Содержание
Как спарсить ссылку на Python?
Всем добрый день. Пишу скрипт на Python, который парсит сайт магазина Лента https://lenta.com/
В разных городах в ассортименте разные товары. Подскажите, как получить ссылку определённого города, чтобы скрипт парсил именно эту ссылку, с этим городом?
- python
- python-3.x
- парсер
- requests
3
Посмотрел по ссылке и тот сайт, выбранный город и магазин, хранит в cookies, который будет передаваться в заголовке запроса Cookie.
Думаю, вам нужно заполнять в cookies следующие значения:
- lentaT2
- CityCookie
- Store
Вот так выглядит для Магнитогорска:
Cookie: .ASPXANONYMOUS=<...>; CustomerId=<...>; ReviewedSkus=<...>; ASP.NET_SessionId=<...>; lentaT2=mgn; CityCookie=mgn; Store=0074
А вот так для Санкт-Петербурга:
Cookie: .ASPXANONYMOUS=<...>; CustomerId=<...>; ReviewedSkus=<...>; ASP.NET_SessionId=<...>; lentaT2=spb; CityCookie=spb; Store=0718
 ASPXANONYMOUS=<...>; CustomerId=<...>; ReviewedSkus=<...>; ASP.NET_SessionId=<...>; lentaT2=spb; CityCookie=spb; Store=0718
ASPXANONYMOUS=<...>; CustomerId=<...>; ReviewedSkus=<...>; ASP.NET_SessionId=<...>; lentaT2=spb; CityCookie=spb; Store=0718
В requests куки передаются параметром как словарь, пример из документации:
>>> url = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'
PS.
Советую:
- Заполнять HTTP заголовок
User-Agent, так ваш скрипт будет сложнее отличить от обычного клиента,requestsавтоматически отправляет этот заголовок, но в нем указывает себя и свою версию - Использовать requests.Session, этот объект помнить куки, что ему сервер возвращал и сам их отправляет в запросах
4
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
парсер — Как спарсить данные с сайта, если есть определенное кол-во ссылок? (python)
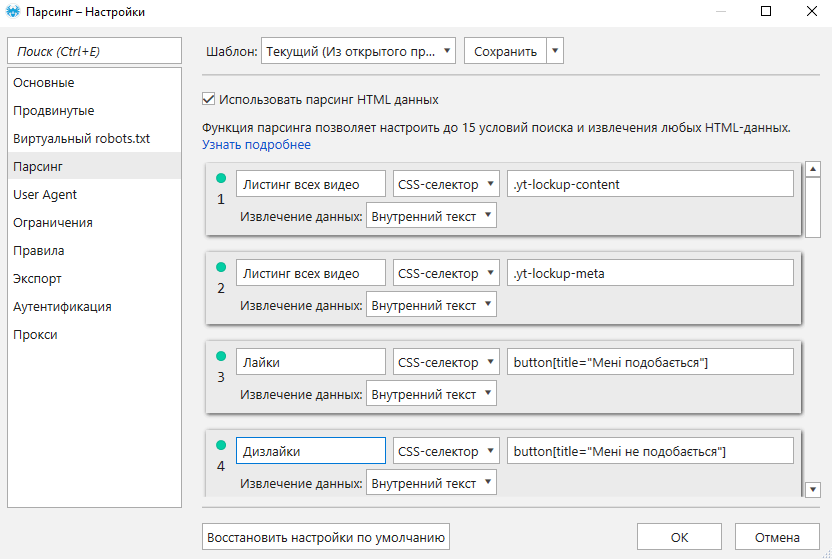
Есть код на Python, я взял его с интернета, чуть-чуть допилил для себя, но сейчас возник один вопрос.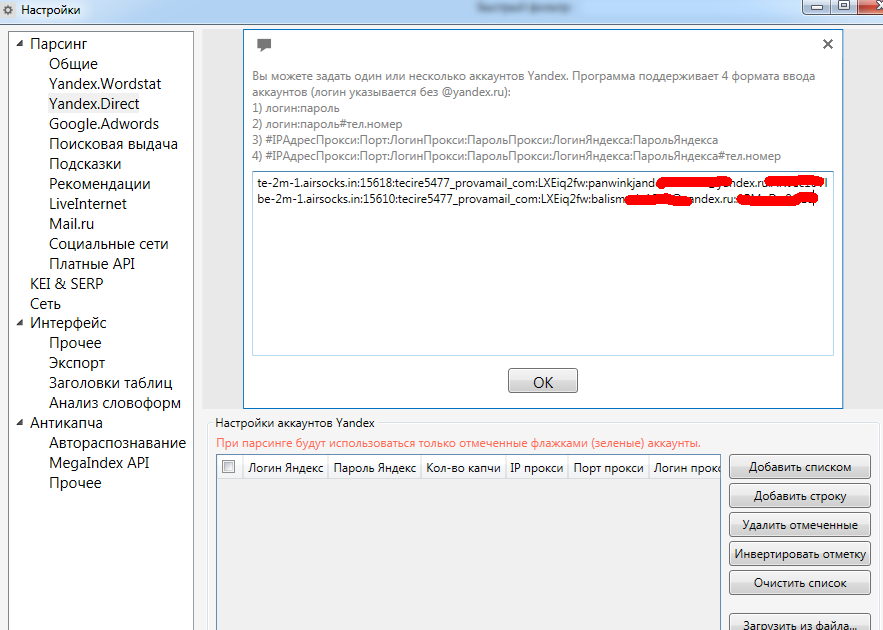
У меня есть ссылки с которых нужно спарсить данные, я в питоне совсем зеленый, не знаю как задавать вопросы в гугле, чтобы правильно получить ответы…
Так вот: имеем сейчас код, который парсит данные с одной ссылки, а надо чтобы он парсил данные со всех ссылок, которые я вставлю, но пока не знаю как это реализовать..(
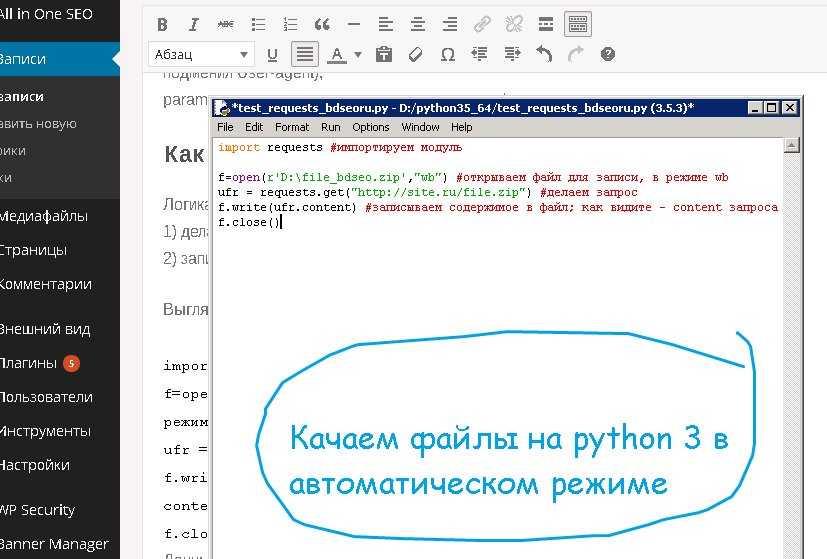
"""Парсинг сайтов"""
import requests # для работы с запросами.
from bs4 import BeautifulSoup # разбирает HTML страницу, делает из неё объект.
import csv # для создания файла, который можно потом открыть в EXEL или OpenOffice.
FILE_NAME = 'toys.csv'
HOST = 'https://www.miele.ru' # сайт, который мы будем пастить.
URL = 'https://www.miele.ru/domestic/oven-1451.htm?mat=11124400&name=H_7164_BP' # url страницы,которую будем пастить.
# Прописываем заголовки, чтобы сайт не подумал, что мы бот.
HEADERS = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0. 9',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'
}
# обращение к странице, чтобы получить HTML.
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params) # запрашиваем данные со страницы.
return r
# получаем контент со страницы (c одной).
def get_content(html):
soup = BeautifulSoup(html, 'html.parser') # сохраняем объект страницы.
items = soup.find_all('div', class_='cc-productDetailHead')
toys = []
for item in items:
toys.append(
{
'title': item.find('div').text,
'model': item.find('strong').text,
'price': item.find('div', class_='priceWrapper').text,
#'linc': HOST + item.find('div', class_='cc-product-tile__button-wrapper').find('a').get('href'),
'photo': item.find('a', class_='cloud-zoom-gallery active main').get('href'),
'othphoto': item. find_all('a', class_='cloud-zoom-gallery')[1].get('href')
}
)
return toys
# Промежуточный тест:
# html = get_html(URL)
# print(get_content(html.text))
""" Функция записи данных """
def save_doc(items, path):
with open(path, 'w', newline='') as file:
writer = csv.writer(file, delimiter=';', dialect='excel')
writer.writerow(['name : Название', 'product_model', 'price : Цена', 'image : Иллюстрация', 'othphoto']) # Первая строка.
for item in items:
writer.writerow([item['title'], item['model'], item['price'], item['photo'], item['othphoto']])
""" Основная функция парсинга """
def pars():
page_count = int(input('Укажите количество страниц для парсинга: '))
html = get_html(URL)
if html.status_code == 200: # Проверям приходят ли к нам данные со страницы.
toys = []
for page in range(1, page_count + 1):
print(f'Парсим {page} страницу')
params = '?count=9&PAGEN_3=' + str(page)
html = get_html(URL + params)
toys. extend(get_content(html.text))
print('Парсинг закончен.')
save_doc(toys, FILE_NAME)
else:
print('ERROR !')
pars()
""" Функция чтения csv файла в консоль """
with open("toys.csv") as r_file:
# Создаем объект словарь, указываем символ-разделитель ","
file_reader = csv.DictReader(r_file, delimiter=";")
# Счетчик для подсчета количества строк и вывода заголовков столбцов
count = 0
# Считывание данных из CSV файла
for row in file_reader:
if count == 0:
# Вывод строки, содержащей заголовки для столбцов.
print(' ', " \
".join(row))
# Вывод содержимого строки по ключу.
print(f' {row["name : Название"]} -- {row["product_model"]} -- {row["price : Цена"]}\
-- {row["image : Иллюстрация"]} -- {row["othphoto"]}')
count += 1
 9',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'
}
# обращение к странице, чтобы получить HTML.
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params) # запрашиваем данные со страницы.
return r
# получаем контент со страницы (c одной).
def get_content(html):
soup = BeautifulSoup(html, 'html.parser') # сохраняем объект страницы.
items = soup.find_all('div', class_='cc-productDetailHead')
toys = []
for item in items:
toys.append(
{
'title': item.find('div').text,
'model': item.find('strong').text,
'price': item.find('div', class_='priceWrapper').text,
#'linc': HOST + item.find('div', class_='cc-product-tile__button-wrapper').find('a').get('href'),
'photo': item.find('a', class_='cloud-zoom-gallery active main').get('href'),
'othphoto': item.
9',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'
}
# обращение к странице, чтобы получить HTML.
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params) # запрашиваем данные со страницы.
return r
# получаем контент со страницы (c одной).
def get_content(html):
soup = BeautifulSoup(html, 'html.parser') # сохраняем объект страницы.
items = soup.find_all('div', class_='cc-productDetailHead')
toys = []
for item in items:
toys.append(
{
'title': item.find('div').text,
'model': item.find('strong').text,
'price': item.find('div', class_='priceWrapper').text,
#'linc': HOST + item.find('div', class_='cc-product-tile__button-wrapper').find('a').get('href'),
'photo': item.find('a', class_='cloud-zoom-gallery active main').get('href'),
'othphoto': item. find_all('a', class_='cloud-zoom-gallery')[1].get('href')
}
)
return toys
# Промежуточный тест:
# html = get_html(URL)
# print(get_content(html.text))
""" Функция записи данных """
def save_doc(items, path):
with open(path, 'w', newline='') as file:
writer = csv.writer(file, delimiter=';', dialect='excel')
writer.writerow(['name : Название', 'product_model', 'price : Цена', 'image : Иллюстрация', 'othphoto']) # Первая строка.
for item in items:
writer.writerow([item['title'], item['model'], item['price'], item['photo'], item['othphoto']])
""" Основная функция парсинга """
def pars():
page_count = int(input('Укажите количество страниц для парсинга: '))
html = get_html(URL)
if html.status_code == 200: # Проверям приходят ли к нам данные со страницы.
toys = []
for page in range(1, page_count + 1):
print(f'Парсим {page} страницу')
params = '?count=9&PAGEN_3=' + str(page)
html = get_html(URL + params)
toys.
find_all('a', class_='cloud-zoom-gallery')[1].get('href')
}
)
return toys
# Промежуточный тест:
# html = get_html(URL)
# print(get_content(html.text))
""" Функция записи данных """
def save_doc(items, path):
with open(path, 'w', newline='') as file:
writer = csv.writer(file, delimiter=';', dialect='excel')
writer.writerow(['name : Название', 'product_model', 'price : Цена', 'image : Иллюстрация', 'othphoto']) # Первая строка.
for item in items:
writer.writerow([item['title'], item['model'], item['price'], item['photo'], item['othphoto']])
""" Основная функция парсинга """
def pars():
page_count = int(input('Укажите количество страниц для парсинга: '))
html = get_html(URL)
if html.status_code == 200: # Проверям приходят ли к нам данные со страницы.
toys = []
for page in range(1, page_count + 1):
print(f'Парсим {page} страницу')
params = '?count=9&PAGEN_3=' + str(page)
html = get_html(URL + params)
toys. extend(get_content(html.text))
print('Парсинг закончен.')
save_doc(toys, FILE_NAME)
else:
print('ERROR !')
pars()
""" Функция чтения csv файла в консоль """
with open("toys.csv") as r_file:
# Создаем объект словарь, указываем символ-разделитель ","
file_reader = csv.DictReader(r_file, delimiter=";")
# Счетчик для подсчета количества строк и вывода заголовков столбцов
count = 0
# Считывание данных из CSV файла
for row in file_reader:
if count == 0:
# Вывод строки, содержащей заголовки для столбцов.
print(' ', " \
".join(row))
# Вывод содержимого строки по ключу.
print(f' {row["name : Название"]} -- {row["product_model"]} -- {row["price : Цена"]}\
-- {row["image : Иллюстрация"]} -- {row["othphoto"]}')
count += 1
extend(get_content(html.text))
print('Парсинг закончен.')
save_doc(toys, FILE_NAME)
else:
print('ERROR !')
pars()
""" Функция чтения csv файла в консоль """
with open("toys.csv") as r_file:
# Создаем объект словарь, указываем символ-разделитель ","
file_reader = csv.DictReader(r_file, delimiter=";")
# Счетчик для подсчета количества строк и вывода заголовков столбцов
count = 0
# Считывание данных из CSV файла
for row in file_reader:
if count == 0:
# Вывод строки, содержащей заголовки для столбцов.
print(' ', " \
".join(row))
# Вывод содержимого строки по ключу.
print(f' {row["name : Название"]} -- {row["product_model"]} -- {row["price : Цена"]}\
-- {row["image : Иллюстрация"]} -- {row["othphoto"]}')
count += 1
Документация JDK 20 — Главная
- Главная
- Ява
- Java SE
- 20
Обзор
- Прочтите меня
- Примечания к выпуску
- Что нового
- Руководство по миграции
- Загрузить JDK
- Руководство по установке
- Формат строки версии
Инструменты
- Технические характеристики инструментов JDK
- Руководство пользователя JShell
- Руководство по JavaDoc
- Руководство пользователя средства упаковки
Язык и библиотеки
- Обновления языка
- Основные библиотеки
- HTTP-клиент JDK
- Учебники по Java
- Модульный JDK
- Руководство программиста API бортового регистратора
- Руководство по интернационализации
Технические характеристики
- Документация API
- Язык и ВМ
- Имена стандартных алгоритмов безопасности Java
- банок
- Собственный интерфейс Java (JNI)
- Инструментальный интерфейс JVM (JVM TI)
- Сериализация
- Проводной протокол отладки Java (JDWP)
- Спецификация комментариев к документации для стандартного доклета
- Прочие характеристики
Безопасность
- Руководство по безопасному кодированию
- Руководство по безопасности
Виртуальная машина HotSpot
- Руководство по виртуальной машине Java
- Настройка сборки мусора
Управление и устранение неполадок
- Руководство по устранению неполадок
- Руководство по мониторингу и управлению
- Руководство по JMX
Client Technologies
- Руководство по специальным возможностям Java
Бесплатный онлайн-анализатор URL-адресов / Разделитель строк запроса
Что такое URI?
Унифицированные идентификаторы ресурсов (URI) используются для идентификации «имен» или «ресурсов». Они бывают двух видов: URN и URL. На самом деле URI может быть и именем, и локатором!
Они бывают двух видов: URN и URL. На самом деле URI может быть и именем, и локатором!
Что такое URL?
Унифицированные указатели ресурсов (URL) позволяют найти ресурс с использованием определенной схемы, чаще всего, но не ограничиваясь ею, с помощью HTTP. Просто подумайте об URL-адресе как об адресе ресурса, а о схеме — как о том, как туда добраться.
Что такое URN?
Единые имена ресурсов — это идентификаторы ресурсов. Они не зависят от местоположения и используют схему urn:.
Каков синтаксис URI?
схема:специфичная-схема-часть?запрос#фрагмент
Примеры:
- ftp://ftp.is.co.za/rfc/rfc1808.txt
- http://www.ietf.org/rfc/rfc2396.txt
- ldap://[2001:db8::7]/c=GB?objectClass?one
- новости:comp.infosystems.www.servers.unix
- тел:+1-816-555-1212
- телнет://192.0.2.16:80/
- urn:oasis:names:specification:docbook:dtd:xml:4.1.2
Каков синтаксис URL?
схема://имя пользователя:[электронная почта защищена]:порт/путь/имя-файла. суффикс?строка-запроса#хэш
суффикс?строка-запроса#хэш
Примеры:
- http://www.google.com
- http://foo:[email protected]/very/long/path.html?p1=v1&p2=v2#more-details
- https://secured.com:443
- ftp://ftp.bogus.com/~some/path/to/a/file.txt
Каков синтаксис URN?
urn:namespame-identifier:namespace-specific-string
Примеры из Википедии:
- urn:isbn:0451450523
- urn:ietf:rfc:2648
- урна:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66
Что такое «информация о пользователе» в URL-адресе?
Часть URL-адреса userinfo состоит из имени пользователя и/или пароля . Они необязательны и используются для аутентификации. Информация о пользователе имеет формат имя пользователя: пароль, за которым следует символ @ и имя хоста. Пароль является необязательным, что часто приводит к запросу пользовательского интерфейса на ввод пароля.
Примеры:
- ftp:// имя пользователя:пароль @host. com/
- ftp:// имя пользователя @host.com/
 com/
com/Что такое «авторитет» в URL-адресе?
Авторитет URL состоит из userinfo , имени хоста и порта . userinfo и порт являются необязательными. Если порт отсутствует, предполагается порт по умолчанию для конкретной схемы. Например порт 80 для http или 443 для https.
Примеры:
- имя пользователя:[электронная почта защищена]/
- субдомен.домен.com
- www.superaddress.com:8080
Что такое «фрагмент» в URL-адресе?
Фрагмент, также известный как хэш, представляет собой указатель на вторичный ресурс с первым ресурсом. Он следует за символом #.
Примеры:
- http://www.foo.bar/?listings.html #section-2
Что такое «путь» в URL-адресе?
Путь URL состоит из сегментов, представляющих структурированную иерархию.