Содержание
Парсинг сайтов в Excel в 2022: пошаговая инструкция
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML.
 Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое; - IMPORTHTML. Позволяет получить данные из таблиц и списков.
 Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
Нас интересует список постов, поэтому открываем первую ссылку.
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
После этого пытаемся получить название товара, которое содержится в h2, единственным на странице, поэтому запрос должен быть:
//h2
И как следствие формула:
=IMPORTXML(A2;»//h2″)
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:
Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h2″)
IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
Теперь просматриваем код таблицы, которая заключена в теге <table>.
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
В данном случае речь идет о меню, которое также представлено в виде списка.
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
Парсинг нетабличных данных с сайтов
12832
15.01.2021
Скачать пример
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.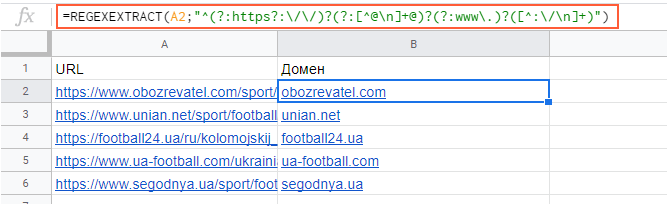 wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:
… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):
Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
Например, так:
- Удалить заменой на пустоту начальный тег: <span> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:
- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.
В итоге получим наши данные в уже гораздо более презентабельном виде:
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.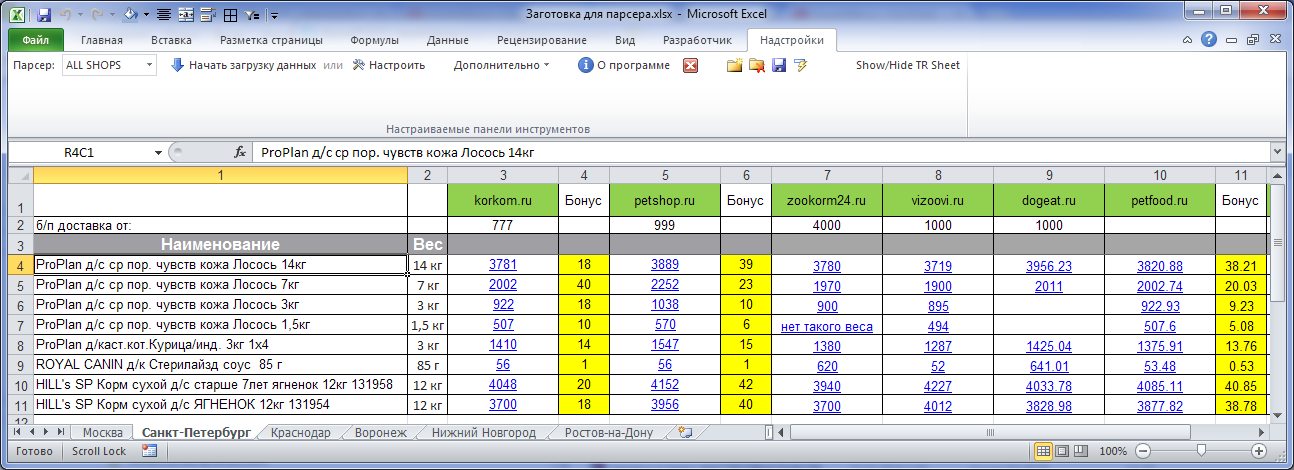
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)
Вот и все хитрости 🙂
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
Извлечение данных с веб-сайта в Excel (учебник 2022 г.
 )
)
Независимо от того, являетесь ли вы цифровым аборигеном или иммигрантом, вы, вероятно, знаете основные функции Excel наизнанку. С помощью Excel легко выполнять простые задачи, такие как сортировка, фильтрация и структурирование данных, а также создание на их основе диаграмм. Когда данные хорошо структурированы, мы можем даже выполнять расширенный анализ данных, используя сводные и регрессионные модели в Excel.
Но проблема в том, как мы можем извлечь масштабируемые данные и эффективно поместить их в Excel? Это было бы чрезвычайно утомительной задачей, если бы она выполнялась вручную путем повторного ввода, поиска, копирования и вставки. Итак, как мы можем добиться автоматического извлечения данных и парсинга с веб-сайтов в Excel?
В этой статье вы можете узнать о 3 способах извлечения данных с веб-сайтов в Excel , чтобы сэкономить ваше время и энергию.
Содержание
- Автоматический парсинг веб-сайтов в Excel
- Получение веб-данных с помощью веб-запросов Excel
- Очистка веб-данных с помощью Excel VBA
Автоматическое копирование веб-сайтов в Excel
Если вы ищете быстрый инструмент для извлечения данных со страниц в Excel, но не разбираетесь в кодировании, попробуйте Octoparse , инструмент автоматической очистки, который может очищать данные веб-сайта и экспортировать их в рабочие листы Excel либо напрямую, либо через API. Загрузите Octoparse на свое устройство Windows или Mac и сразу приступайте к извлечению данных веб-сайта, выполнив простые шаги, описанные ниже. Или вы можете прочитать пошаговое руководство по очистке веб-страниц.
Загрузите Octoparse на свое устройство Windows или Mac и сразу приступайте к извлечению данных веб-сайта, выполнив простые шаги, описанные ниже. Или вы можете прочитать пошаговое руководство по очистке веб-страниц.
Автоматическое извлечение данных с веб-сайта в Excel с помощью Octoparse
- Шаг 1: Скопируйте и вставьте ссылку веб-сайта на панель продуктов Octoparse и запустите автоматическое определение.
- Шаг 2: Настройте поле данных, которое вы хотите очистить, вы также можете настроить рабочий процесс вручную.
- Шаг 3: Запустите задачу после того, как вы проверили, вы можете загрузить данные в формате Excel или других форматах через несколько минут.
Видеоруководство. Эффективное извлечение веб-данных в Excel
 youtube.com/embed/-A-A7HVYz5k?autoplay=1" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""></iframe></p>»>
youtube.com/embed/-A-A7HVYz5k?autoplay=1" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""></iframe></p>»>
Служба поддержки клиентов проекта Web Scraping
лучшим вариантом может быть работа с опытной командой веб-скрейпинга, у которой есть опыт и знания. Соскребать данные с веб-сайтов сложно из-за того, что наличие ботов, защищающих от соскребания, будет ограничивать практику парсинга веб-страниц. Квалифицированная команда веб-парсинга поможет вам правильно получить данные с веб-сайтов и доставить вам структурированные данные в виде листа Excel или в любом нужном вам формате.
Вот несколько историй клиентов о том, как служба парсинга веб-страниц Octoparse помогает предприятиям любого размера.
Получение веб-данных с помощью веб-запросов Excel
За исключением преобразования данных с веб-страницы вручную путем копирования и вставки, веб-запросы Excel используются для быстрого извлечения данных со стандартной веб-страницы на рабочий лист Excel. Он может автоматически обнаруживать таблицы, встроенные в HTML-код веб-страницы. Веб-запросы Excel также можно использовать в ситуациях, когда стандартное соединение ODBC (Open Database Connectivity) сложно создать или поддерживать. Вы можете напрямую извлечь таблицу с любого веб-сайта с помощью веб-запросов Excel.
Он может автоматически обнаруживать таблицы, встроенные в HTML-код веб-страницы. Веб-запросы Excel также можно использовать в ситуациях, когда стандартное соединение ODBC (Open Database Connectivity) сложно создать или поддерживать. Вы можете напрямую извлечь таблицу с любого веб-сайта с помощью веб-запросов Excel.
Здесь перечислены простые шаги по извлечению данных веб-сайта с помощью веб-запросов Excel. Или вы можете проверить по этой ссылке: http://www.excel-university.com/pull-external-data-into-excel/.
1. Выберите Данные > Получить внешние данные > Из Интернета.
2. Появится окно браузера под названием «Новый веб-запрос».
3. В адресной строке напишите веб-адрес.
(изображение с сайта excel-university.com)
4. Страница загрузится, и рядом с данными/таблицами появятся желтые значки.
5. Выберите подходящий.
6. Нажмите кнопку Импорт.
Теперь у вас есть веб-данные, сохраненные в листе Excel, идеально организованные в строки и столбцы по вашему желанию.
Очистка веб-данных с помощью Excel VBA
Большинство из нас использовали бы формулы в Excel (например, =avg(…), =sum(…), =if(…), и т. д.) много, но менее знакомы со встроенным языком — Visual Basic for Application, также известным как VBA. Он широко известен как «Макросы», и такие файлы Excel сохраняются как **.xlsm. Прежде чем использовать его, вам нужно сначала включить вкладку «Разработчик» на ленте (щелкните правой кнопкой мыши «Файл» -> «Настроить ленту» -> проверьте вкладку «Разработчик»). Затем настройте макет. В этом интерфейсе разработчика вы можете писать код VBA, привязанный к различным событиям. Нажмите ЗДЕСЬ (https://msdn.microsoft.com/en-us/library/office/ee814737(v=office.14).aspx), чтобы начать работу с VBA в Excel 2010.
Использование Excel VBA будет немного техническим — это не очень удобно для непрограммистов среди нас. VBA работает, запуская макросы, пошаговые процедуры, написанные в Excel Visual Basic. Чтобы очистить данные с веб-сайтов в Excel с помощью VBA, нам нужно создать или получить некоторый сценарий VBA для отправки некоторых запросов на веб-страницы и получения возвращаемых данных с этих веб-страниц. Обычно для анализа веб-страниц используется VBA с XML, HTTP и регулярными выражениями. В Windows вы можете использовать VBA с Win HTTP или Internet Explorer для очистки данных с веб-сайтов в Excel.
Чтобы очистить данные с веб-сайтов в Excel с помощью VBA, нам нужно создать или получить некоторый сценарий VBA для отправки некоторых запросов на веб-страницы и получения возвращаемых данных с этих веб-страниц. Обычно для анализа веб-страниц используется VBA с XML, HTTP и регулярными выражениями. В Windows вы можете использовать VBA с Win HTTP или Internet Explorer для очистки данных с веб-сайтов в Excel.
Приложив немного терпения и практики, вы сочтете целесообразным изучить некоторый код Excel VBA и некоторые знания HTML, чтобы упростить парсинг веб-страниц в Excel и сделать его более эффективным для автоматизации повторяющейся работы. Существует множество материалов и форумов, на которых вы можете научиться писать код VBA.
Связанные ресурсы
20 лучших инструментов веб-сканирования для извлечения веб-данных
30 лучших бесплатных программ для веб-скрейпинга
10 простых функций Excel для анализа данных
Как извлечь данные из PDF в Excel
Excel Web Scraping — использование MS Excel для очистки веб-сайтов
Microsoft Excel, несомненно, является одним из лучших инструментов очистки python для управления информацией в структурированном виде. форма. Excel похож на швейцарский армейский нож данных с его замечательными функциями и возможностями. Вот как можно использовать MS Excel в качестве базового инструмента для извлечения веб-данных непосредственно на лист. Для этого мы будем использовать веб-запросы Excel.
форма. Excel похож на швейцарский армейский нож данных с его замечательными функциями и возможностями. Вот как можно использовать MS Excel в качестве базового инструмента для извлечения веб-данных непосредственно на лист. Для этого мы будем использовать веб-запросы Excel.
Функция веб-запросов MS Excel используется для извлечения данных веб-сайта для Excel и может быть легко извлечена на рабочий лист. Он может автоматически находить таблицы на веб-странице и позволит вам выбрать конкретную таблицу, из которой вам нужны данные. Веб-запросы также могут быть полезны в ситуациях, когда невозможно поддерживать соединение ODBC, за исключением простого извлечения данных с веб-страниц. Давайте посмотрим, как работают веб-запросы и как вы можете сканировать HTML-таблицы и использовать MS Excel как лучший инструмент для парсинга в python.
Объяснение веб-скрейпинга Excel
Мы начнем с простого веб-запроса для сканирования данных со страницы Yahoo Finance. Эту страницу особенно легко сканировать, и поэтому она хорошо подходит для изучения метода. Страница также довольно проста и не содержит важной информации в виде ссылок или изображений. Вот обучающее видео по использованию MS Excel в качестве инструмента для очистки веб-страниц .
Страница также довольно проста и не содержит важной информации в виде ссылок или изображений. Вот обучающее видео по использованию MS Excel в качестве инструмента для очистки веб-страниц .
1) Создать новый веб-запрос
1. Выберите ячейку, в которой должны отображаться данные
2. Нажмите «Данные» > «Из Интернета»
3. Появится окно «Новый веб-запрос», как показано ниже
4. Введите URL-адрес веб-страницы, из которой необходимо извлечь данные, в адресной строке и нажмите кнопку «Перейти»
5. Нажмите на желто-черные кнопки рядом с таблицей, из которой нужно извлечь данные. Теперь Excel начнет загружать содержимое выбранных таблиц на ваш рабочий лист 9.0003
После того, как данные будут сохранены на листе Excel, вы сможете делать множество вещей, таких как создание диаграмм, сортировка, форматирование и т. д., чтобы лучше понять или представить данные в более простом виде.
2) Настройка запроса
После создания веб-запроса у вас есть возможность настроить его в соответствии с вашими требованиями. Для этого откройте свойства веб-запроса, щелкнув правой кнопкой мыши ячейку с извлеченными данными. Страница, которую вы запрашивали, появится снова, нажмите кнопку «Параметры» справа от адресной строки. Появится новое всплывающее окно, в котором вы можете настроить взаимодействие веб-запроса с целевой страницей. Параметры здесь позволяют вам изменить некоторые основные вещи, связанные с веб-страницами, такие как форматирование и перенаправление.
Для этого откройте свойства веб-запроса, щелкнув правой кнопкой мыши ячейку с извлеченными данными. Страница, которую вы запрашивали, появится снова, нажмите кнопку «Параметры» справа от адресной строки. Появится новое всплывающее окно, в котором вы можете настроить взаимодействие веб-запроса с целевой страницей. Параметры здесь позволяют вам изменить некоторые основные вещи, связанные с веб-страницами, такие как форматирование и перенаправление.
Помимо этого, вы также можете изменить параметры диапазона дат, щелкнув правой кнопкой мыши случайную ячейку с результатами запроса и выбрав Свойства диапазона данных. Появится диалоговое окно свойств диапазона данных, где вы можете внести необходимые изменения. Возможно, вы захотите переименовать диапазон данных во что-то, что вы легко узнаете, например «Цены на акции».
3) Автообновление
Автообновление — это функция веб-запросов, о которой стоит упомянуть и которая делает наш парсер Excel по-настоящему мощным. Вы можете настроить автоматическое обновление извлеченных данных, чтобы лист Excel обновлял данные при каждом изменении исходного веб-сайта. Вы можете установить, как часто вам нужно обновлять данные с исходной веб-страницы в меню параметров диапазона данных. Функцию автоматического обновления можно включить, установив флажок рядом с «Обновлять каждые» и задав предпочтительный интервал времени для обновления данных.
Вы можете настроить автоматическое обновление извлеченных данных, чтобы лист Excel обновлял данные при каждом изменении исходного веб-сайта. Вы можете установить, как часто вам нужно обновлять данные с исходной веб-страницы в меню параметров диапазона данных. Функцию автоматического обновления можно включить, установив флажок рядом с «Обновлять каждые» и задав предпочтительный интервал времени для обновления данных.
Парсинг веб-страниц в масштабе
Хотя извлечение веб-данных с использованием лучших инструментов парсинга python может быть отличным способом сканирования HTML-таблиц с веб-сайтов в Excel, он и близко не подходит к корпоративному решению парсинга веб-страниц. Это может оказаться полезным, если вы собираете данные для исследовательской работы в колледже или являетесь любителем, ищущим бюджетный способ получить некоторые данные. Если вам нужны данные для бизнеса, вам придется полагаться на Служба извлечения веб-данных с опытом работы с веб-скрапингом в больших масштабах.