Содержание
Как полностью скрыть сайт от индексации?
#Оптимизация сайта
#Индексация
#7
Ноябрь’17
17
Ноябрь’17
17
Про то, как закрыть от индексации отдельную страницу и для чего это нужно мы уже писали. Но могут возникнуть случаи, когда от индексации надо закрыть весь сайт или зеркало, что проблематичнее. Существует несколько способов. О них мы сегодня и расскажем.
Существует несколько способов закрыть сайт от индексации.
Запрет в файле robots.txt
Файл robots.txt отвечает за индексацию сайта поисковыми роботами. Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
User-agent: *
Disallow: /
Остальные правила должны быть удалены.
Этот метод самый простой для скрытия сайта от индексации.
С помощью мета-тега robots
Прописав в шаблоне страниц сайта следующее правило <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/> в теге <head>, вы запретите его индексацию.
Как закрыть зеркало сайта от индексации
Зеркало — точная копия сайта, доступная по другому домену. Т.е. два разных домена настроены на одну и ту же папку с сайтом. Цели создания зеркал могут быть разные, но в любом случае мы получаем полную копию сайта, которую рекомендуется закрыть от индексации.
Сделать это стандартными способами невозможно, т.к. по адресам domen1.ru/robots.txt и domen2.ru/robots.txt открывается один и тот же файл robots.txt с одинаковым содержанием. В таком случае необходимо провести специальные настройки на сервере, которые позволят одному из доменов отдавать запрещающий robots.txt.
Похожее
Оптимизация сайта
Индексация
Атрибут rel=canonical
Оптимизация сайта
Индексация
Индексация ссылок
Оптимизация сайта
Индексация
#133
Атрибут rel=canonical
Декабрь’22
11306
22
Оптимизация сайта
Индексация
#119
Индексация ссылок
Апрель’19
4484
30
Оптимизация сайта
Индексация
#111
Описание и настройка директивы Clean-param
Апрель’19
8793
24
Оптимизация сайта
Индексация
#104
Как привлечь быстроробота Яндекс
Февраль’19
2199
21
Оптимизация сайта
Индексация
#94
Проверка индекса сайта. Как найти мусорные или недостающие страницы
Как найти мусорные или недостающие страницы
Декабрь’18
8938
28
Оптимизация сайта
Индексация
#86
Как закрыть ссылки и текст от поисковых систем
Ноябрь’18
5655
22
Оптимизация сайта
Индексация
#82
Почему Яндекс удаляет страницы из поиска
Ноябрь’18
3079
19
Оптимизация сайта
Индексация
#60
Правильная индексация страниц пагинации
Февраль’18
7751
19
Оптимизация сайта
Индексация
#47
Как узнать дату индексации страницы
Ноябрь’17
7491
18
Оптимизация сайта
Индексация
#46
Какие страницы надо закрывать от индексации
Ноябрь’17
10153
18
Оптимизация сайта
Индексация
#38
Как удалить страницу из индекса Яндекса и Google
Ноябрь’17
13370
20
Оптимизация сайта
Индексация
#37
Как добавить страницу в поиск Яндекса и Google
Апрель’17
18950
19
Оптимизация сайта
Индексация
#2
Как проверить индексацию сайта в поисковых системах
Ноябрь’17
17071
27
Оптимизация сайта
Индексация
#1
Как ускорить индексацию сайта
Ноябрь’17
5503
29
Индексация сайта robots.
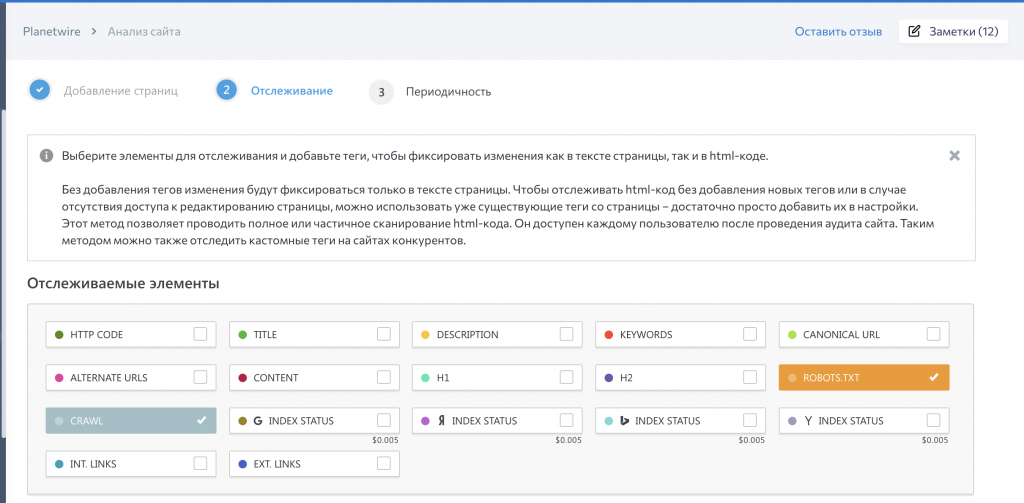 txt, способы закрыть от индексации
txt, способы закрыть от индексации
Последнее обновление: 08 ноября 2022 года
31521
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем закрывать сайт от поисковых роботов?
- Как проверить, закрыт сайт от индексации или нет? robots.txt
- Как закрыть сайт от индексации?
- Какие ошибки встречаются при записи файла robots.txt?
Кому будет полезна статья?
- Веб-разработчикам.
- Контент-редакторам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Несмотря на то, что все ресурсы стремятся попасть в топ поисковой выдачи, в процессе работы возникают ситуации, когда требуется сделать прямо противоположное — закрыть сайт от поисковых роботов. В каких случаях может понадобиться запрет на индексацию, и как это сделать, мы расскажем в этой статье.
Зачем закрывать сайт от поисковых роботов?
Первое время после запуска проекта о нем знают только разработчики и те пользователи, которые получили ссылку на ресурс. В базы поисковых систем и, соответственно, в выдачу сайт попадает только после того, как его найдут и проанализируют краулеры (поисковые работы). С этого момента он становится доступным для пользователей Яндекс и Google.
Но всю ли информацию, содержащуюся на страницах ресурса, должны видеть пользователи? Конечно, нет. Им, прежде всего, интересны полезные материалы: статьи, информация о компании, товарах, услугах, развлекательный контент. Временные файлы, документация для ПО и другая служебная информация пользователям неинтересна, и поэтому не нужна. Если лишние страницы будут отображаться вместе с полезным контентом, это затруднит поиск действительно нужной информации и негативно отразится на позициях ресурса в поисковой выдаче. Вывод — служебную информацию следует закрывать от индексации.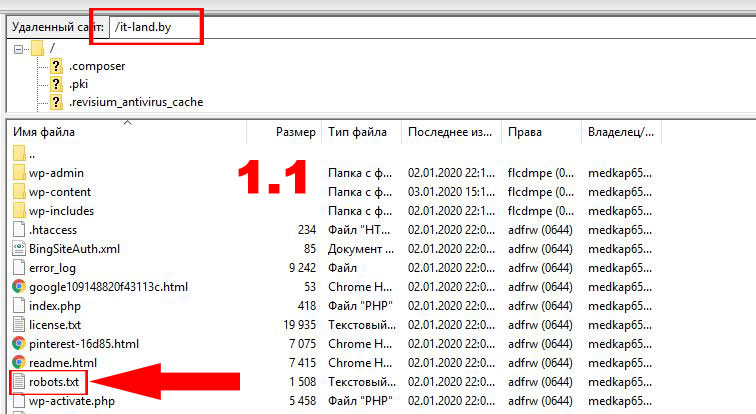
В процессе работы сайта также возникают ситуации, когда требуется полностью закрыть ресурс от поисковиков. Например, во время технических работ, внесения существенных правок, изменения структуры и дизайна проекта. Если этого не сделать, сайт может быть проиндексирован с ошибками, что негативно отразиться на его рейтинге.
Мнение эксперта
Анастасия Курдюкова, руководитель группы оптимизаторов в компании «Ашманов и партнеры»:
«Чтобы сайт быстрее индексировался, рекомендуется закрывать от поисковых роботов мусорные страницы: устаревшие материалы, информацию о прошедших акциях и мероприятиях, а также всплывающие окна и баннеры. Это не только сократит время индексации, но уменьшит нагрузку на сервер, а поисковые роботы смогут проиндексировать более количество качественных страниц».
Как проверить, закрыт сайт от индексации или нет?
Если вы не уверены, индексируется ли сайт поисковыми роботами, какие разделы, страницы и файлы доступны для сканирования, а какие нет, можно проверить ресурс с помощью сервисов Яндекс.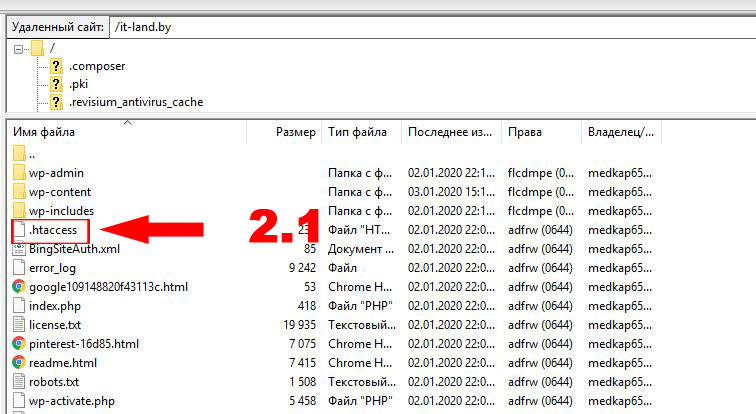 Вебмастер и Google Search Console. Как это сделать, мы рассказали в статье «Проверка файла robot.txt». Протестируйте ресурс в обоих сервисах, и они покажут, какие url проекта индексируются.
Вебмастер и Google Search Console. Как это сделать, мы рассказали в статье «Проверка файла robot.txt». Протестируйте ресурс в обоих сервисах, и они покажут, какие url проекта индексируются.
В качестве альтернативы можно использовать бесплатный инструмент «Определение возраста сайта» от «Пиксель Тулс». С помощью этого сервиса вы узнаете возраст домена, отдельных страницы, дату индексации и кэша. Данные проверки можно отправить в Яндекс.Вебмастер и выгрузить в формате CSV.
Как закрыть сайт от индексации?
Запретить доступ к сайту можно с помощью служебного файла robots.txt. Он находится в корневой папке. Если файла нет, создайте документ в Notepad++ или любом другом текстовом редакторе. Далее следуйте рекомендациям ниже.
Запрет индексации всего сайта
Управление доступом к ресурсу, его разделам и страницам осуществляется с помощью директив User-agent, Disallow и Allow. Директива User-agent указывает на робота, для которого действуют перечисленные ниже правила, Disallow — запрещает индексацию, Allow — разрешает индексацию.
Если вы хотите установить запрет для всех краулеров, в файле robots.txt следует указать:
User-agent: *
Disallow: /
Запрет для всех поисковых роботов, кроме краулеров Яндекса, будет выглядеть так:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Запрет для всех поисковиков, кроме Google, так:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
Вы также можете ограничить доступ для отдельных поисковых роботов, разрешив всем остальным краулерам сканировать без ограничений. Например, запрет для робота YandexImages, который индексирует изображения для показа на Яндекс.Картинках, будет выглядеть так:
User-agent: YandexImages
Disallow: /
Таким образом, с помощью всего трех директив вы можете управлять доступом к сайту для краулеров любых поисковых систем: запрещать или разрешать индексацию всем поисковикам, закрывать доступ одним и открывать другим роботам.
Запрет на индексацию разделов и страниц
Если вы не хотите закрывать от индексации весь сайт, а только некоторые его разделы или страницы, это можно сделать с помощью тех же директив. Для понимания приведем несколько примеров.
- Поисковым роботам доступны все разделы, кроме каталога:
User-agent: *
Disallow: /catalog - Поисковым роботам доступны все страницы, кроме контактов:
User-agent: *
Disallow: /contact.html - Поисковым роботам закрыт весь сайт, кроме одного раздела:
User-agent: *
Disallow: /
Allow: /catalog - Поисковым роботам закрыт весь раздел, кроме одного подраздела:
User-agent: *
Disallow: /product
Allow: /product/auto
Несмотря на простоту управления, файл robots.txt позволяет выполнять достаточно гибкие настройки индексации для краулеров поисковых систем и изменять уровень доступа в зависимости от текущей ситуации.
Как скрыть от индексации ссылки?
Закрыть от краулеров можно не только сайт или его разделы, но и отдельные элементы, например, ссылки. Сделать это можно двумя способами:
- в html-коде страницы указать метатег robots с директивой nofollow;
- вставить атрибут rel=”nofollow” в саму ссылку: <a href=”url” rel=”nofollow”>текст ссылки</а>.
Второй вариант предпочтительнее, так как атрибут rel=”nofollow” запрещает краулерам переходить по ссылке даже в том случае, если поисковая система находит ее через другие материалы вашего сайта или сторонних ресурсов.
Проверь своего подрядчика
Если работа SEO-подрядчика не дает ожидаемых результатов, мы предлагаем провести аудит текущего поискового продвижения. Наша экспертиза поможет выявить существующие проблемы.
Какие ошибки встречаются при записи файла robots.txt?
Если robots. txt будет записан с ошибками, краулеры не смогут корректно проиндексировать файл и полезная для пользователей информация не попадет в поисковую выдачу. Наиболее часто разработчики допускают следующие ошибки:
txt будет записан с ошибками, краулеры не смогут корректно проиндексировать файл и полезная для пользователей информация не попадет в поисковую выдачу. Наиболее часто разработчики допускают следующие ошибки:
- Неверные (перепутанные) значения директив.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: / - Указание нескольких URL в одной директиве.
Неправильно:
Disallow: /admin/ /tags/ /images/
Правильно:
Disallow: /admin/
Disallow: /tags/
Disallow: /images/ - Пустое значение User-agent.
Неправильно:
User-agent:
Disallow: /
Правильно:
User-agent: *
Disallow: / - Некорректный формат директивы Disallow.
Неправильно:
User-agent: Yandex
Disallow: admin
Правильно:
User-agent: Yandex
Disallow: /admin/
Проверить файл robots. txt на наличие ошибок можно с помощью Яндекс.Вебмастер и Google Search Console. Порядок проверки мы подробно описали в статье «Проверка файла robot.txt».
txt на наличие ошибок можно с помощью Яндекс.Вебмастер и Google Search Console. Порядок проверки мы подробно описали в статье «Проверка файла robot.txt».
Выводы
- Запрет на индексацию позволяет скрыть от поисковых роботов временные и служебные документы, неактуальный контент, ссылки, всплывающие окна и баннеры, полностью ограничить доступ к сайту на время технических работ.
- Проверить, какие страницы сайта индексируются, можно с помощью Яндекс.Вебмастер, Google Search Console и бесплатных инструментов, предоставляемых сторонними ресурсами.
- Закрыть сайт или отдельные его разделы и страницы от краулеров можно через robots.txt, который находится в корневом каталоге.
- Гибкие настройки позволяют изменять уровень доступа в зависимости от текущей ситуации.
- После внесения изменений файл robots.txt необходимо проверить на наличие ошибок. Это можно сделать с помощью сервисов поисковых систем Яндекс.Вебмастер и Google Search Console.


Статья
Изменения в Яндексе на 2022 год: новые метрики качества
#SEO, #Яндекс
Статья
Яндекс обновил алгоритмы: как улучшить ранжирование сайта?
#SEO, #Яндекс
Статья
Нестандартное SEO: 7 лайфхаков продвижения в Google от западных специалистов
#SEO, #Google
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Анастасия Курдюкова, руководитель группы оптимизаторов «Ашманов и партнеры», опытный специалист по SEO-оптимизации, ведущая вебинаров для клиентов компании.
Теги:
SEO, Яндекс, Google
Google объясняет, как скрыть веб-сайт из результатов поиска
Google утверждает, что лучший способ скрыть веб-сайт из результатов поиска — использовать пароль, но есть и другие варианты, которые вы можете рассмотреть.
Эта тема освещена в последнем выпуске серии видеороликов Ask Googlebot на YouTube.
Джон Мюллер из Google отвечает на вопрос о том, как предотвратить индексацию контента в поиске и разрешено ли это делать веб-сайтам.
«Короче говоря, да, можете, — говорит Мюллер.
Есть три способа скрыть сайт из результатов поиска:
- Использовать пароль
- Обход блока
- Индексация блока
Веб-сайты могут либо полностью отказаться от индексации, либо проиндексироваться и скрыть контент от робота Googlebot с помощью пароля.
Блокировка контента от робота Googlebot не противоречит рекомендациям для веб-мастеров, если он одновременно заблокирован для пользователей.
Например, если сайт защищен паролем при сканировании роботом Googlebot, он также должен быть защищен паролем для пользователей.
В качестве альтернативы сайт должен иметь директивы, запрещающие роботу Googlebot сканировать или индексировать сайт.
У вас могут возникнуть проблемы, если ваш веб-сайт предоставляет другой контент для робота Googlebot, чем для пользователей.
Это называется «маскировкой» и противоречит рекомендациям Google.
С учетом этого различия, вот правильные способы скрытия контента от поисковых систем.
1. Защита паролем
Блокировка веб-сайта паролем часто является лучшим подходом, если вы хотите сохранить конфиденциальность своего сайта.
Пароль гарантирует, что ни поисковые системы, ни случайные пользователи сети не смогут увидеть ваш контент.
Это обычная практика для веб-сайтов в разработке. Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
2. Заблокировать сканирование
Еще один способ запретить роботу Googlebot доступ к вашему сайту — заблокировать сканирование. Это делается с помощью файла robots.txt.
С помощью этого метода люди могут получить доступ к вашему сайту по прямой ссылке, но она не будет обнаружена «приличными» поисковыми системами.
По словам Мюллера, это не лучший вариант, потому что поисковые системы могут индексировать адрес веб-сайта без доступа к его содержимому.
Такое случается редко, но о такой возможности вам следует знать.
3. Заблокировать индексирование
Третий и последний вариант — заблокировать индексирование вашего веб-сайта.
Для этого вы добавляете на свои страницы метатег noindex robots.
Тег noindex указывает поисковым системам не индексировать эту страницу до тех пор, пока после они ее не просканируют.
Пользователи не видят метатег и могут нормально открывать страницу.
Заключительные мысли Мюллера
Мюллер завершает видео, говоря, что главная рекомендация Google — использовать пароль:
«В целом, для частного контента мы рекомендуем использовать защиту паролем. Легко проверить, работает ли он, и он не позволяет никому получить доступ к вашему контенту.
Блокировка сканирования или индексации — хорошие варианты, когда контент не является частным. Или если есть только части веб-сайта, которые вы не хотите отображать в поиске».
См. полное видео ниже:
Избранное изображение: снимок экрана с сайта YouTube.com/GoogleSearchCentral, ноябрь 2021 г.
Категория
Новости
SEO
Отключить индексирование поисковыми системами | Webflow University
Вернуться ко всем урокам
Вернуться к библиотеке уроков
Все уроки
Отключить индексирование поисковыми системами
Библиотека уроков
Все уроки
Запретить индексирование ваших страниц поисковыми системами, поисковыми системами
весь сайт или только ваш субдомен webflow. io.
io.
У этого видео старый пользовательский интерфейс. Скоро будет обновленная версия!
Клонировать этот проект
Стенограмма
Вы можете указать поисковым системам, какие страницы сканировать, написав файл robots.txt. Вы также можете запретить поисковым системам сканировать и индексировать определенные страницы, папки, весь ваш сайт или субдомен webflow.io. Это полезно для того, чтобы скрыть такие страницы, как страница 404 вашего сайта, от индексации и отображения в результатах поиска.
В этом уроке:
- Как отключить индексирование субдомена Webflow
- Как создать файл robots.txt
- Рекомендации по обеспечению конфиденциальности
- Часто задаваемые вопросы и советы по устранению неполадок
Как отключить индексирование субдомена Webflow
другим поисковым системам запретить индексировать поддомен webflow.io вашего сайта, отключив индексирование в настройках сайта .
- Перейти к Настройки сайта > SEO вкладка > Индексирование раздел
- Установите для Отключить индексирование поддоменов Webflow значение «Да»
- Нажмите Сохранить изменения и опубликовать свой сайт игнорировать этот домен.
Как создать файл robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов сайта, которые вы не хотите сканировать поисковыми системами. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы указать роботам поисковых систем, какой контент им следует сканировать.
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена. Webflow сгенерирует файл /robots.txt для вашего сайта после того, как вы создадите его в настройках сайта .
Чтобы создать файл robots.txt:
- Перейдите к Настройки сайта > SEO вкладка > Индексирование раздел
- Добавьте нужные изменения robots. txt
9 Нажмите Сохранить и опубликовать свой сайт
 txt
txt Важно: Контент с вашего сайта может быть проиндексирован, даже если он не просканирован. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент из другого контента в Интернете. Чтобы убедиться, что ранее проиндексированная страница не проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google.
Правила robots.txt
Любое из этих правил можно использовать для заполнения файла robots.txt.
- Агент пользователя: * означает, что этот раздел относится ко всем роботам.
- Запретить: предписывает роботу не посещать сайт, страницу или папку.
Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: /page-name
Чтобы скрыть всю папку страниц
Агент пользователя: *
Запретить: /имя-папки/
Включить карту сайта
Карта сайта: https://your-site. com/sitemap.xml
com/sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt.
Примечание: Любой может получить доступ к файлу robots.txt вашего сайта, поэтому он может идентифицировать и получить доступ к вашему личному контенту.
Рекомендации по обеспечению конфиденциальности
Если вы хотите предотвратить обнаружение определенной страницы или URL-адреса на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL-адреса. Вместо этого используйте любой из следующих вариантов:
- Используйте метакод noindex, чтобы запретить поисковым системам индексировать ваш контент и удалить контент из индекса поисковых систем.
- Сохраняйте страницы с конфиденциальным содержимым как черновики и не публикуйте их. Защитите паролем страницы, которые вам нужно опубликовать.
Часто задаваемые вопросы и советы по устранению неполадок
Могу ли я использовать файл robots. txt для предотвращения индексации ресурсов моего сайта Webflow?
txt для предотвращения индексации ресурсов моего сайта Webflow?
Невозможно использовать файл robots.txt для предотвращения индексации ресурсов сайта Webflow, поскольку файл robots.txt должен находиться в том же домене, что и контент, к которому он применяется (в данном случае там, где обслуживаются ресурсы) . Webflow обслуживает ресурсы из нашей глобальной CDN, а не из пользовательского домена, в котором находится файл robots.txt.
Я удалил файл robots.txt из настроек своего сайта, но он по-прежнему отображается на моем опубликованном сайте. Как я могу это исправить?
Созданный файл robots.txt нельзя удалить полностью. Однако вы можете заменить его новыми правилами, чтобы разрешить сканирование сайта, например:
User-agent: *
Disallow:
Обязательно сохраните изменения и повторно опубликуйте свой сайт. Если проблема не устранена и вы по-прежнему видите старые правила robots.txt на своем опубликованном сайте, обратитесь в службу поддержки.