Содержание
Что такое кодирование алкоголизма: методы и преимущества
Опубликовано: 31.05.2019
Кодированием называют общую большую группу разнообразных процедур и методик, влияющих на центральную нервную систему человека. После прохождения комплекса, тяга к спиртному заметно уменьшается, зависимый уверен в том, что алкоголь является опасным для его жизни. Наиболее распространенными методами кодирования в Украине является гипнотическое влияние, методика Довженко и иглоукалывание.
В некоторых случаях врачи советуют использовать химические средства: подшивают определенный препарат или химическая защита. В клинике «Брик» лечение алкозависимых строится на результатах проведенных анализов и исследовании общего состояния пациента.
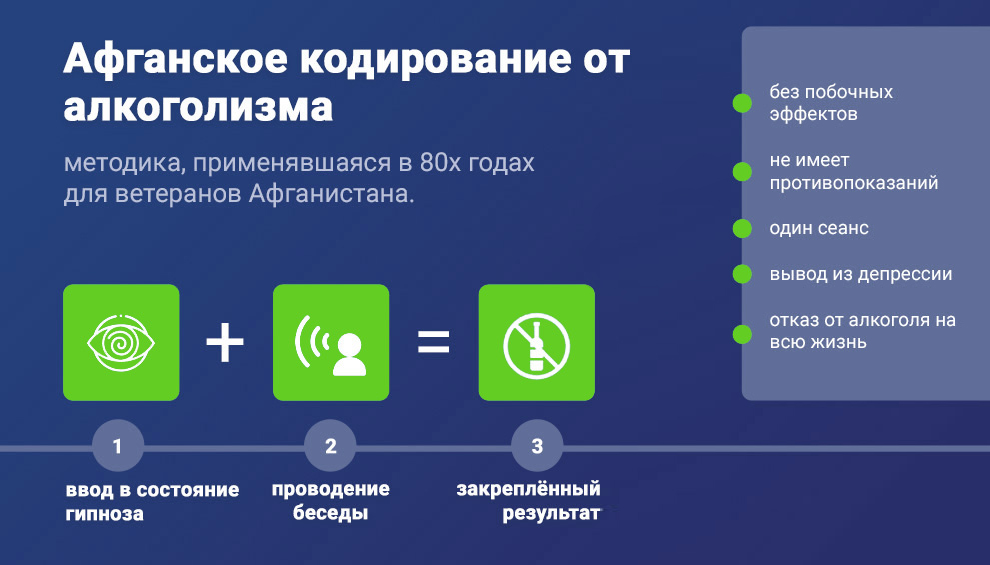
В чем заключается суть метода
Не смотря на то, какой именно вариант был выбран для лечения больного, кодирование и суть процедуры всегда одинакова. Главная задача – стимулировать у человека страх, как он снова начнет употреблять спиртное, то умрет. В организм специалисты вводят определенный медикамент, который имеет довольно долгий действие. Он попадает в кровь, и при появлении алкоголя, смешивается с ним, превращая в яд.
В организм специалисты вводят определенный медикамент, который имеет довольно долгий действие. Он попадает в кровь, и при появлении алкоголя, смешивается с ним, превращая в яд.
Всего за несколько секунд опасная смесь атакует жизненно важные органы, что приводит к серьезным проблемам со здоровьем, а иногда и к смерти. В настоящее время существует два типа кодирования:
- По применению медикаментов. Химическое вещество вводится в организм больного через обычную инъекцию в вену, мышцы или вшивается в виде ампул до мышечных тканей. Перед началом операции врач предупредит зависимого относительно вреда, к которому может привести употребление алкоголя после процедуры.
- С применением гипноза. С задачей хорошо справится проверенный, опытный психолог или психотерапевт. Он вводит человека в гипнотический сон, и складывает в подсознание определенные каноны. Например, при употреблении хотя бы капли спиртных напитков человек тяжело заболеет или умрет.
Специалисты уверяют, что оба методы эффективны, и способны повлиять на зависимого, но большинство пациентов отдают предпочтения первому варианту.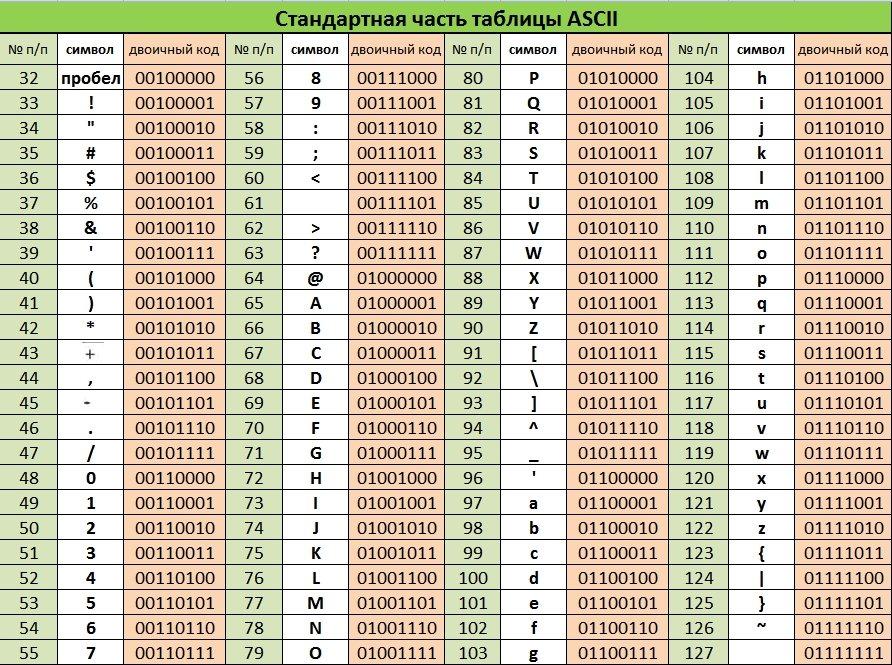 Это объясняется недоверием людей к гипнозу и психологических методов. Существуют ситуации, когда использование медикаментозного кодирования невозможно по состоянию здоровья и противопоказаниями, тогда приходится довериться психологам.
Это объясняется недоверием людей к гипнозу и психологических методов. Существуют ситуации, когда использование медикаментозного кодирования невозможно по состоянию здоровья и противопоказаниями, тогда приходится довериться психологам.
Лечение алкоголизма методом кодирования – преимущества
На протяжении многих лет кодирование успело зарекомендовать себя, как эффективный и надежный метод. С его помощью было спасено множество людей, а реабилитационные центры все время совершенствуют процедуру. Этому помогает развитие инновационных технологий, появление новых средств и медикаментов, научные исследования и открытия. Кроме эффективности, методика имеет и другие преимущества:
- Не требуется долгое лечение в клинике: если человек полностью трезвый, то максимальное количество приемов, потребуется три визита к врачам. Хотя в большинстве случаев достаточно и одного;
- Цена на избавление от зависимости таким путем гораздо ниже, чем при комплексной реабилитации больного;
- Анонимность – большой плюс метода.
 Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома;
Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома; - Отсутствует потребность в отпуске или больничном. Современная клиника Брик идет навстречу клиентам, выбирая удобное для них время.
 Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома;
Пациент не должен сообщать о своей проблеме родственникам или близким, уже через несколько часов он будет дома;На чем базируется методика кодирования
Посещение специалиста – это большой шаг к избавлению от пагубной привычки, но кроме гипноза или медикаментов нужно придерживаться дополнительных правил:
- В течение долгого времени полностью воздерживаться от употребления спиртного, даже в маленьких дозах;
- Изменить образ жизни и круг общения;
- Найти замену алкоголю на психологическом уровне – заняться интересным делом, хобби, найти работу;
- Избавиться от физической зависимости – на пользу пойдут спортивные тренировки, пробежка, прогулки на свежем воздухе перед сном.
С зависимостью надо бороться комплексно, все перечисленные стадии связаны между собой. Врачи берут на себя ответственность за саму процедуру кодирования, дополнительные меры принимает сам пациент.
Что надо знать о кодировании от алкоголя
Эффективный и распространенный метод борьбы с зависимостью имеет определенные особенности, которые нужно принимать во внимание прежде чем прибегать к лечению:
- Запрет употребления спиртного базируется на запугивании человека. Ему угрожают смертью и болезнями. Это отражается на психологическом состоянии, может приводить к депрессивному состоянию, нервозности и агрессивном поведения.
- Процедуру нужно регулярно повторять. Действие медицинских препаратов, что были введены больному, со временем ослабевает. В зависимости от лекарств, продолжительность действия колеблется от трех месяцев до трех лет. Психологический запрет теряет свою силу через определенный период.
- Химические средства могут иметь побочные свойства для некоторых людей.
- Довольно трудно найти настоящего профессионала своего дела, особенно в настоящее время. В клинике «Брик» работают опытные специалисты, готовые оказать комплексную поддержку и помощь больному.
- Эффективность психологического кодирования будет высокой только при условии дальнейшего сотрудничества с психологом. Он должен контролировать состояние пациента, поддерживать его, давать советы и помощь в случае необходимости.
Советы врачей – как вести себя после кодировки
Любые кардинальные изменения в жизни – это всегда стресс для организма. Даже если это изменения в лучшую сторону, нужно поддержать собственное тело в трудный, переходный период. Чтобы сделать отказ от алкоголя не таким сложным заданием, после кодирования нужно:
- Наладить отношения с родными и близкими людьми;
- Заниматься спортом;
- Достаточно спать и отдыхать;
- Ежедневно проводить несколько часов на свежем воздухе;
- Скорректировать режим питания и отказаться от вредной пищи;
- Принимать витамины и минералы для восстановления внутренних органов.
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования.
 Обобщение и детальный разбор / Хабр
Обобщение и детальный разбор / Хабр
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
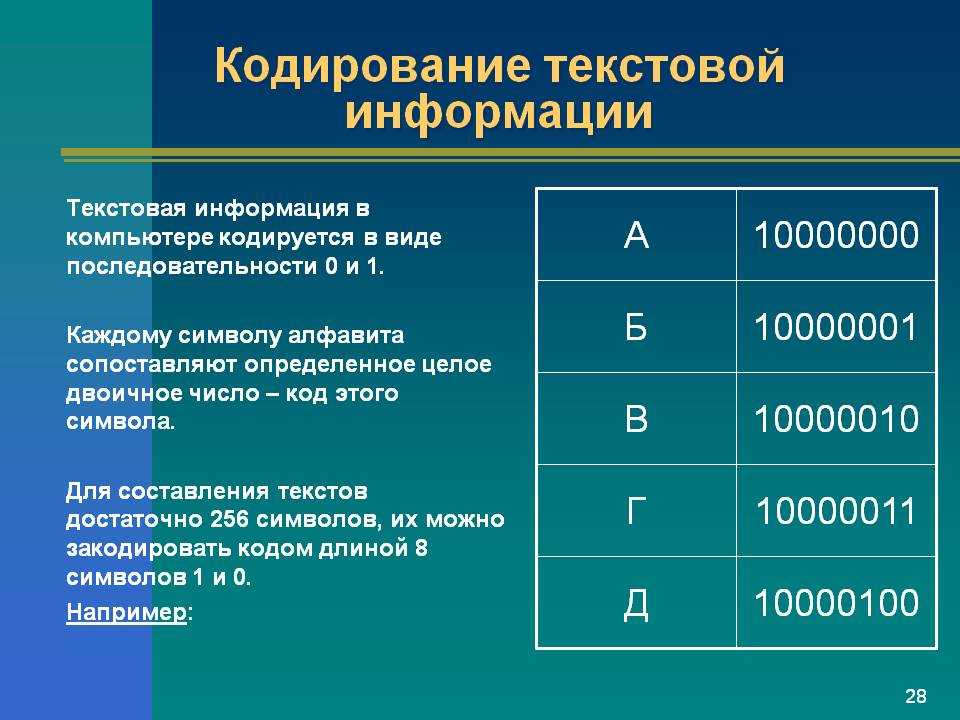
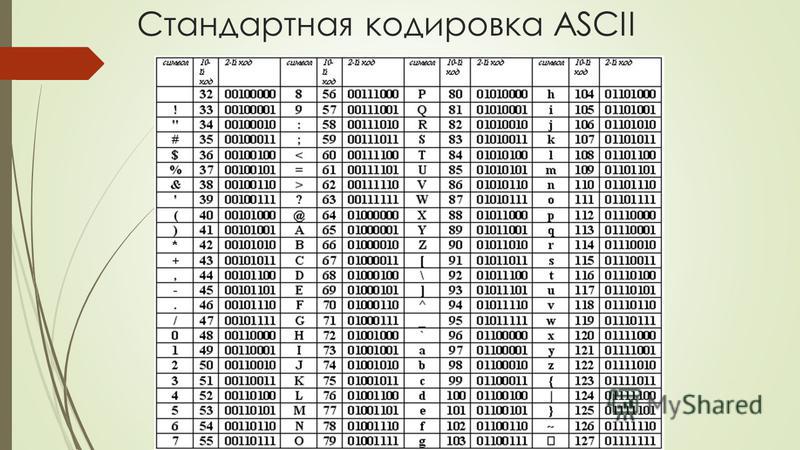
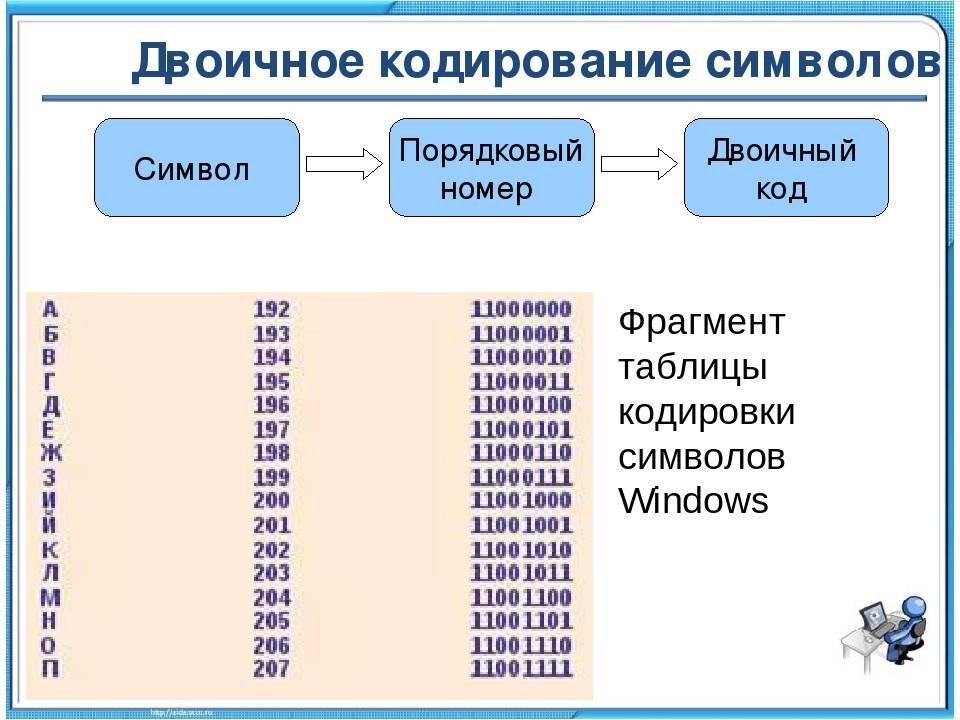
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
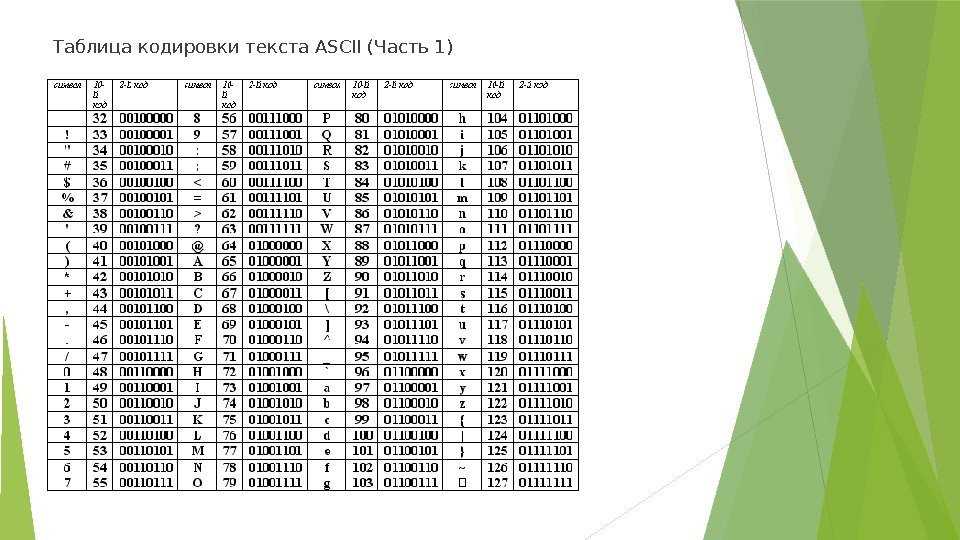
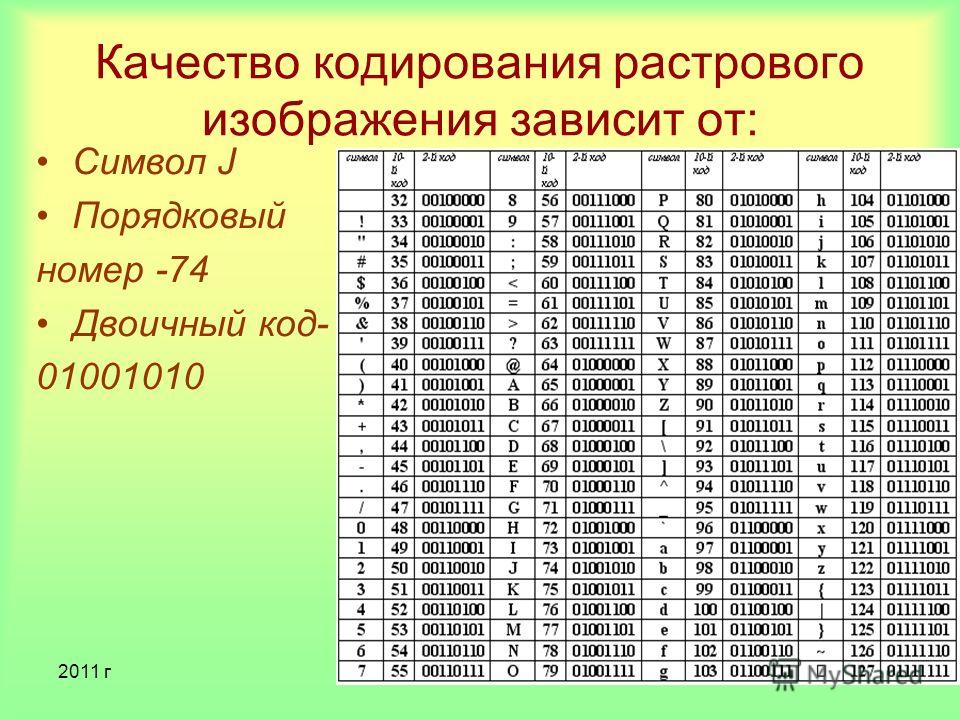
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном.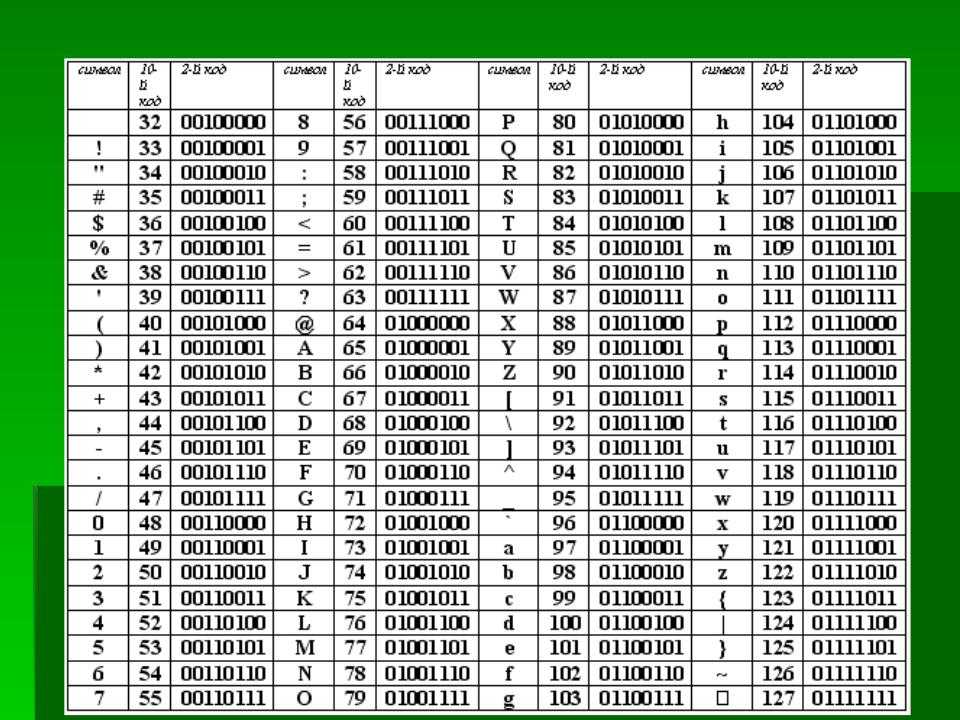 Переведем это в двоичную систему —
Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т. д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.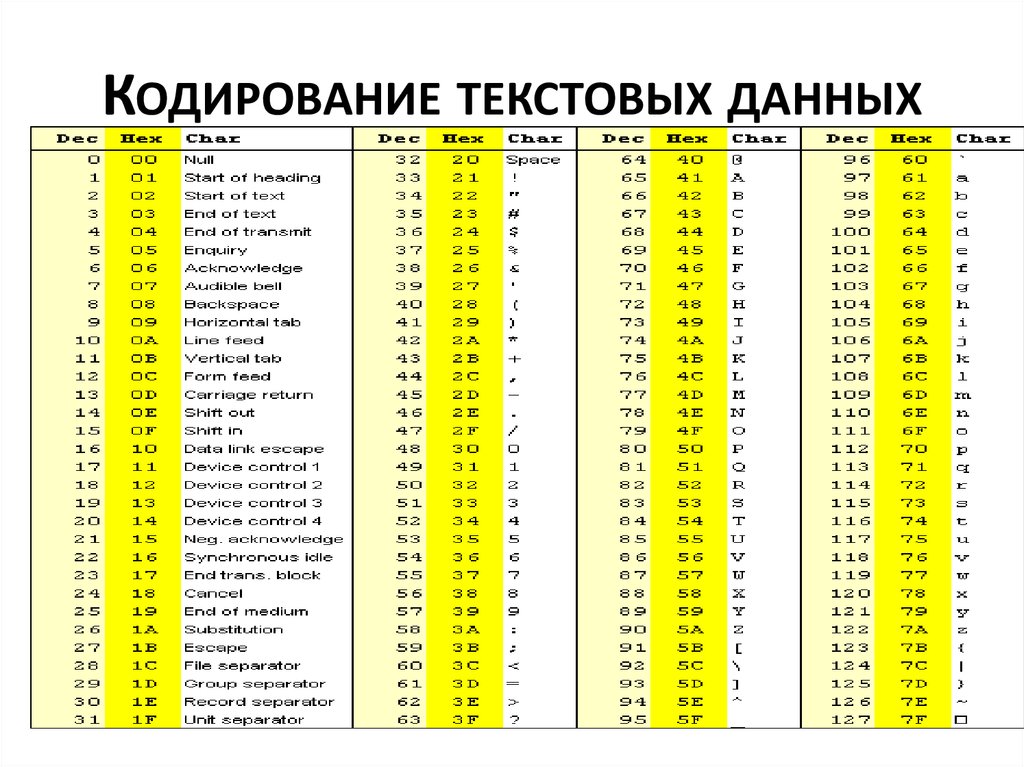
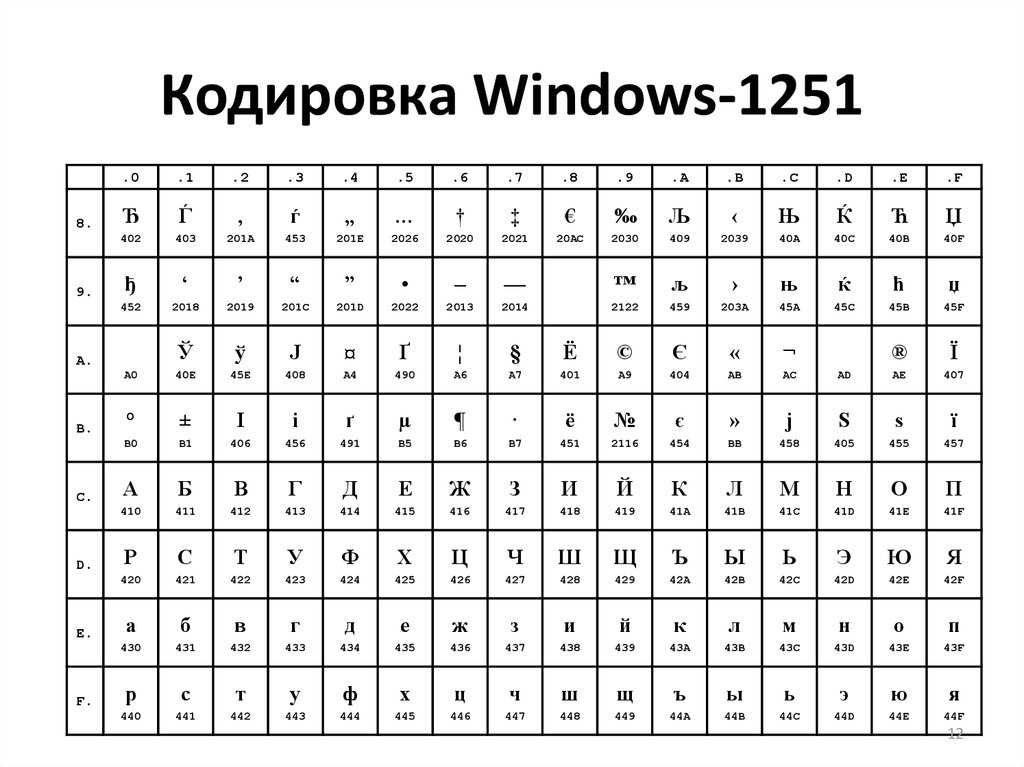
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8.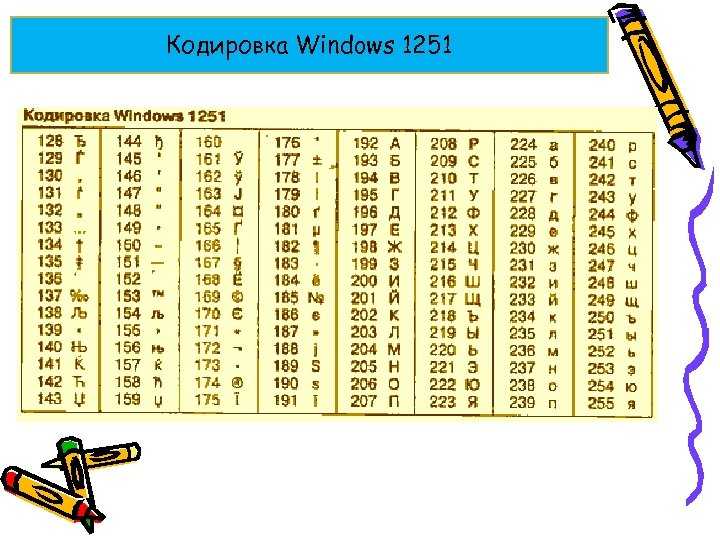 То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
 Компоненты тангутского письма.
Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Что такое кодирование и декодирование?
По
- Эндрю Золя
Что такое кодирование и декодирование в компьютере?
Кодирование и декодирование используются во многих формах связи, включая вычисления, передачу данных, программирование, цифровую электронику и общение между людьми. Эти два процесса включают изменение формата контента для оптимальной передачи или хранения.
Эти два процесса включают изменение формата контента для оптимальной передачи или хранения.
В компьютерах кодирование — это процесс помещения последовательности символов (буквы, цифры, знаки препинания и определенные символы) в специальный формат для эффективной передачи или хранения. Декодирование — это обратный процесс — преобразование закодированного формата обратно в исходную последовательность символов.
Эти термины не следует путать с шифрованием и дешифрованием , которые сосредоточены на сокрытии и защите данных. (Мы можем шифровать данные, не меняя код, или кодировать данные, не скрывая намеренно содержимое.)
Что такое кодирование и декодирование при передаче данных?
Процессы кодирования и декодирования для передачи данных имеют интересное происхождение. Например, азбука Морзе появилась в 1838 году, когда Сэмюэл Морзе создал стандартизированные последовательности сигналов двух длительностей, называемые точек и тире , для использования с телеграфом. Сегодняшние радиолюбители все еще используют Q-сигналы, которые произошли от кодов, созданных Генеральным почтмейстером Великобритании в начале 1900-х годов для облегчения связи между британскими кораблями и береговыми станциями.
Сегодняшние радиолюбители все еще используют Q-сигналы, которые произошли от кодов, созданных Генеральным почтмейстером Великобритании в начале 1900-х годов для облегчения связи между британскими кораблями и береговыми станциями.
Манчестерское кодирование было разработано для хранения данных на магнитных барабанах компьютера Manchester Mark 1, построенного в 1949 году. В этой модели кодирования каждая двоичная цифра или бит кодируется младшим, а затем старшим или высоким, а затем младшим, в течение равного времени. Также известный как фазовое кодирование , манчестерский процесс кодирования используется в потребительских инфракрасных протоколах, радиочастотной идентификации и связи ближнего поля.
Что такое кодирование и декодирование в программировании?
Доступ в Интернет зависит от кодировки. Унифицированный указатель ресурса (URL), адрес веб-страницы, может быть отправлен через Интернет только с использованием Американского стандартного кода для обмена информацией (ASCII), который является кодом, используемым для текстовых файлов в вычислениях.
Унифицированный указатель ресурса (URL), адрес веб-страницы, может быть отправлен через Интернет только с использованием Американского стандартного кода для обмена информацией (ASCII), который является кодом, используемым для текстовых файлов в вычислениях.
Вот пример кодировки ASCII для строки
В файле ASCII 7-битное двоичное число представляет каждый символ, который может быть прописными или строчными буквами, цифрами, знаками препинания и другими распространенными символами. Однако URL-адреса не могут содержать пробелы и часто содержат символы, не входящие в набор символов ASCII. Кодировка URL, также называемая процентное кодирование решает эту проблему путем преобразования пробелов — в знак + или с %20 — и символов, отличных от ASCII, в допустимый формат ASCII.
Другие часто используемые коды в программировании включают BinHex, многоцелевые расширения почты Интернета, Unicode и Uuencode.
Ниже перечислены некоторые способы кодирования и декодирования в различных языках программирования.
В Java
Кодирование и декодирование в Java — это метод представления данных в другом формате для эффективной передачи информации через сеть или Интернет. Кодер преобразует данные в веб-представление. После получения декодер преобразует данные веб-представления в исходный формат.
В Питоне
В языке программирования Python кодировка представляет строку Unicode как строку байтов. Обычно это происходит, когда вы передаете экземпляр по сети или сохраняете его в файл на диске. Декодирование преобразует строку байтов в строку Unicode. Это происходит, когда вы получаете строку байтов из файла на диске или из сети.
В Свифте
В языке программирования Apple Swift модели кодирования и декодирования обычно представляют собой сериализацию данных объекта из строкового формата нотации объектов JavaScript. В этом случае кодирование представляет собой сериализацию, а декодирование — десериализацию. Всякий раз, когда вы сериализуете данные, вы конвертируете их в легко переносимый формат. После транспортировки он преобразуется обратно в исходный формат. Этот подход стандартизирует протокол и обеспечивает взаимодействие между различными языками программирования и платформами.
После транспортировки он преобразуется обратно в исходный формат. Этот подход стандартизирует протокол и обеспечивает взаимодействие между различными языками программирования и платформами.
Что такое кодирование и декодирование в цифровой электронике?
В электронике термины , кодирование, и , декодирование, относятся к аналого-цифровому преобразованию и цифро-аналоговому преобразованию. Эти термины могут применяться к любой форме данных, включая текст, изображения, аудио, видео, мультимедиа и программное обеспечение, а также к сигналам в датчиках, телеметрии и системах управления.
Что такое кодирование и декодирование в человеческом общении?
Люди не думают об этом как о процессе кодирования или декодирования, но человеческое общение начинается, когда отправитель формулирует (кодирует) сообщение. Они выбирают сообщение, которое будут передавать, и канал связи. Люди делают это каждый день, мало задумываясь о процессе кодирования.
Получатель должен понять (декодировать) сообщение, выведя значение слов и фраз, чтобы правильно интерпретировать сообщение. Затем они могут предоставить обратную связь отправителю.
И отправитель, и получатель в любом процессе связи должны иметь дело с шумом, который может помешать процессу связи. Шум включает в себя различные способы, которыми сообщения прерываются, искажаются или задерживаются. Они могут включать реальный физиологический шум, технические проблемы или семантические, психологические и культурные проблемы, которые мешают общению.
Кодирование и декодирование являются неотъемлемой частью любого обмена данными.
Эти процессы происходят почти мгновенно в любой из этих трех моделей:
- Модель трансмиссии. Эта модель связи представляет собой линейный процесс, в котором отправитель передает сообщение получателю.
- Модель взаимодействия. В этой модели участники по очереди являются отправителями и получателями.
- Модель транзакции. Здесь коммуникаторы генерируют социальные реалии в культурном, реляционном и социальном контекстах. Они общаются, чтобы создавать отношения, взаимодействовать с сообществами и формировать межкультурные союзы. В этой модели участники помечены как коммуникаторы , а не отправители и получатели.
Расшифровка сообщений на вашем родном языке не требует усилий. Однако, когда язык незнаком, получателю может понадобиться переводчик или такие инструменты, как Google Translate, для расшифровки сообщения.
Помимо основ кодирования и декодирования, возможности машинного перевода значительно продвинулись в последнее время. Узнайте больше о технологиях и инструментах машинного перевода .
Последнее обновление: июль 2021 г.
Продолжить чтение О кодировании и декодировании
- 5 основных языков программирования для специалистов по кибербезопасности
- Учебник по хранению данных ДНК и возможному использованию
- 2 метода обработки данных для лучшего машинного обучения
- Разработчики, позаботьтесь об изображении для бесплатного кодека изображений JPEG XL
- 10 лучших языков программирования для изучения
Копать глубже в сетевой инфраструктуре
кусочек
Автор: Роберт Шелдон
Расширенный текстовый формат (RTF)
Автор: Кэти Террелл Ханна
двоичный
Автор: Рахул Авати
кодек
Автор: Александр Гиллис
ПоискЕдиные Коммуникации
-
Как подойти к интеграции Webex-Teams и заставить ее работатьCisco и Microsoft наконец устраняют барьеры взаимодействия между приложениями Webex и Teams.
Компании смогут … -
Услуги Carrier UCaaS расширяют преимущества облачной связиUCaaS становится все более популярным, поскольку операторы связи предоставляют пользователям более сложные и интегрированные пакеты. Узнайте, почему это может сделать …
-
Видео Zoom, предложения UCaaS приближаются к Teams, WebexZoom представила множество функций для своей платформы UCaaS на Zoomtopia, включая службы почты и календаря, а также неформальный …
 Компании смогут …
Компании смогут …SearchMobileComputing
-
Вопросы и ответы Jamf: как упрощенная регистрация BYOD помогает ИТ-специалистам и пользователямРуководители Jamf на JNUC 2022 делятся своим видением будущего с упрощенной регистрацией BYOD и ролью iPhone в …
-
Jamf приобретет ZecOps для повышения безопасности iOSJamf заплатит нераскрытую сумму за ZecOps, который регистрирует активность на устройствах iOS для выявления потенциальных атак.
Компании ожидают … -
Apple преследует растущий премиальный рынок с iPhone 14Apple переключила свое внимание на смартфоны премиум-класса в новейшей линейке iPhone 14 с такими функциями, как режим блокировки, который IT …
 Компании ожидают …
Компании ожидают …SearchDataCenter
-
Недорогие суперкомпьютеры HPE нацелены на рынок искусственного интеллектаHPE выпускает недорогие суперкомпьютеры, предназначенные для обработки сложных рабочих нагрузок на основе ИИ. Dell надеется встретиться со своим давним конкурентом в …
-
Серверы Dell PowerEdge следующего поколения предназначены для рабочих нагрузок HPCПоследнее поколение серверов Dell PowerEdge, оснащенное процессором AMD EPYC, в два раза быстрее, чем предыдущее поколение, с …
-
Включите VXLAN в центры обработки данных для повышения скорости сети
СетиVXLAN обеспечивают изоляцию сети и позволяют организациям более эффективно масштабировать сети центров обработки данных.
Рассмотрите VXLAN для расширения…
 Рассмотрите VXLAN для расширения…
Рассмотрите VXLAN для расширения…SearchITChannel
-
Платформы MSP демонстрируют устойчивость по мере роста стоимостиИнтерес к управляемым услугам как к инвестиционной возможности сохраняется, поскольку на рынок выходят более крупные фонды прямых инвестиций в поисках …
-
Партнерская экосистема VMware задействована для ускорения облачных проектовVMware расширяет связи с глобальными системными интеграторами и другими партнерами, поскольку ищет ресурсы, которые помогут клиентам повысить …
-
Облачная экономика остывает, но сделки с ИТ-услугами продолжаютсяОсторожные расходы клиентов замедляют рост более широкого рынка облачных вычислений. Но поставщики ИТ-услуг продолжают заниматься слияниями и поглощениями для…
Что такое кодирование? — Определение Techslang
Кодирование — это процесс преобразования данных в другой формат. Когда вы конвертируете показания температуры из градусов Цельсия в градусы Фаренгейта или деньги из японских иен в доллары США, исходные значения остаются прежними. Они просто представлены в другой форме.
Когда вы конвертируете показания температуры из градусов Цельсия в градусы Фаренгейта или деньги из японских иен в доллары США, исходные значения остаются прежними. Они просто представлены в другой форме.
В мире компьютеров кодирование работает точно так же. Компьютер преобразует данные из одной формы в другую. Это делается для экономии места для хранения или повышения эффективности передачи.
Одним из примеров кодирования является преобразование огромного аудиофайла .WAV в крошечный файл .MP3, который можно легко отправить другу по электронной почте. Файлы закодированы в разных форматах, но будут воспроизводить одну и ту же песню.
Другие интересные термины…
- Что такое декодирование?
- Что такое цифровизация?
Что такое Назначение Кодирование ?
Основной целью кодирования является обеспечение безопасного и адекватного использования данных различными пользователями, использующими различные системы. Идея состоит в том, чтобы сделать данные читаемыми и доступными для всех возможных конечных пользователей. Этот процесс можно сравнить с эффективным переводом текста, например, с иврита на английский, что делает информацию доступной для большего числа пользователей.
Идея состоит в том, чтобы сделать данные читаемыми и доступными для всех возможных конечных пользователей. Этот процесс можно сравнить с эффективным переводом текста, например, с иврита на английский, что делает информацию доступной для большего числа пользователей.
Без кодировки символов веб-сайт будет отображать текст совсем не так, как предполагалось. Неправильное кодирование ухудшает читабельность текста, что также может привести к тому, что поисковые системы не смогут правильно отображать данные или что машины будут неправильно обрабатывать вводимые данные.
Какие существуют типы стандартов кодирования?
Американский стандартный код для обмена информацией
Американский стандартный код для обмена информацией (ASCII) является наиболее часто используемым языком компьютеров для текстовых файлов. Он был разработан Американским национальным институтом стандартов (ANSI). Он представляет буквы алфавита (как строчные, так и прописные), цифры, символы и знаки препинания с использованием семибитных двоичных чисел (строки, состоящие из комбинаций семи нулей или единиц). ASCII имеет 128 символов.
ASCII имеет 128 символов.
Кодировка Unicode
Стандарт Unicode — это универсальный набор символов, позволяющий писать на большинстве языков на компьютерах. Он подразделяется на 8-, 16- и 32-битные наборы символов, насчитывающие более миллиарда символов.
Кодирование URL-адресов
Кодирование унифицированного указателя ресурсов (URL), также известное как «процентное кодирование», часто используется, когда некоторые символы не могут быть включены в URL-адреса. Таким образом, кодирование URL-адресов позволяет представлять нераспознанные символы ASCII в формате Unicode, чтобы все компьютеры могли их читать.
Кодировка Base64
Раньше Base64 использовался только для представления двоичных данных в печатных символах. Он обычно используется в базовой аутентификации по протоколу передачи гипертекста (HTTP) при кодировании учетных данных пользователя. Он также используется для кодирования вложений электронной почты, чтобы обеспечить их передачу по простому протоколу передачи почты (SMTP), и отправки двоичных данных в файлах cookie, чтобы сделать их менее читаемыми для злоумышленников.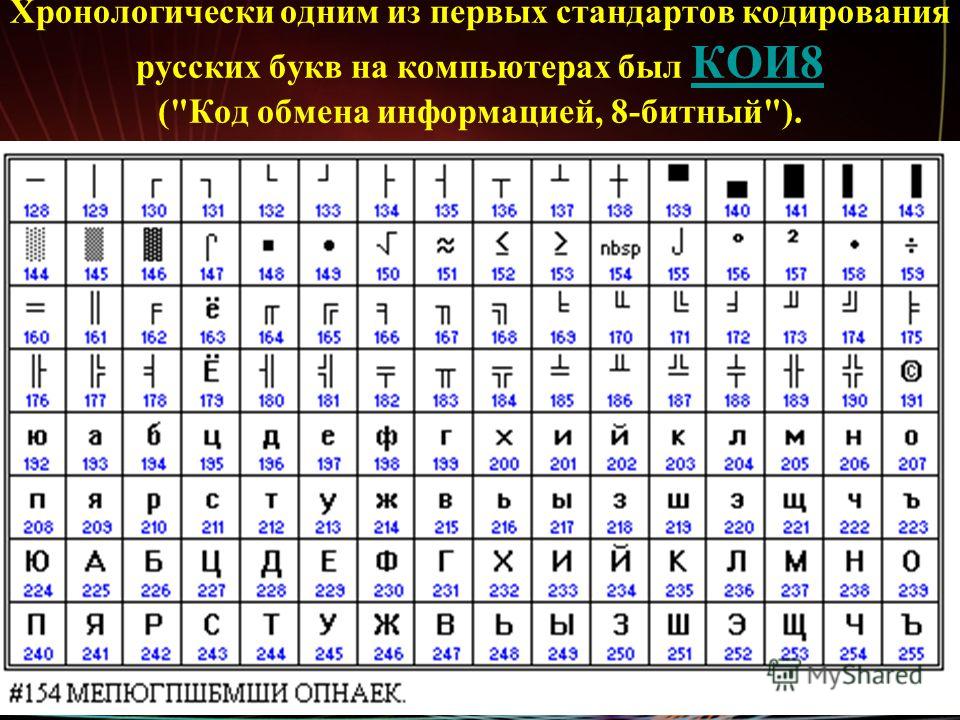
Большинство почтовых систем не могут работать с двоичными данными. Без кодировки Base64 изображения или другие отправленные файлы будут повреждены. Компьютеры работают с данными в байтах, что делает кодировку ASCII непригодной для передачи.
В чем разница между кодированием и декодированием?
Кодирование означает преобразование данных в другую форму, а декодирование — обратное преобразование данных в исходную форму.
Для компьютеров процесс кодирования происходит каждый раз, когда вы сохраняете файл. Поскольку они могут понимать только последовательности нулей и единиц, ваши файлы преобразуются в такой формат. Когда вы просматриваете файл, компьютер декодирует его обратно в исходный формат, чтобы сделать файл удобочитаемым.
Что такое кодирование в человеческом общении?
Этот процесс настолько естественен в человеческом общении, что мы редко обращаем на него внимание. Тем не менее, кодирование происходит каждый раз, когда мы формулируем сообщение, будь то голосовое или цифровое. Когда вы набираете текстовое сообщение для друга, кодирование происходит, когда вы думаете о том, как сформулировать сообщение.
Когда вы набираете текстовое сообщение для друга, кодирование происходит, когда вы думаете о том, как сформулировать сообщение.
Когда ваш друг получает сообщение, он или она пытается понять его смысл. По сути, он или она расшифровывает сообщение.
Что такое кодирование при передаче данных?
Кодирование при передаче данных — это процесс преобразования данных в цифровые сигналы или значения, понятные компьютерам. Как упоминалось ранее, это последовательности двоичных цифр, значение которых может быть только 0 или 1.
Что такое кодирование в программировании?
Кодирование в программировании — это важнейший процесс преобразования данных в различные форматы для облегчения их передачи по сети. Процесс может отличаться в зависимости от языка программирования.
Например, кодирование в Python происходит при передаче экземпляра по сети. С другой стороны, кодирование в Java происходит при передаче данных через Интернет.