Содержание
Страница не найдена – Блог TRINET
Все лица, заполнившие сведения, являющиеся персональными данными на сайте https://www.trinet.ru/ и его поддоменах, а также разместившие иную информацию на сайте https://www.trinet.ru/ и его поддоменах, подтверждают свое согласие на обработку персональных данных и их передачу Оператору обработки персональных данных – ООО «Комплексный интернет-маркетинг» (Юридический адрес: 197022, г. Санкт-Петербург, пр. Медиков, д. 9, лит. Б, пом. 12-Н, ч. 214.1).
Пользователь дает свое согласие на обработку его персональных данных, а именно совершение действий, предусмотренных пунктом 3 части 1 статьи 3 Федерального закона от 27.07.2006 № 152-ФЗ «О персональных данных», и подтверждает, что, давая такое согласие, он действует свободно, своей волей и в своем интересе.
- ОПРЕДЕЛЕНИЕ ТЕРМИНОВ
- В настоящей Политике конфиденциальности используются следующие термины:
- «Администрация сайта Компании (далее – Администрация сайта)» – уполномоченные сотрудники на управление сайтом, действующие от имени «ООО «Комплексный интернет-маркетинг», которые организуют и (или) осуществляет обработку персональных данных, а также определяют цели обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции), совершаемые с персональными данными.

- «Персональные данные» — любая информация, относящаяся к прямо или косвенно определенному или определяемому физическому лицу (субъекту персональных данных).
- «Обработка персональных данных» — любое действие (операция) или совокупность действий (операций), совершаемых с использованием средств автоматизации или без использования таких средств с персональными данными, включая сбор, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (распространение, предоставление, доступ), обезличивание, блокирование, удаление, уничтожение персональных данных.
- «Конфиденциальность персональных данных» — обязательное для соблюдения Оператором или иным получившим доступ к персональным данным лицом требование не допускать их распространения без согласия субъекта персональных данных или наличия иного законного основания.
- «Пользователь сайта (далее Пользователь)» – лицо, имеющее доступ к Сайту, посредством сети Интернет и использующее Сайт Компании.
- «Cookies» — небольшой фрагмент данных, отправленный веб-сервером и хранимый на компьютере пользователя, который веб-клиент или веб-браузер каждый раз пересылает веб-серверу в HTTP/HTTPS-запросе при попытке открыть страницу соответствующего сайта.
- «IP-адрес» — уникальный сетевой адрес узла в компьютерной сети, построенной по протоколу IP.
- «Администрация сайта Компании (далее – Администрация сайта)» – уполномоченные сотрудники на управление сайтом, действующие от имени «ООО «Комплексный интернет-маркетинг», которые организуют и (или) осуществляет обработку персональных данных, а также определяют цели обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции), совершаемые с персональными данными.
- В настоящей Политике конфиденциальности используются следующие термины:
- ОБЩИЕ ПОЛОЖЕНИЯ
- Использование Пользователем сайта https://www.trinet.ru/ и его поддоменов означает согласие с настоящей Политикой конфиденциальности и условиями обработки персональных данных Пользователя.
- В случае несогласия с условиями Политики конфиденциальности Пользователь должен прекратить использование сайта https://www.trinet.ru/ и его поддоменов.
- Настоящая Политика конфиденциальности применяется только к сайту https://www.trinet.ru/ и его поддоменов. Компания не контролирует и не несет ответственность за сайты третьих лиц, на которые Пользователь может перейти по ссылкам, доступным на сайте Компании.
- Администрация сайта не проверяет достоверность персональных данных, предоставляемых Пользователем сайта.
- ПРЕДМЕТ ПОЛИТИКИ КОНФИДЕНЦИАЛЬНОСТИ
- Настоящая Политика конфиденциальности устанавливает обязательства Администрации сайта Компании по неразглашению и обеспечению режима защиты конфиденциальности персональных данных, которые Пользователь предоставляет по запросу Администрации сайта при вводе данных в формы обратной связи на сайте https://www.trinet.ru/ и его поддоменов или при оформлении заказа на приобретение услуг Компании.
Персональные данные, разрешённые к обработке в рамках настоящей Политики конфиденциальности, предоставляются Пользователем путём заполнения форм обратной связи на сайте ООО «Комплексный интернет-маркетинг» и включают в себя следующую информацию:
- фамилию, имя, отчество Пользователя;
- контактный телефон Пользователя;
- адрес электронной почты (e-mail) Пользователя;
- ЦЕЛИ СБОРА ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЯ
- Персональные данные Пользователя Администрация сайта Компании может использовать в целях:
- Для оформления заказа и (или) заключения Договора оказания услуги дистанционным способом с ООО «Комплексный интернет-маркетинг».
- Предоставления Пользователю доступа к персонализированным ресурсам Сайта.
- Установления с Пользователем обратной связи, включая направление уведомлений, запросов, касающихся использования Сайта, оказания услуг, обработка запросов и заявок от Пользователя.
- Определения места нахождения Пользователя для обеспечения безопасности, предотвращения мошенничества.
- Подтверждения достоверности и полноты персональных данных, предоставленных Пользователем.
- Уведомления Пользователя Сайта о состоянии Заказа.
- Обработки и получения платежей, подтверждения налога или налоговых льгот, оспаривания платежа, определения права на получение кредитной линии Пользователем.
- Предоставления Пользователю эффективной клиентской и технической поддержки при возникновении проблем связанных с использованием Сайта.
- Предоставления Пользователю с его согласия, обновлений продукции, специальных предложений, информации о ценах, новостной рассылки и иных сведений от имени Веб-студии или от имени партнеров Веб-студии.
- Осуществления рекламной деятельности с согласия Пользователя.
- Предоставления доступа Пользователю на сайты или сервисы партнеров с целью получения продуктов, обновлений и услуг.
- Для оформления заказа и (или) заключения Договора оказания услуги дистанционным способом с ООО «Комплексный интернет-маркетинг».
- Персональные данные Пользователя Администрация сайта Компании может использовать в целях:
- СПОСОБЫ И СРОКИ ОБРАБОТКИ ПЕРСОНАЛЬНОЙ
- Обработка персональных данных Пользователя осуществляется без ограничения срока, любым законным способом, в том числе в информационных системах персональных данных с использованием средств автоматизации или без использования таких средств.
- Пользователь соглашается с тем, что Администрация сайта вправе передавать персональные данные третьим лицам, в частности, курьерским службам, организациями почтовой связи, операторам электросвязи, исключительно в целях выполнения заказа Пользователя, оформленного на Сайте ООО «Комплексный интернет-маркетинг».
- Персональные данные Пользователя могут быть переданы уполномоченным органам государственной власти Российской Федерации только по основаниям и в порядке, установленным законодательством Российской Федерации.
- При утрате или разглашении персональных данных Администрация сайта информирует Пользователя об утрате или разглашении персональных данных.
- Администрация сайта принимает необходимые организационные и технические меры для защиты персональной информации Пользователя от неправомерного или случайного доступа, уничтожения, изменения, блокирования, копирования, распространения, а также от иных неправомерных действий третьих лиц.
- Администрация сайта совместно с Пользователем принимает все необходимые меры по предотвращению убытков или иных отрицательных последствий, вызванных утратой или разглашением персональных данных Пользователя.
- ОБЯЗАТЕЛЬСТВА СТОРОН
- Пользователь обязан:
- Предоставить информацию о персональных данных, необходимую для пользования Сайтом.
- Обновить, дополнить предоставленную информацию о персональных данных в случае изменения данной информации.
- Администрация сайта обязана:
- Использовать полученную информацию исключительно для целей, указанных в п. 4 настоящей Политики конфиденциальности.
- Обеспечить хранение конфиденциальной информации в тайне, не разглашать без предварительного письменного разрешения Пользователя, а также не осуществлять продажу, обмен, опубликование, либо разглашение иными возможными способами переданных персональных данных Пользователя, за исключением п.п. 5.2. и 5.3. настоящей Политики Конфиденциальности.
- Принимать меры предосторожности для защиты конфиденциальности персональных данных Пользователя согласно порядку, обычно используемого для защиты такого рода информации в существующем деловом обороте.
- Осуществить блокирование персональных данных, относящихся к соответствующему Пользователю, с момента обращения или запроса Пользователя или его законного представителя либо уполномоченного органа по защите прав субъектов персональных данных на период проверки, в случае выявления недостоверных персональных данных или неправомерных действий.
- Использовать полученную информацию исключительно для целей, указанных в п.
- Пользователь обязан:
- ДОПОЛНИТЕЛЬНЫЕ УСЛОВИЯ
- Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
- Новая Политика конфиденциальности вступает в силу с момента ее размещения на Сайте, если иное не предусмотрено новой редакцией Политики конфиденциальности.
- Все предложения или вопросы по настоящей Политике конфиденциальности следует сообщать по адресу [email protected]
- Действующая Политика конфиденциальности размещена на странице по адресу https://www.trinet.ru/politika_konfidencialnosti/
- Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
- ОФЕРТА ВИДЕОХОСТИНГА
- Передаваемые права третьим лицам
- Размещая пользовательский контент посредством использования наших услуг, вы предоставляете каждому пользователю Сервиса неисключительную, безвозмездную, действующую во всем мире лицензию на доступ к вашему Контенту и его использование в пределах, допускаемых функционалом Сервиса, в том числе на отображение его с помощью плеера Сервиса на сайтах третьих лиц посредством технологии embed (iframe), а также разрешаете создание временных технических копий контента и видео-превью такого контента.

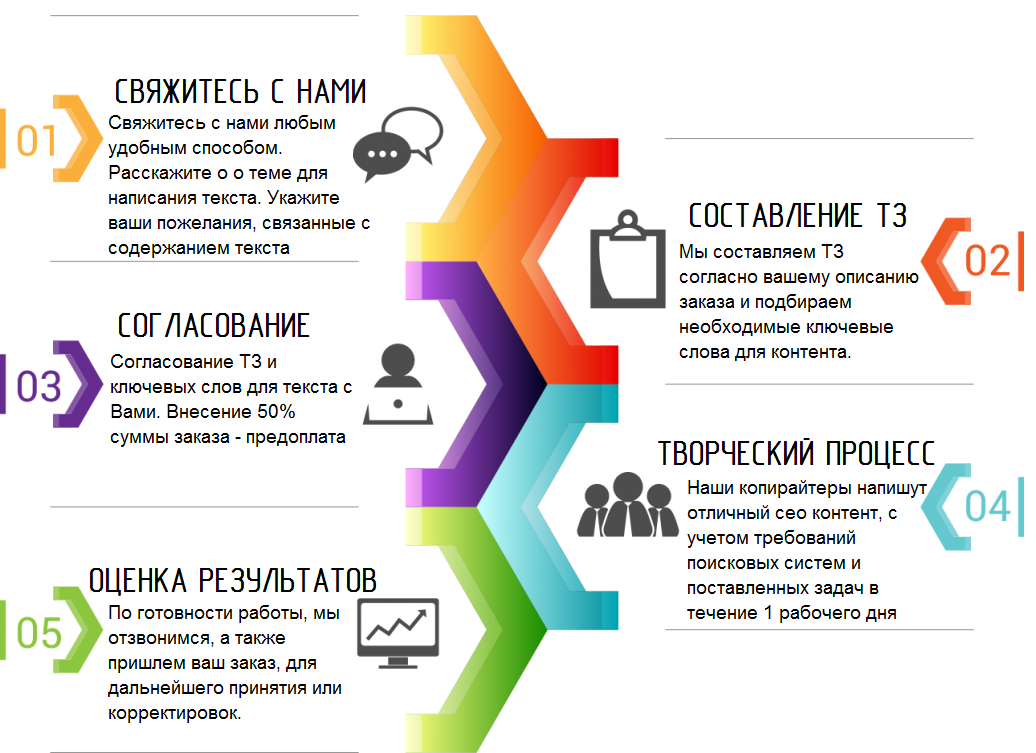



 4 настоящей Политики конфиденциальности.
4 настоящей Политики конфиденциальности.
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()
То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/span
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.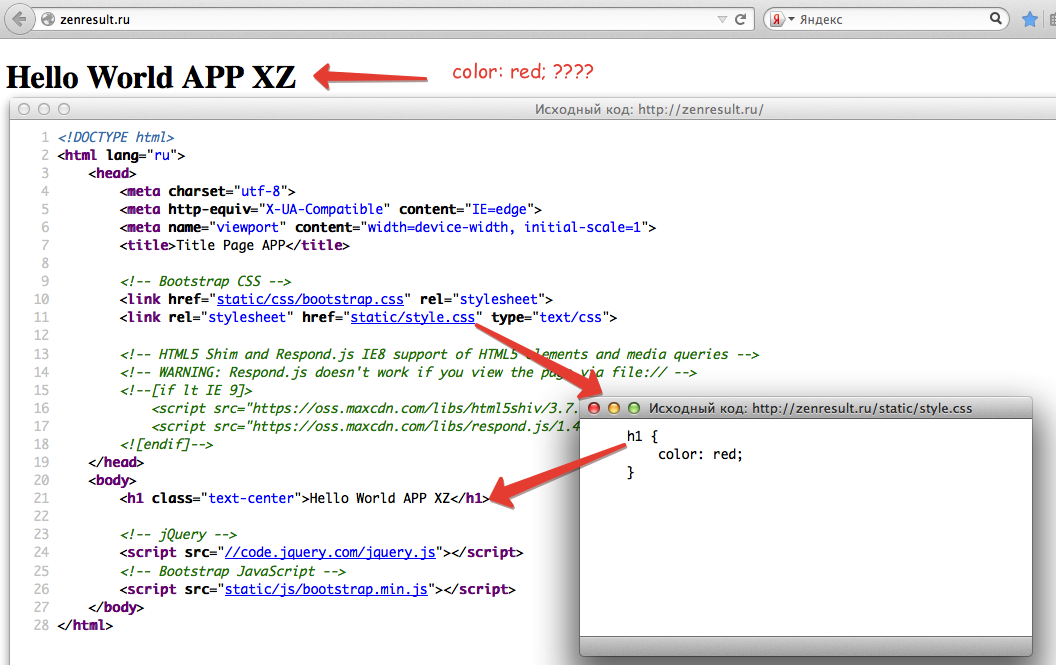 д.
д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@src
У нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]
Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]
Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]
Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.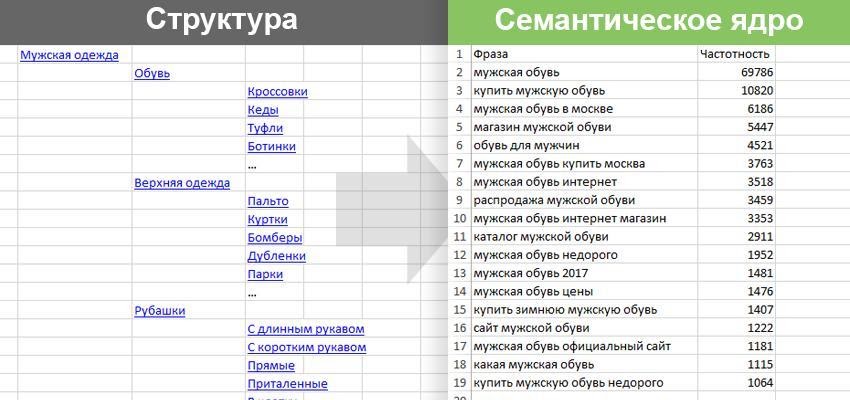
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]
Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.

Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
 Такое ограничение можно обойти, но это долго и дорого.
Такое ограничение можно обойти, но это долго и дорого.Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Как разобрать любой сайт
парсинг
Даниил Охлопков
• 4 мин чтения
Я поделюсь своим подходом, который помогает мне создавать надежные парсеры любого веб-сайта.
Я не буду приводить здесь реальные скрипты, но опишу, как я извлекаю данные с любого веб-сайта. Это должно быть полезно, когда вам нужно решить, как и какую часть веб-сайта следует анализировать.
- Найти официальный API
- Поиск XHR-запросов в инструментах разработчика браузера
- Поиск данных JSON в HTML страницы
- Рендеринг страницы с помощью любого безголового браузера множество A/B-тестов, чтобы увеличить конверсию и улучшить воронки своих веб-сайтов. Это означает, что макет (HTML) и форматирование данных могут быть легко изменены на следующей неделе. В идеале вы хотите закодировать синтаксический анализатор один раз и без периодической адаптации его к новому макету.
Не анализировать HTML, если ничего не работает. XPath и Beutifulsoup не устойчивы к изменениям веб-сайта.
Найдите официальный API
Иногда веб-сайты просто предоставляют вам API, чтобы вы могли извлечь необработанные данные, которые могут вам понадобиться. Вам нужно проверить, существует ли API, прежде чем пытаться что-либо разобрать. Не тратьте время на борьбу с HTML и файлами cookie, если вам это не нужно.
Некоторые веб-сайты все еще имеют RSS-каналы. Они сделаны так, чтобы их легко анализировали машины, но они больше не популярны, поэтому на большинстве веб-сайтов их нет. Если вы хотите извлечь данные из каких-то блогов или новостных сайтов — вам обязательно нужно проверить наличие RSS-каналов!
Ищите запросы XHR
Все современные веб-сайты (не в даркнете, лол) используют Javascript для получения данных.
Это позволяет веб-сайтам плавно открываться и загружать контент (данные) после отображения основного макета (HTML, скелет).Обычно эти данные извлекаются Javascript с помощью запросов GET/POST. Отличным примером является Producthunt:
Просто возьмите необработанные данные JSON!
Рабочий процесс прост:
- Откройте веб-страницу, которую вы хотите проанализировать
- Щелкните правой кнопкой мыши —> Проверить (открыть инструменты разработчика вашего браузера)
- Откройте вкладку «Сеть» и выберите фильтр XHR (чтобы отобразить только запросы, которые могут вам понадобиться)
- Найдите запросы, которые возвращают нужные вам данные
- Скопируйте этот запрос как cURL и используйте его в коде вашего парсера
Иногда вы замечаете, что эти XHR запросы требуют больших строк — токенов, файлов cookie и сеансов. Они генерируются с использованием Javascript или бэкэнда. Не тратьте время на изучение кода JS, чтобы понять, как они были созданы.
Вместо этого вы можете попробовать просто скопировать-вставить их из браузера в свой код — обычно они действительны в течение 7-30 дней. Возможно, это нормально для ваших нужд. Или вы можете найти другой запрос XHR (например,
/login), который выводит все необходимые токены и сеансы. В противном случае я бы предложил перейти на автоматизацию браузера (Selenium, Puppeteer, Splash и т. д.).Ищите данные JSON в HTML-коде
Но иногда в целях SEO некоторые данные уже встроены в HTML-страницу: если вы откроете исходный код любой страницы Linkedin, вы заметите огромный JSONS в ее HTML.
Просто используйте эти JSON из HTML-кода, потому что вероятность того, что его структура будет изменена, очень-очень мала. Напишите свой синтаксический анализатор для извлечения этих JSON, используя простые регулярные выражения или базовые инструменты, которые вы уже знаете.
Если вы видите данные JSON в HTML-коде страницы, вам не нужно отображать их с помощью автономных браузеров — вы можете просто использовать вызовы GET (например,
request.в Python). get Render JS
Для масштабируемости и простоты я предлагаю использовать кластеры удаленных браузеров. Недавно я нашел крутую удаленную автоматизацию сети Selenium под названием Selenoid. Их служба поддержки ужасна, но сам микросервис довольно легко запустить на вашей машине. В результате у вас будет волшебный URL-адрес, который вы вставите в свой драйвер Selenium для удаленного рендеринга всего, а не локально, например. с помощью файла chromedriver. Супер полезно.
Это мой фрагмент использования Selenoid (Python). Обратите внимание на параметр
enable_vnc: он откроет соединение VNC, чтобы увидеть, что происходит в удаленном браузере Selenoid.деф get_selenoid_driver( enable_vnc = False, browser_name = "firefox" ): возможности = { "browserName": имя_браузера, "версия": "", "enableVNC": enable_vnc, "enableVideo": Ложь, "экранРазрешение": "1280x1024x24", "sessionTimeout": "3 м", # Кто-то тоже использовал эти параметры, давайте их тоже "goog:chromeOptions": {"excludeSwitches": ["enable-automation"]}, "предпочтения": { "credentials_enable_service": Ложь, "profile. password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель После рендеринга страницы вы можете случайно найти JSON со всеми необходимыми данными в HTML-коде страницы. Опять же, попробуйте извлечь этот JSON и взять из него все необходимые данные вместо того, чтобы пытаться анализировать HTML-теги и поля, которые могут измениться на следующей неделе.
driver.get(url_to_open) html = driver.page_source
Анализ HTML
Если вы не можете найти в HTML-коде страницы ни правильный XHR-запрос, ни JSON, это означает, что веб-сайт использует SSR, который предварительно заполняет все данные. В этом редкий случай (вероятно, старый сайт), остается только попытаться извлечь нужные данные с помощью селекторов CSS или XPath.
Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются.Надеюсь, это было полезно. Пожалуйста, пишите мне комментарии и вопросы. Увидимся в ближайшее время для получения дополнительных руководств по синтаксическому анализу и ELT! 👋
Основы парсинга веб-страниц. Как очистить данные с веб-сайта в… | Сонхао Ву
Как извлечь данные с веб-сайта в Python
Фото Franck V из Unsplash
В науке о данных мы всегда говорим «Мусор в мусоре». Если у вас нет хорошего качества и количества данных, скорее всего, вы не получите много информации из них. Веб-скрейпинг — один из важных методов автоматического извлечения сторонних данных. В этой статье я расскажу об основах парсинга веб-страниц и использую два примера, чтобы проиллюстрировать два разных способа сделать это в Python.
Что такое Web Scraping
Web Scraping — это автоматический способ извлечения неструктурированных данных с веб-сайта и их сохранения в структурированном формате.
Например, если вы хотите проанализировать, какие маски для лица могут лучше продаваться в Сингапуре, вы можете собрать всю информацию о масках для лица на веб-сайте электронной коммерции, таком как Lazada.Можете ли вы очистить данные со всех веб-сайтов?
Скрапинг увеличивает посещаемость веб-сайта и может привести к выходу из строя сервера веб-сайта. Таким образом, не все веб-сайты позволяют людям выполнять парсинг. Как узнать, какие сайты разрешены, а какие нет? Вы можете посмотреть файл robots.txt на сайте. Вы просто помещаете robots.txt после URL-адреса, который хотите очистить, и вы увидите информацию о том, позволяет ли хост веб-сайта вам очищать веб-сайт.
Возьмем для примера Google.com
Файл robots.txt Google.com
Как видите, Google не разрешает парсинг для многих своих дочерних веб-сайтов. Тем не менее, он допускает определенные пути, такие как «/m/finance», и, таким образом, если вы хотите собирать информацию о финансах, то это абсолютно легальное место для парсинга.
Другое замечание, что вы можете видеть из первой строки на User-agent. Здесь Google указывает правила для всех пользовательских агентов, но веб-сайт может дать определенному пользовательскому агенту специальное разрешение, поэтому вы можете обратиться к информации там.
Как работает просмотр веб-страниц?
Веб-скрапинг просто работает как бот, просматривающий разные страницы веб-сайта и копирующий вставку всего содержимого. Когда вы запускаете код, он отправляет запрос на сервер, и данные содержатся в полученном вами ответе. Затем вы анализируете данные ответа и извлекаете нужные части.
Как мы делаем парсинг в Интернете?
Итак, мы здесь. Существует 2 разных подхода к парсингу веб-страниц в зависимости от того, как веб-сайт структурирует свое содержимое.
A подход 1: Если веб-сайт хранит всю свою информацию в интерфейсе HTML, вы можете напрямую использовать код для загрузки содержимого HTML и извлечения полезной информации.
Примерно 5 шагов, как показано ниже:
- Проверка HTML-кода веб-сайта, который необходимо просканировать
- Доступ к URL-адресу веб-сайта с помощью кода и загрузка всего HTML-содержимого на странице читаемый формат
- Извлеките полезную информацию и сохраните ее в структурированном формате.
- Для информации, отображаемой на нескольких страницах веб-сайта, вам может потребоваться повторить шаги 2–4, чтобы получить полную информацию.
Плюсы и минусы этого подхода: Это просто и прямолинейно. Однако, если структура внешнего интерфейса веб-сайта изменится, вам необходимо соответствующим образом скорректировать свой код.
Подход 2: Если веб-сайт хранит данные в API и веб-сайт запрашивает API каждый раз, когда пользователь посещает веб-сайт, вы можете имитировать запрос и напрямую запрашивать данные из API
Шаги:
- Проверьте сетевой раздел XHR URL-адреса, который вы хотите просканировать
- Найдите запрос-ответ, который дает вам данные, которые вы хотите get), а также заголовок и полезная нагрузка запроса, имитируйте запрос в своем коде и извлекайте данные из API. Обычно данные, полученные от API, имеют довольно аккуратный формат.
- Извлечение полезной информации, которая вам нужна
- Для API с ограничением на размер запроса вам потребуется использовать «цикл for» для многократного извлечения всех данных
Плюсы и минусы этого подхода: Это определенно предпочтительный подход, если вы можете найти запрос API. Полученные данные будут более структурированными и стабильными. Это связано с тем, что по сравнению с внешним интерфейсом веб-сайта компания с меньшей вероятностью изменит свой внутренний API. Однако он немного сложнее первого подхода, особенно если требуется аутентификация или токен.
Различные инструменты и библиотеки для парсинга веб-страниц
Существует множество различных инструментов парсинга, не требующих программирования. Тем не менее, большинство людей по-прежнему используют библиотеку Python для парсинга веб-страниц, потому что она проста в использовании, а также вы можете найти ответ в ее большом сообществе.
Наиболее часто используемая библиотека для парсинга веб-страниц в Python — это Beautiful Soup, Requests и Selenium .
Beautiful Soup: Помогает анализировать документы HTML или XML в удобочитаемом формате. Это позволяет вам искать различные элементы в документах и помогает быстрее находить необходимую информацию.
Запросы: Это модуль Python, в котором вы можете отправлять HTTP-запросы для получения содержимого. Это поможет вам получить доступ к содержимому HTML или API веб-сайта, отправив запросы Get или Post.
Selenium: Он широко используется для тестирования веб-сайтов и позволяет автоматизировать различные события (щелчок, прокрутка и т. д.) на веб-сайте для получения желаемых результатов.
Вы можете использовать Requests + Beautiful Soup или Selenium для очистки веб-страниц. Selenium предпочтительнее, если вам нужно взаимодействовать с веб-сайтом (события JavaScript), а если нет, я предпочту Requests + Beautiful Soup, потому что это быстрее и проще .
Веб-скрейпинг Пример:
Постановка задачи: Я хочу узнать о местном рынке масок для лица. Меня интересует цена маски для лица в Интернете, скидки, рейтинги, количество проданных товаров и т. д. вы можете щелкнуть правой кнопкой мыши и выбрать «проверить»)
Проверить страницу Lazada в ChromeHTML, чтобы узнать цену на Lazada
. Я вижу, что все данные, которые мне нужны, заключены в элемент HTML с уникальным именем класса.
Шаг 2: Получите доступ к URL-адресу веб-сайта с помощью кода и загрузите все HTML-содержимое страницы
# импортировать библиотеку
из bs4 import BeautifulSoup
import request# Запрос на веб-сайт и загрузку HTML-содержимого
url='https: //www.lazada.sg/catalog/?_keyori=ss&from=input&q=mask'
req=requests.get(url)
content=req.textЗапрос содержимого перед применением Beautiful Soup
Я использовал библиотеку запросов для получения данных с веб-сайта.
Вы можете видеть, что пока у нас есть неструктурированный текст.Шаг 3: Форматирование загруженного контента в читаемый формат
суп=BeautifulSoup(content)
Этот шаг очень прост, и мы просто анализируем неструктурированный текст в Beautiful Soup, и вы получаете следующее.
HTML-контент после использования Beautiful Soup
Формат вывода гораздо более удобочитаем, и вы можете искать в нем различные элементы или классы HTML.
Шаг 4. Извлеките полезную информацию и сохраните ее в структурированном формате
Этот шаг требует некоторого времени, чтобы понять структуру веб-сайта и выяснить, где именно хранятся данные. В случае с Lazada он хранится в разделе Script в формате JSON.
raw=soup.findAll('script')[3].text
page=pd.read_json(raw.split("window.pageData=")[1],orient='records')
#Хранить данные
для элемента в page.loc['listItems','mods']:
brand_name.append(item['brandName'])
price. append(item['price'])
location.append(item['location' ])
description.append(ifnull(item['description'],0))
rating_score.append(ifnull(item['ratingScore'],0))Я создал 5 разных списков для хранения различных полей данных, которые я нуждаться. Я использовал здесь цикл for, чтобы пройтись по списку элементов в документах JSON внутри. После этого я объединяю 5 столбцов в выходной файл.
# сохранить данные в вывод
output=pd.DataFrame({'brandName':brand_name,'price':price,'location':location,'description':description,'rating score':rating_score})Окончательный вывод в формате Python DataFrame
Шаг 5: Для информации, отображаемой на нескольких страницах веб-сайта, вам может потребоваться повторить шаги 2–4, чтобы получить полную информацию.
Если вы хотите очистить все данные. Во-первых, вы должны узнать об общем количестве продавцов. Затем вы должны перебирать страницы, передавая добавочные номера страниц, используя полезную нагрузку для URL.
Ниже приведен полный код, который я использовал для очистки, и я перебираю первые 50 страниц, чтобы получить контент на этих страницах.для i в диапазоне (1,50):
time.sleep(max(random.gauss(5,1),2))
print('page'+str(i))
payload['page'] =i
req=requests.get(url,params=payload)
content=req.text
суп=BeautifulSoup(content)
raw=soup.findAll('script')[3].text
page=pd.read_json (raw.split("window.pageData=")[1],orient='records')
для элемента в page.loc['listItems','mods']:
brand_name.append(item['brandName'] )
price.append(item['price'])
location.append(item['location'])
description.append(ifnull(item['description'],0))
rating_score.append(ifnull(item['ratingScore'],0))Пример подхода 2 (запрос данных непосредственно из API) — Ezbuy:
Шаг 1. Проверьте сетевой раздел XHR URL-адреса, который вы хотите просканировать, и найдите запрос-ответ, который дает вам нужные данные можно увидеть из Сети, что вся информация о продукте указана в этом API под названием «Список продуктов по состоянию».
Ответ дает мне все данные, которые мне нужны, и это запрос POST.Шаг 2: В зависимости от типа запроса (отправить или получить), а также заголовка запроса и полезной нагрузки смоделируйте запрос в своем коде и получите данные из API. Обычно данные, полученные от API, имеют довольно аккуратный формат.
s=requests.session()#Define API url
url_search='https://sg-en-web-api.ezbuy.sg/api/EzCategory/ListProductsByCondition'#Define заголовок для почтового запроса
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/83.0.4103.116 Safari/537.36'}#Define полезная нагрузка для формы запроса
data={
"searchCondition":
{"categoryId":0,"freeShippingType":0,"filter: [],"keyWords":"mask"},
"limit": 100,
"смещение": 0,
"язык": "en",
"dataType": "новый"
}req=s.post(url_search,headers=headers,json=data)Здесь я создаю Запрос HTTP POST с использованием библиотеки запросов.
Для почтовых запросов вам необходимо определить заголовок запроса (настройка запроса) и полезную нагрузку (данные, которые вы отправляете с этим почтовым запросом). Иногда здесь требуется токен или аутентификация, и вам нужно будет сначала запросите токен, прежде чем отправлять запрос POST. Здесь нет необходимости извлекать токен, и обычно просто следуйте тому, что находится в полезной нагрузке запроса в сети, и определяйте «пользовательский агент» для заголовка.Еще одна вещь, которую следует отметить, это то, что внутри полезной нагрузки я указал предел как 100 и смещение как 0, потому что я обнаружил, что это позволяет мне запрашивать только 100 строк данных за один раз. Таким образом, что мы можем сделать позже, так это использовать цикл for для изменения смещения и запроса дополнительных точек данных.
Шаг 3. Извлеките полезную информацию, которая вам нужна
#прочитайте данные обратно в виде файла json
j=req.json()# Сохраните данные в полях
для элемента в j['products']:
price. append(элемент['цена'])
location.append(item['originCode'])
name.append(item['name'])
ratingScore.append(item['leftView']['rateScore'])
количество.append(item['rightView ']['text'].split(' Sold')[0]#Объединить все столбцы вместе
output=pd.DataFrame({'Name':name,'price':price,'location':location,' Rating Score':ratingScore,'Quantity Sold':quantity})Данные из API обычно достаточно аккуратны и структурированы, поэтому я просто читал их в формате JSON, после чего извлекал полезные данные в разные столбцы и объединить их вместе в качестве выходных данных.Вы можете увидеть выходные данные ниже.
Вывод данных маски для лица EZbuy
Шаг 4: Для API с ограничением на размер запроса вам потребуется использовать «цикл for» для повторного получения всех данных
#Define API url
url_search='https:// sg-en-web-api.ezbuy.sg/api/EzCategory/ListProductsByCondition'#Определить заголовок для почтового запроса
headers={'user-agent':'Mozilla/5. 0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/ 537,36 (KHTML, например Gecko) Chrome/83.0.4103.116 Safari/537.36'} для i в диапазоне (0,14000,100):
time.sleep(max(random.gauss(3,1),2))
print(i)
data={
"searchCondition":
{"categoryId":0,"freeShippingType":0,"filters":
[],"keyWords":"mask"},
"limit": 100,
"смещение": i,
"язык": "en",
"dataType": "новый"
}
req=s.post(url_search,headers=headers,json=data)
j=req. json()
для товара в j['products']:
price.append(item['price'])
location.append(item['originCode'])
name.append(item['name'])
ratingScore.append(item['leftView']['rateScore'])
quantity.append(item['rightView']['text'].split('Продано')[0])#Объединить все столбцы вместе
output=pd.DataFrame({'Name':name,'price':price,'location':location,'Rating Score':ratingScore,'Quantity Sold':quantity})Вот полный код для очистки все строки данных о масках для лица в Ezbuy.
Я обнаружил, что общее количество строк составляет 14 тыс., и поэтому я пишу цикл for, чтобы пройти через число возрастающих смещений, чтобы запросить все результаты. Еще одна важная вещь, на которую следует обратить внимание, это то, что я установил случайный тайм-аут в начале каждого цикла. Это потому, что я не хочу, чтобы очень частые HTTP-запросы вредили трафику веб-сайта и были обнаружены веб-сайтом.Наконец, Рекомендация
Если вы хотите очистить веб-сайт, я бы посоветовал сначала проверить наличие API в сетевом разделе , используя команду inspect. Если вы сможете найти ответ на запрос, который предоставит вам все необходимые данные, вы сможете создать стабильное и аккуратное решение. Если вы не можете найти данные в сети, вам следует попробовать использовать запросы или Selenium для загрузки HTML-контента и использовать Beautiful Soup для форматирования данных. Наконец, используйте тайм-аут, чтобы избежать слишком частых посещений веб-сайта или API.
 Это означает, что макет (HTML) и форматирование данных могут быть легко изменены на следующей неделе. В идеале вы хотите закодировать синтаксический анализатор один раз и без периодической адаптации его к новому макету.
Это означает, что макет (HTML) и форматирование данных могут быть легко изменены на следующей неделе. В идеале вы хотите закодировать синтаксический анализатор один раз и без периодической адаптации его к новому макету. Это позволяет веб-сайтам плавно открываться и загружать контент (данные) после отображения основного макета (HTML, скелет).
Это позволяет веб-сайтам плавно открываться и загружать контент (данные) после отображения основного макета (HTML, скелет).
 get
get  password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель
password_manager_enabled": Ложь
},
}
драйвер = webdriver.Remote(
command_executor = SELENOID_URL,
желательные_возможности = возможности,
)
driver.implicitly_wait(10) # ждем загрузки страницы несмотря ни на что
если включить_vnc:
print(f"Вы можете просмотреть VNC здесь: {SELENOID_WEB_URL}")
обратный водитель  Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются.
Мой единственный совет здесь — попытаться свести к минимуму запросы и фильтры, используемые для предотвращения переобучения и получения NULL вывода, если некоторые блоки страницы переключаются или слегка изменяются. Например, если вы хотите проанализировать, какие маски для лица могут лучше продаваться в Сингапуре, вы можете собрать всю информацию о масках для лица на веб-сайте электронной коммерции, таком как Lazada.
Например, если вы хотите проанализировать, какие маски для лица могут лучше продаваться в Сингапуре, вы можете собрать всю информацию о масках для лица на веб-сайте электронной коммерции, таком как Lazada.
 Обычно данные, полученные от API, имеют довольно аккуратный формат.
Обычно данные, полученные от API, имеют довольно аккуратный формат.

 Вы можете видеть, что пока у нас есть неструктурированный текст.
Вы можете видеть, что пока у нас есть неструктурированный текст. append(item['price'])
append(item['price']) 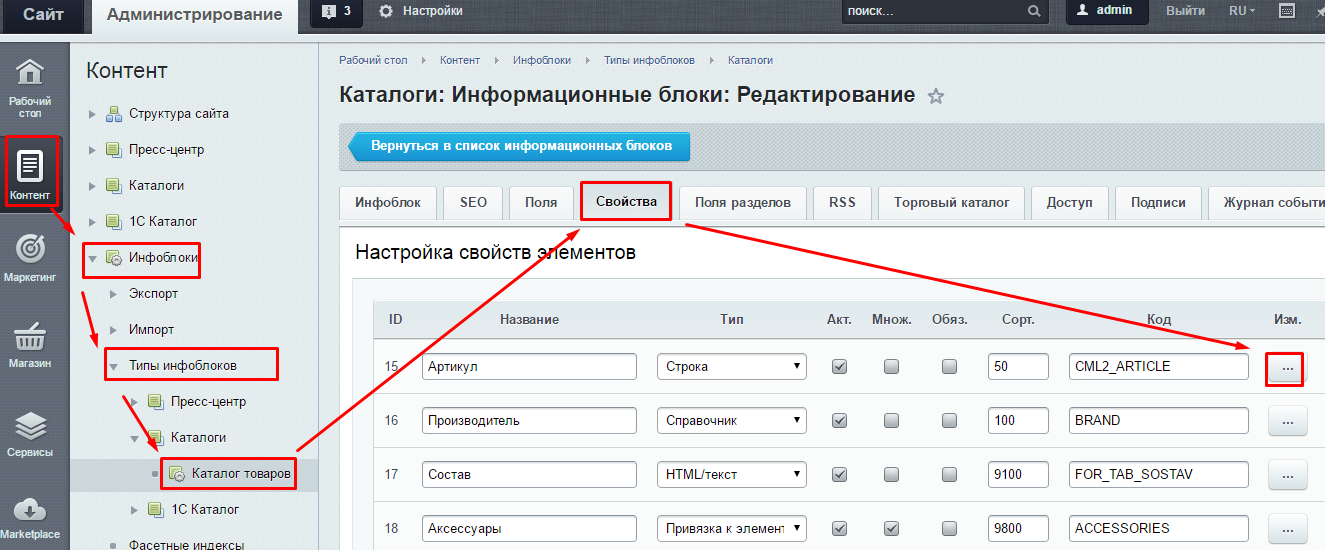 Ниже приведен полный код, который я использовал для очистки, и я перебираю первые 50 страниц, чтобы получить контент на этих страницах.
Ниже приведен полный код, который я использовал для очистки, и я перебираю первые 50 страниц, чтобы получить контент на этих страницах. Ответ дает мне все данные, которые мне нужны, и это запрос POST.
Ответ дает мне все данные, которые мне нужны, и это запрос POST. Для почтовых запросов вам необходимо определить заголовок запроса (настройка запроса) и полезную нагрузку (данные, которые вы отправляете с этим почтовым запросом). Иногда здесь требуется токен или аутентификация, и вам нужно будет сначала запросите токен, прежде чем отправлять запрос POST. Здесь нет необходимости извлекать токен, и обычно просто следуйте тому, что находится в полезной нагрузке запроса в сети, и определяйте «пользовательский агент» для заголовка.
Для почтовых запросов вам необходимо определить заголовок запроса (настройка запроса) и полезную нагрузку (данные, которые вы отправляете с этим почтовым запросом). Иногда здесь требуется токен или аутентификация, и вам нужно будет сначала запросите токен, прежде чем отправлять запрос POST. Здесь нет необходимости извлекать токен, и обычно просто следуйте тому, что находится в полезной нагрузке запроса в сети, и определяйте «пользовательский агент» для заголовка.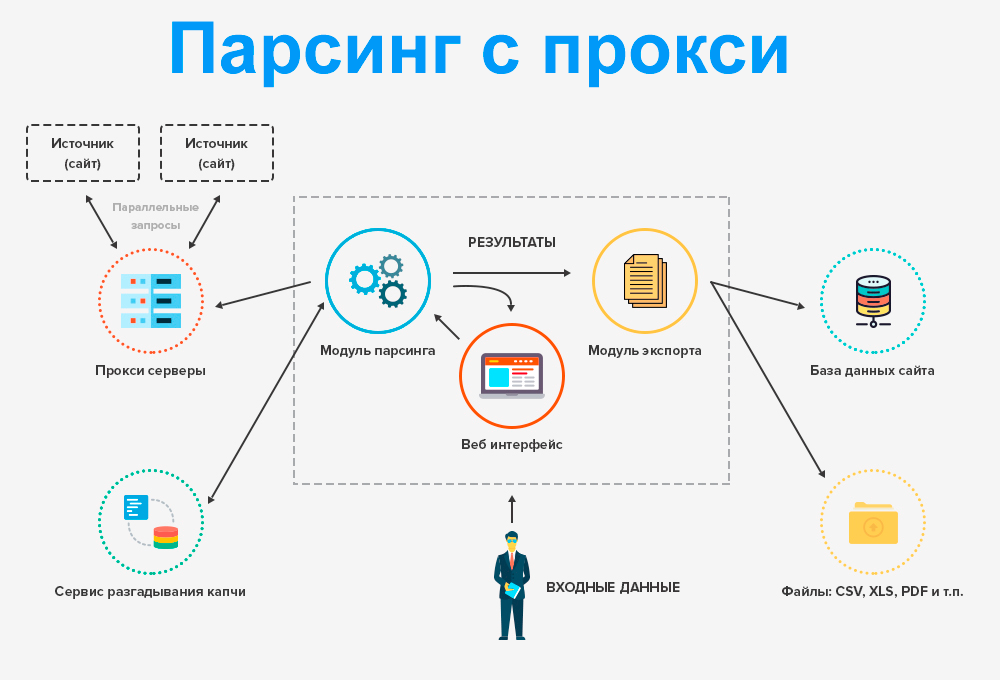 append(элемент['цена'])
append(элемент['цена'])  0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/ 537,36 (KHTML, например Gecko) Chrome/83.0.4103.116 Safari/537.36'} для i в диапазоне (0,14000,100):
0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/ 537,36 (KHTML, например Gecko) Chrome/83.0.4103.116 Safari/537.36'} для i в диапазоне (0,14000,100):  Я обнаружил, что общее количество строк составляет 14 тыс., и поэтому я пишу цикл for, чтобы пройти через число возрастающих смещений, чтобы запросить все результаты. Еще одна важная вещь, на которую следует обратить внимание, это то, что я установил случайный тайм-аут в начале каждого цикла. Это потому, что я не хочу, чтобы очень частые HTTP-запросы вредили трафику веб-сайта и были обнаружены веб-сайтом.
Я обнаружил, что общее количество строк составляет 14 тыс., и поэтому я пишу цикл for, чтобы пройти через число возрастающих смещений, чтобы запросить все результаты. Еще одна важная вещь, на которую следует обратить внимание, это то, что я установил случайный тайм-аут в начале каждого цикла. Это потому, что я не хочу, чтобы очень частые HTTP-запросы вредили трафику веб-сайта и были обнаружены веб-сайтом.