Содержание
Авито скрыл номер телефона ЧТО ДЕЛАТЬ?
Я регулярно работаю с доской объявлений Авито и не перестаю удивляться тому, как часто они меняют свой сайт.
Но не все фишки нравятся – так и с услугой защиты номера. Как это работает и зачем это нужно и как отключить? Читайте далее.
Защита номера – зачем это надо?
В последние годы я и сам замечал такую интересную вещь – живёшь себе спокойно, никого не трогаешь, тебя тоже никто не трогает. Никто тебе не звонит и ничего не предлагает. Пока никто не знает твой номер – тебя не беспокоят:
- Агенты
- Банки
- Менеджеры по продажам
- Спамеры
- Помогаторы
- Сборщики информации для баз данных
Но вся эта лафа кончается с того момента, как только ты подаёшь какое-то объявление через Авито.
Сразу начинаются звонки, ты берёшь трубку в надежде, что это твой любимый покупатель решил посмотреть твою курточку, которую ты
- «один раз померил»
- и которая «не подошла по размеру»,
а не тут-то было!
Сначала на той стороне трубки идёт переключение телефонных линий (что доказывает, что переключают с помощью робота-дозвонщика) и через 5-10 секунд к разговору подключается приветливый, но назойливый голос.
Этот голос совсем не интересует ваша куртка (или что вы там ещё продаёте). Ему (голосу) главное – успеть за первую минуту, пока вы не готовы бросить трубку, вылить на вас ведро спама и ещё умудриться зацепить вас за святое, чтобы пригласить вас в свою клинику, на распродажу или куда-то ещё.
Короче говоря, спам – он и в Африке спам. И если вас реально бесят такие звонки и вы не готовы к их предложениям, то вариант защиты номера телефона вам как раз кстати.
Ещё по теме:
- На Авито теперь можно писать отзывы
- Как быстрее продавать на Avito
Сокрытие номера – как это работает
Фишку с режимом защиты номера от спамеров Авито разработали относительно недавно. Работает это всё предельно просто. Вместо вашего настоящего номера телефона на доске объявлений будет фэйковый номер от системы Авито. Именно его будут видеть спамеры.
Вот что предлагает Avito:
- Звонки от покупателей будут автоматически переадресованы на ваш обычный номер.

- Пользователи не смогут отправлять вам смс и писать в Viber, WhatsApp и другие мессенджеры.
- Сообщения на Авито будут приходить как и раньше.

На этапе подачи объявления вы можете выбрать это пункт:
Подключение защиты номера Авито
Как отключить подмену номера Авито
Если вам захочется вернуть всё назад – вы легко сможете это сделать, отредактировав настройки или при подаче объявления отменив галочку напротив пункта о «защищенном номере».
Однако в последнее время пользователи жалуются, что не могут выключить эту функцию — и вот что пишет Авито:
как убрать подмену номера на Авито
Однако есть ещё один интересный вариант для защиты.
Альтернативный способ спрятать номер на Авито
Про этот вариант не все в курсе, однако он уже встречается и особо продвинутые юзеры им активно пользуются. Ведь, что ни говори, а предыдущий метод защиты номера – это использование переадресации от мобильных операторов и доверия им не всегда достаточно.
По тому же закону Яровой они обязаны собирать и хранить все наши телефонные разговоры. А не всем этого хочется – итак государство о нас знает почти всё!
Здесь вы можете узнать: кто следит за вами через телефон.
Короче, есть более простой способ защитить свой номер на доске объявлений – для связи оставлять только сообщения Авито:
Выбор способа связи на Авито
Подключается эта фича достаточно просто – всё там же на этапе подачи объявления выбираете соответствующий пункт для способа связи:
- По телефону и в сообщениях
- По телефону
- В сообщениях
Если не хотите светить своим номером – смело жмите напротив пункта «в сообщениях» и тогда для связи с вами потенциальные покупатели будут предварительно писать вам текстовые вопросы в личку. А уже там вы сможете дать свой номер тем, кому вы пожелаете сами.
Однако не для всех категорий пока эта фишка доступна.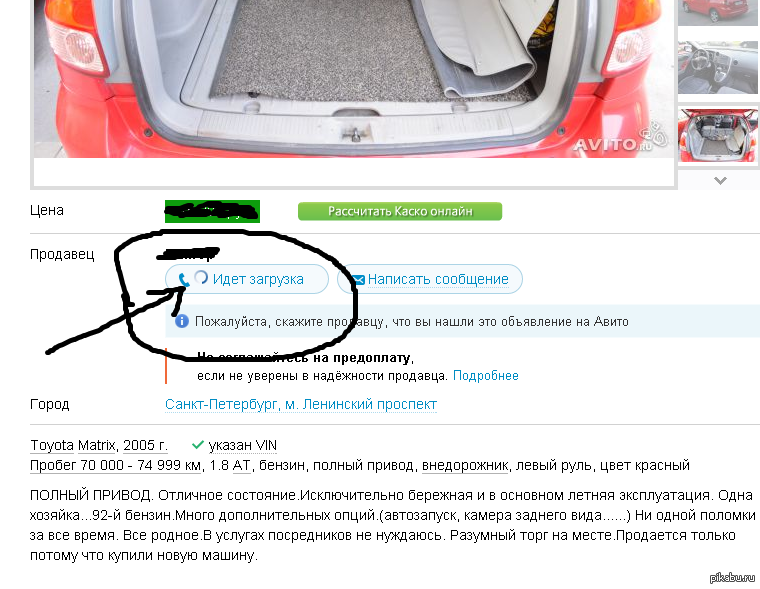 Например в разделе «недвижимость» нельзя выбрать этот пункт.
Например в разделе «недвижимость» нельзя выбрать этот пункт.
А как вам эта функция подмены номера телефона? Давайте обсуждать в комментах.
Оплата за просмотры на Авито: как работает этот тариф
В 2022 год Авито изменил модель оплаты продвижения товаров. Если раньше продавец платил за размещение объявлений на площадке, то сейчас — за их просмотры, то есть за переходы на страницу объявления из результатов поиска. Как работает новая модель оплаты и чем она отличается от предыдущей, разбираемся в этом материале.
Авито — крупнейший в мире, по данным SimilarWeb, сайт с объявлениями. Ежемесячно его посещают более 80 млн человек. Здесь могут продавать товары и услуги как физлица, так и компании. Около половины российских компаний малого и среднего бизнеса уже продвигают свои предложения на Авито.
В этом материале поговорим:
-
как была устроена оплата за размещение до 2022 года
-
как работает новая модель оплаты
-
почему и кому выгодна оплата за просмотры объявлений
-
как продавцу подключить новый тариф
-
что поможет увеличить количество просмотров объявлений
Получайте до 8% от оборота клиентов на Авито
Продвигайте клиентов на Авито и возвращайте до 8% от их оборотов на площадке. Только для участников партнерской программы eLama
Только для участников партнерской программы eLama
Узнать больше
Основной моделью оплаты на Авито для продавцов товаров до 2022 года была оплата за размещение: компания покупала определенное количество объявлений, и в течение 30 дней они появлялись в результатах поиска на площадке. Стоимость продвижения зависела от количества объявлений: чем их больше, тем дешевле размещение каждого из них.
Продавец мог подключить один из трех наборов инструментов: Базовый, Расширенный и Максимальный. Бесплатный «Базовый» тариф открывал доступ к кабинету Авито Pro с расширенной статистикой и возможности подключить пять сотрудников к аккаунту компании. Самый полный — «Максимальный» — включает более 15 инструментов.
А чтобы получать больше заказов и заявок, компания могла добавить опции продвижения. Они подсвечивают цену товара в объявлении, повышают количество показов и увеличивают размер объявления, добавляя в него больше фотографий и информации.
Однако основное, за что нужно было платить рекламодателю, — это возможность загрузить товары на площадку и показывать их в поисковой выдаче.
Оплата за просмотры — новый тариф на Авито. Работая с ним, продавец платит только за уникальный просмотр объявлений. Таким просмотром считается первый за день переход пользователя на страницу объявления. Если в течение дня он еще несколько раз зайдет в объявление, переходы будут бесплатными для продавца, как и сама публикация объявлений и их показы в результатах поисковой выдачи Авито.
Источник: Авито
Авито переходит на оплату за просмотры с весны 2022 года, и уже сейчас продавцы всех категорий в «Товарах» и в некоторых «Услугах» не могут оплачивать размещение. Список категорий постепенно расширяется.
А точно продавец оплачивает только уникальные просмотры?
Да, продавец на Авито не платит за повторные и недобросовестные просмотры, а также действия ботов. Для этого площадка проверяет каждый просмотр по ряду параметров и оценивает:
- Кто открыл объявление: человек или робот, — анализируя время, географию, данные о пользователе и другие характеристики, список которых постоянно расширяется;
- Целевой ли это просмотр, то есть действительно ли пользователь интересуется покупкой или просто кликает из злого умысла. В этом случае система анализирует поведение пользователя, например, какие объявления он смотрел и сколько времени на них провел.
 В этом случае система анализирует поведение пользователя, например, какие объявления он смотрел и сколько времени на них провел.
В этом случае система анализирует поведение пользователя, например, какие объявления он смотрел и сколько времени на них провел.
В результате проверок — параметров более 250, утверждает Авито, — система понимает, кто просмотрел объявление, а продавец оплачивает только целевые просмотры.
Как происходит оплата показов
Деньги списываются с баланса Авито каждый день раз в час. Если сумма достигает порога снятия, Авито уведомляет продавца и приостанавливает размещение объявлений, а после пополнения аванса — возобновляет показы и активирует объявления на 30 дней.
Стоимость просмотра в каждой категории разная, минимальная — 0,4 ₽, средняя — 1 ₽.
Какие инструменты доступны с новым тарифом
С оплатой за просмотры объявлений по умолчанию работает базовый набор инструментов:
- оформление объявлений: выделение текста жирным шрифтом или курсивом, использование списков;
- профессиональный кабинет Авито Pro с расширенной статистикой;
- планирование услуг продвижения;
- подключение сотрудников, которые смогут работать с объявлениями, отвечать на сообщения и звонки;
- коллтрекинг для отслеживания и анализа звонков.

Чтобы получить доступ к другим инструментам, нужно купить расширенный или максимальный пакет — он будет действовать 30 дней. Платные инструменты помогут настроить страницу компании на Авито, скрыть конкурентов в своих объявлениях и привлечь внимание покупателей.
Какие услуги продвижения доступны с новым тарифом
К объявлениям с тарифом за показы можно подключить любые услуги продвижения на Авито:
-
Увеличение просмотров: компания выбирает, во сколько раз и в течение какого периода нужно повысить количество показов объявления. В настройках можно выбрать силу продвижения (до 2, 5, 10, 15 или 20 раз) и длительность действия (на 1 или на 7 дней).
-
Выделение цветом цены на десктопе и в приложении и названия объявления на мобильных устройствах.
Источник: Авито -
Увеличение размера. В объявлении появится галерея фотографий, дополнительный текст, заметная кнопка для связи, а сама карточка станет больше.

Подробнее о том, как сделать объявление заметнее и качественнее, читайте в нашем материале.
Главное преимущество нового тарифа — нет ограничений в количестве объявлений. Продавец может загрузить на Авито весь свой ассортимент, доступный к заказу. Кроме того, он теперь не рискует потратить деньги на безрезультатное размещение объявлений, например, в период внезапного снижения спроса.
О том, как новая оплата улучшила результаты продвижения — читайте в двух кейсах.
Однако эта модель оплаты не выгодна для недобросовестных продавцов, которые демпинговали цены и продавали подделки: как правило, их объявления получали много кликов, и за них теперь придется. Они либо уйдут, либо начнут размещать качественные товары с реальными ценами, что выровняет условия для всех игроков.
Поскольку переход Авито на оплату за просмотры уже завершился, новые продавцы товаров в любой категории теперь сразу начинают работу с новой моделью.
Если у вас до сих пор работает оплата за размещение, то, чтобы подключить оплату за просмотры, нужно перейти на вкладку «Для профессионалов» и настроить тариф. Здесь понадобится указать сумму аванса, а затем перевести ее с баланса eLama.
Здесь понадобится указать сумму аванса, а затем перевести ее с баланса eLama.
Важно, что с баланса eLama можно перевести деньги только на аккаунты, зарегистрированные из кабинета сервиса, и нельзя — на аккаунты, зарегистрированные не через eLama. Как создать аккаунт Авито через eLama, читайте в справочном центре.
После подключения нового тарифа все активные объявления перейдут на оплату за просмотры, а услуги продвижения, если они были активированы, продолжат работать.
При этом оставшиеся в оплаченном тарифе размещения сгорят. Авито рекомендует потратить их до конца действия тарифа с оплатой за размещения, а потом перейти на новый тариф.
Число просмотров объявлений зависит от многих факторов. На некоторые из них продавцы не могут повлиять, например, сезонность, обстановка в мире и стране, активность конкурентов. Однако есть и такие, которыми продавец может управлять, среди них:
- Заголовок объявления. От него зависит, по каким запросам будет показываться объявление. Заголовок должен быть подробным и понятно описывать продукт, но при этом не содержать лишней информации, вроде региона и цены — для них есть отдельные настройки.
- Фотография. Она привлекает внимание пользователя в выдаче и должна быть четкой, контрастной и качественно отличаться от фотографий конкурентов.
- Цена товара должна соответствовать рынку: слишком низкая может вызвать сомнения и отпугнуть покупателя, а высокая — заставит уйти к конкурентам.
- Услуги продвижения пригодятся, если в тематике много конкурентов. Они помогут увеличить количество показов в выдаче и сделают объявление заметнее.
 Заголовок должен быть подробным и понятно описывать продукт, но при этом не содержать лишней информации, вроде региона и цены — для них есть отдельные настройки.
Заголовок должен быть подробным и понятно описывать продукт, но при этом не содержать лишней информации, вроде региона и цены — для них есть отдельные настройки.
Почему и как мы скрываем госномера в рекламе Авито / Блог компании Авито / Хабр
Эй. В конце прошлого года мы начали автоматически скрывать номера автомобилей на фотографиях в карточках объявлений Авито. О том, почему мы так поступили, и какие есть способы решения подобных проблем, читайте в статье.
Задача
На Авито в 2018 году было продано 2,5 млн автомобилей. Это почти 7000 в день. Все объявления о продаже нуждаются в иллюстрации — фото автомобиля. Зато по госномеру на нем можно найти много дополнительной информации об автомобиле. А некоторые наши пользователи пытаются закрыть номерной знак самостоятельно.
Причины, по которым пользователи хотят скрыть номерной знак, могут быть разными. Со своей стороны, мы хотим помочь им защитить свои данные. И мы стараемся улучшить процессы купли-продажи для пользователей. Например, у нас уже давно работает услуга анонимного номера: когда вы продаете машину, для вас создается временный сотовый номер. Ну а чтобы защитить данные о номерных знаках, мы анонимизируем фотографии.
Обзор решения
Для автоматизации процесса защиты фотографий пользователей можно использовать сверточные нейронные сети для обнаружения полигона с номерным знаком.
Сейчас для обнаружения объектов используются архитектуры двух групп: двухэтапные сети, например Faster RCNN и Mask RCNN; одноэтапные (singleshot) — SSD, YOLO, RetinaNet. Обнаружение объекта — это вывод четырех координат прямоугольника, в который вписан интересующий объект.
Упомянутые выше сети умеют находить на картинках множество объектов разного класса, что уже избыточно для решения задачи поиска номеров, т. сфотографировать свою проданную машину и ее случайного соседа, но это случается довольно редко, так что этим можно было бы пренебречь).
Еще одна особенность этих сетей заключается в том, что по умолчанию они создают ограничивающую рамку со сторонами, параллельными осям координат. Это происходит потому, что для обнаружения используется набор предопределенных типов прямоугольных рамок, называемых якорными блоками. Точнее, сначала с помощью сверточной сети (например, resnet34) из картинки получается матрица атрибутов. Затем для каждого подмножества атрибутов, полученных с помощью скользящего окна, происходит классификация: есть объект для k-якоря или нет, и выполняется регрессия в четыре координаты кадра, корректирующие его положение.
Подробнее об этом читайте здесь.
После этого идут еще две головки:
одна для классификации объекта (собака/кошка/растение и т.д.),
вторая (bbox регрессор) — для регрессии координат кадра полученное на предыдущем шаге, чтобы увеличить отношение площади объекта к площади кадра.
Чтобы предсказать повернутую рамку бокса, вам нужно изменить регрессор bbox так, чтобы вы также получили угол поворота рамки. Если этого не сделать, то как-нибудь получится.
Помимо двухэтапного Faster R-CNN, существуют одноэтапные детекторы, такие как RetinaNet. Отличается от предыдущей архитектуры тем, что сразу предсказывает класс и кадр, без предварительного этапа предложения участков картинки, которые могут содержать объекты. Чтобы предсказать повернутые маски, вы также должны изменить заголовок подсети блока.
Одним из примеров существующих архитектур для прогнозирования повернутых ограничивающих рамок является DRBOX. В этой сети не используется предварительная стадия предложения региона, как в Faster RCNN; следовательно, это модификация одностадийных методов. Для обучения этой сети используется K, повернутый на определенные углы ограничивающий прямоугольник (rbox). Сеть предсказывает вероятности для каждого из K rbox содержать целевой объект, координаты, размер bbox и угол поворота.
Для обучения этой сети используется K, повернутый на определенные углы ограничивающий прямоугольник (rbox). Сеть предсказывает вероятности для каждого из K rbox содержать целевой объект, координаты, размер bbox и угол поворота.
Модификация архитектуры и переобучение одной из рассмотренных сетей на данных с повернутыми ограничительными рамками — выполнимая задача. Но наша цель может быть достигнута более легко, потому что область применения сети у нас гораздо уже — только для того, чтобы скрыть номерные знаки.
Поэтому мы решили начать с простой сети для предсказания четырех точек числа, а в последующем можно будет усложнить архитектуру.
Данные
Сборка набора данных разбита на два этапа: собрать фотографии автомобилей и отметить на них область с номерным знаком. В нашей инфраструктуре уже решена первая задача: мы бережно храним все объявления, которые когда-либо размещались на Авито. Для решения второй задачи используем Толоку. На toloka.yandex.ru/requester создаем задачу:
На toloka.yandex.ru/requester создаем задачу:
В задании дается фотография автомобиля. Необходимо выделить номерной знак автомобиля с помощью четырехугольника. При этом государственный номер должен быть присвоен максимально точно.
В Толоке можно создавать задания на разметку данных. Например, оценить качество результатов поиска, разметить разные классы объектов (тексты и картинки), разметить видео и т.д. Их будут выполнять пользователи Толоки, за взимаемую вами плату. Например, в нашем случае толокеры должны выделить на фото свалку с номером автомобиля. В целом, это очень удобно для разметки большого набора данных, но получить высокое качество довольно сложно. В толпе много ботов, задача которых получить от вас деньги, давая ответы случайным образом или используя какую-то стратегию. Для противодействия этим ботам существует система правил и проверок. Основная проверка — смешивание контрольных вопросов: вы вручную размечаете часть заданий с помощью интерфейса Толоки, а затем подмешиваете их в основное задание.
Для задачи классификации очень просто определить, неправильная маркировка или нет, а для задачи выделения области не так просто. Классический способ — подсчет IoU.
Если это соотношение меньше определенного порога для нескольких задач, то такой пользователь блокируется. Однако для двух произвольных четырехугольников вычислить IoU не так просто, тем более что в Толоке это необходимо реализовать на JavaScript. Мы сделали небольшой хак, и считаем, что пользователь не ошибся, если для каждой точки исходного полигона в небольшой окрестности есть точка, отмеченная писцом. Также есть правило быстрого ответа для слишком быстрой блокировки реагирующих пользователей, капчи, несовпадения с мнением большинства и т.д. Настроив эти правила можно рассчитывать на довольно неплохую разметку, но если вам действительно нужна качественная и сложная разметка, вам нужна специально нанимать фрилансеров-переписчиков. В итоге наш датасет составил 4к размеченных изображений, и все это стоило на Толоке 28$.
Модель
Теперь давайте создадим сеть для предсказания четырех точек области. Мы получим признаки с помощью resnet18 (11,7M параметров против 21,8M параметров для resnet34), затем сделаем голову для регрессии на четыре точки (восемь координат) и голову для классификации есть ли на картинке номерной знак или нет. Вторая голова нужна, т.к. в объявлениях о продаже авто не все фото с машинами. На фото может быть деталь автомобиля.
Таких, как мы, конечно, не надо обнаруживать.
Проводим обучение двух целей одновременно, добавляя в набор данных фото без номерного знака с ограничивающей рамкой (0,0,0,0,0,0,0,0,0) цель и значение для классификатора «картинка с/без госномера» — (0, 1).
Затем можно создать единую функцию потерь для обеих целей как сумму следующих потерь. Для регрессии к координатам полигона номерного знака используем гладкую потерю L1.
Его можно интерпретировать как комбинацию L1 и L2, которая ведет себя как L1, когда абсолютное значение аргумента велико, и как L2, когда значение аргумента близко к нулю.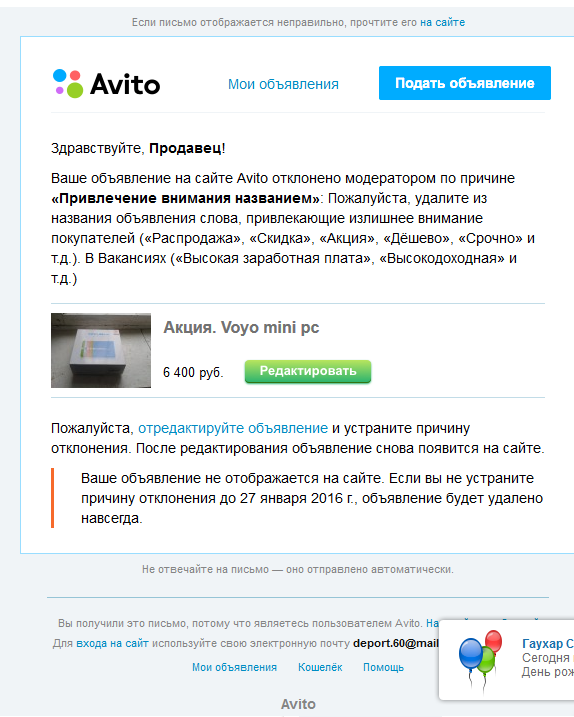 Для классификации мы используем softmax и кроссэнтропийные потери. Экстрактор функций — resnet18, мы используем веса, предварительно обученные в ImageNet, затем мы будем дополнительно обучать экстрактор и головы на нашем наборе данных. В этой задаче мы использовали фреймворк mxnet, так как он является основным для компьютерного зрения в Авито. В целом, микросервисная архитектура позволяет не привязываться к конкретному фреймворку, но когда у вас большая кодовая база, лучше использовать ее и не писать один и тот же код еще раз.
Для классификации мы используем softmax и кроссэнтропийные потери. Экстрактор функций — resnet18, мы используем веса, предварительно обученные в ImageNet, затем мы будем дополнительно обучать экстрактор и головы на нашем наборе данных. В этой задаче мы использовали фреймворк mxnet, так как он является основным для компьютерного зрения в Авито. В целом, микросервисная архитектура позволяет не привязываться к конкретному фреймворку, но когда у вас большая кодовая база, лучше использовать ее и не писать один и тот же код еще раз.
Получив на нашем датасете приемлемое качество, мы обратились к дизайнерам за получением нам номерного знака с логотипом Авито. Сначала мы пытались сделать это сами, конечно, но выглядело это не очень красиво. Далее нужно изменить яркость номерного знака Авито на яркость оригинальной области с номерным знаком и можно наложить логотип на изображение.
Запуск в производство
Проблема воспроизводимости результатов, поддержки и развития проектов, решенная с некоторой погрешностью в мире backend- и frontend-разработки, остается открытой там, где требуется использование моделей машинного обучения. Вы, вероятно, должны были понять устаревшую модель кода. Хорошо, если в ридми есть ссылки на статьи или репозитории с открытым исходным кодом, на которых основывалось решение. Скрипт запуска переобучения может завершаться с ошибками, например, изменилась версия cudnn, и та версия tensorflow больше не работает с этой версией cudnn, а cudnn не работает с этой версией драйверов nvidia. Возможно, для обучения мы использовали один итератор по данным, а для тестирования в продакшене другой. Это может продолжаться довольно долго. В общем, проблемы с воспроизводимостью существуют.
Вы, вероятно, должны были понять устаревшую модель кода. Хорошо, если в ридми есть ссылки на статьи или репозитории с открытым исходным кодом, на которых основывалось решение. Скрипт запуска переобучения может завершаться с ошибками, например, изменилась версия cudnn, и та версия tensorflow больше не работает с этой версией cudnn, а cudnn не работает с этой версией драйверов nvidia. Возможно, для обучения мы использовали один итератор по данным, а для тестирования в продакшене другой. Это может продолжаться довольно долго. В общем, проблемы с воспроизводимостью существуют.
Пробуем удалить их с помощью среды nvidia-docker для обучения моделей, в ней есть все необходимые зависимости для cuda, туда же устанавливаем зависимости для python. Версия библиотеки с итератором по данным, аугментациям и моделям вывода является общей для этапа обучения/экспериментирования и для производства. Таким образом, чтобы обучить модель на новых данных, нужно закачать репозиторий на сервер, запустить шелл-скрипт, который соберет докер-окружение, внутри которого поднимется блокнот jupyter. Внутри у вас будут все блокноты для обучения и тестирования, которые уж точно не вылетят с ошибкой из-за окружения. Лучше, конечно, иметь один файл train.py, но практика показывает, что всегда нужно смотреть глазами на то, что дает модель, и что-то менять в процессе обучения, поэтому в итоге вы все равно будете запускать jupyter.
Внутри у вас будут все блокноты для обучения и тестирования, которые уж точно не вылетят с ошибкой из-за окружения. Лучше, конечно, иметь один файл train.py, но практика показывает, что всегда нужно смотреть глазами на то, что дает модель, и что-то менять в процессе обучения, поэтому в итоге вы все равно будете запускать jupyter.
Веса моделей хранятся в git lfs — это специальная технология для хранения больших файлов в git. До этого мы использовали артефакторы, но использовать git lfs удобнее, т.к. скачав репозиторий с сервисом, вы сразу получаете текущую версию весов, как на продакшене. Автотесты написаны для вывода моделей, поэтому вы не сможете выкатить сервис с весами, которые их не проходят. Сам сервис запускается в докере внутри микросервисной инфраструктуры на кластере kubernetes. Для мониторинга производительности мы используем grafana. После прокатки мы постепенно увеличиваем нагрузку на инстансы сервиса с новой моделью. При выкатывании новой фичи мы создаем а/б тесты и выносим вердикт о дальнейшей судьбе фичи на основе статистических тестов.
В итоге: запустили сглаживание номеров на объявлениях в категории авто для частников, 95-й процентиль времени обработки одного изображения для скрытия номера 250 мс.
Контроль версий данных в Инфомодели Авито | Максим Ланин | AvitoTech
Инфомодель — система управления метаданными Avito. Он управляет классификацией объявлений, таксономией и каталогами объявлений. В нашем недавнем посте мы рассказывали, как мы с этим справляемся: зачем нужна Инфомодель и как она взаимодействует с остальными системами Авито.
Сегодня я затрону не менее важный вопрос работы с данными — подготовку изменений и развертывание в продакшене.
В 2017 году, когда мы начали работу над проектом «Инфомодель», Avito поддерживал по сути две среды — prod и dev. Все данные Infomodel хранились в базе данных. Не было никаких интерфейсов или процессов для модификации данных, все правки в код вносились миграциями. Раньше мы кодировали миграции SQL в основном репозитории нашего монолита, добавляя новые записи в таблицы по мере необходимости или изменяя их. При развертывании миграции выполнялись командой администраторов баз данных в prod или автоматически развертывались в dev.
При развертывании миграции выполнялись командой администраторов баз данных в prod или автоматически развертывались в dev.
Но возникла скрытая проблема: что делать, если ваша фича еще не готова? Что делать, если вам нужно добавить изменения, которые повлияют на работу других? Чтобы новые изменения не вызывали проблем, мы использовали столбец is_active (bool) при извлечении данных из базы данных. В качестве иллюстрации приведем таблицу категорий:
Чтобы получить из нее данные для построения, скажем, дерева категорий, мы сделали простой SELECT запрос следующего вида:
SELECT * FROM Categories WHERE is_active = true;
Если мы хотели добавить новую категорию и скрыть ее на некоторое время, мы создали миграцию, в которую вставили новую строку и установили ее is_active в false . После развертывания кода в среде dev миграция запустилась автоматически и добавила новую строку:
В бэкенде нам пришлось обновить запрос, добавив в него следующее:
SELECT * FROM Categories WHERE is_active = true OR category_id = 3;
Таким образом, у нас появилась новая категория в нашей локальной сборке, но другие не смогли увидеть изменения. Затем мы закончили задачу и удалили
Затем мы закончили задачу и удалили ИЛИ . Группа администраторов баз данных заменила is_active на true при последующем развертывании в рабочей среде.
Вносить частые изменения без привлечения разработчиков каждый раз при таком подходе невозможно, особенно если речь идет о параллельных или совместных изменениях.
Но компания растет, диктует необходимость все более частых изменений, что же делать?
Когда мы проектировали архитектуру первой версии Infomodel, мы поставили перед собой требование дать бизнесу возможность быстро вносить изменения в Infomodel. И, главное, внести изменения, чтобы команды Авито не блокировали работу друг друга.
В итоге мы придумали довольно элегантное и эффективное решение, позволяющее командам:
- работать с данными параллельно;
- выпускайте изменения всякий раз, когда они к этому готовы;
- тестировать изменения на лету;
- знать, кто и когда вносил какие-либо изменения;
- видеть разницу между своими изменениями и тем, что сейчас находится в производстве.
Мы назвали это решение «Контроль версий Infomodel». На что это похоже?
Ставим Git поверх Postgres. Любой, кто работает с Infomodel, работает в изолированной ветке. В ветке можно что угодно изменить — удалить категорию или создать сотню новых.
Все ответвления выполняются из одной общей производственной ветви с именем master , которую нельзя изменить напрямую. С точки зрения интерфейса введение новых веток выглядит так:
У нас есть три разных типа веток. Различия между ними связаны с процессом выпуска, который стоит обсудить, как ветвление работает под капотом.
Одной из задач, которые мы ставили перед собой при разработке технической составляющей контроля версий, была простота и легкая отладка происходящего с ветками.
Схема данных
Чтобы обеспечить изоляцию ветвей друг от друга, мы реализовали ветвление на уровне схемы Postgres. Каждая ветвь представляет собой отдельную схему с тем же набором необходимых таблиц и записей, что и основная. При создании новой ветки мы дублируем всю основную схему. Пользователи работают со своими снимками данных, не мешая другим.
При создании новой ветки мы дублируем всю основную схему. Пользователи работают со своими снимками данных, не мешая другим.
Конечно, пришлось создать отдельную схему для хранения служебной информации, такой как список филиалов и схем, список пользователей и т.д. Есть отдельная 9Схема метаданных 0103 , содержащая необходимый набор таблиц, поддерживающих механизмы Infomodel.
Первая задача выполнена : пользователи могут вносить параллельные изменения в данные без конфликтов.
Но вот первая проблема, с которой мы столкнулись — первичные ключи. При создании новых записей пользователи также создавали новые строки в таблицах с автоинкрементом PK. Добавив две разные записи в две разные схемы, они получили одинаковые ключи, что сделало всю схему бесполезной. Мы переместили все последовательности в схему метаданных и разделили их между схемами ветвей. Это решило проблему, предотвратив идентичные идентификаторы.
Управление изменениями
Подобно Git, мы сохраняем все изменения, сделанные пользователем. Для этого в каждой схеме (включая master) есть служебная таблица с именем
Для этого в каждой схеме (включая master) есть служебная таблица с именем changelog . В этой таблице хранятся записи по каждому изменению в текущей ветке:
Как видно из таблицы, мы знаем, кто что делал, когда и с какой сущностью. В результате пользователь всегда может увидеть в интерфейсе список своих изменений или найти и отладить чужие:
Представим, что пользователь хочет удалить категорию. Сама категория и все связанные с ней атрибуты будут удалены за один шаг. И на одно действие пользователя будет создано несколько записей в журнале изменений. Чтобы объединить эти записи, мы ввели batch_hash (строка) свойство. Используя его, мы можем идентифицировать все изменения, внесенные в базу данных, в рамках одного и того же действия пользователя. Мы также можем откатить изменения одно за другим, используя его.
Таким образом мы достигли еще двух вещей — мы видим все изменения и видим разницу.
Развертывание изменений в рабочей среде
Тот факт, что мы сохраняем все изменения, позволяет нам объединять ветки. Точный процесс выпуска изменений в продакшн, как было сказано выше, есть не что иное, как блокировка ветки для изменений и применение записей из журнала изменений одна за другой к сущностям в
Точный процесс выпуска изменений в продакшн, как было сказано выше, есть не что иное, как блокировка ветки для изменений и применение записей из журнала изменений одна за другой к сущностям в мастер-ветвь , откуда они развертываются в производство.
Мы позволяем пользователям самим решать когда они будут готовы отправить свои изменения в продукт.
Создание веток с именем, начинающимся с номера задачи Jira, позволяет отличать ветки друг от друга и связывать изменения в инфомодели с внешними изменениями. Мы знаем, какие PR были сделаны в рамках задачи и прошли ли они испытания. Если нет, мы предотвращаем выпуск изменений.
После запуска релиза мы запускаем еще несколько тестовых сборок, прежде чем объединять изменения. Таким образом, продуктовые команды могут быть уверены, что изменение ничего не сломает.
Задержка ветки
После добавления изменений из одной ветки в prod остальные активные ветки автоматически блокируются для выпуска.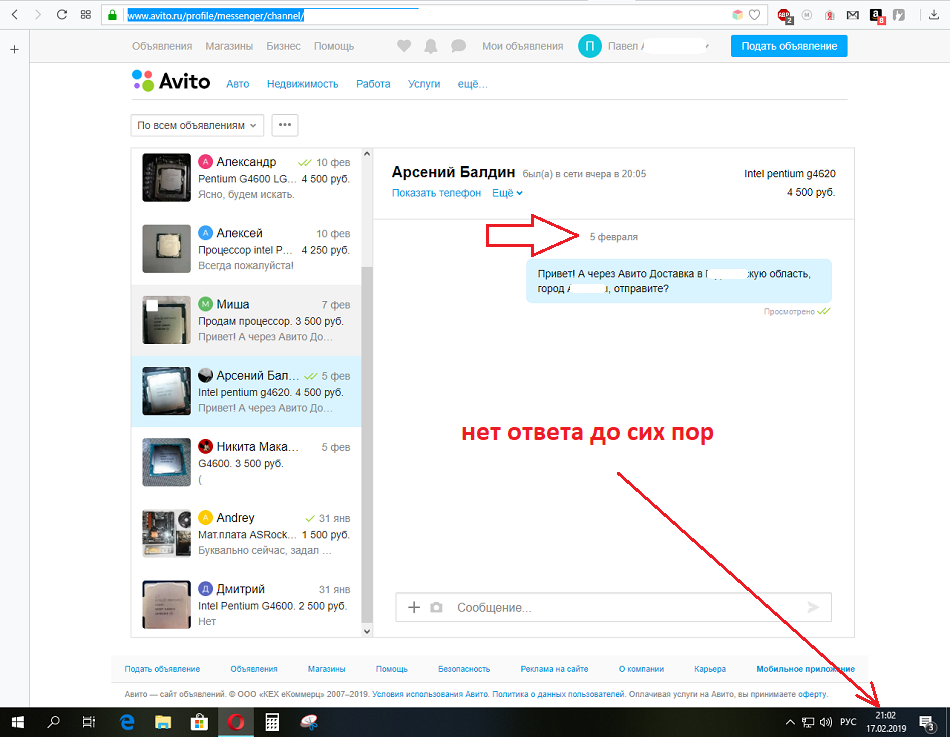 Пользователи могут вносить изменения, но не могут их выпускать, потому что владелец ветки не видит всей обновленной картины.
Пользователи могут вносить изменения, но не могут их выпускать, потому что владелец ветки не видит всей обновленной картины.
Чтобы это исправить, пользователь может одним кликом загрузить мастер в свою ветку. Под капотом мы создадим еще одну чистую схему из мастера и загрузим все изменения из предыдущей ветки, которые сделал пользователь. Механизм аналогичен git перебазировать .
Но и здесь есть свои подводные камни. Что делать, если в master были добавлены изменения, удаляющие часть сущностей, с которыми пользователь работал в своей ветке? В схеме пользователя будут строки, которые ссылаются на несуществующие записи через внешний ключ.
Для решения таких проблем у нас есть инструмент, известный как Сборщик мусора . Задача сборщика мусора — следить за тем, чтобы в ветке пользователя все было согласованно, и удалять записи, ссылающиеся в никуда. Он запускается после каждой загрузки на мастер. По завершении инструмент отправляет пользователю уведомление в Slack об успешном завершении операции. Изменения, внесенные сборщиком мусора, отмечены цифрой 9.0103 is_auto (bool) свойство в журнале изменений и может быть найдено в пользовательском интерфейсе с помощью фильтра.
Изменения, внесенные сборщиком мусора, отмечены цифрой 9.0103 is_auto (bool) свойство в журнале изменений и может быть найдено в пользовательском интерфейсе с помощью фильтра.
Прежде чем опубликовать изменения, пользователь может захотеть посмотреть, как они выглядят на Авито. Для этого пользователь может создать тестовый стенд для нашего монолита или ее конкретного сервиса и запустить его ветку. Это позволит серверной части переключиться с master на данную ветку и показать результат пользователю.
Таким образом, мы рассмотрели последний пункт в спецификациях, т.е. тестирование наших изменений на лету.
К недостаткам можно отнести отсутствие среды разработки как таковой. Один экземпляр Infomodel распределяет данные в рабочей среде и во всех средах разработки, которые связаны с невыпущенными ветвями.
Другим очевидным недостатком является необходимость переноса всех существующих схем ветвей при изменении схемы данных. Иногда это вызывает серьезные проблемы, учитывая их количество.