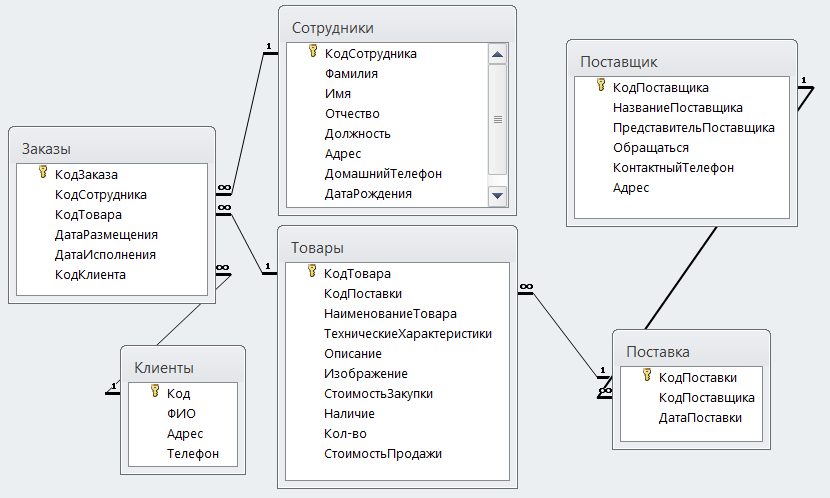
Содержание
7 типов современных баз данных: предназначение, достоинства и недостатки
Артём Гогин
руководитель направления в хранилище данных в Сбербанке
Существуют сотни баз данных SQL и NoSQL. Одни популярны, другие игнорируются. Некоторые просты и хорошо документированы, а некоторые сложны в использовании. Одни имеют открытый код, а другие проприетарные. Что, возможно, наиболее важно, некоторые масштабируемы, оптимизированы, высокодоступны, а некоторые сложно масштабировать или поддерживать.
Возникает естественный вопрос: какую базу данных выбрать? Чтобы ответить на него, мы должны решить, чего мы хотим достичь с помощью базы данных. Чтобы составить представление, необходимо ответить на следующие вопросы:
- Нужен ли нам аналитический доступ к базе данных?
- Нужно ли нам писать или читать в реальном времени?
- Сколько таблиц / записей мы хотим сохранить?
- Какая доступность нам нужна?
- Нужны ли нам столбцы?
- Сможем ли мы получить доступ к таблицам, отфильтрованным по столбцам или по строкам?
Принимая решение, нужно помнить, что может предложить та или иная база данных. Специфика каждой БД может отличаться, но в целом существует только несколько типов, в рамках которых мы можем достичь в основном одинаковых целей. Рассмотрим их подробнее.
Специфика каждой БД может отличаться, но в целом существует только несколько типов, в рамках которых мы можем достичь в основном одинаковых целей. Рассмотрим их подробнее.
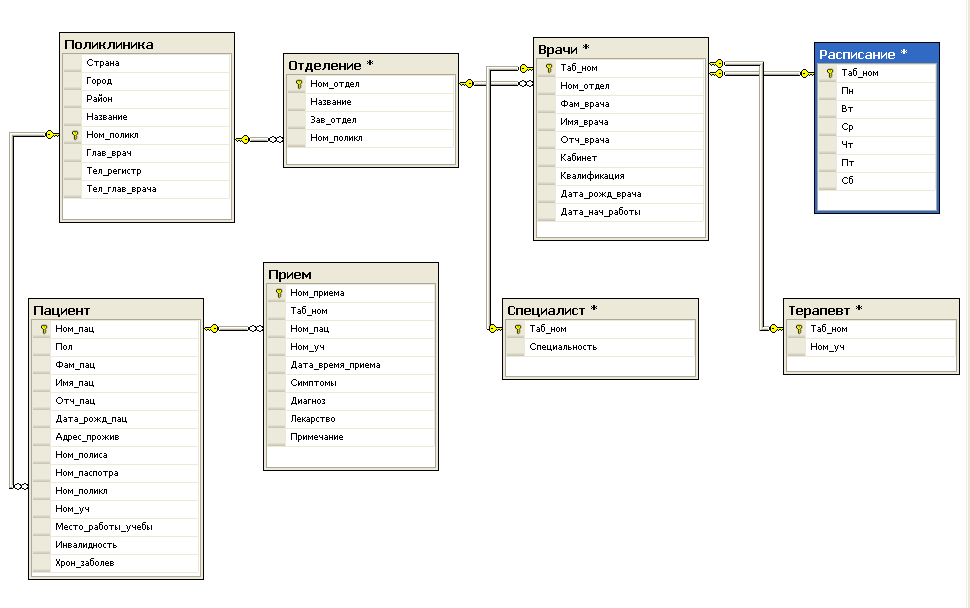
Реляционные базы данных SQL
Если вы когда-либо работали с базами данных, скорее всего, вы начали с этого типа, потому что он самый популярный и распространенный. Такие БД позволяют хранить данные в реляционных таблицах с определенными столбцами определенного типа. Реляционные таблицы хороши для нормализации и объединения.
Достоинства:
- Поддержка SQL
- ACID-транзакции (атомарность, согласованность, изоляция и долговечность)
- Поддержка индексации и разделения
Недостатки:
- Плохая поддержка неструктурированных данных / сложных типов
- Плохая оптимизация обработки событий
- Сложное / дорогое масштабирование
Примеры: Oracle DB, MySQL, PostgreSQL.
Документно-ориентированные базы данных
Если мы не хотим объединять несколько таблиц для получения нужных данных, мы можем взглянуть на документно-ориентированные базы данных. Они позволяют хранить записи в формате JSON. В этом формате мы можем создать сложное значение для любого ключа и сразу включить всю структуру данных в одну запись.
Они позволяют хранить записи в формате JSON. В этом формате мы можем создать сложное значение для любого ключа и сразу включить всю структуру данных в одну запись.
Достоинства:
- Нет привязки к схеме
- Нет необходимости всегда писать все поля в каждой записи
- Хорошая поддержка сложных типов
- Подходит для OLTP
Недостатки:
- Плохая поддержка транзакций
- Слабая аналитическая поддержка
- Сложное / дорогое масштабирование
Примеры: MongoDB.
Базы данных в оперативной памяти
Базы данных этого типа могут предоставлять в реальном времени ответ для выбора и вставки определенных записей. Большинство из них в основном хранят данные в ОЗУ, но в некоторых случаях они также предлагают постоянное хранилище на жестких дисках или твердотельных накопителях. Большинство этих баз данных работают с записями «ключ-значение», поэтому значения можно запоминать в формате, ориентированном на документы. Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
Достоинства:
- Быстрое написание
- Быстрое чтение
Недостатки:
- Труднодостижимая надёжность
- Дорогое масштабирование
Примеры: Redis, Tarantool, Apache Ignite.
Базы данных с широкими столбцами
Эти базы данных хранят данные в виде записей ключ / значение на жестком диске или твердотельном накопителе. Эти решения предназначены для достаточно хорошего масштабирования, чтобы управлять петабайтами данных на тысячах общих серверов в распределенной системе. Они представляют архитектуру SSTable. Эта архитектура была разработана для двух случаев использования: быстрый доступ к ключу и быстрая запись с высокой доступностью.
Достоинства:
- Быстрая запись построчно
- Быстрое чтение по ключу
- Хорошая масштабируемость
- Высокая доступность
Недостатки:
- Формат «ключ-значение»
- Нет поддержки аналитики
Примеры: Cassandra, HBase.
Столбчатые базы данных
Иногда нам нужно быстро получить доступ к данным не с помощью определенных ключей, а с помощью определенных столбцов. В этом случае лучше отказаться от построчной вставки и перейти к пакетной записи. Пакетная вставка позволяет столбчатым базам данных готовить данные для быстрого чтения по столбцам.
Достоинства:
- Быстрое чтение столбец за столбцом
- Хорошая аналитическая поддержка
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
Примеры: Vertica, Clickhouse.
Поисковая система
Если мы хотим получить доступ к данным с помощью фильтра по любому значению и даже по любому слову в столбце, мы должны вспомнить про поисковые системы. Эти базы данных выполняют индексацию каждого слова в столбцах и позволяют выполнять полнотекстовый поиск. Они идеально подходят для хранения и анализа журналов или больших текстовых значений.
Достоинства:
- Быстрый доступ по любому слову
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
- Плохая аналитическая поддержка
Примеры: Elastic.
Графовые базы данных
Для некоторых случаев подходят графовые структуры данных. Если ваши задачи требуют работы с графами, существуют специальные базы данных, которые удовлетворят ваши потребности.
Достоинства:
- Структура данных графа
- Управляемые отношения между сущностями
- Гибкие конструкции
Недостатки:
- Специальный язык запросов
- Трудно масштабировать
Примеры: Neo4j.
Выводы
Практически любую задачу можно выполнить практически с любым типом базы данных. Вопрос в том, насколько это будет дорого и оптимизировано. Выбор инструмента, к которому вы привыкли, может сократить ваше время вывода на рынок. Но он также может стоить вам огромных денег на обслуживание и расширение вашего оборудования, которое может быть использовано неэффективно. Всегда старайтесь использовать базу данных так, как она задумана. Возможно, решение, соответствующее вашим потребностям, уже существует.
Но он также может стоить вам огромных денег на обслуживание и расширение вашего оборудования, которое может быть использовано неэффективно. Всегда старайтесь использовать базу данных так, как она задумана. Возможно, решение, соответствующее вашим потребностям, уже существует.
Если вы готовитесь к собеседованию, посмотрите также статью, в которой собраны 27 распространённых вопросов по SQL и ответы на них.
SQLite, MySQL и PostgreSQL: сравниваем популярные реляционные СУБД
Реляционные базы данных используются уже очень давно. Они стали популярными благодаря успешным реализациям реляционных моделей в системах управления, оказавшимся весьма удобными для работы с данными. В этой статье мы сравним три самые популярные реляционные системы управления базами данных (РСУБД): SQLite, MySQL и PostgreSQL.
Системы управления базами данных
Базы данных — это логически смоделированные хранилища любых типов данных. Каждая база данных, не являющаяся бессхемной, следует модели, которая задаёт определённую структуру обработки данных. СУБД — это приложения (или библиотеки), управляющие базами данных различных форм, размеров и типов.
СУБД — это приложения (или библиотеки), управляющие базами данных различных форм, размеров и типов.
Чтобы лучше разобраться в СУБД, ознакомьтесь с этой статьёй.
Реляционные системы управления базами данных
Реляционные системы реализуют реляционную модель работы с данными, которая определяет всю хранимую информацию как набор связанных записей и атрибутов в таблице.
СУБД такого типа используют структуры (таблицы) для хранения и работы с данными. Каждый столбец (атрибут) содержит свой тип информации. Каждая запись в базе данных, обладающая уникальным ключом, передаётся в строку таблицы, и её атрибуты отображаются в столбцах таблицы.
Отношения и типы данных
Отношения можно определить как математические множества, содержащие наборы атрибутов, отображающие хранящуюся информацию.
Каждый элемент, формирующий запись, должен удовлетворять определённому типу данных (целое число, дата и т.д.). Различные РСУБД используют разные типы данные, которые не всегда взаимозаменяемы.
Такого рода ограничения обычны для реляционных баз данных. Фактически, они и формируют суть отношений.
Популярные РСУБД
В этой статье мы расскажем о 3 наиболее популярных РСУБД:
- SQLite: очень мощная встраиваемая РСУБД.
- MySQL: самая популярная и часто используемая РСУБД.
- PostgreSQL: самая продвинутая и гибкая РСУБД.
SQLite
SQLite — это изумительная библиотека, встраиваемая в приложение, которое её использует. Будучи файловой БД, она предоставляет отличный набор инструментов для более простой (в сравнении с серверными БД) обработки любых видов данных.
Когда приложение использует SQLite, их связь производится с помощью функциональных и прямых вызовов файлов, содержащих данные (например, баз данных SQLite), а не какого-то интерфейса, что повышает скорость и производительность операций.
Поддерживаемые типы данных
- NULL: NULL-значение.


- INTEGER: целое со знаком, хранящееся в 1, 2, 3, 4, 6, или 8 байтах.
- REAL: число с плавающей запятой, хранящееся в 8-байтовом формате IEEE.
- TEXT: текстовая строка с кодировкойUTF-8, UTF-16BE или UTF-16LE.
- BLOB: тип данных, хранящийся точно в таком же виде, в каком и был получен.
Note: для получения более подробной информации ознакомьтесь с документацией.
Преимущества
- Файловая: вся база данных хранится в одном файле, что облегчает перемещение.
- Стандартизированная: SQLite использует SQL; некоторые функции опущены (
RIGHT OUTER JOINилиFOR EACH STATEMENT), однако, есть и некоторые новые.
- Отлично подходит для разработки и даже тестирования: во время этапа разработки большинству требуется масштабируемое решение. SQLite, со своим богатым набором функций, может предоставить более чем достаточный функционал, при этом будучи достаточно простой для работы с одним файлом и связанной сишной библиотекой.
 SQLite, со своим богатым набором функций, может предоставить более чем достаточный функционал, при этом будучи достаточно простой для работы с одним файлом и связанной сишной библиотекой.
SQLite, со своим богатым набором функций, может предоставить более чем достаточный функционал, при этом будучи достаточно простой для работы с одним файлом и связанной сишной библиотекой.Недостатки
- Отсутствие пользовательского управления: продвинутые БД предоставляют пользователям возможность управлять связями в таблицах в соответствии с привилегиями, но у SQLite такой функции нет.
- Невозможность дополнительной настройки: опять-таки, SQLite нельзя сделать более производительной, поковырявшись в настройках — так уж она устроена.
Когда стоит использовать SQLite
- Встроенные приложения: все портируемые не предназначенные для масштабирования приложения — например, локальные однопользовательские приложения, мобильные приложения или игры.
- Система доступа к дисковой памяти: в большинстве случаев приложения, часто производящие прямые операции чтения/записи на диск, можно перевести на SQLite для повышения производительности.

- Тестирование: отлично подойдёт для большинства приложений, частью функционала которых является тестирование бизнес-логики.
Когда не стоит использовать SQLite
- Многопользовательские приложения: если вы работаете над приложением, доступом к БД в котором будут одновременно пользоваться несколько человек, лучше выбрать полнофункциональную РСУБД — например, MySQL.
- Приложения, записывающие большие объёмы данных: одним из ограничений SQLite являются операции записи. Эта РСУБД допускает единовременное исполнение лишь одной операции записи.
MySQL
MySQL — это самая популярная из всех крупных серверных БД. Разобраться в ней очень просто, да и в сети о ней можно найти большое количество информации. Хотя MySQL и не пытается полностью реализовать SQL-стандарты, она предлагает широкий функционал. Приложения общаются с базой данных через процесс-демон.
Поддерживаемые типы данных
- TINYINT: очень маленькое целое.
- SMALLINT: маленькое целое.
- MEDIUMINT: целое среднего размера.
- INT или INTEGER: целое нормального размера.
- BIGINT: большое целое.
- FLOAT: знаковое число с плавающей запятой одинарной точности.
- DOUBLE, DOUBLE PRECISION, REAL: знаковое число с плавающей запятой двойной точности.
- DECIMAL, NUMERIC: знаковое число с плавающей запятой.
- DATE: дата.
- DATETIME: комбинация даты и времени.
- TIMESTAMP: отметка времени.
- TIME: время.
- YEAR: год в формате YY или YYYY.
- CHAR: строка фиксированного размера, дополняемая справа пробелами до максимальной длины.
- VARCHAR: строка переменной длины. 32 — 1) символов.
 32 — 1) символов.
32 — 1) символов.- ENUM: перечисление.
- SET: множества.
Преимущества
- Простота: MySQL легко устанавливается. Существует много сторонних инструментов, включая визуальные, облегчающих начало работы с БД.
- Много функций: MySQL поддерживает большую часть функционала SQL.
- Безопасность: в MySQL встроено много функций безопасности.
- Мощность и масштабируемость: MySQL может работать с действительно большими объёмами данных, и неплохо походит для масштабируемых приложений.
- Скорость: пренебрежение некоторыми стандартами позволяет MySQL работать производительнее, местами срезая на поворотах.
Недостатки
- Известные ограничения: по определению, MySQL не может сделать всё, что угодно, и в ней присутствуют определённые ограничения функциональности.
- Вопросы надёжности: некоторые операции реализованы менее надёжно, чем в других РСУБД.
- Застой в разработке: хотя MySQL и является open-source продуктом, работа над ней сильно заторможена. Тем не менее, существует несколько БД, полностью основанных на MySQL (например, MariaDB). Кстати, подробнее о родстве MariaDB и MySQL можно из нашего интервью с создателем обеих РСУБД — Джеймсом Боттомли.
Когда стоит использовать MySQL
- Распределённые операции: когда вам нужен функционал бо́льший, чем может предоставить SQLite, стоит использовать MySQL.
- Высокая безопасность: функции безопасности MySQL предоставляют надёжную защиту доступа и использования данных.
- Веб-сайты и приложения: большая часть веб-ресурсов вполне может работать с MySQL, несмотря на ограничения. Этот инструмент весьма гибок и прост в обращении, что только на руку в длительной перспективе.
- Кастомные решения: если вы работаете над очень специфичным продуктом, MySQL подстроится под ваши потребности благодаря широкому спектру настроек и режимов работы.
Когда не стоит использовать MySQL
- SQL-совместимость: поскольку MySQL не пытается полностью реализовать стандарты SQL, она не является полностью совместимой с SQL. Из-за этого могут возникнуть проблемы при интеграции с другими РСУБД.
- Конкурентность: хотя MySQL неплохо справляется с операциями чтения, одновременные операции чтения-записи могут вызвать проблемы.
- Недостаток функций: в зависимости от выбора движка MySQL может недоставать некоторых функций.
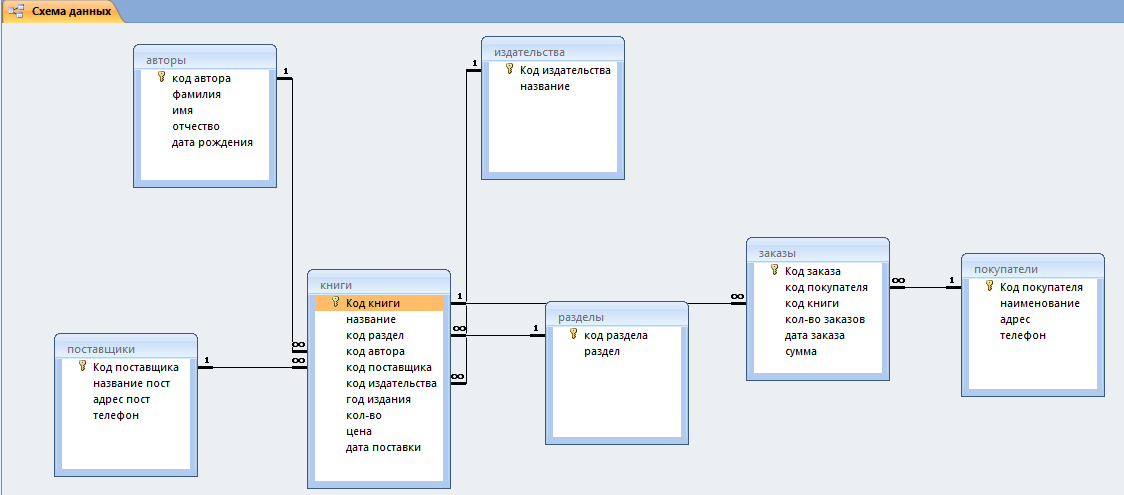
PostgreSQL
PostgreSQL — это самая продвинутая РСУБД, ориентирующаяся в первую очередь на полное соответствие стандартам и расширяемость. PostgreSQL, или Postgres, пытается полностью соответствовать SQL-стандартам ANSI/ISO.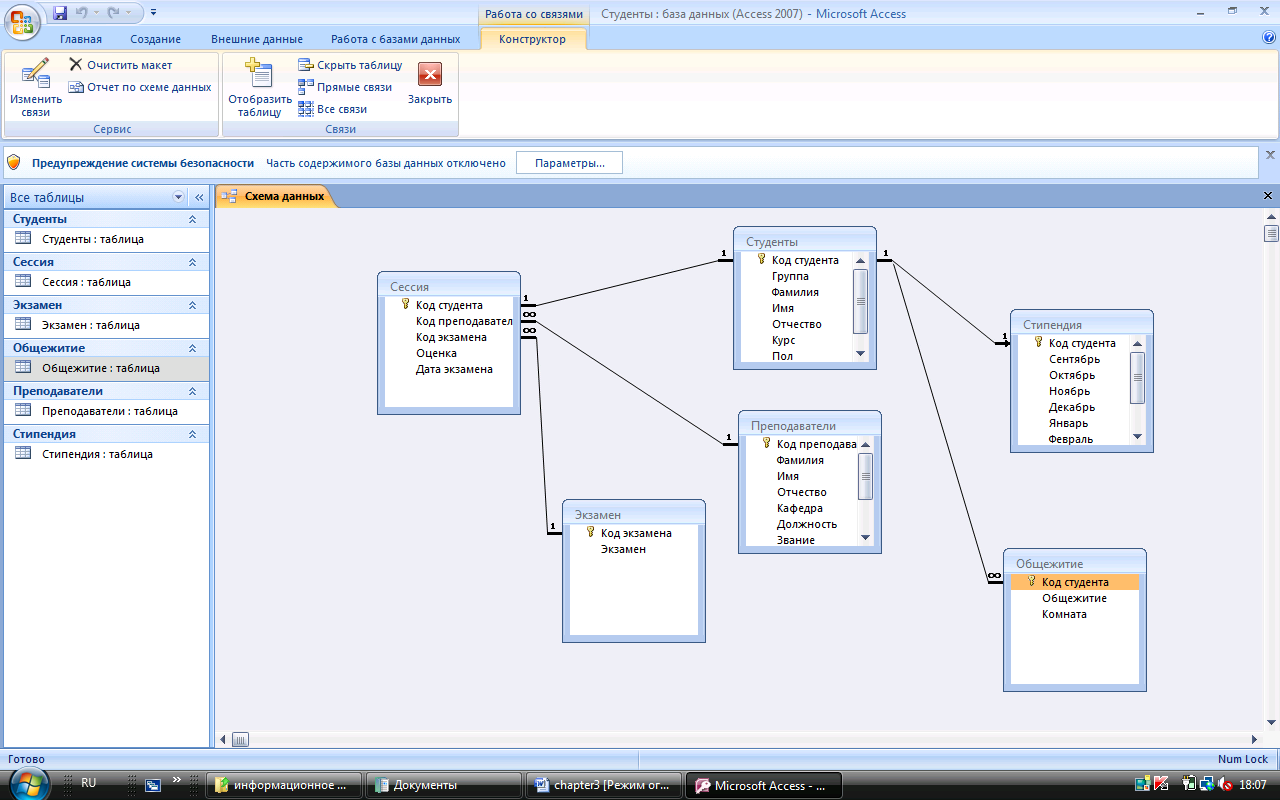
PostgreSQL отличается от других РСУБД тем, что обладает объектно-ориентированным функционалом, в том числе полной поддержкой концепта ACID (Atomicity, Consistency, Isolation, Durability).
Будучи основанным на мощной технологии Postgres отлично справляется с одновременной обработкой нескольких заданий. Поддержка конкурентности реализована с использованием MVCC (Multiversion Concurrency Control), что также обеспечивает совместимость с ACID.
Хотя эта РСУБД не так популярна, как MySQL, существует много сторонних инструментов и библиотек для облегчения работы с PostgreSQL.
Поддерживаемые типы данных
- bigint: знаковое 8-байтное целое.
- bigserial: автоматически инкрементируемое 8-битное целое.
- bit [(n)]: битовая строка фиксированной длины.
- bit varying [(n)]: битовая строка переменной длины.
- boolean: булевская величина.
- box: прямоугольник на плоскости.
- bytea: бинарные данные.
- character varying [(n)]: строка символов фиксированной длины.
- character [(n)]: строка символов переменной длины.
- cidr: сетевой адрес IPv4 или IPv6.
- circle: круг на плоскости.
- date: календарная дата.
- double precision: число с плавающей запятой двойной точности.
- inet: адрес хоста IPv4 или IPv6.
- integer: знаковое 4-байтное целое.
- interval [fields] [(p)]: временной промежуток.
- line: бесконечная прямая на плоскости.
- lseg: отрезок на плоскости.
- macaddr: MAC-адрес.

- money: денежная величина.
- path: геометрический путь на плоскости.
- point: геометрическая точка на плоскости.
- polygon: многоугольник на плоскости.
- real: число с плавающей запятой одинарной точности.
- smallint: знаковое 2-байтное целое.
- serial: автоматически инкрементируемое 4-битное целое.
- text: строка символов переменной длины.
- time [(p)] [without time zone]: время суток (без часового пояса).
- time [(p)] with time zone: время суток (с часовым поясом).
- timestamp [(p)] [without time zone]: дата и время (без часового пояса).
- timestamp [(p)] with time zone: дата и время (с часовым поясом).

- tsquery: запрос текстового поиска.
- tsvector: документ текстового поиска.
- txid_snapshot: снэпшот ID пользовательской транзакции.
- uuid: уникальный идентификатор.
- xml: XML-данные.
Преимущества
- Полная SQL-совместимость.
- Сообщество: PostgreSQL поддерживается опытным сообществом 24/7.
- Поддержка сторонними организациями: несмотря на очень продвинутые функции, PostgreSQL используется в многих инструментах, связанных с РСУБД.
- Расширяемость: PostgreSQL можно программно расширить за счёт хранимых процедур.
- Объектно-ориентированность: PostgreSQL — не только реляционная, но и объектно-ориентированная СУБД.
Недостатки
- Производительность: В простых операциях чтения PostgreSQL может уступать своим соперникам.
- Популярность: из-за своей сложности инструмент не очень популярен.
- Хостинг: из-за вышеперечисленных факторов проблематично найти подходящего провайдера.
Когда стоит использовать PostgreSQL
- Целостность данных: если приоритет стоит на надёжность и целостность данных, PostgreSQL — лучший выбор.
- Сложные процедуры: если ваша БД должна выполнять сложные процедуры, стоит выбрать PostgreSQL в силу её расширяемости.
- Интеграция: если в будущем вам предстоит перемещать всю базу на другое решение, меньше всего проблем возникнет с PostgreSQL.
Когда не стоит использовать PostgreSQL
- Скорость: если всё, что нужно — это быстрые операции чтения, не стоит использовать PostgreSQL.
- Простые ситуации: если вам не требуется повышенная надёжность, поддержка ACID и всё такое, использование PostgreSQL — это стрельба из пушки по мухам.
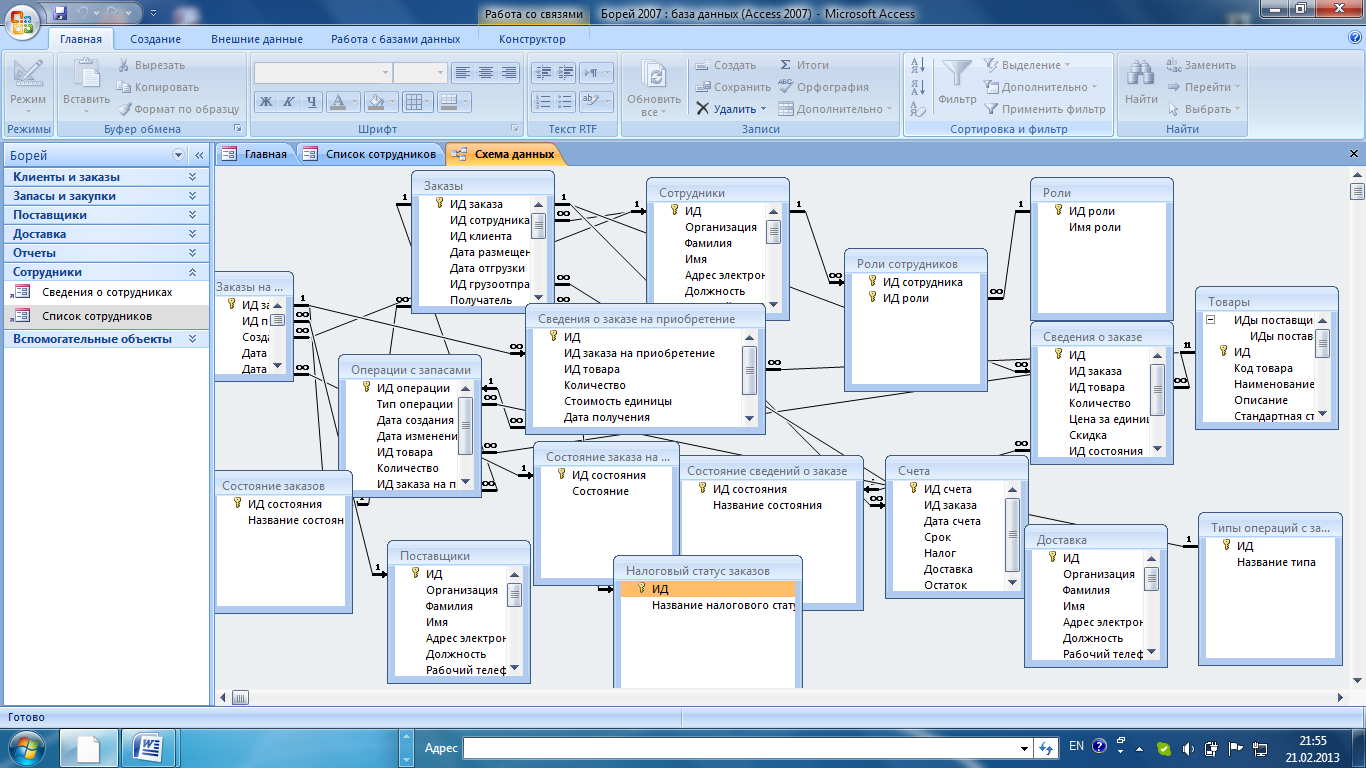
Перевод статьи «SQLite vs MySQL vs PostgreSQL: A Comparison Of Relational Database Management Systems»
Облегченная база данных (SQL или NoSQL)
В настоящее время я работаю над веб-сайтом, который должен существовать на виртуальной машине с очень низкой доступностью памяти (на данный момент мне сказали ожидать 512 МБ). К сожалению, по крайней мере в ближайшем будущем база данных и веб-приложение должны быть на одном сервере.
Теперь я прочитал несколько вопросов здесь и попытался провести собственное исследование, но есть так много вариантов на выбор. По сути, какой достаточно легкий сервер базы данных я могу установить? SQL или NoSQL на самом деле не имеет значения; это не будет интенсивно использовать базу данных, но я хотел бы не ограничиваться тем, что я выбираю сейчас. Это означает, что если возможно, путь к масштабированию с несколькими серверами был бы отличным, но, очевидно, не обязательным на данном этапе.
Сейчас я думаю либо о MongoDB, либо о MySQL, но я не уверен, что это лучший выбор.
Мое веб-приложение работает на nginx с PHP, что я считаю лучшим выбором на данный момент, поэтому меня больше всего беспокоит база данных.
- sql
- база данных
- память
- nosql
2
если вам нужна самая легкая база данных , я бы сказал sqlite 3. она специально разработана для этой задачи, маленькая и быстрая, и по моему опыту надежная и простая в использовании.
Я сам не использую php, но, похоже, здесь есть поддержка.
sqlite поддерживает в значительной степени «стандартный» sql, за исключением того, что он не применяет типы — вы можете определить столбец как текст, но сохранить и получить целочисленное значение, если хотите. на практике это не имеет большого значения, и пока вы не используете эту «функцию», вы можете без особых проблем переключиться на более крупную базу данных в будущем.
, но на практике я бы начал с mysql, поскольку он, вероятно, уже установлен и доступен. если это вызывает проблемы с использованием памяти, переключитесь на sqlite. но для простой базы данных без излишеств вы можете начать с mysql.
если это вызывает проблемы с использованием памяти, переключитесь на sqlite. но для простой базы данных без излишеств вы можете начать с mysql.
0
При выборе между реляционной базой данных или базой данных, ориентированной на документы, лучше всего сосредоточиться на потребностях хранения данных конкретного приложения. Если приложение, лучше подходящее для реляционной базы данных, написано поверх документно-ориентированной базы данных, такой как MongoDB, оно будет менее эффективным и будет потреблять больше ресурсов.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
memgraphdb — легкие графовые базы данных для прототипирования
спросил
Изменено
7 месяцев назад
Просмотрено
4к раз
Для создания прототипа я ищу легковесную графовую базу данных — по сути, графический эквивалент для Memcached, Redis или SQLite; что-то тривиальное в использовании и развертывании (в среде JavaScript/Ruby/Python/Go/. ..).
..).
Хотя Neo4j предоставляет все, что мне нужно, он немного тяжеловат для моих целей.
Самое близкое, что я нашел, это HeliosJS, хотя он использует Gremlin, тогда как я бы предпочел Cypher.
Будем признательны за любые рекомендации.
- граф-базы данных
- memgraphdb
Cypher работает только с Neo4j, поэтому если вы привязаны к его использованию, то вы также привязаны к Neo4j. Я не знаю о каких-либо других реализациях этого языка для любого другого графа.
Для прототипирования я всегда рекомендую TinkerGraph с Gremlin REPL. TinkerGraph очень легкий и работает как графическая база данных в памяти. Это самая быстрая из всех реализаций Blueprints. Я почти всегда сначала обращаюсь к Gremlin/TinkerGraph при «прототипировании», попытке обхода, тестировании схемы графа, загрузке образца набора данных и т. д., поскольку он обеспечивает мгновенную обратную связь, множество вариантов интеграции и всю мощь Groovy. для манипулирования данными. Подробнее о Gremlin REPL как «верстаке для графиков» можно прочитать здесь. 9Обновление 0003
Подробнее о Gremlin REPL как «верстаке для графиков» можно прочитать здесь. 9Обновление 0003
: обратите внимание, что приведенные выше ссылки указывают на TinkerPop 2.x. TinkerPop 3.x также предлагает TinkerGraph и консоль Gremlin.
4
Вот в 2022 году у нас есть еще несколько вариантов. Memgraph — это графовая база данных в памяти, которая обеспечивает реализацию Cypher. Я нашел этот вопрос SO и следующий обзор пяти баз данных Python в памяти в верхней части поиска «облегченной базы данных графов в памяти» —
https://memgraph.com/blog/in-memory-database- питон
Я еще не пробовал ни один из них, но буду пробовать Memgraph для интенсивной задачи с графиком в памяти в Python.
Другой вариант, который я рассмотрю, — это Apache TinkerPop, который предлагает Gremlin для запросов (GQL, который, среди прочего, использует цепочку методов) и имеет интерфейсы Python, такие как gremlinpython, который поддерживает стиль вызова цепочки методов.