Содержание
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
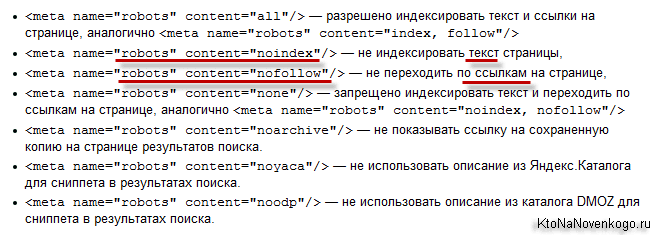
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц. - <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots. txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
 txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически.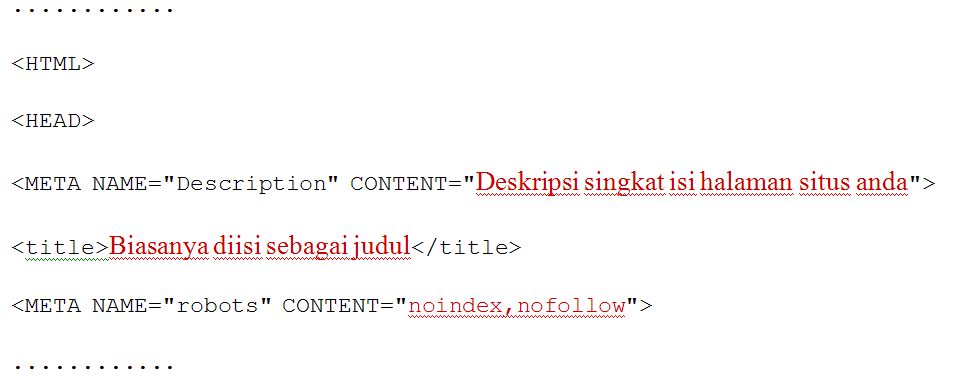 Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www. searchengines.ru/mett_katts_ne_nofollow_int_links.html )
searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Как закрыть страницу (сайт) от индексации с помощью meta-тега robots (noindex, follow) по GET-параметру в URL или по вхождению строки
В ряде случаев полезным, оказывается, закрыть ряд страниц сайта от индексации с помощью meta-тега robots, при этом оставив возможность роботу переходить по ссылкам со страницы. Делается это с помощью проверки наличия строки или запрашиваемого параметра в URL-адресе страницы.
Делается это с помощью проверки наличия строки или запрашиваемого параметра в URL-адресе страницы.
Проверка запроса GET-параметра
Используйте строчки указанные ниже для проверки запроса параметра SHOWALL_1 при формировании страницы и установке meta-тега noindex, follow. Вы можете заменить параметр SHOWALL_1 на любой другой удобный для вас, скажем, PAGEN_1, page и так далее.
<? if ($_REQUEST[‘SHOWALL_1’]) { ?>
<meta name=»robots» content=»noindex, follow»/>
<?} else {?>
<meta name=»robots» content=»index, follow»/>
<?}?>
Таким образом, мы установим значение meta-тега (noindex, follow) для страниц с параметром и значение (index, follow) для страниц без параметра.
Проверка вхождения строки в URL
Если требуется закрыть таким образом от индексации папку или какой-то тип страниц по строчке в URL-адресе, то производится проверка наличия этой строки в URL с помощью представленных ниже строк.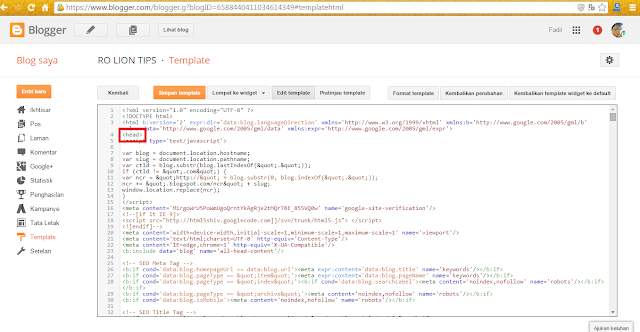
<? if (strstr($_SERVER[«REQUEST_URI»],»detail»)!=false) { ?>
<meta name=»robots» content=»noindex, follow»/ >
<?} else {? >
<meta name=»robots» content=»index, follow»/ >
<?}?>
Таким образом, мы установим значение meta-тега (noindex, follow) для страниц с наличием строки detail и значение (index, follow) для страниц без этой строки. Набор символов detail вы можете заменять по своему желанию на другие наборы, скажем, archive, old, print и так далее.
Или GET-параметр или строка
Полезным оказывается одном правилом закрыть от индексации и страницы с GET-параметром и страницы с наличием строчки в URL, делается это с применением оператора ИЛИ. Пример с запросом параметра PAGEN_2 ИЛИ вхождением строки print.
<? if ((strstr($_SERVER[«REQUEST_URI»],»print»)!=false)||$_REQUEST[‘PAGEN_2’]) { ?>
<meta name=»robots» content=»noindex, follow»/ >
<?} else {? >
<meta name=»robots» content=»index, follow»/ >
<?}?>
Внимание! Важно проверять, чтобы в других местах шаблона (1С-Битрикс или другой CMS) не было второго подключения meta-тега с противоречившими значениями. Иначе можно не добиться желаемого эффекта. При наличии двух и большего числа различных тегов, робот Яндекса выбирает самый разрешающий/положительный из них (индексировать и следовать по ссылкам), если такой вариант указан в meta-теге. Имеется возможность отдельно указывать правила именно для робота Яндекса или для робота Google, тогда используйте строчки.
Иначе можно не добиться желаемого эффекта. При наличии двух и большего числа различных тегов, робот Яндекса выбирает самый разрешающий/положительный из них (индексировать и следовать по ссылкам), если такой вариант указан в meta-теге. Имеется возможность отдельно указывать правила именно для робота Яндекса или для робота Google, тогда используйте строчки.
= Яндекс =
<? if ($_REQUEST[‘SHOWALL_2’]) { ?>
<meta name=»yandex» content=»noindex, follow»/>
<?} else {?>
<meta name=»yandex» content=»index, follow»/>
<?}?>
= Google =
<? if ($_REQUEST[‘SHOWALL_2’]) { ?>
<meta name=»googlebot» content=»noindex, follow»/>
<?} else {?>
<meta name=»googlebot» content=»index, follow»/>
<?}?>
Добавить в избранное
мета-роботов Тег | Как использовать тег Meta Robots для SEO
Использование тега Meta Robots для SEO
Вы можете использовать метатег robots, чтобы контролировать, где и как поисковые роботы Google и других поисковых систем перемещаются по вашему сайту и передают ссылочный вес со страницы на страницу .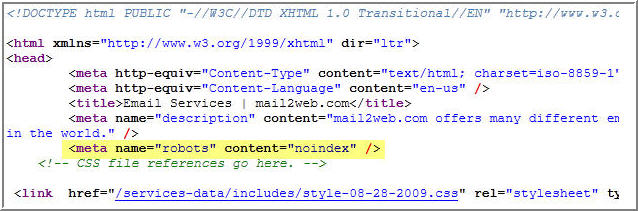 Если это звучит знакомо для другого текстового файла на вашем веб-сайте, следите за обновлениями…
Если это звучит знакомо для другого текстового файла на вашем веб-сайте, следите за обновлениями…
В этом руководстве мы рассмотрим
- Что такое метатег robots и почему он важен
- Как вы используете метатег robots тег для SEO
- Преимущества использования метатега robots
Что такое метатег robots и имеет ли он значение?
Метатег robots — это HTML-тег, который размещается в теге заголовка страницы и содержит инструкции для ботов. Как и файл robots.txt, он сообщает поисковым роботам, разрешено ли им индексировать страницу.
Чтобы найти мета-тег robots на странице, просто щелкните правой кнопкой мыши на веб-странице, выберите «Просмотр источника», а затем выполните поиск для «роботов». Это будет выглядеть примерно так:
< meta name="slurp" content="noindex" />
которые применяются к конкретным пользовательским агентам. В этом конкретном примере метатег robots говорит поисковым системам не индексировать страницу. Однако боты могут свободно переходить по ссылкам, которые они находят на странице.
В этом конкретном примере метатег robots говорит поисковым системам не индексировать страницу. Однако боты могут свободно переходить по ссылкам, которые они находят на странице.
Метатег robots имеет значение, поскольку он добавляет дополнительный уровень защиты к файлу robots.txt. Когда сканер переходит по внешней ссылке и попадает на одну из ваших страниц, он все еще может сканировать и индексировать эту страницу, потому что он не видел файл robots.txt.
Метатег robots предотвращает сканирование и индексирование.
Чем мета-роботы отличаются от robots.txt?
Применяется метатег robots только на страницу, содержащую тег. Файлы robots.txt применяются ко всему вашему веб-сайту.
Как работает метатег robots?
Как видите, тег состоит из двух частей: name=»» и content=»».
Прочтите руководство по сканерам поисковых систем и сканированию, чтобы узнать больше о том, как они работают.
Часть имени указывает агент пользователя бота, которого вы инструктируете, точно так же, как строка агента пользователя в файле robots.txt. В отличие от robots.txt, вы не используете подстановочный знак для включения всех ботов. Для этого просто напишите «роботы».
Отсюда и название метатега robots.
Во второй части, content=»» вы указываете ботам, что делать.
Какие существуют значения метатегов robots?
В поле содержимого тега robots можно добавить множество различных значений. Каждое из этих значений делает что-то свое:
- Индекс: Указывает поисковым системам проиндексировать страницу. На первый взгляд это может показаться бессмысленным, так как по умолчанию используется «Индекс», но это может быть полезно, если вы хотите, чтобы только определенная группа поисковых систем индексировала страницу.
- NoIndex: Указывает поисковым системам не индексировать страницу, чтобы она не отображалась в результатах поиска.
- NoImageIndex: Указывает поисковым системам не индексировать изображения на странице. Однако, если кто-то добавит это изображение где-нибудь еще в Интернете, Google все равно проиндексирует его и покажет в результатах поиска изображений.
- Нет: Это работает как ярлык для «noindex, nofollow». Он говорит поисковым системам игнорировать страницу и делать вид, что никогда ее не видел.
- Follow: Указывает поисковым системам переходить по ссылкам, которые они находят на странице. Как и в случае с «Индексом», это статус по умолчанию, когда бот не находит применимый к нему метатег robots.
- NoFollow: Сообщает поисковым системам вообще не переходить ни по каким ссылкам на странице. Вы также можете добавить это значение к отдельной ссылке.
- NoArchive: Указывает поисковым системам не показывать кэшированные копии страницы.
- NoCache: То же, что и «NoArchive», за исключением использования MSN/Live.
- NoSnippet: Запрещает поисковым системам показывать фрагмент этой страницы в результатах поиска. Это также предотвращает их кеширование страницы.
- NoTranslate: Указывает поисковым системам не предлагать переведенные версии страницы в результатах поиска.
- Unavailable_after: Указывает поисковым системам не отображать страницу в результатах поиска после определенной даты.
- NoYDir: Указывает поисковой системе не использовать Yahoo! Описание страницы каталога в поисковом сниппете.
- NoODP: Запрещает поисковым системам использовать описание страницы из DMOZ в фрагменте поиска. ODP — это сообщество, которое управляет и поддерживает каталог DMOZ.

Последние два значения «NoYDir и NoODP» в настоящее время не используются. Ни Yahoo! Каталог или DMOZ больше не существуют. Тем не менее, вы все еще можете видеть их в Интернете.
Немного усложняет ситуацию тот факт, что не все поисковые системы поддерживают все значения.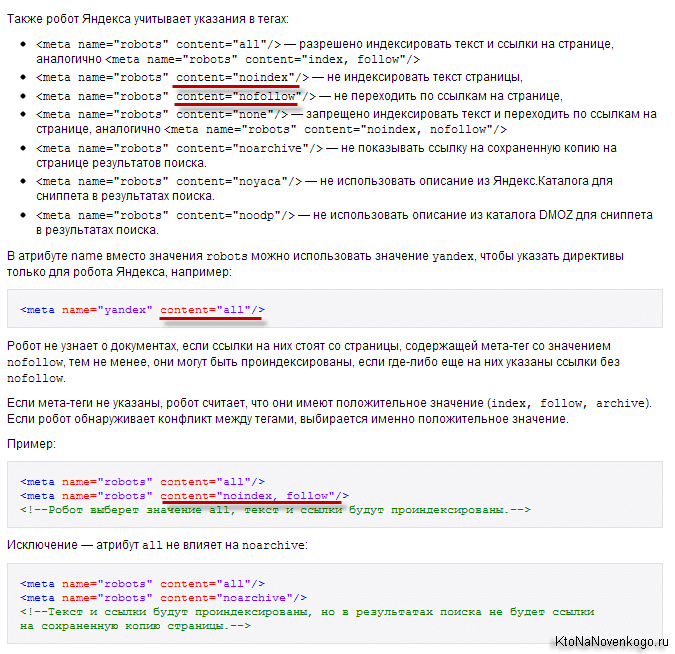 Итак, вот удобная таблица, которая разбивает это на части:
Итак, вот удобная таблица, которая разбивает это на части:
Какие поисковые системы распознают какие значения? Value Google noimageindex Да Нет Нет follow Да Нет noodp Нет Нет Нет noydir Нет Нет Нет
Используя запятые, вы можете создавать многодирективные метатеги вместо создания одного тега для каждой директивы. На самом деле, вы будете видеть это довольно часто, так как многие метатеги роботов используют значения «noindex, nofollow»:
Как использовать роботов Метатеги для SEO?
Обеспечение того, чтобы определенные малоценные страницы не попадали в индекс Google и результаты поиска, является такой же частью SEO, как и попадание страниц в результаты поиска. Не индексирование малоценных страниц может увеличить так называемую «сканирующую потребность» вашего сайта, что может способствовать более частому сканированию вашего сайта.
Не индексирование малоценных страниц может увеличить так называемую «сканирующую потребность» вашего сайта, что может способствовать более частому сканированию вашего сайта.
Meta robots также добавляет дополнительный уровень защиты для страниц, которые вы заблокировали с помощью файла robots.txt. Эти страницы все еще могут быть проиндексированы, если Google попадет на них по внешней обратной ссылке. Отсутствие индексации страницы предотвратит это.
Использование метатега robots для предотвращения индексации страницы и перехода по ссылкам выглядит следующим образом:
два наиболее часто используемых значения, используемые в метатеге robots. Однако другие значения, перечисленные выше, также имеют ценность для SEO:
- NoImageIndex: Указывает поисковым системам не сканировать изображения на странице.
- Нет: Это эквивалентно использованию «noindex, nofollow», объединенных в одно значение. Поисковые роботы не будут индексировать страницу или переходить по каким-либо ссылкам.
- NoArchive: Запретить поисковым системам показывать кешированную версию вашей страницы. Убедитесь, что люди всегда видят последнюю версию вашего контента. MSN/Live использует «NoCache» вместо «NoArchive».
- NoSnippet: Это останавливает поисковые системы от отображения фрагмента вашего сайта в результатах поиска и от показа кэшированной версии страницы.
 Поисковые роботы не будут индексировать страницу или переходить по каким-либо ссылкам.
Поисковые роботы не будут индексировать страницу или переходить по каким-либо ссылкам.Если весь смысл SEO заключается в попадании страниц в результаты поиска, то как мета-роботы страницы помогают SEO?
- Предотвращает индексирование и отображение личных файлов или папок в результатах поиска. Обычно рекомендуется вообще не публиковать этот контент на вашем сайте или защищать его паролем. Однако, если по какой-то причине вам нужно разместить его на своем сайте, метатег robots не позволит ему попасть в Google.
- Помогает поисковым системам более эффективно сканировать ваш сайт. Поисковые роботы имеют ограниченный краулинговый бюджет, поэтому теоретически они могут тратить все свое время на сканирование страниц, рейтинг которых вас не волнует, игнорируя самые важные из них. Блокировка индексации этих неважных файлов поможет поисковым роботам перейти на более ценные страницы.
- Если у вас есть страница, набравшая много ссылок, но вы не хотите, чтобы она индексировалась, используйте директиву follow, чтобы передать эту массу ссылок на другие страницы вашего сайта.
 Поисковые роботы имеют ограниченный краулинговый бюджет, поэтому теоретически они могут тратить все свое время на сканирование страниц, рейтинг которых вас не волнует, игнорируя самые важные из них. Блокировка индексации этих неважных файлов поможет поисковым роботам перейти на более ценные страницы.
Поисковые роботы имеют ограниченный краулинговый бюджет, поэтому теоретически они могут тратить все свое время на сканирование страниц, рейтинг которых вас не волнует, игнорируя самые важные из них. Блокировка индексации этих неважных файлов поможет поисковым роботам перейти на более ценные страницы.Хотя никогда не рекомендуется публиковать конфиденциальную информацию на вашем веб-сайте, иногда это происходит. Блокировка этих URL-адресов через robots.txt говорит всем, кто читает его, что им следует взглянуть на эти страницы. Добавление «noindex» к метатегу robots не позволит этой странице появляться в результатах поиска, не отображая ее там, где кто-то может ее найти.
Самая важная часть использования метатега robots — убедиться, что вы используете его правильно. Нередки случаи, когда весь сайт деиндексируется из-за того, что кто-то случайно добавил тег robots noindex ко всему сайту. Поэтому понимание того, как работает метатег robots, абсолютно необходимо для SEO.
Поэтому понимание того, как работает метатег robots, абсолютно необходимо для SEO.
Мета-теги Noindex: Как неиндексировать страницу
В ЭТОЙ СТАТЬЕ:
Это может показаться нелогичным, но не каждая страница вашего сайта должна отображаться в результатах поиска. Поисковая оптимизация (SEO) направлена на повышение видимости в поиске и органического трафика, и иногда вы можете лучше всего достичь этой цели, ограничивая контент, который может отображаться в результатах поиска.
Если вы ломаете голову или разоблачаете мой блеф, читайте дальше, чтобы узнать о преимуществах отсутствия индексации страницы или подкаталога и о том, как реализовать теги noindex.
Что означает Noindex?
Термин «noindex» — это специальная директива в метатеге robots, которая указывает поисковым роботам исключить страницу из страниц результатов поисковой системы (SERP). Это означает, что искатели не смогут получить доступ к странице через поиск.
Важная часть любой технической стратегии SEO, метатеги robots позволяют вам исключать страницы, которые не представляют ценности для пользователей или содержат информацию, которую вы не хотите отображать в результатах поиска, например:
- Страницы подтверждения и благодарности
- Страницы входа
- Политика конфиденциальности или страница условий обслуживания
- Закрытый контент
- Сообщения об ошибках
Метатег Robots, Robots.
 txt и X-Robots Tag
txt и X-Robots Tag
Метатег Robots часто путают с файлом robots.txt и тегом x-robots. Все три дают инструкции поисковым роботам на страницах и являются частью протокола исключения роботов (REP). Проще говоря: они сообщают Google, что вводить в поиск Google, а что не включать в него, а также какие страницы следует сканировать. Однако они не могут и не должны использоваться взаимозаменяемо.
Метатег Robots
Метатег robots добавляется в раздел
определенной веб-страницы и передает инструкции только для этой конкретной страницы. Метатег robots, который часто называют тегом noindex или метатегом noindex, может сделать больше, чем просто указать поисковому роботу не индексировать страницу.Его также можно использовать, чтобы попросить сканеров не переходить по ссылкам, перевести страницу, заблокировать определенного поискового бота или предотвратить появление кэшированной ссылки в поисковой выдаче.
Общие директивы метатегов роботов включают:
- Noindex, nofollow —
Googlebot и другие поисковые роботы могут получить доступ к странице, но они не должны индексировать ее или переходить по ссылкам. - Noindex, follow —
Googlebot и другие поисковые роботы могут получать доступ к странице и переходить по ссылкам на ней, но они не должны индексировать саму страницу. Вам не нужно включать «follow» в метатег, так как это значение по умолчанию.

Robots.txt
Robots.txt — это файл, который позволяет владельцам сайтов сообщать поисковым системам, какие части их сайта не должны сканироваться. Это похоже на личную табличку «Не беспокоить» для вашего веб-сайта, которая висит в корневом каталоге вашего домена или поддомена.
Файл robots.txt лучше всего подходит для блокировки доступа и сканирования целых подкаталогов, а не отдельных страниц. Используйте его, чтобы заблокировать поисковым сканерам доступ и индексацию:
- Внутренние поисковые страницы
- Параметры URL
- Форумы, на которых спам, созданный пользователями, может вызвать проблемы
- Внутренние подкаталоги, например, предназначенные только для сотрудников
Выполните следующие действия, чтобы создать файл robots. txt и обязательно укажите ссылку на карту сайта в формате XML. .
txt и обязательно укажите ссылку на карту сайта в формате XML. .
Если вы ссылаетесь на страницу, включенную в файл robots.txt, вы также можете добавить к ней метатег robots, чтобы она не отображалась в результатах поиска. Помните: robots.txt блокирует доступ поисковых роботов к странице, но не ее индексацию. Если страницы, на которые распространяются ваши директивы robots.txt, получают внешние ссылки, поисковые системы могут их проиндексировать. Чтобы избежать этого, используйте метатег robots вместе с файлом robots.txt.
Тег X-Robots
Чтобы заблокировать PDF, видео или изображение от появления в поисковой выдаче, используйте тег x-robots. Те же самые директивы, указанные для метатегов robots, используются для x-robots. Однако, в отличие от метатега robots, который находится в заголовке HTML страницы, тег x-robots размещается в ответе заголовка HTTP.
Директива выглядит следующим образом:
X-Robots-Tag: noindex
Когда не индексировать страницу
Обуздать раздувание индекса
Раздувание индекса происходит, когда Google индексирует страницы, практически не представляющие ценности для поисковиков. Эти посторонние страницы отвлекают ресурсы от более ценных страниц. Используйте метатег robots, чтобы управлять тем, какие страницы будут отображаться в результатах поиска.
Эти посторонние страницы отвлекают ресурсы от более ценных страниц. Используйте метатег robots, чтобы управлять тем, какие страницы будут отображаться в результатах поиска.
Искоренение каннибализации ключевых слов
Каннибализация ключевых слов происходит, когда две страницы имеют схожее ключевое слово и цель поиска, что заставляет их конкурировать друг с другом в поисковой выдаче.
Если у вас есть две страницы, поглощающие друг друга, и вы хотите сохранить обе без изменения их содержимого, не индексируйте одну. Тем не менее, вы должны делать это только в том случае, если страница, которую вы не индексируете, не привлекает трафик по ключевым словам, которых нет на другой странице. В такой ситуации вам может потребоваться переработать контент на одной или обеих страницах, чтобы решить проблему каннибализации.
Защита закрытых целевых страниц
Когда вы предлагаете ценный ресурс клиентам в обмен на контактную информацию, убедитесь, что он недоступен каким-либо другим способом.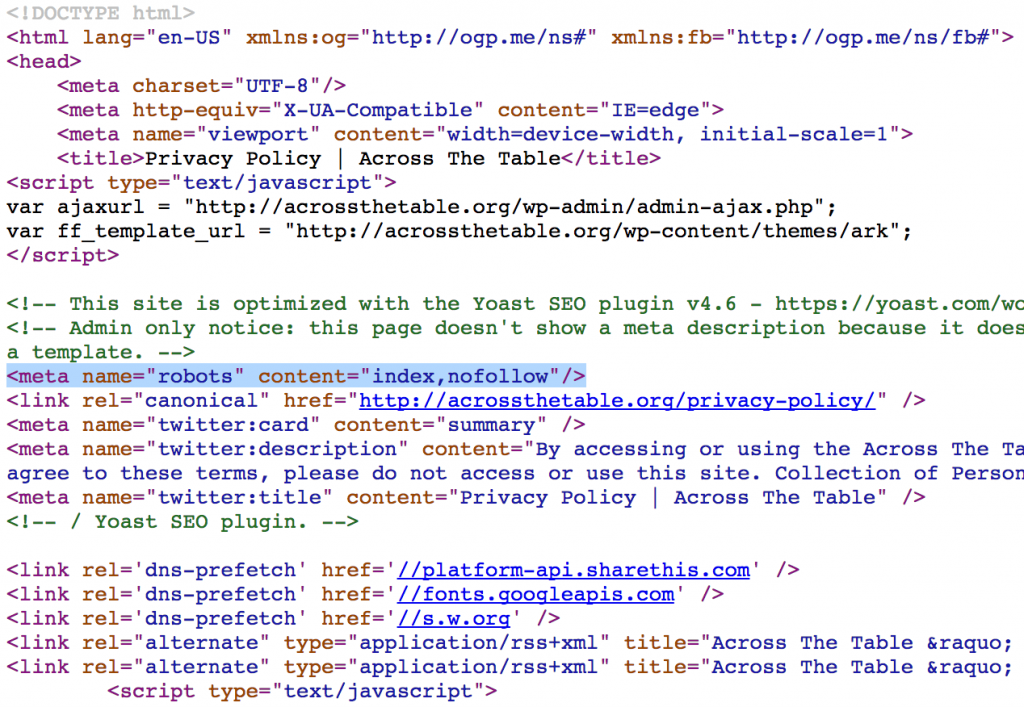 Добавьте метатег robots, чтобы не индексировать страницу, чтобы она не отображалась в поисковой выдаче.
Добавьте метатег robots, чтобы не индексировать страницу, чтобы она не отображалась в поисковой выдаче.
Исключение непопулярных продуктов из поиска
Сайты электронной торговли часто предлагают товары для обслуживания определенных клиентов, даже если спрос на них не слишком велик. Например, у продавца автозапчастей или у другой технической компании могут быть товары для конкретных моделей или редкого оборудования. Если эти страницы продуктов или категорий не привлекают органического трафика, их можно вообще не индексировать.
Как не индексировать страницу
Используя тег noindex в разделе заголовка HTML или заголовках ответов, вы можете запретить поисковым системам включать страницу в результаты поиска. Убедитесь, что страница не заблокирована или запрещена в вашем файле robots.txt, а поисковые системы могут получить к ней доступ.
Метатег noindex размещается в заголовке HTML-кода страницы. Код не чувствителен к регистру и выглядит так:
«Роботы» означает, что директива применяется к любому поисковому роботу, но вы можете выделить поисковые роботы, заменив «роботы» известными именами поисковых роботов, такими как «Googlebot» или «bingbot».
Поисковые роботы по-прежнему будут переходить по ссылкам на странице, если вы также не добавите команду nofollow. Вы можете сделать это, чтобы предотвратить прохождение ссылочного капитала через страницу или предотвратить переход сканера по ссылке на закрытый контент.
Чтобы добавить значение nofollow, отделите его от директивы noindex запятой.
Примечание: Прежде чем запретить индексирование страницы, проверьте наличие входящего органического трафика в Google Search Console. Если это так, определите, как ваш сайт может продолжать захватывать этот трафик, прежде чем не индексировать страницу.
Как добавить метатег Robots в HTML-код
- Откройте исходный код страницы, которую вы хотите запретить индексировать.
- Найдите заголовок вверху страницы. Он начинается с и заканчивается на. Вероятно, в заголовке будет и другой код.
- Добавьте метатег robots в новую строку так, чтобы он отображался между тегами и.

Вот и все! Если ваша страница уже проиндексирована, вы можете попросить Google повторно просканировать ее, вставив ее URL-адрес в инструмент проверки URL-адресов.
Уже проиндексировано? Используйте инструмент для удаления URL
Когда вы добавляете тег noindex на новую страницу контента, робот Googlebot увидит директиву при сканировании страницы и не будет ее индексировать.
Однако, если вы добавляете тег на страницу, которая уже проиндексировано , страница будет отображаться в результатах поиска до тех пор, пока она не будет просканирована повторно и боты не увидят новые инструкции noindex. Вы можете попросить Google повторно просканировать URL-адрес в Google Search Console с помощью инструмента проверки URL-адресов, но он не удалит страницу из поисковой выдачи мгновенно.
Если вам нужно немедленно удалить страницу из поисковой выдачи, используйте инструмент удаления в Google Search Console. Это предотвратит появление страниц в результатах поиска Google примерно на шесть месяцев. К тому времени метатег noindex должен работать.
Это предотвратит появление страниц в результатах поиска Google примерно на шесть месяцев. К тому времени метатег noindex должен работать.
Как не индексировать страницу в WordPress
Каждая страница в WordPress индексируется по умолчанию. Вы можете использовать плагин Yoast SEO, чтобы не индексировать страницу в WordPress без написания кода. Вот как.
Перейдите на вкладку «Дополнительно» в мета-поле Yoast SEO.
Под вопросом «Разрешить поисковым системам показывать это сообщение в результатах поиска?» выберите «Нет» в раскрывающемся списке.
Хотя этот параметр предписывает Google не индексировать сообщение, боты по-прежнему будут автоматически переходить по ссылкам на странице для сканирования других страниц.
Если вы хотите добавить директиву nofollow, нажмите кнопку «Нет» под вопросом: «Должны ли поисковые системы переходить по ссылкам в этом сообщении?»
Вы можете ожидать, что Google, Bing и другие законные поисковые системы будут соблюдать метатег robots.
Могу ли я ссылаться на непроиндексированные страницы?
Да. Тег noindex сообщает поисковым роботам, как обрабатывать страницу при сканировании и индексировании. Это не влияет на вашу способность ссылаться на страницу. Это может быть полезно для страниц категорий в блоге, которые не должны отображаться в результатах поиска, но могут предоставить ботам ссылки на ценные страницы, которые должны.
Когда следует использовать метатег robots?
Если у вас есть страница, которая не представляет никакой ценности для пользователей, например страница благодарности или страница для печати, не индексируйте ее метатегом robots, чтобы она не отображалась в поисковой выдаче.
Когда не следует использовать директиву noindex?
Технически вы можете решить проблемы с дублированием контента и некоторые проблемы с краулинговым бюджетом с помощью директив noindex, но это не лучший способ. Дублированный контент лучше всего обрабатывается с помощью канонических тегов, которые концентрируют ссылочный вес дубликатов на каноническую страницу. Если вы пытаетесь сэкономить бюджет сканирования, вам следует использовать файл robots.txt, чтобы запретить сканирование этого раздела сайта.
Если вы пытаетесь сэкономить бюджет сканирования, вам следует использовать файл robots.txt, чтобы запретить сканирование этого раздела сайта.
Пропускают ли неиндексированные страницы ссылочный вес?
Да. Несмотря на то, что страница не проиндексирована, она все равно может делиться любым авторитетом ранжирования. Однако поисковые роботы должны иметь возможность переходить по ссылкам на странице, чтобы ссылочный вес проходил через них. Если для страницы установлены значения noindex и nofollow, она не может передать ссылочный вес.
При отсутствии индексации страница автоматически удаляется из поисковой выдачи Google?
Если ваша страница уже проиндексирована, добавление метатега robots не приведет к ее автоматическому удалению из результатов поиска. Чтобы страницы, которые уже проиндексированы, исчезли из поисковой выдачи, требуется некоторое время. Поисковым ботам необходимо повторно просканировать страницы, чтобы увидеть тег noindex.