Содержание
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()
То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
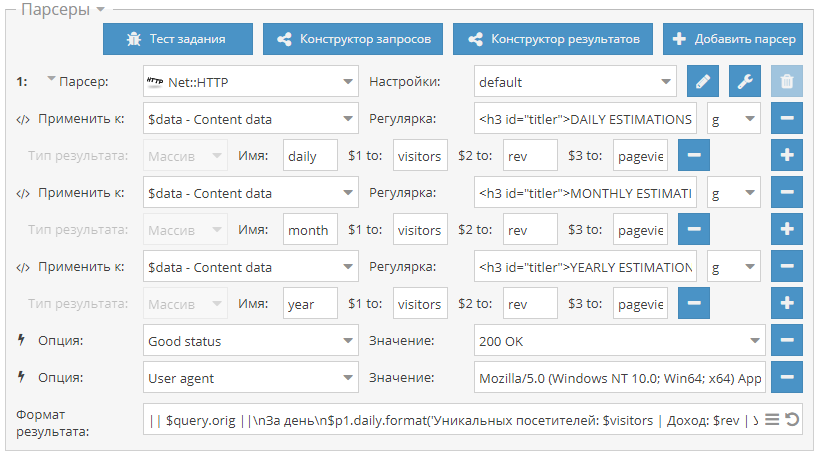
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/span
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.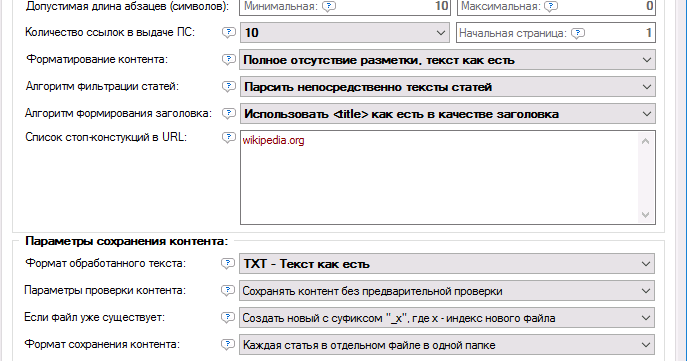
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction.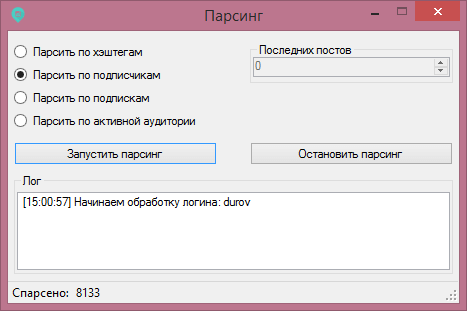 И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.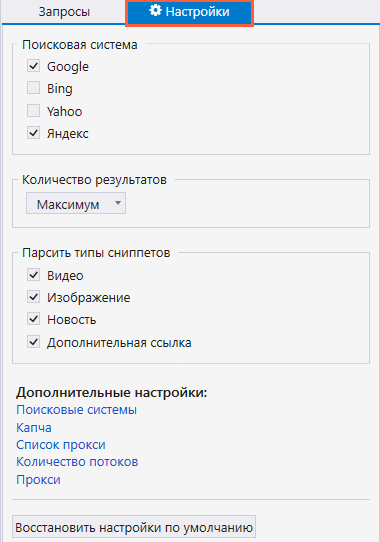
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т. д.
д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@src
У нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.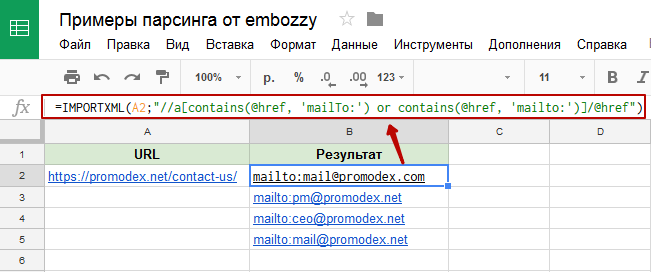
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]
Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]
Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.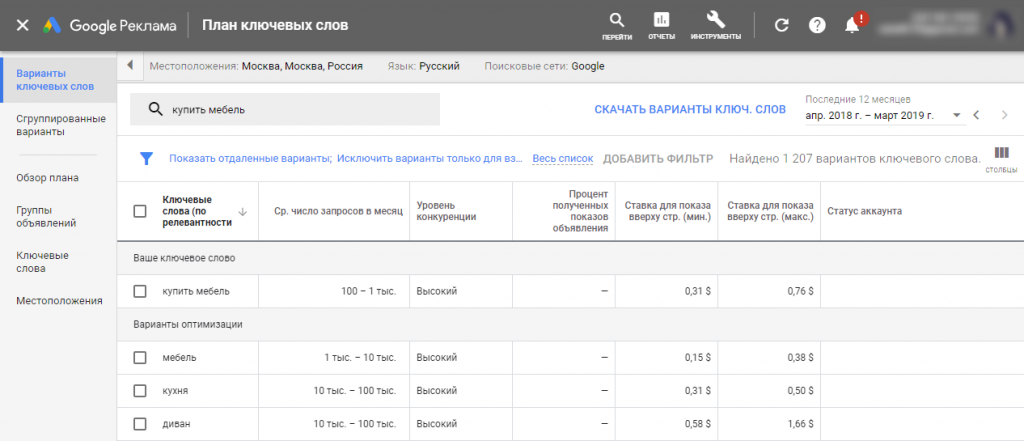
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]
Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]
Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.


Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
 Такое ограничение можно обойти, но это долго и дорого.
Такое ограничение можно обойти, но это долго и дорого.Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Парсинг данных с сайтов: что это и зачем он нужен
Парсинг обычно применяют, когда нужно быстро собрать большой объем данных. Его выполняют с помощью специальных сервисов — парсеров. В этой статье мы разберем, с какой целью можно использовать парсинг, что он позволяет узнать о конкурентах и законен ли он. Также мы рассмотрим, как пошагово спарсить данные с помощью одного из инструментов.
Время чтения 17 минут
Вы можете перейти сразу к интересующему разделу:
- Что такое парсинг
- Способы применения парсинга
- Что могут узнать конкуренты с помощью парсинга
- Законно ли парсить сайты
- Этапы парсинга
- Как парсить данные
- Как защитить свой сайт от парсинга
- Выводы
Что такое парсинг
Парсинг — это процесс автоматического сбора данных и их структурирования.
Специальные программы или сервисы-парсеры «обходят» сайт и собирают данные, которые соответствуют заданному условию.
Простой пример: допустим, нужно собрать контакты потенциальных партнеров из определенной ниши. Вы можете это сделать вручную. Надо будет заходить на каждый сайт, искать раздел «Контакты», копировать в отдельную таблицу телефон и т. д. Так на каждую площадку у вас уйдет по пять-семь минут. Но этот процесс можно автоматизировать. Задаете в программе для парсинга условия выборки и через какое-то время получаете готовую таблицу со списком сайтов и телефонов.
Плюсы парсинга очевидны — если сравнивать его с ручным сбором и сортировкой данных:
- вы получаете данные очень быстро;
- можно задавать десятки параметров для составления выборки;
- в отчете не будет ошибок;
- парсинг можно настроить с определенной периодичностью — например, собирать данные каждый понедельник;
- многие парсеры не только собирают данные, но и советуют, как исправить ошибки на сайте.

В сети достаточно много программ для парсинга. Они могут находиться в «облаке» или «коробке»:
- облачная версия — это SaaS, вам нужно будет зарегистрироваться и работать с сервисом прямо в браузере;
- коробочная версия — решение, которое нужно установить на ваш компьютер, и работать с ним в окне программы.
В обоих случаях вы платите за доступ к парсеру в течение какого-то времени. Например, месяца, года или нескольких лет.
Способы применения парсинга
Область применения парсинга можно свести к двум целям:
- анализ конкурентов, чтобы лучше понимать, как они работают, и заимствовать у них какие-то подходы;
- анализ собственной площадки для устранения ошибок, быстрого внедрения изменений и т. д.
Пример того, что может предложить один из парсеров для поиска, устранения ошибок и прокачки SEO
Мы регулярно используем парсер для блога Ringostat. Например, когда нужно найти изображения, к которым по какой-то причине не прописан атрибут Alt. Поисковики считают это ошибкой и могут понизить в выдаче тот сайт, на котором много таких иллюстраций. Даже страшно представить, сколько времени потребовалось бы на ручной поиск таких картинок. А благодаря парсеру мы получаем список со ссылками за несколько минут.
Поисковики считают это ошибкой и могут понизить в выдаче тот сайт, на котором много таких иллюстраций. Даже страшно представить, сколько времени потребовалось бы на ручной поиск таких картинок. А благодаря парсеру мы получаем список со ссылками за несколько минут.
Теперь давайте рассмотрим для каких целей еще можно использовать парсинг.
- Исследование рынка. Парсинг позволяет быстро оценить, какие товары и цены у конкурентов.
- Анализ динамики изменений. Парсинг можно проводить регулярно, чтобы оценивать, как менялись какие-то показатели. Например, росли или падали цены, изменялось количество онлайн-объявлений или сообщений на форуме.
- Устранение недочетов на собственном ресурсе. Выявление ошибок в мета-тегах, битых ссылок, проблем с редиректами, дублирующихся элементов и т. д.
- Сбор ссылок, ведущих на вашу площадку. Это поможет оценить работу подрядчика по линкбилдингу. Как проверять внешние ссылки и какими инструментами это делать, подробно описано в статье. Пример такого отчета:
- Наполнение каталога интернет-магазина. Обычно у таких сайтов огромное количество позиций и уходит много времени, чтобы составить описание для всех товаров. Чтобы упростить этот процесс, часто парсят зарубежные магазины и просто переводят информацию о товарах.
- Составление клиентской базы. В этом случае парсят контактные данные, например, пользователей соцсетей, участников форумов и т. д. Но тут стоит помнить, что сбор информации, которой нет в открытом доступе, незаконен.
- Сбор отзывов и комментариев на форумах, в соцсетях.
- Создание контента, который строится на выборке данных. Например, результаты спортивных состязаний, инфографики по изменению цен, погоды и т. д.
 Пример такого отчета:
Пример такого отчета: Кстати, недобросовестные люди могут использовать парсеры для DDOS-атак. Если одновременно начать парсить сотни страниц сайта, то площадку можно «положить» на какое-то время. Это, разумеется, незаконно — об этом подробнее ниже От подобных атак можно защититься, если на сервере установлена защита.
Что могут узнать конкуренты с помощью парсинга
В принципе, любую информацию, которая размещена на вашем сайте. Чаще всего ищут:
- цены;
- контакты компании;
- описание товаров, их характеристик и в целом контент;
- фото и видео;
- информацию о скидках;
- отзывы.
Проводить такую «разведку» могут не только конкуренты. Например, журналист может провести исследование, правда ли интернет-магазины предоставляют настоящие скидки на Черную пятницу. Или искусственно завышают цены незадолго до нее и реальную цену выдают за скидку. С этой целью он может заранее спарсить цены десятка интернет-магазинов и сравнить с ценами на Черную пятницу.
Или другой пример — Игорь Горбенко с помощью парсинга проанализировал, насколько продавцы цветов поднимают цены к Дню святого Валентина:
Кстати, эта статья вызвала большой резонанс. Поэтому, если вы блогер или новостное издание, парсинг однозначно стоит взять на вооружение.
Законно ли парсить сайты
Если кратко, то законно — если вы парсите информацию, которая есть в открытом доступе. Это логично, ведь так любой человек и без парсера может собрать интересующие данные. Что преследуется законом:
Это логично, ведь так любой человек и без парсера может собрать интересующие данные. Что преследуется законом:
- парсинг с целью DDOS-атаки;
- сбор личных данных пользователей, которые находятся не на виду — например, в личном кабинете, указывались при регистрации и т. д.;
- парсинг для воровства контента — например, перепост чужих статей под своим именем, использование авторских фото не из бесплатных стоков;
- сбор информации, которая составляет государственную или коммерческую тайну.
Рассмотрим это подробнее с точки зрения законодательства Украины.
Согласно ЗУ «Об информации», информация по режиму доступа делится на общедоступную и информацию с ограниченным доступом. В свою очередь информация с ограниченным доступом делится на конфиденциальную, гостайну и служебную. Определения каждого вида содержатся в ЗУ «О доступе к публичной информации.
В большей степени любой спор касательно незаконного парсинга и/или распространения информации касается именно конфиденциальных данных.
- Информация о физлице, которая может его идентифицировать, априори является конфиденциальной и может быть использована только по согласию. Поэтому, чтобы парсинг был законным, парсить нужно либо деперсонифицированные данные, либо получать согласие распорядителя информации — владельца сайта, на котором зарегистрирован пользователь.
- Если речь идет об информации, не являющейся персональной, она может считаться конфиденциальной, только если ее владелец определил ее как таковую. Так, чаще всего на сайтах размещается либо политика конфиденциальности, либо правила пользования сайтом. В этом документе/на этой странице указаны права и обязанности посетителей/пользователей, которые нужно соблюдать. Поэтому перед парсингом стоить проверить, не запрещен ли сбор информации и использование данных сайта.
Также важным является возможное нарушение авторских установленных ЗУ «Об авторских и смежных правах» и ГКУ. Перед парсингом нужно понимать, что любой тип контента защищен авторским правом с момента его создания.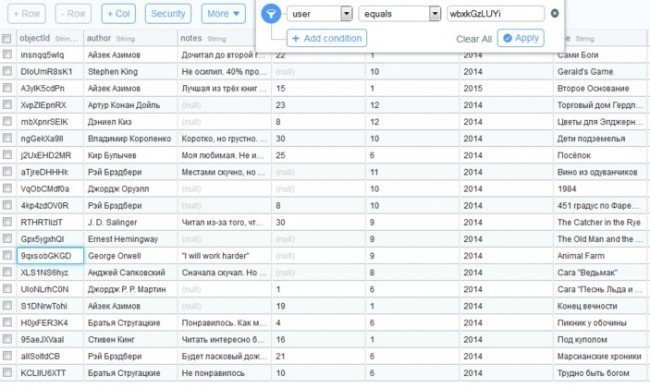 И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
И только автор определяет как (платно/бесплатно), где (статья/сайт/реклама) и сколько (на протяжении срока действия лицензии/бессрочно) можно использовать его творение.
Даже при условии правомерности парсинга, его осуществление не должно подрывать нормальную работу сайта, который парсят. Если из-за парсинга информации произойдет сбой и утечка или подделка данных, то подобные действия могут расцениваться как несанкционированное вмешательство в работу сайта, что является нарушением согласно УК Украины.
Есть еще один нюанс. Представим, что одна компания долго разрабатывала продукт, вкладывала деньги, чтобы собрать базу пользователей или покупателей, а другая спарсила все и за несколько недель создала практически аналогичный сервис или продукт. Подобные действия при наличии весомой доказательной базы могут расцениваться как нарушение условий конкуренции согласно ЗУ «О защите от недобросовестной конкуренции».
Этапы парсинга
Если не погружаться в технические подробности, то парсинг строится из таких этапов:
- пользователь задает в парсере условия, которым должна соответствовать выборка — например, все цены на конкретном сайте;
- программа проходится по сайту или нескольким и собирает релевантную информацию;
- данные сортируются;
- пользователь получает отчет — если проводилась проверка на ошибки, то критичные выделяются контрастным цветом;
- отчет можно выгрузить в нужном формате — обычно парсеры поддерживают несколько.

Пример отчета Netpeak Spider, где критичные ошибки выделяются красным цветом
Источник
Как парсить данные
Теперь давайте более подробно рассмотрим, как парсить данные. Разберем его в разрезе довольно частой задачи для менеджера — собрать базу для «холодного» обзвона. В качестве примера возьмем парсер Netpeak Checker, с которым работаем и сами.
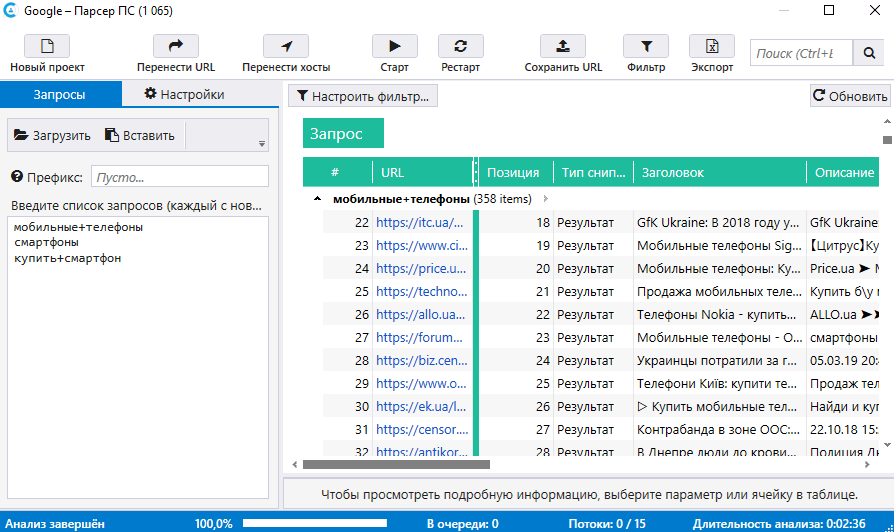
Допустим, наша компания продает оборудование для салонов красоты. И сотруднику нужно собрать базу контактов таких компаний, чтобы позвонить и предложить им наш товар. Обычно на старте готового списка площадок у менеджера нет. Поэтому для поиска можно использовать встроенный в программу инструмент «Парсер поисковых систем».
Вводим в нем нужные запросы — «салон красоты», «парикмахерская», «бьюти-процедуры».
На вкладке «Настройки» выбираем поисковую систему и количество результатов — например, топ-10 или все результаты выдачи. В дополнительных настройках указываем язык выдачи и параметры геолокации, чтобы в результаты попадали салоны красоты только из нужного нам региона. Сохраняем настройки и нажимаем «Старт», чтобы начать парсинг.
Сохраняем настройки и нажимаем «Старт», чтобы начать парсинг.
Чтобы провести парсинг номеров телефонов с главных страниц найденных сайтов, нажимаем на кнопку «Перенести хосты». После этого ссылки отобразятся в основной таблице программы.
Теперь, когда у нас есть полный список салонов, на боковой панели в разделе параметров «On-Page» отмечаем пункт «Телефонные номера» и нажимаем «Старт». Все найденные телефоны с сайтов и их число будут внесены в соответствующих колонках основной таблицы результатов.
Если бы у нас заранее был собран перечень необходимых адресов, мы могли бы их просто загрузить в программу и точно так же собрать телефоны.
Сохраняем данные в формате CSV, нажав кнопку «Экспорт».
Вот и все — мы получили список салонов и их телефонов.
Кстати, сэкономить время можно не только за счет парсинга. Вы в любом случае тратите где-то минуту, чтобы набрать номер на телефоне. Если в вашем списке хотя бы 50 компаний, на это в сумме уйдет почти час. Но есть способ тратить на набор номера одну секунду.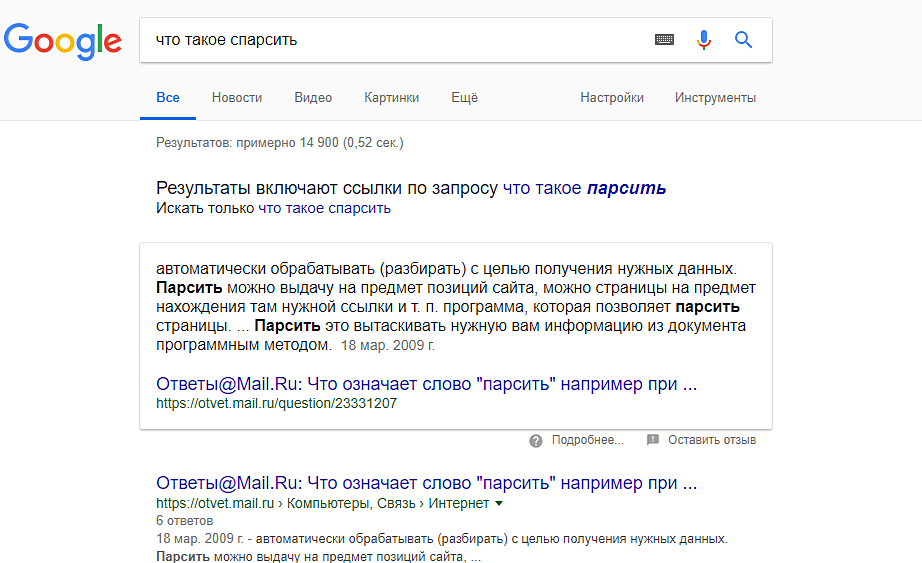 Это Ringostat Smart Phone — умный телефон, встроенный прямо в браузер Chrome. Он позволяет звонить, просто нажав на номер, расположенный на любом сайте, в карточке CRM или просто в таблице. Как в нашем примере.
Это Ringostat Smart Phone — умный телефон, встроенный прямо в браузер Chrome. Он позволяет звонить, просто нажав на номер, расположенный на любом сайте, в карточке CRM или просто в таблице. Как в нашем примере.
Подключите Ringostat, установите расширение и сможете обзвонить базу за минимальное время. При желании ее можно сразу перенести в CRM и звонить уже оттуда с помощью Ringostat Smart Phone. Тут видно, что звонок происходит мгновенно:
Этот процесс описан в статье «Лайфхак для менеджера: как подготовить базу за минимальное время».
Как защитить свой сайт от парсинга
Как мы упоминали выше, парсинг не всегда используют в нормальных целях. Если вы боитесь атаки со стороны конкурентов, площадку можно защитить. Существует несколько способов, как это сделать.
- Ограничьте число действий, которые можно совершить на вашей площадке за определенное время. Например, разрешите только три запроса в течение минуты с одного IP-адреса.
- Отслеживайте подозрительную активность. Если заметили сильно много запросов с одного адреса, запретите ему доступ. Или показывайте reCAPTCHA, чтобы пользователь подтвердил, что он человек, а не бот или парсер.
- Создайте учетную запись, чтобы действия на сайте мог совершать зарегистрированный посетитель.
- Идентифицируйте всех, кто заходит на площадку. Например, по скорости заполнения формы или месту нажатия на кнопку. Есть скрипты, которые позволят собирать информацию о местонахождении пользователя, разрешении экрана.
- Скройте информацию о структуре сайта. Пусть доступ к ней будет только у администратора.
- Обращайте внимание на похожие или идентичные запросы, одновременно поступающие с разных IP-адресов. Парсинг может быть распределенным. Например, через прокси-сервера.
 Если заметили сильно много запросов с одного адреса, запретите ему доступ. Или показывайте reCAPTCHA, чтобы пользователь подтвердил, что он человек, а не бот или парсер.
Если заметили сильно много запросов с одного адреса, запретите ему доступ. Или показывайте reCAPTCHA, чтобы пользователь подтвердил, что он человек, а не бот или парсер.В любом случае, помните, что всегда есть риск заблокировать реального пользователя, а не программу. Поэтому тут вам решать, что важнее — безопасность сайта или риск потери потенциального клиента.
Выводы
- Парсинг — это сбор и сортировка данных с определенными параметрами. У этого инструмента масса преимуществ: скорость, отсутствие ошибок в выборке, возможность проводить парсинг регулярно. Плюс, многие парсеры не просто собирают данные, но и советуют, как исправить критические ошибки на вашем сайте.
- Парсинг используется для анализа конкурентов, исследования рынка, поиска и устранения ошибок на собственной площадке, создания контента. Интернет-магазины используют его, чтобы переводить описания товаров с иностранных площадок.
- Парсинг вполне законен, если вы собираете информацию, которая есть в открытом доступе. Нельзя проводить его, чтобы «положить» ресурс конкурента, украсть чужой контент или получить данные, не предназначенные для общего доступа.
- Если боитесь атаки на свой сайт, парсинг можно выявить и запретить. Способов существует несколько, но многие парсеры хвастаются в сети, что умеют их обходить. Плюс, вы всегда рискуете заблокировать «живого» человека
 У этого инструмента масса преимуществ: скорость, отсутствие ошибок в выборке, возможность проводить парсинг регулярно. Плюс, многие парсеры не просто собирают данные, но и советуют, как исправить критические ошибки на вашем сайте.
У этого инструмента масса преимуществ: скорость, отсутствие ошибок в выборке, возможность проводить парсинг регулярно. Плюс, многие парсеры не просто собирают данные, но и советуют, как исправить критические ошибки на вашем сайте.Grammarpedia — Как анализировать
Проверь себя:
Синтаксический анализ
Синтаксический анализ относится к деятельности по анализу предложения на составляющие его категории и функции. Разбор — это навык: то, чему вы можете научиться, а не то, о чем вы просто знаете. На этой странице описана процедура разбора английских предложений.
Разбор — это навык: то, чему вы можете научиться, а не то, о чем вы просто знаете. На этой странице описана процедура разбора английских предложений.
Содержимое1. Найдите глаголы 2. Рассмотрим время пункта 3. Определите неконечные пункты 4. Найти основные составляющие Связанные страницыВведение |
Хотя мы упоминаем ряд стратегий, которые помогут вам анализировать определенные типы конструкций на этом сайте, мы суммируем здесь основную процедуру. Если вы раньше не изучали грамматику, вы можете обнаружить, что будет полезнее вернуться на эту страницу после того, как вы прочтете остальную часть этого сайта и ознакомитесь с категориями и функциями, упомянутыми здесь.
[Вернуться к началу]
Поиск глаголов
Первый шаг в разборе предложения — поиск глаголов. Это полезно по ряду причин. Во-первых, глагол является ключом ко всему предложению, поэтому имеет смысл сначала разобраться с ним. Кроме того, предложения, содержащие несколько предложений, легче всего определить, найдя все глаголы. При определении глаголов помните, что одно предложение может содержать до трех вспомогательных глаголов в дополнение к лексическому глаголу. Здесь нас интересует лексический глагол.
Кроме того, предложения, содержащие несколько предложений, легче всего определить, найдя все глаголы. При определении глаголов помните, что одно предложение может содержать до трех вспомогательных глаголов в дополнение к лексическому глаголу. Здесь нас интересует лексический глагол.
Все лексических глаголов в следующем примере выделены жирным шрифтом.
Я планирую с по уйти пораньше с работы, когда я поеду в отпуск.
Для начала полезно обратить внимание на то, где в предложении появляются флективные суффиксы, связанные с лексическими глаголами (-s, -ed, -ing, -en). Но у этой стратегии есть ограничения, поскольку (i) некоторые глаголы не требуют суффиксов (см., например, leave и go в приведенном выше примере), и (ii) все эти суффиксы также появляются у существительных по разным причинам.
Также полезно рассмотреть любые вспомогательные глаголы (be, have, do и модальные глаголы can, may, will, should и т. д.). В этом примере мы видим форму am. Это форма настоящего времени первого лица единственного числа вспомогательного глагола be.
д.). В этом примере мы видим форму am. Это форма настоящего времени первого лица единственного числа вспомогательного глагола be.
[Вернуться к началу]
Учитывайте время предложения
Еще одна полезная вещь, которую нужно разобраться в отношении глаголов, — это время каждого предложения. В нашем примере есть только один глагол с временной пометкой. Он выделен жирным шрифтом:
I 900:37 утра планирую уйти пораньше с работы, когда уеду в отпуск.
[Вернуться к началу]
Идентификация неконечных предложений
Одна из причин, по которой полезно иметь возможность идентифицировать неконечные предложения, заключается в том, что неконечные предложения всегда подчинены. Поиск придаточных предложений значительно упрощает определение того, как связаны между собой различные элементы в предложении.
Неконечные предложения содержат неконечные глаголы. Это глаголы в формах инфинитива, причастия настоящего или причастия прошедшего времени , которые не поддерживаются вспомогательным .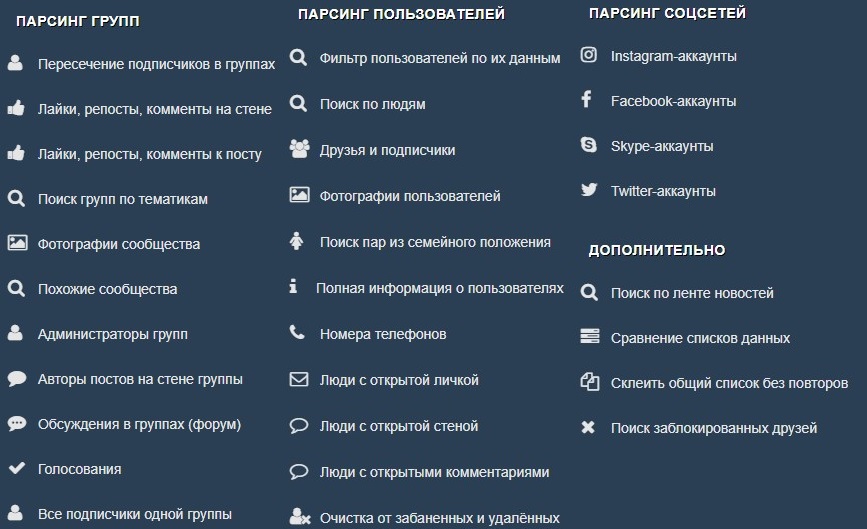 В нашем примере есть один инфинитивный глагол, оставить. Он выделен жирным шрифтом:
В нашем примере есть один инфинитивный глагол, оставить. Он выделен жирным шрифтом:
Я планирую уйти с работы пораньше , когда уеду в отпуск.
Обратите внимание, что есть также примеры придаточных предложений, содержащих конечные глаголы, поэтому одна только эта процедура не идентифицирует все придаточные предложения. В нашем примере глагол go является частью конечного придаточного предложения:
Я планирую уйти с работы пораньше когда я уезжаю в отпуск .
[Вернуться к началу]
Поиск основных составляющих
Следующим шагом в анализе предложения является определение основных составляющих и установление типа транзитивности. Мы установили, что основным глаголом в нашем примере является планирование (поскольку мы только что отметили, что два других лексических глагола входят в состав придаточных предложений). В чем заключается транзитивность планирования и какие основные составляющие оно принимает в нашем предложении?
Поскольку наше предложение довольно сложное, может помочь начать с более общего рассмотрения плана глагола. Основной пункт, содержащий план, приведен ниже:
Основной пункт, содержащий план, приведен ниже:
Сара запланировала отпуск.
Это предложение является переходным: оно содержит подлежащее (Сара) и дополнение (праздник). Та же самая закономерность встречается и в нашем предложении. Субъект (Я) и объект (уйти с работы пораньше) выделены жирным шрифтом:
Я планирую уйти пораньше с работы когда поеду в отпуск.
Осталось что-нибудь?
Если повезет, все, что у вас останется, это некоторая дополнительная наречная информация, относящаяся к времени, месту или способу предложения. В нашем примере в этой функции есть придаточное предложение:
Я планирую уйти пораньше с работы когда ухожу в отпуск .
[Вернуться к началу]
Как разбирать предложения — синонимы
ФРЕДДИ СИЛВЕР
VOCAB
Разбор предложений включает определение функции каждого слова. Раньше в школе регулярно преподавали формальную английскую грамматику, полагая, что это улучшит правильное использование языка учащимися. Однако исследования показали, что выполнение формальных грамматических упражнений оказало минимальное положительное влияние на письменные сочинения учащихся. Разбор предложений вышел из моды. Сегодня педагоги говорят, что классное время лучше проводить, участвуя в письме в контексте. Тем не менее, учащимся полезно уметь определять части речи и понимать их функции в предложениях. Знание того, как разбирать предложение, может быть полезным для учащихся, изучающих английский как второй язык.
Однако исследования показали, что выполнение формальных грамматических упражнений оказало минимальное положительное влияние на письменные сочинения учащихся. Разбор предложений вышел из моды. Сегодня педагоги говорят, что классное время лучше проводить, участвуя в письме в контексте. Тем не менее, учащимся полезно уметь определять части речи и понимать их функции в предложениях. Знание того, как разбирать предложение, может быть полезным для учащихся, изучающих английский как второй язык.
Исследуйте эту статью
- Выберите короткое предложение из газеты
- Прочтите предложение Aloud
- Регистрация является основным действием
- Осмотр
- . Приведите Double Line
- Examine
- Drail A Double Line
- . предложение-2
- Нарисуйте еще одну линию
- Повторите шаги
- Разработайте систему цветового кодирования
69
необходимые вещи
- Знание частей речи
- Текстовый материал
- Блокнот
- Цветные ручки или карандаши
1 Выберите короткое предложение из газеты
Выберите короткое предложение из газеты, журнала или книги. Скопируйте предложение в тетрадь. Оставьте пустую строку между каждой строкой письма.
Скопируйте предложение в тетрадь. Оставьте пустую строку между каждой строкой письма.
Словарь
2 Прочитайте предложение вслух
Прочитайте предложение вслух. Визуализируйте смысл предложения.
3 Определите главное действие
Определите главное действие предложения. Например, в предложении «Молодой человек, который украл деньги, быстро побежал по улице», основным действием является бег, поэтому слово «побежал» является главным сказуемым предложения.
4 Изучите предложение
Изучите предложение, чтобы определить, есть ли слова, которые добавляют дополнительное описание к основному сказуемому. В этом примере дескрипторы «быстро вниз по улице». Попробуйте задать себе вопросы «как?» «куда?» и почему?» о главном предикате, в этом примере, «run», чтобы помочь вам найти дескрипторы.
5 Проведите двойную черту
Проведите двойную черту под всеми словами в полном сказуемом. В данном примере «быстро бежал по улице». Обратите внимание, что этот предикат сообщает вам о действии — «run», а также о том, где и как это произошло. Нарисуйте линию карандашом другого цвета под словом «побежал», чтобы обозначить его как основное сказуемое.
В данном примере «быстро бежал по улице». Обратите внимание, что этот предикат сообщает вам о действии — «run», а также о том, где и как это произошло. Нарисуйте линию карандашом другого цвета под словом «побежал», чтобы обозначить его как основное сказуемое.
6 Идентифицировать исполнителя
Идентифицировать исполнителя действия основного предиката. Задайте себе вопрос «Кто совершил действие?» В этом примере вы спросите: «Кто бежал?» или «кто бежал?» Нарисуйте одну линию под исполнителем действия или предметом. В этом примере основным подлежащим является «мужчина».
7 Изучите предложение-2
Изучите предложение, чтобы определить, есть ли слова, которые добавляют дополнительное описание к основному предмету. В этом примере дескрипторами являются «молодой человек, который украл деньги». Попробуйте задать себе вопросы: «Какого рода?» или «какой?» о главном предмете, в этом примере «человек», чтобы помочь вам найти дескрипторы.
8 Нарисуйте еще одну линию
Нарисуйте еще одну линию под всем объектом, используя ручку другого цвета. В этом примере полным предметом является «Молодой человек, который украл деньги».
В этом примере полным предметом является «Молодой человек, который украл деньги».
9 Повторите шаги
Повторите шаги с 1 по 8 для дополнительных предложений, чтобы попрактиковаться. Имейте в виду, что разбор предложений состоит из определения основного подлежащего и полного подлежащего, а также основного сказуемого и полного сказуемого предложения. Кроме того, синтаксический анализ включает в себя идентификацию слов, которые изменяют или описывают подлежащее и сказуемое.
10 Разработайте систему цветового кодирования
Разработайте систему цветового кодирования символов, которая поможет вам различать модифицирующие слова при разборе предложений. Используйте разные цвета или знаки, такие как круглые или квадратные скобки, для определения прилагательных, таких как «молодой», и таких предложений, как «кто украл деньги».
предупреждения
- Начните с более коротких предложений, пока не освоите навык разбора предложений.
