Содержание
Что такое кластерный анализ? | Основы торговли по кластерам
Кластер — это цена актива в определенный промежуток времени, на котором совершались сделки. Результирующий объём покупок и продаж указан цифрой внутри кластера. Бар любого ТФ вмещает в себя ,как правило, несколько кластеров. Это позволяет детально видеть объемы покупок, продаж и их баланс в каждом отдельном баре, по каждому ценовому уровню.
Рис. 1 Построение кластерного графика
Изменение цены одного актива, неизбежно влечёт за собой цепочку ценовых движений и на других инструментах. В большинстве случаев понимание трендового движения происходит уже в тот момент, когда оно бурно развивается, и вход в рынок по тренду чреват попаданием в коррекционную волну. Для успешных сделок необходимо понимать текущую ситуацию и уметь предвидеть будущие ценовые движения. Этому можно научиться, анализируя график кластеров.
С помощью кластерного анализа можно видеть активность участников рынка внутри даже самого маленького ценового бара. Это наиболее точный и детальный анализ, так как показывает точечное распределение объёмов сделок по каждому ценовому уровню актива.
Это наиболее точный и детальный анализ, так как показывает точечное распределение объёмов сделок по каждому ценовому уровню актива.
На рынке постоянно идёт противоборство интересов продавцов и покупателей. И каждое самое маленькое движение цены (тик), является тем ходом к компромиссу – ценовому уровню — который в данный момент устраивает обе стороны.
Но рынок динамичен, количество продавцов и покупателей непрерывно изменяется. Если в один момент времени на рынке доминировали продавцы, то в следующий момент, вероятнее всего, будут покупатели. Не одинаковым оказывается и количество совершённых сделок на соседних ценовых уровнях. И всё же сначала рыночная ситуация отражается на суммарных объёмах сделок, а уж затем на цене.
Если видеть действия доминирующих участников рынка (продавцов или покупателей), то можно предсказывать и само движение цены.
Для успешного применения кластерного анализа прежде всего следует понять, что такое кластер и дельта. Кластером называют ценовое движение, которое разбито на уровни, на которых совершались сделки с известными объёмами. Дельта показывает разницу между покупками и продажами, происходящими в каждом кластере.
Кластером называют ценовое движение, которое разбито на уровни, на которых совершались сделки с известными объёмами. Дельта показывает разницу между покупками и продажами, происходящими в каждом кластере.
Рис. 2 Кластерный график
Каждый кластер, или группа дельт, позволяет разобраться в том, покупатели или продавцы преобладают на рынке в данный момент времени. Достаточно лишь подсчитать общую дельту, просуммировав продажи и покупки. Если дельта отрицательна, то рынок перепродан, на нём избыточными являются сделки на продажу. Когда же дельта положительна, то на рынке явно доминируют покупатели.
Сама дельта может принимать нормальное или критическое значение. Значение объёма дельты сверх нормального в кластере выделяют красным цветом.
Если дельта умеренна, то это характеризует флетовое состояние на рынке. При нормальном значении дельты на рынке наблюдается трендовое движение, а вот критическое значение всегда является предвестником разворота цены.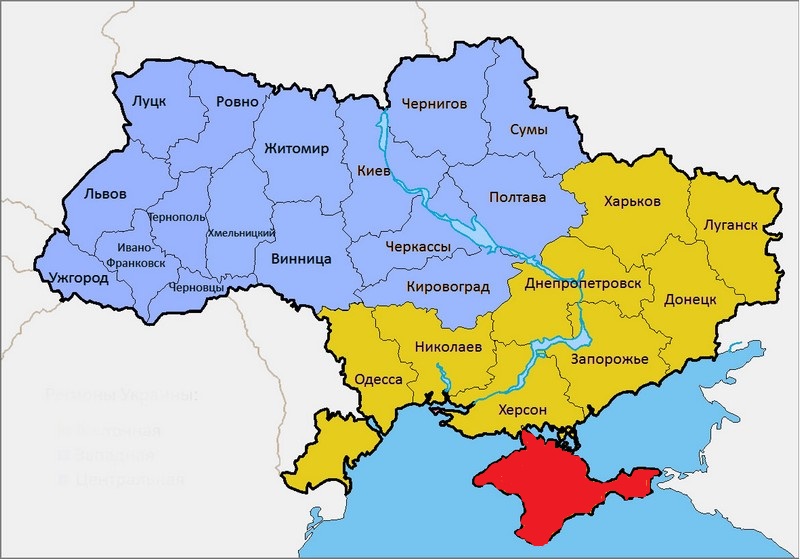
Торговля с помощью кластерного анализа
Для получения максимальной прибыли нужно уметь определить переход дельты из умеренного уровня в нормальный. Ведь в этом случае можно заметить само начало перехода от флета к трендовому движению и суметь получить наибольшую прибыль.
Более наглядным является кластерный график на нём можно увидеть значимые уровни накопления и распределения объемов, построить уровни поддержки и сопротивления. Это позволяет трейдеру найти точный вход в сделку.
Используя дельту, можно судить о преобладании на рынке продаж или покупок. Кластерный анализ позволяет наблюдать сделки и отслеживать их объёмы внутри бара любого ТФ. Особо это важно при подходе к значимым уровням поддержки или сопротивления. Суждения по кластерам — ключ к пониманию рынка.Видео о настройке и торговле в ATAS по кластерам (футпринт).
0 ответы
Ответить
Хотите присоединиться к обсуждению?
Не стесняйтесь вносить свой вклад!
© Copyright — Atas. Net | API | Custom indicators
Net | API | Custom indicators
DISCLAIMER: Trading on the financial markets is often accompanied by a high level of risk. The product of our company is the software that gives an opportunity to get additional data for market analysis. The client, in turn, uses the data at his/her own discretion. Any information provided on this site is for informative purposes only and not to be construed as a recommendation for trading operations.
Восстановить пароль
Вы соглашаетесь
Вам на почту отправлено письмо с инструкциями по восстановлению пароля
Your Registration was successful. The login credentials have been sent to your e-mail.
You already have access to the ATAS platform. Please use credentials provided you previously
You already have full access to the ATAS platform which supports this combine
Кластерный анализ
Кластерный анализ
Кластерный анализ
- Основная цель
- Проверка статистической
значимости - Области применения
- Объединение (древовидная
кластеризация)- Иерархическое дерево
- Меры расстояния
- Правила объединения или связи
- Двувходовое объединение
- Вводный обзор
- Двувходовое объединение
- Метод K средних
- Пример
- Вычисления
- Интерпретация результатов
Основная цель
Термин кластерный анализ (впервые ввел Tryon,
1939) в действительности включает в себя набор
различных алгоритмов
классификации. Общий вопрос, задаваемый
Общий вопрос, задаваемый
исследователями во многих областях, состоит в
том, как организовать наблюдаемые данные в
наглядные структуры, т.е. развернуть таксономии.
Например, биологи ставят цель разбить животных
на различные виды, чтобы содержательно описать
различия между ними. В соответствии с
современной системой, принятой в биологии,
человек принадлежит к приматам, млекопитающим,
амниотам, позвоночным и животным. Заметьте, что в
этой классификации, чем выше уровень агрегации,
тем меньше сходства между членами в
соответствующем классе. Человек имеет больше
сходства с другими приматами (т.е. с обезьянами),
чем с «отдаленными» членами семейства
млекопитающих (например, собаками) и т.д. В
последующих разделах будут рассмотрены общие
методы кластерного анализа, см. Объединение
(древовидная кластеризация), Двувходовое
объединение и Метод K средних.
Проверка
статистической значимости
Заметим, что предыдущие рассуждения ссылаются
на алгоритмы кластеризации, но ничего не
упоминают о проверке статистической значимости.
Фактически, кластерный анализ является не
столько обычным статистическим методом, сколько
«набором» различных алгоритмов
«распределения объектов по кластерам».
Существует точка зрения, что в отличие от многих
других статистических процедур, методы
кластерного анализа используются в большинстве
случаев тогда, когда вы не имеете каких-либо
априорных гипотез относительно классов, но все
еще находитесь в описательной стадии
исследования. Следует понимать, что кластерный
анализ определяет «наиболее возможно значимое
решение». Поэтому проверка статистической
значимости в действительности здесь
неприменима, даже в случаях, когда известны
p-уровни (как, например, в методе K
средних).
Области применения
Техника кластеризации применяется в самых
разнообразных областях. Хартиган (Hartigan, 1975) дал
прекрасный обзор многих опубликованных
исследований, содержащих результаты, полученные
методами кластерного анализа. Например, в
Например, в
области медицины кластеризация заболеваний,
лечения заболеваний или симптомов заболеваний
приводит к широко используемым таксономиям. В
области психиатрии правильная диагностика
кластеров симптомов, таких как паранойя,
шизофрения и т.д., является решающей для успешной
терапии. В археологии с помощью кластерного
анализа исследователи пытаются установить
таксономии каменных орудий, похоронных объектов
и т.д. Известны широкие применения кластерного
анализа в маркетинговых исследованиях. В общем,
всякий раз, когда необходимо классифицировать
«горы» информации к пригодным для
дальнейшей обработки группам, кластерный анализ
оказывается весьма полезным и эффективным.
| В начало |
Объединение
(древовидная кластеризация)
- Иерархическое дерево
- Меры расстояния
- Правила объединения или связи
Общая логика
Приведенный в разделе Основная
цель пример поясняет цель алгоритма
объединения (древовидной кластеризации).
Назначение этого алгоритма
состоит в объединении объектов (например,
животных) в достаточно большие кластеры,
используя некоторую меру сходства или
расстояние между объектами. Типичным
результатом такой кластеризации является
иерархическое дерево.
Иерархическое дерево
Рассмотрим горизонтальную древовидную
диаграмму. Диаграмма начинается с каждого
объекта в классе (в левой части диаграммы). Теперь
представим себе, что постепенно (очень малыми
шагами) вы «ослабляете» ваш критерий о том,
какие объекты являются уникальными, а какие нет.
Другими словами, вы понижаете порог, относящийся
к решению об объединении двух или более объектов
в один кластер.
В результате, вы связываете вместе всё
большее и большее число объектов и агрегируете (объединяете)
все больше и больше кластеров, состоящих из все
сильнее различающихся элементов. Окончательно,
Окончательно,
на последнем шаге все объекты объединяются
вместе. На этих диаграммах горизонтальные оси
представляют расстояние объединения (в вертикальных
древовидных диаграммах вертикальные оси
представляют расстояние объединения). Так, для
каждого узла в графе (там, где формируется новый
кластер) вы можете видеть величину расстояния,
для которого соответствующие элементы
связываются в новый единственный кластер. Когда
данные имеют ясную «структуру» в терминах
кластеров объектов, сходных между собой, тогда
эта структура, скорее всего, должна быть отражена
в иерархическом дереве различными ветвями. В
результате успешного анализа методом
объединения появляется возможность обнаружить
кластеры (ветви) и интерпретировать их.
Меры расстояния
Объединение или метод древовидной
кластеризации используется при формировании
кластеров несходства или расстояния между
объектами. Эти расстояния могут определяться в
Эти расстояния могут определяться в
одномерном или многомерном пространстве.
Например, если вы должны кластеризовать типы еды
в кафе, то можете принять во внимание количество
содержащихся в ней калорий, цену, субъективную
оценку вкуса и т.д. Наиболее прямой путь
вычисления расстояний между объектами в
многомерном пространстве состоит в вычислении
евклидовых расстояний. Если вы имеете двух- или
трёхмерное пространство, то эта мера является
реальным геометрическим расстоянием между
объектами в пространстве (как будто расстояния
между объектами измерены рулеткой). Однако
алгоритм объединения не «заботится» о том,
являются ли «предоставленные» для этого
расстояния настоящими или некоторыми другими
производными мерами расстояния, что более
значимо для исследователя; и задачей
исследователей является подобрать правильный
метод для специфических применений.
Евклидово расстояние. Это, по-видимому,
Это, по-видимому,
наиболее общий тип расстояния. Оно попросту
является геометрическим расстоянием в
многомерном пространстве и вычисляется
следующим образом:
расстояние(x,y) = {i (xi — yi)2 }1/2
Заметим, что евклидово расстояние (и его
квадрат) вычисляется по исходным, а не по
стандартизованным данным. Это обычный способ его
вычисления, который имеет определенные
преимущества (например, расстояние между двумя
объектами не изменяется при введении в анализ
нового объекта, который может оказаться
выбросом). Тем не менее, на расстояния могут
сильно влиять различия между осями, по
координатам которых вычисляются эти расстояния.
К примеру, если одна из осей измерена в
сантиметрах, а вы потом переведете ее в
миллиметры (умножая значения на 10), то
окончательное евклидово расстояние (или квадрат
евклидова расстояния), вычисляемое по
координатам, сильно изменится, и, как следствие,
результаты кластерного анализа могут сильно
отличаться от предыдущих.
Квадрат евклидова расстояния. Иногда может
возникнуть желание возвести в квадрат
стандартное евклидово расстояние, чтобы придать
большие веса более отдаленным друг от друга
объектам. Это расстояние вычисляется следующим
образом (см. также замечания в предыдущем пункте):
расстояние(x,y) = i (xi — yi)2
Расстояние городских кварталов
(манхэттенское расстояние). Это расстояние
является просто средним разностей по
координатам. В большинстве случаев эта мера
расстояния приводит к таким же результатам, как и
для обычного расстояния Евклида. Однако отметим,
что для этой меры влияние отдельных больших
разностей (выбросов) уменьшается (так как они не
возводятся в квадрат). Манхэттенское расстояние
вычисляется по формуле:
расстояние(x,y) = i |xi — yi|
Расстояние Чебышева. Это расстояние может
Это расстояние может
оказаться полезным, когда желают определить два
объекта как «различные», если они
различаются по какой-либо одной координате
(каким-либо одним измерением). Расстояние
Чебышева вычисляется по формуле:
расстояние(x,y) = Максимум|xi — yi|
Степенное расстояние. Иногда желают
прогрессивно увеличить или уменьшить вес,
относящийся к размерности, для которой
соответствующие объекты сильно отличаются. Это
может быть достигнуто с использованием
степенного расстояния. Степенное расстояние
вычисляется по формуле:
расстояние(x,y) = (i |xi — yi|p)1/r
где r и p — параметры,
определяемые пользователем. Несколько примеров
вычислений могут показать, как «работает»
эта мера. Параметр p
ответственен за постепенное взвешивание
разностей по отдельным координатам, параметр r ответственен за прогрессивное
взвешивание больших расстояний между объектами.
Если оба параметра — r и p, равны двум, то это расстояние
совпадает с расстоянием Евклида.
Процент несогласия. Эта мера используется в
тех случаях, когда данные являются
категориальными. Это расстояние вычисляется по
формуле:
расстояние(x,y) = (Количество xi yi)/ i
Правила объединения
или связи
На первом шаге, когда каждый объект
представляет собой отдельный кластер,
расстояния между этими объектами определяются
выбранной мерой. Однако когда связываются вместе
несколько объектов, возникает вопрос, как
следует определить расстояния между кластерами?
Другими словами, необходимо правило объединения
или связи для двух кластеров. Здесь имеются
различные возможности: например, вы можете
связать два кластера вместе, когда любые два
объекта в двух кластерах ближе друг к другу, чем
соответствующее расстояние связи. Другими
Другими
словами, вы используете «правило ближайшего
соседа» для определения расстояния между
кластерами; этот метод называется методом одиночной
связи. Это правило строит «волокнистые»
кластеры, т.е. кластеры, «сцепленные вместе»
только отдельными элементами, случайно
оказавшимися ближе остальных друг к другу. Как
альтернативу вы можете использовать соседей в
кластерах, которые находятся дальше всех
остальных пар объектов друг от друга. Этот метод
называется метод полной связи. Существует
также множество других методов объединения
кластеров, подобных тем, что были рассмотрены.
Одиночная связь (метод ближайшего соседа). Как
было описано выше, в этом методе расстояние между
двумя кластерами определяется расстоянием между
двумя наиболее близкими объектами (ближайшими
соседями) в различных кластерах. Это правило
должно, в известном смысле, нанизывать объекты
вместе для формирования кластеров, и
результирующие кластеры имеют тенденцию быть
представленными длинными «цепочками».
Полная связь (метод наиболее удаленных
соседей). В этом методе расстояния между
кластерами определяются наибольшим расстоянием
между любыми двумя объектами в различных
кластерах (т.е. «наиболее удаленными
соседями»). Этот метод обычно работает очень
хорошо, когда объекты происходят на самом деле из
реально различных «рощ». Если же кластеры
имеют в некотором роде удлиненную форму или их
естественный тип является «цепочечным», то
этот метод непригоден.
Невзвешенное попарное среднее. В этом
методе расстояние между двумя различными
кластерами вычисляется как среднее расстояние
между всеми парами объектов в них. Метод
эффективен, когда объекты в действительности
формируют различные «рощи», однако он
работает одинаково хорошо и в случаях
протяженных («цепочного» типа) кластеров.
Отметим, что в своей книге Снит и Сокэл (Sneath, Sokal,
1973) вводят аббревиатуру UPGMA для ссылки на этот
метод, как на метод невзвешенного попарного
арифметического среднего — unweighted pair-group method
using arithmetic averages.
Взвешенное попарное среднее. Метод
идентичен методу невзвешенного попарного
среднего, за исключением того, что при
вычислениях размер соответствующих кластеров
(т.е. число объектов, содержащихся в них)
используется в качестве весового коэффициента.
Поэтому предлагаемый метод должен быть
использован (скорее даже, чем предыдущий), когда
предполагаются неравные размеры кластеров. В
книге Снита и Сокэла (Sneath, Sokal, 1973) вводится
аббревиатура WPGMA для ссылки на этот метод, как
на метод взвешенного попарного
арифметического среднего — weighted pair-group method using
arithmetic averages.
Невзвешенный центроидный метод. В этом
методе расстояние между двумя кластерами
определяется как расстояние между их центрами
тяжести. Снит и Сокэл (Sneath and Sokal (1973)) используют
аббревиатуру UPGMC для ссылки на этот метод, как
на метод невзвешенного попарного центроидного
усреднения — unweighted pair-group method using the centroid average.
Взвешенный центроидный метод (медиана). тот
метод идентичен предыдущему, за исключением
того, что при вычислениях используются веса для
учёта разницы между размерами кластеров (т.е.
числами объектов в них). Поэтому, если имеются
(или подозреваются) значительные отличия в
размерах кластеров, этот метод оказывается
предпочтительнее предыдущего. Снит и Сокэл (Sneath,
Sokal 1973) использовали аббревиатуру WPGMC для
ссылок на него, как на метод невзвешенного
попарного центроидного усреднения — weighted
pair-group method using the centroid average.
Метод Варда. Этот метод отличается от всех
других методов, поскольку он использует методы
дисперсионного анализа для оценки расстояний
между кластерами. Метод минимизирует сумму
квадратов (SS) для любых двух (гипотетических)
кластеров, которые могут быть сформированы на
каждом шаге. Подробности можно найти в работе
Варда (Ward, 1963). В целом метод представляется очень
В целом метод представляется очень
эффективным, однако он стремится создавать
кластеры малого размера.
Для обзора других методов кластеризации, см. Двухвходовое объединение и Метод K средних.
| В начало |
Двувходовое
объединение
- Вводный обзор
- Двувходовое объединение
Вводный обзор
Ранее этот метод обсуждался в терминах
«объектов», которые должны быть
кластеризованы (см. Объединение
(древовидная кластеризация)). Во всех других
видах анализа интересующий исследователя вопрос
обычно выражается в терминах наблюдений или
переменных. Оказывается, что кластеризация, как
по наблюдениям, так и по переменным может
привести к достаточно интересным результатам.
Например, представьте, что медицинский
исследователь собирает данные о различных
характеристиках (переменные) состояний
пациентов (наблюдений), страдающих сердечными
заболеваниями. Исследователь может захотеть
Исследователь может захотеть
кластеризовать наблюдения (пациентов) для
определения кластеров пациентов со сходными
симптомами. В то же самое время исследователь
может захотеть кластеризовать переменные для
определения кластеров переменных, которые
связаны со сходным физическим состоянием.
Двувходовое
объединение
После этого обсуждения, относящегося к тому,
кластеризовать наблюдения или переменные, можно
задать вопрос, а почему бы не проводить
кластеризацию в обоих направлениях? Модуль Кластерный
анализ содержит эффективную двувходовую
процедуру объединения, позволяющую сделать
именно это. Однако двувходовое объединение
используется (относительно редко) в
обстоятельствах, когда ожидается, что и
наблюдения и переменные одновременно вносят
вклад в обнаружение осмысленных кластеров.
Так, возвращаясь к предыдущему примеру, можно
предположить, что медицинскому исследователю
требуется выделить кластеры пациентов, сходных
по отношению к определенным кластерам
характеристик физического состояния. Трудность
Трудность
с интерпретацией полученных результатов
возникает вследствие того, что сходства между
различными кластерами могут происходить из (или
быть причиной) некоторого различия подмножеств
переменных. Поэтому получающиеся кластеры
являются по своей природе неоднородными.
Возможно это кажется вначале немного туманным; в
самом деле, в сравнении с другими описанными
методами кластерного анализа (см. Объединение (древовидная
кластеризация) и Метод K средних),
двувходовое объединение является, вероятно,
наименее часто используемым методом. Однако
некоторые исследователи полагают, что он
предлагает мощное средство разведочного анализа
данных (за более подробной информацией вы можете
обратиться к описанию этого метода у Хартигана
(Hartigan, 1975)).
| В начало |
Метод K средних
- Пример
- Вычисления
- Интерпретация результатов
Общая логика
Этот метод кластеризации существенно
отличается от таких агломеративных методов, как Объединение (древовидная
кластеризация) и Двувходовое
объединение. Предположим, вы уже имеете
Предположим, вы уже имеете
гипотезы относительно числа кластеров (по
наблюдениям или по переменным). Вы можете указать
системе образовать ровно три кластера так, чтобы
они были настолько различны, насколько это
возможно. Это именно тот тип задач, которые
решает алгоритм
метода K средних. В общем случае метод K средних
строит ровно K различных кластеров,
расположенных на возможно больших расстояниях
друг от друга.
Пример
В примере с физическим состоянием (см. Двувходовое объединение),
медицинский исследователь может иметь
«подозрение» из своего клинического опыта,
что его пациенты в основном попадают в три
различные категории. Далее он может захотеть
узнать, может ли его интуиция быть подтверждена
численно, то есть, в самом ли деле кластерный
анализ K средних даст три кластера пациентов,
как ожидалось? Если это так, то средние различных
мер физических параметров для каждого кластера
будут давать количественный способ
представления гипотез исследователя (например,
пациенты в кластере 1 имеют высокий параметр 1,
меньший параметр 2 и т. д.).
д.).
Вычисления
С вычислительной точки зрения вы можете
рассматривать этот метод, как дисперсионный
анализ (см. Дисперсионный анализ)
«наоборот». Программа начинает с K случайно
выбранных кластеров, а затем изменяет
принадлежность объектов к ним, чтобы: (1) -
минимизировать изменчивость внутри
кластеров, и (2) — максимизировать изменчивость между
кластерами. Данный способ аналогичен методу
«дисперсионный анализ (ANOVA) наоборот» в том
смысле, что критерий значимости в дисперсионном
анализе сравнивает межгрупповую изменчивость с
внутригрупповой при проверке гипотезы о том, что
средние в группах отличаются друг от друга. В
кластеризации методом K средних программа
перемещает объекты (т.е. наблюдения) из одних
групп (кластеров) в другие для того, чтобы
получить наиболее значимый результат при
проведении дисперсионного анализа (ANOVA).
Интерпретация
результатов
Обычно, когда результаты кластерного анализа
методом K средних получены, можно рассчитать
средние для каждого кластера по каждому
измерению, чтобы оценить, насколько кластеры
различаются друг от друга. В идеале вы должны
В идеале вы должны
получить сильно различающиеся средние для
большинства, если не для всех измерений,
используемых в анализе. Значения F-статистики,
полученные для каждого измерения, являются
другим индикатором того, насколько хорошо
соответствующее измерение дискриминирует
кластеры.
Все права на материалы электронного учебника принадлежат компании StatSoft
Кластеризация в машинном обучении — GeeksforGeeks
Улучшить статью
Сохранить статью
Введение в кластеризацию
В основном это тип метода обучения без учителя . Метод обучения без учителя — это метод, в котором мы получаем ссылки из наборов данных, состоящих из входных данных без помеченных ответов. Как правило, он используется как процесс для поиска значимой структуры, объяснительных основных процессов, порождающих функций и группировок, присущих набору примеров.
Кластеризация — это задача разделения совокупности или точек данных на ряд групп таким образом, чтобы точки данных в одних и тех же группах были более похожи на другие точки данных в той же группе и отличались от точек данных в других группах. Это в основном совокупность объектов на основе сходства и несходства между ними.
Например, . Точки данных на приведенном ниже графике, сгруппированные вместе, можно отнести к одной группе. Мы можем различить кластеры, и мы можем определить, что на изображении ниже есть 3 кластера.
Кластеры не обязательно должны быть сферическими. Например:
DBSCAN: пространственная кластеризация приложений с шумом на основе плотности
Эти точки данных группируются с использованием базовой концепции, согласно которой точка данных находится в пределах заданного ограничения от центра кластера. Для расчета выбросов используются различные дистанционные методы и методы.![]()
Зачем нужна кластеризация?
Кластеризация очень важна, поскольку она определяет внутреннюю группировку имеющихся неразмеченных данных. Критериев хорошей кластеризации нет. От пользователя зависит, какие критерии он может использовать для удовлетворения своих потребностей. Например, нас может интересовать поиск представителей для однородных групп (редукция данных), поиск «естественных кластеров» и описание их неизвестных свойств («естественные» типы данных), поиск полезных и подходящих группировок («полезные» классы данных). или при обнаружении необычных объектов данных (обнаружение выбросов). Этот алгоритм должен делать некоторые предположения, которые составляют сходство точек, и каждое предположение создает разные и одинаково достоверные кластеры.
Методы кластеризации:
- Методы, основанные на плотности: Эти методы рассматривают кластеры как плотную область, имеющую некоторые сходства и отличия от более низкой плотной области пространства.
 Эти методы обладают хорошей точностью и возможностью объединения двух кластеров. Пример DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) , ОПТИКА (Точки заказа для определения структуры кластеризации) и т. д.
Эти методы обладают хорошей точностью и возможностью объединения двух кластеров. Пример DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) , ОПТИКА (Точки заказа для определения структуры кластеризации) и т. д. - Методы на основе иерархии: Кластеры, сформированные в этом методе, формируют древовидную структуру на основе иерархии. Новые кластеры формируются с использованием ранее сформированного. Он разделен на две категории
- Агломерации (снизу вверх Подход )
- Разделительные (сверху вниз подход )
 Эти методы обладают хорошей точностью и возможностью объединения двух кластеров. Пример DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) , ОПТИКА (Точки заказа для определения структуры кластеризации) и т. д.
Эти методы обладают хорошей точностью и возможностью объединения двух кластеров. Пример DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) , ОПТИКА (Точки заказа для определения структуры кластеризации) и т. д.Примеры . Сокращение кластеризации и использование иерархий) и т. д.
- Методы разделения: Эти методы разбивают объекты на k кластеров, и каждый раздел образует один кластер. Этот метод используется для оптимизации функции подобия объективного критерия, например, когда расстояние является основным параметром. Пример K-средних, CLARANS (кластеризация крупных приложений на основе случайного поиска) и т. д.
- Методы на основе сетки: In В этом методе пространство данных разбивается на конечное число ячеек, образующих структуру, подобную сетке. Все операции кластеризации, выполняемые в этих сетках, выполняются быстро и не зависят от количества объектов данных, пример 9.0023 STING (статистическая информационная сетка), кластер волн, CLIQUE (кластеризация в поисках) и т. д.
Алгоритмы кластеризации:
Алгоритм кластеризации K-средних — это простейший алгоритм обучения без учителя, который решает проблему кластеризации. означает, что алгоритм разбивает n наблюдений на k кластеров, где каждое наблюдение принадлежит кластеру с ближайшим средним значением, служащим прототипом кластера.
Применение кластеризации в различных областях
- Маркетинг: Его можно использовать для характеристики и выявления сегментов клиентов в маркетинговых целях.
- Биология: Может использоваться для классификации различных видов растений и животных.
- Библиотеки: Используется для группирования различных книг на основе тем и информации.
- Страховка: Используется для подтверждения клиентов, их полисов и выявления мошенничества.
Градостроительство: Используется для создания групп домов и изучения их стоимости в зависимости от их географического положения и других имеющихся факторов.
Изучение землетрясений: Изучив районы, пострадавшие от землетрясения, мы можем определить опасные зоны.
Ссылки:
Wiki
Иерархическая кластеризация
Ijarcs
matteucc
analyticsvidhya
knowm
Как формировать кластеры в Python: методы кластеризации данных
Что такое кластеризация?
Кластеризация — это процесс разделения различных частей данных на основе общих характеристик. Разрозненные отрасли, включая розничную торговлю, финансы и здравоохранение, используют методы кластеризации для решения различных аналитических задач. В розничной торговле кластеризация может помочь идентифицировать отдельные группы потребителей, что затем может позволить компании создавать целевую рекламу на основе демографических данных потребителей, которые могут быть слишком сложными для проверки вручную. В финансах кластеризация может обнаруживать различные формы незаконной рыночной деятельности, такие как спуфинг книги ордеров, когда трейдеры обманным путем размещают крупные ордера, чтобы заставить других трейдеров покупать или продавать актив. В здравоохранении методы кластеризации использовались для определения моделей затрат пациентов, ранних неврологических расстройств и экспрессии раковых генов.
Python предлагает множество полезных инструментов для выполнения кластерного анализа. Лучший инструмент для использования зависит от проблемы и типа доступных данных. Существует три широко используемых метода формирования кластеров в Python: кластеризация K-средних, смешанные модели Гаусса и спектральная кластеризация. Для относительно низкоразмерных задач (максимум несколько десятков входных данных), таких как идентификация отдельных групп потребителей, кластеризация K-средних является отличным выбором. Для более сложных задач, таких как обнаружение незаконной рыночной деятельности, лучше подойдет более надежная и гибкая модель, такая как смешанная модель Гаусса. Наконец, для многомерных задач с потенциальными тысячами входных данных наилучшим вариантом является спектральная кластеризация.
В дополнение к выбору алгоритма, соответствующего задаче, вам также необходимо иметь способ оценить, насколько хорошо работают эти алгоритмы кластеризации Python. Как правило, для оценки производительности модели используется среднее расстояние внутри кластера от центра. В частности, среднее расстояние каждого наблюдения от центра кластера, называемое центроидом, используется для измерения компактности кластера. Это имеет смысл, потому что хороший алгоритм кластеризации Python должен генерировать группы данных, которые плотно упакованы вместе. Чем ближе точки данных друг к другу в кластере Python, тем лучше результаты алгоритма. Сумма в пределах расстояния до кластера, нанесенная на график в зависимости от количества используемых кластеров, является распространенным способом оценки производительности.
Для наших целей мы будем проводить анализ сегментации клиентов на основе данных сегментации клиентов торгового центра.
Методы кластеризации данных в Python
- K-средние кластеризации
- Гауссовые модели смеси
- Спектральная кластеризация
Подробнее от руководства Sadrach Pierrea по выбору Machine Learning Models в Python
. чтение наших данных во фрейм данных Pandas:
импортировать панд как pd
df = pd.read_csv("Mall_Customers.csv")
print(df.head()) Мы видим, что наши данные довольно просты. Он содержит столбец с идентификаторами клиентов, полом, возрастом, доходом и столбец, обозначающий оценку расходов по шкале от одного до 100. Целью нашего упражнения по кластеризации Python будет создание уникальных групп клиентов, где каждый член этого группа больше похожа друг на друга, чем на членов других групп.
Кластеризация K-средних в Python
Кластеризация K-средних в Python — это тип неконтролируемого машинного обучения, что означает, что алгоритм обучается только на входных данных, а не на выходных данных. Он работает, находя отдельные группы данных (то есть кластеры), которые находятся ближе всего друг к другу. В частности, он разбивает данные на кластеры, в которых каждая точка попадает в кластер, среднее значение которого ближе всего к этой точке данных.
Давайте импортируем класс K-средних из модуля кластеров в Scikit-learn:
из sklearn.clusters import KMeans
Далее давайте определим входные данные, которые мы будем использовать для нашего алгоритма кластеризации K-средних. Давайте используем возраст и оценку расходов:
X = df[['Возраст', 'Оценка расходов (1-100)']].
Следующее, что нам нужно сделать, это определить количество кластеров Python, которые мы будем использовать. Мы будем использовать метод локтя, который строит график зависимости суммы квадратов внутри кластера (WCSS) от количества кластеров. Нам нужно определить цикл for, содержащий экземпляры класса K-средних. Этот цикл for будет перебирать номера кластеров от 1 до 10. Мы также инициализируем список, который будем использовать для добавления значений WCSS:
для i в диапазоне (1, 11):
kmeans = KMeans (n_clusters = i, random_state = 0)
kmeans.fit(X) Затем мы добавляем значения WCSS в наш список. Мы получаем доступ к этим значениям через атрибут инерции объекта K-средних:
для i в диапазоне (1, 11):
kmeans = KMeans (n_clusters = i, random_state = 0)
kmeans.fit(X)
wcss.append(kmeans.intertia_) Наконец, мы можем построить зависимость WCSS от количества кластеров. Во-первых, давайте импортируем Matplotlib и Seaborn, что позволит нам создавать и форматировать визуализацию данных:
импортировать matplotlib.
Давайте стилизуем графики с помощью Seaborn:
sns.set()
Затем построим график зависимости WCSS от кластеров:
plt.plot(range(1, 11), wcss)
Затем добавим a title:
plt.title('Выбор количества кластеров методом локтя') И, наконец, маркируйте оси:
plt.xlabel('Кластеры')
plt.ylabel('WCSS')
plt.show() Из этого графика видно, что четыре — это оптимальное количество кластеров, так как здесь появляется «локоть» кривой.
Мы видим, что K-средние нашли четыре кластера, которые разбиты следующим образом:
Молодые клиенты с умеренным показателем расходов.
Молодые клиенты с высокой оценкой расходов.
Клиенты среднего возраста с низким уровнем расходов.
Пожилые клиенты с умеренным уровнем расходов.
Этот тип информации может быть очень полезен для розничных компаний, стремящихся ориентироваться на определенные демографические группы потребителей. Например, если большинство людей с высокими показателями расходов моложе, компания может ориентироваться на эти группы населения с помощью рекламы и рекламных акций.
Модель гауссовой смеси (GMM) в Python
В этой модели предполагается, что кластеры в Python можно моделировать с использованием распределения Гаусса. Распределения Гаусса, неофициально называемые кривыми нормального распределения, представляют собой функции, которые описывают многие важные вещи, такие как рост и вес населения.
Эти модели полезны, поскольку распределения Гаусса имеют четко определенные свойства, такие как среднее значение, дисперсия и ковариация. Среднее значение — это просто среднее значение входа в кластере. Дисперсия измеряет колебания значений для одного входа. Ковариация — это матрица статистики, описывающая, как входные данные связаны друг с другом и, в частности, как они изменяются вместе.
В совокупности эти параметры позволяют алгоритму GMM создавать гибкие кластеры идентификаторов сложной формы. В то время как K-средние обычно идентифицируют кластеры сферической формы, GMM может более широко идентифицировать кластеры Python различной формы. На практике это делает GMM более надежным, чем метод K-средних.
Давайте начнем с импорта пакета GMM из Scikit-learn:
из sklearn.mixture import GaussianMixture
Затем давайте инициализируем экземпляр класса GaussianMixture. Давайте начнем с рассмотрения трех кластеров Python и подгоним модель под наши входные данные (в данном случае возраст и показатель расходов):
из sklearn.mixture импорт GaussianMixture n_кластеров = 3 gmm_model = GaussianMixture (n_components = n_clusters) gmm_model.fit(X)
Теперь давайте сгенерируем метки кластера и сохраним результаты вместе с нашими входными данными в новом фрейме данных:
cluster_labels = gmm_model.predict(X) X = pd.
Далее, давайте изобразим каждый кластер в цикле for:
для k в диапазоне (0, n_clusters):
данные = X[X["кластер"]==k]
plt.scatter(data["Возраст"],data["Оценка расходов (1-100)"],c=color[k]) И, наконец, отформатируйте график:
plt.title("Кластеры, идентифицированные моделью смеси Гуасса")
plt.ylabel("Оценка расходов (1-100)")
plt.xlabel("Возраст")
plt.show() Красные и синие кластеры кажутся относительно четко определенными. Синяя группа — это молодые клиенты с высокой оценкой расходов, а красная — молодые клиенты со средней оценкой расходов. Зеленый кластер менее четко определен, поскольку он охватывает все возрасты и уровни расходов как от низких, так и от умеренных.
Теперь попробуем четыре кластера:
... n_кластеров = 4 gmm_model = GaussianMixture (n_components = n_clusters) ...
Хотя четыре кластера демонстрируют небольшое улучшение, как красный, так и синий по-прежнему довольно широкие с точки зрения возраста и значений расходов. Итак, попробуем пять кластеров:
Пять кластеров кажутся подходящими. Их можно описать следующим образом:
Молодые клиенты с высокой оценкой расходов (зеленые).
Молодые клиенты со средним уровнем расходов (черный цвет).
Клиенты от молодого до среднего возраста с низким уровнем расходов (синий).
Клиенты среднего и старшего возраста с низким уровнем расходов (желтый).
Клиенты от среднего до старшего возраста с умеренным уровнем расходов (красный).
Смешанные модели Гаусса обычно более надежны и гибки, чем кластеризация K-средних в Python. Опять же, это связано с тем, что GMM фиксирует сложные формы кластеров, а K-средние — нет. Это позволяет GMM точно идентифицировать кластеры Python, которые являются более сложными, чем сферические кластеры, которые идентифицирует K-средние. GMM — идеальный метод для наборов данных среднего размера и сложности, поскольку он лучше подходит для сбора кластеров в наборах сложной формы.
Спектральная кластеризация в Python
Спектральная кластеризация — это распространенный метод, используемый в Python для кластерного анализа многомерных и часто сложных данных. Он работает, выполняя уменьшение размерности на входе и создавая кластеры Python в пространстве с уменьшенной размерностью. Поскольку наши данные не содержат много входных данных, это будет в основном для целей иллюстрации, но должно быть просто применить этот метод к более сложным и большим наборам данных.
Давайте начнем с импорта класса SpectralClustering из модуля кластера в Scikit-learn:
из sklearn.cluster import SpectralClustering
Затем давайте определим наш экземпляр класса SpectralClustering с пятью кластерами:
spectral_cluster_model= SpectralClustering(
n_кластеров = 5,
случайное_состояние = 25,
n_соседей=8,
сходство = 'ближайшие_соседи'
) Далее, давайте определим наш объект модели для наших входных данных и сохраним результаты в том же фрейме данных:
X['cluster'] = Spectra_cluster_model.
Наконец, давайте нанесем на график наши кластеры:
fig, ax = plt.subplots () sns.scatterplot(x='Возраст', y='Оценка расходов (1-100)', data=X, hue='cluster', ax=ax) ax.set(title='Спектральная кластеризация')
Мы видим, что кластеры один, два, три и четыре довольно различны, в то время как нулевой кластер кажется довольно широким. Как правило, мы видим некоторые из тех же закономерностей с группами кластеров, что и для K-средних и GMM, хотя предыдущие методы давали лучшее разделение между кластерами. Опять же, спектральная кластеризация в Python лучше подходит для задач, связанных с гораздо большими наборами данных, например, с сотнями или тысячами входных данных и миллионами строк.
Код из этого поста доступен на GitHub.
Дополнительные сведения о науке о данныхХотите быстрее и проще получать аналитические данные по бизнес-аналитике?
Добавьте кластеризацию в свой инструментарий
Хотя мы рассматривали кластерный анализ только в контексте сегментации клиентов, он широко применим в самых разных отраслях. Обсуждаемые нами методы кластеризации Python использовались для решения самых разных задач. Кластеризация K-средних использовалась для выявления уязвимых групп пациентов. Смешанные модели Гаусса использовались для обнаружения незаконных рыночных действий, таких как поддельная торговля, накачка и сброс и вброс котировок. Методы спектральной кластеризации использовались для решения сложных проблем здравоохранения, таких как группировка медицинских терминов для получения знаний о здравоохранении.
Независимо от отрасли, любая современная организация или компания может найти большую ценность в возможности идентифицировать важные кластеры из своих данных. Python предоставляет множество простых в реализации инструментов для выполнения кластерного анализа на всех уровнях сложности данных. Кроме того, хорошее знание того, какие методы работают лучше всего с учетом сложности данных, является бесценным навыком для любого специалиста по данным. То, что мы рассмотрели, обеспечивает прочную основу для специалистов по данным, которые начинают изучать, как выполнять кластерный анализ в Python.