Содержание
Обзор нового интерфейса Яндекс.Директ + как вернуть старый — Маркетинг на vc.ru
Яндекс выкатил новый интерфейс в открытый доступ достаточно давно, но до сих пор многие пользуются старым. Мне тоже привычнее и быстрее работать в старом, но на некоторых аккаунтах возможности вернуть обратно уже нет, так что придется привыкать.
3131
просмотров
Новый интерфейс в Яндекс.Директ
Я сразу оговорюсь, что это краткий обзор. Но оставлю ссылку на официальную справку Яндекса по новому интерфейсу
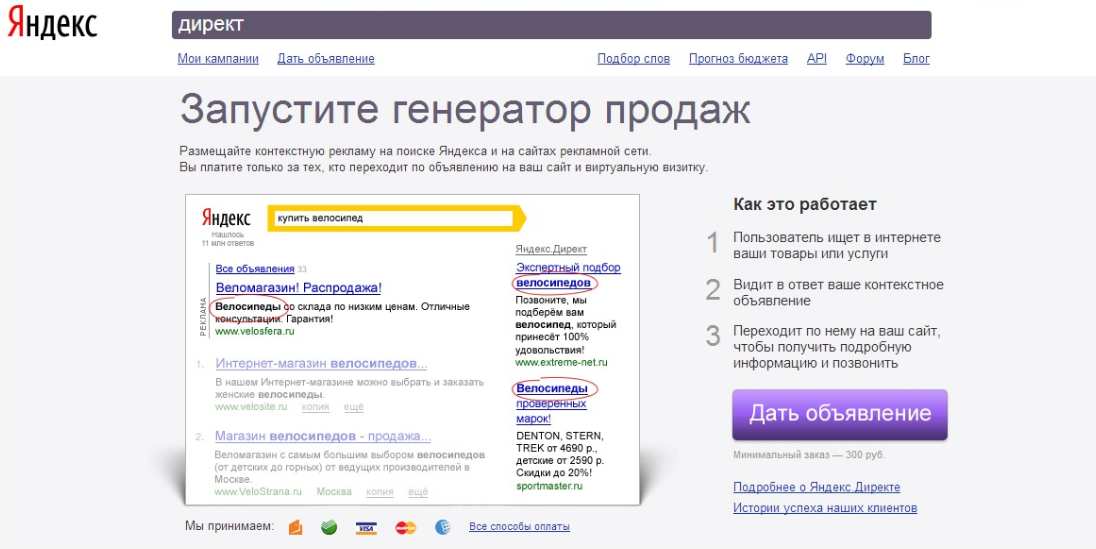
Как вернуть старый интерфейс в Яндекс.Директ
Я коротко остановлюсь на этой теме, потому что скоро Яндекс закроет эту возможность и полностью перейдет на новый вариант кабинета.
Если что, вернуть назад можно вот тут:
Как вернуть старый интерфейс Яндекс Директ Ярослав Осинцев
Краткий обзор нового интерфейса Директа
Я начну с общего обзора рабочей области кабинета. Все больше старый добрый Директ начинает походить на Google и в целом, ничего плохого в этом нет. Но если вы никогда не работали в интерфейсе Google Рекламы, то придется долго перестраиваться.
Все больше старый добрый Директ начинает походить на Google и в целом, ничего плохого в этом нет. Но если вы никогда не работали в интерфейсе Google Рекламы, то придется долго перестраиваться.
Новый интерфейс Яндекс.Директ Ярослав Осинцев
В левой части экрана появились разделы, которые облегчают доступ к некоторым инструментам:
- Рекомендации — это подсказки от Яндекса по улучшению кампании, по аналогии с советами в Google Рекламе
- Кампании — общий раздел с кампаниями, все стандартно
- Статистика — тут есть доступ к общей статистики по кампаниям, мониторгингу по фразам и заказу отчетов.
- Библиотека — вот эта фича мне очень понравилась. Тут есть быстрый доступ к аудиториям, фидам, приложениям и можно создавать списки минус-фраз.
- Инструменты — в инструментах располагается прогноз бюджета, выгрузка/загрузка через exel, доступ в подбор слов и.
 т.п.
т.п. - Гид — подробный гайд по новому кабинету от самого Яндекса, со скриншотами.
- Идеи для улучшения — можно предложить Яндексу свои идеи по улучшению сервиса
 т.п.
т.п.Что касается левой панели это в целом все, давайте перейдем к основной рабочей области
Рабочая область нового интерфейса Директ Ярослав Осинцев
Сверху располагаются понятные фильтры, которые позволяют быстро настраивать рабочую область. По кнопке «конверсии» можно посмотреть конверсии по целям (он их отфильтрует в кампаниях).
Остальные фильтры понятны интуитивно, можно фильтровать по типу кампаний, оставить или показать только архивные, выбрать период и.т.д.
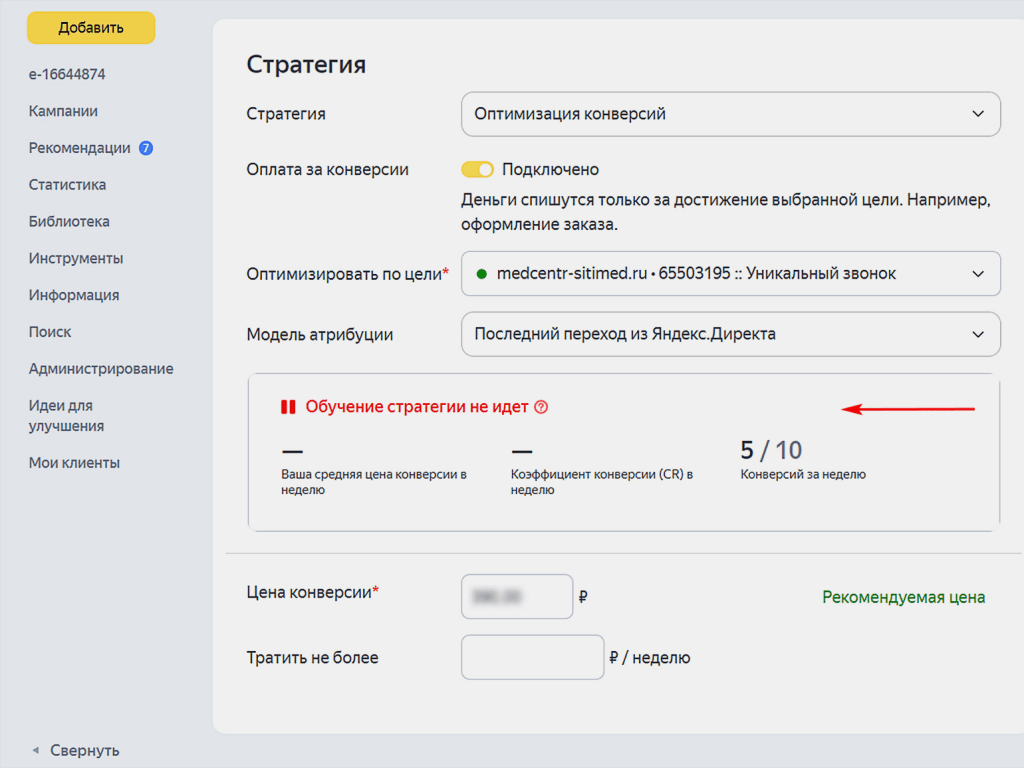
Что меня удивило — это фишка со временем обработки. Например, если вы загоните кампанию в архив и потом отфильтруете только активные — какое то время кампания все еще будет показываться по этому фильтру. Я долго не мог понять что я делаю не так, пока не обратил внимание на статус «обрабатывается«.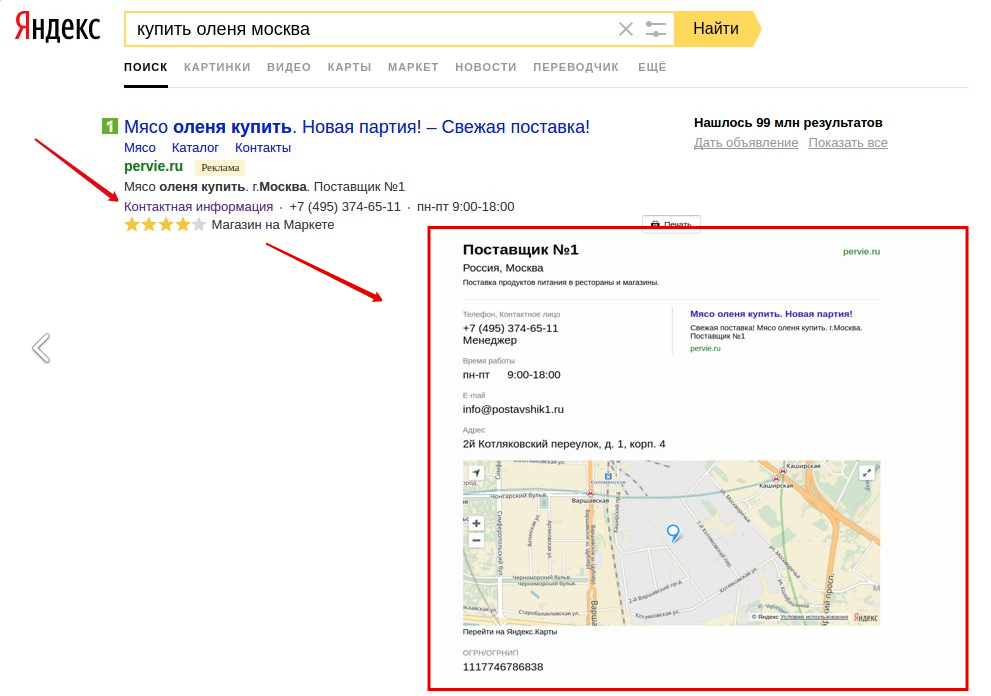 После обработки все фильтруется как нужно.
После обработки все фильтруется как нужно.
Сама логика интерфейса чем-то похожа на работу в новом Direct Commander. У вас есть четкая иерархическая система вверху: кампания — группа — объявление
Это позволяет быстро перемещаться между разделами, но в целом — не могу сказать что раньше было неудобно.
Ставки и фразы, фильтры фидов и аудитории так же можно выбрать в меню сверху.
Новый интерфейс Яндекс Ярослав Осинцев
Заключение
Не могу сказать что новый интерфейс мне пришелся по душе, но по-моему он действительно удобнее и солиднее выглядит. Другое дело, что за 5 лет работы в старом мне жутко неудобно и хочется вернуть все как было, чтобы не искать нужную кнопку.
По началу у меня вообще был ступор, я не понимал как и что смотреть. Но спустя пару недель работы начинаю привыкать, хотя часто возвращаю обратно старый интерфейс чтобы быстро поправить что-то.
Гид по интерфейсу — Директ.
 Справка
Справка
На странице кампаний вы можете изучить статистику, принять решения на основе данных и сразу внести изменения.
В мобильном виде списка кампаний отображаются только базовые показатели в зависимости от типа и стратегии кампании. Посмотреть подробную статистику можно на странице кампании. Чтобы открыть версию для компьютера на мобильном устройстве, нажмите ваш аватар в верхнем правом углу и выберите Версия для компьютера.
- Где найти привычные функции
- Основные элементы
- Навигация
- Действия с кампаниями
- Просмотр статистики
- Оплата и настройка общего счета
- Подбор фраз
- Поиск и замена
- Назначение ставок
- Рекомендации
- Управление ставками
Найдите нужную кампанию в списке и нажмите Перейти.
- Единая ставка на кампанию
В кампаниях с ручным управлением ставками нажмите и перейдите в Мастер ставок.
- Статистика по всем кампаниям
Она в боковом меню.
- Посмотреть качество аккаунта
Нажмите на логин под кнопкой Добавить.
- Зарегистрированные представители
В меню слева нажмите Информация → Ваши представители.
- Я вижу только часть своих кампаний. Где остальные?
- Проверьте фильтры. Директ показывает отдельно кампании с оплатой за показы и клики. Чтобы увидеть кампании в архиве, измените фильтр статуса: вместо «Все, кроме архивных» выберите «Все кампании» или «Архивные».
- Где ссылки, которые раньше были внизу страницы?
Ссылки, которые были внизу страницы, переехали в меню слева:
фиды, список условий ретаргетинга, креативы смарт-баннеров, конструктор Турбо-страниц, мобильные приложения — в Библиотеке;
работа с XLS/XLSX-файлами, история изменений, Подбор слов — в Инструментах.
- На экране много лишнего
В правом верхнем углу нажмите и выберите столбцы, которые нужны.
Все данные по вашим кампаниям, группам и объявлениям представлены в одном окне.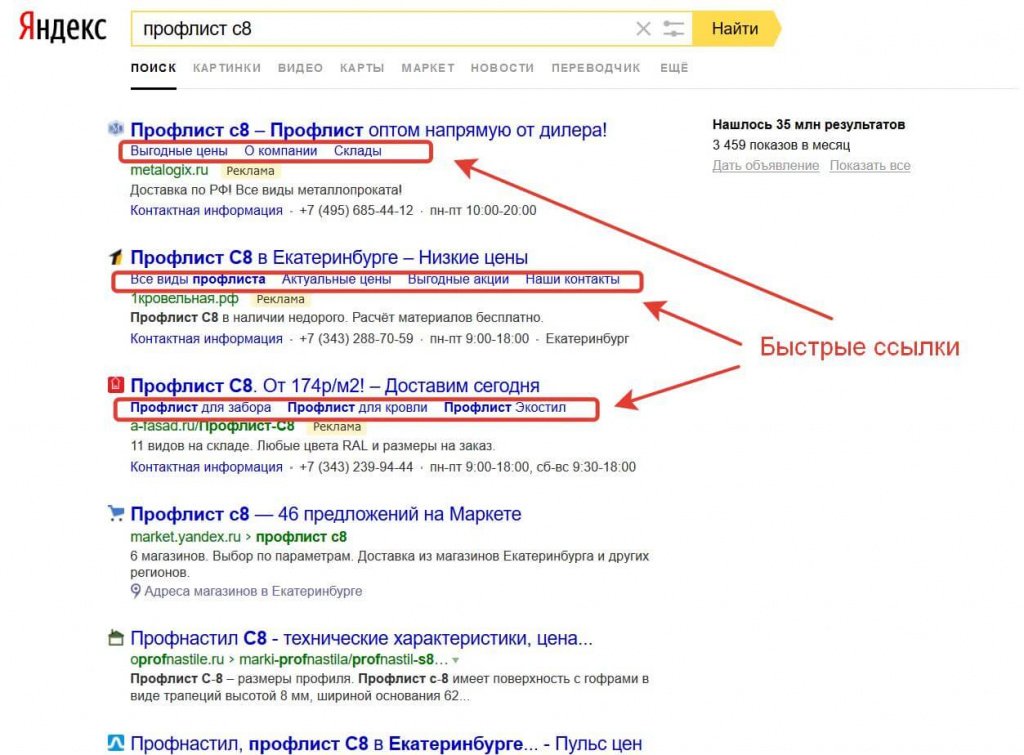 Основные элементы показаны на рисунке.
Основные элементы показаны на рисунке.
Быстрый доступ к статистике, информации о представителях, ко всем инструментам и дополнительным материалам для рекламных кампаний, собранных в библиотеке.
Данные о кампаниях
Все нужные и важные показатели отображаются на одной странице.
Поиск и фильтрация
Позволяют быстро найти все объявления с определенным словом, даже если они из разных групп или кампаний, или найти все кампании с определенным количеством кликов. Например, на вкладке Объявления в фильтре выберите Параметры → Изображение → = Включено, чтобы показать только объявления с изображением.
Чтобы увидеть медийные кампании, вместо Кампании с оплатой за клики выберите Кампании с оплатой за показы.
Новый интерфейс Директа. Работа с фильтрами
Посмотреть видео
 youtube.com/embed/8ys5vmL6NqQ» data-url=»https://www.youtube.com/embed/8ys5vmL6NqQ» allowfullscreen=»allowfullscreen» controls=»true»>
youtube.com/embed/8ys5vmL6NqQ» data-url=»https://www.youtube.com/embed/8ys5vmL6NqQ» allowfullscreen=»allowfullscreen» controls=»true»> Вкладки навигации
Вы можете переключаться между объектами: кампаниями, группами, объявлениями и ключевыми фразами. Сначала отметьте нужные кампании, затем перейдите на нужную вкладку, например, Группы. Там будут только группы выбранных кампаний.
Аналогично вы можете перейти из кампаний сразу к объявлениям или из группы к ключевым фразам и обратно.
Настройка внешнего вида таблицы
Вы можете добавлять и удалять столбцы с данными на страницах кампаний, групп, объявлений, фраз. Нажмите и отметьте нужные показатели. Чтобы изменить порядок расположения данных, передвиньте показатель на нужное место.
Новый интерфейс Директа.
Внешний видПосмотреть видео
Действия
Действия помогут, если нужно выполнить какие-то операции с выбранными объектами: изменить статус, перейти в Мастер отчетов или Мастер ставок.
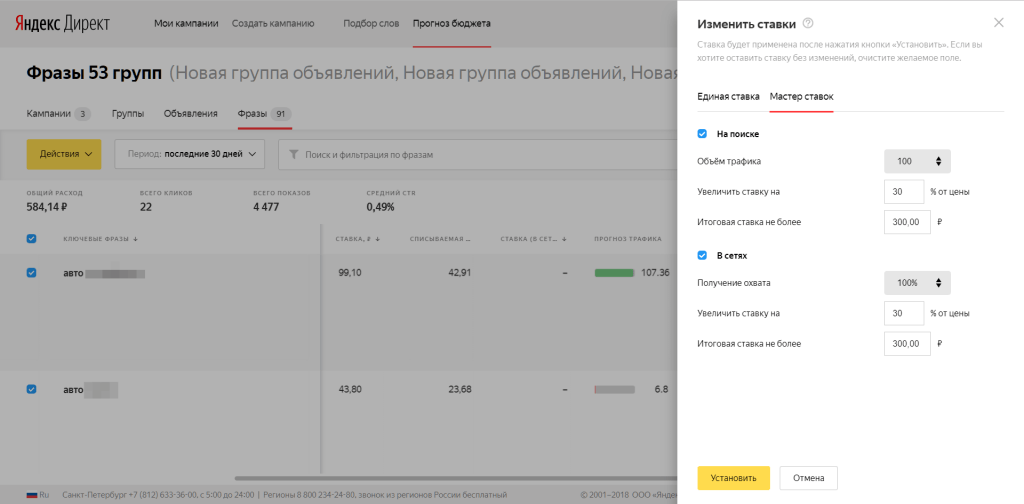 Внешний вид
Внешний видНовый интерфейс Директа. Навигация Посмотреть видео |
- Как найти нужные кампании
- В поле рядом со значком фильтра введите название или номер нужной кампании. Также найти нужную кампанию можно при помощи фильтрации по стратегии, местам показа и другим критериям.
- Как посмотреть подробную информацию о кампании и ее условиях показа
Кнопка Перейти к кампании расположена рядом с ее названием. Также можно нажать рядом с кампанией и выбрать этот пункт в меню.
- Где найти список условий ретаргетинга или креативы смарт-баннеров
- Чтобы найти список условий ретаргетинга, фиды, креативы смарт-баннеров, конструктор Турбо-страниц, мобильные приложения и минус-фразы, в меню слева нажмите Библиотека.
- Как перейти в сервис подбора слов (wordstat)
- В меню слева нажмите Инструменты → Подбор слов.
- Как перейти в настройки пользователя
- В меню слева нажмите имя пользователя и выберите Мои настройки.

- Как создать кампанию
- В меню слева нажмите Добавить → Кампанию.
- Как выделить кампании в самые важные
Отметьте нужные кампании в списке, затем нажмите Действия → Добавить в самые важные.
Чтобы увидеть список самых важных, в фильтре по статусу кампаний выберите Только самые важные.
- Как отправить на модерацию, запустить или остановить одну кампанию
Нажмите рядом с кампанией и выберите нужное действие: отправить на модерацию, запустить, остановить, удалить, отправить в архив, разархивировать, выгрузить в XLS/XLSX.
- Как запустить или отправить на модерацию несколько кампаний
- Чтобы остановить, запустить, отправить на модерацию, скопировать, удалить, отправить в архив, разархивировать, добавить или убрать из важных несколько кампаний, отметьте нужные кампании в списке, затем нажмите Действие и выберите подходящее из них.
- Как выставить дневной бюджет кампании
- Выберите кампанию и в столбце Бюджет укажите нужное значение.
- Как увидеть и поменять настройки кампании
- Слева от кампании нажмите и в открывшемся меню выберите Редактировать.
- Как увидеть список всех групп или объявлений в кампании
- Отметьте нужные кампании и нажмите Группы или Объявления в меню над списком кампаний.
- Как увидеть список всех условий показа
- Отметьте нужные кампании и нажмите в меню над таблицей: Ставки и фразы, Фильтры фидов, Ретаргетинг и подбор аудитории или Профили пользователей.
- Как отслеживать нужные показатели на странице кампаний
Создайте свою таблицу с данными по кампаниям:
Добавьте или удалите столбцы с помощью меню → Колонки кампаний. Чтобы изменить порядок расположения столбцов, передвиньте показатель на нужное место.
Добавьте к данным статистику по целям (если они настроены в Метрике) — в меню → Выбор целей отметьте нужные.
Выберите период, за который нужна статистика, — внизу нажмите кнопку Статистика <n> кампаний.
- Как перейти в Мастер отчетов
- Если нужен более подробный анализ, перейдите в Мастер отчетов:
по одной кампании — нажмите рядом с ней и в меню выберите Статистика;
по нескольким кампаниям — отметьте их, нажмите Действия → Статистика <n> кампаний;
по всем кампаниям — в меню слева выберите Статистика → Статистика по всем кампаниям.
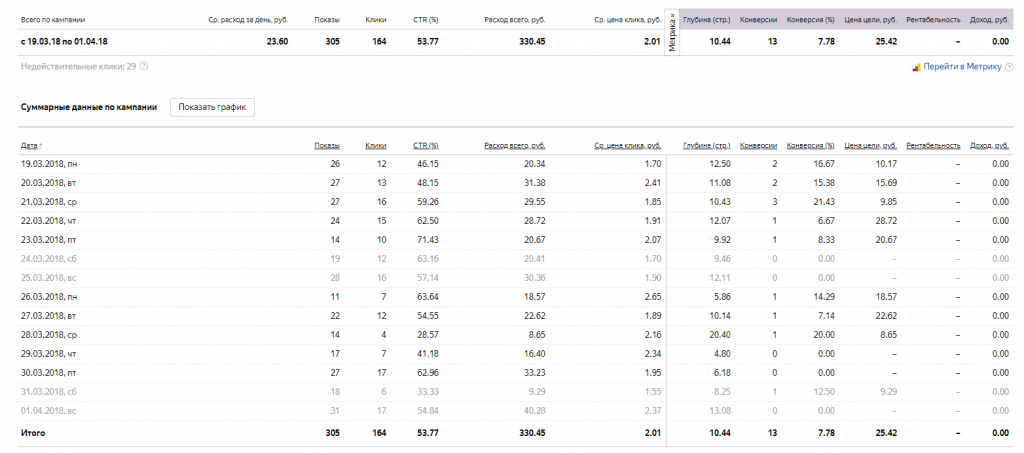
Подробнее о Мастере отчетов
- Как пополнить счет
Нажмите Пополнить под логином. В открывшемся окне укажите сумму оплаты, выберите подходящий способ и нажмите Выставить счёт.
Подробнее о способах оплаты
- Как перейти к настройкам общего счета
Нажмите Пополнить под логином. В открывшемся окне нажмите Перейти к настройкам.
Подробнее об общем счете
- Как просмотреть и изменить средний дневной бюджет
Нажмите Пополнить под логином. В открывшемся окне в блоке Средний дневной бюджет указана сумма текущего ограничения. Чтобы ее скорректировать, нажмите Изменить. В окне Общий счет в блоке Средний дневной бюджет нажмите Настроить и задайте нужное ограничение.
Подробнее о среднем дневном бюджете
Подбор фраз помогает расширить набор ключевых фраз и минус-фраз на группы объявлений, используя информацию о запросах пользователей Яндекса из сервиса wordstat. yandex.ru.
yandex.ru.
Чтобы подобрать ключевые фразы в меню слева нажмите Добавить → Ключевые фразы, выберите кампанию и группу, нажмите Добавить.
Подробнее о подборе фраз.
Инструмент поиска и замены позволяет быстро внести исправления сразу в несколько ключевых фраз в разных кампаниях и группах, например, исправить опечатку.
Чтобы выполнить замену, на вкладке Ставки и фразы внизу нажмите кнопку Поиск и замена.
Подробнее о поиске и замене.
Вы можете быстро назначить ставки на поиске и в сетях:
для всей кампании;
для большого количества ключевых фраз, даже если они относятся к разным кампаниям или группам объявлений.
- Для всей кампании
Выберите кампанию и внизу нажмите Мастер ставок.
- Для ключевых фраз
Выберите нужные кампании и группы объявлений. На странице Ставки и фразы выберите фразы и нажмите Мастер ставок.
Подробнее о назначении ставок.
Рекомендации подскажут вам, как нужно изменить кампании, чтобы они приносили больше кликов и конверсий. Директ проанализирует данные ваших кампаний и даст персональные советы по их улучшению. Следуйте рекомендациям и следите за результатами.
Чтобы посмотреть, что советует Директ, перейдите в меню в раздел Рекомендации. Подробнее о рекомендациях.
Внимание. Специалисты отдела клиентского сервиса могут вас проконсультировать только по рекламным кампаниям того логина, с которого вы обращаетесь. Логин можно увидеть в правом верхнем углу экрана. Специалист получит доступ к вашим данным только при обработке обращения.
Написать в чат
Клиентам и представителям агентств можно связаться с нами круглосуточно по телефонам:
Россия: 8 800 234-24-80 (звонок из России бесплатный)
Москва: +7 495 739-37-77
Беларусь: 8 820 00-73-00-52 (звонок из Беларуси бесплатный), +375 17 336-31-36
Казахстан: +7 727 313-28-05, доб. 2480
2480
Для доступа к кампаниям специалисту потребуется PIN-код.
Все о специальных элементах в Яндексе
Поисковая система Яндекс имеет в своем арсенале очень богатый функционал, упрощающий поиск информации для пользователей. Интерфейс результатов поиска, помимо привычных сниппетов — строк с названиями сайтов в виде ссылки и краткого описания, еще и разбавлен специальными блоками. Тип и назначение таких элементов варьируется в зависимости от характера запроса.
Специальные элементы поисковой системы Яндекс
Для спецэлементов есть общепринятый термин — поисковые колдуны (SERP Features). Спецэлементы формируются путем обработки базы данных и сервисов Яндекса, а также крупных официальных источников информации, таких как Википедия. Пользователь может наблюдать за магами при поиске информации о текущем курсе валют, прогнозе погоды, рецепте и т.д. страницу результатов без необходимости перехода на сторонние ресурсы. Блоки, которые формируются на странице, содержат исчерпывающую информацию для пользователя. Элементы часто занимают первую и последнюю строчки выдачи, также справа формируется специальный дополнительный блок. Позиция колдунов на странице выдачи не статична и меняется в зависимости от запроса и обновлений алгоритма. Колдуны разбавляют страницу выдачи, чтобы пользователь максимально быстро находил нужную информацию, а также рекомендуют варианты или товары, которые могут его заинтересовать.
Элементы часто занимают первую и последнюю строчки выдачи, также справа формируется специальный дополнительный блок. Позиция колдунов на странице выдачи не статична и меняется в зависимости от запроса и обновлений алгоритма. Колдуны разбавляют страницу выдачи, чтобы пользователь максимально быстро находил нужную информацию, а также рекомендуют варианты или товары, которые могут его заинтересовать.
Типы колдунов
Каждый тип спецэлемента предназначен для определенного типа запроса. По характеру поисковые запросы можно разделить на информационные, коммерческие или ГЕО. Алгоритмы системы легко распознают тип запроса и отображают мастер с наиболее подходящим интерфейсом. Рассмотрим подробнее основные виды.
Блок ответов
Это колдун в «нулевой строке» вопроса с кратким и полным ответом на информационный запрос. Примеры тем запросов: рейтинги, рецепты, FAQ. Под ответом есть ссылка на исходный сайт.
Быстрый ответ
Если вводится общий или популярный запрос, то Яндекс использует блок Быстрый ответ.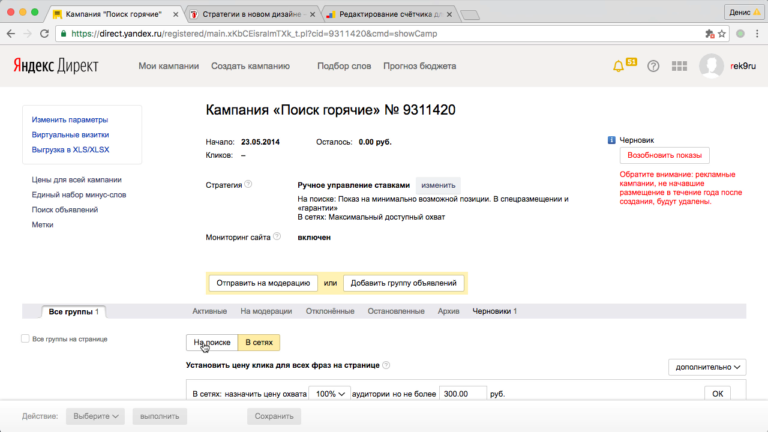 Отличие от предыдущего колдуна в том, что в блоке не будет указана ссылка на источник, так как поисковик выводит данные со своих сервисов. Простым примером запроса может быть «обменный курс» или «калькулятор».
Отличие от предыдущего колдуна в том, что в блоке не будет указана ссылка на источник, так как поисковик выводит данные со своих сервисов. Простым примером запроса может быть «обменный курс» или «калькулятор».
Адреса и карты
Это специальный блок, который отображается при привязке коммерческого запроса к определенной локации. Если ввести запрос типа «супермаркет на старом Арбате», то появится блок с ограниченным фрагментом карты, а также карусель из 10 организаций, соответствующих запросу. Данные берутся с сервиса Яндекс, поэтому колдун предложит вам перейти на карты.
Object Response
Этот специальный элемент работает аналогично быстрым ответам, но отображается только для информационных запросов, таких как имена известных людей, фильмы или телепередачи. Источником данных для этого колдуна являются его собственные сервисы и Википедия. Помимо фотографий, в этом блоке может отображаться видеоконтент.
«Блок знаний»
Этот колдун ориентирован на запросы бренда. В специальном блоке отображается полная информация о компании, рейтинги и отзывы, контактная информация. Кроме того, будут предложены и другие подобные места.
В специальном блоке отображается полная информация о компании, рейтинги и отзывы, контактная информация. Кроме того, будут предложены и другие подобные места.
Картинки и Видео
Колдун выводит на запрос специальный блок, который подразумевает ответ в виде графического или видео контента. Эти специальные элементы отображаются как для информационных, так и для коммерческих запросов, при условии, что сайт достаточно оптимизирован. Таким образом, пользователи могут видеть фотографии и целые обзоры товаров.
Карусель
Карусель — это часть специального блока, содержащая выбор вариантов запросов информации: список сериалов, книг, футболистов и т. д. Используется для контентных сайтов.
Яндекс.Маркет
Мастер для интернет-магазинов, отображающий специальные элементы для коммерческих запросов типа «цена» или «заказ». Имеет несколько вариантов одновременного отображения блока: как специальный блок в правой части поисковой выдачи, как ссылка на «Яндекс Маркет» в любом месте органической выдачи или как ссылка на товар с пометкой « Реклама».
«Вам может быть интересно»
Специальные элементы, которые отображаются в виде дополнительных серых блоков под сниппетом на странице результатов поиска. Внутри блока находятся текстовые ссылки с похожими поисковыми запросами.
Яндекс.Директ
Рекламные блоки также являются специальными элементами Яндекса и занимают первое и последнее места на странице результатов поиска. Увидеть их можно только при вводе коммерческого запроса. Есть дополнительный вид этого колдуна — «Все объявления Яндекс Директ». Его можно увидеть на любой позиции органической выдачи в виде ссылки на товар и блоков «Возможно, вам будет интересно».
Чат Организации
Колдун, который отображает специальный блок чата в правой части выдачи и позволяет сразу начать диалог с организацией, предоставляющей различные товары или услуги.
Яндекс.Q
Когда пользователь вводит вопрос, сервис Яндекс Экспертов сразу выведет ответ на страницу поиска, если найдет что-то подходящее в своей базе.
Обогащенные ответы
В мае 2021 года Яндекс начал тестирование колдуна нового типа — обогащенных ответов. И уже в июле сервис был полностью запущен. По сути, это своего рода расширенный сниппет или блок для сайта, в котором отображается дополнительная информация. Особенности этого колдуна в том, что он доступен всем партнерам поисковой системы, а не только сервисам Яндекса. По словам разработчиков, расширенные ответы обычно ранжируются в поисковой выдаче. Таким образом, чем лучше ресурс отвечает на запрос, тем больше вероятность получить дополнительные блоки на странице поиска.
Типы расширенных ответов:
- Навигационные
- Адреса
- Список организаций
- Продукты
- Рецепты еды и напитков
- Данные из социальных сетей
- оценок
- Новости
- Отзывы
- Фрагмент изображения
- Быстрый ответ
- Фрагмент видео
- Фильмы и сериалы
- Список гостиниц
- Галерея продуктов
Принципы сотрудничества
Однако для того, чтобы этот колдун появился в сниппете, необходимо соблюдение определенных строгих условий или, как это называют сами разработчики, принципов.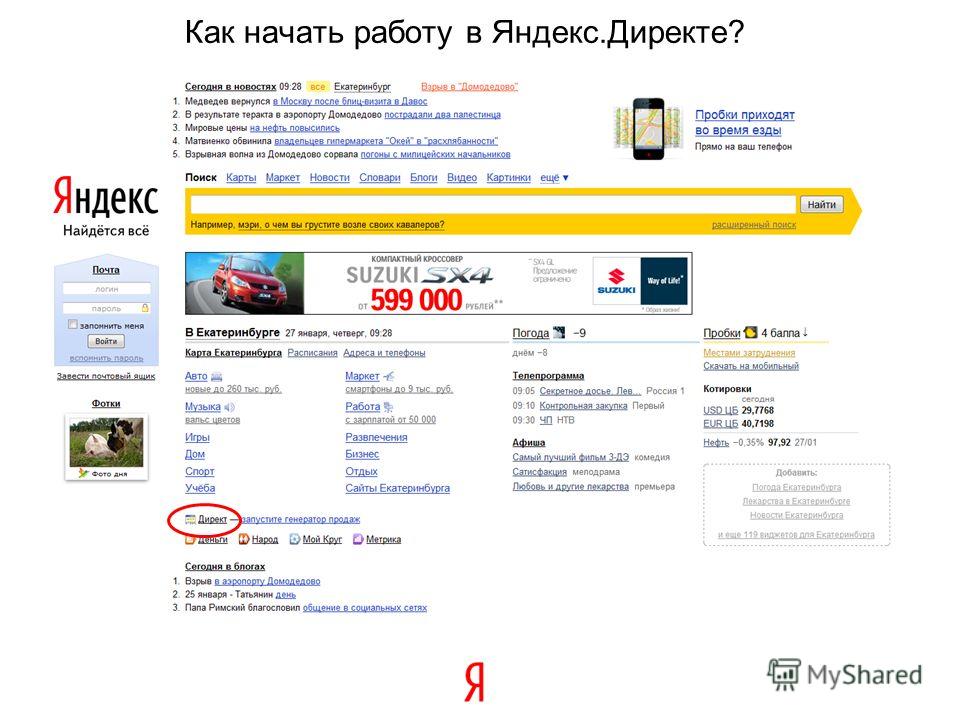 Основой для партнерства станет полная интеграция сайта с сервисами Яндекса и предоставление большого объема внутренних данных, таких как посещаемость и финансовые обороты.
Основой для партнерства станет полная интеграция сайта с сервисами Яндекса и предоставление большого объема внутренних данных, таких как посещаемость и финансовые обороты.
Y1
Помимо расширенных сниппетов разработчики запустили в тестовом режиме новую версию поиска Яндекса под названием «Y1». Новый поисковик основан на двух новых технологиях «ЯТИ» и «ЯЛМ» — тяжелых нейронных сетях с внушительным названием «трансформер». Обновленный алгоритм не меняет основной миссии компании — пользователь должен найти нужную информацию как можно быстрее.
Помимо нового дизайна поисковик также должен пополниться новыми специальными элементами.
Поиск без поиска
Быстрые ответы получат обновление и будут принадлежать группе колдунов «Поиск без поиска».
Примеры новых колдунов:
- Рекомендуемый фрагмент видео – проигрывает видео сразу в нужном пользователю месте;
- Куда лететь? — колдун показывает важную информацию о странах и курортах: меры карантина, как добраться, отели и прочее.
- Что посмотреть? – Рекомендует фильмы, книги и сериалы на собственных и сторонних сервисах.
- Где поесть? — анализирует и показывает местные заведения общепита, сравнивая отзывы, цены и другие важные параметры
- Как наши? — показывает самые актуальные новости в зависимости от местонахождения пользователя.
Умная камера
Новый колдун условно называется «Поиск без слов». Он основан на принципе распознавания объектов по фотографии. Достаточно просто просканировать любой предмет, животное или человека, чтобы колдун смог найти нужную информацию.
Search Safe
В поиске появится служба контроля качества, которая будет отслеживать отзывы о кампаниях и удалять не несущие смысловой нагрузки или являющиеся фейком. Пользователь сразу увидит рейтинги магазинов и другую полезную информацию. Также будет значительно улучшена защита от сомнительных ресурсов и угроз. Дополнительные блоки сигнализируют о репутации сайта.
Мобильное приложение
Теперь новую версию поиска Y1 можно протестировать в мобильном приложении. Все новые виды колдунов уже интегрированы в поисковик.
Кроме того, вы можете ознакомиться с обновленным дизайном главной страницы, специальными элементами в результатах поиска, а также другими новыми функциями.
Заключение
Использование колдунов значительно упрощает поиск пользователей, так как информация представлена в виде привлекательных информативных блоков. С другой стороны, большое количество рекламных блоков затрудняет поиск нужной информации или услуги.
На любой сайт можно добавить микроданные, формирующие расширенный фрагмент. Если ваш сайт соответствует всем условиям поисковой системы, то с помощью колдунов вы сможете значительно увеличить количество трафика.
Принцип реализации расширенных ответов позволяет всем сайтам конкурировать с сервисами Яндекса на общих условиях. Если тестирование Y1 пройдет успешно, вскоре все перейдут на новую версию, что, несомненно, станет катализатором новых обновлений спецэлементов.
Павел Власюк
SEO-специалист
Узнайте, как мы можем помочь развитию вашего бизнеса
Свяжитесь с нами!
похожие статьи
подписываться:
#
SEO
12 ноября 2021
#
SEO
3 ноября 2021
#
SEO
13 октября 2021
Комментарии
Эволюция структур данных в Яндекс.
 Метрике
Метрике
Яндекс.Метрика — вторая по величине система веб-аналитики в мире. Метрика получает поток данных о событиях, которые произошли на сайтах или в приложениях. Наша задача состоит в том, чтобы обработать эти данные и представить их в анализируемом виде.
Обработка данных сама по себе не является проблемой. Настоящая трудность заключается в попытке определить, в какой форме следует сохранять обработанные результаты, чтобы с ними было удобно работать. В процессе разработки нам несколько раз приходилось полностью менять подход к организации хранения данных. Мы начали с таблиц MyISAM, затем использовали LSM-деревья и, в конце концов, придумали столбцовую базу данных ClickHouse. В этой статье я объясню, почему мы остановились на последнем варианте.
Яндекс.Метрика была запущена в 2008 году и работает уже более девяти лет. Каждый раз, когда мы меняли подход к хранению данных в прошлом, это происходило из-за того, что то или иное решение оказывалось неэффективным: либо был недостаточный запас производительности, либо решение было ненадежным, либо потребляло слишком много вычислительных ресурсов, либо просто не позволяло нам реализовать то, что нам нужно.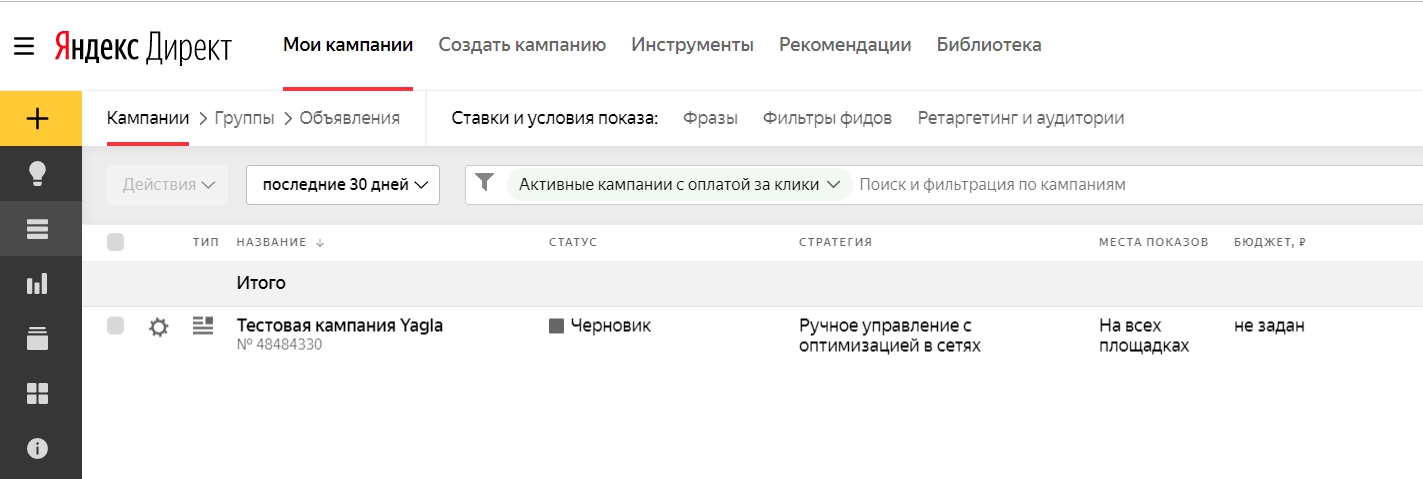
В старой Яндекс.Метрике для сайтов более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов внутристраничной аналитики (например, карты кликов), Вебвизор (позволяет изучать действия отдельных пользователей в большая детализация), а также отдельный конструктор отчетов.
С новыми Metrica и Appmetrica вы можете настраивать каждый отчет вместо того, чтобы иметь дело с «фиксированными» типами. Вы можете добавить новые параметры (например, в отчете по поисковым запросам вы можете разбить данные по целевым страницам), сегментировать и сравнивать (скажем, между источниками трафика для всех посетителей и посетителей из Сан-Франциско), изменить свой набор метрик и т. д. Таким образом, новая система требует совершенно другого подхода к хранению данных, чем тот, который мы использовали ранее.
MyISAM
Метрика создавалась как ответвление сервиса поисковых объявлений Яндекс.Директа. Таблицы MySQL с движком MyISAM использовались в Директе для хранения статистики, с чего мы и начинали в Метрике.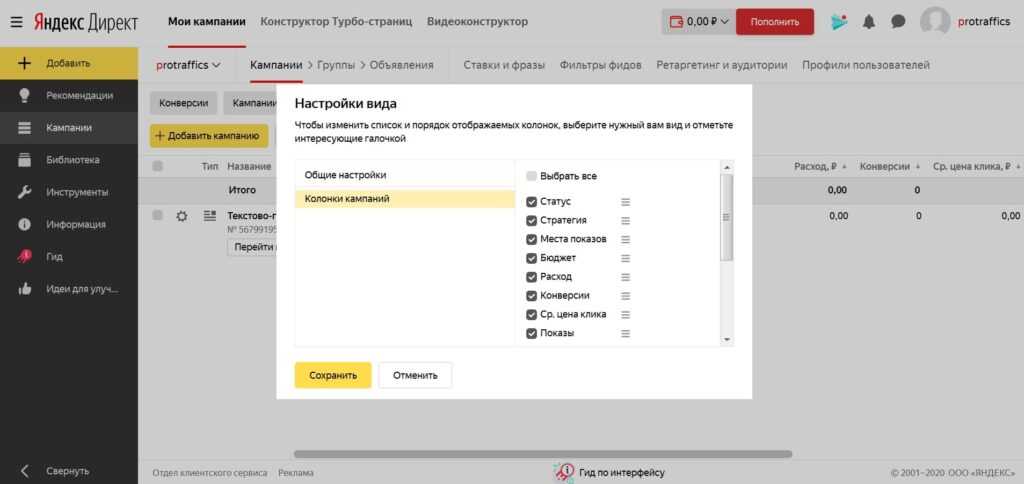 Мы использовали MyISAM для хранения «фиксированных» отчетов с 2008 по 2011 год.
Мы использовали MyISAM для хранения «фиксированных» отчетов с 2008 по 2011 год.
Позвольте мне немного объяснить, какую структуру должны иметь таблицы отчетов, например, при работе с географией. Отчет формируется по конкретному сайту (точнее, по конкретному идентификатору счетчика Метрики). Это означает, что первичный ключ должен содержать CounterID. Пользователь может выбрать произвольный период отчета. Сохранение данных для каждой пары дат не имеет смысла, поэтому данные сохраняются для каждой даты, а затем суммируются по запросу для выбранного интервала. Следовательно, первичный ключ содержит дату.
Данные в отчете отображаются по регионам либо в виде списка, либо в виде дерева, состоящего из стран, регионов и городов. Таким образом, имеет смысл поместить RegionID в первичный ключ таблицы и собрать данные в дерево на стороне кода приложения, а не на стороне базы данных.
Допустим, мы также хотим учитывать среднюю продолжительность сеанса. Это означает, что столбцы таблицы должны содержать количество сеансов и общую продолжительность сеанса.
Таким образом, результирующая таблица будет иметь следующую структуру: CounterID, Date, RegionID -> Visits, SumVisitTime,… Теперь посмотрим, что происходит, когда мы запрашиваем отчет. Запрос SELECT выполняется с условиями, ГДЕ CounterID = AND Date BETWEEN min_date AND max_date. Другими словами, считывается диапазон первичного ключа.
Как на самом деле данные хранятся на диске?
Таблица MyISAM состоит из файла данных и индексного файла. Если из таблицы ничего не удалялось и длина строк при обновлении не менялась, то файл данных будет состоять из сериализованных строк, расположенных последовательно в том порядке, в котором они были вставлены. Индекс (включая первичный ключ) представляет собой B-дерево, листья которого содержат смещения в файле данных. Когда мы читаем данные диапазона индекса, набор смещений в файле данных извлекается из индекса. Затем файл данных считывается по этому набору смещений.
Рассмотрим реальную ситуацию, когда индекс находится в оперативной памяти (кэш ключей в MySQL или системный кеш страниц), но данные в нем не кэшируются. Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от того, сколько операций поиска необходимо выполнить. Количество операций поиска определяется расположением данных на диске.
Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от того, сколько операций поиска необходимо выполнить. Количество операций поиска определяется расположением данных на диске.
События Метрики поступают практически в том же порядке, в котором они происходили на самом деле. В этом входящем потоке данные с разных счетчиков разбросаны совершенно хаотично. Другими словами, входящие данные являются локальными по времени, но не локальными по номеру счетчика. При записи в таблицу MyISAM данные с разных счетчиков также размещаются довольно хаотично. Это означает, что для чтения отчета с данными вам потребуется выполнить примерно столько случайных чтений, сколько строк в таблице нам нужно.
Типичный жесткий диск со скоростью вращения 7200 об/мин может выполнять от 100 до 200 случайных операций чтения в секунду. Массив RAID, при правильном использовании, может выполнять гораздо больше функций.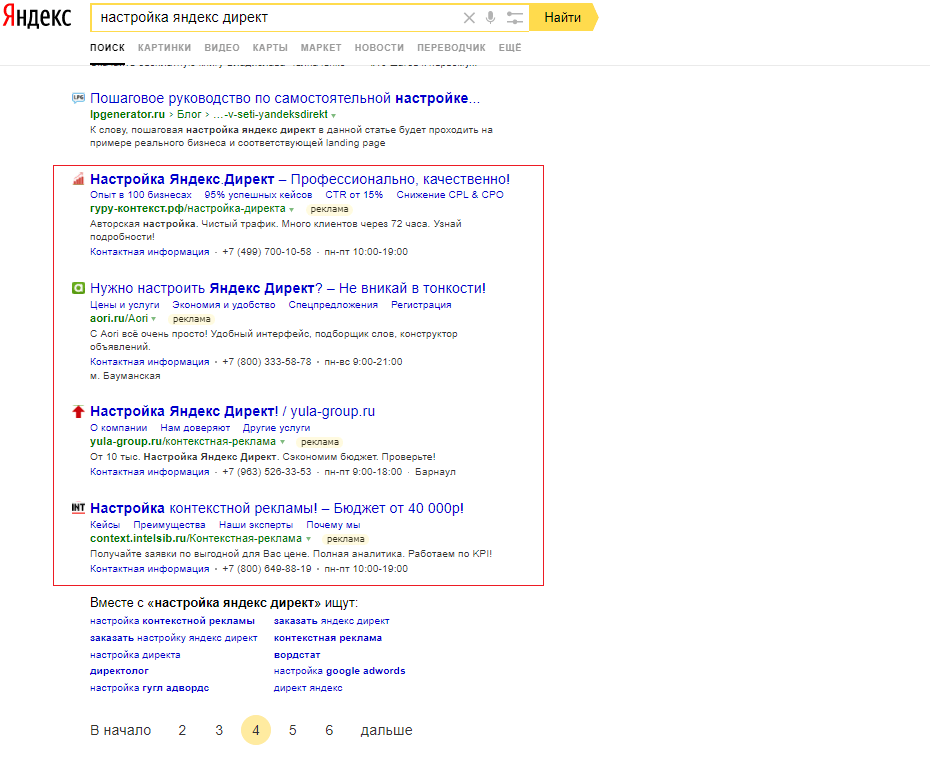 Один семилетний SSD может выполнять 30 000 случайных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. С этой системой, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
Один семилетний SSD может выполнять 30 000 случайных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. С этой системой, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
InnoDB гораздо лучше подходит для чтения диапазонов первичных ключей, поскольку использует кластеризованный первичный ключ (т. е. данные хранятся упорядоченным образом в первичном ключе). Но InnoDB было невозможно использовать из-за низкой скорости записи. Если это напоминает вам о TokuDB, то читайте дальше.
Мы применили несколько трюков, чтобы MyISAM работал быстрее при выборе диапазона первичного ключа.
Таблица сортировки. Поскольку данные должны обновляться постепенно, недостаточно отсортировать таблицу один раз, но сортировать ее каждый раз невозможно. Тем не менее, это можно делать периодически для старых данных.
Разделение. Таблица делится на несколько меньших диапазонов первичных ключей. Это сделано в расчете на то, что данные из одного раздела будут храниться более-менее локально и запросы на диапазон первичного ключа будут обрабатываться быстрее. Этот метод можно отнести к ручной реализации кластеризованного первичного ключа. Это немного замедляет вставку данных. Однако при выборе количества разделов обычно удается достичь компромисса между скоростью вставки и скоростью чтения.
Это сделано в расчете на то, что данные из одного раздела будут храниться более-менее локально и запросы на диапазон первичного ключа будут обрабатываться быстрее. Этот метод можно отнести к ручной реализации кластеризованного первичного ключа. Это немного замедляет вставку данных. Однако при выборе количества разделов обычно удается достичь компромисса между скоростью вставки и скоростью чтения.
Разделение данных по поколениям. При одной схеме разбиения выборки могут сильно тормозить, при другой — скорость вставки. И оба тормозят при использовании промежуточного варианта. Решение этой проблемы состоит в том, чтобы разделить данные на несколько отдельных поколений. Например, первое поколение мы будем называть операционными данными; здесь разделение либо происходит по мере вставки данных (по времени), либо не происходит вообще. Мы будем называть архивные данные второго поколения; здесь происходит разбиение по мере чтения данных (по номеру счетчика). Данные передаются от поколения к поколению через скрипт, но не слишком часто (например, раз в день) и считываются сразу со всех поколений. Это помогает, но и создает массу трудностей.
Это помогает, но и создает массу трудностей.
Эти (и другие) уловки некоторое время использовались в Яндекс.Метрике, чтобы все работало.
Подытожим недостатки предыдущей системы:
- очень сложно поддерживать локальность данных на диске
- таблицы заблокированы во время INSERT
- репликация медленная; реплики часто отстают
- согласованность данных после аппаратного сбоя не гарантируется
- агрегатов, таких как количество уникальных пользователей, очень сложно подсчитать и сохранить
- сжатие данных сложно использовать и работает неэффективно
- индексы занимают много места и не помещаются в ОЗУ полностью
- данные должны быть сегментированы вручную
- многие вычисления должны быть выполнены на стороне кода приложения после SELECT
- сложный в обслуживании и эксплуатации
Изображение: расположение данных на диске (художественный рендеринг)
Таким образом, использование MyISAM было крайне неудобным.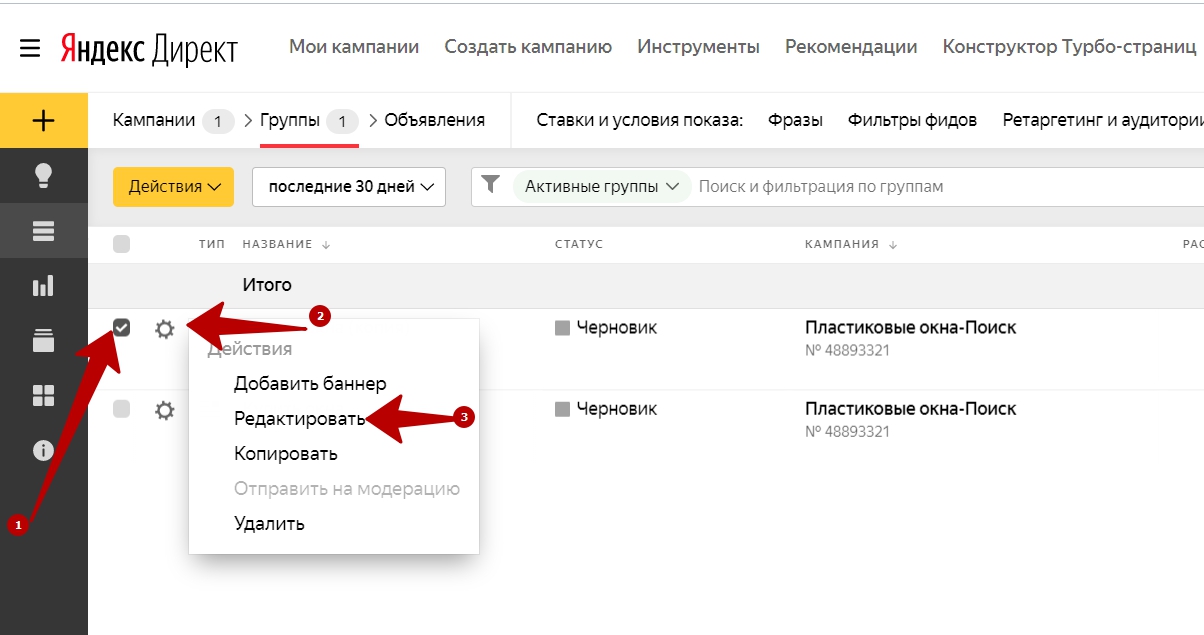 В дневное время серверы работали со 100% нагрузкой на дисковые массивы (постоянное движение головок). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, нам приходилось довольно часто восстанавливать RAID-массивы. Иногда реплики так сильно отставали, что нам приходилось их удалять и создавать заново. Переключение мастера репликации действительно неудобно.
В дневное время серверы работали со 100% нагрузкой на дисковые массивы (постоянное движение головок). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, нам приходилось довольно часто восстанавливать RAID-массивы. Иногда реплики так сильно отставали, что нам приходилось их удалять и создавать заново. Переключение мастера репликации действительно неудобно.
Несмотря на недостатки, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM. Потом все было переконвертировано в Metrage, удалено и в итоге освободилось много серверов.
Metrage и OLAPServer
Мы используем Metrage для хранения фиксированных отчетов с 2010 года. Предположим, у вас есть следующий сценарий:
- данные постоянно записываются в базу данных небольшими партиями
- поток записи относительно большой (не менее нескольких сотен тысяч строк в секунду)
- сравнительно мало запросов на чтение (несколько тысяч запросов в секунду)
- все чтения диапазона первичного ключа (до миллионов строк на запрос)
- строк довольно короткие (около 100 байт без сжатия)
Довольно распространенная структура данных LSM Tree хорошо подходит для этого. Эта структура состоит из сравнительно небольшой группы «фрагментов» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные сначала помещаются в некую структуру данных ОЗУ (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков будут уплотняться в один больший в фоновом режиме. Таким образом поддерживается относительно небольшой набор фрагментов.
Эта структура состоит из сравнительно небольшой группы «фрагментов» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные сначала помещаются в некую структуру данных ОЗУ (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков будут уплотняться в один больший в фоновом режиме. Таким образом поддерживается относительно небольшой набор фрагментов.
Такие структуры данных используются в HBase и Cassandra. Среди встроенных структур данных LSM-Tree реализованы LevelDB и RocksDB. Впоследствии RocksDB используется в MyRocks, MongoRocks, TiDB, CockroachDB и многих других.
Metrage также является LSM-деревом. Произвольные структуры данных (зафиксированные во время компиляции) могут использоваться в нем как «строки». Каждая строка представляет собой пару ключ-значение. Ключ — это структура с операциями сравнения на равенство и неравенство. Значение представляет собой произвольную структуру с операциями обновления (добавления чего-либо) и слияния (агрегирования или объединения с другим значением). Короче говоря, это CRDT.
Короче говоря, это CRDT.
В качестве значений могут выступать как простые структуры (целочисленные кортежи), так и более сложные (например, хэш-таблицы для подсчета количества уникальных посетителей или структуры карты кликов). С помощью операций обновления и слияния постоянно осуществляется инкрементная агрегация данных в следующих точках:
- при вставке данных при формировании новых пакетов в ОЗУ
- во время фонового слияния
- во время запросов на чтение
Metrage также содержит необходимую нам логику предметной области, которая выполняется во время запросов. Например, для региональных отчетов ключ в таблице будет содержать идентификатор самого низкого региона (города, села) и, если нам нужен отчет по стране, данные по стране будут агрегироваться на стороне сервера базы данных.
Вот основные преимущества этой структуры данных:
- Данные достаточно локально расположены на жестком диске; чтение диапазона первичного ключа происходит быстро.
- Данные сжаты блоками. Поскольку данные хранятся упорядоченно, сжатие работает довольно хорошо при использовании алгоритмов быстрого сжатия (в 2010 году мы использовали QuickLZ, с 2011 года — LZ4).
- Хранение данных, отсортированных по первичному ключу, позволяет нам использовать разреженный индекс. Разреженный индекс — это массив значений первичного ключа для каждой N-й строки (порядка N тысяч). Этот индекс максимально компактен и всегда умещается в оперативной памяти.
Поскольку чтение выполняется не очень часто (даже несмотря на то, что при этом считывается много строк), увеличение задержки из-за большого количества фрагментов и распаковки блоков данных не имеет значения. Чтение дополнительных строк из-за разреженности индекса также не имеет значения.
Записанные фрагменты данных не изменяются. Это позволяет читать и писать без блокировки — для чтения делается снимок данных. Используется простой и унифицированный код, но мы можем легко реализовать всю необходимую предметно-ориентированную логику.
Нам пришлось написать Metrage вместо изменения существующего решения, потому что его на самом деле не было. В 2010 году LevelDB не существовало, а TokuDB в то время была собственностью.
Все системы, реализующие LSM-Tree, подходили для хранения неструктурированных данных и карт из BLOB в BLOB с небольшими вариациями. Но чтобы адаптировать этот тип системы для работы с произвольным CRDT, потребовалось бы гораздо больше времени, чем для разработки Metrage.
Конвертация данных из MySQL в Metrage заняла довольно много времени: если на работу программы конвертации ушло всего около недели, то на основную ее часть ушло около двух месяцев.
После передачи отчетов в Метраж мы сразу увидели увеличение скорости интерфейса Метрики. Мы используем Metrage уже пять лет, и это решение оказалось надежным. За это время было всего несколько мелких поломок. Его преимущества заключаются в простоте и эффективности, что делает его гораздо лучшим выбором для хранения данных, чем MyISAM.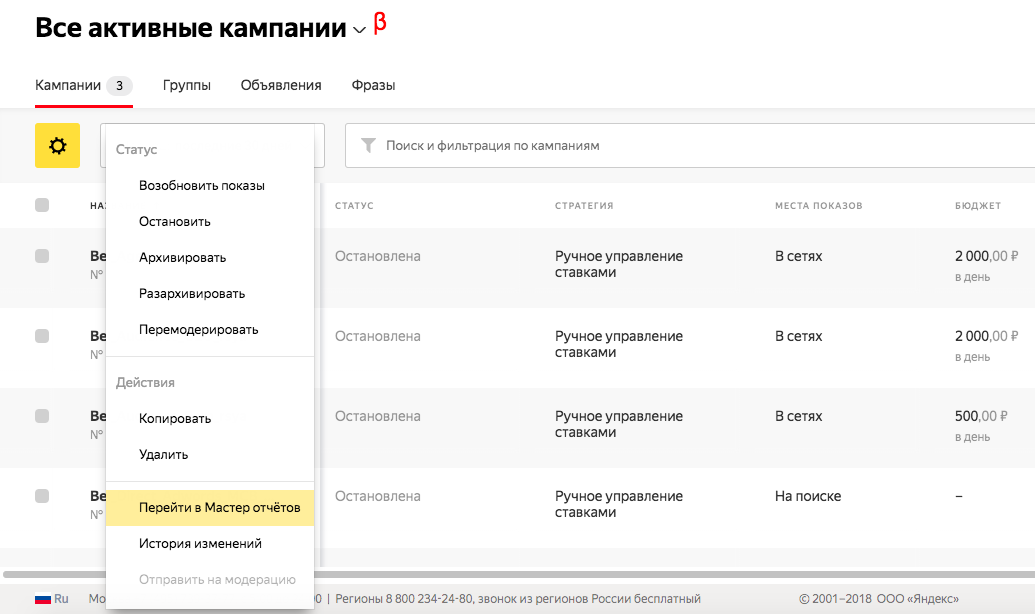
По состоянию на 2015 год мы хранили 3,37 триллиона строк в Metrage и использовали для этого 39 * 2 серверов. Потом мы отошли от хранения данных в Metrage и удалили большую часть таблиц. У системы есть свои недостатки; он действительно эффективно работает только с фиксированными отчетами. Metrage агрегирует данные и сохраняет агрегированные данные. Но для этого вы должны заранее перечислить все способы, которыми вы хотите агрегировать данные. То есть, если мы делаем это 40 разными способами, значит, Метрика будет содержать 40 типов отчетов и не более.
Чтобы смягчить это, нам пришлось какое-то время сохранять отдельное хранилище для мастера настраиваемых отчетов под названием OLAPServer. Это простая и очень ограниченная реализация столбцовой базы данных. Он поддерживает только один набор таблиц во время компиляции — таблицу сеансов. В отличие от Metrage, данные обновляются не в режиме реального времени, а несколько раз в день. Единственный поддерживаемый тип данных — это числа фиксированной длины от 1 до 8 байт, поэтому он не подходил для отчетов с другими видами данных, например URL-адресами.
ClickHouse
С помощью OLAPServer мы поняли, насколько хорошо СУБД, ориентированные на столбцы, справляются с задачами специальной аналитики с неагрегированными данными. Если вы можете получить любой отчет из неагрегированных данных, то возникает вопрос, нужно ли данные вообще агрегировать заранее, как мы сделали с Metrage.
Изображение: обработка запросов в столбцовой базе данных
С одной стороны, предварительное агрегирование данных может уменьшить объем данных, которые используются в момент загрузки страницы отчета. С другой стороны, однако, агрегированные данные не решают всего. Вот почему:
- вам нужно заранее составить список отчетов, которые нужны вашим пользователям
- другими словами, пользователь не может составить пользовательский отчет
- при агрегации большого количества ключей объем данных не уменьшается и агрегация бесполезна
- при большом количестве отчетов слишком много вариантов агрегирования (комбинаторный взрыв)
- при агрегировании ключей высокой мощности (например, URL) количество данных уменьшается ненамного (менее чем вдвое)
- за счет этого объем данных может не уменьшаться, а фактически расти при агрегации
- пользователи не будут просматривать все отчеты, которые мы для них рассчитываем (другими словами, многие расчеты оказываются бесполезными)
- трудно поддерживать логическую согласованность при хранении большого количества различных агрегатов
Как видите, если ничего не агрегировать и работать с неагрегированными данными, то возможно объем вычислений даже сократится. Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Значит, если мы агрегируем данные заранее, то делать это нужно постоянно (в реальном времени), но асинхронно по отношению к запросам пользователей. Мы действительно должны просто агрегировать данные в режиме реального времени; большая часть получаемого отчета должна состоять из подготовленных данных.
Если данные не агрегируются заранее, вся работа должна выполняться в момент запроса пользователем (т. е. в ожидании загрузки страницы отчета). Это означает, что в ответ на запрос пользователя необходимо обработать многие миллиарды строк; чем быстрее это можно сделать, тем лучше.
Для этого нужна хорошая столбцовая СУБД. На рынке не было колоночно-ориентированных СУБД, которые достаточно хорошо справлялись бы с задачами интернет-аналитики в масштабах Рунета (российского интернета) и не требовали бы запредельно дорогих лицензий.
В последнее время в качестве альтернативы коммерческим столбцовым СУБД стали появляться решения для эффективной оперативной аналитики данных в распределенных вычислительных системах: Cloudera Impala, Spark SQL, Presto и Apache Drill. Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
В Яндексе мы разработали, а затем выложили в открытый доступ собственную колоночно-ориентированную СУБД — ClickHouse. Давайте рассмотрим основные требования, которые мы имели в виду, прежде чем приступить к разработке.
Возможность работы с большими наборами данных. В текущей Яндекс.Метрике для сайтов ClickHouse используется для хранения всех данных для отчетов. По состоянию на сентябрь 2017 года база данных состоит из 25,1 трлн строк. Он состоит из неагрегированных данных, которые используются для получения отчетов в режиме реального времени. Каждая строка в самой большой таблице содержит более 500 столбцов.
Система должна масштабироваться линейно. ClickHouse позволяет увеличивать размер кластера, добавляя новые серверы по мере необходимости. Например, основной кластер Яндекс. Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Высокая эффективность. Мы действительно фокусируемся на высокой производительности нашей базы данных. По результатам внутренних тестов ClickHouse обрабатывает запросы быстрее, чем любая другая система, которую мы могли бы приобрести. Например, ClickHouse работает в среднем в 2,8-3,4 раза быстрее на запросах веб-аналитики, чем одна из самых эффективных коммерческих столбцовых СУБД (назовем ее DBMS-V).
Функциональных возможностей должно быть достаточно для инструментов веб-аналитики. База данных поддерживает диалект языка SQL, подзапросы и соединения (локальные и распределенные). Существует множество расширений SQL: функции для веб-аналитики, массивы и вложенные структуры данных, функции высшего порядка, агрегатные функции для приближенных расчетов с помощью скетчинга и т. д.
д.
ClickHouse изначально разрабатывался командой Яндекс.Метрики. Кроме того, нам удалось сделать систему достаточно гибкой и расширяемой, чтобы ее можно было успешно использовать для решения различных задач. Хотя база данных может работать на больших кластерах, ее можно установить на один сервер или даже на виртуальную машину.
ClickHouse хорошо оснащен для создания всевозможных аналитических инструментов. Только подумайте: если система справится с задачами Яндекс.Метрики, можете быть уверены, что ClickHouse справится с остальными задачами с большим запасом производительности.
ClickHouse хорошо работает в качестве базы данных временных рядов; в Яндексе он обычно используется в качестве бэкенда для Graphite вместо Ceres/Whisper. Это позволяет нам работать с более чем триллионом показателей на одном сервере.
ClickHouse используется аналитикой для внутренних задач. Исходя из нашего опыта в Яндексе, ClickHouse работает примерно на три порядка выше, чем древние методы обработки данных (скрипты на MapReduce). Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
Если аналитик должен составить отчет, и он компетентен в своей работе, он не будет просто строить один отчет. Скорее, они начнут с поиска десятков других отчетов, чтобы лучше понять природу данных и проверить различные гипотезы. Часто бывает полезно посмотреть на данные под разными углами, чтобы выдвинуть и проверить новые гипотезы, даже если у вас нет четкой цели.
Это возможно только в том случае, если скорость анализа данных позволяет проводить мгновенные исследования. Чем быстрее выполняются запросы, тем больше гипотез можно проверить. Работая с ClickHouse, даже возникает ощущение, что они способны думать быстрее.
Образно говоря, в традиционных системах данные подобны мертвому грузу. Манипулировать им можно, но это занимает много времени и неудобно. Однако если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных срезах и детализировать до отдельных строк данных.
Спустя год с открытым исходным кодом ClickHouse теперь используется сотнями компаний по всему миру. Например, CloudFlare использует ClickHouse для аналитики DNS-трафика, ежедневно получая около 75 миллиардов событий. Другой пример — Vertamedia (платформа SSP для видео), которая ежедневно обрабатывает 200 миллиардов событий в ClickHouse со скоростью обработки около 3 миллионов строк в секунду.
Выводы
Яндекс.Метрика стала второй по величине системой веб-аналитики в мире. Объем данных, которые принимает Метрика, вырос с 200 миллионов событий в день в 2009 году до более чем 25 миллиардов в 2017 году. постоянно модифицировать наш подход к хранению данных.
Эффективное использование оборудования очень важно для нас. По нашему опыту, когда у вас есть большой объем данных, лучше не беспокоиться о том, насколько хорошо масштабируется система, а вместо этого сосредоточиться на том, насколько эффективно используется каждая аппаратная единица: каждое ядро процессора, диск и твердотельный накопитель, ОЗУ и сеть.