Содержание
зачем нужна, как создавать и как тестировать
Оглавление
Руководитель школы,
основной автор федерального профстандарта системного аналитика,
Certified Professional for Requirements Engineering
Контекстная диаграмма
Зачем нужна контекстная диаграмма?
Обсуждение и визуализация назначения и границ системы
Контекстная диаграмма прежде всего позволяет быстро, кратко и ёмко описать назначение и границы системы, выявить и устранить коллективные расхождения в их понимании, показать и договориться о её масштабе.
Быстрое выявление функциональных системных требований
Второе её назначение — служить источником для быстрой генерации первичного набора системных функциональных требований при необходимости проектирования системы не «сверху-вниз», от бизнес-модели, бизнес-требований, модели деятельности организации, требований заинтересованных лиц, модели использования, как предлагает нам системная инженерия, а «из середины».
Как устроена контекстная диаграмма
Контекстная диаграмма относится к категории диаграмм, описывающих систему на уровне «чёрного ящика» — а именно, только внешние свойства (в данном случае — потоки данных), но не содержание системы.
Контекстная диаграмма содержит 3 основных компонента:
- Проектируемый объект (например, система)
- Взаимодействующие с проектируемым объектом элементы окружения (группы пользователей, смежные системы)
- Потоки данных (исходящие и входящие)
Пример контекстной диаграммы для программной системы управления Заказами в ресторане:
Потоки данных могут передаваться между окружением и (программной) системой любым образом — с помощью графического пользовательского интерфейса (GUI), командной строки (CLI), программных вызовов (API), почтовых сообщений и т.д.
Если система имеет физические интерфейсы, то это могут быть разнообразные джойстики, рукоятки управления, специализированные клавиатуры, датчики распознавания движения, изображения, жестов и т. д.
д.
В стандартной форме не принято указывать виды интерфейсов взаимодействия и тем более протоколы, чтобы не усложнять диаграмму и не пытаться принимать вторичные решения, пока не приняты первичные.
Пример контекстной диаграммы для программной системы автоматизации Единого расчётного центра (ЕРЦ) коммунальных услуг:
Как создавать контекстную диаграмму
Контекстная диаграмма может разрабатываться в ходе рабочего семинара, в ходе серии интервью или на основе результатов серии интервью.
Контекстную диаграмму можно рисовать на маркерной доске, в среде проектирования или в онлайн-инструменте (Google Draw, Draw.io, Miro и т.д.). Мы рекомендуем маркерную доску или онлайн-инструмент с совместным редактированием.
Порядок разработки контекстной диаграммы на рабочем семинаре:
- Из числа заинтересованных лиц собирается рабочая группа (обычно от 3 до 5 человек)
- Рабочая группа фиксирует в центре диаграммы название конкретной системы
- Рабочая группа выдвигает и отображает группы пользователей, которые должны взаимодействовать с системой, обсуждает их перечень, дополняет его
- Рабочая группа выдвигает и отображает смежные системы, которые должны взаимодействовать с системой, обсуждает их перечень, дополняет его
- Рабочая группа последовательно проходит по каждому элементу окружения и описывает потоки данных, связывающие его с системой
- Рабочая группа проводит тестирование контекстной диаграммы, дополняя диаграмму по ходу тестирования
Для экономии времени участников тестирование можно производить 1-2 участниками, однако это ухудшает осведомлённость группы о найденных проблемах, поэтому мы не рекомендуем так делать.
Как тестировать контекстную диаграмму
Диаграмму можно тестировать 2-мя способами — через контроль соответствия входных и выходных данных системы или через сквозной устный сценарий использования системы.
Тестирование контекстной диаграммы с помощью парных соответствий
Контроль соответствия входных и выходных данных системы опирается на принцип (aka «Закон сохранения данных»), что если в систему попадают какие-то данные (входной поток), они должны как-то использоваться для как минимум одного выходного потока.
И наоборот, если есть выходной поток, то система либо должна генерировать эти данные согласно каким-то правилам (например, случайно) или формировать их на основе каких-то других входных данных.
Более формально парные соответствия можно проконтролировать через таблицу, например:
Тестирование контекстной диаграммы с помощью сквозного сценария
В зависимости от сложности системы, можно проводить неформальное или формальное тестирование диаграммы через сквозной сценарий её использования.
Как выглядит неформальное тестирование — один из участников семинара, опираясь на конкретные потоки данных и указывая их на диаграмме, рассказывает возможный сквозной сценарий использования системы, начиная с логически более ранних событий и продолжая последующими, например:
- Система загружает реестр пользователей из AD
- Администратор настраивает полномочия пользователей
- и т.д.
Фактически такой рассказ служит своеобразной «нарративной» формой изложения концепции (использования) системы, наколеночно, но тем не менее достаточно эффективно подменяет создание полной модели использования для целей контекстной диаграммы.
По ходу рассказа остальные участники помечают на диаграмме задействованные в сценарии потоки, дают свои комментарии, оперативно вносят изменения и дополнения в диаграмму. Очень часто в таком сценарии обнаруживаются пропущенные потоки данных.
При желании такой сквозной сценарий можно разработать и записать, сделав его приложением к контекстной диаграмме, иллюстрирующим текстом работу системы.
Как применять контекстную
диаграмму после её создания
Диаграмма может использоваться в документе концепции системы, документе системных требований или вики-документации для получения обзорного представления о назначении системы у читателя.
Контекстная диаграмма не создаётся один раз и навсегда, она может эволюционировать в ходе проекта. Другое дело, что каждое изменение диаграммы по сути означает изменение рамок системы и должно внимательно отрабатываться проектной командой.
Выявление и контроль полноты (функциональных) системных требований
При создании системных требований возникает риск упустить что-то важное или наоборот, избыточно проработать очевидное.
Чтобы не упустить что-то важное среди системных функций, можно применять:
- Трассировку системных требований на требования заинтересованных лиц
- Модель использования системы (обычно в форме набора сценариев использования, use case’ов)
- Контекстную диаграмму системы
Контекстная диаграмма может эффективно использоваться для выявления первичного набора системных функциональных требований.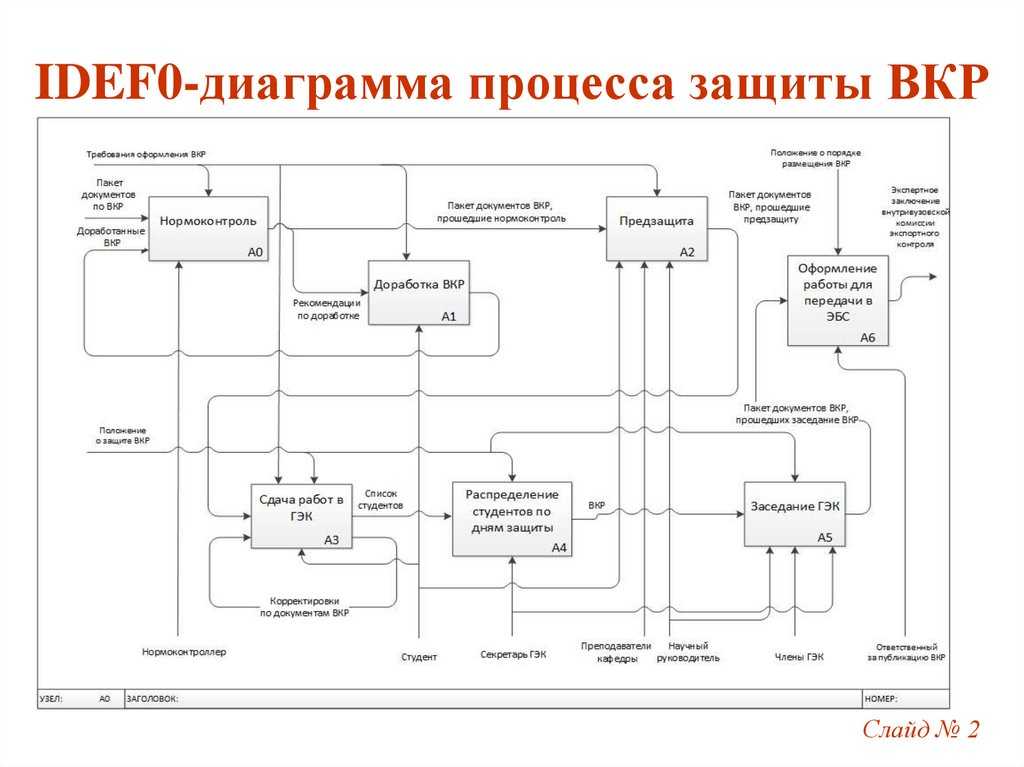 Каждый поток данных на диаграмме по сути означает, подразумевает какую-то функцию.
Каждый поток данных на диаграмме по сути означает, подразумевает какую-то функцию.
Наибольшие гарантии даёт применение всех 3-х методов, однако контекстная диаграмма — это самый простой и дешёвый их них, поэтому часто стоит начинать проработку системных требований именно с неё.
Чтобы убедиться в том, что при выявлении первичного набора системных функциональных требований вы не упустили ни один из нарисованных потоков данных, бывает полезно развернуть потоки данных в таблицу, на которую потом страссировать порождённые ей требования:
Если выполнить все рекомендации статьи, то у вас может получиться такая схема трассировок:
Особенности диаграммы
В канонической форме не делают различий в том, как на диаграмме показываются группы пользователей и смежные системы, однако вы можете ввести собственные правила для большей наглядности, например, разный цветовой фон.
Откуда взялась контекстная диаграмма
и почему до сих пор актуальна
Похоже что контекстная диаграмма в той или иной форме использовалась человечеством в разное время, однако свою каноническую форму получила у Тома ДеМарко в 70-80-х годах в семействе методологий Structured Analysis and Structured Design как верхний уровень диаграммы потоков данных — DFD (Data Flow Diagram).
При создании нотации и языка UML его авторы не взяли в него контекстную диаграмму, а использовали диаграмму схожего назначения — диаграмму использования (Use Case Diagram, UCD).
Диаграмма использования фокусируется только на части потоков данных, применение которых помогает агентам в достижении важных для них результатов и, таким образом, относится к более высокому уровню — уровню модели использования.
По задумке авторов UML, отсутствие всех потоков данных не позволяет использовать UCD для выявления функциональных требований непосредственно, а требует предварительной проработки сценариев использования и извлечения ФТ уже из них.
Таким образом диаграммы не взаимозаменяемы, а скорее дополняют друг друга и поэтому для сложных систем полезно строить обе диаграммы.
Подписаться на новые статьи
Научиться создавать эффективные системные требования
Научиться создавать эффективные системные требования под руководством опытного наставника с использованием контекстных диаграмм, а также ещё 10 других современных аналитических техник, можно на нашем онлайн-курсе «Системный анализ и Разработка требований к ИТ-системам»
| СМОТРЕТЬ ПРОГРАМММУ |
Нотация IDEF0 [BS Docs 5]
IDEF0 — нотация графического моделирования, используемая для создания функциональной модели, отображающей структуру и функции системы, а также потоки информации и материальных объектов, связывающих эти функции.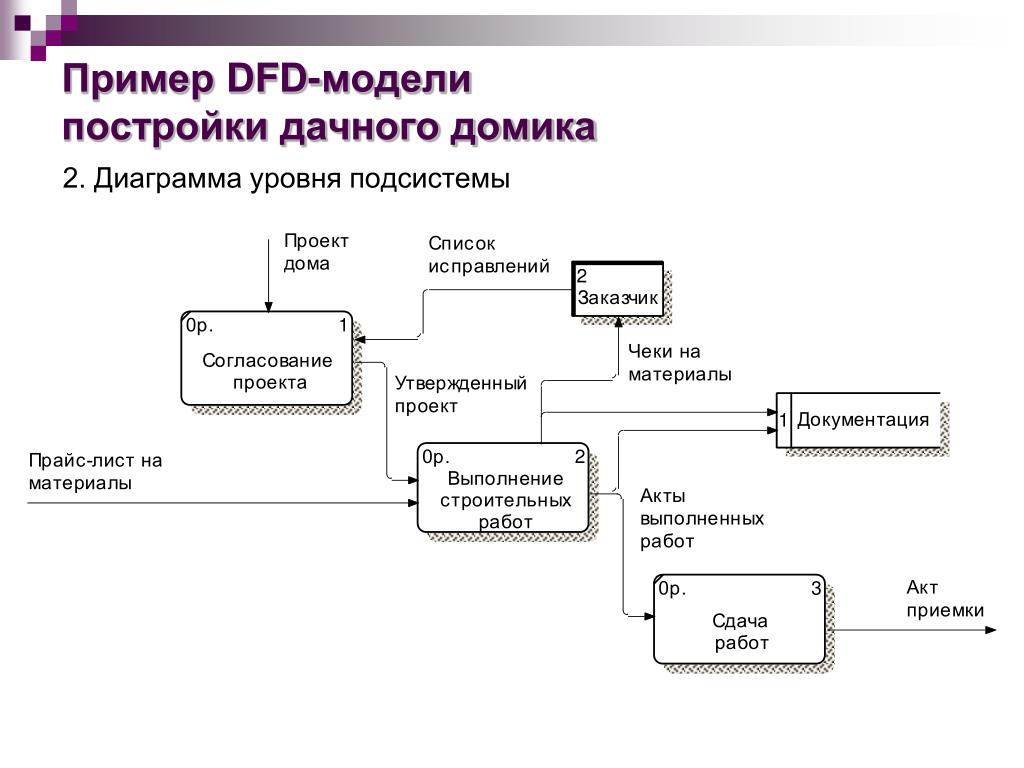 Стандарт IDEF0 (Integration Definition for Function Modeling) утвержден в США в 1993 как Федеральный стандарт обработки информации. В России находится в статусе руководящего документа с 2000 года и в настоящее время в качестве стандарта не утвержден. Тем не менее методология IDEF0 является одним из популярных подходов для описания бизнес-процессов. К ее особенностям можно отнести:
Стандарт IDEF0 (Integration Definition for Function Modeling) утвержден в США в 1993 как Федеральный стандарт обработки информации. В России находится в статусе руководящего документа с 2000 года и в настоящее время в качестве стандарта не утвержден. Тем не менее методология IDEF0 является одним из популярных подходов для описания бизнес-процессов. К ее особенностям можно отнести:
использование контекстной диаграммы;
поддержка декомпозиции;
доминирование;
выделение 4 типов стрелок.
Контекстная диаграмма. Самая верхняя диаграмма, на которой объект моделирования представлен единственным блоком с граничными стрелками. Эта диаграмма называется A-0 (А минус нуль). Стрелки на этой диаграмме отображают связи объекта моделирования с окружающей средой. Диаграмма A-0 устанавливает область моделирования и ее границу. Пример диаграммы A-0 приведен на Рис. 1.
Рисунок 1. Диаграмма A-0 в нотации IDEF0
Диаграмма A-0 в нотации IDEF0
Поддержка декомпозиции. Нотация IDEF0 поддерживает последовательную декомпозицию функций до требуемого уровня детализации. Дочерняя диаграмма, создаваемая при декомпозиции, охватывает ту же область, что и родительская функция, но описывает ее более подробно. Согласно методологии IDEF0 при декомпозиции стрелки родительской функции переносятся на дочернюю диаграмму в виде граничных стрелок.
Доминирование. Блоки модели IDEF0 на неконтекстной диаграмме должны располагаться по диагонали — от левого верхнего угла диаграммы до правого нижнего в порядке присвоенных номеров. Блоки на диаграмме, расположенные вверху слева, «доминируют» над блоками, расположенными внизу справа. «Доминирование» понимается как влияние, которое блок оказывает на другие блоки диаграммы. Расположение блоков на листе диаграммы отражает авторское понимание доминирования. Таким образом, топология диаграммы показывает, какие функции оказывают большее влияние на остальные.
Выделение 4 типов стрелок. Выделяются следующие типы стрелок: «Вход», «Выход», «Механизм», «Управление». Входы преобразуются или расходуются функцией, чтобы создать то, что появится на его выходе. Управления определяют условия, необходимые функции, чтобы произвести правильный выход. Выходы — данные или материальные объекты, произведенные функцией. Механизмы идентифицируют средства, поддерживающие выполнение функции. Таким образом, блок IDEF0 показывает преобразование входа в выход с помощью механизмов с учетом управляющих воздействий.
Описание назначения графических символов, используемых в нотации IDEF0, приведено в Таблице 1.
| Название | Кнопка | Графический символ | Описание |
|---|---|---|---|
| Функция | Функция обозначается прямоугольным блоком. Внутри каждого блока помещается его имя и номер. Имя должно быть активным глаголом, глагольным оборотом или отглагольным существительным. Номер блока размещается в правом нижнем углу. Номера блоков используются для идентификации на диаграмме и в соответствующем тексте. Номер блока размещается в правом нижнем углу. Номера блоков используются для идентификации на диаграмме и в соответствующем тексте. | ||
| Стрелка | Стрелки обозначают входящие и исходящие из функции объекты (данные). Каждая сторона функционального блока имеет стандартное значение с точки зрения связи блок-стрелка. В свою очередь, сторона блока, к которой присоединена стрелка, однозначно определяет ее роль. Стрелки, входящие в левую сторону блока — входы. Стрелки, входящие в блок сверху — управления. Стрелки, покидающие функцию справа — выходы, т.е. данные или материальные объекты, произведенные функцией. Стрелки, подключенные к нижней стороне блока, представляют механизмы. | ||
| Туннелированная стрелка | Туннелированные стрелки означают, что данные, передаваемые с помощью этих стрелок, не рассматриваются на родительской диаграмме и/или на дочерней диаграмме. Стрелка, помещенная в туннель там, где она присоединяется к блоку, означает, что данные, выраженные этой стрелкой, не обязательны на следующем уровне декомпозиции.  Стрелка, помещаемая в туннель на свободном конце, означает, что выраженные ею данные отсутствуют на родительской диаграмме. Туннелированные стрелки могут быть использованы на диаграммах функции в нотации IDEF0 и процессов в нотациях «Basic Flowchart», «Cross-functional Flowchart». | ||
| Внешняя ссылка | Символ обозначает место, сущность или оргединицу, которые находятся за границами моделируемой системы. Внешние ссылки используются для обозначения источника или приемника стрелки вне модели. На диаграммах Внешняя ссылка изображается в виде квадрата, рядом с которым показано наименование Внешней ссылки. Внешние ссылки могут быть использованы на диаграммах процессов и функций в любых нотациях. | ||
| Междиаграммная ссылка | Символ, обозначающий другую диаграмму. Междиаграммная ссылка служит для обозначения перехода стрелки на диаграмму другой функции или процесса без отображения стрелки на вышележащей диаграмме (при использовании иерархических моделей). В качестве междиаграммной ссылки не может выступать диаграмма процесса в нотациях EPC и BPMN. | ||
| Ссылка на единицу деятельности | Символ обозначает ссылку на типовую модель единицы деятельности. Например, наиболее часто повторяющиеся процессы в рамках модели бизнес-процессов могут быть выделены в качестве типовых в отдельную папку в Навигаторе. Диаграмма типового процесса формируется один раз в одном месте Навигатора. Далее на любой диаграмме может быть использована ссылка на единицу деятельности на типовой процесс. Параметры типового процесса заполняются непосредственно в Окне свойств типового процесса. Постоянный список оргединиц, принимающих участие в выполнении типового процесса, формируется также в Окне свойств типового процесса. Список оргединиц, принимающих участие при выполнении типового процесса в рамках вышележащего процесса, формируется в Окне свойств ссылки на единицу деятельности на типовой процесс.  Ссылки на единицу деятельности могут быть использованы на диаграммах функций и процессов в любых нотациях. | ||
| Сноска | Выносной символ, предназначенный для нанесения комментариев. Символ может быть использован на диаграммах функций и процессов в любых нотациях. | ||
| Текст | Комментарий без сноски. Символ может быть использован на диаграммах функций и процессов в любых нотациях. |
Таблица 1. Графические символы, используемые в нотации IDEF0
Информация о способах добавления символов на диаграмму содержится в главе Руководство пользователя → Создание модели деятельности организации.
Пример функциональной диаграммы в нотации IDEF0 приведен на Рис. 2.
Рисунок 2. Функциональная диаграмма в нотации IDEF0
Процессы,
Диаграмма
Контекст — король. Контекстные функции в Scala 3 | Адам Варски | SoftwareMill Tech Blog
Контекстные функции — одна из новых контекстных абстракций, появившихся в Scala 3. Выпуск близится быстро, дизайн завершен, так что давайте рассмотрим эту функцию более подробно!
Выпуск близится быстро, дизайн завершен, так что давайте рассмотрим эту функцию более подробно!
Если вы предпочитаете видеоверсию с кодированием в реальном времени, посмотрите недавнюю встречу Scala In The City на ту же тему.
Аудиенция у короля, Зофия Варска
Прежде чем мы углубимся в примеры использования и подумаем, почему вам вообще может быть интересно использовать контекстные функции, давайте посмотрим, что они из себя представляют и как их использовать.
Обычная функция может быть написана на Scala следующим образом:
val f: Int => String = (x: Int) => s"Got: $ x"
Контекстная функция выглядит аналогично , однако принципиальное отличие состоит в том, что параметры являются неявными. То есть при использовании функции параметры должны быть в неявной области видимости и ранее предоставлены компилятору, например. используя с учетом ; по умолчанию они не передаются явно.
тип контекстной функции записывается с использованием ?=> вместо => , и в реализации мы можем ссылаться на неявные параметры, находящиеся в области видимости, как определено типом. В Scala 3 это делается с помощью invoke[T] , который в Scala 2 известен как неявно[T] . Здесь, в теле функции, мы можем получить доступ к заданному значению Int :
val g: Int ?=> String = s"Got: $ {summon[Int]}" Как F имеет функцию Type , , G — это экземпляр контекстной функции1 :
Val FF: Function1 [int, String] = F
Val GG: ContextFunction1 [int, String] = F
Val GG: контекст1 [int, строка] = F
Val GG: ContextFunction1 [int, String] = F
Val GG: ContextFunction1 [int, String] = F
VAL String] = g
Контекстные функции — это обычные значения, которые можно передавать как параметры или хранить в коллекциях. Мы можем вызвать контекстную функцию, явно указав неявные параметры:
Мы можем вызвать контекстную функцию, явно указав неявные параметры:
println(g(using 16))
Или мы можем предоставить значение в неявной области. Компилятор догадается об остальном:
println {
задано Int = 42
g
} Замечание: никогда не следует использовать «общие» типы, такие как
IntилиStringдля заданных/допустимых значений. . Вместо этого все, что попадает в неявную область, должно иметь узкий, настраиваемый тип, чтобы избежать случайного загрязнения неявной области.
Как и обычные функции, контекстные функции могут иметь несколько параметров, как в каррированной, так и в некарриентной форме:
val g1: Int ?=> Boolean ?=> String = s" $ {summon[Int]}
$ {summon[Boolean]}" val g2: (Int, Boolean) ? => String = s" $ {summon[Int]}
$ {summon[Boolean]}" Но это еще не все — компилятор Scala изменит форму контекстных функций по мере необходимости. Изменение порядка параметров или использование каррированной функции там, где нужна некаррированная, не является проблемой. Например, если у нас есть следующие функции, которые используют функции контекста:
Изменение порядка параметров или использование каррированной функции там, где нужна некаррированная, не является проблемой. Например, если у нас есть следующие функции, которые используют функции контекста:
def run1(f: Int ?=> Boolean ?=> String): Unit =
println(f( с использованием 9)( с использованием false)) def run2(f: Boolean ?=> Int ?=> String): Unit =
println(f( с использованием true)( с использованием 10)) def run3(f: (Boolean, Int) ?=> String): Unit =
println(f ( с использованием false, 11))
мы можем вызвать их как с g1 так и с g2 напрямую:
run1(g1)
run2(g1)
run3(g1)
В месте вызова компилятор создаст новую контекстную функцию желаемой формы, если предоставленная функция имеет все необходимые параметры для удовлетворения требований.
Давайте начнем с некоторых применений! Если вы занимались программированием с использованием Scala 2 и Akka, вы, вероятно, сталкивались с ExecutionContext . Почти любой метод, который имел дело с Future , вероятно, имел дополнительные .неявный ec: список параметров ExecutionContext .
Например, вот как может выглядеть в Scala 2 упрощенный фрагмент функции бизнес-логики, которая сохраняет нового пользователя в БД, если пользователя с данным email еще не существует:
case class User (email: String) def newUser(u: User)(
неявный ec: ExecutionContext): Future[Boolean] = {
lookupUser(u.email).flatMap {
case Some (_) => Будущее. успешно (ложь)
case None => saveUser(u).map(_ => true)
}
} def lookupUser(email: String)(
неявный ec: ExecutionContext): Future[ Опция [Пользователь]] = ??? def saveUser(u: User)(
неявный ec: ExecutionContext): Future[Unit] = ???
Мы предполагаем, что методы lookupUser и saveUser взаимодействуют с базой данных каким-то асинхронным или синхронным образом.
Обратите внимание, что ExecutionContext должен проходить через все вызовы. Это не нарушает договоренности, но все же раздражает и является еще одним шаблонным шаблоном. Было бы здорово, если бы мы могли зафиксировать тот факт, что нам нужен ExecutionContext каким-то абстрактным образом…
Оказывается, со Scala 3 мы можем! Вот для чего нужны контекстные функции. Давайте определим псевдоним типа:
type Executable[T] = ExecutionContext ?=> Future[T]
Любой метод с типом результата Executable[T] потребует заданный (неявный) контекст выполнения для получения результата ( Future ). Вот как может выглядеть наш код после рефакторинга:
case class User(email: String) def newUser(u: User): Executable[Boolean] = {
lookupUser(u.email).flatMap {
case Some(_) => Future.successful(false)
case None => saveUser(u). map(_ => true)
map(_ => true)
}
} def lookupUser(email: String): Executable[Option[User]] = ??? def saveUser(u: User): Executable[Unit] = ???  map(_ => true)
map(_ => true) Подписи типов короче — это один плюс. В остальном код не изменился — это еще одно преимущество. Например, для метода lookupUser требуется ExecutionContext . Он автоматически предоставляется компилятором, поскольку он находится в области действия, как указано в сигнатуре метода контекстной функции верхнего уровня.
Исполняемый как абстракция
Однако чисто синтаксическое изменение, которое мы видели выше — дающее нам более чистые сигнатуры типов — не единственное отличие. Поскольку теперь у нас есть абстракция для «вычисления, требующего контекста выполнения», мы можем создавать комбинаторы, которые работают с ними. Например:
// повторяет данное вычисление до `n` раз и возвращает
// успешный результат, если таковой имеется
def retry[T](n: Int, f: Executable[T]): Executable[T]// запускает все заданные вычисления, причем не более `n` выполняется за
// параллельно в любое время
def runParN[T](n: Int, fs: List[Executable[T]]): Executable[List[T]]
Это возможно из-за кажущегося невинным синтаксиса, но огромная смысловая разница. Результат метода:
Результат метода:
def newUser(u: User)( неявный ec: ExecutionContext): Future[Boolean]
— это запущенное вычисление , которое в итоге вернет логическое значение. С другой стороны:
def newUser(u: User): Executable[Boolean]
возвращает ленивое вычисление , которое будет выполняться только при предоставлении ExecutionContext (либо через неявную область действия, либо явно). Это позволяет реализовать операторы, как описано выше, которые могут управлять тем, когда и как выполняются вычисления.
Если вы уже сталкивались с типами данных IO , ZIO или Task , это может показаться вам знакомым. Основная идея этих типов данных аналогична: записывать асинхронные вычисления как значения с ленивой оценкой и предоставлять богатый набор комбинаторов, формируя набор инструментов параллелизма. Взгляните на эффекты кошек, Monix или ZIO для более подробной информации!
Если вам нужна помощь в навигации по библиотекам функционального программирования Scala, взгляните на эту статью, недавно опубликованную Кшиштофом Атласиком.

Но следите за подписями типов!
Однако использование функций контекста, как описано выше (для захвата ленивых вычислений), имеет один важный недостаток. Поведение может измениться в зависимости от того, предоставляете ли вы сигнатуру типа или нет. Например:
def save(u: User): Executable[Boolean] = ??? дано ExecutionContext = ???
val result1 = save(u)
val result2: Executable[Boolean] = save(u)
result1 будет Future[Boolean] — текущее вычисление. Компилятор будет охотно использовать данный контекст выполнения из текущей области. Однако, поскольку мы добавили тип к result2 , теперь у нас есть (контекстная) функция, которая в конечном итоге создаст Future только при наличии контекста выполнения.
Компилятор также с радостью адаптирует Future[Boolean] в Executable[Boolean] :
val v: Future[Boolean] = ???
val f: Executable[Boolean] = v
даже если это может быть не то, что вы ожидаете — каждый раз, когда контекст выполнения предоставляется f , он возвращает одно и то же (выполняется или завершено) будущее v . Отсюда и создается впечатление, что «овеществленный»
Отсюда и создается впечатление, что «овеществленный» IO / Task /Типы данных ZIO по-прежнему превосходят Future или Executable при описании параллельно выполняемых вычислений.
King от Stanisław Warski
Наш второй пример использования затронет тему, которая часто вызывает споры среди программистов: внедрение зависимостей.
Расширяя наш предыдущий пример, давайте посмотрим на следующий код:
case class User(email: String)class UserModel {
def find(email: String): Option[User] = ???
def save(u: User): Unit = ???
}class UserService(userModel: UserModel) {
def newUser(u: User): Boolean = {
userModel.find(u.email) match {
case 9004 > false
case None =>
userModel.save(u)
true
}
}
}класс Api(userService: UserService) {
val userService(new Boolean =User Results: "x@y.
}
 com"))
com")) Асинхронный аспект ( Future s) здесь опущен, но его можно добавить так же, как и раньше. Мы разделили функциональность между тремя классами:
-
UserModelвзаимодействует с базой данных и предоставляет функциональность для поиска и сохранения экземпляраUser -
UserServiceреализует нашу бизнес-логику, в зависимости отuserModel -
Apiпредоставляет функциональность внешнему миру — здесь не так, как, например. конечная точка HTTP, но в гораздо упрощенной форме прямого вызова.
Обратите внимание, что зависимость между UserService и UserModel hidden . Клиент UserService , который здесь является классом Api , понятия не имеет, какие зависимости есть у службы. Это деталь реализации этого класса.
В реализации отсутствует одна вещь, которую мы добавим: управление транзакциями. Предполагая, что мы работаем с реляционной базой данных, мы хотели бы, чтобы логика, реализованная в
Предполагая, что мы работаем с реляционной базой данных, мы хотели бы, чтобы логика, реализованная в UserService (поиск и условное сохранение) для запуска в одной транзакции.
Есть много подходов, которые мы можем использовать, но мы выберем тот, который является композиционным, не требует фреймворков или манипуляций с байт-кодом и в то же время удобочитаем. Методы в UserModel вернут фрагментов транзакции , которые затем будут объединены внутри UserService в более крупный фрагмент.
Что такое фрагмент транзакции? Это будет любое вычисление, которое нуждается в открытом Connection (предположим, что это соединение с нашей СУБД) и возвращает какое-то значение. Чтобы упростить работу с такими вычислениями — функциями от Connection до некоторого типа T — воспользуемся контекстными функциями:
trait Connection
type Connected[T] = Connection ?=> T class UserModel {
def find(email: String): Connected[Option[User]] = ???
def save(u: User): Connected[Unit] = ???
}class UserService(userModel: UserModel) {
def newUser(u: User): Connected[Boolean] = {
userModel.
case Some(_) = > false
case None =>
userModel.save(u)
true
}
}
}
 find(u.email) match {
find(u.email) match { Обратите внимание, что мы ничего не изменили в реализации — только сигнатуры типов! При вызове, например. userModel.find компилятору нужен данный Соединение — и одно доступно, благодаря типу newUser .
И снова мы имеем дело с ленивыми вычислениями. Здесь они зависят от данного соединения. И снова, если вы работали с библиотеками Scala 2, такими как Doobie или Slick, это может показаться вам знакомым:
Connected[IO[T]] ~= ConnectionIO[T] // doobie
Connected[Future[T]] ~ = DBIOAction[T] // slick
Идея не нова, но мы получаем в свое распоряжение новый мощный инструмент для моделирования вычислений — контекстные функции.
В классе API нам нужен способ устранения зависимости вычислений от Connection . То есть нам нужен способ запуска транзакции. Это может быть захвачено
То есть нам нужен способ запуска транзакции. Это может быть захвачено DB class:
class DB {
def transact[T](f: Connected[T]): T = ???
} class Api(userService: UserService, db: DB) {
val результат: Boolean =
db.transact(userService.newUser(User("[email protected]")))
} Скрытые и явные зависимости
Мы отметили, что UserModel является скрытой зависимостью UserService . С Connected мы используем другой тип: явные зависимости (или, может быть, лучше было бы назвать: контекстные зависимости ). Эти зависимости распространяются на вызывающую сторону. То есть тот, кто использует наш метод, знает о зависимости и должен предоставить ее значение (что может означать распространение зависимости выше по уровню).
Оба типа зависимостей полезны и выполняют разные роли. Конструкторы отлично подходят для реализации «традиционного» внедрения зависимостей, когда зависимости скрыты. Контекстные функции , с другой стороны, можно использовать для простой реализации явных зависимостей.
Контекстные функции , с другой стороны, можно использовать для простой реализации явных зависимостей.
Читательская монада
Еще одно путешествие в мир функционального программирования. Мы уже видели различие между скрытыми и явными/контекстными зависимостями. Это всплыло при сравнении монады чтения и конструкторов для внедрения зависимостей.
Действительно, контекстные функции реализуют монаду чтения на уровне языка. Реализация имеет меньше синтаксических и временных накладных расходов, поэтому ее определенно стоит рассмотреть!
Как мы уже отмечали в начале, контекстные функции могут иметь несколько параметров, и точная форма контекстной функции (с каррированием/без каррирования) и порядок параметров не имеют значения.
Благодаря этому мы можем масштабировать явные зависимости, описанные ранее, чтобы обрабатывать больше зависимостей. Например, предположим, что у нас есть две зависимости, которые мы хотим отслеживать явно и которые необходимо передать вызывающей стороне:
trait Connection
type Connected[T] = Connection ?=> T trait User
type Secure[T] = User ?=> T
Затем мы можем выполнить вычисление, для которого требуются оба из них:
Черта РесурсDef touch(r: Ресурс): Подключено[Безопасный[Устройство]] = ???
touch — это операция, которая является фрагментом транзакции и должна выполняться в контексте вошедшего в систему пользователя.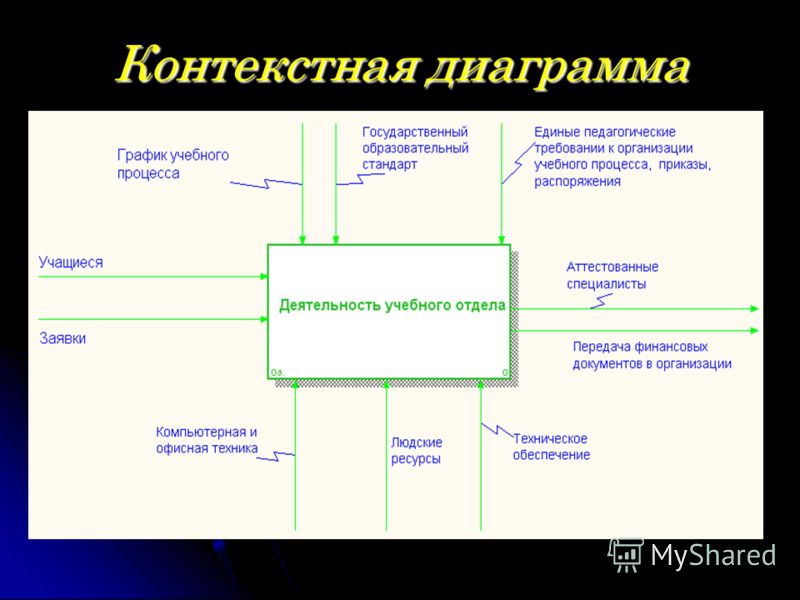 Мы можем устранить внутреннюю зависимость, предоставив заданное значение
Мы можем устранить внутреннюю зависимость, предоставив заданное значение User type:
def update(r: Resource): Connected[Unit] = {
данный User = ???
touch(r)
} Опять же, способ вложения требований Connected и Secure не имеет значения. Следовательно, мы можем вводить и устранять явные зависимости без каких-либо синтаксических издержек.
King от Franciszek Warski
Если вы сегодня используете IO / Task или ZIO , вам может быть интересно, будут ли контекстные функции работать с этими типами данных?
Попробуем! Мы будем использовать те же зависимости, использование которых мы хотим отслеживать, как и раньше. Предположим, у нас есть очень простая реализация монады IO и две программы: одна представляет собой фрагмент транзакции, а другая требует вошедшего в систему пользователя:
case class IO[T](run: () => T) {
def flatMap[U](other: T => IO[U]): IO[U] =
IO(() => other(run()). run())
} val p1: Secure[IO[Int]] = ???
val p2: Connected[IO[String]] = ???  run())
run()) Естественный вопрос — что произойдет, если мы попытаемся скомпоновать эти два вычисления? То есть, что происходит, когда мы flatMap p1 и p2 , или наоборот?
val r1: Secure[Connected[IO[String]]] = p1.flatMap(_ => p2)
val r2: Connected[Secure[IO[String]]] = p1.flatMap(_ = > p2)
Все компилируется просто отлично: требования распространяются на внешний уровень, даже если они используются внутри Функция flatMap .
Обратите внимание, что компилятор не выведет за нас типы для
r1/r2, но проведет нас через сообщения об ошибках, какая зависимость отсутствует. Например, если мы попытаемся ввестиr1: Connected[IO[String]], мы получим (Intотносится к зависимостиp1):
неявный аргумент типа User не найден для параметра Secure[IO[Int]]
Контекстные зависимости и среда ZIO
Последнее упоминание о мире функционального программирования на Scala. Тип данных
Тип данных ZIO[R, E, A] описывает вычисление, которое с учетом среды R выдает либо ошибку E , либо значение A . Звучит похоже — разве среда и контекст не работают одинаково?
В какой-то степени да. Мы могли бы провести следующее сравнение:
ZIO[R, E, A] ~= R ?=> асинхронно Либо[E, A]
Контекстные функции имеют множество преимуществ, предоставляемых средой ZIO: компонуемость, простое устранение зависимостей и введение, низкие синтаксические издержки. У них также есть некоторые преимущества перед ними — зависимости не нужно оборачивать Has[T] , чтобы использовать и представлять несколько зависимостей в одном параметре типа.
Но у них есть и недостатки. Среда ZIO поддерживает эффективное создание зависимостей и безопасное освобождение ресурсов зависимостей (если таковые имеются). Это хорошо интегрируется с остальной частью библиотеки, которая представляет собой набор инструментов для работы с побочными эффектами и параллельными вычислениями.
Можно было бы ввести функциональные возможности безопасности ресурсов в контекстно-функциональный подход через библиотеку. Интересное направление для будущей работы!
Контекстные функции и побочные эффекты
Ранее мы упоминали, что при работе с псевдонимом типа Executable добавление сигнатуры типа может изменить поведение программы. Это действительно может стать препятствием для этой абстракции. А как насчет второго варианта использования, который мы описали, — управления явными зависимостями?
Если рассматриваемая контекстная функция является чистой — то есть ее вызов не имеет побочных эффектов — точный момент, когда мы применяем параметр контекста, не имеет значения. Результат всегда будет одним и тем же (однако это может быть оптимизация, например, вызов функции один раз, а не пару раз).
Обратите внимание, что это исключает наш тип Executable[T] — поскольку это псевдоним для ExecutionContext ?=> Future[T] , применение контекста выполнения является потенциально побочной операцией: новое будущее может быть создан, и вычисления могут быть запущены в фоновом режиме.
С другой стороны, Connected[IO[T]] должна быть чистой функцией: применение открытого соединения с БД даст только лениво оцененное описание вычисления — никаких побочных эффектов быть не должно. Следовательно, функции контекста в сочетании с функциональными эффектами кажутся выигрышной комбинацией.
Контекстные функции — отличное дополнение к системе типов Scala. Они делают язык более регулярным, поскольку теперь точно так же, как обычный метод можно преобразовать в значение функции, то же самое можно сделать и с методом с заданными/неявными параметрами.
Но не только регулярность: контекстные функции открывают двери для новых возможностей абстракции, начиная от правильного представления требований ExecutionContext и заканчивая беспрепятственным распространением контекстных зависимостей и дополнением того, как внедрение зависимостей может быть реализовано с помощью языка Scala.
Кроме того, вероятно, появится еще много способов использования, когда люди начнут ежедневно работать со Scala 3. С нетерпением жду! 🙂
С нетерпением жду! 🙂
Многоликое `this` в javascript | by Michał Witkowski
В этом посте я постараюсь объяснить одну из самых фундаментальных частей JavaScript: контекст выполнения. Если вы часто используете JS-фреймворки, понимание «этого» на первый взгляд может показаться приятным дополнением. Однако, если вы собираетесь серьезно заняться программированием, понимание контекста абсолютно необходимо для того, чтобы стать программистом на JavaScript.
Мы используем это почти так же, как мы используем его в естественном языке. Мы бы скорее написали «Моя мама посинела, это очень беспокоит». вместо «Моя мама посинела. Моя мама, которая синеет, очень беспокоится». Знание контекста этого позволяет нам понять, что нас так беспокоит.
Попробуем как-то связать это с языком программирования. В JavaScript мы используем и как ярлык, ссылку. Он относится к объектам, переменным, и мы используем его в контексте.
Это очень беспокоит, но не бойтесь. Через минуту все станет ясно.
Через минуту все станет ясно.
Что вы подумаете, если кто-то скажет: «Это очень тревожно»? Без какого-либо заметного повода, просто как начало разговора, без контекста и вступления. Скорее всего, вы начнете связывать с этим с чем-то вокруг или с последней ситуацией.
Это происходит с браузером МНОГО. Сотни тысяч разработчиков используют и без контекста. Наш бедный браузер изо всех сил пытается понять это со ссылкой на глобальный объект, окно в этом конкретном примере.
Пример 1
[Веб-браузеры]
Вне любой функции в глобальном контексте выполнения, этот относится к глобальному контексту (окну).
Еще раз обратимся к реальному примеру: контекст функции можно воспринимать как контекст предложения. «Моя мама посинела, это очень беспокоит». Мы использовали это в предложении, поэтому мы знаем, что такое .это означает , но мы можем использовать его и в других предложениях. Например: «Надвигается ураган, это очень беспокоит». Тот же
Например: «Надвигается ураган, это очень беспокоит». Тот же это , но другой контекст и совсем другой смысл.
Контекст в JavaScript связан с объектами. Он относится к объекту внутри выполняемой функции. this относится к объекту, в котором выполняется функция.
Пример 1
this определяется тем, как вызывается функция. Как видите, все вышеперечисленные функции были вызваны в глобальном контексте.
Пример 2
Когда функция вызывается как метод объекта, этот устанавливается для объекта, для которого вызывается метод.
Пример 3
Верно — Мы по-прежнему находимся в глобальном контексте.
Ложь — Функция вызывается как метод объекта.
True — Функция вызывается как метод объекта.
False — Функция вызывается как метод объекта y_obj, поэтому этот является его контекстом.
Пример 4
В строгом режиме правила другие. Контекст остается таким, каким он был установлен. В этом конкретном примере этот не был определен, поэтому он остался неопределенным.
Пример 5
Как и в предыдущем примере, функция вызывается как метод объекта, независимо от того, как она была определена.
Пример 6
этот является динамическим, то есть он может меняться от одного объекта к другому
Пример 7
Мы можем вызвать фрукты с помощью этого и по имени объекта.
Пример 8
Итак, новое изменяет правила. новый оператор создает экземпляр объекта. Контекст функции будет установлен на созданный экземпляр объекта.
Пример из жизни: «Это очень тревожно, моя мама посинела».
Эти методы позволяют выполнять любую функцию в любом желаемом контексте. Давайте посмотрим, как они работают, на примерах.
Пример 1
xo xo — Мы вызвали test в глобальном контексте.
lorem ipsum — Используя вызов, мы вызываем тест в контексте foo.
lorem ipsum — Используя команду apply, мы вызываем тест в контексте foo.
Эти два метода позволяют выполнять функцию в любом желаемом контексте.
apply позволяет вызывать функцию с аргументами в виде массива, тогда как call требует, чтобы параметры были указаны явно.
Пример 2
Не определено — В объекте документа нет переменной.
Не определено — В объекте документа нет переменной. В этой ситуации вызов не может изменить контекст.
15 — Мы создали новый объект {a:15} и в этом контексте вызвали тест.
Метод привязки постоянно устанавливает контекст в указанное значение.
После использования привязки это неизменяемо, даже при вызове вызова, применения или привязки.
Стрелочные функции были представлены как функция в ES6. Их можно рассматривать как очень удобный инструмент. Однако вы должны знать, что стрелочные функции работают иначе, чем обычные функции с точки зрения контекста. Давайте посмотрим.
Пример 1
Когда мы используем стрелочные функции, этот сохраняет значение окружающего лексического контекста.
Пример 2
Обратите внимание на разницу между стрелкой и обычной функцией. Со стрелочной функцией мы находимся в контексте окна.
Мы можем сказать, что:
x => this.y равно function (x) { return this.y }.bind(this)
Стрелочная функция всегда связывала «это» и поэтому не может использоваться в качестве конструктора. Этот последний пример иллюстрирует разницу.
Пример 3
Как только вы узнаете разницу между функцией dynamic и лексической this , дважды подумайте, прежде чем объявлять новую функцию.