Содержание
Парсер мобильных номеров ВКонтакте | Сервис поиска аудитории ВКонтакте vk.barkov.net
Наш Сервис VK.BARKOV.NET предоставляет вам массу технических возможностей для получения доступных данных о пользователях ВКонтакте.
Если вам нужен парсер мобильных номеров ВКонтакте, пройдите по этой ссылке, введите список интересующих вас пользователей ВКонтакте в поле, а специальная функция (парсер) выдаст вам информацию о номерах мобильных телефонов, указанных на страничках пользователей ВК.
Отдельным парсером вы можете собирать и домашние номера телефонов пользователей ВК.
Обратите внимание — это будут только открытые доступные номера телефонов, указанные самими пользователями на своих страницах в блоке «Контакты».
Парсить номера, к которым привязаны аккаунты, ВК не позволяет никому.
Многие пользователи указывают мобильные телефоны также в разделе данных «Номера домашних телефонов» https://vk.barkov.net/phones.aspx
Рекомендуем парсить и в этом разделе данных тоже.
Запустить скрипт для решения вопроса
Полезный небольшой видеоурок по этой теме
О сервисе поиска аудитории ВКонтакте
vk.barkov.net — это универсальный набор инструментов, который собирает самые разнообразные данные из ВКонтакте в удобном виде.
Каждый инструмент (скрипт) решает свою задачу:
Например, есть скрипт для получения списка всех подписчиков группы.
А вот тут лежит скрипт для сбора списка всех людей, поставивших лайк или сделавших репост к конкретному посту на стене или к любым постам на стене.
Ещё есть скрипт для получения списка аккаунтов в других соцсетях подписчиков группы ВКонтакте.
И таких скриптов уже более 200. Все они перечислены в меню слева. И мы регулярно добавляем новые скрипты по запросам пользователей.
Запустить скрипт для решения вопроса
Полезные ответы на вопросы по этому же функционалу для сбора данных из ВКонтакте
Собрать мобильные номера телефонов в определенной группе ВК
Узнать номера телефонов по id ВКонтакте
Пробить номера подписчиков группы ВКонтакте
Узнать номера телефонов друзей моих друзей ВКонтакте
Как узнать номера телефонов по списку пользователей ВК?
Вывести список пользователей с именами и телефонами ВКонтакте
Поиск номеров мобильных телефонов пользователей ВК
Как собрать контакты членов сообществ ВКонтакте?
Собрать и сгруппировать ВКонтакте телефоны по странам
Парсить группы ВК на номера телефонов
Спарсить номера телефонов в группах вк
Скрипт по номерам телефонов чтоб давал имена
Есть база аккаунтов ВК, нужны их номера
Извлечь телефон подписчиков групп ВКонтакте
Нужен номер телефона ВКонтакте
Как собрать мобильные телефоны пользователей ВКонтакте?
Номер телефона по id vk
Как можно пробить номера телефонов по айди ВКонтакте?
Собрать телефоны ВК, сгруппировав по странам
Сбор номеров из группы ВК
Граббер email-адресов.
 Законно ли это и какие сервисы можно использовать
Законно ли это и какие сервисы можно использовать
Что такое парсинг
Почему в большинстве случаев парсинг — не вариант
Можно ли парсить и использовать email-адреса
Программы и сервисы для парсинга
Что в итоге
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Для запуска любой email-рассылки необходима база подписчиков. Чтобы собрать электронные адреса, можно пойти стандартным путём — вовлекать аудиторию в общение, рассказывать о потенциальной пользе, собирать контакты в обмен на что-то ценное.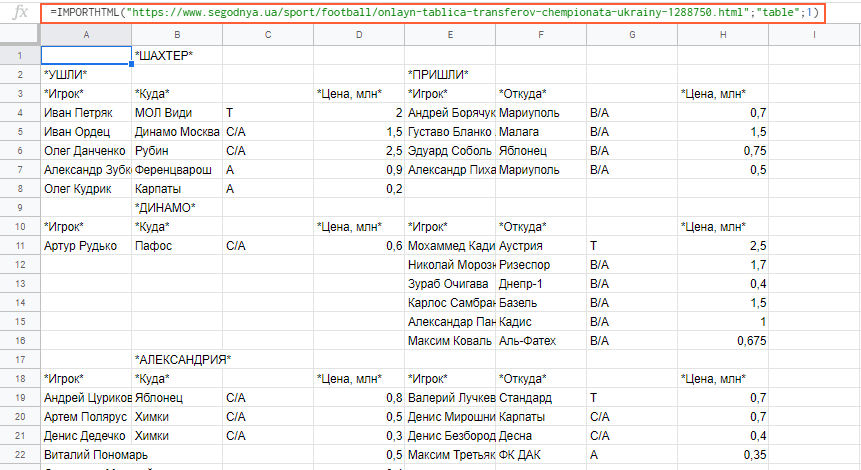 А можно использовать граббер email-адресов (парсер), который в кратчайшие сроки соберёт десятки тысяч контактов потенциальных подписчиков.
А можно использовать граббер email-адресов (парсер), который в кратчайшие сроки соберёт десятки тысяч контактов потенциальных подписчиков.
Парсер выглядит простым вариантом, но на деле все совсем непросто — особенно, если вы захотите собрать email-адреса.
Что такое парсинг
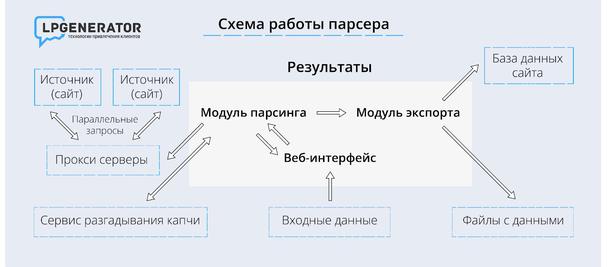
Представьте, что пользователь посещает различные сайты, копирует с них данные и сортирует их с учётом нужных критериев. Так работает парсинг, только вместо пользователей по сайтам ходят специальные роботы. Сервис-парсер обращается к страницам целевого сайта, получает HTML-код, ищет в нём нужные данные и сохраняет их в собственной базе.
Парсить можно самые разные данные. Например, можно собирать телефоны, прайсы, каталоги товаров, структуру сайтов и многое другое. В том числе можно парсить email-адреса. Для этого в настройках сервиса (или в скрипте) указывают параметры отслеживания — элементы, составляющие электронный адрес («@», «email»). Как только парсер находит совпадения, он отправляет данные в базу. По итогам парсинга пользователь получает список, состоящий из URL сайтов и собранных email.
По итогам парсинга пользователь получает список, состоящий из URL сайтов и собранных email.
Преимущества парсинга очевидны:
- сбор данных полностью автоматизирован;
- параметры поиска можно настраивать;
- можно собрать большой объём данных в кратчайшие сроки.
Применение парсинга выглядит очень удобным. Но вот с законностью есть проблемы.
Почему в большинстве случаев парсинг — не вариант
В ФЗ №149 «Об информации…» сказано, что «К общедоступной информации относятся общеизвестные сведения и иная информация, доступ к которой не ограничен». Поскольку в большинстве случаев парсер собирает открытые данные, опубликованные в общем доступе, это не запрещено законом. Но есть нюансы. Парсинг признают легальным инструментом, если он не нарушает какой-либо закон. Рассмотрим, причиной каких нарушений может стать парсинг.
Нарушение авторских и смежных прав
У любого контента в интернете есть автор или правообладатель, даже если это не указано в подписи к материалу. Нормы об авторском праве в некоторых случаях позволяют использовать чужой контент без разрешения владельца: при использовании цитирования, в информационных или образовательных целях. Однако если авторские произведения используют с целью получения дохода, видоизменяют либо присваивают авторство — это признают нарушением авторских прав. Нарушителя ждёт административный штраф.
Нормы об авторском праве в некоторых случаях позволяют использовать чужой контент без разрешения владельца: при использовании цитирования, в информационных или образовательных целях. Однако если авторские произведения используют с целью получения дохода, видоизменяют либо присваивают авторство — это признают нарушением авторских прав. Нарушителя ждёт административный штраф.
Например, нельзя парсить чужой контент и публиковать его от своего имени — это нарушение авторских прав.
Вывод
Парсинг любой информации для получения коммерческой выгоды запрещён.
Неправомерный доступ к компьютерной информации
Закон запрещает неправомерный доступ к информации, если это повлекло за собой уничтожение, блокировку, изменение или копирование сведений. Нарушителя могут оштрафовать, отправить на, исправительные или принудительные работы или лишить свободы.
Если даже парсинг никак не влияет на контент, парсер в любом случае копирует информацию. Не понятно, что понимать под неправомерным доступом. Можно предположить, что это любая попытка неавторизованного входа, когда доступ к информации ограничен, защищён или запрещён. Например, для использования сайта требуется регистрация пользователя. К незаконным методам можно отнести и обход технической блокировки парсинга.
Можно предположить, что это любая попытка неавторизованного входа, когда доступ к информации ограничен, защищён или запрещён. Например, для использования сайта требуется регистрация пользователя. К незаконным методам можно отнести и обход технической блокировки парсинга.
Вывод
Нельзя парсить данные, доступ к которым требует дополнительных действий со стороны пользователя. То есть, запрещено обходить блокировку парсинга, взламывать пароли, получать доступ к закрытым сведениям.
Использование гражданских прав для ограничения конкуренции
В законе есть такое понятие, как злоупотребление правом. Например, любой пользователь имеет право пользоваться общедоступной информацией, но только если это не вредит другим лицам. Кроме того, запрещено использовать гражданские права с целью навредить конкурентам.
Получается, что если парсинг причиняет вред конкурентам, это незаконно. Пострадавшее лицо может потребовать возместить убытки. К примеру, парсер собирает закрытые базы данных конкурирующих организаций, чтобы использовать их для обхода конкурентов.
Вывод
Нельзя использовать парсинг с целью навредить конкурентам или обрести доминирующее положение на рынке благодаря определённым сведениям.
Разглашение коммерческой тайны
Запрещено собирать сведения, которые представляют коммерческую тайну. За это могут оштрафовать, отправить на исправительные или принудительные работы и даже лишить свободы. При разглашении или использовании коммерческих сведений без согласия владельца наказание увеличивают.
Коммерческой тайной могут быть списки клиентов и поставщиков, методы сбыта, исходные коды и прочее. Основные критерии — ограниченный доступ и получение экономической выгоды от использования данных.
Вывод
Запрещено применять парсинг для доступа к закрытой коммерческой информации, даже если впоследствии эта информация не будет использована.
Незаконное обращение с персональными данными
Без разрешения владельца нельзя собирать, обрабатывать и использовать персональные данные. Причём не имеет значения то, что человек сам разместил свои данные в открытом доступе. Это не делает их общедоступными.
Причём не имеет значения то, что человек сам разместил свои данные в открытом доступе. Это не делает их общедоступными.
При парсинге бывает сложно определить, что можно считать персональными данными. По закону это любая информация, которая прямо или косвенно относится к определяемому физическому лицу. При этом не существуют унифицированного перечня видов данных. К персональной информации можно отнести любые сведения, которые позволяют идентифицировать человека.
Например, парсер собирает телефоны пользователей без ФИО. Но каждый номер закреплён за человеком по договору с оператором. Теоретически пользователя можно идентифицировать и телефонные номера можно признать персональными данными.
Вывод
Нельзя парсить персональные данные.
Приведу несколько ситуаций, в которых парсинг не запрещен и может быть полезен владельцам сайтов и маркетологам:
- Исследование рынка и анализ конкурентов. Например, чтобы узнать структуру сайта у компаний из вашей сферы.

- Поиск ошибок на собственном ресурсе. Например, чтобы найти битые ссылки или цепочки редиректов.
- Сбор семантики. Какие запросы популярны среди ваших клиентов? Какие странички на сайте нужно внедрить?
- Изучение контента. Например, чтобы узнать миссию и ценности других компаний из вашей ниши.

Можно ли парсить и использовать email-адреса
Получается, что, парсинг законом разрешён как инструмент. Но имеет значение, что именно парсить и для каких целей.
Какие email-адреса можно парсить
Не всегда ясно, можно ли признать email-адреса персональной информацией. Сам по себе адрес электронной почты — это обезличенный набор букв и цифр. По нему сложно определить конкретного владельца. Например, [email protected] или [email protected]. Такие адреса нельзя считать персональными данными и, соответственно, их можно парсить.
А вот если вместе с теми же адресами парсят ФИО владельцев, то это уже незаконный сбор персональных данных. Пример: Иван Иванов — [email protected], Маша Петрова — [email protected].
Пример: Иван Иванов — [email protected], Маша Петрова — [email protected].
Адреса электронной почты могут стать персональными данными, если в них есть информация, которая помогает идентифицировать человека: имя, фамилия, отчество, город проживания, год рождения. К примеру, [email protected], [email protected]. Парсинг таких адресов будет нарушением закона.
Ещё один нюанс в принадлежности email. В законе о персональных данных говорится о принадлежности информации физическому лицу. Соответственно, если электронный адрес принадлежит юридическому лицу, то он не признаётся персональной информацией.
То есть, если с помощью граббера собирают email-адреса компаний, даже в сочетании с названиями организаций, это не считается нарушением закона. Исключение — парсинг списков email-адресов организаций, которые составляют коммерческую тайну и/или защищены от несанкционированного доступа.
Кстати, без согласия рассылать письма компаниям можно только через личную почту. Например, можно со своей почты отправить на корпоративную почту коммерческое предложение или запрос интересующей информации. Но если делать это регулярно и большими объёмами, то легко попасть под спам-фильтры почтовых сервисов.
Например, можно со своей почты отправить на корпоративную почту коммерческое предложение или запрос интересующей информации. Но если делать это регулярно и большими объёмами, то легко попасть под спам-фильтры почтовых сервисов.
Вывод
Можно парсить email физических лиц, по которым невозможно идентифицировать владельцев. Также можно парсить электронные адреса компаний, опубликованные в открытом доступе.
Как использовать спарсенные email-адреса для рассылок
Независимо от того, можно ли считать адреса электронной почты персональными данными или нет, необходимо соблюдать правила обработки информации. Если захотите использовать email-адреса для создания базы подписчиков и запуска рассылки, нужно взять согласие владельцев.
Теоретически, можно сделать рассылку по списку спарсенных адресов и в первом письме запросить согласие владельцев. Всех согласившихся адресатов можно добавить в базу email, а проигнорировавших письмо — просто удалить. Но сервисы email-рассылок не позволят рассылать письма без согласия получателей.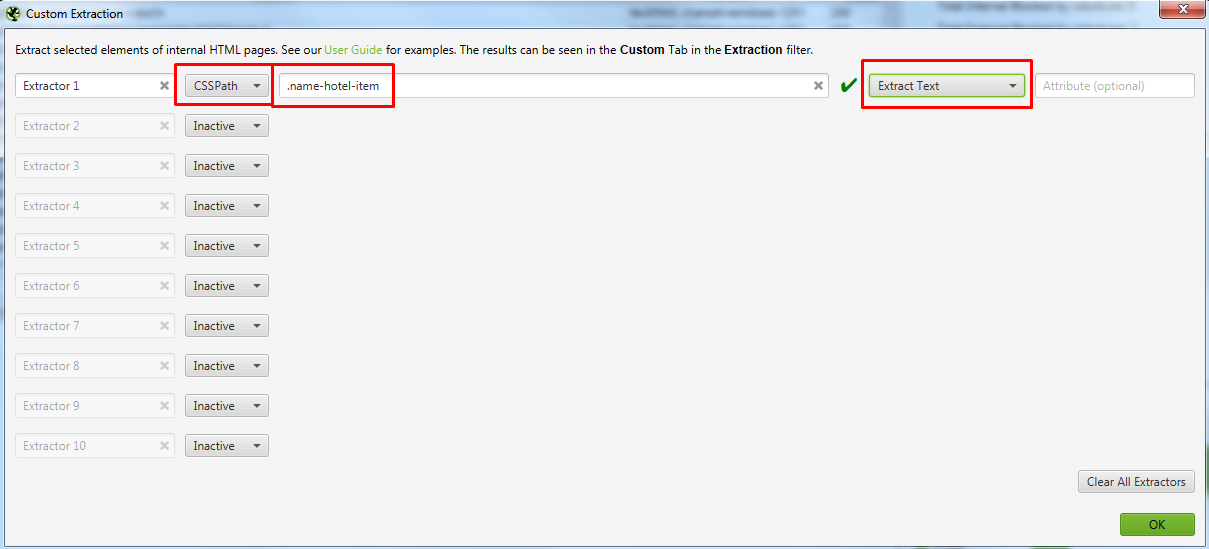 А при ручной рассылке большого объёма писем без согласия владельцев почтовые сервисы отправят сообщения в спам.
А при ручной рассылке большого объёма писем без согласия владельцев почтовые сервисы отправят сообщения в спам.
Выходом может стать отправка по спарсенным email не более 1-3 писем в день в общем и постепенное расширение легальной базы после получения согласия на рассылку. Но это потребует много времени и не факт, что адресаты принадлежат к целевой аудитории и дадут согласие. Более оптимально — применять законные способы сбора email.
Вывод
Использовать парсинг для легальных рассылок малоэффективно. Гораздо эффективнее применять законные способы сбора базы адресов. Например, через форму подписки на сайте либо предлагать подписку текущим клиентам.
Для чего ещё применяют спарсенные email кроме рассылок
Списки спарсенных email можно применять для запуска рекламы. Например, можно настроить таргетинг на потенциальных клиентов в ВКонтакте, Facebook*, Instagram* и в сети MyTarget (проекты mail.ru). Для этого список электронных адресов нужно загрузить в выбранную рекламную систему и настроить кампанию с нужными условиями.
Данный метод довольно популярен, поскольку позволяет быстро собрать аудиторию и запустить рекламную кампанию. При этом рекламные системы пока не могут проверять законность сбора email и относят этот этап к личной ответственности рекламодателя. Но в целом, такой способ использования спарсенных электронных адресов тоже нарушает закон. К тому же, таргетинг на незаинтересованных пользователей — это просто слив рекламного бюджета.
Программы и сервисы для парсинга
- Hunter — Email Finder Extension. Расширение для браузера, которое умеет извлекать электронные адреса с сайтов. Также может собирать дополнительную информацию — имя, должность, профиль в соцсети, телефон.
- EmailDrop. Программа для сбора электронных адресов с нужной веб-страницы и экспорта их в файл.
- Skrapp.io. Расширение браузера, которое ищет электронные адреса сотрудников B2B-компаний на сайтах и в Linkedin.
- Email Extractor. Бесплатный сервис, который извлекает электронные адреса из загруженного текста объёмом до 100 тысяч символов.
- Barkov.net. Сборщик email-адресов пользователей «ВКонтакте».
- Scrapebox Email Scraper. Сервис для парсинга email-адресов в разных поисковых системах, на разных сайтах и из локальных файлов. При экспорте можно сохранять URL-адрес, с которого получен email.
- LetsExtract. Программа для поиска электронных адресов в Skype, Facebook* и Twitter. Также есть поиск email по ключевым словам в разных поисковых системах. Можно просто запустить парсер на любом сайте и собрать необходимые данные.
 Бесплатный сервис, который извлекает электронные адреса из загруженного текста объёмом до 100 тысяч символов.
Бесплатный сервис, который извлекает электронные адреса из загруженного текста объёмом до 100 тысяч символов.Что в итоге
Получается, сам по себе парсинг законом разрешён. Но имеет значение, какие данные парсят и с какой целью. В частности, запрещено собирать email-адреса, если их можно признать персональными данными. Парсинг не запрещён, если объектом сбора выступают email-адреса компаний и организаций при условии отсутствия коммерческой тайны, вреда конкурентам и ограниченного доступа.
Спарсенные email-адреса нельзя использовать для запуска честной рассылки — владельцы не давали на это согласия. Электронные адреса, собранные с помощью парсинга, нередко применяют для запуска таргетированной рекламы, но и это незаконно.
Парсинг можно применять для исследования рынка, анализа конкурентов, поиска ошибок на собственном ресурсе, сбора семантики, изучения контента. Но собирать электронные адреса лучше законными методами и только с согласия владельцев.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Веб-скрапинг для извлечения контактной информации— Списки рассылки | Родриго Надер
Когда вы начинаете работать с наукой о данных и машинным обучением, вы замечаете, что есть важная вещь, которую вы чаще всего упускаете, пытаясь решить проблему: данные!
Найти нужный тип данных для конкретной задачи непросто, и, несмотря на огромное количество собранных и даже обработанных наборов данных в Интернете, много раз вам придется извлекать информацию с нуля в грязной, дикой среде. веб. Вот тут и приходит на помощь веб-скрапинг.
В течение последних нескольких недель я исследовал веб-скрапинг с помощью Python и Scrapy и решил применить его к Contact Extractor , боту, который предназначен для сканирования некоторых веб-сайтов и сбора электронных писем и другой контактной информации. какой-то поиск по тегам.
Существует множество бесплатных пакетов Python, ориентированных на веб-скрапинг, сканирование и синтаксический анализ, например Requests , Selenium и Beautiful Soup , поэтому, если хотите, найдите время, чтобы изучить некоторые из них и решить, какой из них подходит вам лучше всего. В этой статье дается краткое введение в некоторые из этих основных библиотек.
Что касается меня, то я некоторое время использовал Beautiful Soup , в основном для анализа HTML, а теперь объединил его со средой Scrapy, так как это мощная многоцелевая платформа для очистки и сканирования веб-страниц. Чтобы узнать о его функциях, я предлагаю просмотреть несколько руководств на YouTube и прочитать его документацию.
Хотя эта серия статей предназначена для работы с телефонными номерами и, возможно, другими формами контактной информации, в этой первой мы будем придерживаться только извлечения электронной почты, чтобы не усложнять задачу. Цель этого первого скребка — найти в Google множество веб-сайтов по определенному тегу, проанализировать каждый из них, ища электронные письма, и зарегистрировать их во фрейме данных.
Итак, давайте предположим, что вы хотите получить тысячу электронных писем, связанных с агентствами Real State, вы можете ввести несколько разных тегов и сохранить эти письма в файле CSV на своем компьютере. Было бы здорово помочь создать быстрый список рассылки, чтобы позже отправлять много писем одновременно.
Эта проблема будет решена в 5 шагов:
1 — Извлечение веб-сайтов из Google с помощью googlesearch
2 — Создание регулярного выражения для извлечения писем
3 — Очистите веб-сайты с помощью Scrapy Spider
4 — Сохраните эти электронные письма в файле CSV
5 — Соберите все вместе
В этой статье представлен некоторый код, но вы можете пропустить его, если хотите, Я постараюсь сделать его максимально интуитивным. Давайте пройдемся по шагам.
Давайте пройдемся по шагам.
1 — Извлечение веб-сайтов из Google с помощью
googlesearch
Чтобы извлечь URL-адреса из тега, мы будем использовать библиотеку googlesearch . Этот пакет имеет метод под названием поиск , который, учитывая запрос, количество веб-сайтов для поиска и язык, возвращает ссылки из поиска Google. Но перед вызовом этой функции давайте импортируем несколько модулей:
import logging
import os
import pandas as pd
import re
import scrapy
from scrapy.crawler import CrawlerProcess
from scrapy.linkextractors.lxmlhtml import LxmlLinkExtractor
from googlesearch import searchlogging .getLogger('scrapy').propagate = Ложь
Эта последняя строка используется, чтобы избежать слишком большого количества журналов и предупреждений при использовании Scrapy внутри Jupyter Notebook.
Итак, давайте сделаем простую функцию с search :
def get_urls(tag, n, language):
urls = [url для URL в поиске(tag, stop=n, lang=language)][:n]
return urls
Этот фрагмент кода возвращает список строк URL. Давайте проверим:
Давайте проверим:
get_urls('movie rating', 5 , 'en') Круто. Теперь этот список URL (назовем его google_urls ) будет работать как вход для нашего Spider, который будет читать исходный код каждой страницы и искать электронные письма.
2 — Создайте регулярное выражение
для извлечения электронных писем легко манипулировать текстом, искать закономерности в строках — находить, извлекать и заменять части текста — на основе последовательности символов. Например, извлечение электронных писем может быть выполнено с использованием метод findall , например:
mail_list = re.findall('\w+@\w+\.{1}\w+', html_text) Выражение ‘\w+@\w+\.{1} \w+’ , использованное здесь, может быть переведено примерно так:
«Ищите каждую часть строки, которая начинается с одной или нескольких букв, за которыми следует знак и (‘ @ ‘), за которыми следует одна или несколько букв с точкой в конце.
 После этого в нем снова должна быть одна или несколько букв».
После этого в нем снова должна быть одна или несколько букв».Если вы хотите узнать больше о регулярном выражении , на YouTube есть несколько отличных видеороликов, в том числе это введение от Sentdex, а документация поможет вам начать работу.
Конечно, приведенное выше выражение можно улучшить, чтобы избежать нежелательных сообщений электронной почты или ошибок при извлечении, но пока мы будем считать его достаточно хорошим.
3 — Парсинг веб-сайтов с помощью
Scrapy Spider
Простой Spider состоит из имени, списка URL-адресов для запуска запрашивает и один или несколько методов для анализа ответа . Наш полный Spider выглядит следующим образом:
class MailSpider(scrapy.Spider):name = 'email'
def parse(self, response):
links = LxmlLinkExtractor(allow=()).extract_links(response )
ссылок = [str(link.
links.append(str(response.url))для ссылки в ссылках:
yield scrapy.Request(url=link, callback=self.parse_link )def parse_link(self, response):
для слова в self.reject:
если слово в str(response.url):
returnhtml_text = str(response.text) mail_list = re.findall('\ w+@\w+\.{1}\w+', html_text)
dic = {'email': mail_list, 'link': str(response.url)}
df = pd.DataFrame(dic)df. to_csv(self.path, mode='a', header=False)
df.to_csv(self.path, mode='a', header=False)
 url) для ссылки в ссылках]
url) для ссылки в ссылках] Разбивая его, Spider получает список URL-адресов как вводите и читайте их исходные коды один за другим. Вы могли заметить, что мы ищем не только электронные письма внутри URL-адресов, но и ссылки. Это связано с тем, что на большинстве веб-сайтов контактную информацию можно найти не прямо на главной странице, а на странице контактов или около того. Поэтому в первом методе разбора мы запускаем объект извлечения ссылок ( LxmlLinkExtractor ), который проверяет наличие новых URL-адресов внутри источника. Эти URL-адреса передаются методу parse_link — это фактический метод, в котором мы применяем наше регулярное выражение findall для поиска электронных писем.
Эти URL-адреса передаются методу parse_link — это фактический метод, в котором мы применяем наше регулярное выражение findall для поиска электронных писем.
Приведенный ниже фрагмент кода отвечает за отправку ссылок из одного метода анализа в другой. Это достигается с помощью аргумента обратного вызова , который определяет, в какой метод должен быть отправлен URL-адрес запроса.
yield scrapy.Request(url=link, callback=self.parse_link)
Внутри parse_link мы можем отметить цикл for , используя переменную reject . Это список слов, которых следует избегать при поиске веб-адресов. Например, если я ищу tag= ‘рестораны в Рио-де-Жанейро’, , но не хочу наткнуться на страницы facebook или twitter , я мог бы включить эти слова как плохие слова при создании сайта Spider’s. процесс :
процесс = CrawlerProcess({'USER_AGENT': 'Mozilla/5. 0'})
process.crawl(MailSpider, start_urls=google_urls, path=path, reject=reject)
process.start()  0'})
0'}) Список google_urls будет передан в качестве аргумента, когда мы вызываем метод процесса для запуска паука , путь определяет, где сохранить CSV-файл, а отклонить работает, как описано выше.
Использование процессов для запуска пауков — это способ реализации Scrapy внутри Jupyter Notebooks. Если вы запускаете более одного Spider одновременно, Scrapy ускорит работу за счет многопроцессорной обработки. Это большое преимущество выбора этой структуры по сравнению с ее альтернативами.
4 — Сохраните эти электронные письма в файле CSV
Scrapy также имеет свои собственные методы для хранения и экспорта извлеченных данных, но в этом случае я просто использую свой собственный (возможно, более медленный) способ с pandas ‘ метод to_csv . Для каждого извлеченного веб-сайта я создаю фрейм данных со столбцами: [электронная почта, ссылка] и добавляю его в ранее созданный файл CSV.
Здесь я просто определяю две основные вспомогательные функции для создания нового CSV-файла, и, если этот файл уже существует, он спрашивает, хотим ли мы его перезаписать.
def ask_user(вопрос):
ответ = ввод(вопрос + 'y/n' + '\n')
если ответ == 'y':
вернуть True
иначе:
вернуть Falsedef create_file(path):
response = False
, если os.path.exists(path):
response = ask_user('Файл уже существует, заменить?')
, если response == False: вернутьс open(path, 'wb') в качестве файла:
file.close()
5 — Собираем все вместе
Наконец, мы создаем основную функцию, в которой все работает вместе. Сначала он записывает пустой кадр данных в новый файл CSV, затем получает google_urls с помощью функции get_urls и запускаем процесс выполнения нашего паука.
def get_info(tag, n, language, path, reject=[]):create_file(path)
df = pd.DataFrame(columns=['email', 'link'], index=[0])
df.print('Сбор URL-адресов Google...')
google_urls = get_urls(тег, n, язык)print('Поиск электронных писем.. .')
процесс = CrawlerProcess({'USER_AGENT': 'Mozilla/5.0'})
process.crawl(MailSpider, start_urls=google_urls, path=path, reject=reject)
process.start()print('Очистка электронной почты...')
df = pd.read_csv(path, index_col=0)
df.columns = ['электронная почта', 'ссылка']
df = df.drop_duplicates (подмножество = 'электронная почта')
df = df.reset_index (drop = True)
df.to_csv (путь, режим = 'w' , header=True)return df
 to_csv(path, mode='w', header=True)
to_csv(path, mode='w', header=True) Хорошо, давайте протестируем и проверим результаты:
bad_words = ['facebook', 'instagram', 'youtube', 'twitter', 'wiki']
df = get_info('mastering studio london', 300, 'pt', 'studios.csv', reject=bad_words)
Поскольку я позволил заменить старый файл, studios.csv был создан с результатами. Помимо сохранения данных в CSV-файле, наша последняя функция возвращает фрейм данных с очищенной информацией.
df.head()
Вот оно! Несмотря на то, что у нас есть список с тысячами электронных писем, вы увидите, что среди них некоторые кажутся странными, некоторые даже не являются электронными письмами, и, вероятно, большинство из них в конечном итоге оказываются для нас бесполезными. Поэтому следующим шагом будет поиск способов отфильтровать большую часть нерелевантных электронных писем и найти стратегии, чтобы оставить только те, которые могут быть полезны. Может быть, с помощью машинного обучения? Я надеюсь, что это так.
Это все для этого поста. Эта статья была написана как первая из серии статей с использованием Scrapy для создания Contact Extractor . Спасибо, если дочитали до конца. А пока я с удовольствием пишу свой второй пост. Не стесняйтесь оставлять любые комментарии, идеи или проблемы. И если вам понравилось, не забудьте хлопнуть ! Увидимся в следующем посте.
Контактная информация Scraper — Получите контактную информацию · Apify
Наша контактная информация Scraper может сканировать любой веб-сайт и извлекать следующую контактную информацию для лиц, перечисленных на веб-сайте:
- Адреса электронной почты
- Телефонные номера (из телефонных ссылок или извлеченные из текста)
- профилей LinkedIn
- Твиттер обрабатывает
- профилей Instagram
- профили пользователей или страницы Facebook
- аккаунтов YouTube
Сканирование контактных данных может дать вам быстрый способ получить данные о привлечении потенциальных клиентов для ваших отделов маркетинга и продаж. Сбор контактной информации может помочь вам заполнить и поддерживать актуальную базу данных лидов и потенциальных клиентов. Вместо того, чтобы вручную посещать веб-страницы и копировать и вставлять имена и номера, вы можете извлекать данные и быстро сортировать их в электронных таблицах или вводить их непосредственно в существующий рабочий процесс.
Сбор контактной информации может помочь вам заполнить и поддерживать актуальную базу данных лидов и потенциальных клиентов. Вместо того, чтобы вручную посещать веб-страницы и копировать и вставлять имена и номера, вы можете извлекать данные и быстро сортировать их в электронных таблицах или вводить их непосредственно в существующий рабочий процесс.
Ознакомьтесь с нашими отраслевыми страницами, чтобы узнать о примерах использования и других идеях о том, как вы можете воспользоваться преимуществами парсинга веб-страниц.
Следуйте нашему простому пошаговому руководству, чтобы узнать, как использовать Contact Details Scraper.
Apify ежемесячно предоставляет вам кредиты на бесплатное использование в размере 5 долларов США в рамках бесплатного плана Apify, и вы можете получить до 10 000 результатов от Contact Details Scraper за эти кредиты. Таким образом, 10 000 результатов будут совершенно бесплатными!
Но если вам нужно получать больше данных или получать их регулярно, вам следует оформить подписку на Apify. Мы рекомендуем наши $ 49/месяц Персональный план — вы можете получать до 100 000 результатов каждый месяц с ежемесячным планом за 49 долларов. Или 1 миллион результатов с тарифным планом Team за 499 долларов!
Мы рекомендуем наши $ 49/месяц Персональный план — вы можете получать до 100 000 результатов каждый месяц с ежемесячным планом за 49 долларов. Или 1 миллион результатов с тарифным планом Team за 499 долларов!
Вы должны знать, что ваши результаты могут содержать личные данные. Персональные данные защищены GDPR в Европейском Союзе и другими нормами по всему миру. Вы не должны очищать личные данные, если у вас нет законных оснований для этого. Если вы не уверены, является ли ваша причина законной, проконсультируйтесь со своими юристами. Вы также можете прочитать наш пост в блоге о законности парсинга веб-страниц.
Параметры ввода
Актер предлагает несколько параметров ввода, позволяющих указать, какие страницы будут сканироваться:
- Начальные URL-адреса — позволяет добавить список URL-адресов веб-страниц, с которых должен запускаться парсер. Вы можете ввести несколько URL-адресов, загрузить текстовый файл с URL-адресами или даже использовать документ Google Sheets.
- Максимальная глубина ссылки — указывает, насколько глубоко действующее лицо будет очищать ссылки с веб-страниц, указанных в начальных URL-адресах. Если ноль, актор игнорирует ссылки и сканирует только начальные URL-адреса.
- Оставаться в пределах домена — если этот параметр включен, актер будет переходить по ссылкам только в том же домене, что и страница перехода. Например, если этот параметр включен и актор находит на http://www.example.com/some-page ссылку на http://www.another-domain.com/, он не будет сканировать вторую страницу, потому что
www.example.comотличается отwww.another-domain.com
Актер также принимает дополнительные параметры ввода, которые позволяют указать прокси-серверы, ограничить количество страниц и т. д.
Результаты
Актор сохраняет свои результаты в наборе данных по умолчанию, связанном с запуском актора. Затем вы можете загрузить результаты в таких форматах, как JSON, HTML, CSV, XML или Excel. Для каждой просканированной страницы извлекается следующая контактная информация (показаны примеры):
Электронная почта
[email protected] [email protected] [email protected]
Телефонные номера — извлекаются из телефонных ссылок в HTML (например,
телефон).123456789 +123456789 00123456789
Неопределенные телефонные номера — они извлекаются из обычного текста веб-страницы с использованием ряда регулярных выражений. Обратите внимание, что этот подход может генерировать ложные срабатывания.
+123.456.7890 123456789 123-456-789
Профили LinkedIn
https://www.linkedin.com/in/alan-turing en.linkedin.com/in/alan-turing linkedin.com/in/alan-turing
Профили Twitter
https://www.
twitter.com/apify
twitter.com/apify
Результаты также содержат информацию об URL-адресе веб-страницы, домене, ссылающемся URL-адресе (если страница была связана с другой страницы) и глубине (насколько ссылок от начальных URL-адресов страница была найдена).
Для получения дополнительной информации щелкните вкладку ввода
Образец вывода и набора данных
Для каждой просканированной страницы результирующий набор данных содержит одну запись, которая выглядит следующим образом (в формате JSON):
{
"url": "http://www.robertlmyers.com/index.html",
"домен": "robertlmyers.com",
"глубина": 2,
"referrerUrl": "http://www.robertlmyers.com",
"электронные письма": [
"[email protected]"
],
"телефоны": [],
"телефонынеопределенные": [
"717.393.3643"
],
"ссылки": [],
"твиттеры": [],
"инстаграм": [],
"фейсбук": [
"https://www.facebook.com/robertlmyers/"
]
}
И последнее, но не менее важное: Contact Details Scraper можно подключить практически к любому облачному сервису или веб-приложению благодаря интеграции на платформе Apify.