Содержание
Когда выбрать базу данных MongoDB: гайд для новичков
Подготовили небольшой гайд по СУБД MongoDB: вы узнаете, в чем ее особенности, плюсы и недостатки, для каких проектов она подходит, а когда лучше выбрать реляционную базу данных.
Что такое база данных MongoDB и в чем ее особенности
MongoDB — документоориентированная система управления базами данных с открытым исходным кодом. Для хранения данных используется JSON-подобный формат. Эта СУБД отличается высокой доступностью, масштабируемостью и безопасностью.
Главные особенности MongoDB:
- Это кроссплатформенная документоориентированная база данных NoSQL с открытым исходным кодом.
- Она не требует описания схемы таблиц, как в реляционных БД. Данные хранятся в виде коллекций и документов.
- Между коллекциями нет сложных соединений типа JOIN, как между таблицами реляционных БД. Обычно соединение производится при сохранении данных путем объединения документов.
- Данные хранятся в формате BSON (бинарные JSON-подобные документы).

- У коллекций не обязательно должна быть схожая структура. У одного документа может быть один набор полей, в то время как у другого документа — совершенно другой (как тип, так и количество полей).

В одном документе могут быть поля разных типов данных, данные не нужно приводить к одному типу. Основное преимущество MongoDB заключается в том, что она может хранить любые данные, но эти данные должны быть в формате JSON.
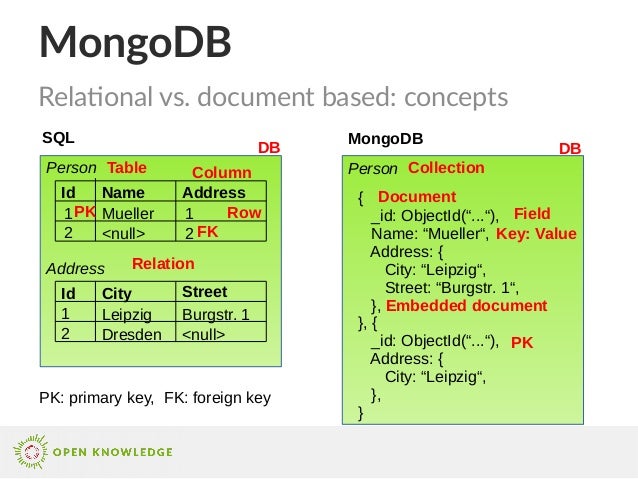
Пример документа в MongoDB
На схеме показано, как выглядит документ в MongoDB:
Источник
MongoDB добавляет поле _id с уникальным значением для идентификации документа в коллекции. Это поле обязательно для заполнения в каждом документе. Оно похоже на первичный ключ документа. Если вы создаете новый документ без поля _id, то MongoDB автоматически создаст его и добавит 24-значный уникальный идентификатор к каждому документу в коллекции.
Обратите внимание: сами данные заказа (OrderID, Product и Quantity) в MongoDB фактически хранятся как встроенный документ в самой коллекции, а в реляционных СУБД они обычно хранятся в отдельной таблице. Это одно из ключевых особенностей модели данных MongoDB.
Это одно из ключевых особенностей модели данных MongoDB.
Структура хранилища MongoDB
СУБД MongoDB полагается на концепции базы данных, коллекций и документов. Рассмотрим основные термины, а для лучшего понимания сравним их с терминами из языка структурированных запросов (SQL):
- База данных — это физический контейнер для коллекций.
- Коллекция — группа документов MongoDB. В терминологии SQL это соответствует таблице.
- Документ — запись в коллекции MongoDB, набор пар ключ-значение. В терминологии SQL это похоже на строку в таблице базы данных.
- Поле — ключ в документе. В терминологии SQL похоже на столбец в таблице.
- Встроенный документ — в терминологии SQL похоже на создание связей между несколькими таблицами, по которым разбросаны данные, что делается операциями JOIN.
Зачем использовать MongoDB: преимущества этой СУБД
Ниже приведены несколько причин, по которым стоит использовать MongoDB:
- Документоориентированная база — сохранение данных в формате документов вместо формата реляционного типа, это делает MongoDB очень гибкой и адаптируемой к бизнес-требованиям. Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру.
- Специальные запросы — MongoDB поддерживает поиск по полям, диапазонные запросы и поиск по регулярным выражениям. Могут быть сделаны запросы для возврата определенных полей в документах.
- Индексация — можно создать индексы для улучшения производительности поиска в MongoDB. Любое поле в документе может быть проиндексировано. Это обеспечивает высокую скорость работы СУБД.
- Репликация — эта СУБД может обеспечить высокую доступность с помощью наборов реплик. Набор реплик состоит из двух или более экземпляров MongoDB. Каждая реплика набора может выступать в роли первичной или вторичной. Первичная реплика — главный сервер, который взаимодействует с клиентом и выполняет все операции чтения/записи. Вторичные реплики сохраняют копию данных первичной реплики с помощью встроенной репликации. Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.
- Балансировка нагрузки — MongoDB использует концепцию шардинга для горизонтального масштабирования с помощью разделения данных между несколькими экземплярами БД. Она может работать на нескольких серверах, балансируя нагрузку и/или дублируя данные, чтобы поддерживать работоспособность системы в случае аппаратного сбоя.
- Возможность развернуть в облаке — вы получаете готовую к работе, оптимально сконфигурированную, масштабируемую и управляемую базу данных по запросу за две минуты.
- Доступность — MongoDB поддерживает все популярные языки программирования, ее можно использовать бесплатно как open source решение.
 Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру.
Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру. Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.
Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.В облаке VK Cloud (бывш. MCS) реализована техническая поддержка, хостинг и обновление СУБД MongoDB до актуальных версий. Доступна помощь экспертов VK в миграции данных и настройке баз данных.
Недостатки MongoDB
Вот основные минусы MongoDB:
- Эта база данных не настолько соответствует требованиям ACID (атомарность, согласованность, изолированность и устойчивость), как реляционные базы данных.
- Транзакции с использованием MongoDB являются сложными
- В MongoDB нет положений о хранимых процедурах или функциях, поэтому не получится реализовать какую-либо бизнес-логику на уровне базы данных, что можно сделать в реляционных БД.
Когда стоит и не стоит использовать MongoDB
MongoDB часто выбирают, когда нужна масштабируемая база данных, в настоящее время ее используют в качестве хранилища внутренних данных многие организации, такие как IBM, Twitter, Zendesk, Forbes, Facebook, Google и другие.
Примеры, когда MongoDB подходит для проекта:
- Каталог товаров в электронной коммерции.
- Блоги и системы управления контентом, особенно те, где много контента, в том числе видео и изображений.
- Аналитика в реальном времени и высокоскоростное журналирование, кэширование данных и кейсов, когда важна высокая масштабируемость системы.
- Хранение данных датчиков и устройств.
- Работа с большими данными для машинного обучения и исследований в ритейле и других отраслях.
- Ведение данных на основе местоположения, то есть геопространственных данных.
- Социальные сети, новостные форумы и другие похожие сценарии.
- Слабосвязанные данные без четкой схемы хранения.
- Стартапы и развертывание новых проектов, где структура данных пока неизвестна.

Примеры, когда MongoDB лучше не использовать:
- Транзакционные системы, приложения, требующие транзакций на уровне базы данных, например банковские приложения.
- Проекты, где модель данных определена заранее.
- Хранение сильносвязанных данных.
В этой статье мы познакомились с MongoDB, одной из самых популярных баз данных NoSQL. Для более глубокого погружения можно продолжить изучение MongoDB по документации.
Когда стоит и не стоит использовать MongoDB / Хабр
Разработчик и сотрудник проекта CouldBoost.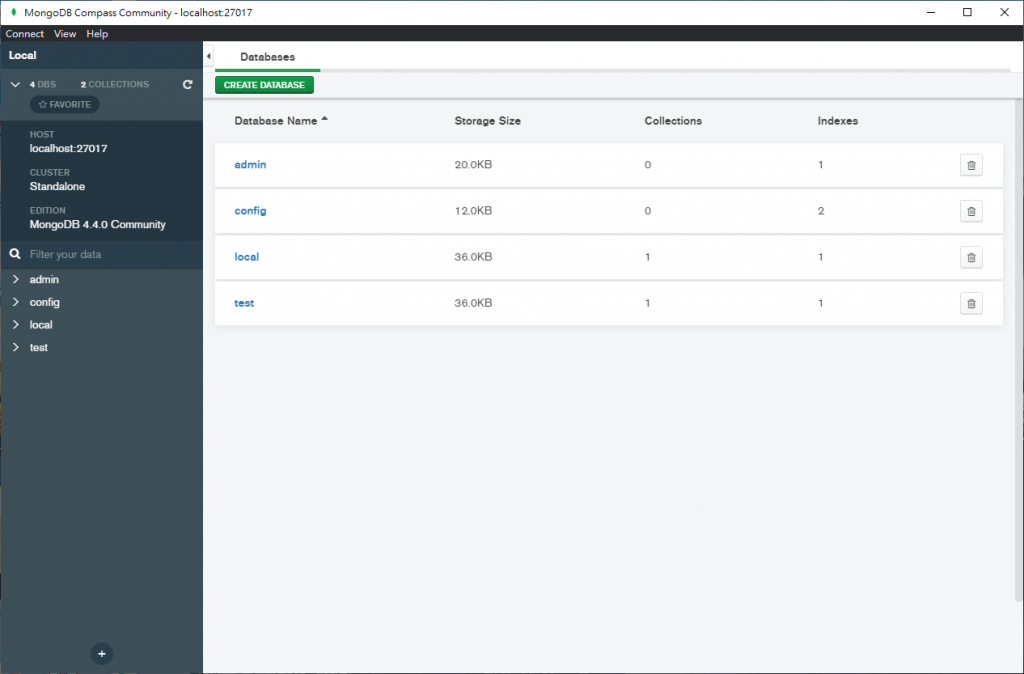 io Наваз Дандала (Nawaz Dhandala) написал материал о том, почему в некоторых случаях не стоит использовать MongoDB. Мы в «Латере» развиваем биллинг для операторов связи «Гидра» и уже много лет работаем с этой СУБД, поэтому решили представить и свое мнение по данному вопросу.
io Наваз Дандала (Nawaz Dhandala) написал материал о том, почему в некоторых случаях не стоит использовать MongoDB. Мы в «Латере» развиваем биллинг для операторов связи «Гидра» и уже много лет работаем с этой СУБД, поэтому решили представить и свое мнение по данному вопросу.
Дандала сразу оговаривается, что работал со многими СУБД (как SQL, так и NoSQL) и считает MongoDB отличным инструментом, однако существуют сценарии, в которых его применение нецелесообразно.
Документоориентированные СУБД такие, как MongoDB, прекрасно справляются с хранением JSON-данных, сгруппированных в «коллекции». В таком формате можно хранить любые JSON-документы и удобно категоризировать и по коллекциям. Содержащийся в MongoDB JSON-документ называется двоичным JSON или BSON и, как любой другой документ этого формата, является неструктурированным. Поэтому, в отличии от традиционных СУБД, в коллекциях можно сохранять любые виды данных, и эта гибкость сочетается с горизонтальной масштабируемостью базы данных. Эта возможность нравится многим разработчикам, однако «не все так однозначно».
Эта возможность нравится многим разработчикам, однако «не все так однозначно».
Если MongoDB такая классная, почему ее не используют все и всегда?
Выбор СУБД зависит в том числе и от того, что за приложение планируется создать. То есть базу данных выбирают не разработчики, а сам продукт, убежден Дандала. Он приводит пример, подтверждающий этот тезис.
При создании приложения, концепция которого подразумевает работу с документами, MongoDB будет хорошим выбором. К такому типу приложений можно отнести, к примеру, движок блог-платформы, где каждый автор сможет иметь по несколько блогов, и каждый из них будет содержать множество комментариев. База данных для обслуживания такого приложения должна быть легко расширяемой, и здесь MongoDB подойдет как нельзя лучше.
Однако, необходимо отметить, что у MongoDB нет связей между документами и “коллекциями” (частично это компенсируется Database Reference — ссылками в СУБД, но это не полностью решает проблему). В итоге, возникает ситуация, при которой имеется некий набор данных, который никак не связан с другой информацией в базе, и не существует никакого способа объединить данные из различных документов. В SQL-системах это было бы элементарной задачей.
В итоге, возникает ситуация, при которой имеется некий набор данных, который никак не связан с другой информацией в базе, и не существует никакого способа объединить данные из различных документов. В SQL-системах это было бы элементарной задачей.
Здесь возникает другой вопрос — если в MongoDB нет связей и возможностей по объединению двух таблиц, то зачем ее тогда вообще использовать? Ответ — потому что эта СУБД отлично масштабируется, и по сравнению с традиционными SQL-системами, гораздо быстрее осуществляет чтение и запись.MongoDB прекрасно подходит для приложений, в которых практически не используются данные с зависимостями и необходима масштабируемость базы данных.
Многие разработчики применяют MongoDB и для хранения связанных данных, реализуя объединения вручную в коде — этого достаточно в сценариях «одноуровневого» объединения или малого количества связей. То есть данный метод далеко не универсален.
Так какую СУБД выбрать?
Существует огромное количество различных СУБД, и каждая из них соответствует определённому набору требований, которые разработчики предъявляют к своему приложению:
- Документоориентированные СУБД (к примеру, MongoDB): Как уже сказано выше, документоориентированные СУБД используются для хранения JSON-документов в “коллекциях” и осуществления запросов по нужным полям. Можно использовать эту базу данных для создания приложений, в которых не будет содержаться слишком большого количества связей. Хорошим примером такого приложения является движок для блог-платформы или хранения каталога продуктов.
- Графовые СУБД (например Neo4j): Графовая СУБД используется для хранения между субъектами, где узлы являются субъектами, а грани — связями. Например, если разработчики создают социальную сеть, и один пользователь подписывается на другого, то пользователи являются узлами, а их “подписка” — связью. Такие СУБД прекрасно справляются с образованием связей, даже если глубина таких связей более ста уровней. Этот инструмент столь эффективен, что может даже позволяет выявлять мошенничество в сфере электронной коммерции.
- Кэш (например Redis): Такие СУБД используются, когда требуется крайне быстрый доступ к данным. Если создается приложение для интернет-торговли, в котором есть подгружаемые на каждой страницы категории, то вместо обращения к базе данных при каждом чтении, что крайне затратно, можно хранить данные в кэше. Он позволяет быстро осуществлять операции чтения/записи. Дандала советует применять СУБД, использующие кэш, в качестве оболочки для обработки часто запрашиваемых данных, избавляющей от необходимости совершения частых запросов к самой базе.
- Поисковые СУБД (например ElasticSearch): В случае необходимости осуществления полнотекстового поиска по базе данных (например поиск продукции в ecommerce-приложении), то хорошей идее будет использование поисковой СУБД вроде ElasticSearch. Эта система способна искать по огромному массиву данных и обладает обширной функциональностью — например, СУБД умеет осуществлять поиск по именованным категориям.
- Строковые СУБД (например Cassandra): СУБД Cassandra используется для хранения последовательных данных, логов, или огромного объема информации, который может генерироваться автоматически — к примеру, каким-нибудь датчиками. Если разработчики собираются использовать СУБД для записи больших массивов данных и при этом планируется, что будет намного меньше обращений для чтения и данные не будут иметь связи и объединения, тогда Cassandra будет хорошим выбором, уверен Дандала.
 Можно использовать эту базу данных для создания приложений, в которых не будет содержаться слишком большого количества связей. Хорошим примером такого приложения является движок для блог-платформы или хранения каталога продуктов.
Можно использовать эту базу данных для создания приложений, в которых не будет содержаться слишком большого количества связей. Хорошим примером такого приложения является движок для блог-платформы или хранения каталога продуктов.
 Он позволяет быстро осуществлять операции чтения/записи. Дандала советует применять СУБД, использующие кэш, в качестве оболочки для обработки часто запрашиваемых данных, избавляющей от необходимости совершения частых запросов к самой базе.
Он позволяет быстро осуществлять операции чтения/записи. Дандала советует применять СУБД, использующие кэш, в качестве оболочки для обработки часто запрашиваемых данных, избавляющей от необходимости совершения частых запросов к самой базе.
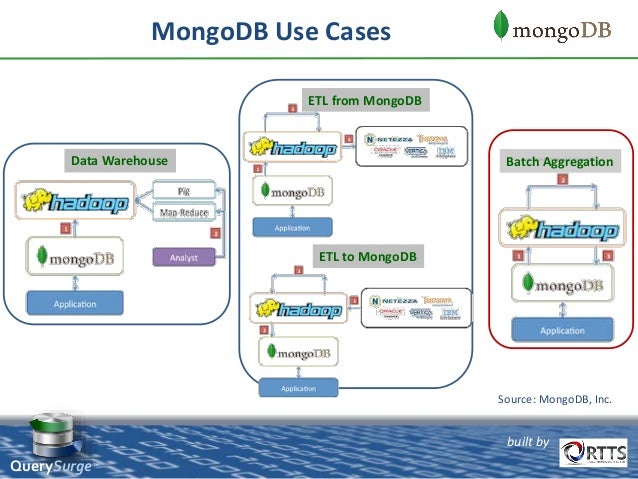
Использование комбинации баз данных
Существуют и ситуации, в которых может понадобиться использование сразу нескольких различных СУБД.
Например, если в приложении есть функция поиска, то его можно реализовать с помощью ElasticSearch, а уже для хранения данных без связей лучше подойдет MongoDB. Если речь иет о проекте в сфере «интернета вещей», где огромное количество всевозможных устройств и датчиков генерируют гигантские объёмы данных, вполне разумно будет использовать Cassandra.
Принцип, при котором используются несколько СУБД для работы в одном приложении, называется “Polyglot Persistence”. В этой статье можно почитать о плюсах и минусах такого подхода.
Наш опыт
Наша биллинговая система «Гидра» использует для учета первичных данных и хранения финансовой информации реляционную СУБД. Она идеально подходит для этих целей. Но некоторые модули Гидры, например, RADIUS-сервер, работают под высокой нагрузкой и могут получать тысячи запросов в секунду с жесткими ограничениями на время обработки запроса. Кроме того, в БД нашего автономного RADIUS-сервера данные хранятся в виде набора AVP (attribute/value pair). В таком сценарии реляционная СУБД уже не выглядит лучшим решением, и тут на помощь приходит MongoDB с ее хранилищем документов произвольной структуры, быстрой выдачей ответа и горизонтальной масштабируемостью.
Кроме того, в БД нашего автономного RADIUS-сервера данные хранятся в виде набора AVP (attribute/value pair). В таком сценарии реляционная СУБД уже не выглядит лучшим решением, и тут на помощь приходит MongoDB с ее хранилищем документов произвольной структуры, быстрой выдачей ответа и горизонтальной масштабируемостью.
При эксплуатации более чем на 100 инсталляциях Гидры на протяжении последних 5 лет серьезных проблем с Mongo мы не обнаружили. Но пара нюансов все же есть. Во-первых, после внезапного отключения сервера БД хоть и восстанавливается благодаря журналу, но происходит это медленно. К счастью, необходимость в этом возникает нечасто. Во-вторых, даже при небольшом размере БД редко используемые данные сбрасываются на диск и когда запрос к ним все же приходит, их извлечение занимает много времени. В результате нарушаются ограничения на время выполнения запроса.
Все это относится к движку MMAPv1, который применяется в Mongo по умолчанию. С другими (WiredTiger и InMemory) мы пока не экспериментировали — проблемы не настолько серьезны.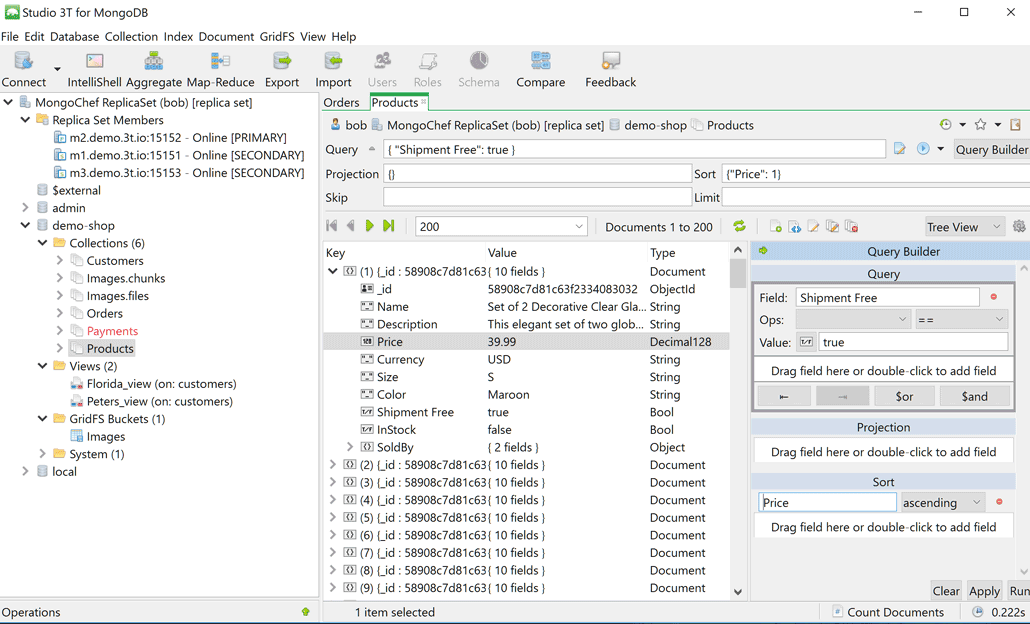
На этой странице популярная MongoDB
операции. Каждый пример содержит:
объяснение операции в примере, показывающем
цель и пример использования методаобъяснение того, как использовать операцию, включая параметры,
возвращаемые значения и распространенные исключения, с которыми вы можете столкнутьсяполная программа Node.js, которую можно скопировать и вставить для запуска примера
в вашей собственной среде
Как использовать примеры использования
В этих примерах используется
Пример данных MongoDB Atlas
база данных. Вы можете использовать эти образцы данных на уровне бесплатного пользования.
MongoDB Atlas, следуя руководству по началу работы с Atlas, или вы
может импортировать образец набора данных в локальный экземпляр MongoDB.
После того, как вы импортировали набор данных, вы можете скопировать и вставить использование
пример в выбранную вами среду разработки. Вы можете следить за
краткое руководство, чтобы узнать больше о получении
начал с Node. js, npm и драйвера Node.js. После того, как вы скопировали
js, npm и драйвера Node.js. После того, как вы скопировали
пример использования, вам нужно будет отредактировать одну строку, чтобы запустить пример
с вашим экземпляром MongoDB:
| // Замените следующую строку подключения вашего развертывания MongoDB. |
| const uri = |
| «mongodb+srv:// |
Во всех примерах используется импорт модуля ES. Вы можете включить импорт модуля ES добавив в файл package.json следующую пару ключ-значение:
| «type»: «module» |
CommonJS
Вы можете использовать любой пример использования с CommonJS require . Чтобы использовать CommonJS , требуется , вы
необходимо заменить оператор ES-модуля import на ваш CommonJS require
утверждение.
Нажмите на вкладку, чтобы увидеть синтаксис для импорта драйвера с модулем ES
import и CommonJS требуют :
Вы можете использовать Руководство по подключению Atlas, чтобы включить подключение к вашему экземпляру
Atlas и найдите строку подключения для замены переменной uri в файле
пример использования. Если ваш экземпляр использует аутентификацию SCRAM, вы можете заменить
Если ваш экземпляр использует аутентификацию SCRAM, вы можете заменить с вашим именем пользователя,
с вашим паролем и с IP
адрес или URL вашего экземпляра. Проконсультируйтесь с
Руководство по подключению для получения дополнительной информации
о подключении к вашему экземпляру MongoDB.
Доступные примеры использования
-
Операции поиска
-
Операции вставки
-
Операции обновления
-
03 Операции удаления
-
Количество документов
-
Получите различные значения поля
-
Запустите команду
-
СМОТРЕТЬ ФОРМЕНТЫ
-
Выполнить операции
← Операции. MongoDB: синтаксис, оболочка и запрос данных
MongoDB — это база данных документов, предназначенная для облегчения разработчикам работы с данными в любой форме и на любом языке программирования. Независимо от того, запускаете ли вы свой первый кластер MongoDB Atlas или являетесь давним пользователем-ветераном, мы собрали наш лучший набор полезных примеров, чтобы освежить ваши знания или помочь вам сориентироваться. Не стесняйтесь обращаться к официальной документации для более подробного обсуждения всех этих тем.
Независимо от того, запускаете ли вы свой первый кластер MongoDB Atlas или являетесь давним пользователем-ветераном, мы собрали наш лучший набор полезных примеров, чтобы освежить ваши знания или помочь вам сориентироваться. Не стесняйтесь обращаться к официальной документации для более подробного обсуждения всех этих тем.
Структурирование данных документа
Документы MongoDB отформатированы в BSON (расширенная двоичная форма JSON), что обеспечивает максимальную гибкость при структурировании данных всех типов. Ниже приведены лишь некоторые из способов структурирования документов.
Хранение вложенных структур данных
Возможно, наиболее мощной функцией баз данных документов является возможность вложения объектов внутрь документов. Хорошее эмпирическое правило для структурирования данных в MongoDB — предпочитать встраивание данных в документы, а не разбивать их на отдельные коллекции, если только у вас нет веской причины (например, необходимости хранить неограниченные списки элементов или необходимости искать объекты напрямую без извлечения).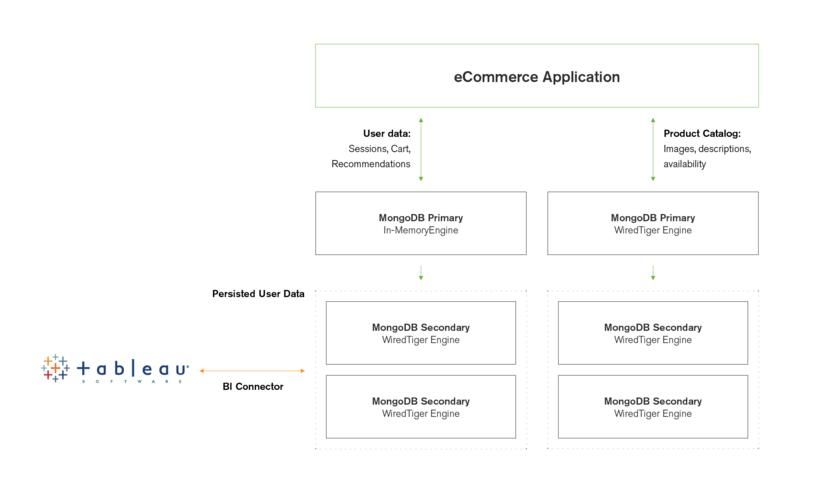 исходный документ).
исходный документ).
{_id: ObjectId("5effaa5662679b5af2c58829"),
электронная почта: «[email protected]»,
имя: {дано: «Джесси», семья: «Сяо»},
возраст: 31 год,
адреса: [{метка: «дом»,
улица: «улица Вязов, 101»,
город: «Спрингфилд»,
состояние: «КА»,
почтовый индекс: «»,
страна: «США»},
{метка: «мама»,
улица: «555 Main Street»,
город: «Джонстаун»,
провинция: «Онтарио»,
страна: «CA»}]
}
Обратите внимание, что поле имени представляет собой вложенный объект, содержащий компоненты имени и фамилии, а поле адресов хранит массив, содержащий несколько адресов. Каждый адрес может иметь разные поля, что упрощает хранение разных типов данных.
Использование оболочки MongoDB
Оболочка MongoDB — отличный инструмент для навигации, проверки и даже управления данными документа. Если вы используете MongoDB на своем локальном компьютере, запустить оболочку так же просто, как ввести mongo и нажать клавишу ввода, которая подключится к MongoDB на локальном хосте через стандартный порт (27017). Если вы подключаетесь к кластеру MongoDB Atlas или другому удаленному экземпляру, добавьте строку подключения после команды mongo.
Если вы подключаетесь к кластеру MongoDB Atlas или другому удаленному экземпляру, добавьте строку подключения после команды mongo.
Вот несколько быстрых примеров оболочки:
Список баз данных
> show dbs; админ 0.000GB конфиг 0.000GB местный 0.000GB моя_база данных 0,004 ГБ >
Список коллекций
> use my_database; > показать коллекции; пользователи сообщения >
Подсчет документов в коллекции
> use my_database; > db.users.count() 20234 >
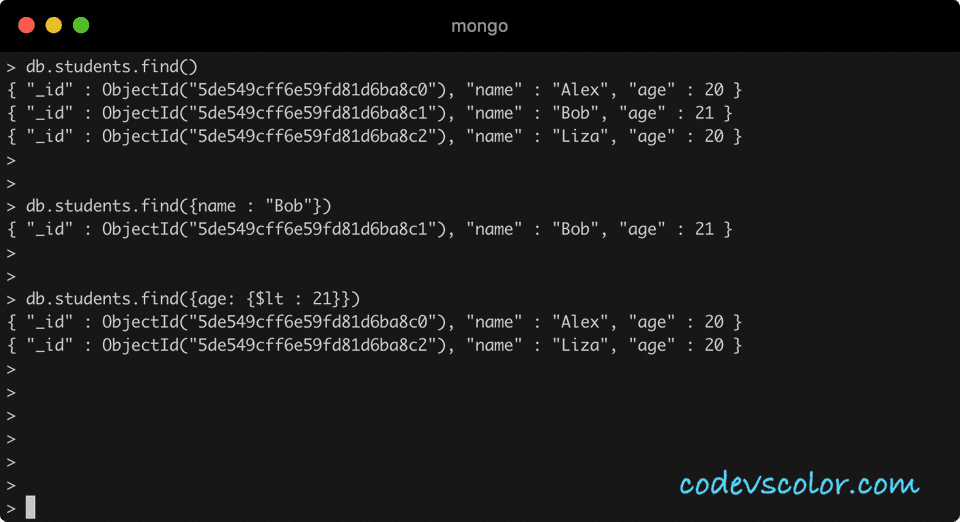
Найти первый документ в коллекции
> db.users.findOne()
{
"_id": ObjectId("5ce45d7606444f199acfba1e"),
"имя": {дано: "Алекс", семья: "Смит"},
"электронная почта": "[email protected]"
"возраст": 27
}
>
Найти документ по идентификатору
> db.users.findOne({_id: ObjectId("5ce45d7606444f199acfba1e")})
{
"_id": идентификатор объекта ("5ce45d7606444f199acfba1e"),
"имя": {дано: "Алекс", семья: "Смит"},
"электронная почта": "email@example. com",
"возраст": 27
}
>
 com",
"возраст": 27
}
>
com",
"возраст": 27
}
>
Запрос коллекций MongoDB
Язык запросов MongoDB (MQL) использует тот же синтаксис, что и документы, что делает его интуитивно понятным и простым в использовании даже для сложных запросов. Давайте рассмотрим несколько примеров запросов MongoDB.
Найти ограниченное количество результатов
> db.users.find().limit(10) … >
Поиск пользователей по фамилии
> db.users.find({"name.family": "Smith"}).count()
1
>
Обратите внимание, что мы заключаем «name.family» в кавычки, потому что в середине у него есть точка.
Запрос документов по числовым диапазонам
// Все сообщения, имеющие поле «Нравится» с числовым значением больше единицы:
> db.post.find({лайки: {$gt: 1}})
// Все посты с 0 лайками
> db.post.find({лайков: 0})
// Все посты, у которых НЕ ровно 1 лайк
> db.post.find({лайки: {$ne: 1}})
Сортировать результаты по полю
// упорядочить по возрасту, в порядке возрастания (сначала самые маленькие значения) > db.
 user.find().sort({возраст: 1})
{
"_id": идентификатор объекта ("5ce45d7606444f199acfba1e"),
"имя": {дано: "Алекс", семья: "Смит"},
"электронная почта": "
user.find().sort({возраст: 1})
{
"_id": идентификатор объекта ("5ce45d7606444f199acfba1e"),
"имя": {дано: "Алекс", семья: "Смит"},
"электронная почта": "Управление индексами
MongoDB позволяет создавать индексы даже для вложенных полей во вложенных документах, чтобы поддерживать высокую производительность запросов, даже когда коллекции становятся очень большими.
Создать индекс
> db.user.createIndex({"name.family": 1})
Создайте уникальный индекс
> db.user.createIndex({email: 1}, {unique: true})
Уникальные индексы позволяют гарантировать, что в коллекции есть не более одной записи с заданным значением для этого поля — очень полезно для таких вещей, как адреса электронной почты!
См. Индексы в коллекции
> db.user.getIndexes()
[
{
"в": 2,
"ключ" : {
"_id": 1
},
"имя": "_id_",
«ns» : «my_database.user»
},
{
"в": 2,
"ключ" : {
"имя.дано" : 1
},
"имя": "имя.данное_1",
«ns» : «my_database.user»
}
]
Обратите внимание, что по умолчанию коллекции всегда имеют индекс в поле _id для упрощения поиска документа по первичному ключу, поэтому любые дополнительные индексы будут перечислены после этого.
Удалить индекс
> db.user.dropIndex("name.given_1")
Заключение
Максимальная гибкость MongoDB означает, что это далеко не полный список всего, что вы можете с ней делать! Для получения дополнительной информации перейдите к документации MongoDB или пройдите курс обучения в университете MongoDB.