Содержание
Парсинг с помощью Python. Урок 1
Этим уроком мы начинаем курс, про который нас часто спрашивали — курс по парсингу данных с помощью Python. Мы уже рассказывали о парсинге без программирования, с помощью расширений для браузера, но их возможности ограничены и подходят не для всех сайтов. А вот Python поможет вам спарсить практически что угодно.
Съемка и монтаж: Глеб Лиманский
Чтобы правильно парсить, нужно понимать, как устроены сайты. Почти все они сверстаны с помощью языка HTML. Разберемся в его устройстве на примере сайта «КиноПоиск» и попробуем спарсить список из 250 лучших фильмов по версии пользователей сайта.
Похожим на «КиноПоиск» образом устроены многие сайты, с которых журналистам бывает необходимо собрать данные, поэтому он хорошо подойдет для примера.
Для этого курса мы используем браузер Google Chrome, поэтому, чтобы вам было проще понимать наши действия и не путаться в названиях функций, советуем использовать его же. Но в других браузерах, Firefox или Opera, например, все эти функции тоже есть.
Но в других браузерах, Firefox или Opera, например, все эти функции тоже есть.
Если вы кликнете на любое место сайта правой кнопкой мыши и нажмете на «Посмотреть код», то справа появится панель с кодом HTML (ее еще называют панелью разработчика).
Этот язык строится по тегам. Главный — html, в head обычно прописана метаинформация (заголовок, например), а нас сейчас интересует тег body, где лежит основная информация страницы.
Чтобы посмотреть код конкретного элемента, нужно кликнуть именно на него и нажать «Посмотреть код» — тогда в панели разработчика подсветится нужный тег.
И наоборот, если двигаться по коду в панели справа, то слева, на самой странице, будет подсвечиваться сверстанный этим тегом элемент.
На страницах со списками одни и те же теги (название, оценка и так далее) повторяются от карточки к карточке. Поэтому нужно обнаружить и выписать эти конкретные теги. Но сначала вытащим весь код страницы, и здесь пригодится библиотека Requests — мы уже рассказывали о ней, советуем сначала прочитать тот урок и установить ее.
Открываем Jupyter, импортируем библиотеку с помощью import requests. Чтобы обратиться к сайту, создаем переменную url и присваиваем ей значение нужного сайта (у нас это ссылка на топ «КиноПоиска»).
Отправим на сервер запрос с помощью команды get, на вход которой мы передаем переменную url. С помощью команды text посмотрим, что получилось.
Как видите, код получился нечитаемым. Справиться с этим поможет другая библиотека, Beautifulsoup. Импортируем ее с помощью команды from bs4 import BeautifulSoup. Возможно, для этого понадобится сначала установить библиотеку через pip install.
Мы должны передать библиотеке ответ, полученный с помощью Requests. Создадим переменную soup, передадим r.text и укажем необходимый формат (в нашем случае lxml).
Код упорядочен, теги идут один за одним — теперь мы можем вынимать из кода то, что нам нужно. Для этого вернемся в браузер, на страницу с данными. Как видно на скриншоте, подряд расположены несколько тегов div с классом desktop-rating-selection-file-item — это карточка каждого из фильмов в списке.
Для этого вернемся в браузер, на страницу с данными. Как видно на скриншоте, подряд расположены несколько тегов div с классом desktop-rating-selection-file-item — это карточка каждого из фильмов в списке.
Сначала вытащим данные только из первой карточки, а затем перепишем код так, чтобы он сработал на все фильмы со страницы. Скопируем название класса — для этого два раза кликните на него мышкой и нажмите Ctrl+C (Cmd+C для macOS).
В Beautifulsoup есть команда find — укажем ей нужный тег (div) и через запятую класс (desktop-rating-selection-file-item). После class обязательно нужно поставить нижнее подчеркивание.
Отобразился уже не весь код, а только нужный элемент, в котором видно название фильма. Вернемся на сайт, чтобы углубиться в карточку и посмотреть, как называются нужные нам детали. Кликнем на название фильма «Зеленая миля» и снова выберем «Посмотреть код».
Например, мы видим, что ссылка на фильм лежит в теге a и имеет собственный класс selection-film-item-meta__link. В теге a, в свою очередь, есть теги p с русским и оригинальным названиями фильмов. Эти три элемента мы и заберем.
Дополним нашу первую команду: ставим точку, снова пишем find, указываем тег a и его класс.
Чтобы сделать ссылку на фильм работающей, в начале нужно дописать к ней домен. Сама ссылка лежит внутри тега, поэтому find мы применить не сможем. Воспользуемся командой get и укажем нужный атрибут (в нашем случае href).
Допишем в начало команды домен «КиноПоиска» и запустим еще раз — так мы получим готовую ссылку. Положим этот код в переменную link.
По аналогии достанем русскоязычное и оригинальное названия. Возьмем тот же код, допишем новый find, укажем нужные тег и класс. Чтобы очистить результат от ненужных элементов кода, добавим в конце команду text. Эти переменные назовем russian_name и original_name соответственно.
Чтобы очистить результат от ненужных элементов кода, добавим в конце команду text. Эти переменные назовем russian_name и original_name соответственно.
Еще мы можем достать из карточки страну производства и жанр — все будет работать точно так же, только класс будет не p, как у названий, а span. Страну положим в переменную country.
Однако в коде «КиноПоиска» страна и жанр имеют одинаковый класс selection-film-item-meta__meta-additional-item — а команда find находит только первое соответствие вашему запросу. Применим команду findAll, а все остальное оставим как раньше, чтобы получить список.
Чтобы вытащить только жанр, добавим нумерацию в квадратных скобках (не забывайте, что в Python отсчет идет с 0, поэтому нам нужен номер 1) и команду text. Переменную назовем film_type.
Основную информацию о фильме мы достали, но можем получить и кое-что еще — например, оценку. Проверим, как называется класс этого элемента на странице «КиноПоиска» с помощью уже известного метода «Посмотреть код». Как видите, нам повезло — класс имеет уникальное название, глубоко копать не придется.
Скопируем ту часть изначальной команды find, где мы заходим в первый div карточки фильма и сразу укажем новый поиск по тегу span и классу rating__value rating__value_positive (и не забудем про text). Переменную назовем rate.
Мы уже сделали почти всю работу, но пока что наш код работает только для первой карточки фильма в списке. Исправим это. Создадим переменную films, зададим новый поиск по самому первому div, но уже с командой findAll. И заодно посмотрим длину списка с помощью команды len. Их будет 50, потому что список топ-250 разбит на 5 страниц. Далее мы научим код ходить и по другим страницам.
Далее мы научим код ходить и по другим страницам.
Напишем цикл для каждого film в списке films. Пока скопируем команду по поиску link и посмотрим, что там нужно поправить. Нам не нужен запрос к первому div, потому что до этого мы обратились к нему через findAll — заменим его на film. Повторим так с каждым элементом.
Создадим переменную data, в который будем добавлять все переменные, которые запрашиваем.
Запустим код и посмотрим, что отображается в data.
Все ровно так, как нам было нужно. Осталось только разобраться, как собирать данные и со следующих страниц. Если мы перейдем на вторую страницу списка, то увидим, что ссылка в адресной строке браузера изменилась — там появилось page=2.
То есть, нам нужно передать этот параметр в цикл. Создадим перед циклом переменную url и воспользуемся методом f-строк, чтобы поместить внутрь фигурных скобок тот параметр, который нам нужен — номер страницы. Назовем параметр p и поместим его в цикл в промежутке от 1 до 6.
Назовем параметр p и поместим его в цикл в промежутке от 1 до 6.
Переменную data при этом нужно вынести в начало кода, чтобы она не перезаписывалась с каждым новым циклом, а дополнялась. После этого скопируем код для запуска Requests и Beautifulsoup.
Извините, на скрине ошибка: последнее значение в range должно быть 6, иначе скрипт пройдет только по четырем страницам
Код готов к работе. Но еще мы советуем добавить временные промежутки между запросами, чтобы не перегружать сервер, к которому обращаемся. Вернемся в область, где ранее импортировали Beautifulsoup, и импортируем из библиотеки time функцию sleep.
В основной код допишем, чтобы между запросами проходило 3 секунды. Чтобы в реальном времени проверить работоспособность скрипта, добавим команду print.
Ошибка с позапрошлого скрина исправлена: последнее значение в range — 6, поэтому скрипт прошел по всем пяти страницам
Все должно сработать. Если сейчас снова проверить длину нашего списка командой len(data), там будет 250 — как и в топе «КиноПоиска». Теперь сохраним наши данные в таблицу. Снова вернемся в область импорта и добавим туда Pandas и используем его для записи в csv.
Если сейчас снова проверить длину нашего списка командой len(data), там будет 250 — как и в топе «КиноПоиска». Теперь сохраним наши данные в таблицу. Снова вернемся в область импорта и добавим туда Pandas и используем его для записи в csv.
Введем названия для колонок — пусть они дублируют названия переменных, которые мы присвоили ранее (не забудьте поместить их в ‘кавычки’). И после этого экспортируем наши данные.
Код для импорта данных в таблицу csv
Итоговая таблица в csv
Последнее, что мы разберем на этом уроке — как научить код не ломаться и продолжать работу, если у фильма не будет указано какого-то из параметров. Пропишем, например, исключение для рейтинга фильма (rate) — если его нет, будет стоять прочерк.
«КиноПоиск» поддался нашему скрипту без проблем, но бывают сайты, запросы с которых не хотят отдавать нам необходимую информацию. Как с этим справиться — расскажем в следующих уроках.
Если у вас что-то не получилось — пишите в наш Telegram-чат, постараемся подсказать.
Руководство по парсингу веб-сайтов в 2021 году — Маркетинг на vc.ru
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов. Тема парсинга в последнее время становится все более востребованной и в этой статье мы хотим дать общий обзор подходов и механизмов парсинга данных, учитывая правовые особенности.
10 299
просмотров
За последнее десятилетие данные стали ресурсом для развития бизнеса, а Интернет — их основным источником благодаря пяти миллиардам пользователей, формирующим миллиарды фрагментов данных каждую секунду. Анализ данных Всемирной паутины может помочь компаниям выявлять скрытые закономерности, позволяющие им добиваться выполнения своих целей. Однако сбор большого объема данных — непростая для компаний задача, особенно для тех, которые думают, что кнопка «Экспортировать в Excel» (если такая присутствует) и обработка данных вручную — единственные способы сбора данных.
Парсинг веб-сайтов позволяет компаниям автоматизировать процессы сбора данных во Всемирной паутине, используя ботов или автоматические скрипты, называемые «обходчиками» веб-страниц, автоматическими сборщиками данных или веб-сборщиками (web crawlers). В этой статье раскрыты все важные аспекты парсинга веб-сайтов, включая понятие парсинга, почему он важен, как он работает, варианты применения, а также сведения о поставщиках парсеров и руководство по доступным к покупке программным продуктам и услугам.
Что такое парсинг веб-сайтов?
Парсинг веб-сайтов, который также называют сбором/извлечением данных, скрейпингом данных или содержимого экрана, добычей данных/интернет-данных и иногда обходом/сканированием Всемирной паутины, — это процесс извлечения данных из веб-сайтов.
Процесс парсинга веб-сайтов включает в себя отправку запросов на получение веб-страницы и извлечение из нее машиночитаемой информации.
Всё более широкое использование аналитики данных и автоматизации — существенные тенденции бизнеса. Парсинг веб-сайтов может стать движущей силой для обеих тенденций. Помимо этих причин, у парсинга веб-сайтов есть множество применений, которые могут повлиять на все отрасли. Парсинг веб-сайтов дает компаниям возможность:
Парсинг веб-сайтов может стать движущей силой для обеих тенденций. Помимо этих причин, у парсинга веб-сайтов есть множество применений, которые могут повлиять на все отрасли. Парсинг веб-сайтов дает компаниям возможность:
- автоматизировать процессы сбора данных в необходимом масштабе;
- получить доступ к источникам данных во Всемирной паутине, которые могут повысить эффективность вашего бизнеса;
- принимать решения, опираясь на данные.
Эти факторы объясняют возрастающий интерес к парсингу веб-сайтов, который можно наблюдать в Google Trends на представленном выше изображении.
Как осуществляется парсинг веб-сайтов?
Обычно процесс парсинга веб-сайтов состоит из следующих последовательных шагов:
- Идентификация целевых URL-адресов.
- Если веб-сайт, сканируемый для сбора данных, использует инструменты противодействия парсингу, то парсеру, возможно, придется выбрать подходящий прокси-сервер, чтобы получить новый IP-адрес, через который парсер будет отправлять свой запрос.

- Отправка запросов на эти URL-адреса для получения HTML-кода.
- Использование указателей для обнаружения местонахождения данных в HTML-коде.
- Аналитический разбор строки данных, которая содержит нужную информацию.
- Преобразование собранных данных в желаемый формат.
- Передача собранных данных в выбранное хранилище данных.

Для чего применяется парсинг веб-сайтов?
Распространенные варианты применения парсинга веб-сайтов перечислены ниже.
- Аналитика данных и наука о данных (data science).Сбор «тренировочных» данных для машинного обучения.Наполнение корпоративных баз данных.
- Маркетинг и продажи.Сравнение цен (особенно актуально в электронной коммерции).Извлечение описания товаров.Отслеживание в поисковых системах конкурентов и текущего состояния компаний в рамках усилий по поисковой оптимизации (SEO). Лидогенерация.Тестирование веб-сайтов.Отслеживание потребительских настроений.
- PR.Агрегация новостей о компании.
- Торговля.Сбор финансовых данных.
- Стратегическое планирование.Исследование рынка.
 Лидогенерация.Тестирование веб-сайтов.Отслеживание потребительских настроений.
Лидогенерация.Тестирование веб-сайтов.Отслеживание потребительских настроений.Как выглядит сфера парсинга веб-сайтов?
Чтобы называться компаний по парсингу веб-сайтов, поставщик подобных программных решений должен предоставлять возможность извлечения данных из множества интернет-ресурсов и возможность экспорта извлеченных данных в различные форматы. Да, сфера парсинга веб-сайтов переполнена, и есть разные способы решения задач по парсингу веб-сайтов на корпоративном уровне.
Инструменты
Решения с открытым исходным кодом
Фреймворки с открытым исходным кодом делают парсинг веб-сайтов дешевле и проще для личного использования. Наиболее широко используемые инструменты: Scrapy, Selenium, BeautifulSoup и Puppeteer.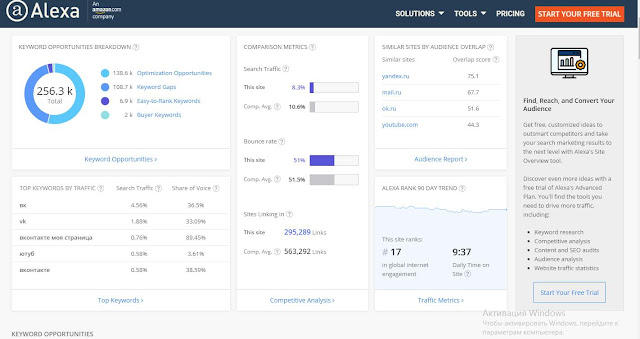
Пользователи могут собирать информацию, используя библиотеки наподобие Selenium, чтобы автоматизировать этот процесс. Когда на веб-странице есть список, то чаще всего есть и другие страницы, помимо той, которая сразу отображается пользователю. Пример — веб-страницы с «бесконечной прокруткой». Например, предположим, что вы просматриваете веб-страницы YouTube. На веб-странице, которую вы просматриваете, среди всех перечисленных видео не оказалось такого, который вы бы захотели посмотреть. Затем вам нужно прокрутить список вниз, чтобы появились следующие видео. Selenium позволяет пользователям автоматизировать перемещение по последующим страницам списка и сканирование требуемой информации о каждом элементе списка. Далее пользователи могут сформировать набор данных, содержащий информацию о каждом элементе списка, представленного на веб-сайте. Например, можно создать набор данных о фильмах, в который будут входить наименования, рейтинги IMDb, актеры и позиции фильмов в топе 250 IMDb, сканируя список лучших фильмов по версии IMDb с помощью инструментов с открытым исходным кодом наподобие Scrapy.
Проприетарные программные решения
Хотя на рынке есть различные проприетарные решения, продукты разделены на два типа:
- Решения, для взаимодействия с которыми нужно писать программный код. Поставщики таких решений предоставляют ключ API для доступа к данным.
- Решения без кода, для использования которых необязательно обладать навыками программирования и которые предоставляют инструменты, делающие сканирование веб-сайтов более доступным.
Облачные (SaaS) решения
Хотя парсить данные со своего собственного веб-сайта нетрудно, эта задача будет более сложной на веб-сайтах, стремящихся противодействовать сканированию своего контента роботами, которые не относятся к роботам поисковых систем. Как следствие, передовые парсеры собирают данные с использованием набора различных IP-адресов и цифровых подписей, действуя не как автоматический программный робот, а как группа пользователей, просматривающих веб-сайт.
Управляемые услуги
Полностью управляемые услуги по парсингу веб-сайтов, также называемые «данные-как-услуга» (data-as-a-service, DaaS), будут более удобны для компаний, которым нужен широкомасштабный сбор данных. Работа с веб-сервисами, предоставляющими такие услуги, обычно выглядит так:
- Клиент отправляет требования, как например: перечень сканируемых веб-сайтов, извлекаемые поля и частота сбора данных.
- Компания-поставщик управляемых услуг проверяет, возможно ли выполнить эти требования, и подготавливает к работе программных роботов, которые будут собирать данные.
- Компания использует лучшие методы «очистки» данных, преобразует их в нужный формат и отправляет клиенту.
Такие компании, как Yipitdata, PromptCloud и ScrapeHero, — некоторые из поставщиков, предлагающих полностью управляемые услуги по парсингу веб-сайтов.
Собственные внутриорганизационные решения
Используя готовое существующее программное обеспечение (ПО) с открытым или закрытым исходным кодом и навыки программирования, любая компания может создавать качественные парсеры веб-сайтов. При условии, что у компании есть технический персонал для осуществления этой задачи, и что парсинг необходим для реализации стратегически важного проекта, собственную разработку можно считать оптимальным вариантом.
При условии, что у компании есть технический персонал для осуществления этой задачи, и что парсинг необходим для реализации стратегически важного проекта, собственную разработку можно считать оптимальным вариантом.
Схема выбор инструмента для парсинга
Выбор подходящего инструмента или веб-сервиса для сбора данных во Всемирной паутине зависит от различных факторов, включая тип проекта, бюджет и наличие технического персонала. Чтобы кратко охарактеризовать представленную выше схему принятия решения, правильный ход мыслей при выборе автоматического сборщика данных должен быть таким:
- Собираетесь ли вы собирать данные только для личного использования? Если да, то выберите инструмент с открытым исходным кодом или его community-версию, что позволит вам собирать данные бесплатно.
- Если нет, то работает ли ваша IT-компания над стратегически важными проектами, которые дифференцируют ваши продукты или услуг?
- Если да, то сформируйте в компании команду, которая будет предотвращать сбор ваших данных сторонними компаниями.
- Если нет, то позволяет ли ваш бюджет инвестировать более $10 000?
- Если да, то отдайте предпочтение управляемым услугам, поскольку системы парсинга данных требуют существенных усилий по их поддержке. Возможно, что вам не захочется, чтобы команда вашей компании была сосредоточена на поддержке проекта, который не является стратегически важным.
- Если нет, то есть ли у вас навыки программирования? Если есть, то отдайте предпочтение решениям с открытым исходным кодом или недорогим проприетарным решениям. Разработка своего парсера может быть эффективнее, чем использование решений, не требующих написания программного кода, поскольку разработанное решение может предложить более высокий уровень автоматизации.
- Если их нет, то сделайте выбор в пользу решений, которыми можно пользоваться без программирования. Большинство из них проприетарные, но их можно приобрести и с ограниченным бюджетом.
Законно ли заниматься парсингом?
Коротко говоря, если: при парсинге собираются общедоступные данные, парсинг не наносит вред компании-владельцу данных, среди собранных данных нет персональных и при повторной публикации собранных данных добавляется ссылка на источник, то, по всей видимости, заниматься парсингом законно. Однако это не юридическое заключение, поэтому, пожалуйста, обратитесь к профессиональному юристу за конкретной консультацией.
Персональные данные
Законность парсинга ранее долгое время была неоднозначной, но сейчас в этом вопросе больше ясности. В настоящее время нормативно-правовые акты, регулирующие конфиденциальность персональных данных, наподобие GDPR Европейского союза и CCPA в Калифорнии не препятствуют парсингу веб-сайтов. В России недавно приняли дополнительные поправки в закон об Персональных данных. Просто убедитесь, что:
- Собираются общедоступные данные.
- Персональные данные хранятся в надежных условиях и в соответствии с передовыми методиками.
- Данные не продаются или не передаются посторонним, если только на это не было получено согласие отдельного пользователя.
Данные, которые не относятся к персональным
Говоря о компаниях, Апелляционный суд девятого округа США после иска LinkedIn против hiQ постановил, что автоматический парсинг общедоступных данных, очевидно, не нарушает Закон о компьютерном мошенничестве и злоупотреблении (Computer Fraud and Abuse Act, CFAA).
Ограничения
Тем не менее при использовании парсинга веб-сайтов действуют ограничения.
- Извлечение данных не должно причинять какой-либо ущерб владельцам данных.
- Парсер не может публиковать данные без указания их источника. Это было бы неэтично и незаконно.
Примеры
При оценке законности парсинга учтите также, что каждый результат поиска, который вы видите на страницах поисковых систем, был собран ею. Помимо этого, сообщается, что хедж-фонды тратят миллиарды на сбор данных, чтобы принимать более эффективные инвестиционные решения. Поэтому парсинг — это не сомнительная практика, которую применяют только небольшие компании.
Помимо этого, сообщается, что хедж-фонды тратят миллиарды на сбор данных, чтобы принимать более эффективные инвестиционные решения. Поэтому парсинг — это не сомнительная практика, которую применяют только небольшие компании.
Почему владельцы веб-сайтов хотят защитить их от парсинга?
Отчет 2020 от imperva о нежелательных программных роботах, собирающих данные
- Сборщики данных могут значительно ухудшить производительность веб-сайта. Роботы, включая поисковых, составляют 24% веб-трафика согласно Imperva — поставщику ПО для обеспечения информационной безопасности.
- Конкуренты могут собирать и анализировать данные на страницах веб-сайта. Например, это позволяет им посредством уведомлений оперативно узнавать о новых клиентах, партнерских связях или возможностях конкурентов.
- Кроме того, внутренние непубличные данные владельцев веб-сайта могут быть собраны конкурентами, создающими аналогичные продукты или конкурирующие услуги, уменьшая спрос на услуги владельцев веб-сайта.
- Защищенный авторским правом контент владельцев веб-сайта может быть скопирован и процитирован без ссылок на источник, приводя к потере дохода у создателей контента.

Какие сложности могут возникнуть при парсинге веб-сайтов?
- Веб-сайты со сложной структурой: большинство веб-страниц основаны на использовании HTML, и структура одной веб-страницы может сильно отличаться от структуры другой. Следовательно, когда вам нужно спарсить несколько веб-сайтов, для каждого из них придется создать свой парсер.
- Поддержка парсера может быть дорогой: веб-сайты всё время меняют дизайн веб-страницы. Если местоположение собираемых данных меняется, то программный код сборщиков данных необходимо снова доработать.
- Используемые веб-сайтами инструменты противодействия парсингу: такие инструменты позволяют веб-разработчикам управлять контентом, который отображается роботам и людям, а также ограничивать роботам возможность собирать данные на веб-сайте. Некоторые из методов защиты от парсинга: блокировка IP-адресов, captcha (Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматический тест Тьюринга для различения компьютеров и людей) и ловушки в виде приманок для парсеров.
- Необходимость авторизации: чтобы собрать во Всемирной паутине определенную информацию, возможно, вам сначала потребуется пройти авторизацию. Поэтому когда веб-сайт требует войти в систему, нужно убедиться, что парсер сохраняет файлы cookie, которые были отправлены вместе с запросом, чтобы веб-сайт воспринимал парсер в качестве авторизованного ранее посетителя.
- Медленная или нестабильная скорость загрузки: когда веб-сайты загружают контент медленно или не отвечают на запросы, может помочь обновление страницы, хотя парсер, возможно, не знает, что делать в такой ситуации.
 Некоторые из методов защиты от парсинга: блокировка IP-адресов, captcha (Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматический тест Тьюринга для различения компьютеров и людей) и ловушки в виде приманок для парсеров.
Некоторые из методов защиты от парсинга: блокировка IP-адресов, captcha (Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматический тест Тьюринга для различения компьютеров и людей) и ловушки в виде приманок для парсеров.Какие приемы парсинга веб-сайтов считаются лучшими?
Распространенные и наиболее успешные приемы парсинга веб-сайтов:
Использование прокси-серверов
Многие администраторы крупных веб-сайтов применяют инструменты для защиты от роботов. Роботам приходится обходить их, чтобы просканировать большое количество HTML-страниц. Использование прокси-серверов и отправка запросов через разные IP-адреса могут помочь преодолеть эти трудности.
Роботам приходится обходить их, чтобы просканировать большое количество HTML-страниц. Использование прокси-серверов и отправка запросов через разные IP-адреса могут помочь преодолеть эти трудности.
Использование динамического IP-адреса
Переход от статического IP-адреса на динамический также может оказаться полезным для того, чтобы парсер не обнаружили и не заблокировали.
Замедление процесса сбора данных
Следует ограничить частоту отправки запросов на один и тот же веб-сайт по двум причинам:
- веб-сборщиков данных легче обнаружить, если они делают запросы быстрее людей;
- сервер веб-сайта может перестать отвечать, если он получает слишком много запросов одновременно. Кроме того, эту проблему поможет решить программирование сборщика данных на взаимодействие с веб-страницей и планирование сеансов сбора данных таким образом, чтобы они начинались не в периоды пиковой нагрузки на веб-сайты.
Соблюдение требований GDPR
Согласно GDPR, незаконно собирать личную информацию (personally identifiable information, PII) резидентов ЕС, если только у вас нет их явного на это согласия.
Бойтесь пользовательских соглашений
Если вы собираетесь собирать данные на веб-сайте, где требуется проходить авторизацию, вам нужно принять пользовательское соглашение (Terms & Conditions), чтобы зарегистрироваться там. Некоторые пользовательские соглашения включают в себя принципы компаний, связанные с парсингом данных, в соответствии с которыми вам не разрешается парсить любые данные на веб-сайте.
Однако даже несмотря на то, что пользовательское соглашение LinkedIn однозначно запрещает парсинг данных, как упоминалось выше, парсинг LinkedIn пока еще не нарушает закон. Мы не дает юридическое заключение и не беремся однозначно разъяснять смысл пользовательских соглашений компаний.
Что сулит будущее для парсинга веб-сайтов?
Парсинг превращается в игру в кошки-мышки между владельцами контента и его сборщиками — обе стороны тратят миллиарды на преодоление мер, разработанных другой стороной. Можно ожидать, что обе стороны будут использовать машинное обучение для создания более продвинутых систем.
Открытый исходный код играет важную роль в разработке ПО, в том числе в области разработки парсеров. Кроме того, популярность Python растет, и она уже довольно высока. Можно ожидать, что библиотеки с открытым исходным кодом, как например: Selenium, Scrapy и Beautiful Soup, которые работают на Python, будут в ближайшем будущем формировать подходы к парсингу веб-сайтов.
Вместе с библиотеками с открытым исходным кодом интерес к искусственному интеллекту (ИИ) делает будущее более радужным, поскольку системы на основе ИИ в значительной степени полагаются на данные, а автоматизация сбора данных может содействовать различным вариантам применения ИИ с тренировкой на общедоступных данных.
Как парсить любой сайт
парсинг
Даниил Охлопков
• 4 мин чтения
Я поделюсь своим подходом, который помогает мне создавать надежные парсеры любого веб-сайта.
Я не буду приводить здесь реальные скрипты, но опишу, как я извлекаю данные с любого веб-сайта. Это должно быть полезно, когда вам нужно решить, как и какую часть веб-сайта следует анализировать.
Это должно быть полезно, когда вам нужно решить, как и какую часть веб-сайта следует анализировать.
- Найти официальный API
- Поиск XHR-запросов в инструментах разработки браузера
- Поиск данных JSON в HTML-коде страницы
- Рендеринг страницы с помощью любого безголового браузера множество A/B-тестов, чтобы увеличить конверсию и улучшить воронки своих веб-сайтов. Это означает, что макет (HTML) и форматирование данных могут быть легко изменены на следующей неделе. В идеале вы хотите закодировать синтаксический анализатор один раз и без периодической адаптации его к новому макету.
Не анализировать HTML, если ничего не работает. XPath и Beutifulsoup не устойчивы к изменениям веб-сайта.
Найдите официальный API
Иногда веб-сайты просто предоставляют вам API, чтобы вы могли извлечь необработанные данные, которые могут вам понадобиться. Вам нужно проверить, существует ли API, прежде чем пытаться что-либо разобрать.
Не тратьте время на борьбу с HTML и файлами cookie, если вам это не нужно.Некоторые веб-сайты все еще имеют RSS-каналы. Они сделаны так, чтобы их легко анализировали машины, но они больше не популярны, поэтому на большинстве веб-сайтов их нет. Если вы хотите извлечь данные из каких-то блогов или новостных сайтов — вам обязательно нужно проверить наличие RSS-каналов!
Ищите запросы XHR
Все современные веб-сайты (не в даркнете, лол) используют Javascript для получения данных. Это позволяет веб-сайтам плавно открываться и загружать контент (данные) после отображения основного макета (HTML, скелет).
Обычно эти данные извлекаются Javascript с помощью запросов GET/POST. Отличным примером является Producthunt:
Просто возьмите необработанные данные JSON!
Рабочий процесс прост:
- Откройте веб-страницу, которую вы хотите проанализировать
- Щелкните правой кнопкой мыши —> Проверить (открыть инструменты разработчика вашего браузера)
- Откройте вкладку «Сеть» и выберите фильтр XHR (чтобы отобразить только запросы, которые могут вам понадобиться)
- Найдите запросы, которые возвращают нужные вам данные
- Скопируйте этот запрос как cURL и используйте его в коде вашего парсера
Иногда вы замечаете, что эти XHR запросы требуют больших строк — токенов, файлов cookie и сеансов.
Они генерируются с использованием Javascript или бэкэнда. Не тратьте время на изучение кода JS, чтобы понять, как они были созданы.Вместо этого вы можете попробовать просто скопировать и вставить их из браузера в свой код — обычно они действительны в течение 7-30 дней. Возможно, это нормально для ваших нужд. Или вы можете найти другой запрос XHR (например,
/login), который выводит все необходимые вам токены и сеансы. В противном случае я бы предложил перейти на автоматизацию браузера (Selenium, Puppeteer, Splash и т. д.).Ищите данные JSON в HTML-коде
Но иногда в целях SEO некоторые данные уже встроены в HTML-страницу: если вы откроете исходный код любой страницы Linkedin, вы заметите огромный JSONS в ее HTML.
Просто используйте эти JSON из HTML-кода, потому что вероятность того, что его структура будет изменена, очень-очень мала. Напишите свой синтаксический анализатор для извлечения этих JSON, используя простые регулярные выражения или базовые инструменты, которые вы уже знаете.
Если вы видите данные JSON в HTML-коде страницы, вам не нужно отображать их с помощью автономных браузеров — вы можете просто использовать вызовы GET (например,
request.getв Python).Render JS
Для масштабируемости и простоты я предлагаю использовать кластеры удаленных браузеров. Недавно я нашел крутую удаленную автоматизацию сети Selenium под названием Selenoid. Их служба поддержки ужасна, но сам микросервис довольно легко запустить на вашей машине. В результате у вас будет волшебный URL-адрес, который вы вставите в свой драйвер Selenium для удаленного рендеринга всего, а не локально, например. с помощью файла chromedriver. Супер полезно.
Это мой фрагмент использования Selenoid (Python). Обратите внимание на параметр
enable_vnc: он откроет соединение VNC, чтобы увидеть, что происходит в удаленном браузере Selenoid.деф get_selenoid_driver( enable_vnc = False, browser_name = "firefox" ): возможности = { "browserName": имя_браузера, "версия": "", "enableVNC": enable_vnc, "enableVideo": Ложь, "экранРазрешение": "1280x1024x24", "sessionTimeout": "3 м", # Кто-то тоже использовал эти параметры, давайте их тоже "goog:chromeOptions": {"excludeSwitches": ["enable-automation"]}, "предпочтения": { "credentials_enable_service": Ложь, "profile. password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель После рендеринга страницы вы можете случайно найти JSON со всеми необходимыми данными в HTML-коде страницы. Опять же, попробуйте извлечь этот JSON и взять из него все необходимые данные вместо того, чтобы пытаться анализировать HTML-теги и поля, которые могут измениться на следующей неделе.
driver.get(url_to_open) html = driver.page_source
Разбор HTML
Если вы не можете найти ни правильный XHR-запрос, ни JSON в HTML-коде страницы, это означает, что веб-сайт использует SSR, который предварительно заполняет все данные. В этом редкое дело (вероятно, старый сайт), остается только попытаться извлечь нужные данные с помощью селекторов CSS или XPath.
Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются.Надеюсь, это было полезно. Пожалуйста, пишите мне комментарии и вопросы. Увидимся в ближайшее время для получения дополнительных руководств по синтаксическому анализу и ELT! 👋
Парсинг веб-страниц с помощью Python — Полное руководство по парсингу веб-страниц на Python
Последнее обновление 13 июля 2022 г. 1M Views
Omkar S Hiremath Технический энтузиаст в области блокчейн, Hadoop, Python, кибербезопасности, этического взлома. Заинтересован во всем… Технический энтузиаст в области блокчейна, Hadoop, Python, кибербезопасности, этического взлома. Интересуется всем и вся о компьютерах.
1 / 2 Блог веб-скрейпинга
Стать сертифицированным специалистом
Веб-скрейпинг с помощью Python
Представьте, что вам нужно извлечь большой объем данных с веб-сайтов, и вы хотите сделать это как можно быстрее .
Как бы вы это сделали, не заходя на каждый сайт вручную и не получая данные? Что ж, «веб-скрейпинг» — вот ответ. Web Scraping просто делает эту работу проще и быстрее.В этой статье о веб-скрейпинге с помощью Python вы кратко узнаете о веб-скрейпинге и увидите, как извлечь данные с веб-сайта с демонстрацией. Я буду освещать следующие темы:
- Почему используется Web Scraping?
- Что такое парсинг веб-страниц?
- Законен ли веб-скрейпинг?
- Почему Python хорош для парсинга веб-страниц?
- Как вы очищаете данные с веб-сайта?
- Библиотеки, используемые для парсинга веб-страниц
- Пример парсинга веб-страниц: Парсинг веб-сайта Flipkart
Для чего используется парсинг веб-страниц?
Веб-скрапинг используется для сбора больших объемов информации с веб-сайтов. Но зачем кому-то собирать такие большие данные с веб-сайтов? Чтобы узнать об этом, давайте посмотрим на приложения веб-скрейпинга:
- Сравнение цен: Такие сервисы, как ParseHub, используют веб-скрейпинг для сбора данных с веб-сайтов интернет-магазинов и используют их для сравнения цен на товары.
- Сбор адресов электронной почты: Многие компании, использующие электронную почту в качестве средства маркетинга, используют веб-скрапинг для сбора идентификаторов электронной почты, а затем рассылают массовые электронные письма.
- Парсинг социальных сетей: Парсинг веб-страниц используется для сбора данных с веб-сайтов социальных сетей, таких как Twitter, чтобы выяснить, что в тренде.
- Исследования и разработки: Веб-скрапинг используется для сбора большого набора данных (статистика, общая информация, температура и т. д.) с веб-сайтов, которые анализируются и используются для проведения опросов или исследований и разработок.
- Списки вакансий: Подробная информация о вакансиях и собеседованиях собирается с разных веб-сайтов, а затем перечисляется в одном месте, чтобы пользователь мог легко получить к ней доступ.
Что такое парсинг веб-страниц?
Веб-скрапинг — это автоматизированный метод, используемый для извлечения больших объемов данных с веб-сайтов.
Данные на сайтах неструктурированы. Веб-скрапинг помогает собирать эти неструктурированные данные и хранить их в структурированной форме. Существуют различные способы очистки веб-сайтов, такие как онлайн-сервисы, API или написание собственного кода. В этой статье мы увидим, как реализовать веб-скрапинг с помощью Python.Законен ли веб-скрейпинг?
Говоря о том, является ли парсинг законным или нет, некоторые веб-сайты разрешают парсинг, а некоторые нет. Чтобы узнать, разрешает ли веб-сайт парсинг или нет, вы можете посмотреть файл «robots.txt» веб-сайта. Вы можете найти этот файл, добавив «/robots.txt» к URL-адресу, который вы хотите очистить. В этом примере я очищаю веб-сайт Flipkart. Таким образом, чтобы увидеть файл «robots.txt», URL-адрес: www.flipkart.com/robots.txt.
Получите всестороннее знание Python вместе с его разнообразными приложениями
Почему Python хорош для парсинга веб-страниц?
Вот список функций Python, которые делают его более подходящим для просмотра веб-страниц.
- Простота использования: Программирование на Python очень просто. Вам не нужно добавлять точку с запятой «;» или фигурные скобки «{}» в любом месте. Это делает его менее грязным и простым в использовании.
- Большая коллекция библиотек: Python имеет огромную коллекцию библиотек, таких как Numpy, Matlplotlib, Pandas и т. д., которые предоставляют методы и службы для различных целей. Следовательно, он подходит для просмотра веб-страниц и дальнейшей обработки извлеченных данных.
- Динамически типизированный: В Python вам не нужно определять типы данных для переменных, вы можете напрямую использовать переменные везде, где это необходимо. Это экономит время и ускоряет работу.
- Легко понятный синтаксис: Синтаксис Python легко понять, главным образом потому, что чтение кода Python очень похоже на чтение оператора на английском языке. Он выразительный и легко читаемый, а отступы, используемые в Python, также помогают пользователю различать разные области/блоки в коде.
- Небольшой код, большая задача: Веб-скрапинг используется для экономии времени. Но что толку, если вы тратите больше времени на написание кода? Ну, вам не нужно. В Python вы можете писать небольшие коды для выполнения больших задач. Следовательно, вы экономите время даже при написании кода.
- Сообщество: Что делать, если вы застряли при написании кода? Вам не о чем беспокоиться. Сообщество Python имеет одно из самых больших и активных сообществ, к которому вы можете обратиться за помощью.
Узнайте о нашем обучении Python в лучших городах/странах
Как вы очищаете данные с веб-сайта?
Когда вы запускаете код для просмотра веб-страниц, запрос отправляется на указанный вами URL-адрес. В ответ на запрос сервер отправляет данные и позволяет прочитать страницу HTML или XML. Затем код анализирует страницу HTML или XML, находит данные и извлекает их.
Чтобы извлечь данные с помощью веб-скрапинга с помощью Python, вам необходимо выполнить следующие основные шаги:
- Найдите URL-адрес, который вы хотите очистить
- Проверка страницы
- Найдите данные, которые вы хотите извлечь
- Напишите код
- Запустите код и извлеките данные
- Сохраните данные в требуемом формате
Теперь давайте посмотрим, как извлечь данные с веб-сайта Flipkart с помощью Python.
Изучайте Python, глубокое обучение, НЛП, искусственный интеллект, машинное обучение с помощью этих курсов искусственного интеллекта и машинного обучения программы сертификации PG Diploma от NIT Warangal.
Библиотеки, используемые для парсинга веб-страниц
Как мы знаем, у Python есть различные приложения и разные библиотеки для разных целей. В нашей дальнейшей демонстрации мы будем использовать следующие библиотеки:
- Selenium : Selenium — это библиотека для веб-тестирования. Он используется для автоматизации действий браузера.
- BeautifulSoup : Beautiful Soup — это пакет Python для анализа документов HTML и XML. Он создает деревья синтаксического анализа, которые помогают легко извлекать данные.
- Pandas : Pandas — это библиотека, используемая для обработки и анализа данных. Он используется для извлечения данных и их сохранения в нужном формате.
Подпишитесь на наш канал YouTube, чтобы получать новые обновления..!
Web Scraping Example : Scraping Flipkart Website
Pre-requisites:
- Python 2.x or Python 3.x with Selenium , BeautifulSoup, pandas libraries installed
- Google-chrome browser
- Операционная система Ubuntu
Начнем!
Шаг 1: Найдите URL-адрес, который вы хотите очистить
В этом примере мы собираемся очистить веб-сайт Flipkart , чтобы извлечь цену, имя и рейтинг ноутбуков. URL-адрес этой страницы: https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Шаг 2. Осмотр страницы
Данные обычно вложены в теги. Итак, мы проверяем страницу, чтобы увидеть, под каким тегом вложены данные, которые мы хотим очистить.
Чтобы проверить страницу, просто щелкните правой кнопкой мыши элемент и нажмите «Проверить».Когда вы нажмете на вкладку «Проверка», вы увидите открытое окно «Инспектор браузера».
Шаг 3: Найдите данные, которые вы хотите извлечь
Давайте извлечем цену, имя и рейтинг, которые находятся в теге «div» соответственно.
Изучите Python за 42 часа!
Шаг 4: Напишите код
Сначала создадим файл Python. Для этого откройте терминал в Ubuntu и введите gedit <ваше имя файла> с расширением .py.
Я назову свой файл «web-s». Вот команда:
gedit web-s.py
Теперь давайте напишем наш код в этом файле.
Для начала импортируем все необходимые библиотеки:
из selenium import webdriver из BeautifulSoup импортировать BeautifulSoup импортировать панд как pd
Чтобы настроить webdriver для использования браузера Chrome, мы должны установить путь к chromedriver
driver = webdriver.
Chrome("/usr/lib/chromium-browser/chromedriver") Обратитесь к приведенному ниже коду, чтобы открыть URL-адрес:
products=[] #Список для хранения названия продукта цены=[] #Список для хранения цены товара ratings=[] #Список для хранения рейтинга продукта driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&amp;amp;amp;amp;amp;amp;amp ;амп;уник")Теперь, когда мы написали код для открытия URL-адреса, пришло время извлечь данные с веб-сайта. Как упоминалось ранее, данные, которые мы хотим извлечь, вложены в теги
. Итак, я найду теги div с соответствующими именами классов, извлеку данные и сохраним их в переменной. См. приведенный ниже код:content = driver.page_source суп = BeautifulSoup(содержание) для супа.findAll('a',href=True, attrs={'class':'_31qSD5'}): name=a.find('div', attrs={'класс':'_3wU53n'}) цена=a.find('div', attrs={'класс':'_1vC4OE _2rQ-NK'}) rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'}) products. append(имя.текст)
цены.добавлять(цена.текст)
ratings.append(рейтинг.текст)
Шаг 5: Запустите код и извлеките данные
Чтобы запустить код, используйте следующую команду:
python web-s.py
Шаг 6: Сохраните данные в требуемом формате
После извлечения данных вы можете сохранить их в формате. Этот формат зависит от ваших требований. В этом примере мы будем хранить извлеченные данные в формате CSV (значения, разделенные запятыми). Для этого я добавлю в свой код следующие строки:
df = pd.DataFrame({'Название продукта':продукты,'Цена':цены,'Рейтинг':рейтинги}) df.to_csv('products.csv', index=False, encoding='utf-8')Теперь я снова запущу весь код.
Создается файл с именем «products.csv», и этот файл содержит извлеченные данные.
Надеюсь, вам понравилась эта статья «Скрапинг веб-страниц с помощью Python». Я надеюсь, что этот блог был информативным и добавил ценности вашим знаниям.
 Не тратьте время на борьбу с HTML и файлами cookie, если вам это не нужно.
Не тратьте время на борьбу с HTML и файлами cookie, если вам это не нужно. Они генерируются с использованием Javascript или бэкэнда. Не тратьте время на изучение кода JS, чтобы понять, как они были созданы.
Они генерируются с использованием Javascript или бэкэнда. Не тратьте время на изучение кода JS, чтобы понять, как они были созданы.
 password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель
password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель 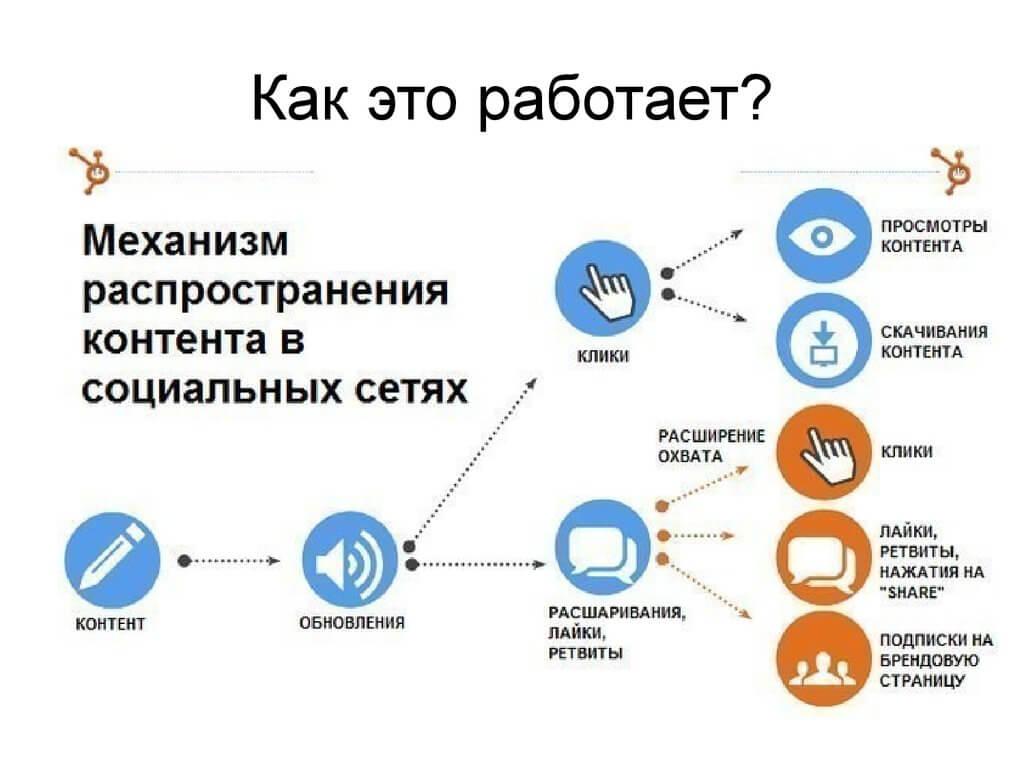 Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются.
Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются. Как бы вы это сделали, не заходя на каждый сайт вручную и не получая данные? Что ж, «веб-скрейпинг» — вот ответ. Web Scraping просто делает эту работу проще и быстрее.
Как бы вы это сделали, не заходя на каждый сайт вручную и не получая данные? Что ж, «веб-скрейпинг» — вот ответ. Web Scraping просто делает эту работу проще и быстрее.
 Данные на сайтах неструктурированы. Веб-скрапинг помогает собирать эти неструктурированные данные и хранить их в структурированной форме. Существуют различные способы очистки веб-сайтов, такие как онлайн-сервисы, API или написание собственного кода. В этой статье мы увидим, как реализовать веб-скрапинг с помощью Python.
Данные на сайтах неструктурированы. Веб-скрапинг помогает собирать эти неструктурированные данные и хранить их в структурированной форме. Существуют различные способы очистки веб-сайтов, такие как онлайн-сервисы, API или написание собственного кода. В этой статье мы увидим, как реализовать веб-скрапинг с помощью Python.

 Чтобы проверить страницу, просто щелкните правой кнопкой мыши элемент и нажмите «Проверить».
Чтобы проверить страницу, просто щелкните правой кнопкой мыши элемент и нажмите «Проверить».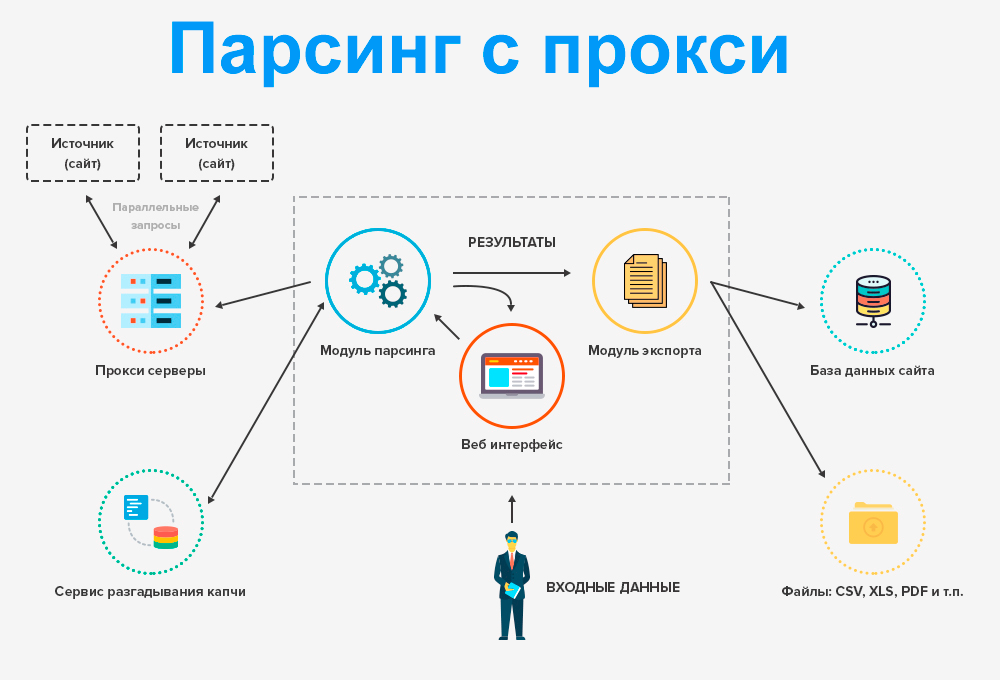 append(имя.текст)
цены.добавлять(цена.текст)
ratings.append(рейтинг.текст)
append(имя.текст)
цены.добавлять(цена.текст)
ratings.append(рейтинг.текст)