Содержание
Рендеринг веб сайтов 101 / Хабр
Вы вводите название сайта в адресную строку браузера, нажимаете enter, и по привычке видите запрашиваемую страницу. Все просто: ввел название сайта — сайт отобразился. Однако для более любознательных хочу рассказать, что происходит между тем как браузер начинает получать куски сайта (да, сайт приходит кусками, по-другому — чанками) и отображает полностью нарисованную страницу.
Как устроен браузер?
Перед историей о том, как браузер рисует страницу, важно понять как он устроен, какие процессы и на каком уровне выполняются. При знакомстве с процессом рендеринга мы не раз вспомним о компонентах браузера. Итак, под капотом браузер выглядит примерно следующим образом:
User Interface — это все что видит пользователь: адресная строка, кнопки вперед/назад, меню, закладки — за исключением области где отображается сайт.
Browser Engine отвечает за взаимодействие между User Interface и Rendering Engine. Например клик по кнопке назад должен сказать компоненте RE что нужно отрисовать предыдущее состояние.
Например клик по кнопке назад должен сказать компоненте RE что нужно отрисовать предыдущее состояние.
Rendering Engine отвечает за отображение веб-страницы. В зависимости от типа файла, эта компонента может парсить и рендерить как HTML/XML и CSS, так и PDF .
Network выполняет xhr запросы за ресурсами, и в целом, общение браузера с остальным интернетом происходит через эту компоненту, включая проксирование, кэширование и так далее.
JS Engine место где парсится и исполняется js код.
UI Backend используется чтобы рисовать стандартные компоненты типа чекбоксов, инпутов, кнопок.
Data Persistence отвечает за хранение локальных данных, например в куках, SessionStorage, indexDB и так далее.
Далее узнаем как рассмотренные компоненты браузера взаимодействуют между собой и разберем подробнее, что происходит внутри Rendering Engine. Другими словами …
Как браузер переводит html в пиксели на экране?
Итак, с помощью компонента Network браузер начал получать html-файл чанками обычно по 8кб, что дальше? А далее идет процесс парсинга (спецификация процесса) и рендеринга этого файла в компоненте, как вы уже догадались — Rendering Engine.
Важно! Для повышения юзабилити, браузер не дожидается пока загрузится и распарсится весь html. Вместо этого браузер сразу пытается отобразить пользователю страницу (далее рассмотрим как).
Сам процесс парсинга выглядит так:
Результатом парсинга является DOM дерево. Возьмем к примеру такой html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Web Rendering</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div>
<div>
<h2>Hey</h2>
</div>
<div>
<p>
Lorem <span>ipsum</span>.
</p>
</div>
<footer>
Contact me
</footer>
</div>
<script src="./code.js"></script>
</body>
</html>
DOM дерево такого html файла будет выглядеть так:
По мере того как браузер парсит html файл, он встречает теги содержащие ссылки на сторонние ресурсы ( <link>, <script>, <img> и так далее) — по мере их обнаружения происходит запрос за этими ресурсами.
Таким образом, отправив запрос по адресу прописанному в атрибуте href тега <link rel=»stylessheet»> и получив файл css стилей, браузер парсит этот файл и строит так называемый CSS Object Model — CSSOM.
Представим что у нас есть такой файл стилей:
body {
font-size: 14px;
}
.wrapper {
width: 960px;
margin: 0 auto;
}
.wrapper .header h2 {
font-size: 26px;
}
.wrapper p {
color: red;
}
footer {
padding: 20px 0;
}
Из которого получим такой CSSOM:
Attention: тут построено дерево из стилей нашего css-файла. Кроме того, также есть user agent’s styles — дефолтные стили браузера и инлайновые стили — прописанные в html тегах.
Подробнее об алгоритме парсинга css стилей можно прочитать в спецификации.
Теперь у нас есть DOM и CSSOM - первый отвечает на вопрос «что?», второй на вопрос «как?». Если думаете, что следующим этапом является соединение DOM и CSSOM’а, то вы совершенно правы! DOM + CSSOM = Render Tree.
Render Tree — это дерево видимых (!) элементов построенных в том порядке, в котором они должны рендериться на странице. Обратите внимание, что элементы имеющие css правило display: none или другие, отрицательно влияющие на отображение — не будут находится в render tree.
Браузер строит Render Tree чтобы точно определить что ему нужно отрисовать и в каком порядке. Построение Render дерева происходит примерно так: начиная с рутового элемента (html), парсер проходит по всем видимым элементам (пропуская link, script, meta, скрытые через css элементы) и для каждого видимого элемента находит соответствующее css правило из CSSOM.
В движке firefox’a элементы Render Tree называются фреймами (frames). Webkit использует термин renderer или render object. Render object знает как разместить себя на странице, а так же содержит информацию о своих дочерних элементах. И для самых любознательных, если заглянуть в исходники webkit’a — можно найти класс который так и называется — RenderObject.
Продолжая наш пример мы получим такой Render Tree:
На данный момент мы имеем в некотором состоянии Render Tree — дерево содержащее информацию о том что и как нужно отрисовать. Теперь браузер должен понять на каком месте и с какими размерами будет отображаться элемент. Процесс вычисления позиции и размеров называется Layout.
Layout — это рекурсивный процесс определения положения и размеров элементов из Render Tree. Он начинается от корневого Render Object, которым является , и проходит рекурсивно вниз по части или всей иерархии дерева высчитывая геометрические размеры дочерних render object’ов. Корневой элемент имеет позицию (0,0) и его размеры равны размерам видимой части окна, то есть размеру viewport’a.
В Html используется поточная модель компоновки (flow based layout), другими словами геометрические размеры элементов в некоторых случаях можно рассчитать за один проход (если элементы, встречающиеся в потоке позже, не влияют на позицию и размеры уже пройденных элементов).
Layout может быть глобальный, когда требуется рассчитать положение render object’ов всего дерева, и инкрементальный, когда требуется рассчитать только часть дерева. Глобальный layout происходит, например, при изменении размеров шрифта или при событии resize’a. Инкрементальный layout происходит только для render object’ов, помеченных как «dirty».
Пара слов о «системе грязных битов (dirty bit system)». Эта система используется браузерами для оптимизации процесса, чтобы не пересчитывать весь layout. При добавлении нового или изменении существующего render object — он сам и его дочерние элементы помечаются флагом «dirty». Если render object не изменяется, но его дочерние элементы были изменены или добавлены, то этот render object помечается как «children are dirty».
К концу процесса layout каждый render object имеет свое положение и размеры.
Подводя промежуточный итог: браузер знает что, как и где рисовать. Следовательно — осталось только нарисовать. Этот процесс, как ни странно, называется Paint.
Следовательно — осталось только нарисовать. Этот процесс, как ни странно, называется Paint.
Paint — этап, где пиксель монитора заполняется цветом указанным в свойствах render object’а и белый экран превращается в картину задуманную автором (разработчиком). На всем пути рендеринга — это самый дорогой процесс (не то чтобы предыдущее дешевые).
Также, как и процесс layout, отрисовка (paint) может быть глобальной — дерево перерисовывается полностью, и инкрементальной — дерево перерисовывается частично. Для частичного перерисовывания render object помечает свой rectangle как невалидный. Операционная система расценивает эту область как требующую перерисовки и вызывает событие paint. При этом браузер умеет объединять области, чтобы выполнить разом перерисовку для всех мест, где это необходимо.
Определение размеров и положения элементов дерева (layout) и перерисовка (paint) являются дорогостоящими процессами. Они выполняются на уровне CPU. Разрабатывая динамические веб приложения, в которых эти процессы будут запускаться очень часто — мы никогда не достигнем плавных анимаций.
Значит, должно быть что-то, что помогло бы создавать сайты с богатой анимацией, при этом не нагружая CPU и рисуя каждый кадр менее чем за 16,6мс (60 fps). Действительно, браузер выполняет еще один этап, который помогает оптимизировать динамику сайтов — Composite (композиция).
Перед композицией, все нарисованные элементы находятся на одном слое (memory layer). То есть, изменение параметров (например, геометрических размеров или положения) одних элементов повлекут перерасчет параметров соседних элементов. Но если распределить элементы на композиционные слои — изменение параметров элемента вызовут перерасчет только на определенном слое, не затрагивая при этом элементы на других слоях. Таким образом, этот процесс является самым дешевым по производительности, поэтому нужно стараться вносить изменения вызывающие только composite.
Резюмируя вышесказанное, получаем такой процесс рендеринга веб страницы:
TLDR;
Браузер получает html файл, парсит его и строит DOM. Встречая css стили, браузер их подгружает, парсит, строит CSSOM и объединяет вместе с DOM’ом — получаем Render Tree. Осталось выяснить где расположить элементы из Render Tree — этим занимается задача layout. После расположения элементов, можно начать рисовать их — это задача paint, этап на котором заполняются пиксели экрана.
Встречая css стили, браузер их подгружает, парсит, строит CSSOM и объединяет вместе с DOM’ом — получаем Render Tree. Осталось выяснить где расположить элементы из Render Tree — этим занимается задача layout. После расположения элементов, можно начать рисовать их — это задача paint, этап на котором заполняются пиксели экрана.
Динамика
Что происходит когда изменяется css свойство? Или, например, добавляется новый dom узел? В случае изменения css свойств все зависит от изменяемого свойства. Есть только два свойства которые вызывают задачу composite — это opacity и transform. Только эти два свойства являются самыми дешевыми для анимации. К примеру, изменение background вызовет задачу paint (затем composite), а изменение display вызовет сначала layout, далее paint, после чего composite. Список задач, которые вызываются изменениями стилей можно посмотреть на csstriggers.com.
При добавлении новой ноды в dom дерево — очевидно браузеру нужно добавить новый объект в дерево, посчитать его положение на странице, посчитать положения других элементов на странице (если они были аффектнуты новым элементом), и в конце все это нарисовать — звучит дорого. Поэтому делая такие операции необходимо иметь в виду производительность, ведь не каждый пользователь интернета запускает ваше веб-приложение на самой последней модели устройства.
Поэтому делая такие операции необходимо иметь в виду производительность, ведь не каждый пользователь интернета запускает ваше веб-приложение на самой последней модели устройства.
Подводя итог, мы рассмотрели из каких компонентов состоит браузер, как они взаимодействуют друг с другом и как Rendering Engine рисует страницу пользователю.
Посмотреть вышеописанное можно в devtools’ах хрома, но чтобы не выходить за рамки названия статьи — на этом пока все.
Источники
- https://blog.algolia.com/performant-web-animations/
- https://www.zeolearn.com/magazine/components-of-web-browsers
- https://www.html5rocks.com/ru/tutorials/internals/howbrowserswork
- https://blog.sessionstack.com/how-javascript-works-the-rendering-engine-and-tips-to-optimize-its-
performance-7b95553baeda - https://developers.google.com/web/fundamentals/performance/rendering
Как работают браузеры — Web Performance
Пользователи хотят использовать приложения, в которых загрузка контента происходит быстро, а взаимодействие — плавно. Разработчик должен стараться оптимизировать своё приложение как минимум по этим двум показателям.
Разработчик должен стараться оптимизировать своё приложение как минимум по этим двум показателям.
Чтобы понять, как улучшить производительность и ощущаемую пользователем производительность (User Perceived Performance, UPP), вам необходимо понимать, как работают браузеры.
Быстрые приложения дают лучшие ощущения. Пользователи ожидают, что приложение будет грузиться быстро, а взаимодействие с ним будет плавным.
Две главных проблемы в производительности — это проблема скорости сети и проблема однопоточности браузеров.
Сетевые задержки — это главная проблема, которую нужно преодолеть для достижения быстрой загрузки. Чтобы ускорить загрузку разработчик должен посылать запрошенные данные как можно быстрее или, на худой конец, сделать вид, что они отправляются очень быстро. Сетевые задержки — это время, которое требуется для передачи данных от источника к браузеру. Производительность здесь — это то, что делает загрузку страниц как можно более быстрой.
В большинстве своём браузеры рассматриваются как однопоточные приложения. Чтобы достичь плавности взаимодействия, разработчик должен обеспечивать производительность во всём, начиная от плавного скроллинга, до быстрой реакции на нажатие экрана. Время рендера — это ключевое понятие. Разработчик должен обеспечить такую работу приложения, чтобы все его задачи могли быть выполнены достаточно быстро. В таком случае процессор будет свободен для обработки пользовательского ввода. Для решения проблемы однопоточности вы должны понять природу браузеров и научиться разгружать основной поток процесса там, где это возможно и допустимо.
Чтобы достичь плавности взаимодействия, разработчик должен обеспечивать производительность во всём, начиная от плавного скроллинга, до быстрой реакции на нажатие экрана. Время рендера — это ключевое понятие. Разработчик должен обеспечить такую работу приложения, чтобы все его задачи могли быть выполнены достаточно быстро. В таком случае процессор будет свободен для обработки пользовательского ввода. Для решения проблемы однопоточности вы должны понять природу браузеров и научиться разгружать основной поток процесса там, где это возможно и допустимо.
Навигация — это первый этап при загрузке приложения. Он происходит каждый раз, когда пользователь запрашивает страницу, вводя URL в адресную строку браузера, нажимает на ссылку, отправляет заполненные поля формы и выполняет некоторые другие действия.
Одна из задач разработчика — сократить время, которое требуется приложению, чтобы этап навигации завершился. В идеальных условиях это обычно не занимает много времени, но задержки сети и ширина канала — препятствия, которые приводят к задержкам загрузки приложения.
DNS запрос
Первый шаг навигации к странице — это поиск места, откуда нужно запрашивать данные. Если вы переходите на https://example.com, браузер грузит HTML-код страницы с IP-адреса 93.184.216.34. Если вы никогда ранее не были на этом сайте, произойдёт поиск DNS записи.
Ваш браузер запрашивает DNS запись. Как правило, запрос содержит имя сервера, который должен быть преобразован в IP-адрес. Ответ на этот запрос какое-то время будет сохранён в кеше устройства, чтобы его можно было быстро получить при следующем запросе к тому же серверу.
DNS запрос обычно требуется совершить лишь единожды при загрузке страницы. Однако, DNS запросы должны быть выполнены для каждого уникального имени хоста, который запрашивается страницей. Скажем, если ваши шрифты, картинки, скрипты, реклама или счётчики аналитики находятся на разных доменах, DNS запрос будет осуществлён для каждого из них.
Это может быть проблемой с точки зрения производительности, особенно для мобильных сетей. Когда пользователь находится в мобильной сети, каждый DNS запрос должен пройти от мобильного устройства до сотовой вышки, а уже оттуда дойти до авторитетного DNS-сервера. Расстояние и помехи между телефоном, вышкой и сервером имён могут значительно увеличить задержку.
Когда пользователь находится в мобильной сети, каждый DNS запрос должен пройти от мобильного устройства до сотовой вышки, а уже оттуда дойти до авторитетного DNS-сервера. Расстояние и помехи между телефоном, вышкой и сервером имён могут значительно увеличить задержку.
TCP Рукопожатие (Handshake)
В тот момент, когда IP адрес становится известен, браузер начинает установку соединения к серверу с помощью рукопожатия TCP three-way handshake (en-US). Этот механизм спроектирован так, чтобы два устройства, пытающиеся установить связь, могли обменяться параметрами соединения, прежде чем приступать к передаче данных. Чаще всего — через защищённое соединение HTTPS.
Трёхэтапное рукопожатие TCP — это техника, очень часто упоминаемая как «SYN-SYN-ACK» (SYN, SYN-ACK, ACK, если быть точнее), т.к. при установке соединения передаются 3 сообщения. Это означает, что прежде чем установится соединение, браузер должен обменяться ещё тремя сообщениями с сервером.
TLS Переговоры (Negotiation)
Для установки безопасных соединений с использованием HTTPS требуется ещё одно рукопожатие. На этот раз — TLS переговоры. На этом шаге определяется, какой шифр будет использоваться для шифрования соединения, удостоверяется надёжность сервера и устанавливается безопасное соединение. Этот шаг также требует несколько дополнительных сообщений, которыми должны обменяться сервер и браузер, прежде чем данные будут посланы.
И хотя обеспечение безопасности соединения снижает скорость загрузки приложения, безопасное соединение стоит затрат на него, так как в этом случае данные не могут быть дешифрованы третьим лицом.
После обмена восемью сообщениями, браузер, наконец, достигает всех условий, чтобы сделать запрос.
Как только мы установили соединение с веб-сервером, браузер отправляет инициирующий HTTP GET запрос от имени пользователя. Чаще всего запрашивается HTML файл. В момент, когда сервер получает запрос, он начинает ответ с посылки заголовков ответа и содержимым HTML-файла.
<!doctype HTML>
<html>
<head>
<meta charset="UTF-8"/>
<title>My simple page</title>
<link rel="stylesheet" src="styles.css"/>
<script src="myscript.js"></script>
</head>
<body>
<h2>My Page</h2>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myimage.jpg" alt="image description"/>
</div>
<script src="anotherscript.js"></script>
</body>
</html>
Этот ответ содержит в себе первый байт полученных данных. Время до первого байта (Time to First Byte, TTFB) — это время между моментом когда пользователь отправил запрос, скажем, нажав на ссылку, и моментом получения первого пакета данных HTML. Первый пакет обычно содержит 14КБ данных.
В примере выше ответ значительно меньше, чем 14КБ; скрипты и стили, перечисленные в ответе, не будут запрошены, пока браузер не обработает ответ. Процесс обработки ответа — парсинг — мы обсудим отдельно.
Процесс обработки ответа — парсинг — мы обсудим отдельно.
TCP медленный старт / правило 14kb
Объём первого пакета данных — всегда 14KB. Это часть спецификации TCP slow start (en-US) — алгоритма, который балансирует скорость соединения. Такое правило позволяет постепенно, по мере необходимости, увеличивать размеры передаваемых данных, пока не будет определена максимальная ширина канала.
В алгоритме TCP slow start (en-US) каждый следующий отправленный сервером пакет увеличивается в размере в два раза. Например, размер второго пакета будет около 28КБ. Размер пакетов будет увеличиваться до тех пор, пока не достигнет какого-то порогового значения или не упрётся в проблему переполнения.
Если вы когда-то слышали о правиле 14КБ, то должны понимать, что оптимизация производительности загрузки должна учитывать ограничения этого начального запроса. Медленный старт TCP позволяет плавно ускорять передачу данных так, чтобы избежать проблемы переполнения, когда много данных ожидают отправки, но не отправляются из-за ограничений ширины канала.
Контроль переполнения
Любое соединение имеет ограничения, связанные с аппаратной и сетевой системами. Если сервер отправит слишком много пакетов за раз — они могут быть отброшены. Для того, чтобы избежать таких проблем, браузер должен реагировать на получение пакетов и подтверждать, что он получает их. Такой ответ-подтверждение называется Aknowledgements (ACK). Если из-за ограничений соединения браузер не получит данных, то он не пошлёт подтверждений ACK. В этом случае, сервер зарегистрирует, что какие-то пакеты не дошли и пошлёт их заново, что приведёт к лишней работе сервера и дополнительной нагрузке сети.
Как только браузер получает первый кусочек данных, он сразу начинает обрабатывать получаемую информацию. Эта обработка называется «Парсинг» (Parsing). Во время парсинга получаемые данные преобразуются в DOM и CSSOM (en-US), которые напрямую участвуют в отрисовке.
DOM (Объектная модель документа) — это внутреннее представление разметки HTML. Браузер предоставляет доступ к манипуляции объектами этой модели через разные JavaScript API.
Даже если ответ на запрос больше 14КБ, браузер всё равно начинает парсинг данных и пытается отрисовать страницу с теми данными, которые уже доступны. Именно поэтому при оптимизации производительности очень важно включать в инициирующий 14КБ ответ все необходимые для рендера данные — так браузер сможет быстрее начать формирование страницы. Однако, прежде чем что-либо появится на экране, HTML, CSS и JavaScript должны быть обработаны.
Построение дерева объектной модели документа
Мы уже рассказывали о пяти шагах в критическом пути рендеринга.
Первый шаг — это обработка разметки HTML и построение дерева DOM. Обработка HTML включает в себя токенизацию и построение дерева. HTML-токены состоят из тегов старта и финиша, а также атрибутов. Если документ сформирован правильно, его обработка прямолинейна и быстра. Парсер (обработчик) преобразует входящие токены в документ и строит дерево документа.
Объектная модель документа (DOM) описывает содержимое документа. Элемент <html> — это первый тег и корневой элемент дерева документа. Дерево отражает связи и иерархию между разными тегами. Теги, вложенные в другие теги являются детьми. Чем больше существует узлов в дереве, тем сложнее это дерево построить.
Дерево отражает связи и иерархию между разными тегами. Теги, вложенные в другие теги являются детьми. Чем больше существует узлов в дереве, тем сложнее это дерево построить.
Когда парсер находит неблокирующие ресурсы (например, изображения), браузер отправляет запрос на загрузку ресурсов, но сам продолжает обработку. Обработка может продолжаться когда обнаружена ссылка на CSS файл, но если обнаружен <script>, особенно если он без параметров async или defer — такой скрипт считается блокирующим и приостанавливает обработку HTML до завершения загрузки скрипта. Несмотря на то, что сканер предзагрузки (о нём ниже) браузера может находить и запрашивать такие скрипты заранее, сложные и объёмные скрипты всё ещё могут стать причиной заметных задержек загрузки страницы.
Сканер предзагрузки
Построение дерева DOM занимает весь поток процесса. Так как это явно узкое место в производительности, был создан особый сканер предзагрузки. Он обрабатывает доступное содержимое документа и запрашивает высокоприоритетные ресурсы (CSS, JavaScript и шрифты). Благодаря этому сканеру нам не нужно ждать, пока парсер дойдёт до конкретного места, где вызывается ресурс. Он запрашивает и получает эти данные заранее, в фоновом режиме, так что когда основной поток HTML-парсера доходит до запроса ресурса, высока вероятность, что ресурс уже запрошен или находится в процессе загрузки. Оптимизации, которые даёт этот сканер, уменьшают время блокирования рендера.
Он обрабатывает доступное содержимое документа и запрашивает высокоприоритетные ресурсы (CSS, JavaScript и шрифты). Благодаря этому сканеру нам не нужно ждать, пока парсер дойдёт до конкретного места, где вызывается ресурс. Он запрашивает и получает эти данные заранее, в фоновом режиме, так что когда основной поток HTML-парсера доходит до запроса ресурса, высока вероятность, что ресурс уже запрошен или находится в процессе загрузки. Оптимизации, которые даёт этот сканер, уменьшают время блокирования рендера.
<link rel="stylesheet" src="styles.css"/> <script src="myscript.js" async></script> <img src="myimage.jpg" alt="image description"/> <script src="anotherscript.js" async></script>
В примере выше основной поток обрабатывает HTML и CSS. В то же время, сканер предзагрузки находит скрипты и изображение и начинает их загрузку. Чтобы сделать скрипт неблокирующим, добавьте атрибут async или, в случае, если порядок загрузки скриптов важен, атрибут defer.
Примечание: Ожидание получения CSS не блокирует парсинг HTML, но он блокирует JavaScript, потому что JavaScript часто используется для выборки узлов документа по CSS-селекторам.
Построение модели стилей CSSOM
Второй шаг при прохождении критического пути рендеринга — это обработка CSS и построение CSSOM дерева. CSSOM (объектная модель CSS) похожа на DOM. И DOM, и CSSOM — это деревья. Они являются независимыми структурами данных. Браузер преобразует CSS файлы в карту стилей, которую он может понять и с которой может работать. Браузер считывает каждый набор правил в CSS, создаёт дерево узлов с родителями, детьми и соседями, основываясь на CSS селекторах.
Как и в HTML, браузер должен преобразовать полученные правила CSS во что-то, с чем он может работать. Таким образом, весь этот процесс — это повторение формирования DOM, только для CSS.
CSSOM дерево включает в себя стили пользовательского агента — это стили, которые браузер вставляет по умолчанию. Браузер начинает построение модели с наиболее общих правил для каждого узла, постепенно применяя более специфичные правила. Другими словами, он применяет правила каскадно. Отсюда и название CSS — Cascading Style Sheets.
Браузер начинает построение модели с наиболее общих правил для каждого узла, постепенно применяя более специфичные правила. Другими словами, он применяет правила каскадно. Отсюда и название CSS — Cascading Style Sheets.
Построение CSSOM происходит очень быстро и не отображается отдельным цветом в средствах разработчика. Оно настолько быстрое, что чаще всего включается в показатель «Повторное вычисление стилей (Recalculate Styles)» в средствах разработчика. Этот показатель показывает общее время обработки стилей — обработку CSS, построение CSSOM и рекурсивное вычисление стилей. С точки зрения оптимизации производительности здесь нечего делать, так как построение CSSOM, в целом, занимает даже меньше времени, чем DNS запрос.
Остальные процессы
Компиляция JavaScript
Как CSS обработан и CSSOM создан, другие ресурсы, например, JavaScript-файлы, продолжают загружаться (спасибо сканеру предзагрузки). JavaScript по окончании загрузки должен быть интерпретирован, скомпилирован, обработан и исполнен. Скрипты преобразовываются в абстрактное синтаксическое дерево (AST). Некоторые браузеры берут Abstract Syntax Tree и передают его в интерпретатор, который преобразует дерево в байт-код. Байт-код исполняется в основном потоке. Весь этот процесс называется компиляцией.
Скрипты преобразовываются в абстрактное синтаксическое дерево (AST). Некоторые браузеры берут Abstract Syntax Tree и передают его в интерпретатор, который преобразует дерево в байт-код. Байт-код исполняется в основном потоке. Весь этот процесс называется компиляцией.
Построение дерева доступности
Браузер также строит дерево доступности, которое используется устройствами-помощниками для понимания и интерпретирования контента. Объектная модель доступности (accessibility object model, AOM) — это семантическая версия DOM. Браузер обновляет AOM в тот же момент, когда обновляется DOM. В то же время, дерево доступности не может быть изменено вспомогательными технологиями.
Пока модель AOM не построена, содержимое страницы недоступно для голосовых помощников и считывателей экрана (en-US).
Этапы рендеринга включают в себя стилизацию, компоновку (layout), отрисовку (paint) и, в некоторых случаях, композицию (composition). CSSOM и DOM деревья, созданные на предыдущем этапе комбинируются в дерево рендера, которое затем используется для расчёта положения каждого видимого элемента. После этого элементы будут отрисованы на экране. В некоторых случаях содержимое может быть вынесено на отдельные слои и совмещено (composition) — такой подход увеличивает производительность, позволяя отрисовывать содержимое экрана на графическом процессоре вместо ЦПУ. Это освобождает основной поток.
После этого элементы будут отрисованы на экране. В некоторых случаях содержимое может быть вынесено на отдельные слои и совмещено (composition) — такой подход увеличивает производительность, позволяя отрисовывать содержимое экрана на графическом процессоре вместо ЦПУ. Это освобождает основной поток.
Стилизация
Третий шаг в критическом пути рендеринга — это комбинирование DOM и CSSOM в дерево рендеринга. Конструирование этого дерева начинается с прохода всего DOM-дерева от корня, с выявлением каждого видимого узла.
Элементы, которые не должны быть показаны, например, <head>, а так же их дети или любые элементы с display:none, такие как script { display: none; }, не будут включены в дерево рендера, так как они не должны быть отрисованы. Узлы с правилом visibility: hidden включены в дерево рендера, так как они всё равно занимают своё место. Так как мы не указали никаких специальных правил для перезаписи стилей агента по умолчанию, узел script в примере выше также не будет включён в дерево рендера.
Каждый видимый узел имеет свои правила из CSSOM. Дерево рендера содержит все видимые узлы с их содержимым и вычисленными стилями. Стили определяются путём применения всех подходящих правил с использованием CSS каскада.
Компоновка (Layout)
Четвёртый шаг на критическом пути рендеринга — это запуск компоновки (layout) элементов дерева рендера. На этом шаге вычисляется геометрия каждого узла, то есть ширина, высота, положение элементов. Reflow (перекомпоновка) — это любой последующий процесс определения размеров и позиции для любой из частей целого документа.
Как только дерево рендера построено — начинается layout. Дерево несёт в себе информацию о том, какие узлы должны быть отрисованы (даже если они невидимы), и какие стили должны быть применены, но в дереве нет никакой информации о размерах и позиции элементов. Чтобы определить эти значения, браузер начинает обход дерева.
На веб-странице практически все элементы прямоугольны (box). Разные устройства и настройки подразумевают бесчисленное количество разных размеров видимой области. На начальной фазе браузер, учитывая размер видимой области, определяет какие размеры разных элементов должны быть на экране. Использует размер видимой области как базис, процесс начинает вычисление с элемента
На начальной фазе браузер, учитывая размер видимой области, определяет какие размеры разных элементов должны быть на экране. Использует размер видимой области как базис, процесс начинает вычисление с элемента body, затем переходит к его потомкам, вычисляет размеры каждого элемента и резервирует место для тех элементов, размеры которых он ещё не знает (например, изображения).
Момент, когда позиция и размеры узлов вычислены, называется layout. Последующие вычисления позиций и размеров называются reflow. В нашем примере предполагаемый начальный layout происходит перед тем, как изображение получено. Так как мы не задавали размер изображения, в момент получения изображения произойдёт reflow.
Отрисовка (Paint)
Последний шаг критического пути рендеринга — это отрисовка каждого отдельного узла на экране. Момент, когда это происходит впервые, называется first meaningful paint (первая значащая отрисовка). Во время фазы отрисовки или растеризации, браузер конвертирует каждый контейнер box в настоящие пиксели на экране (напомним, что данные контейнеров формируются на этапе layout).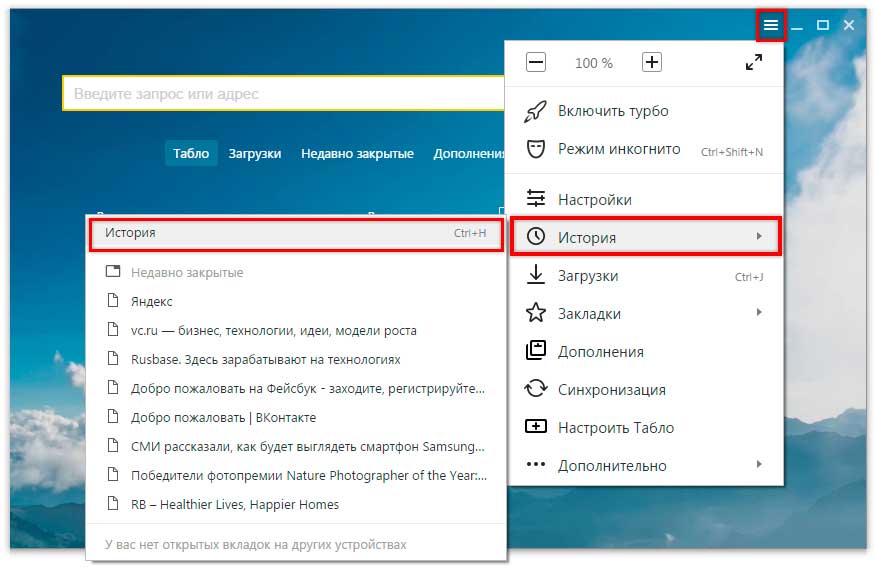 Отрисовка подразумевает рисование каждой визуальной частицы элемента на экране (текст, цвета, границы, тени) и рисование заменяемых элементов (картинки, кнопки). Браузер должен выполнять это быстро.
Отрисовка подразумевает рисование каждой визуальной частицы элемента на экране (текст, цвета, границы, тени) и рисование заменяемых элементов (картинки, кнопки). Браузер должен выполнять это быстро.
Чтобы обеспечить плавную прокрутку и анимацию, отрисовка каждого элемента занимает весь основной поток. Сюда включается вычисление стилей, повторное вычисление стилей и отрисовка. Все эти этапы должны выполняться не дольше 16.67 мс. (1000мс. / 60 кадров в секунду). При разрешении 2048х1536 экран iPad содержит 3.145.000 пикселей, которые должны быть отрисованы. Это много! Для того, чтобы сделать инициирующую и повторную отрисовки быстрее, можно разбить весь процесс на несколько слоёв. Когда это случается — становится необходима композиция.
Отрисовка может разбить элементы в дереве рендера на слои. Для того, чтобы ускорить их рендер, браузер может перенести отрисовку разных слоёв на GPU (вместо основного потока CPU). Для переноса вычислений отрисовки на GPU вы можете использовать некоторые специальные HTML теги, например <video> и <canvas>; а также CSS-свойства opacity, transform и will-change. Узлы, созданные таким образом, будут отрисованы на их собственном слое, вместе с их потомками, если только потомки сами по себе не будут вынесены в отдельные слои.
Узлы, созданные таким образом, будут отрисованы на их собственном слое, вместе с их потомками, если только потомки сами по себе не будут вынесены в отдельные слои.
Слои улучшают производительность. Но, с точки зрения управления памяти, они неэффективны. Поэтому старайтесь не использовать их там, где в нет необходимости.
Композиция (Compositing)
Когда разделы документа отрисованы на разных слоях, а один слой находится над другим или перекрывает его, становится необходима композиция. Этот шаг позволяет браузеру гарантировать, что каждый слой отрисован на экране в правильном порядке, а содержимое отображается корректно.
При догрузке ранее запрошенных ресурсов (например, изображений) может потребоваться перерассчитать размеры и положение элементов относительно друг друга. Этот перерасчёт — reflow — запускает перерисовку (repaint) и перекомпозицию (re-composite). Если мы заранее определили размер изображения, перерасчёт не будет необходим и в этом случае только тот слой, который должен быть перерисован — будет перерисован. Но если мы не определили размер изображения заранее, то браузер, после получения ответа от сервера, будет вынужден отмотать процесс рендеринга обратно к шагу компоновки (layout) и начать процесс отрисовки ещё раз.
Но если мы не определили размер изображения заранее, то браузер, после получения ответа от сервера, будет вынужден отмотать процесс рендеринга обратно к шагу компоновки (layout) и начать процесс отрисовки ещё раз.
Можно было бы подумать, что как только основной поток завершает отрисовку страницы — «всё готово». Это не всегда так. Если среди загружаемых ресурсов есть JavaScript, загрузка которого была корректно отложена, а запуск которого происходит только после события onload, основной поток начинает обработку скриптов. Во время этой обработки браузер не может обрабатывать события прокрутки, нажатий и др.
Time to Interactive (TTI, время до интерактивности) — это показатель того, как много времени проходит между самым первым сетевым запросом и моментом, когда страница становится интерактивной. В хронологии этот этап следует сразу за First Contentful Paint. Интерактивностью называется показатель того, что страница отреагировала на действие пользователя за время в 50мс. Если процессор занят обработкой, компиляцией и выполнением JavaScript, то браузер не может отреагировать достаточно быстро, а значит страница считается не интерактивной.
Если процессор занят обработкой, компиляцией и выполнением JavaScript, то браузер не может отреагировать достаточно быстро, а значит страница считается не интерактивной.
В нашем примере, даже несмотря на то, что изображение загрузилось быстро, скрипт anotherscript.js, размер которого достигает 2МБ, загружается долго. В этом случае пользователь увидит страницу очень быстро, но не будет способен взаимодействовать с ней, пока скрипт не будет загружен, обработан и исполнен. Это плохая практика. Старайтесь избегать полной загрузки процесса.
В примере выше загрузка содержимого DOM заняла около 1.5 секунд. Все это время основной поток процесса был полностью загружен и не был способен обработать пользовательский ввод.
- Производительность Web
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
Наполнение страницы: как работают браузеры — Производительность в Интернете
Пользователи хотят работать в Интернете с контентом, который быстро загружается и с которым легко взаимодействовать. Поэтому разработчик должен стремиться к достижению этих двух целей.
Чтобы понять, как улучшить производительность и воспринимаемую производительность, нужно понять, как работает браузер.
Быстрые сайты обеспечивают лучший пользовательский опыт. Пользователи хотят и ожидают веб-интерфейса с контентом, который быстро загружается и с которым легко взаимодействовать.
Две основные проблемы с веб-производительностью — это проблемы, связанные с задержкой, и проблемы, связанные с тем фактом, что по большей части браузеры являются однопоточными.
Задержка — самая большая угроза нашей способности обеспечить быструю загрузку страницы. Цель разработчиков — сделать так, чтобы сайт загружался как можно быстрее — или, по крайней мере, отображалось как для сверхбыстрой загрузки — чтобы пользователь как можно быстрее получал запрошенную информацию. Сетевая задержка — это время, необходимое для передачи байтов по воздуху на компьютеры. Веб-производительность — это то, что мы должны сделать, чтобы страница загружалась как можно быстрее.
Сетевая задержка — это время, необходимое для передачи байтов по воздуху на компьютеры. Веб-производительность — это то, что мы должны сделать, чтобы страница загружалась как можно быстрее.
По большей части браузеры считаются однопоточными. То есть они выполняют задачу от начала до конца, прежде чем приступить к другой задаче. Для плавного взаимодействия цель разработчика — обеспечить эффективное взаимодействие с сайтом, от плавной прокрутки до отклика на прикосновение. Время рендеринга является ключевым моментом, так как главный поток может завершить всю работу, которую мы на него возлагаем, и при этом всегда быть доступным для обработки взаимодействий с пользователем. Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия.
Навигация — это первый шаг в загрузке веб-страницы. Это происходит всякий раз, когда пользователь запрашивает страницу, вводя URL-адрес в адресную строку, щелкая ссылку, отправляя форму, а также выполняя другие действия.
Это происходит всякий раз, когда пользователь запрашивает страницу, вводя URL-адрес в адресную строку, щелкая ссылку, отправляя форму, а также выполняя другие действия.
Одна из целей веб-производительности — свести к минимуму время, необходимое для завершения навигации. В идеальных условиях это обычно не занимает слишком много времени, но задержка и пропускная способность являются врагами, которые могут вызывать задержки.
DNS-поиск
Первым шагом при переходе на веб-страницу является определение местоположения ресурсов этой страницы. Если вы перейдете к https://example.com , HTML-страница расположена на сервере с IP-адресом 93.184.216.34 . Если вы никогда не посещали этот сайт, необходимо выполнить поиск DNS.
Ваш браузер запрашивает поиск DNS, который в конечном итоге обрабатывается сервером имен, который, в свою очередь, отвечает IP-адресом. После этого первоначального запроса IP-адрес, скорее всего, будет кэшироваться на некоторое время, что ускоряет последующие запросы за счет извлечения IP-адреса из кэша вместо повторного обращения к серверу имен.
DNS-запросы обычно нужно выполнять только один раз для каждого имени хоста для загрузки страницы. Однако поиск DNS должен выполняться для каждого уникального имени хоста, на которое ссылается запрошенная страница. Если ваши шрифты, изображения, сценарии, реклама и метрики имеют разные имена хостов, для каждого из них необходимо выполнить поиск в DNS.
Это может отрицательно сказаться на производительности, особенно в мобильных сетях. Когда пользователь находится в мобильной сети, каждый поиск DNS должен идти с телефона на вышку сотовой связи, чтобы достичь авторитетного DNS-сервера. Расстояние между телефоном, вышкой сотовой связи и сервером имен может увеличить задержку.
TCP Handshake
Когда IP-адрес известен, браузер устанавливает соединение с сервером через трехстороннее TCP-рукопожатие. Этот механизм разработан таким образом, что два объекта, пытающиеся установить связь, — в данном случае браузер и веб-сервер — могут согласовать параметры сетевого TCP-сокета перед передачей данных, часто по протоколу HTTPS.
Метод трехэтапного квитирования TCP часто называют «SYN-SYN-ACK» или, точнее, SYN, SYN-ACK, ACK, поскольку протокол TCP передает три сообщения для согласования и запуска сеанса TCP между двумя компьютерами. . Да, это означает еще три сообщения взад и вперед между каждым сервером, и запрос еще не сделан.
Согласование TLS
Для безопасных соединений, установленных через HTTPS, требуется еще одно «рукопожатие». Это рукопожатие или, скорее, согласование TLS определяет, какой шифр будет использоваться для шифрования связи, проверяет сервер и устанавливает наличие безопасного соединения перед началом фактической передачи данных. Это требует еще трех обращений к серверу, прежде чем запрос контента будет фактически отправлен.
Хотя обеспечение безопасности соединения увеличивает время загрузки страницы, безопасное соединение стоит затрат на задержку, поскольку данные, передаваемые между браузером и веб-сервером, не могут быть расшифрованы третьей стороной.
После 8 обходов браузер, наконец, может выполнить запрос.
Как только мы установили соединение с веб-сервером, браузер отправляет начальный HTTP-запрос GET от имени пользователя, который для веб-сайтов чаще всего представляет собой HTML-файл. Как только сервер получит запрос, он ответит соответствующими заголовками ответа и содержимым HTML.
<голова>
<метакодировка="UTF-8" />
Моя простая страница
<ссылка rel="stylesheet" href="styles.css" />
<тело>
Моя страница
Абзац с ссылкой
<дел>


 Первый фрагмент контента обычно составляет 14 КБ данных.
Первый фрагмент контента обычно составляет 14 КБ данных. Медленный запуск TCP постепенно увеличивает скорость передачи, соответствующую возможностям сети, чтобы избежать перегрузки.
Медленный запуск TCP постепенно увеличивает скорость передачи, соответствующую возможностям сети, чтобы избежать перегрузки. DOM также открыт, и им можно манипулировать с помощью различных API-интерфейсов в JavaScript.
DOM также открыт, и им можно манипулировать с помощью различных API-интерфейсов в JavaScript. Синтаксический анализатор анализирует токенизированный ввод в документ, создавая дерево документа.
Синтаксический анализатор анализирует токенизированный ввод в документ, создавая дерево документа.