Содержание
Что такое формат JPEG – подробное описание для фотографов
Любой, кто когда-либо пользовался Интернетом, вероятно, видел изображения в формате JPEG. На сегодняшний день это самый распространенный способ кодирования, отправки по сети и хранения изображений. Формат JPEG используется миллиарды раз в день. Без JPEG Всемирная паутина была бы немного менее красочной, намного медленнее и, вероятно, не обладала бы таким богатством изображений кошек!
Сегодня вы можете отправить изображение в формате JPEG другу по электронной почте, не беспокоясь о том, какое устройство, браузер или операционную систему он использует. Но так было не всегда. В начале 1980-х компьютеры уже могли хранить и отображать цифровые изображения, но существовало много конкурирующих идей и подходов для этой реализации. Вы не могли просто отправить картинку с одного компьютера на другой и ожидать, что это будет нормально работать.
Для решения этой проблемы в 1986 году совместными усилиями ISO (Международная организация по стандартизации) и IEC (Международная электротехническая комиссия) была создана Объединенная группа экспертов по фотографии (Joint Photographic Experts Group – аббревиатура JPEG) со штаб-квартирой в Женеве (Швейцария).
JPEG, группа экспертов, создала JPEG, стандарт сжатия цифровых изображений, в 1992 году.
Технические детали формата JPEG
Вся информация на компьютере хранится в виде серии двоичных чисел. Как правило, эти биты, нули и единицы, объединяются в группы по восемь, известные как байты. Когда вы открываете изображение JPEG на своем компьютере, что-то (браузер, ваша операционная система или что-то еще) должно декодировать байты, чтобы восстановить исходное изображение в виде списка цветов, которые затем можно отобразить.
Если вы откроете любое изображение с помощью текстового редактора (например, Notepad++), вы увидите кучу искаженных символов. Открыв изображение в текстовом редакторе, вы запутали компьютер, точно так же, как запутали свой мозг, когда слишком сильно терли глаза и начинаете видеть тусклые пятна и цвета!
Эти тусклые пятна, которые вы видите – известны как фосфены – не происходят от каких-либо световых стимулов, и при этом они не являются галлюцинациями, созданными в вашем уме. Они возникают потому, что ваш мозг предполагает, что любой электрический сигнал, поступающий через нервы в ваш глаз, передает световую информацию. Мозг должен сделать это предположение, потому что нет никакого способа узнать, является ли данный сигнал звуком, образом или чем-то еще. Все нервы в вашем теле несут электрический импульс одинакового типа. Когда вы оказываете давление, потирая глаза, вы посылаете невизуальные сигналы, что запускают рецепторы в вашем глазу, которые ваш мозг интерпретирует – в данном случае неправильно – как образ. И вы буквально видите давление на глаза!
Они возникают потому, что ваш мозг предполагает, что любой электрический сигнал, поступающий через нервы в ваш глаз, передает световую информацию. Мозг должен сделать это предположение, потому что нет никакого способа узнать, является ли данный сигнал звуком, образом или чем-то еще. Все нервы в вашем теле несут электрический импульс одинакового типа. Когда вы оказываете давление, потирая глаза, вы посылаете невизуальные сигналы, что запускают рецепторы в вашем глазу, которые ваш мозг интерпретирует – в данном случае неправильно – как образ. И вы буквально видите давление на глаза!
Компьютеры во многом похожи на наш мозг, — здесь важна правильная интерпретация сигналов. Все двоичные данные состоят из единиц и нулей, базовых компонентов, которые могут передавать любую информацию. Ваш компьютер часто догадывается, как ее интерпретировать, используя подсказки (например, расширение файла). Здесь мы заставили его интерпретировать картинку как текст, потому что именно этого ожидает текстовый редактор.
Если же вы откроете картинку в HEX-редакторе, то вы увидите просто большой набор цифр. В таких редакторах байты представлены в виде десятичных чисел. Вы можете вносить изменения в байты, и редактор будет изменять изображение.
А для просмотра изображений, закодированных в формате JPEG, сначала их надо декодировать. Этот процесс выполняется специальной программой поэтапно, но в обратном кодированию порядке.
Общая информация о формате JPEG
Файлы изображений в формате JPEG имеют следующие расширения: JPG, JFIF, JPE и JPEG. На сегодняшний день самым распространенным вариантом является расширение JPG.
Хранение графической информации в файловом формате JPEG использует алгоритм метода сжатия с потерями. Это позволяет сжимать данные с достаточно высокой эффективностью. В формате JPEG можно сохранять картинки с глубиной цвета до 24 бит/пиксель и размером их сторон не более 65535 пикселей (2311,93 см).
В JPEG не сохраняется альфа-канал (прозрачность).
Преимущества формата JPEG
Формат JPEG приобрел популярность из-за своего алгоритма сжатия, который позволяет значительно сжимать информацию и при этом сохранять основные цвета и яркость. Файлы в этом формате могут иметь небольшой размер, но при этом сохранять приемлемое качество изображений.
Этот формат используется во всех цифровых фотокамерах.
Изображения в формате JPEG можно без проблем просмотреть на любом электронном устройстве: компьютер, телевизор, смартфон, игровая приставка и так далее. Этот формат поддерживается во всех основных операционных системах: Mac OS, Linux, Windows, Android, iOS.
Недостатки формата JPEG
Главным недостатком формата JPEG можно считать то, что картинки в этом формате можно эффективно обрабатывать только один раз. После каждого сохранения изображения теряют качество и чем выше уровень сжатия, тем хуже будет их качество.
Другим недостатком формата JPEG является то, что он не сохраняет слои и альфа каналы (прозрачность).
Ограничения формата, которые напрямую зависят от уровня сжатия информации:
- Искажение цвета
- Мозаичность
- Ореолы вокруг контуров
- Появление шумов
- Потеря детализации
- Ступенчатость линий
- Ухудшение резкости
Детальнее о процессе сжатия файлов в формате JPEG
Чтобы дать вам представление о масштабе сжатия, которое используется в этом формате, представьте себе изображение весом примерно в 100 килобайт. Если бы информация об изображении хранилась без сжатия, для каждого пикселя потребовалось бы три числа – по одному для каждого из красного, зеленого и синего компонентов. Это будет означать в общей сложности 1 140 000 чисел, или около 1,2 мегабайт. Благодаря сжатию JPEG выходной файл становится в более чем десять раз меньше!
Процесс сжатия картинки в формате JPEG производится не сразу, а поэтапно.
Три уровня сжатия, которые используются в JPEG
- Подвыборка насыщенности цвета, Цветовая субдискретизация (Chrominance Subsampling)
- Дискретное косинусное преобразование и квантование (Discrete Cosine Transform and Quantization)
- Длина цикла, дельта и кодирование Хаффмана (Run-Length, Delta & Huffman Encoding)
Этап сжатия №1: Подвыборка насыщенности цвета, Цветовая субдискретизация
В первую очередь цифровое изображение переводится из цветового пространства RGB в YCbCr. В нем компонента
В нем компонента Y отвечает за яркость изображения, Cb – это относительная синева (relative blueness), Cr – это относительное покраснение (relative redness). Последние 2 компонента кодируются полностью, и в них уменьшается информация о цвете.
Этот этап в некоторой мере похож на то, как работают человеческие глаза. Цветовые рецепторы в наших глазах, известные как «колбочки», делятся на три типа, каждый из которых наиболее чувствителен к красному, зеленому или синему. Палочки, другой тип рецептора, которым наши глаза видят, могут обнаруживать только изменения яркости, но они гораздо более чувствительны. В наших глазах около ста двадцати миллионов палочек по сравнению с жалкими шестью миллионами колбочек.
Это означает, что наши глаза гораздо лучше обнаруживают изменения яркости, чем они обнаруживают изменения цвета. Если мы можем отделить цвет от яркости, мы можем удалить немного цвета, чтобы никто не заметил. Подвыборка насыщенности цвета – это процесс представления цветовых компонентов изображения с более низким разрешением, чем у его компонентов яркости.
Подвыборка насыщенности цвета – это процесс представления цветовых компонентов изображения с более низким разрешением, чем у его компонентов яркости.
Каждый пиксель имеет ровно один компонент Y, тогда как каждая дискретная группа из четырех пикселей имеет ровно один компонент Cb и один компонент Cr. Таким образом, изображение содержит только четверть информации о первоначальном цвете.
Использование цветового пространства YCbCr не является уникальным для JPEG. На самом деле, он был разработан в 1938 году для телевизионных передач. Не у всех были цветные телевизоры, поэтому отделение цвета от яркости позволило всем получать одинаковую передачу, а телевизоры, которые не поддерживали цвет, просто использовали компонент яркости.
Этап сжатия №2: Дискретное косинусное преобразование и квантование
На этом этапе все изображение разбивается на отдельные квадраты размером 8×8 пикселей и над каждым из них производится преобразование. При этом каждый квадрат раскладывается на составные цвета для подсчета частоты появления их по всему изображению.
При этом каждый квадрат раскладывается на составные цвета для подсчета частоты появления их по всему изображению.
Этот уровень сжатия в значительной степени является определяющей особенностью JPEG. После преобразования цветов в YCbCr компоненты сжимаются по отдельности. Дискретное косинусное преобразование (Discrete Cosine Transform – DCT) – это процесс разбиения изображения на блоки 8×8 и преобразования каждого блока в комбинацию из 64 паттернов.
Звучит невероятным то, что любое изображение может быть представлено с использованием 64 особых шаблонов (паттернов). Но это то же самое, что сказать, что любое место на Земле можно представить с использованием только двух чисел: долготы и широты. Поверхность Земли можно представить как двумерную, поэтому здесь нужны только два числа. Изображение 8х8 имеет шестьдесят четыре измерения, поэтому нам нужно шестьдесят четыре числа.
С точки зрения сжатия, не очевидно, как это помогает нам. Если нам нужно шестьдесят четыре числа для представления изображения 8×8, почему это лучше, чем хранить шестьдесят четыре компонента яркости? Мы делаем это по той же причине, по которой мы преобразовали три числа RGB в три числа YCbCr: это позволяет нам удалять детали, которые менее заметны.
Трудно понять, как именно выглядят детали, которые удаляются на этом этапе сжатия, потому что JPEG применяет дискретное косинусное преобразование только к блокам по 8×8 пикселей за один раз. Однако нет причин, по которым мы не можем применить его ко всему изображению.
На этом этапе сжатия JPEG удаляет высокочастотные детали. Преобразование цветов в коэффициенты (паттерны) DCT не является операцией с потерями. Это шаг квантования осуществляется с потерями, при котором значения высокой частоты, значения близкие к нулю или оба, удаляются. Когда вы выбираете более низкую настройку качества для изображения JPEG, это увеличивает порог для того, сколько из этих значений будет удалено, что приводит к меньшему размеру файла, но к более «зернистому» изображению.
Объем удаляемой из файла JPEG информации во время такой обработки сильно зависит от указанного уровня сжатия, и чем он больше, тем хуже будет качество изображения. Такое изображение уже никогда нельзя будет вернуть к первоначальному виду. Именно поэтому JPEG называется форматом сжатия с потерями качества. Размер файла после сжатия по сравнению с исходным файлом напрямую зависит от детализации изображения и чем больше мелких деталей, тем больше размер файла. Лучше сжимаются те изображения, в которых меньше шума и больше плавных цветовых и яркостных переходов. Чем выше контраст, тем хуже сжимается картинка.
Именно поэтому JPEG называется форматом сжатия с потерями качества. Размер файла после сжатия по сравнению с исходным файлом напрямую зависит от детализации изображения и чем больше мелких деталей, тем больше размер файла. Лучше сжимаются те изображения, в которых меньше шума и больше плавных цветовых и яркостных переходов. Чем выше контраст, тем хуже сжимается картинка.
Этап сжатия №3: Длина цикла, дельта и кодирование Хаффмана
На этом этапе сжатия кодируются цвета и яркость изображения. При этом сохраняются только отличия 64-х пиксельных квадратов, а вся одинаковая информация удаляется. Затем результаты такого кодирования представляются числами, которые тоже сжимаются по специальному алгоритму.
Все этапы сжатия до сих пор были с потерями. Этот последний слой сжатия, напротив, без потерь. Он не удаляет какую-либо информацию, но значительно уменьшает размер файла.
Как происходит сжатие, если не отсекается какая-то информация?
Подумайте о простом сплошном черном изображении. JPEG использует около 5000 чисел, чтобы представить его, но мы можем сделать намного лучше. Как можно сделать это с наименьшим количеством байтов? Наименьшее, что можно придумать, это четыре байта: три для указания цвета и один для определения количества пикселей, имеющих этот цвет. Идея выразить все повторяющиеся значения кратко таким способом называется кодированием по длине прогона. Это будет без потерь, потому что мы можем восстановить закодированные данные точно в том виде, как это было раньше.
JPEG использует около 5000 чисел, чтобы представить его, но мы можем сделать намного лучше. Как можно сделать это с наименьшим количеством байтов? Наименьшее, что можно придумать, это четыре байта: три для указания цвета и один для определения количества пикселей, имеющих этот цвет. Идея выразить все повторяющиеся значения кратко таким способом называется кодированием по длине прогона. Это будет без потерь, потому что мы можем восстановить закодированные данные точно в том виде, как это было раньше.
Размер файла сплошного черного изображения JPEG намного больше, чем четыре байта, потому что помните, что в слое DCT сжатие применяется к блокам 8×8 одновременно. Поэтому, как минимум, нам понадобится один коэффициент DCT для каждого блока в 64 пикселя. Нам нужен только один, потому что вместо сохранения одного коэффициента DCT, за которым следуют 63 нуля для этого изображения, кодирование по длине прогона позволяет нам просто сохранить одно число и сказать «остальные равны нулю».
Дельта-кодирование – это метод хранения каждого байта в качестве относительного значения по сравнению с чем-то перед ним, вместо сохранения его абсолютного значения.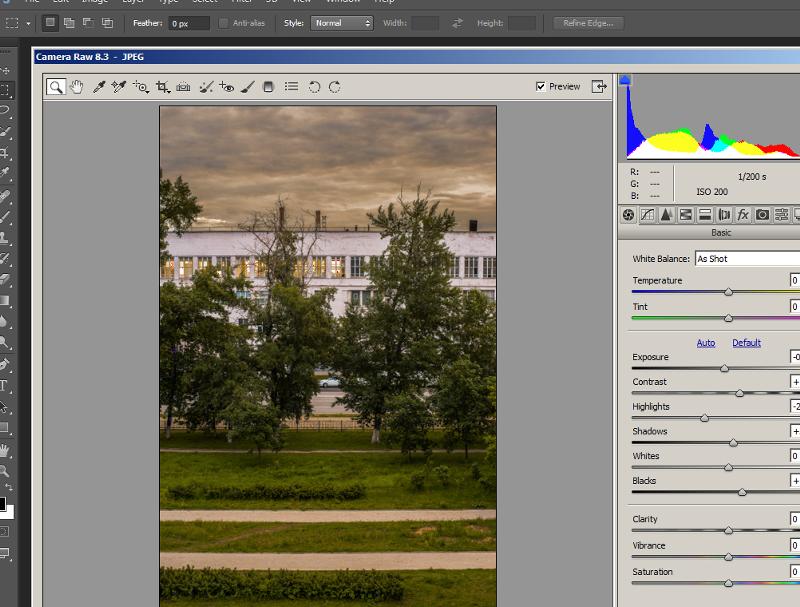
Для этого этапа характерно то, что здесь происходит запись заголовков в JPEG. Заголовки – это первые около 500 байтов, которые содержат метаданные об изображении, такие как его ширина и высота. Без заголовка практически невозможно (или, по крайней мере, очень трудно) декодировать изображение JPEG. Каждое изображение JPEG сжимается с кодом, который специфичен для этого конкретного изображения. Эти коды определены в словаре, хранящемся в заголовке. Этот метод называется кодированием Хаффмана, а словарь (алфавит) называется таблицей Хаффмана. Каждый компонент цвета может иметь свою собственную таблицу Хаффмана.
Таблицы Хаффмана оказывают такое сильное влияние на изображение, потому что они говорят нам, как читать отдельные биты. До сих пор мы имели дело с двоичными числами в десятичном виде. Это скрывает тот факт, что если вы хотите сохранить число 1 в байте, оно будет выглядеть как 00000001, потому что каждый байт должен иметь ровно восемь битов, даже если ему нужен только один бит.
Это потенциально огромная трата хранилища, если у вас много небольших номеров. Кодирование Хаффмана – это метод, который позволяет нам ослабить это требование о том, что каждое число должно занимать восемь битов.
Как декодировать JPEG изображения?
Зная этапы процесса сжатия (кодирования) картинки, описанные выше, мы сможем представить себе процесс чтения (декодирования) изображения в формате JPEG. Для этого нам нужно:
- Извлечь таблицу(ы) Хаффмана из заголовка и декодировать биты.
- Извлечь коэффициенты дискретного косинусного преобразования для каждого компонента цвета/яркости, для каждого блока 8×8, без кодировки длин серий и дельты.
- Объединить волны косинуса, основанные на коэффициентах, чтобы получить значения пикселей для каждого блока 8×8 (это называется обратным дискретным косинусным преобразованием).
- Увеличить компоненты цветности, если они были подвергнуты выборке (эта информация содержится в заголовке).
- Преобразовать полученные значения YCbCr каждого пикселя в RGB.

- Отобразить картинку в JPEG на экран!
Это довольно большая работа, которая делается программой только для того, чтобы вы могли увидеть простую картинку с изображением котика!
Как правильно сохранять фотографии в формате JPEG
Учитывая все достоинства и недостатки файлового формата JPEG, которые мы рассмотрели выше, вы сможете эффективно сохранять изображения в этом формате. Это позволит вам сэкономить дисковое пространство на компьютере и при этом сберечь высокое качество изображений.
Многие фотографы делают основную ошибку: фотографии других, более «тяжелых» графических форматов, для экономии места переводят в формат JPEG, обрабатывают несколько раз и при этом еще сильно сжимают. Все это можно делать только с копиями фотографий. Не забывайте, что формат JPEG предназначен в основном для эффективного просмотра изображений, а не для последующих обработок и доработок.
Если вы делаете фотографии в формате JPEG, а затем хотите их качественно обработать, тогда сначала их следует перевести в формат PSD или TIFF. Эти форматы будут иметь большой размер, но зато у них не будет тех недостатков, которые присущи файлам JPEG. Только после окончательного завершения обработки фотографии вы можете сохранить ее в формате JPEG.
Эти форматы будут иметь большой размер, но зато у них не будет тех недостатков, которые присущи файлам JPEG. Только после окончательного завершения обработки фотографии вы можете сохранить ее в формате JPEG.
Для улучшения качества фотографий в формате JPEG, при сохранении всегда устанавливайте цветовой профиль sRGB. Этот профиль поддерживается всеми графическими программами, всеми техническими устройствами и на всех платформах. В результате ваши фотографии будут выглядеть везде одинаково.
На сегодня все. Надеемся, что данная статья была вам полезна и интересна. Если у вас есть какие-то вопросы или замечания по данной теме, не стесняйтесь их озвучивать в разделе комментирования ниже.
Спасибо, что читаете нас!
Теги:
Web, фото
2512
-
Опубликовано -
Технологии
-
прокомментируйте статью
-
расскажите друзьям
Как устроен формат JPEG / Хабр
Изображения формата JPEG встречаются повсюду в нашей цифровой жизни, но за этим покровом осведомлённости скрываются алгоритмы, устраняющие детали, не воспринимаемые человеческим глазом.
 В итоге получается высочайшее визуальное качество при наименьшем размере файла – но как конкретно всё это работает? Давайте посмотрим, чего именно не видят наши глаза!
В итоге получается высочайшее визуальное качество при наименьшем размере файла – но как конкретно всё это работает? Давайте посмотрим, чего именно не видят наши глаза!
Легко принять, как само собой разумеющееся, возможность отправить фотку другу, и не волноваться по поводу того, какое устройство, браузер или операционную систему он использует – однако так было не всегда. К началу 1980-х компьютеры умели хранить и показывать цифровые изображения, однако по поводу наилучшего способа для этого существовало множество конкурирующих идей. Нельзя было просто отправить изображение с одного компьютера на другой и надеяться, что всё заработает.
Для решения этой проблемы в 1986 году был собран комитет экспертов со всего мира под названием «Объединённая группа экспертов по фотографии» (Joint Photographic Experts Group, JPEG), основанный в рамках совместной работы Международной организации по стандартизации (ISO) и Международной электротехнической комиссии (IEC) – двух международных организаций по стандартизации, штаб-квартира которых расположена в Женеве (Швейцария).
Группа людей под названием JPEG создала стандарт сжатия цифровых изображений JPEG в 1992 году. Любой человек, использовавший интернет, вероятно, встречался с изображениями в кодировке JPEG. Это самый распространённый способ кодирования, отправки и хранения изображений. От веб-страниц до емейла и соцсетей, JPEG используется миллиарды раз в день – практически каждый раз, когда мы смотрим изображение онлайн или отправляем его. Без JPEG веб был бы менее ярким, более медленным, и, вероятно, в нём было бы меньше фоток котиков!
Эта статья – о том, как декодировать JPEG изображение. Иначе говоря, о том, что требуется для преобразования сжатых данных, хранящихся на компьютере, в изображение, появляющееся на экране. Об этом стоит знать не только потому, что это важно для понимания технологии, которую мы используем ежедневно, но и потому, что раскрывая уровни сжатия, мы лучше узнаём восприятие и зрение, а также то, к каким деталям наши глаза восприимчивей всего.
Кроме того, играться с изображениями таким способом очень интересно.
Заглядывая внутрь JPEG
На компьютере всё хранится в виде последовательности двоичных чисел. Обычно эти биты, нули и единицы, группируются по восемь, составляя байты. Когда вы открываете JPEG изображение на компьютере, что-то (браузер, операционка, ещё что-то) должно декодировать байты, восстановив изначальное изображение в виде списка цветов, которые можно показать.
Если вы скачаете эту умильную фотографию кота и откроете её в текстовом редакторе, вы увидите кучу бессвязных символов.
Здесь я использую Notepad++ для изучения содержимого файла, поскольку обычные текстовые редакторы, типа Notepad из Windows, испортят двоичный файл после сохранения, и он перестанет удовлетворять формату JPEG.
Открывая изображение в текстовом редакторе, вы сбиваете компьютер с толку, точно так же, как вы сбиваете с толку свой мозг, когда потрёте глаза и начинаете видеть цветные пятна!
Эти пятна, которые вы видите, известны, как фосфены, и не являются результатом воздействия светового стимула или галлюцинациями, порождёнными разумом. Они возникают, потому что ваш мозг считает, что любые электрические сигналы в глазных нервах передают информацию о свете. Мозгу необходимо делать такие предположения, поскольку никак нельзя узнать, является ли сигнал звуком, видением или чем-то ещё. Все нервы в теле передают абсолютно одинаковые электрические импульсы. Давя на глаза, вы отправляете сигналы, не являющиеся зрительными, но активирующие рецепторы глаза, что ваш мозг интерпретирует – в данном случае, неверно – как нечто зрительное. Вы буквально способны видеть давление!
Они возникают, потому что ваш мозг считает, что любые электрические сигналы в глазных нервах передают информацию о свете. Мозгу необходимо делать такие предположения, поскольку никак нельзя узнать, является ли сигнал звуком, видением или чем-то ещё. Все нервы в теле передают абсолютно одинаковые электрические импульсы. Давя на глаза, вы отправляете сигналы, не являющиеся зрительными, но активирующие рецепторы глаза, что ваш мозг интерпретирует – в данном случае, неверно – как нечто зрительное. Вы буквально способны видеть давление!
Забавно думать о том, насколько компьютеры похожи на мозг, однако это также является полезной аналогией, иллюстрирующей, насколько сильно значение данных – передаваемых по телу нервами, или хранящихся на компьютере – зависит от их интерпретации. Все двоичные данные состоят из нулей и единиц, базовых компонентов, способных передавать информацию любого вида. Ваш компьютер часто догадывается, как интерпретировать их при помощи подсказок, например, расширений файлов. А сейчас мы заставляем его интерпретировать их как текст, поскольку именно этого ожидает текстовый редактор.
А сейчас мы заставляем его интерпретировать их как текст, поскольку именно этого ожидает текстовый редактор.
Чтобы понять, как декодировать JPEG, нам нужно увидеть сами изначальные сигналы – двоичные данные. Это можно сделать при помощи шестнадцатеричного редактора, или же прямо на веб-странице оригинала статьи! Там есть изображение, рядом с которым в текстовом поле приведены все его байты (кроме заголовка), представленные в десятичном виде. Вы можете менять их, и скрипт перекодирует и выдаст новое изображение на лету.
Можно узнать многое, просто играясь с этим редактором. К примеру, можете ли вы сказать, в каком порядке хранятся пиксели?
В этом примере странно то, что изменение некоторых чисел вообще не влияет на изображение, а, например, если заменить число 17 на 0 в первой строке, то фотка полностью испортится!
Другие изменения, например, замена 7 на строке 1988 на число 254 изменяет цвет, но только последующих пикселей.
Возможно, наиболее странным будет то, что некоторые числа меняют не только цвет, но и форму изображения. Измените 70 в строке 12 на 2 и посмотрите на верхний ряд изображения, чтобы увидеть, что я имею в виду.
Измените 70 в строке 12 на 2 и посмотрите на верхний ряд изображения, чтобы увидеть, что я имею в виду.
И вне зависимости от того, какое JPEG изображение вы используете, вы всегда будете находить эти загадочные шахматные последовательности при редактировании байтов.
Играясь с редактором, тяжело понять, как воссоздаётся фотка из этих байтов, поскольку JPEG сжатие состоит из трёх различных технологий, применяющихся последовательно по уровням. Мы изучим каждую из них отдельно, чтобы раскрыть наблюдаемое нами загадочное поведение.
Три уровня JPEG сжатия:
- Цветовая субдискретизация.
- Дискретное косинусное преобразование и дискретизация.
- Кодирование длин серий, дельта и Хаффмана
Дабы вы могли представить себе масштабы сжатия, обратите внимание, что изображение, приведённое выше, представляет 79 819 чисел, то есть, около 79 Кб. Если бы мы хранили его без сжатия, для каждого пикселя потребовалось бы по три числа – для красной, зелёной и синей составляющей. Это составило бы 917 700 чисел, или ок. 917 Кб. В результате JPEG сжатия итоговый файл уменьшился больше чем в 10 раз!
Это составило бы 917 700 чисел, или ок. 917 Кб. В результате JPEG сжатия итоговый файл уменьшился больше чем в 10 раз!
На самом деле, это изображение можно сжать гораздо сильнее. Снизу приведены два изображения рядом – фотка справа была ужата до 16 Кб, то есть в 57 раз меньше, чем несжатая версия!
Если присмотреться, будет видно, что эти изображения не идентичны. Оба они – картинки с JPEG сжатием, однако правая гораздо меньше по объёму. Также она выглядит чуть похуже (посмотрите на квадраты цветов фона). Поэтому JPEG ещё называют сжатием с потерями; в процессе сжатия изображение меняется и теряет некоторые детали.
1. Цветовая субдискретизация
Вот изображение с применением только первого уровня сжатия.
(Интерактивная версия – в оригинале статьи). Удаление одного числа рушит все цвета. Однако если удалить ровно шесть чисел, это практически не влияет на изображение.
Теперь числа чуть проще расшифровать. Это почти что простой список цветов, у которого каждый байт изменяет ровно один пиксель, но при этом он уже в два раза меньше несжатого изображения (которое занимало бы ок. 300 Кб в таком уменьшенном размере). Догадаетесь, почему?
Это почти что простой список цветов, у которого каждый байт изменяет ровно один пиксель, но при этом он уже в два раза меньше несжатого изображения (которое занимало бы ок. 300 Кб в таком уменьшенном размере). Догадаетесь, почему?
Можно видеть, что эти числа не обозначают стандартные красную, зелёную и синюю компоненты, поскольку если заменить все числа нулями, мы получим зелёное изображение (а не белое).
Это потому, что эти байты обозначают Y (яркость),
Cb (относительная голубизна),
и Cr (относительная краснота) картинки.
Почему не использовать RGB? Ведь именно так работает большинство современных экранов. Ваш монитор может демонстрировать любой цвет, включая красный, зелёный и синий цвета с разной интенсивностью для каждого пикселя. Белый получается включением всех трёх на полную яркость, а чёрный – их отключением.
Это также очень похоже на работу человеческого глаза. Цветовые рецепторы наших глаз называются «колбочки», и делятся на три типа, каждый из которых более чувствителен либо к красному, либо к зелёному, либо к синему цветам [колбочки S-типа чувствительны в фиолетово-синей (S от англ. Short — коротковолновый спектр), M-типа — в зелено-желтой (M от англ. Medium — средневолновый), и L-типа — в желто-красной (L от англ. Long — длинноволновый) частях спектра. Наличие этих трёх видов колбочек (и палочек, чувствительных в изумрудно-зелёной части спектра) даёт человеку цветное зрение. / прим. перев.]. Палочки, другой тип фоторецепторов в наших глазах, способны улавливать только изменения в яркости, однако они гораздо более чувствительные. В наших глазах есть около 120 млн палочек и всего 6 млн колбочек.
Short — коротковолновый спектр), M-типа — в зелено-желтой (M от англ. Medium — средневолновый), и L-типа — в желто-красной (L от англ. Long — длинноволновый) частях спектра. Наличие этих трёх видов колбочек (и палочек, чувствительных в изумрудно-зелёной части спектра) даёт человеку цветное зрение. / прим. перев.]. Палочки, другой тип фоторецепторов в наших глазах, способны улавливать только изменения в яркости, однако они гораздо более чувствительные. В наших глазах есть около 120 млн палочек и всего 6 млн колбочек.
Поэтому наши глаза гораздо лучше замечают изменения в яркости, чем изменения в цвете. Если отделить цвет от яркости, можно убрать немного цвета, и никто ничего не заметит. Цветовая субдискретизация – это процесс представления цветовых компонентов изображения в меньшем разрешении по сравнению с компонентами яркости. В примере выше у каждого пикселя ровно один компонент Y, а у каждой отдельной группы из четырёх пикселей есть ровно одна компонента Cb и одна Cr. Поэтому изображение содержит в четыре раза меньше цветовой информации, чем было у оригинала.
Цветовое пространство YCbCr используется не только в JPEG. Его изначально придумали в 1938 году для телепередач. Не у всех есть цветной телевизор, поэтому разделение цвета и яркости позволило всем получать один и тот же сигнал, а телевизоры без цвета просто использовали только компонент яркости.
Поэтому удаление одного числа из редактора полностью рушит все цвета. Компоненты хранятся в виде Y Y Y Y Cb Cr (на самом деле, не обязательно в таком порядке – порядок хранения задаётся в заголовке файла). Удаление первого числа приведёт к тому, что первое значение Cb будет воспринято, как Y, Cr как Cb, и в целом получится эффект домино, переключающий все цвета картинки.
Спецификация JPEG не обязывает вас использовать YCbCr. Но в большинстве файлов она используются, поскольку она даёт изображения лучшего качества после субдискретизации по сравнению с RGB. Но вам не обязательно верить мне на слово. Посмотрите сами в табличке ниже, как будет выглядеть субдискретизация каждого отдельного компонента как в RGB, так и в YCbCr.
(Интерактивная версия – в оригинале статьи).
Удаление синего не так заметно, как красного или зелёного. Всё потому, что из шести миллионов колбочек в ваших глазах около 64% чувствительны к красному, 32% к зелёному и 2% к синему.
Субдискретизация компонента Y (слева внизу) видна лучше всего. Заметно даже небольшое изменение.
Преобразование изображения из RGB в YCbCr не уменьшает размер файла, но облегчает поиск менее заметных деталей, которые можно удалить. Сжатие с потерями происходит на втором этапе. В её основе лежит идея представления данных в более сжимаемом виде.
2. Дискретное косинусное преобразование и дискретизация
Этот уровень сжатия по большей части и определяет суть JPEG. После преобразования цветов в YCbCr компоненты сжимаются по отдельности, поэтому далее мы можем сконцентрироваться только на компоненте Y. И вот как выглядят байты компонента Y после применения этого уровня.
(Интерактивная версия – в оригинале статьи). В интерактивной версии клик на пикселе прокручивает редактор на строчку, которая его обозначает. Попробуйте поудалять числа с конца или добавить несколько нулей к определённому числу.
В интерактивной версии клик на пикселе прокручивает редактор на строчку, которая его обозначает. Попробуйте поудалять числа с конца или добавить несколько нулей к определённому числу.
На первый взгляд, выглядит, как очень плохое сжатие. В изображении 100 000 пикселей, и для обозначения их яркости (Y-компоненты) требуется 102 400 чисел — это хуже, чем если вообще ничего не сжимать!
Однако обратите внимание на то, что большинство этих чисел равны нулю. Более того, все эти нули в конце строк можно удалять, не меняя изображение. Остаётся порядка 26 000 чисел, а это уже почти в 4 раза меньше!
На этом уровне находится секрет шахматных узоров. В отличие от других эффектов, которые мы видели, появление этих узоров не является глюком. Они – строительные блоки всего изображения. В каждой строчке редактора содержится ровно 64 числа, коэффициенты дискретного косинусного преобразования (DCT), соответствующие интенсивностям 64-х уникальных узоров.
Эти узоры формируются на основе графика косинуса. Вот, как выглядят некоторые из них:
Вот, как выглядят некоторые из них:
8 из 64 коэффициентов
Ниже – изображение, демонстрирующее все 64 узора.
(Интерактивная версия – в оригинале статьи).
Эти узоры имеют особое значение, поскольку они формируют базис изображений размера 8х8. Если вы незнакомы с линейной алгеброй, то это означает, что любое изображение размера 8х8 можно получить из этих 64-х узоров. DCT – это процесс разбиения изображений на блоки 8х8 и преобразования каждого блока в комбинацию из этих 64 коэффициентов.
То, что любое изображение можно составить из 64 определённых узоров, кажется волшебством. Однако это то же самое, что сказать, что любое место на Земле можно описать двумя числами – широтой и долготой [с указанием полушарий / прим. перев.]. Мы часто считаем поверхность Земли двумерной, поэтому нам требуются всего два числа. Изображение 8х8 имеет 64 измерения, поэтому нам требуются 64 числа.
Пока непонятно, как это помогает нам в смысле сжатия. Если нам нужно 64 числа для представления изображения 8х8, почему этот способ будет лучше, чем просто хранить 64 компоненты яркости? Мы делаем это по той же причине, по которой мы превратили три числа RGB в три числа YCbCr: это позволяет нам удалить незаметные детали.
Сложно увидеть, какие именно детали удаляются на этом этапе, поскольку JPEG применяет DCT к блокам 8х8. Однако никто не запрещает нам применить его к целой картинке. Вот, как выглядит DCT по компоненте Y в применении к целой картинке:
С конца можно удалить более 60 000 чисел практически без заметных изменений на фотке.
Однако отметьте, что если мы обнулим первые пять чисел, разница будет очевидной.
Числа в начале обозначают изменения низкой частоты в изображении, и наши глаза улавливают их лучше всего. Числа ближе к концу обозначают изменения высоких частот, которые сложнее заметить. Чтобы «увидеть то, что не видно глазом», мы можем изолировать эти детали высокой частоты, обнулив первые 5000 чисел.
Мы видим все области изображения, в которых происходит наибольшее изменение от пикселя к пикселю. Выделяются глаза кота, его усы, махровое одеяло и тени в нижнем левом углу. Можно пойти и дальше, обнулив первые 10 000 чисел:
20 000:
40 000:
60 000:
Эти высокочастотные детали JPEG и удаляет на этапе сжатия. Преобразование цветов в коэффициенты DCT не несёт потерь. Потери образуются на шаге дискретизации, где удаляются величины высокой частоты или близкие к нулю. Когда вы понижаете качество сохранения JPEG, программа увеличивает порог количества удаляемых значений, что даёт уменьшение размера файла, но делает картинку более пикселизированной. Поэтому изображение в первом разделе, которое было в 57 раз меньше, так выглядело. Каждый блок 8х8 представлялся гораздо меньшим количеством коэффициентов DCT по сравнению с более качественной версией.
Преобразование цветов в коэффициенты DCT не несёт потерь. Потери образуются на шаге дискретизации, где удаляются величины высокой частоты или близкие к нулю. Когда вы понижаете качество сохранения JPEG, программа увеличивает порог количества удаляемых значений, что даёт уменьшение размера файла, но делает картинку более пикселизированной. Поэтому изображение в первом разделе, которое было в 57 раз меньше, так выглядело. Каждый блок 8х8 представлялся гораздо меньшим количеством коэффициентов DCT по сравнению с более качественной версией.
Можно сделать такой крутой эффект, как постепенная потоковая передача изображений. Можно вывести размытую картинку, которая становится всё более детализированной по мере скачивания всё большего количества коэффициентов.
Вот, просто для интереса, что получится при использовании всего 24 000 чисел:
Или всего 5000:
Очень размыто, но как будто узнаваемо!
3. Кодирование длин серий, дельта и Хаффмана
Пока что все этапы сжатия шли с потерями. Последний этап, наоборот, идёт без потерь. Он не удаляет информацию, однако значительно уменьшает размер файла.
Последний этап, наоборот, идёт без потерь. Он не удаляет информацию, однако значительно уменьшает размер файла.
Как можно сжать что-либо, не отбрасывая информацию? Представьте, как бы мы описали простой чёрный прямоугольник 700 х 437.
JPEG использует для этого 5000 чисел, но можно достичь гораздо лучшего результата. Можете представить себе схему кодирования, которая бы описывала подобное изображение как можно меньшим количеством байт?
Минимальная схема, которую смог придумать я, использует четыре: три для обозначения цвета, и четвёртый – сколько пикселей имеет такой цвет. Идея представления повторяющихся значений таким сжатым способом называется кодирование длин серий. Она не имеет потерь, поскольку мы можем восстановить закодированные данные в первозданном виде.
Размер файла JPEG с чёрным прямоугольником гораздо больше 4 байт – вспомните, что на уровне DCT сжатие применяется к блокам 8х8 пикселей. Поэтому как минимум нам нужен один коэффициент DCT на каждые 64 пикселя. Один нам нужен потому, что вместо того, чтобы хранить один DCT-коэффициент, за которым идёт 63 нуля, кодирование длин серий позволяет нам хранить одно число и обозначить, что «все остальные – нули».
Один нам нужен потому, что вместо того, чтобы хранить один DCT-коэффициент, за которым идёт 63 нуля, кодирование длин серий позволяет нам хранить одно число и обозначить, что «все остальные – нули».
Дельта-кодирование – это техника, при которой каждый байт содержит отличие от какого-то значения, а не абсолютную величину. Поэтому редактирование определённых байтов изменяет цвет всех остальных пикселей. К примеру, вместо того, чтобы хранить
12 13 14 14 14 13 13 14
Мы могли бы начать с 12, а потом просто обозначать, сколько надо прибавить или отнять, чтобы получить следующее число. И эта последовательность в дельта-кодировании приобретает вид:
12 1 1 0 0 -1 0 1
Преобразованные данные не получаются меньше исходных, но сжимать их уже легче. Применение дельта-кодирования перед кодированием длин серий может сильно помочь, оставаясь при этом сжатием без потерь.
Дельта-кодирование – одна из немногих техник, применяемых вне блоков 8х8. Из 64 коэффициентов DCT один – просто постоянная волновая функция (сплошной цвет). Он представляет среднюю яркость каждого блока для компонент яркости, или среднюю голубизну для компонентов Cb, и так далее. Первое значение каждого DCT-блока называется DC-значением, и каждое DC-значение проходит дельта-кодирование по отношению к предыдущим. Поэтому изменение яркости первого блока повлияет на все блоки.
Он представляет среднюю яркость каждого блока для компонент яркости, или среднюю голубизну для компонентов Cb, и так далее. Первое значение каждого DCT-блока называется DC-значением, и каждое DC-значение проходит дельта-кодирование по отношению к предыдущим. Поэтому изменение яркости первого блока повлияет на все блоки.
Остаётся последняя загадка: как изменение единственного числа полностью портит всю картинку? Пока таких свойств у уровней сжатия не было. Ответ лежит в заголовке JPEG. Первые 500 байт содержат метаданные об изображении – ширину, высоту, и проч., и пока мы с ними не работали.
Без заголовка практически невозможно (ну, или очень сложно) декодировать JPEG. Это будет выглядеть так, будто я пытаюсь описать вам картину, и начинаю изобретать слова для того, чтобы передать своё впечатление. Описание будет, вероятно, весьма сжатым, поскольку я могу изобретать слова именно с тем значением, которое я хочу передать, однако для всех остальных они не будут иметь смысла.
Звучит глупо, но именно так это и происходит. Каждое изображение JPEG сжимается с кодами, специфичными именно для него. Словарь кодов хранится в заголовке. Эта техника называется «код Хаффмана», а словарь – таблицей Хаффмана. В заголовке таблица отмечена двумя байтами – 255 и потом 196. У каждого цветового компонента может быть своя таблица.
Каждое изображение JPEG сжимается с кодами, специфичными именно для него. Словарь кодов хранится в заголовке. Эта техника называется «код Хаффмана», а словарь – таблицей Хаффмана. В заголовке таблица отмечена двумя байтами – 255 и потом 196. У каждого цветового компонента может быть своя таблица.
Изменения таблиц радикально повлияют на любое изображение. Хороший пример – поменять на 15-й строке 1 на 12.
Это происходит потому, что в таблицах указывается, как нужно читать отдельные биты. Пока что мы работали только с двоичными числами в десятичном виде. Но это скрывает от нас тот факт, что если вы хотите хранить число 1 в байте, то оно будет выглядеть, как 00000001, поскольку в каждом байте должно быть ровно восемь бит, даже если нужен из них всего один.
Потенциально это большая трата места, если у вас есть много мелких чисел. Код Хаффмана – это техника, позволяющая нам ослабить это требование, по которому каждое число должно занимать восемь бит. Это значит, что если вы видите два байта:
234 115
То, в зависимости от таблицы Хаффмана, это могут быть три числа. Чтобы их извлечь, вам надо сначала разбить их на отдельные биты:
Чтобы их извлечь, вам надо сначала разбить их на отдельные биты:
11101010 01110011
Затем обращаемся к таблице, чтобы понять, как их группировать. К примеру, это могут быть первые шесть битов, (111010), или 58 в десятичной системе, за которыми идут пять битов (10011), или 19, и наконец последние четыре бита (0011), или 3.
Поэтому очень сложно разобраться в байтах на этом этапе сжатия. Байты не представляют то, что кажется. Не буду углубляться в детали работы с таблицей в данной статье, но материалов по этому вопросу в сети достаточно.
Один из интересных трюков, которые можно проделать, зная это – отделить заголовок от JPEG и хранить его отдельно. По сути, получится, что файл сможете прочесть только вы. Facebook проделывает это, чтобы ещё сильнее уменьшать файлы.
Что ещё можно сделать – совсем немного изменить таблицу Хаффмана. Для других это будет выглядеть, как испорченная картинка. И только вы будете знать волшебный вариант её исправления.
Подведём итоги: так что же нужно для декодирования JPEG? Необходимо:
- Извлечь таблицу (таблицы) Хаффмана из заголовка и декодировать биты.
- Извлечь коэффициенты дискретного косинусного преобразования для каждого компонента цвета и яркости для каждого блока 8х8, проведя обратные преобразования кодирования длин серий и дельты.
- Скомбинировать косинусы на основе коэффициентов, чтобы получить значения пикселей для каждого блока 8х8.
- Масштабировать компоненты цветов, если проводилась субдискретизация (эта информация есть в заголовке).
- Преобразовать полученные значения YCbCr для каждого пикселя в RGB.
- Вывести изображение на экран!
Серьёзная работа для простого просмотра фотки с котиком! Однако, что мне в этом нравится – видно, насколько технология JPEG человекоцентрична. Она основана на особенностях нашего восприятия, позволяющих достичь гораздо лучшего сжатия, чем обычные технологии. И теперь, понимая, как работает JPEG, можно представить, как эти технологии можно перенести в другие области. К примеру, дельта-кодирование в видео может дать серьёзное уменьшение размера файла, поскольку там часто есть целые области, не меняющиеся от кадра к кадру (к примеру, фон).
Код, использованный в статье, открыт, и содержит инструкции по замене картинок на свои собственные.
форматов JPEG — прогрессивный и базовый | Винсент Табора | High-Definition Pro
Baseline JPEG и Progressive JPEG
JPEG (Joint Photographic Experts Group) — это формат сжатия изображений, используемый для файлов изображений. Поскольку JPEG сжат, это хороший формат изображения для веб-сайтов, позволяющий быстрее загружать. Он получил всеобщее признание благодаря поддержке продуктов многих поставщиков и популярных интернет-браузеров. Файлы JPEG имеют расширение .jpg или .jpeg и являются распространенным типом файлов, используемых в фотографии.
Для JPEG требуется кодировщик, который сжимает формат изображения, будь то из камеры RAW или непосредственно из процессора изображений. Камеры могут сохранять захваченное изображение непосредственно в формате JPEG, в зависимости от настроек. Это можно установить в меню камеры (дополнительную информацию см. в документации к камере).
в документации к камере).
После того, как изображение было сжато, его необходимо декодировать. Декодер должен быть установлен на устройстве или в приложении для рендеринга и отображения изображения JPEG. Это встроенная функция для веб-браузеров и программного обеспечения для обработки изображений, включая функции предварительного просмотра изображений в таких операционных системах, как macOS и Windows.
Формат сжатия JPEG с потерями
Чтобы лучше понять JPEG, давайте начнем с краткой предыстории. Изображение в формате JPEG — это изображение, обработанное с использованием алгоритма сжатия с потерями . Когда изображение сжимается, информация теряется в деталях. Это нормально, потому что целью создания изображений JPEG является минимизация количества битов в памяти, эффективно уменьшая размер файла. Чем меньше размер файла, тем быстрее загружается и отображается изображение из сети.
Процесс начинается с преобразования цвета путем выборки цветовых каналов изображения (RGB). Это относится к методу субдискретизации , который представляет собой метод обработки сигналов, используемый для построения изображения. Затем он разбивается на блоки по пикселей с использованием DCT (дискретных косинусных преобразований) для квантования . Это часть аналого-цифрового преобразования сигнала в схеме процессора изображения. Результатом является закодированное изображение JPEG.
Это относится к методу субдискретизации , который представляет собой метод обработки сигналов, используемый для построения изображения. Затем он разбивается на блоки по пикселей с использованием DCT (дискретных косинусных преобразований) для квантования . Это часть аналого-цифрового преобразования сигнала в схеме процессора изображения. Результатом является закодированное изображение JPEG.
Существует два типа, которые обычно используются для отображения содержимого JPEG.
- Базовый или стандартный JPEG
- Progressive JPEG
Давайте рассмотрим разницу между двумя типами JPEG. Более технические детали JPEG не будут обсуждаться в этой статье. Я больше сосредоточусь на приложении.
Baseline JPEG
Это стандартный формат сжатия JPEG, широко поддерживаемый многими продуктами обработки изображений. Сюда входят цифровые камеры и программное обеспечение для редактирования изображений. Одним из наиболее распространенных применений базового JPEG являются изображения, отображаемые в веб-браузере. Базовый алгоритм JPEG рендерит изображение построчно по мере обработки данных при загрузке из сети. Данные обрабатываются потоками, по мере поступления данных в буфер компьютера из сети. Затем он отображает изображение сверху вниз и слева направо.
Сюда входят цифровые камеры и программное обеспечение для редактирования изображений. Одним из наиболее распространенных применений базового JPEG являются изображения, отображаемые в веб-браузере. Базовый алгоритм JPEG рендерит изображение построчно по мере обработки данных при загрузке из сети. Данные обрабатываются потоками, по мере поступления данных в буфер компьютера из сети. Затем он отображает изображение сверху вниз и слева направо.
Хотя целью сжатия данных является уменьшение размера файла для более быстрой загрузки, это также зависит от скорости сети и мощности процессора при обработке данных. Графический процессор также помогает в рендеринге больших файлов, если приложение поддерживает его. Большие файлы изображений RAW с высоким разрешением, размер которых превышает 30 МП (мегапикселей) в сжатом виде, могут занять больше времени для загрузки и декодирования.
Базовое изображение JPEG рендерится сверху вниз, показывая сначала верхнюю часть изображения. Затем он движется вниз, пока вы не увидите полное изображение.
Progressive JPEG
Формат сжатия JPEG с прогрессивной разверткой визуализирует изображение аналогично GIF (формату обмена графикой) . При рендеринге в веб-браузере изображение медленно загружает изображение по одному слою за раз. Он исчезает в изображении, пока оно не будет полностью визуализировано. Алгоритм прогрессивного JPEG сначала создает впечатление размытого изображения. Затем постепенно изображение начинает визуализироваться, пока не отобразит полностью визуализированное изображение. Браузер на самом деле интерпретирует изображение построчно, но дает размытый предварительный просмотр полного изображения в заполнителе, где изображение вставляется на веб-страницу.
В то время как базовая линия визуализируется построчно по мере считывания данных по мере их отправки в веб-браузер, изображение в формате JPEG с прогрессивной разверткой начинает немедленно отображать полное изображение. Контраст изображения становится более резким и детализированным по мере того, как данные обрабатываются механизмом рендеринга веб-браузера. Наконец, вы увидите полную глубину изображения после его полного рендеринга.
Наконец, вы увидите полную глубину изображения после его полного рендеринга.
Progressive JPEG медленно визуализирует изображение, начиная с размытого пиксельного предварительного просмотра. Затем оно начинает становиться четче и резче, с большей контрастностью и глубиной, пока вы не увидите полное изображение.
Главное отличие
Возможно вопрос должен зависеть от требований. Есть некоторые заблуждения, которые необходимо объяснить. Некоторые веб-разработчики скажут, что прогрессивный JPEG лучше подходит для «быстрой» загрузки изображений на веб-страницу. Это не означает, что это увеличивает фактическую скорость Интернета, поскольку эта переменная является фиксированной. Если скорость вашего интернет-соединения составляет 4 Мбит/с, она останется прежней. Сжатие уменьшает количество бит в изображении, что в целом ускоряет загрузку по существующей ссылке.
Progressive просто дает немедленный предварительный просмотр изображения во время его загрузки. Он начинается с пикселизации и медленно увеличивает контрастность, а глубина становится явно более четкой, пока изображение не будет полностью визуализировано. Когда веб-разработчики говорят, что это быстрее, это потому, что изображение появляется в их заполнителях, чтобы дать пользователям представление о местонахождении изображений во время загрузки. В базовом формате JPEG верхняя часть изображения появляется первой при рендеринге. Если изображение еще не начало загружаться, пользователь может пропустить его, так как вы не получите предварительный просмотр в заполнителе, как рендерятся прогрессивные изображения JPEG.
Когда веб-разработчики говорят, что это быстрее, это потому, что изображение появляется в их заполнителях, чтобы дать пользователям представление о местонахождении изображений во время загрузки. В базовом формате JPEG верхняя часть изображения появляется первой при рендеринге. Если изображение еще не начало загружаться, пользователь может пропустить его, так как вы не получите предварительный просмотр в заполнителе, как рендерятся прогрессивные изображения JPEG.
Это пример изображений, загружаемых в галерею изображений веб-страницы. Обратите внимание, что в правом нижнем углу отсутствует одно изображение. На самом деле это не отсутствующий образ. Изображение еще не загружено в браузер, но, поскольку оно является базовым, оно не дает предварительного просмотра изображения в заполнителе. Это может привести к тому, что некоторые пользователи решат, что изображение отсутствует, и начнут обновлять страницу. При более быстром подключении к Интернету это обычно не проблема. Это более проблематично при медленном подключении к Интернету. Эта галерея изображений отображает прогрессивные изображения JPEG. Сначала они будут выглядеть размытыми, затем постепенно станут четче и четче, пока изображения полностью не загрузятся на веб-страницу. Это может создать неправильное впечатление у пользователей с медленным подключением к Интернету, считая изображения размытыми. При более быстром соединении это не проблема, и он обеспечивает предварительный просмотр заполнителя, чтобы информировать пользователя о том, что есть изображение, которое должно появиться.
Эта галерея изображений отображает прогрессивные изображения JPEG. Сначала они будут выглядеть размытыми, затем постепенно станут четче и четче, пока изображения полностью не загрузятся на веб-страницу. Это может создать неправильное впечатление у пользователей с медленным подключением к Интернету, считая изображения размытыми. При более быстром соединении это не проблема, и он обеспечивает предварительный просмотр заполнителя, чтобы информировать пользователя о том, что есть изображение, которое должно появиться.
Оба формата использовали сжатие JPEG. Именно так изображения отображаются во время декодирования (когда изображение загружается в браузер). Прогрессивные форматы больше предназначены для Интернета или изображений JPEG, поступающих из сети. При открытии локальных базовых и прогрессивных изображений JPEG из редактора изображений они отображаются по-разному. Это связано с тем, что у вас больше пропускной способности между локальным устройством хранения и редактором изображений. Он открывается мгновенно, если только хранилище не из сети (например, облачный диск).
Он открывается мгновенно, если только хранилище не из сети (например, облачный диск).
Преобразование форматов
Вы можете преобразовать базовый формат в прогрессивный и наоборот. Все, что вам нужно, это программное обеспечение для редактирования изображений (например, Adobe Photoshop). В Photoshop после открытия базового изображения JPEG выполните следующие действия:
- Выберите «Файл» -> «Сохранить как…» (дайте новому файлу имя)
2. Выберите формат файла JPEG.
3. В параметрах формата выберите Прогрессивный. Нажмите OK, чтобы сохранить файл.
Для прогрессивного JPEG можно выбрать до 5 сканов. Минимум и значение по умолчанию установлено на 3.
Краткий обзор
Это не сравнение того, какой формат сжатия JPEG лучше другого. Оба они представляют собой сжатые информационные форматы с потерями, которые воспроизводят изображение одинакового качества. Основное отличие заключается в том, как они отображают изображение пользователю из сети (например, из Интернета). Это в основном проблема с просмотром контента из Интернета.
Это в основном проблема с просмотром контента из Интернета.
Progressive будет отображаться быстрее, потому что он может загружать превью изображения в свои заполнители по мере того, как страница загружает содержимое из сети. Базовая линия будет отображаться медленнее, потому что пользователи сначала увидят рендеринг изображения сверху, а затем перейдут к низу.
У пользователей может сложиться ложное впечатление от изображений JPEG с прогрессивной разверткой, поскольку сначала они выглядят размытыми. С другой стороны, пользователи могут не знать, что базовое изображение JPEG загружается на страницу, если они не видят, что появляется верхняя часть изображения.
Для коммерческой печати и бумажных изданий я не рекомендую ни формат, ни любой тип сжатого изображения с потерями. Лучше использовать формат без потерь, такой как TIFF, который сохраняет больше деталей.
Проблемы по большей части незначительные. Более высокая скорость Интернета решила проблему загрузки веб-контента. Для медленных интернет-соединений прогрессивный JPEG имеет преимущество, предоставляя пользователям предварительный просмотр изображения по мере его рендеринга. Для загрузки базового JPEG при медленном соединении может потребоваться некоторое время, но он не обеспечивает предварительный просмотр в заполнителе, чтобы пользователи знали об этом. В некоторых случаях пользователь может просто покинуть страницу, не зная, что есть еще не загруженные изображения, поскольку он не видел верхнюю часть рендеринга изображения в веб-браузере.
Для медленных интернет-соединений прогрессивный JPEG имеет преимущество, предоставляя пользователям предварительный просмотр изображения по мере его рендеринга. Для загрузки базового JPEG при медленном соединении может потребоваться некоторое время, но он не обеспечивает предварительный просмотр в заполнителе, чтобы пользователи знали об этом. В некоторых случаях пользователь может просто покинуть страницу, не зная, что есть еще не загруженные изображения, поскольку он не видел верхнюю часть рендеринга изображения в веб-браузере.
Сводка из Энциклопедии форматов графических файлов
Также известен как: JFIF, JFI, JPG, JPEG
| Тип | Растровое изображение |
| Цвета | До 24 бит |
| Сжатие | JPEG |
| Максимальный размер изображения | 64Kx64K пикселей |
| Числовой формат | |
| Несколько изображений в файле | № |
| Инициатор | Микросистемы C-Cube |
| Платформа | Все |
| Вспомогательные приложения | Слишком много, чтобы перечислить |
См. также также | Глава 9, Сжатие данных (раздел JPEG) |
Использование
Используется в основном в программах обработки графики и изображений.
Комментарии
Один из немногих форматов, в котором используется сжатие JPEG.
это обеспечивает превосходное сжатие изображений с глубокими пикселями.
Спецификации поставщика
доступны для этого формата.
Фрагменты кода
доступны для этого формата.
Примеры изображений
доступны для этого формата.
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ: jfif—>
JPEG (Объединенная группа экспертов по фотографии) относится к
организация стандартов, метод сжатия файлов, а иногда и
формат файла. Фактически спецификация JPEG
сам по себе, который мы описываем в терминах сжатия в главе 9, сам по себе не определяет общий обмен файлами.
формат для хранения и передачи данных JPEG между
компьютерные платформы и операционные системы. JPEG
JPEG
Формат обмена файлами (JFIF) является развитием
C-Cube Microsystems для хранения
Данные в формате JPEG. JFIF это
разработан, чтобы разрешить файлы, содержащие JPEG-кодированные
потоки данных для обмена между другими несовместимыми системами
и приложений.
Содержание:
Организация файлов
Сведения о файле
Дополнительная информация
Файл JFIF в основном представляет собой JPEG
поток данных с некоторыми ограничениями и маркером идентификации. Чтобы
чтобы понять формат JFIF, вам нужно
понимать JPEG; в дополнение к
Глава 9, см. часто задаваемые вопросы по JPEG
(Часто задаваемые вопросы), включенный в
CD-ROM и доступны в Интернете.
Данные JPEG и JFIF являются байтовыми.
потоки, всегда сохраняющие 16-битные значения слов в формате с обратным порядком байтов.
Данные JPEG обычно хранятся в виде потока
блоков, и каждый блок идентифицируется значением маркера.
Первые два байта каждого потока JPEG являются
Значения маркера начала изображения (SOI) FFh D8h. В
В
JFIF-совместимый файл есть
Маркер JFIF APP0 (приложение), немедленно
после SOI, который состоит из кодовых значений маркера FFh E0h
и символы JFIF в данных маркера, как
описано в следующем разделе. В добавок к
Сегмент маркера JFIF, может быть один или несколько
необязательные сегменты маркера расширения JFIF, за которыми следуют
фактическими данными изображения.
Хотя файлы JFIF не имеют
формально определенный заголовок, SOI и JFIF APP0
маркеры, взятые вместе, действуют как заголовок в следующем сегменте маркера.
состав:
typedef структура _JFIFHeader
{
БАЙТ SOI[2]; /* 00h Начало маркера изображения */
БАЙТ APP0[2]; /* 02h Маркер использования приложения */
БАЙТ Длина[2]; /* 04h Длина поля APP0 */
БАЙТ-идентификатор[5]; /* 06h "JFIF" (заканчивается нулем) Строка идентификатора */
БАЙТ Версия[2]; /* 07h Версия формата JFIF */
БАЙТ Единицы; /* 09h Единицы, используемые для разрешения */
БАЙТ Xdensity[2]; /* Горизонтальное разрешение 0Ah */
БАЙТ Ydensity[2]; /* Разрешение по вертикали 0 каналов */
БАЙТ XЭскиз; /* 0Eh Количество пикселей по горизонтали */
БАЙТ YЭскиз; /* 0Fh Количество пикселей по вертикали */
} JFIFHEAD;
SOI является началом маркера изображения и всегда содержит код маркера.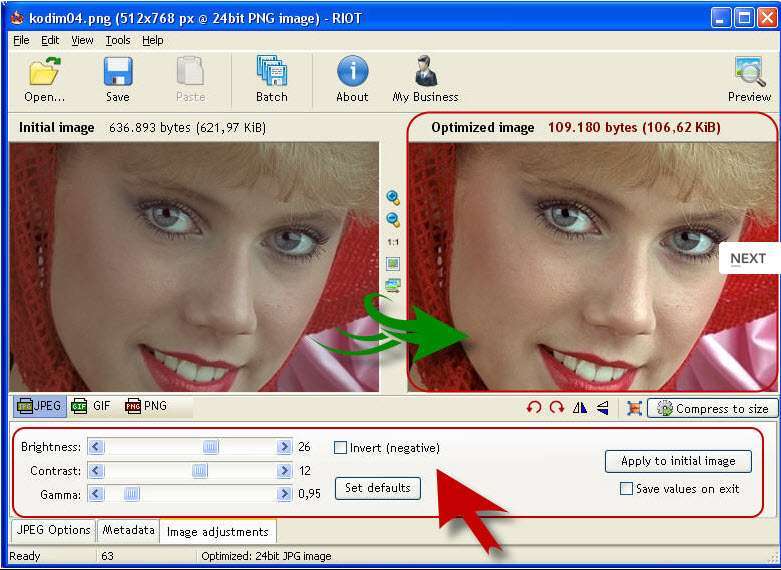
значения FFh D8h.
APP0 является маркером приложения и всегда содержит код маркера.
значения FFh E0h.
Длина — это размер маркера JFIF (APP0).
сегмент, включая размер самого поля «Длина» и любой
миниатюрные данные, содержащиеся в сегменте APP0. Из-за этого
значение длины равно 16 + 3 * XThumbnail * YThumbnail.
Идентификатор содержит значения 4Ah 46h 49h 46h 00h
(JFIF) и используется для идентификации кодового потока как
в соответствии со спецификацией JFIF.
Версия определяет версию JFIF.
спецификация, где первый байт содержит основную версию
номер и второй байт, содержащий дополнительный номер версии. Для
версия 1.02, значения поля Версия: 01h 02h; старые файлы
содержать 01h 00h или 01h 01h.
Units, Xdensity и Ydensity определяют единицы измерения, используемые для
опишите разрешение изображения. Единицы могут быть 01h для точек на дюйм, 02h
для точек на сантиметр или 00h для отсутствия (используйте измерение как пиксель
соотношение сторон). Xdensity и Ydensity — горизонтальная и вертикальная
Xdensity и Ydensity — горизонтальная и вертикальная
разрешение данных изображения соответственно. Если значение поля Единицы
равно 00h, поля Xdensity и Ydensity будут содержать соотношение пикселей
соотношение (Xdensity : Ydensity), а не разрешение изображения. Потому что
неквадратные пиксели не рекомендуются из соображений портативности,
Значения Xdensity и Ydensity обычно равны 1, когда значение Units
0.
XThumbnail и YThumbnail задают размеры уменьшенного изображения.
включен в маркер JFIF APP0. Если нет миниатюры
изображение включено в маркер, то эти поля содержат 0. A
уменьшенное изображение представляет собой уменьшенное представление изображения, хранящегося в
основной поток данных JPEG (некоторые люди называют его иконкой
или превью изображения). Сами данные эскиза состоят из массива
XThumbnail * Значения пикселей YThumbnail, где каждое значение пикселя занимает
три байта и содержит 24-битное значение RGB (хранится
в порядке R,G,B). Миниатюра не сжимается
изображение.
Сохранение эскиза изображения в маркере JFIF APP0
сейчас не рекомендуется, хотя по-прежнему поддерживается для отсталых
совместимость. Версия 1.02 JFIF определяет
маркеры расширения, которые позволяют сохранять эскизы изображений отдельно
от идентификационного маркера. Этот метод является более гибким, поскольку
разрешены несколько форматов эскизов, и поскольку несколько
миниатюрные изображения разных размеров могут быть включены в
файл. Версия 1.02 позволяет отображать эскизы цветов (один байт на пиксель).
плюс карта цветов с 256 элементами) и JPEG-сжатие
миниатюры, в дополнение к 24-битной миниатюре RGB
формат. В любом случае миниатюра изображения ограничена размером менее 64 КБ.
байтов, потому что он должен соответствовать маркеру APP0.
После сегмента маркера JFIF может быть один
или более необязательный маркер расширения JFIF
сегменты. Сегменты расширения используются для хранения дополнительной информации.
и встречаются только в JFIF версии 1. 02 и
02 и
позже. Структура этих сегментов расширения показана ниже:
typedef структура _JFIFExtension
{
БАЙТ APP0[2]; /* 00h Маркер использования приложения */
БАЙТ Длина[2]; /* 02h Длина поля APP0 */
БАЙТ-идентификатор[5]; /* 04h "JFXX" (заканчивается нулем) Строка идентификатора */
БАЙТРасширенныйКод; /* 09h Идентификационный код расширения */
} JFIFEXTENSION;
APP0 содержит значения FFh E0h.
Длина хранит длину в байтах сегмента расширения.
Идентификатор содержит значения 4Ah 46h 58h 58h 00h (JFXX).
ExtensionCode указывает тип информации, которую этот маркер расширения
магазины. Для версии 1.02 определены только коды расширения 10h.
(миниатюра закодирована с использованием JPEG), 11h (миниатюра
хранится с использованием 1-байтовых пикселей и палитры) и 13h (миниатюра хранится
с использованием 3-байтовых пикселей RGB).
Данные расширения следуют за информацией сегмента расширения и различаются по размеру.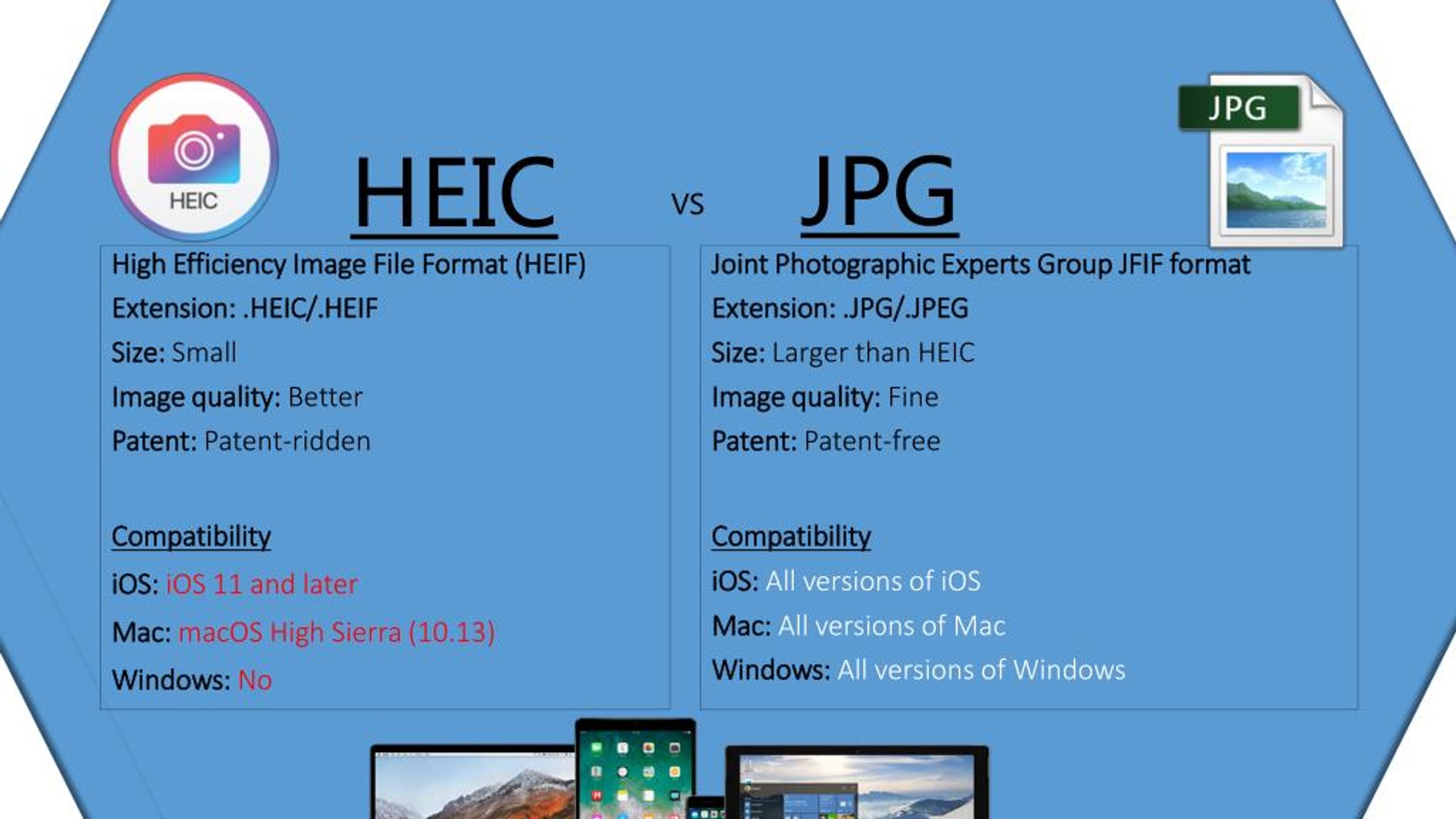
и содержимое в зависимости от значения ExtensionCode. (См. текущую спецификацию JFIF для возможных форматов сегмента маркера расширения.)
Декодеры JFIF должны быть готовы игнорировать
нераспознанные маркеры расширения и сегменты APPn. Специфично для приложения
Маркеры APPn, не распознанные декодером JPEG, могут
можно просто пропустить, используя поле длины данных маркера.
Маркер JFIF, по сути, является гарантией того, что
файл соответствует соглашениям JFIF. Большинство
Поэтому декодеры JFIF учитывают
Сегмент маркера JFIF является необязательным и вполне
способен читать необработанный поток данных JPEG, который
соответствует соглашениям JFIF в отношении цвета
выравнивание пространства и образца. (там много таких файлов,
потому что JFIF просто формализовал общепринятую практику в
эти области.) Надежный декодер будет обрабатывать JFIF
файл как поток блоков, без предположений о порядке блоков
помимо тех, которые предусмотрены стандартом JPEG. Этот
позволяет читать многие нестандартные и неверные
Варианты файла JFIF, такие как вставленный маркер COM
между маркерами SOI и JFIF APP0 (есть
их тоже немало). Мы также рекомендуем
Мы также рекомендуем
декодер должен принимать любой файл JFIF с известным
основной номер версии, даже если дополнительный номер версии новее, чем
известные декодеру.
Фактические данные JPEG в JFIF
файл следует всем маркерам APP0 и придерживается формата, определенного в
Документация в формате JPEG. Базовый уровень
Процесс JPEG является рекомендуемым типом данных изображения
кодировка для использования в файлах JFIF. Это для
обеспечить максимальную совместимость файлов JFIF для данных
обмен.
Чтобы идентифицировать файл JFIF или поток данных, выполните поиск
значения FFh D8h FFh. Это идентифицирует маркер SOI, за которым следует
другой маркер. В правильном файле JFIF следующий
байт будет E0h, что указывает на маркер JFIF APP0
сегмент. Однако возможно, что один или несколько других маркеров
сегменты могут быть ошибочно записаны между SOI и
Маркеры JFIF APP0 (нарушение
спецификации JFIF). Как упоминалось ранее,
декодер все равно должен попытаться прочитать файл.
Следующие два байта (длина сегмента APP0) различаются по значению, но
обычно 00h 10h, за ними следуют пятибайтовые значения 4Ah
46ч 49ч 46ч 00ч (JFIF). Если эти значения найдены,
маркер SOI (FFh D8h) отмечает начало
Поток данных JFIF. Если только значения FFh D8h FFh
найдены, но не остальные данные, то «сырые»
Обнаружен поток данных JPEG. Все
Потоки данных JFIF и JPEG заканчиваются
со значениями маркера конца изображения (EOI) FFh D9час
Существует множество проприетарных форматов файлов изображений, содержащих
Данные JPEG. Многие просто инкапсулируют
поток данных JPEG или JFIF внутри
их собственная оболочка формата файла. Сканирование для
Маркер JPEG SOI и считывание до тех пор, пока маркер EOI не будет
обычно позволяет извлечь
Поток данных JPEG/JFIF. По меньшей мере
один собственный формат файла изображения, формат .HSI от Handmade
Программное обеспечение, содержит данные JPEG, но не может быть
успешно читается или распаковывается без использования специального программного обеспечения, благодаря
к проприетарным модификациям кодировки JPEG
процесс. (Все файлы .HSI начинаются со значений 68h 73h 69ч 31ч и
(Все файлы .HSI начинаются со значений 68h 73h 69ч 31ч и
не следует считать обычными файлами JPEG.)
Только два непатентованных формата, кроме JFIF,
в настоящее время поддерживают данные в формате JPEG. Последний
версия формата PICT для Macintosh добавляет
Заголовок PICT в файл JFIF
транслировать. Удалите заголовок PICT (все
до маркера SOI) и любые завершающие данные (все после маркера EOI).
маркер), и у вас есть эквивалент JFIF
файл. Другой формат, TIFF 6.0, также поддерживает
JPEG и подробно обсуждается в статье о
ТИФФ.
Для получения дополнительной информации о формате файла JFIF см.
см. спецификацию на компакт-диске. Вы также можете связаться
C-Cube Microsystems по адресу:
Микросистемы C-Cube
Вниманию: Скотт Сент-Клер
Корпоративные коммуникации
1778 бульвар Маккарти.
Милпитас, Калифорния 95035
Голос: 408-944-6300
ФАКС: 408-944-6314
См. также главу 9.для получения информации о сжатии JPEG.
JPEG
FAQ и
Часто задаваемые вопросы по сжатию, также включенные в
компакт-диск, содержащий справочную информацию о
JPEG.
Сам стандарт JPEG недоступен
в электронном виде; Вы должны заказать бумажную копию через
ИСО. В США копии стандартного
можно заказать у:
Американский национальный институт стандартов, Inc.
Кому: Продажи
1430 Бродвей
Нью-Йорк, NY 10018
Голос: 212-642-4900
Стандарт разделен на две части; Часть 1 является фактической спецификацией, и
Часть 2 посвящена методам проверки соответствия. Часть 1 проекта уже достигла
Статус международного стандарта. См. этот документ:
Цифровое сжатие и кодирование непрерывного тона неподвижного изображения
Изображения, часть 1: требования и рекомендации . Документ
номер ISO/IEC IS 10918-1.
Часть 2 все еще находится в статусе проекта комитета. См. этот документ:
Цифровое сжатие и кодирование непрерывного тона неподвижного изображения
Изображения, часть 2: проверка на соответствие .
