице с благодарностью
Более 65% пользователей, которые участвуют в акциях Easypromos, делают это с помощью мобильных устройств. С целью предоставить этим пользователям еще более простой способ делиться рекламными акциями со своими друзьями, мы ввели интеграцию с Whatsapp, Telegram и Line . Организаторы и пользователи акции теперь могут делиться конкурсами и розыгрышами на своих любимых каналах.
В этом сообщении блога мы поговорим о продвижении конкурсов Whatsapp, а также о том, как и почему вы должны делиться своими акциями в этих трех популярных сетях.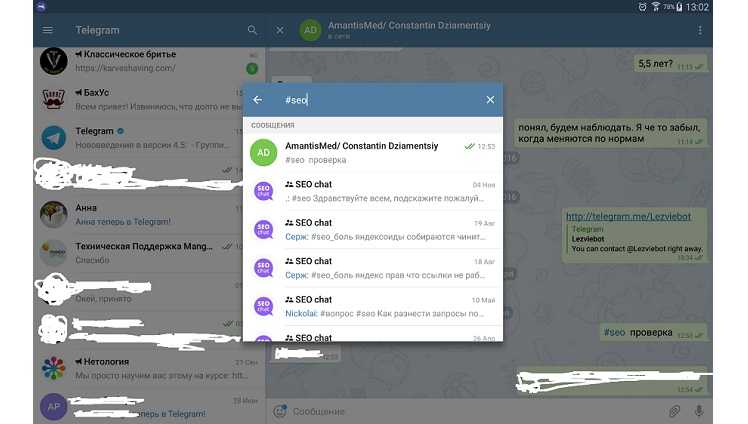
Как делиться конкурсами и розыгрышами в Whatsapp, Telegram и Line
Начнем с того, что все рекламные акции Easypromos, опубликованные на микросайте, могут быть опубликованы в других социальных сетях . Помня об этой цели, участники видят кнопку Поделиться на разных этапах участия. Всего одним щелчком мыши пользователи могут отправить сообщение друзьям или даже целым группам друзей через Whatsapp или другие приложения для обмена сообщениями. В сообщении будет вирусный контент, подготовленный организатором, а также ссылка на акцию.
Вот шаги, чтобы поделиться рекламной акцией в Whatsapp или других приложениях для обмена мгновенными сообщениями:
Хотели бы вы сами проверить возможность обмена акциями? Получите доступ к нашей ДЕМО-версии со своего мобильного телефона!
Используете ли вы WhatsApp для бизнеса? В настоящее время многие бренды предпочитают обслуживать клиентов через Whatsapp, а не по телефону или по электронной почте.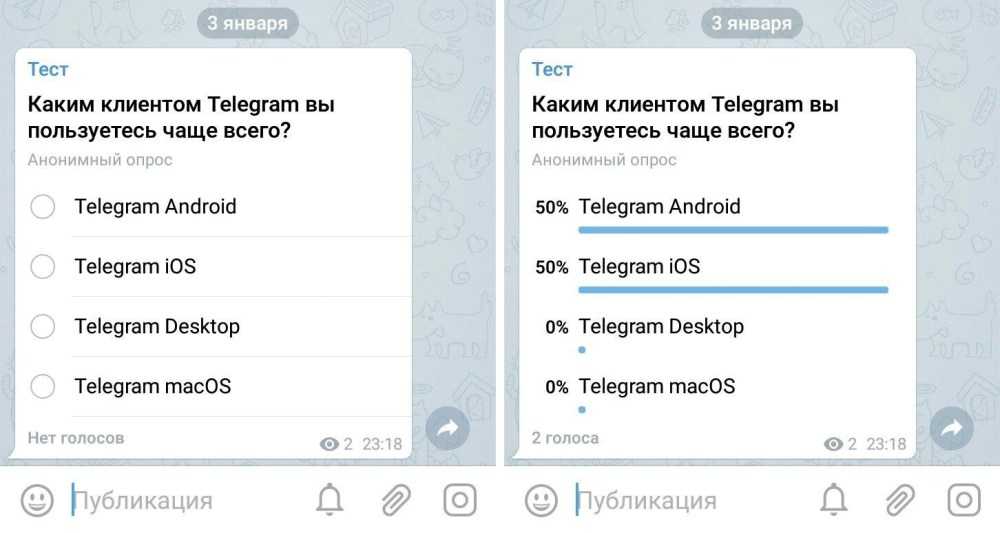 Почему? Потому что легче передавать определенную информацию, например снимки экрана или инструкции, и это экономит время. Может пора поблагодарить всех клиентов, которые связались с вами через Whatsapp, Telegram или Line? Все, что вам нужно сделать, это поделиться с ними прямой ссылкой на розыгрыш или конкурс WhatsApp!
Почему? Потому что легче передавать определенную информацию, например снимки экрана или инструкции, и это экономит время. Может пора поблагодарить всех клиентов, которые связались с вами через Whatsapp, Telegram или Line? Все, что вам нужно сделать, это поделиться с ними прямой ссылкой на розыгрыш или конкурс WhatsApp!
Но давайте не будем забывать, что участники промоакций также склонны делиться акциями со своими друзьями и семьей. Иногда они просто хотят дать им шанс на победу, а иногда пытаются привлечь больше пользователей, чтобы получить более высокие шансы на победу!
Все рекламные акции Easypromos, запущенные на микросайте, доступны для обмена в Whatsapp, Telegram или Line. Вы можете поделиться рекламной акцией или призвать участников сделать это. Кнопка «Поделиться » доступна на различных страницах:
Розыгрыш WhatsApp: поделитесь им со страницы приветствия
Администратор может определить общее сообщение, которым пользователь может поделиться через социальные сети, отправив личное сообщение через Whatsapp, Telegram и Line или по электронной почте:
Участники могут скопировать ссылку на продвижение и вставьте ее прямо в чат WhatsApp, Telegram или Line.
Поделитесь розыгрышем в Whatsapp, Telegram или Line со страницы благодарности
Пользователь может легко поделиться конкурсом или участием, например, изображением, из Спасибо страница.
Посмотрите, сколько пользователей вы привлекли через Whatsapp
Хотите знать, сколько людей участвовало в вашей акции через Whatsapp? Посетите статистику своей акции, чтобы узнать, сколько пользователей узнали о вашей кампании в приложении для обмена мгновенными сообщениями.
Помимо обмена подарками и конкурсами в Whatsapp, Telegram и Line, вы также можете поделиться ими:
- По электронной почте
- В социальных сетях
- На своем веб-сайте, в блоге или электронной коммерции, встроив рекламу на свой сайт
Для кого доступна интеграция Whatsapp, Telegram и Line?
Интеграция с этими приложениями для обмена сообщениями доступна для всех рекламных акций, созданных с помощью версий Easypromos Premium и White Label, а также будет доступна для базовых рекламных акций.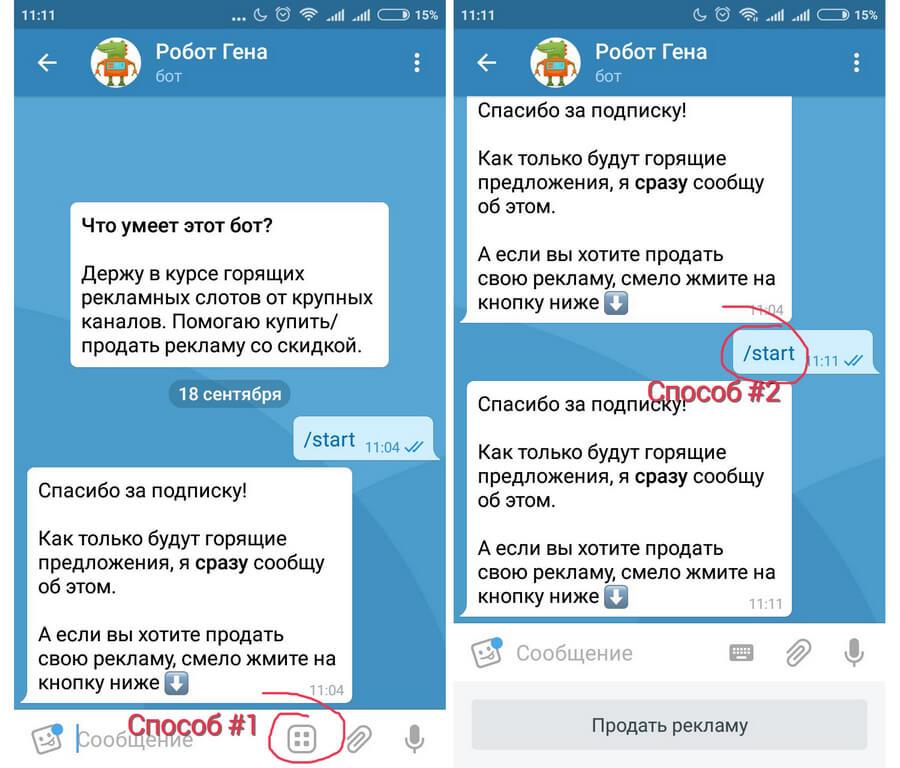
У вас есть вопросы о публикации ваших рекламных акций в Whatsapp и других приложениях для обмена мгновенными сообщениями? Поболтай с нами!
Карлес Бонфилл
Генеральный директор и соучредитель Easypromos. Он имеет степень в области компьютерных наук, специализируясь на управлении сетями, архитектуре и безопасности. В 2009 году он разработал Easypromos, одну из первых глобальных платформ для продвижения, и с тех пор он является техническим директором и директором по развитию. Он внимательно следит за эволюцией цифрового маркетинга, чтобы адаптировать к нему рекламные акции. Карлес любит спорт и свою семью.
Решение, занявшее второе место
Недавно Telegram провел конкурс по кластеризации данных, в котором участникам было предложено создать прототип службы агрегации новостей, аналогичной таким службам, как Новости Google и Яндекс.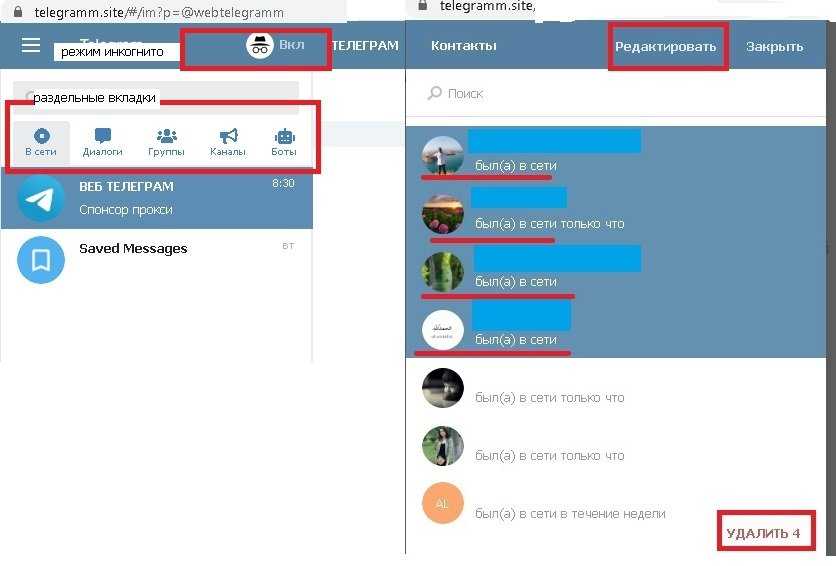 Новости. Я занял второе место в этом конкурсе (псевдоним: Daring Frog), используя только Python, поэтому решил поделиться подробностями своего решения на случай, если оно кому-то покажется полезным. Вы можете проверить баллы за задачу (благодаря Mindful Kitten), сравнить скорость, итоговую таблицу лидеров, код и поиграть с живым приложением, которое выглядит так:
Новости. Я занял второе место в этом конкурсе (псевдоним: Daring Frog), используя только Python, поэтому решил поделиться подробностями своего решения на случай, если оно кому-то покажется полезным. Вы можете проверить баллы за задачу (благодаря Mindful Kitten), сравнить скорость, итоговую таблицу лидеров, код и поиграть с живым приложением, которое выглядит так:
Онлайн-приложение, доступное по адресу: https://entry1410-dcround2.usercontent.dev/20200525/en/
Полное описание доступно на странице конкурса (рекомендую ознакомиться с ним, прежде чем читать этот пост). Вкратце, задача состояла в том, чтобы создать двоичный исполняемый файл, который может выполнять следующие действия:
🗃
Часть 1 — автономная пакетная обработка
- Пройти входной каталог и проанализировать все HTML-файлы (статьи) в нем с содержанием новостей
- Определить язык статьи и отфильтровать статьи не на английском или русском языке
- Классифицировать статьи по одной или нескольким из 7 категорий:
общество,экономика,технология,спорт,развлечение,наука,прочее- Отфильтровать статьи, не являющиеся новостями (например, инструкции, советы, энциклопедический контент)
- Группировать статьи в темы. Тред - это просто сборник статей об одном и том же событии
- Сортировка статей в теме по релевантности
- Сортировать темы по важности
📡
Часть 2 — Онлайн-обработка с помощью HTTP-сервера
- Запустите HTTP-сервер, загрузите его предыдущее состояние, если оно существует
- Указатель входящих статей
- Обновление существующих статей
- Удалить существующие статьи
- Возврат цепочек статей с дополнительными фильтрами по языку, категории и временному диапазону
Помимо этих требований, Telegram подчеркнул, что «скорость имеет первостепенное значение», запросил размер двоичного файла 200 МБ или меньше и потребовал, чтобы двоичный файл выполнялся на автономном 8-ядерном компьютере Debian GNU/Linux 10.
1 с 16 ГБ ОЗУ без графического процессора. . Кроме того, было невозможно протестировать или запустить приложение на стороне Telegram перед отправкой, поэтому участники в основном должны были обеспечить безупречную воспроизводимость. Эти требования были основными факторами, обусловившими мое предпочтение простоты алгоритмов и библиотек, которые я использовал.Отказ от ответственности: поскольку конкурс длился всего 2 недели, в этом решении есть многочисленные недочеты и области для улучшения. Я перечисляю некоторые из них в Приложении A.
🗃 Часть 1 — Пакетная обработка в автономном режиме
1. Предварительная обработка. Входной HTML-код читается как обычный текст. Метатеги для заголовка, описания, URL-адреса и времени публикации извлекаются с помощью простых регулярных выражений. Базовая очистка выполняется для заголовка и описания: удаление знаков препинания и специальных символов, приведение к нижнему регистру (но не для аббревиатур), добавление пробелов вокруг значений валюты (например, «100$» становится «100 $»), ограничение максимальной длины строки.
Слова нормализуются с помощью lemminflect (для английского языка) и OpenCorpora (для RU) для улучшения качества категоризации и кластеризации (описано ниже), поскольку это помогает уменьшить размер словаря и уменьшить переоснащение. Оригинальные тексты сохраняются и используются вместе с очищенными, в зависимости от задачи.2. Определение языка. Определение языка выполняется с помощью библиотеки fastText (
lid.176.bin). Язык устанавливается равнымUNK, если показатель достоверности fastText ниже заданного порога. Дополнительные эвристики (сопоставление определенных символов и популярных фраз) используются для устранения неоднозначности угловых случаев для языков, которые fastText считает похожими на русский (UA, TG, BG).Предварительная обработка и определение языка выполняются совместно с использованием 16 потоков, объединенных в
multiprocessingкак HTML-файлы, которые можно обрабатывать независимо.3. Классификация категорий. Классификация по категориям выполняется с использованием простого SGDClassifier из scikit-learn с
modified_huberпотеря. Входными данными для модели является вектор из TfidfVectorizer, который запускается при объединении заголовка статьи, домена и описания с максимальной длиной такого текста, ограниченной 500 символами. TfidfVectorizer работает с уни- и биграммами (со стоп-словами NLTK), использует сублинейное масштабирование TF,min_df=3,max_df=0,95иdtype=np.float32.Для этой задачи отлично подходит простой SGDClassifier:
- Он очень хорошо отражает широту словарного запаса, что важно, поскольку в мире новостей существует много терминов, относящихся к конкретным категориям, и часто необходимо запоминать их на основе только на нескольких доступных примерах. Например. Размер словарного запаса TfidfVectorizer составляет 142 КБ для RU и 70 КБ для EN, что считается большим для типичного варианта использования, но вполне подходит для захвата разнообразия новостей.
- С такой простой моделью можно избежать переобучения даже при использовании такого большого словаря и небольшого набора данных.
- Он невероятно быстр и поддерживает ввод разреженных матриц. Разреженность означает, что мы можем 1) эффективно работать с большим объемом словаря без необходимости передавать выходные данные TF-IDF через дорогостоящий этап SVD и 2) нет необходимости поддерживать массивные матрицы внедрения, которые занимают ОЗУ, место на диске и приводят к перепараметризации. модели.
- Его легко интерпретировать и отлаживать (можно легко проследить предсказания модели вплоть до веса, присвоенного каждому словарному термину).
Я также рассматривал десятки других типов моделей — см. Приложение B, почему они не были выбраны.
TfidfVectorizer и SGDClassifier обучены на таких наборах данных, как Lenta.ru (RU), HuffPost (EN), TagMyNews (EN), News Aggregator Dataset (EN), BBC (EN), Webhose (EN), а также веб-сайтах, просканированных вручную для категорий новостей (например, технологии, автомобили, погода), которые пострадали от нехватки меток в вышеупомянутых наборах данных.
Обучающий набор был дополнительно обогащен с использованием неразмеченных выборочных данных, предоставленных Telegram, путем автоматического назначения меток категорий с использованием информации URL статьи: например. если /футбол/находится в URL авторитетного домена, и мы можем отнести его кспортивнойкатегории с очень высокой степенью достоверности. В целом, сохраняя разумное распределение примеров по классам (примерно совпадающие соотношения, ожидаемые на момент вывода), мне удалось получить примерно 120 тыс. обучающих примеров для английского языка и 313 тыс. для русского языка. В таблице ниже вы можете увидеть количество и соотношение обучающих примеров по категориям:4. Фильтрация новостей . Фильтрация новостей основана на наборе эвристик, которые представляют собой простые правила, основанные на следующих функциях:
- Классификатор категории (описан выше) показатель достоверности
- Количество токенов в названии/описании статьи
- Наличие специальных символов
- Сопоставление предварительно одобренных или предварительно запрещенных слов, единиц подслов или лемм
- Заголовок, соответствующий некоторым предварительно скомпилированным регулярным выражениям: статьи с практическими рекомендациями, плохие фразы, плохие начала заголовков, списки/перечисления (например, «10 советов для…») и т. д.
- Совпадение с заведомо неверным шаблоном заголовка. Это небольшая хитрость, которую вы можете использовать для поиска шаблонных (например, автоматически сгенерированных) заголовков, по сути, путем преобразования заголовка в код (например,
Музыка — Lounge. 27.03.2020.становитсяW — W. ##.##.####.) и группировать такие коды или просто проверять наиболее частые. Это занимает всего пару строк кода:
Подробные правила можно посмотреть в скрипте вывода.
5. Кластеризация потоков . Новости объединяются в потоки с помощью DBSCAN со следующими параметрами:
min_samples=2, eps=0,55, metric='cosine', который выполняется на векторах TF-IDF заголовков статей. Векторы TF-IDF создаются с помощью TfidfVectorizer с функцией токенизации SentencePiece. Так же, как и для классификации новостей, я поставилdtype=np.float32для векторизатора TF-IDF, чтобы немного ускорить работу. Модели TfidfVectorizer и SentencePiece обучаются на всех примерах статей на английском и русском языках, предоставленных Telegram (~ 600 000 на каждый язык). Модель SentencePiece имеет словарь размером 10 тыс. токенов. Кроме того, для некоторых токенов (например, связанных с географическим положением) я повышаю баллы TF-IDF, чтобы придать им большее значение в кластеризации (это, например, приводит к тому, что новости с одинаковыми названиями из несвязанных городов принудительно помещаются в отдельные кластеры).6. Сортировка статей в потоке. Внутри кластеров статьи в первую очередь сортируются по релевантности (вычисляется как сумма скалярных произведений с векторами всех других статей в кластере). Также выполняется вторичная и третичная сортировка по PageRank домена и свежести соответственно. При сортировке я гарантирую, что ни одна пара последовательных статей не принадлежит одному и тому же издателю, что обеспечивает некоторое разнообразие в ленте.
Для названия ветки статей я просто использую заголовок верхней статьи в отсортированном списке. Все операции кластеризации выполняются на одной разреженной матрице и поэтому выполняются достаточно быстро.7. Сортировка нитей. Ветки новостей сортируются просто по произведению количества уникальных доменов в ветке на объединенный PageRank этих доменов. И если этот балл одинаков для двух статей, выполняется дополнительная сортировка по количеству статей в треде. Категория темы определяется просто как наиболее часто встречающаяся категория среди статей в теме. PageRank домена был рассчитан с использованием образцов статей, предоставленных Telegram для всех доменов с не менее чем 100 публикациями (~ 3 000 доменов).
📡 Часть 2 — Онлайн-обработка
с HTTP-сервером
1. Запустите HTTP-сервер. Для обработки HTTP-запросов используется SimpleHTTPRequestHandler.
Сервер отвечает HTTP/1.1 503 Служба недоступнадо загрузки ресурсов (таких как модели, векторизаторы, словари и предыдущее состояние индекса).2. Указатель входящих статей. Поскольку статьи поступают бесконечным потоком, нам в основном приходится выполнять кластеризацию в реальном времени, поскольку потоки статей могут расширяться или изменяться со временем. Из описания конкурса не было ясно, можем ли мы терпеть какие-либо задержки при кластеризации, поэтому я решил выбрать решение, в котором индексы и кластеры статей всегда актуальны. Для этого я написал наивный алгоритм агломерационной кластеризации, похожий на SLINK.
Шаг 0: Входящая статья предварительно обрабатывается, векторизуется и классифицируется, как описано выше в автономном разделе. В случае, если статья не {EN,RU} или не является новостью, мы сохраняем ее как таковую и пропускаем следующие шаги.
Шаг 1: Для плетения изделий в нити мы работаем с 16-часовыми интервалами (ковшами). Для данной статьи извлекаются ее предыдущие, текущие и будущие сегменты, т. е. рассматривается 48-часовое окно (мы предполагаем, что ни один поток статей не будет занимать более двух полных дней). Нам нужно заглянуть в «будущее», так как возможно, что некоторые статьи приходят с задержкой, например. если краулер найдет вчерашнюю статью, мы можем захотеть сшить ее в кластер из сегодняшнего дня.
Шаг 2: Выбираются токены заголовков статей с оценкой IDF ниже заданного порога (т. е. мы игнорируем слишком общие термины). Для таких токенов в каждом сегменте (прошлом, настоящем и будущем) мы выполняем поиск по инвертированному индексу, чтобы получить подмножество ранее проиндексированных статей, которые имеют один или несколько общих терминов с текущей статьей. Перевернутый индекс — это простая lil_matrix, где строки — это идентификаторы терминов, а столбцы — идентификаторы статей, поэтому мы можем выполнить поиск по идентификаторам токенов из вектора TF-IDF, чтобы получить идентификаторы соответствующих статей, которые затем можно использовать для поиска векторов. («встраивания») релевантных статей в основную матрицу «встраивания».
Шаг 3: Среди этих статей-кандидатов мы находим самую близкую статью по сходству скалярного произведения, рассчитанному на L2-нормализованных векторах TF-IDF. Если мы находим существующую статью, сходство которой выше заданного порога, мы можем присвоить нашу новую статью кластеру с существующей статьей. Если мы не находим существующую статью, которая достаточно похожа, мы создаем новый кластер.
Шаг 4: L2-нормализованный вектор TF-IDF для новой статьи накладывается поверх существующей матрицы CSR с векторами для ранее проиндексированных статей в этом периоде времени. Матрица CSR отлично подходит для этого варианта использования, поскольку она обеспечивает быстрое умножение, прекрасно сочетается с разреженностью векторизатора TF-IDF, обеспечивает быстрое v-стекирование и удаление строк, и в целом представляется наиболее эффективной разреженной матрицей для этого варианта использования. Обратите внимание, что каждый период времени имеет свою собственную матрицу CSR, что значительно ускоряет скалярное произведение (поскольку мы можем игнорировать векторы для всех других нерелевантных периодов времени), а также гарантирует, что индекс может масштабироваться линейно со временем (если мы сильно упрощаем и предполагаем постоянное дневное число новостей).
Шаг 5: Все другие соответствующие свойства инвертированного индекса и информации о кластере (максимальное время, категория, список статей) обновляются соответствующим образом.3. Обновить существующие статьи. Обновление статьи происходит, если какой-либо из ее атрибутов изменился, и осуществляется простым ее удалением и повторной индексацией.
4. Удалить существующие статьи. Удалить статью просто, так как мы просто стираем всю информацию об этой статье. Один потенциально интересный момент здесь заключается в том, что мы хотим удалить строку из матрицы «встраивания» (с нормализованными векторами TF-IDF), что не является тем, что матрица CSR поддерживает по умолчанию.
К счастью, мы можем выполнять эффективное удаление на месте следующим образом:5. Возврат цепочек статей с дополнительными фильтрами по языку, категории и временному диапазону. Это просто, так как нам нужно всего лишь перебирать соответствующие периоды времени для данного языка и возвращать потоки статей, которые принадлежат к данной категории в пределах указанного диапазона времени.
Telegram потребовал предоставить исполняемый двоичный файл в заявке на конкурс. Также было дополнительное требование, чтобы размер двоичного файла не превышал 200 МБ. Поэтому я использовал отдельную среду conda с минимальным набором используемых библиотек (всего
fasttext,numpy,scipy,scikit-learn,предложение). Используя эту среду, легко создать облегченный двоичный исполняемый файл, указавpyinstallerна сценарий вывода Python:.
выполните следующую команду (следуя API, описанному здесь): ./tgnews threads "/path/to/directory/with/articles".Или просто запустите его напрямую с помощью скрипта Python, например:
python tgnews.py threads "/path/to/directory/with/articles".В конце концов, мое решение представляет собой просто комбинацию
Python,fastText,SentencePiece,TF-IDF,SGDClassifierиDBS CAN. Я нахожу его очень простым и немного хакерским, но, несмотря на это, он оказался вторым по качеству и третьим по скорости выполнения (на уровне или быстрее, чем решения C++ 🤷♂). Эта простота позволила мне делать все на моем старом MacBook Pro 2012 года, что редко возможно в соревнованиях, подобных Kaggle.Есть много вещей, которые я хотел бы сделать по-другому, и я перечисляю некоторые из них ниже.
Надеюсь, вам было интересно это читать и вы узнали что-то новое. Если у вас есть какие-либо вопросы, свяжитесь со мной в LinkedIn. Я также настоятельно рекомендую прочитать несколько подробных обзоров замечательных решений, занявших 1-е и 3-е места в конкурсе.И, конечно же, в заключение я хотел бы поблагодарить организаторов за организацию этого мероприятия. Это было очень весело, и я определенно многому научился.
- Поддержка параллельных запросов. На этапе оценки команда Telegram отправляла до 100 параллельных запросов к двоичному файлу, что не поддерживалось моим представленным приложением. К счастью, они все еще могли отправлять запросы в одном потоке для большинства этапов оценки, но этого нельзя было сделать для режима «Сегодня», поэтому мое приложение полностью вылетало там. Я думал, что это полностью дисквалифицироват мою заявку, но, вероятно, хорошие результаты во всех других задачах помогли с окончательным рейтингом.
- Фильтрация новостей должна основываться на модели, а не на наборе эвристик на основе регулярных выражений. Одной из идей может быть объединение задач по фильтрации новостей и категоризации, как это сделали некоторые участники (1, 2), однако может быть выгодно разделить их. В любом случае есть необходимость в тщательно помеченных «неновостных» примерах, поскольку это нечетко определенное понятие, для которого практически нет общедоступных данных.
- Модели категоризации новостей явно не хватает глубины (т. е. она не принимает решения на основе «значения», а скорее основывает их на запоминании определенных ассоциаций терминов и категорий). Если позволяют вычислительные ресурсы, было бы полезно объединить широту текущей модели с глубиной и нелинейностью, которую привносят нейронные сети. Это можно сделать с помощью моделей Wide & Deep, ансамблей моделей или других методов.
- Предварительно обученные встраивания могут быть добавлены по всему конвейеру (фильтрация новостей, категоризация, кластеризация). Я полностью опустил их из-за требований к размеру двоичного файла 200 МБ.
- Следует использовать другие функции статьи и издателя. Использование только заголовка, URL и части описания крайне ограничено.
- Текущая кластеризация, основанная на исчерпывающем поиске точечного произведения, должна быть отброшена в пользу масштабируемых высокопроизводительных методов ANN, подобных ScaNN, HNSW и FAISS. Это поможет поддерживать индексы размером в миллионы и миллиарды, сохраняя при этом низкую задержку.
- , а также машины с большой памятью (RAM) для хранения соответствующих частей индекса в памяти.
- Создание помеченного набора данных для конкретной задачи. Было бы не слишком дорого получить метки 100K-1M, этого должно быть достаточно для тонкой настройки моделей, обученных на общедоступных наборах данных. Если бюджет является ограничением, вам поможет активное обучение. Не маркируя образцы статей, я, вероятно, столкнулся с перекосом в пользу обучения и всевозможными другими нежелательными предубеждениями. Команда с 1-го места пометила статьи с помощью оценщиков, что позволило им значительно превзойти другие отправленные материалы в задаче категоризации.
Следует использовать GPU/TPU
- HDBSCAN для пакетной автономной кластеризации. Обычно HDBSCAN — это удобный инструмент для кластеризации, который очень хорошо масштабируется и дает очень качественные результаты. Однако здесь DBSCAN превзошел его как по качеству, так и по скорости IIRC.
- BIRCH для потоковой кластеризации (слишком медленно).
- DenStream для потоковой кластеризации (пользовательский алгоритм был более гибким).
- FAISS для потоковой кластеризации (IIRC, это было ненамного быстрее, чем хорошо оптимизированные операции с разреженными матрицами, особенно при небольших объемах данных).
- Использование
float16(вместоfloat32). Исходя из мира графических процессоров, я подумал, что это то, чтоscipyиnumpyтакже могут поддерживать, но, к сожалению, это не так, посколькуfloat16не поддерживается на ЦП. - Другие типы моделей для классификации новостей. Я пробовал все, начиная с
scikit-learn, которые работают с разреженными входными данными. Никакая другая модель не может сравниться по качеству и скорости с простымSGDClassifier.ComplementNBбыл близок или немного лучше по производительности, но приводил к большему размеру двоичного файла. - Другие фреймворки для классификации новостей (TF, Keras, PyTorch): я исключил их с самого начала, чтобы размер двоичного файла был небольшим, а вывод был быстрым. Добавление TF к отдельному двоичному файлу приведет к тому, что его размер превысит 200 МБ.
- Загрузка текстовых файлов в формате
jsonилиgzip. Это значительно медленнее, чем старый добрыйpickleиз-за декомпрессии и необходимости анализироватьjsonфайл. - Обход фильтрации новостей для всех статей ведущих издателей по PageRank. Идея заключалась в том, что, возможно, они никогда не будут публиковать неновостной контент. Я был не прав, иногда попадаются статьи, которые по описанию задачи будут классифицироваться как «не новости».
- Использование взвешенных по TF-IDF вложений CBOW fastText для кластеризации (вместо разреженных векторов TF-IDF). Обычно вы обнаружите, что взвешенные по TF-IDF вложения (например, word2vec) являются очень сильной, быстрой и простой базовой линией, но здесь они были медленнее и приводили к более размытым кластерам.
- английских флексий из WordNet.
 Тред - это просто сборник статей об одном и том же событии
Тред - это просто сборник статей об одном и том же событии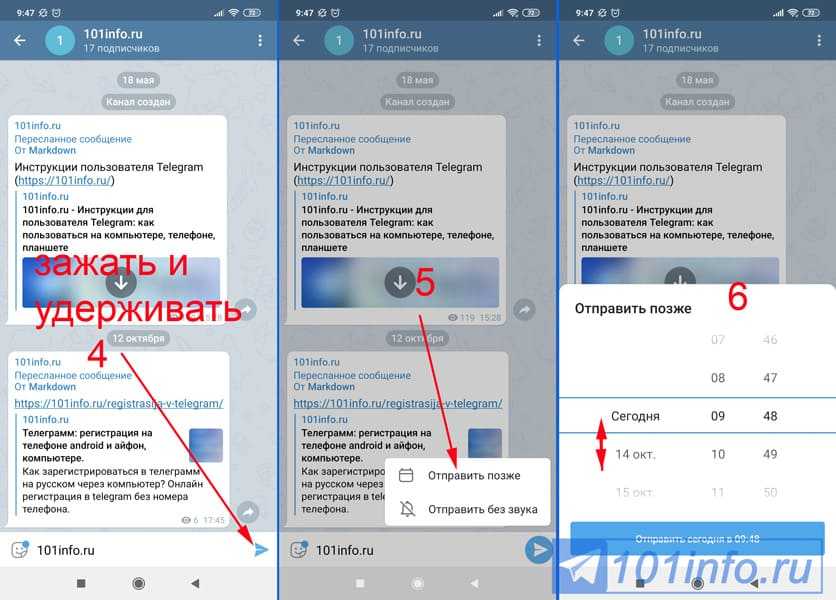 1 с 16 ГБ ОЗУ без графического процессора. . Кроме того, было невозможно протестировать или запустить приложение на стороне Telegram перед отправкой, поэтому участники в основном должны были обеспечить безупречную воспроизводимость. Эти требования были основными факторами, обусловившими мое предпочтение простоты алгоритмов и библиотек, которые я использовал.
1 с 16 ГБ ОЗУ без графического процессора. . Кроме того, было невозможно протестировать или запустить приложение на стороне Telegram перед отправкой, поэтому участники в основном должны были обеспечить безупречную воспроизводимость. Эти требования были основными факторами, обусловившими мое предпочтение простоты алгоритмов и библиотек, которые я использовал. Слова нормализуются с помощью lemminflect (для английского языка) и OpenCorpora (для RU) для улучшения качества категоризации и кластеризации (описано ниже), поскольку это помогает уменьшить размер словаря и уменьшить переоснащение. Оригинальные тексты сохраняются и используются вместе с очищенными, в зависимости от задачи.
Слова нормализуются с помощью lemminflect (для английского языка) и OpenCorpora (для RU) для улучшения качества категоризации и кластеризации (описано ниже), поскольку это помогает уменьшить размер словаря и уменьшить переоснащение. Оригинальные тексты сохраняются и используются вместе с очищенными, в зависимости от задачи.
 Обучающий набор был дополнительно обогащен с использованием неразмеченных выборочных данных, предоставленных Telegram, путем автоматического назначения меток категорий с использованием информации URL статьи: например. если
Обучающий набор был дополнительно обогащен с использованием неразмеченных выборочных данных, предоставленных Telegram, путем автоматического назначения меток категорий с использованием информации URL статьи: например. если  д.
д. Модели TfidfVectorizer и SentencePiece обучаются на всех примерах статей на английском и русском языках, предоставленных Telegram (~ 600 000 на каждый язык). Модель SentencePiece имеет словарь размером 10 тыс. токенов. Кроме того, для некоторых токенов (например, связанных с географическим положением) я повышаю баллы TF-IDF, чтобы придать им большее значение в кластеризации (это, например, приводит к тому, что новости с одинаковыми названиями из несвязанных городов принудительно помещаются в отдельные кластеры).
Модели TfidfVectorizer и SentencePiece обучаются на всех примерах статей на английском и русском языках, предоставленных Telegram (~ 600 000 на каждый язык). Модель SentencePiece имеет словарь размером 10 тыс. токенов. Кроме того, для некоторых токенов (например, связанных с географическим положением) я повышаю баллы TF-IDF, чтобы придать им большее значение в кластеризации (это, например, приводит к тому, что новости с одинаковыми названиями из несвязанных городов принудительно помещаются в отдельные кластеры). Для названия ветки статей я просто использую заголовок верхней статьи в отсортированном списке. Все операции кластеризации выполняются на одной разреженной матрице и поэтому выполняются достаточно быстро.
Для названия ветки статей я просто использую заголовок верхней статьи в отсортированном списке. Все операции кластеризации выполняются на одной разреженной матрице и поэтому выполняются достаточно быстро. Сервер отвечает
Сервер отвечает  Для данной статьи извлекаются ее предыдущие, текущие и будущие сегменты, т. е. рассматривается 48-часовое окно (мы предполагаем, что ни один поток статей не будет занимать более двух полных дней). Нам нужно заглянуть в «будущее», так как возможно, что некоторые статьи приходят с задержкой, например. если краулер найдет вчерашнюю статью, мы можем захотеть сшить ее в кластер из сегодняшнего дня.
Для данной статьи извлекаются ее предыдущие, текущие и будущие сегменты, т. е. рассматривается 48-часовое окно (мы предполагаем, что ни один поток статей не будет занимать более двух полных дней). Нам нужно заглянуть в «будущее», так как возможно, что некоторые статьи приходят с задержкой, например. если краулер найдет вчерашнюю статью, мы можем захотеть сшить ее в кластер из сегодняшнего дня. 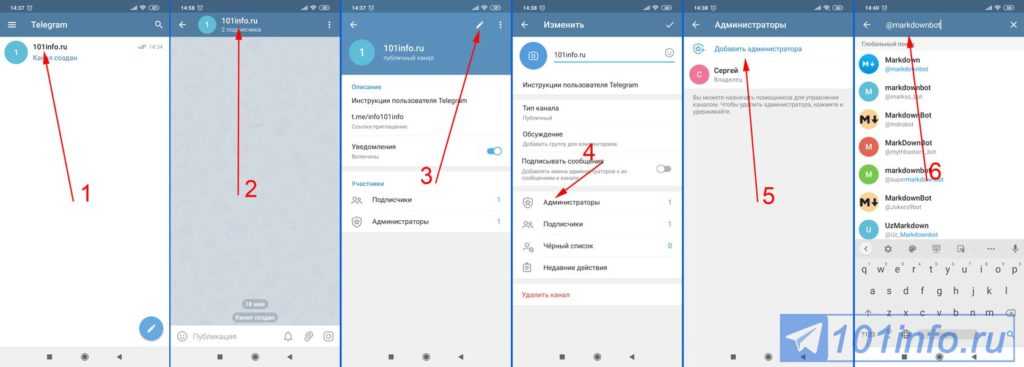 («встраивания») релевантных статей в основную матрицу «встраивания».
(«встраивания») релевантных статей в основную матрицу «встраивания».  Обратите внимание, что каждый период времени имеет свою собственную матрицу CSR, что значительно ускоряет скалярное произведение (поскольку мы можем игнорировать векторы для всех других нерелевантных периодов времени), а также гарантирует, что индекс может масштабироваться линейно со временем (если мы сильно упрощаем и предполагаем постоянное дневное число новостей).
Обратите внимание, что каждый период времени имеет свою собственную матрицу CSR, что значительно ускоряет скалярное произведение (поскольку мы можем игнорировать векторы для всех других нерелевантных периодов времени), а также гарантирует, что индекс может масштабироваться линейно со временем (если мы сильно упрощаем и предполагаем постоянное дневное число новостей).  К счастью, мы можем выполнять эффективное удаление на месте следующим образом:
К счастью, мы можем выполнять эффективное удаление на месте следующим образом: выполните следующую команду (следуя API, описанному здесь):
выполните следующую команду (следуя API, описанному здесь):  Надеюсь, вам было интересно это читать и вы узнали что-то новое. Если у вас есть какие-либо вопросы, свяжитесь со мной в LinkedIn. Я также настоятельно рекомендую прочитать несколько подробных обзоров замечательных решений, занявших 1-е и 3-е места в конкурсе.
Надеюсь, вам было интересно это читать и вы узнали что-то новое. Если у вас есть какие-либо вопросы, свяжитесь со мной в LinkedIn. Я также настоятельно рекомендую прочитать несколько подробных обзоров замечательных решений, занявших 1-е и 3-е места в конкурсе.
 Я полностью опустил их из-за требований к размеру двоичного файла 200 МБ.
Я полностью опустил их из-за требований к размеру двоичного файла 200 МБ. Не маркируя образцы статей, я, вероятно, столкнулся с перекосом в пользу обучения и всевозможными другими нежелательными предубеждениями. Команда с 1-го места пометила статьи с помощью оценщиков, что позволило им значительно превзойти другие отправленные материалы в задаче категоризации.
Не маркируя образцы статей, я, вероятно, столкнулся с перекосом в пользу обучения и всевозможными другими нежелательными предубеждениями. Команда с 1-го места пометила статьи с помощью оценщиков, что позволило им значительно превзойти другие отправленные материалы в задаче категоризации.