Содержание
Метатег robots и HTTP-заголовок X-Robots-Tag
Вы можете указать роботам правила загрузки и индексирования определенных страниц сайта одним из способов:
прописать метатег robots в HTML-коде страницы в элементе head;
настроить HTTP-заголовок X-Robots-Tag для определенного URL на сервере вашего сайта.
Примечание. Если страница запрещена в файле robots.txt, то директива метатега или заголовка не действует.
По умолчанию метатег и заголовок учитываются поисковыми роботами. Можно указать директивы для определенных роботов.
- Поддерживаемые Яндексом директивы
- Указание нескольких директив
- Указания для определенных роботов
| Директива | Описание | Метатег robots | Заголовок X-Robots-Tag |
|---|---|---|---|
| noindex | Не индексировать текст страницы. Страница не будет участвовать в результатах поиска. Страница не будет участвовать в результатах поиска. | ||
| nofollow | Не переходить по ссылкам на странице. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. | ||
| none | Соответствует директивам noindex, nofollow. | ||
| noarchive | Не показывать ссылку на сохраненную копию в результатах поиска. | ||
| noyaca | Не использовать сформированное автоматически описание. | — | |
| index | follow | archive | Отмена соответствующих запрещающих директив. | — | |
| all | Соответствует директивам index и follow — разрешено индексировать текст и ссылки на странице. | — |
Разрешающие директивы используются роботом по умолчанию, поэтому их можно не указывать, если нет других директив. В сочетании с запрещающими директивами разрешающие имеют приоритет. Пример.
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Пример:
Запись, которая запрещает индексирование страницы.
<html>
<head>
<meta name="robots" content="noindex" />
</head>
<body>...</body>
</html>HTTP-ответ, где заголовок запрещает индексирование страницы.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex
Вы можете указать директивы через запятую.
<meta name="yandex" content="noindex, nofollow" />
Вы можете передать несколько заголовков в одном ответе, а также перечислить директивы через запятую.
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
Если для робота Яндекса указаны противоречивые директивы, то он учтет положительное значение. Пример с директивами метатега:
<meta name="robots" content="all"/> <meta name="robots" content="noindex, follow"/> <!--Робот выберет значение all, текст и ссылки будут проиндексированы.--> <meta name="robots" content="all"/> <meta name="robots" content="noarchive"/> <!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки на сохраненную копию страницы.-->
 -->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->
-->
<meta name="robots" content="all"/>
<meta name="robots" content="noarchive"/>
<!--Текст и ссылки будут проиндексированы, но в результатах поиска не будет ссылки
на сохраненную копию страницы.-->Указать директиву только для роботов Яндекса можно с помощью метатега robots. Пример:
<meta name="yandex" content="noindex" />
Если вы перечислите общие директивы и директивы для роботов Яндекса, то поисковая система учтет все указания.
<meta name="robots" content="noindex" /> <meta name="yandex" content="nofollow" />
Такие директивы робот Яндекса воспримет как noindex, nofollow.
Если страницы долгое время не попадают в результаты поиска или были исключены, в форме приведите примеры таких страниц.
самая подробная справка от Q-SEO
В первую очередь давайте начнем с того, что существует несколько принципиально разных понятий: тег <noindex>, атрибут rel=”nofollow” и мета-тег <meta name=»robots» content=»noindex, nofollow» />. В этой статье мы подробно разберемся с их определениями и предназначениями.
В этой статье мы подробно разберемся с их определениями и предназначениями.
Что такое тег <noindex>
<noindex>…</noindex> – тег, который предложили использовать поисковые системы для запрета индексации заключенного в него контента. Данный тег не входит в официальную спецификацию гипертекстовой разметки веб-страниц формата html.
Важно: распознается он лишь поисковыми системами Яндекс и Рамблер. Google не относится к числу поисковых систем, понимающих данный html тег.
Что такое атрибут rel=”nofollow”
rel=”nofollow” – значение, запрещающее поисковым системам переходить по ссылке, в которой используется данный атрибут.
Ниже будут рассмотрены все примеры использования тега <noindex> и атрибута rel=”nofollow”.
Тег noindex и атрибут rel=“nofollow”
Тег <noindex> для ссылок
Данный тег можно использовать для закрытия ссылок от индексации. Вот так это будет выглядеть в коде страницы:
для ссылок
<noindex><a href=»http://site.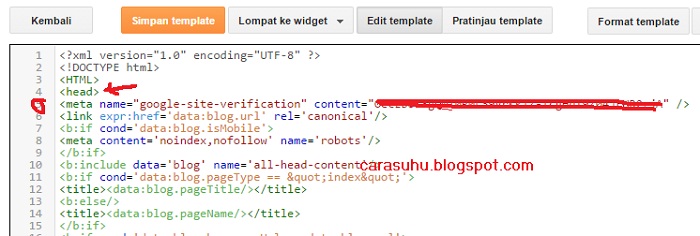 com/»>текст ссылки</a></noindex>
com/»>текст ссылки</a></noindex>
|
| <noindex><a href=»http://site.com/»>текст ссылки</a></noindex> |
Тег <noindex> для контента
Данный тег можно использовать и для закрытия контента от индексации. Существует два способа. В коде страницы это будет выглядеть так:
для контента — вариант 1
<noindex>Текст, запрещённый к индексированию</noindex>
|
| <noindex>Текст, запрещённый к индексированию</noindex> |
для контента — вариант 2
<!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
|
| <!—noindex—>Текст, запрещённый к индексированию<!—/noindex—> |
Но стоит помнить, что данный тег понимают только поисковые системы Яндекс и Рамблер. Его свойства не распространяются на Google. Поэтому, если на вашем сайте есть некачественный контент, закрыть его таким способом можно только от роботов Яндекса и Рамблера.
Его свойства не распространяются на Google. Поэтому, если на вашем сайте есть некачественный контент, закрыть его таким способом можно только от роботов Яндекса и Рамблера.
rel=”nofollow” для ссылок
Данный атрибут, чаще всего, используется оптимизаторами в том случае, если они хотят, чтобы поисковые системы не учитывали наличие исходящей ссылки, как фактор передачи веса, но ссылка всё равно будет изучена роботом. Вот как это выглядит в коде:
rel=”nofollow”
<a href=»http://site.com/» rel=»nofollow»>текст ссылки</a>
|
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Обычно, это уместно тогда, когда ссылки проставляются автоматически, например, в комментариях. Если вы не можете или не хотите поручиться за содержание страниц, на которые ведут ссылки с вашего сайта, следует вставлять в теги таких ссылок rel=»nofollow». Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
Такой атрибут понимают и Google-боты и Яндекс-боты, а в своих справках поисковые системы пишут следующее:
https://support.google.com/webmasters/answer/96569?hl=ru
https://yandex.ru/support/webmaster/controlling-robot/html.xml?lang=ru
Передает ли nofollow-ссылка вес
Если вы внимательно прочитали информацию по указанным выше ссылкам, теперь вы знаете, что вес по nofollow-ссылке не передается. Но из практики, мы можем смело сказать, что наличие таких ссылок в ссылочном профиле – очень полезный и достаточно естественный фактор в глазах поисковых систем. Но иметь много исходящих ссылок на своем сайте может быть негативным фактором, даже если они закрыты через данный атрибут.
Нужно ли использовать rel=”nofollow” для внутренних ссылок
Для того, чтобы сквозные ссылки, например на страницу регистрации или входа в личный кабинет не отнимали вес у других страниц, и не передавали его бесполезно, можно использовать rel=”nofollow”.
Как использовать совместно тег <noindex> и rel=”nofollow”
Вот пример кода, когда оптимизаторы используют тег <noindex> и атрибут rel=”nofollow” одновременно:
«совместно
<noindex><a href=»http://site. com/» rel=»nofollow»>текст ссылки</a></noindex>
com/» rel=»nofollow»>текст ссылки</a></noindex>
|
| <noindex><a href=»http://site.com/» rel=»nofollow»>текст ссылки</a></noindex> |
Но этот метод полноценно работает только для роботов Яндекса. Google понимает только лишь rel=»nofollow»>.
Мета-тег <meta name=»robots» content=»noindex, nofollow» />
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и выглядит это следующим образом:
Мета-тег
<head>
…
<meta name=»robots» content=»noindex, nofollow» />
…
</head>
|
| <head> … <meta name=»robots» content=»noindex, nofollow» /> … </head> |
Суть значений noindex и nofollow в мета-теге остается та же:
Noindex – запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.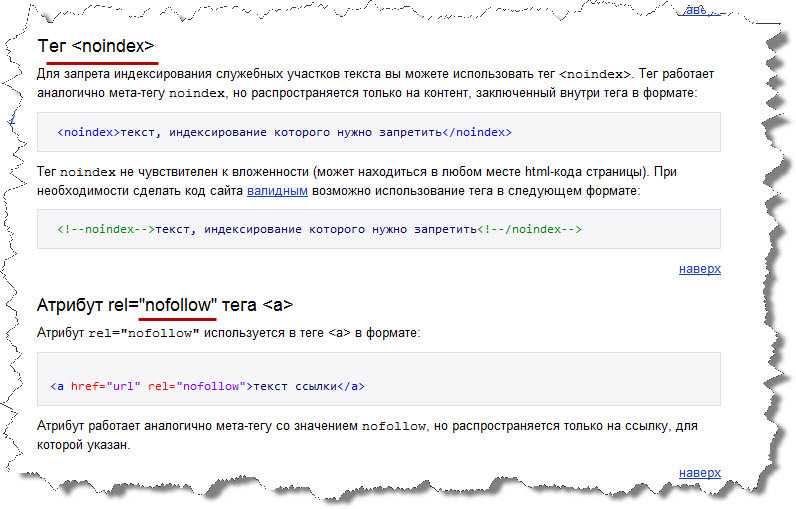
Nofollow – запрещает поисковым роботам переходить по ссылкам на уровне страницы (и по внешним, и по внутренним).
Комбинации <meta name=»robots» content=»х, y» />
Есть несколько случаев, когда используют данный мета-тег на практике. Под эти случаи есть разные решения:
- <meta name=»robots» content=»noindex, follow» /> нужно использовать в случае, если вы не хотите, чтобы страница была проиндексирована поисковыми системами, но роботы смогли бы перейти по ссылкам с этой страницы на другие. Например, это может быть вторая страница пагинации на сайте типа site.com/category/?page=2, на которой есть ссылки на следующие товары и вы не хотите, чтобы эта страница была проиндексирована поисковой системой.
- <meta name=»robots» content=»noindex» /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но просматривать ее и ходить по ссылкам роботы смогут.
- <meta name=»robots» content=»noindex, nofollow» /> – запрещает индексировать контент на соответствующей странице, а также запрещает роботам переходить по ссылкам.
- <meta name=»robots» content=»index, follow» /> – разрешает роботам индексировать страницу и ходить по ссылкам. Такой мета-тег не имеет смысла использовать, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия. Но если на вашем сайте он установлен и вы не собираетесь ограничивать работу робота, специально удалять его нет смысла.
- <meta name=»robots» content=»index, nofollow» /> — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.
- <meta name=»robots» content=»nofollow» /> — делает то же самое — разрешает индексировать страницу, но по ссылкам, которые в ней содержатся, робот переходить не будет.

Данный мета-тег можно использовать как для Google, так и для Яндекс отдельно
Если вам необходимо закрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />. Так говорит справка Google.
Так говорит справка Google.
Если закрыть от индексации только для Яндекса – <meta name=»yandex» content=»noindex»/>. Об этом также очень подробно написано в справке Яндекс.
Как сочетать meta name=»robots» с robots.txt и в чем принципиальная разница
Некоторые оптимизаторы не понимают разницу между мета-тегом <meta name=»robots» content=»noindex, nofollow» /> и закрытием соответствующей страницы в файле robots.txt. Оба способа запрещают поисковым роботам индексировать страницу сайта, но отличие все же есть:
Первый – разрешает роботам зайти на эту страницу, увидеть мета-тег и исключить ее из индекса или не индексировать.
Второй – запрещает зайти на страницу, и если вдруг она ранее уже была проиндексирована, она может долго находится в индексе поисковых систем, даже если вы ее закроете в файле robots.txt, без права на переиндексацию, впоследствии вы можете видеть ее в поиске так:
Поэтому для непроиндексированных страниц можно использовать любой из вариантов.
Если же страница уже была проиндексирована, рекомендуется установить в секцию <head> мета-тег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индекса и предотвратит последующее попадение в него.
Если ваш сайт создан на WordPress, правильно настроить данные мета-теги поможет бесплатный плагин Yoast SEO. Примерно вот так это выглядит:
Помочь проанализировать наличие всех этих элементов (и мета-тегов и тегов и атрибутов) в коде страниц сайта может расширение для браузера RDS-бар:
Правильно настроив его, вы сможете видеть контент, завернутый в тег <noindex> (будет подсвечиваться):
Ссылки с rel=»nofollow» (ссылка будет перечеркнутой, а в данном случае она еще и завернута в тег <noindex>):
И использование мета-тега <meta name=»robots» content=»x, y» />:
Теперь вы знаете как с помощью данных методов настроить правильную индексацию страниц. Это может оказать положительное влияние на процесс раскрутки веб-сайта.
Комментарии
Комментарии
Использование метатега robots | Блог Google Search Central
Прошло много времени с тех пор, как мы опубликовали эту запись в блоге. Часть информации может быть устаревшей (например, некоторые изображения могут отсутствовать, а некоторые ссылки уже не работают).
Вторник, 6 марта 2007 г.
Недавно Дэнни Салливан поднял хорошие вопросы о том, как
поисковые системы обрабатывают метатеги.
Вот несколько ответов о том, как мы обрабатываем эти теги в Google.
Несколько значений содержимого
Мы рекомендуем размещать все значения содержимого в одном метатеге. Это позволяет легко находить метатеги.
читать и снижает вероятность конфликтов. Например:
Если страница содержит несколько метатегов одного типа, мы объединим значения содержимого.
Например, мы будем интерпретировать
аналогично:
Если значения содержимого конфликтуют, мы будем использовать наиболее строгие. Итак, если на странице есть эти метатеги:
Итак, если на странице есть эти метатеги:
Мы будем подчиняться значению noindex .
Ненужные значения содержимого
По умолчанию робот Googlebot индексирует страницу и переходит по ссылкам на нее. Так что нет необходимости помечать страницы
со значениями содержимого индекс или следует за .
Направление метатега robots специально для робота Googlebot
Чтобы предоставить инструкции для всех поисковых систем, установите метаимя на роботов . К
предоставьте инструкции только для робота Googlebot, установите метаимя Googlebot . Если хочешь
Если хочешь
предоставлять разные инструкции для разных поисковых систем (например, если вы хотите
поисковая система индексирует страницу, но не другую), лучше всего использовать определенный метатег для каждого
поисковую систему, а не использовать общий метатег robots в сочетании с конкретным. Ты можешь найти
список ботов на robotstxt.org.
Корпус и проставка
Робот Google понимает любую комбинацию строчных и прописных букв. Таким образом, каждый из этих метатегов
интерпретируется точно так же:
Если у вас есть несколько значений содержимого, вы должны поставить запятую между ними, но не имеет значения, если
вы также включаете пробелы. Таким образом, следующие метатеги интерпретируются одинаково:
 txt file and robots meta tags»> Если вы используете и файл robots.txt, и метатеги robots
txt file and robots meta tags»> Если вы используете и файл robots.txt, и метатеги robots Если инструкции robots.txt и метатега для страницы конфликтуют, Googlebot следует наиболее
ограничительный. Более конкретно:
- Если вы заблокируете страницу с помощью файла robots.txt, робот Googlebot никогда не просканирует страницу и никогда не прочитает
метатеги на странице. - Если вы разрешите страницу с файлом robots.txt, но заблокируете ее от индексации с помощью метатега, робот Googlebot
получит доступ к странице, прочитает метатег и впоследствии не проиндексирует ее.
Действительные значения содержания метаданных robots
Googlebot интерпретирует следующие значения метатегов robots:
-
noindex: запрещает включение страницы в индекс. -
nofollow: запрещает роботу Googlebot переходить по любым ссылкам на странице. (Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки, который не позволяет роботу Googlebot
по отдельной ссылке.) -
без архива: запрещает кэшированную копию этой страницы быть доступной в поиске
полученные результаты. -
nosnippet: предотвращает появление описания под страницей в поиске
результатов, а также предотвращает кеширование страницы. -
noodp: блокирует
Описание проекта Open Directory
страница от использования в описании, которое появляется под страницей в результатах поиска. -
нет: эквивалентноnoindex, nofollow.
 (Обратите внимание, что это
(Обратите внимание, что этоСлово о значении содержания
нет
Как определено
robotstxt. org,
org,
следующее направление означает noindex, nofollow .
Однако некоторые веб-мастера используют этот тег, чтобы указать отсутствие ограничений для роботов и непреднамеренно заблокировать
все поисковые системы из их контента.
Обновление: Для получения дополнительной информации см.
Документация по метатегу robots.
Основы SEO: Объяснение мета-роботов «Noindex, Nofollow»
Сегодня мы поговорим об одной из самых больших ошибок SEO , которую может совершить владелец веб-сайта (или веб-разработчик): noindex . Одно упоминание об этом может вызвать у разработчика мурашки по спине.
Обновление от 29.08.2018. См. примечания к обновлению в конце сообщения.
Что такое тег
?
Проще говоря, этот метатег сообщает поисковым системам, какие действия они могут выполнять (или не выполнять) на определенной странице. Основные поисковые системы будут соблюдать команды, включенные в этот тег.
Основные поисковые системы будут соблюдать команды, включенные в этот тег.
Этот метатег может быть включен где угодно между тегами и в заголовке страницы, как показано ниже:
ВАЖНО: Этот тег не действует на весь сайт. Он может содержать разные значения на разных страницах одного и того же сайта.
Доступные значения для тега META ROBOTS
Ниже приведен список допустимых значений для тега META ROBOTS.
- Индекс ( значение по умолчанию )
- Noindex
- None
- Follow
- Nofollow
- Noarchive
- Nosnippet
- Noodp ( no longer relevant )
- Noydir ( no longer relevant )
These values can be combined, so for example the все приведенные ниже варианты являются абсолютно допустимыми метатегами robots:
Эффект NOINDEX,NOFOLLOW
Значение NOINDEX указывает поисковым системам НЕ индексировать эту страницу, поэтому эта страница не должна отображаться в результатах поиска .
Значение NOFOLLOW указывает поисковым системам НЕ отслеживать (обнаруживать) страницы, на которые есть ССЫЛКИ на этой странице.
Иногда разработчики добавляют метатег роботов NOINDEX,NOFOLLOW на веб-сайты разработки, чтобы поисковые системы случайно не начали отправлять трафик на веб-сайт, который все еще находится в стадии разработки.
Или у вас может быть текущий (действующий) веб-сайт на www.example.com, но вы также храните копию для разработки на www.dev.example.com/. В этом случае рекомендуется не индексировать, не следовать версии Dev, чтобы избежать многих потенциальных проблем.
Часто случается так, что люди случайно добавляют этот тег на работающие веб-сайты, забывают добавить его в разрабатываемые копии или, что еще хуже, забывают удалить его с действующих веб-сайтов после запуска.
Да, такие же результаты и проблемы могут возникнуть из-за плохой robots.txt в корне сайта, но это выходит за рамки темы этого поста.
~3% веб-сайтов отелей затронуты
индексирует свой сайт.
Это было шокирующее открытие, которое побудило нас написать эту статью.
Как проверить, содержит ли мой веб-сайт эту ошибку?
К счастью, есть очень простой способ проверить любой веб-сайт/страницу на наличие этой ошибки.
Просто откройте страницу в браузере, щелкните правой кнопкой мыши где-нибудь на странице (но не на ссылках или изображениях) и выберите «Просмотреть исходный код страницы». В большинстве браузеров для Windows вы можете просто нажать CTRL+U на клавиатуре.
При этом откроется новая вкладка с полным HTML-кодом (как его видит браузер) для текущей страницы. Как упоминалось ранее, метатеги обычно находятся в верхней части веб-сайта, как в этом примере:
Если вы видите на этой странице строку META ROBOTS со значением NOINDEX или NONE, то вам необходимо принять меры немедленно !
Как уязвимые веб-сайты выглядят в результатах поиска?
Я рад, что вы (надеюсь) спросили.
Есть очень удобный способ поиска в Google проиндексированных страниц с определенного доменного имени: [site:example.com] (без квадратных скобок).
Итак, мы идем в Google и ищем домен, который использует мета-роботов NOINDEX на их веб-сайте, и вот что мы получаем:
Я надеюсь, вы понимаете, какой ущерб может нанести полное удаление вашего веб-сайта из Google и других поисковых систем. Ваш органический поисковый трафик упадет до нуля в течение нескольких дней.
Как исправить/удалить строку Meta Robots?
К счастью, решить эту проблему несложно, и ее не следует откладывать. Сначала нужно определить, откуда идет эта линия.
В WordPress первое, что вы должны сделать, это перейти в Панель управления > Настройки > Чтение.
Убедитесь, что флажок для Видимость поисковой системы равен снят .
Если это не решило проблему, то вам следует проверить, не зашита ли эта строка в тему.
Чтобы проверить это, вы должны перейти в «Внешний вид»> «Редактор», а затем выбрать «Theme Header.php» из списка файлов справа (действительно для большинства тем).
Просмотрите этот файл и убедитесь, что в нем нет тега META ROBOTS с вредоносным значением. Если есть — удалите его и нажмите синюю кнопку «Обновить файл».
В заключение
Эта строка кода может вызвать головную боль, потерю дохода и негативные долгосрочные последствия для SEO.
Подвержен ли NOINDEX вашему веб-сайту? Проверьте сегодня!
Обновления от 29.08.2018:
Я хотел не торопиться и упомянуть новые цифры от 29 августа 2018 года.
Количество сайтов, которые я анализирую, резко увеличилось. В исходной статье упоминались данные, полученные с 50 000 веб-сайтов отелей. Сейчас я анализирую ~875 000 уникальных сайтов отелей (уникальные домены).
Результаты этих 875 000+ веб-сайтов отелей показывают, что 1,502% веб-сайтов отелей используют NOINDEX или NONE в качестве значения мета-роботов.