Содержание
Как правильно составить файл robots.txt: инструкция
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Зачем это нужно:
- уменьшить количество запросов к серверу;
- оптимизировать краулинговый бюджет сайта — общее количество страниц, которое за один раз может посетить поисковый бот;
- уменьшить шанс того, что в выдачу попадут страницы, которые там не нужны.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию <head> HTML-кода страницы:
<meta name="robots" content="noindex, nofollow"/>
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
- Формат — только txt.
- Вес — не превышающий 32 КБ.
- Название — строго строчными буквами «robots.txt». Никакие другие варианты, к примеру, с заглавной, боты не воспримут.
- Наполнение — строго латиница. Все записи должны быть на латинице, включая адрес сайта: если он кириллический, его нужно переконвертировать в punycode.
 Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах. - Исключение для предыдущего правила — комментарии вебмастера. Они могут быть на любом языке, поскольку специалист оставляет их для себя и коллег, а не для поисковых ботов. Для обозначения комментариев используют символ «#». Все, что указано после «#», роботы проигнорируют, поэтому следите, чтобы туда случайно не попали важные команды.
- Количество файлов robots.txt — должен быть один общий файл на весь сайт вместе с поддоменами.
- Местоположение — корневой каталог. У поддоменов файл должен быть таким же, только разместить его нужно в корневом каталоге каждого поддомена.
- Ссылка на файл — https://example.com/robots.txt (вместо https://example.com нужно указать адрес вашего сайта).
- Ссылка на robots.txt должна отдавать код ответа сервера 200 OK.
 Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.

Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пример:
Disallow: /blog/page-2.html
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
User-agent: *
Disallow:
А эта запись запрещает всем роботом сканировать весь сайт:
User-agent: *
Disallow: /
Если речь идет о новом сайте, проследите, чтобы в файле robots.
 txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Disallow: /catalog/blog/photo/
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Disallow: /catalog/
Disallow: /blog/
Disallow: /photo/
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
User-agent: *
Allow: /album/photo1.html
Disallow: /album/
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index. php» индексировать не нужно:
php» индексировать не нужно:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Sitemap: https://example.com/sitemap.xml
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
Disallow: /catalog/category1$
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
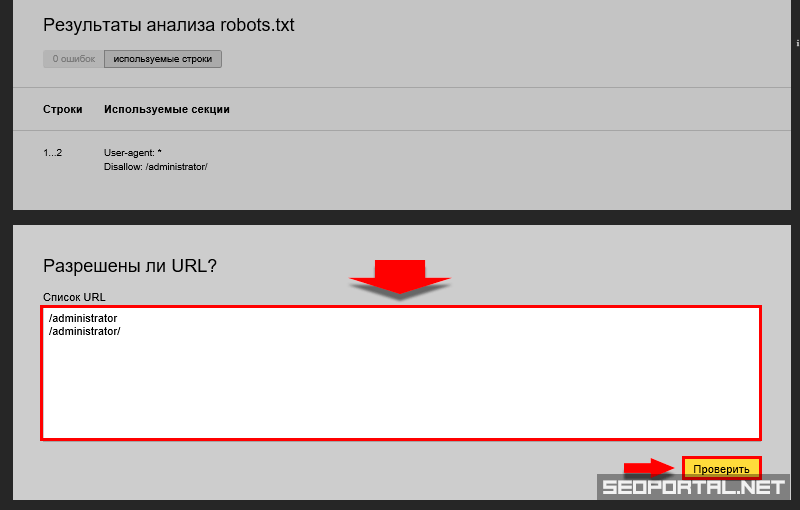
- Найти ошибки в заполнении robots — инструмент от Яндекса. Укажите сайт и введите содержимое файла в поле.
- Проверить доступность для ботов — инструмент от Google. Введите ссылку на URL с вашим robots.txt.
- Определить наличие файла robots.txt в корневом каталоге и доступность сайта для индексации — Анализ сайта от PR-CY. В сервисе есть еще 70+ тестов с проверкой SEO, технических параметров, ссылок и другого.
 Укажите сайт и введите содержимое файла в поле.
Укажите сайт и введите содержимое файла в поле.Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots. txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
- Robots.txt Editor,
- Virtual Robots.txt,
- WordPress Robots.txt optimization (+XML Sitemap).
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: *&s=
Disallow: /search/
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc. php # файл API WP
php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
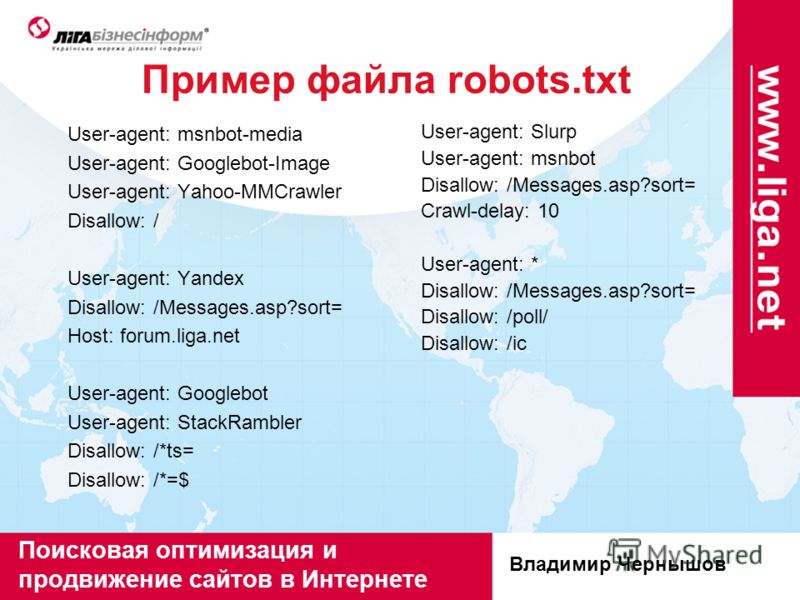
1C-Битрикс
В модуле «Поисковая оптимизация» этой CMS начиная с версии 14.0.0 можно настроить управление файлом robots из административной панели сайта. Нужный раздел находится в меню Маркетинг > Поисковая оптимизация > Настройка robots. txt.
txt.
Пример robots.txt для сайта на Битрикс
Похожий набор рекомендаций с дополнениями, подразумевающими, что у сайта есть личный кабинет пользователя.
User-agent: *
Disallow: /cgi-bin # закрыли папку на хостинге
Disallow: /bitrix/ # закрыли папку с системными файлами Битрикс
Disallow: *bitrix_*= # GET-запросы Битрикс
Disallow: /local/ # другая папка с системными файлами Битрикс
Disallow: /*index.php$ # дубли страниц с index.php
Disallow: /auth/ # страница авторизации
Disallow: *auth=
Disallow: /personal/ # личный кабинет
Disallow: *register= # страница регистрации
Disallow: *forgot_password= # страница с функцией восстановления пароля
Disallow: *change_password= # страница с возможностью изменить пароль
Disallow: *login= # вход с логином
Disallow: *logout= # выход из кабинета
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url=
Disallow: *back_url_admin=
Disallow: *captcha # страница с прохождением капчи
Disallow: */feed # новостные ленты
Disallow: */rss # rss-фиды
Disallow: *?FILTER*= # несколько популярных параметров фильтров в каталоге
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # все ссылки, имеющие метки UTM
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открыли папку, где находятся файлы uploads
Allow: /bitrix/*. js # здесь и далее открыли скрипты js и css
js # здесь и далее открыли скрипты js и css
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg # открыли доступ к картинкам в формате jpg и далее в других форматах
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
Sitemap: https://example.com/sitemap.xml
OpenCart
У этого движка есть официальный модуль Редактирование robots.txt Opencart для работы с файлом прямо из панели администратора.
Пример robots.txt для магазина на OpenCart
CMS OpenCart обычно используют в качестве базы для интернет-магазина, поэтому пример robots заточен под нужды e-commerce.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example. com/sitemap.xml
com/sitemap.xml
Joomla
Отдельных расширений, связанных с формированием файла robots.txt для этой CMS нет, система управления автоматически генерирует файл при установке, в нем содержатся все необходимые запреты.
Пример robots.txt для сайта на Joomla
В файле закрыты плагины, шаблоны и прочие системные решения.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковые системы воспринимают директивы в robots.txt как рекомендации, которым можно следовать или не следовать. Тем не менее, если в файле не будет противоречий, а на закрытые страницы нет входящих ссылок — у ботов не будет причин игнорировать правила. Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt
Как настроить robots.txt
Как создать robots.txt
Требования к файлу robots.txt
Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots. txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
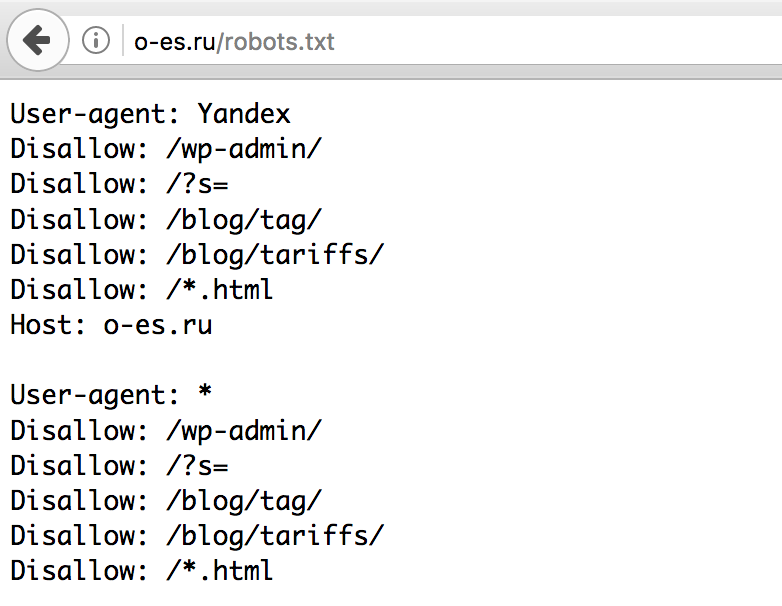
Кому нужен robots.txt
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т. д.
 д.
д.Как настроить файл robots.txt
Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.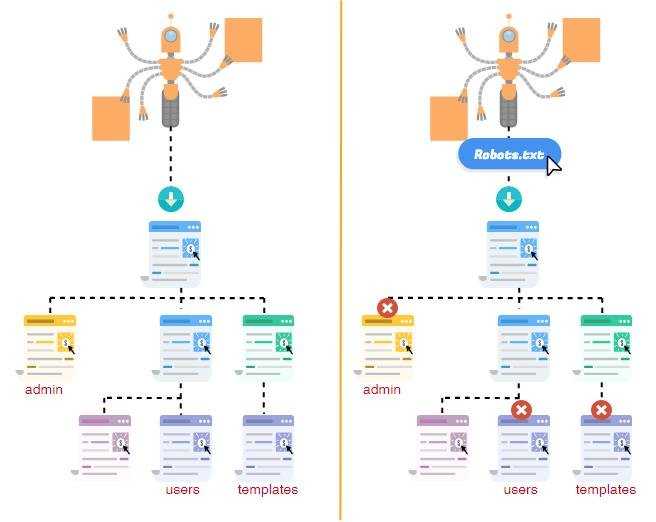
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txt
Способ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txt
Когда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txt
Проверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Лонч
07. 04.2023
04.2023
Чек-лист
07.04.2023
Ценности бренда
06.04.2023
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальности
Наш юрист будет ругаться, если вы не примете 🙁
Как создать файл robots.txt для вашего веб-сайта [5 шагов]
Основная задача веб-робота — обход или сканирование веб-сайтов и страниц в поисках информации; они неустанно работают над сбором данных для поисковых систем и других приложений. Для некоторых есть веская причина держать страницы подальше от поисковых систем. Независимо от того, хотите ли вы настроить доступ к своему сайту или хотите работать над сайтом разработки, не отображаясь в результатах Google, файл robots.txt после его внедрения позволяет веб-сканерам и ботам знать, какую информацию они могут собирать.
Что такое файл robots.txt?
robots.txt — это простой текстовый файл веб-сайта в корне вашего сайта, который соответствует стандарту исключения роботов. Например, www.yourdomain.com будет иметь файл robots.txt по адресу www.yourdomain.com/robots.txt. Файл состоит из одного или нескольких правил, которые разрешают или блокируют доступ сканерам, ограничивая их доступ к указанному пути к файлу на веб-сайте. По умолчанию все файлы полностью разрешены для сканирования, если не указано иное.
Файл robots.txt является одним из первых аспектов, проанализированных поисковыми роботами. Важно отметить, что на вашем сайте может быть только один файл robots.txt. Файл размещается на одной или нескольких страницах или на всем сайте, чтобы поисковые системы не отображали информацию о вашем сайте.
В этой статье описаны пять шагов для создания файла robots.txt и синтаксис, необходимый для защиты от ботов.
Как настроить файл Robots.txt
1.
 Создайте файл Robots.txt
Создайте файл Robots.txt
У вас должен быть доступ к корню вашего домена. Ваш провайдер веб-хостинга может помочь вам определить, есть ли у вас соответствующий доступ.
Наиболее важной частью файла является его создание и расположение. С помощью любого текстового редактора создайте файл robots.txt. Его можно найти по адресу: 9.0003
- Корень вашего домена: www.yourdomain.com/robots.txt.
- Ваши поддомены: page.yourdomain.com/robots.txt.
- Нестандартные порты: www.yourdomain.com:881/robots.txt.
Примечание:
Файлы robots.txt не помещаются в подкаталог вашего домена (www.yourdomain.com/page/robots.txt).
Наконец, вам нужно убедиться, что ваш файл robots.txt является текстовым файлом в кодировке UTF-8. Google и другие популярные поисковые системы и сканеры могут игнорировать символы вне диапазона UTF-8, что может сделать ваши правила robots.txt недействительными.
2. Установите свой агент пользователя robots.
 txt
txt
Следующим шагом в создании файлов robots.txt является установка агента пользователя . Пользовательский агент относится к поисковым роботам или поисковым системам, которые вы хотите разрешить или заблокировать. Несколько объектов могут быть пользовательским агентом . Ниже мы перечислили несколько поисковых роботов, а также их ассоциации.
Существует три разных способа установить пользовательский агент в файле robots.txt.
Создание одного агента пользователя
Синтаксис, который вы используете для установки агента пользователя: Агент пользователя: NameOfBot . Ниже DuckDuckBot является единственным установленным пользовательским агентом .
# Пример установки user-agent Пользовательский агент: DuckDuckBot
Создание более одного пользовательского агента
Если нам нужно добавить более одного, выполните тот же процесс, что и для пользовательского агента DuckDuckBot , в следующей строке, введя имя дополнительные пользовательский агент . В этом примере мы использовали Facebot.
В этом примере мы использовали Facebot.
#Пример установки более одного пользовательского агента Агент пользователя: DuckDuckBot Агент пользователя: Facebot
Установка всех сканеров в качестве агента пользователя
Чтобы заблокировать всех ботов или сканеров, замените имя бота звездочкой (*).
#Пример того, как установить все поисковые роботы в качестве агента пользователя User-agent: *
Примечание:
Знак решетки (#) обозначает начало комментария.
3. Установите правила для файла robots.txt
Файл robots.txt читается группами. Группа будет указывать, кем является пользовательский агент , и иметь одно правило или директиву, чтобы указать, к каким файлам или каталогам пользовательский агент может или не может получить доступ.
Вот используемые директивы:
- Запретить : Директива, относящаяся к странице или каталогу, относящемуся к вашему корневому домену, который вы не хотите сканировать названным агентом пользователя . Он начинается с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько запретить настройки для каждого правила.
- Разрешить : Директива относится к странице или каталогу, относящемуся к вашему корневому домену, который вы хотите, чтобы названный пользовательский агент сканировал. Например, вы можете использовать директиву allow для переопределения правила disallow . Он также будет начинаться с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько разрешить настройки для каждого правила.
- Карта сайта : Директива карты сайта является необязательной и указывает местоположение карты сайта для веб-сайта. Единственным условием является то, что это должен быть полный URL-адрес. Вы можете использовать ноль или больше, в зависимости от того, что необходимо.
 Он начинается с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько запретить настройки для каждого правила.
Он начинается с косой черты (/), за которой следует полный URL-адрес страницы. Вы завершите его косой чертой, только если он относится к каталогу, а не к целой странице. Вы можете использовать один или несколько запретить настройки для каждого правила.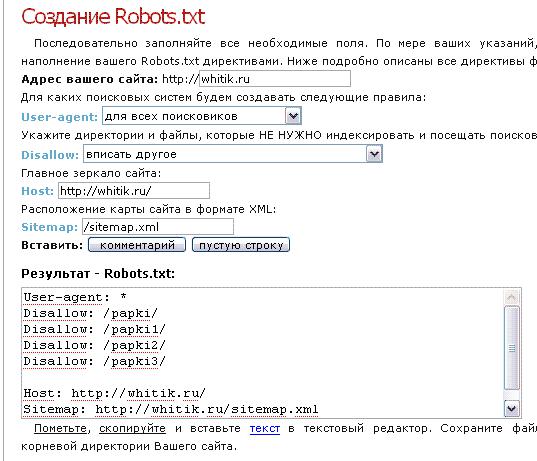 Единственным условием является то, что это должен быть полный URL-адрес. Вы можете использовать ноль или больше, в зависимости от того, что необходимо.
Единственным условием является то, что это должен быть полный URL-адрес. Вы можете использовать ноль или больше, в зависимости от того, что необходимо.Поисковые роботы обрабатывают группы сверху вниз. Как упоминалось ранее, они получают доступ к любой странице или каталогу, для которых явно не установлено значение , запрещающее . Поэтому добавьте Disallow: / под user-agent информация в каждой группе, чтобы запретить этим конкретным пользовательским агентам сканировать ваш сайт.
# Пример как заблокировать DuckDuckBot Агент пользователя: DuckDuckBot Запретить: / #Пример того, как заблокировать более одного пользовательского агента Агент пользователя: DuckDuckBot Агент пользователя: Facebot Запретить: / #Пример того, как заблокировать все поисковые роботы Пользовательский агент: * Disallow: /
Чтобы заблокировать определенный поддомен от всех поисковых роботов, добавьте косую черту и полный URL-адрес поддомена в правило запрета.
# Пример Пользовательский агент: * Disallow: /https://page.yourdomain.com/robots.txt
Если вы хотите заблокировать каталог, выполните тот же процесс, добавив косую черту и имя вашего каталога, но затем закончите еще одной косой чертой.
# Пример Пользовательский агент: * Disallow: /images/
Наконец, если вы хотите, чтобы все поисковые системы собирали информацию на всех страницах вашего сайта, вы можете создать правило allow или disallow , но не забудьте добавить косую черту при использовании разрешить правило . Примеры обоих правил показаны ниже.
# Разрешить пример, чтобы разрешить все поисковые роботы Пользовательский агент: * Позволять: / # Пример запрета, чтобы разрешить все поисковые роботы Пользовательский агент: * Disallow:
4. Загрузите файл robots.txt
Веб-сайты не содержат файл robots.txt автоматически, поскольку он не требуется. Как только вы решите создать его, загрузите файл в корневой каталог вашего сайта. Загрузка зависит от файловой структуры вашего сайта и среды веб-хостинга. Обратитесь к своему хостинг-провайдеру, чтобы узнать, как загрузить файл robots.txt.
Загрузка зависит от файловой структуры вашего сайта и среды веб-хостинга. Обратитесь к своему хостинг-провайдеру, чтобы узнать, как загрузить файл robots.txt.
5. Проверьте правильность работы файла robots.txt
Существует несколько способов проверить правильность работы файла robots.txt. С любым из них вы можете увидеть любые ошибки в вашем синтаксисе или логике. Вот некоторые из них:
- Тестер Google robots.txt в их Search Console.
- Средство проверки и тестирования robots.txt от Merkle, Inc.
- Средство тестирования robots.txt компании Ryte.
Бонус: использование robots.txt в WordPress
Если вы используете WordPress плагин Yoast SEO, вы увидите раздел в окне администратора для создания файла robots.txt.
Войдите в серверную часть своего веб-сайта WordPress и откройте Инструменты в разделе SEO , а затем нажмите Редактор файлов .
Yoast
Следуйте той же последовательности, что и раньше, чтобы установить пользовательские агенты и правила.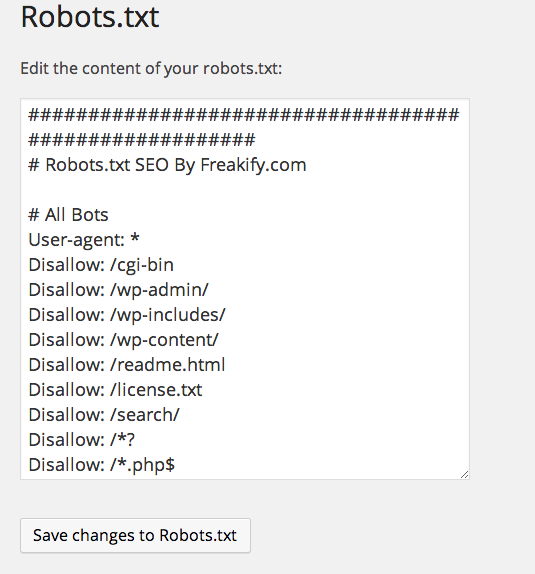 Ниже мы заблокировали поисковые роботы из каталогов WordPress wp-admin и wp-includes, но по-прежнему разрешаем пользователям и ботам видеть другие страницы сайта. Когда закончите, нажмите Сохраните изменения в robots.txt , чтобы активировать файл robots.txt.
Ниже мы заблокировали поисковые роботы из каталогов WordPress wp-admin и wp-includes, но по-прежнему разрешаем пользователям и ботам видеть другие страницы сайта. Когда закончите, нажмите Сохраните изменения в robots.txt , чтобы активировать файл robots.txt.
Отключить сканирование корзины
Поисковые системы, сканирующие ссылки добавления в корзину и нежелательные страницы, могут повредить вашему поисковому рейтингу. Ссылки «Добавить в корзину» могут вызывать более специфические проблемы, поскольку эти страницы не кэшируются, что увеличивает нагрузку на ЦП и память вашего сервера, поскольку страницы повторяются.
К счастью, адаптировать файл robot.txt вашего сайта несложно, чтобы поисковые системы сканировали только те страницы, которые вам нужны. Используйте эти строки кода в файле robots.txt сайта, чтобы адресовать ссылки для добавления в корзину и указать поисковым системам не индексировать их.
Агент пользователя: * Disallow: /*add-to-cart=*
Также рекомендуется изменить файл robots. txt, чтобы запретить индексирование страниц корзины, оформления заказа и моей учетной записи, что можно сделать, добавив строки ниже.
txt, чтобы запретить индексирование страниц корзины, оформления заказа и моей учетной записи, что можно сделать, добавив строки ниже.
Запретить: /корзина/ Запретить: /checkout/ Disallow: /my-account/
Заключение
Мы рассмотрели, как создать файл robots.txt. Эти шаги просты в выполнении и могут сэкономить ваше время и нервы, связанные с сканированием содержимого вашего сайта без вашего разрешения. Создайте файл robots.txt, чтобы заблокировать ненужное сканирование поисковыми системами и ботами.
Если вы размещаете с помощью Liquid Web и у вас есть вопросы по созданию файла robots.txt для вашего веб-сайта, обратитесь за помощью в нашу службу поддержки.
Что такое файл robots.txt? Рекомендации по синтаксису Robot.txt
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции по обходу указываются путем «запрета» или «разрешения» поведения определенных (или всех) пользовательских агентов.
Базовый формат:
Агент пользователя: [имя агента пользователя]Запретить: [строка URL не должна сканироваться]
Вместе эти две строки считаются полным файлом robots.txt — хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т.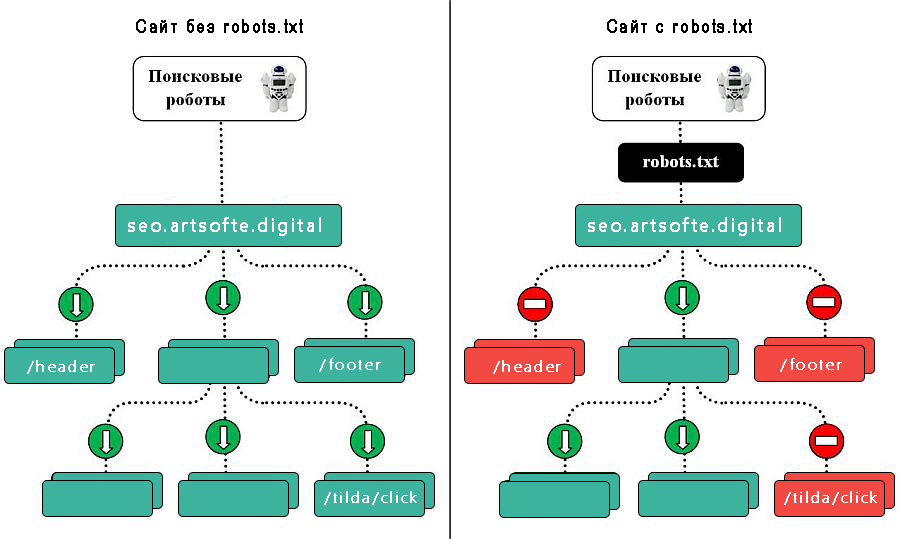 д.).
д.).
В файле robots.txt каждый набор директив агента пользователя отображается как отдельный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами агента пользователя каждое правило запрещает или разрешает Только применяется к пользовательскому агенту (агентам), указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, сканер будет обращать внимание (и следовать директивам) только на наиболее конкретные группа инструкций.
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе пользовательских агентов: *.
Пример robots.txt:
Вот несколько примеров robots. txt в действии для сайта www.example.com:
txt в действии для сайта www.example.com:
URL-адрес файла robots.txt: www.example.com/robots.txt
Блокировка всех поисковых роботов для всего контента
User-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt означает, что все поисковые роботы не будут сканировать какие-либо страницы на www.example. com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контенту
Агент пользователя: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам просканировать все страницы на www.example.com, включая главную страницу.
Блокировка определенного поискового робота из определенной папки
Агент пользователя: Googlebot Запретить: /example-subfolder/
Этот синтаксис указывает только сканеру Google (имя пользовательского агента Googlebot) не сканировать любые страницы, которые содержать строку URL www. example.com/example-subfolder/.
example.com/example-subfolder/.
Блокировка определенного поискового робота на определенной веб-странице
Агент пользователя: Bingbot Запретить: /example-subfolder/blocked-page.html
Этот синтаксис указывает только сканеру Bing (имя пользовательского агента Bing) избегать сканирование конкретной страницы по адресу www.example.com/example-subfolder/blocked-page.html.
Как работает файл robots.txt?
Поисковые системы выполняют две основные функции:
- Сканирование сети в поисках контента;
- Индексирование этого контента, чтобы его можно было предоставить тем, кто ищет информацию.
Для обхода сайтов поисковые системы следуют ссылкам, чтобы перейти с одного сайта на другой — в конечном счете, сканируя многие миллиарды ссылок и веб-сайтов. Такое поведение сканирования иногда называют «пауками».
После перехода на веб-сайт, но до его сканирования поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другие необходимые сведения о файле robots.txt:
(более подробно обсуждается ниже)
Чтобы файл robots.txt можно было найти, он должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен называться «robots.txt» (не Robots.txt, robots.TXT и т. д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваш файл robots.txt. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или скребки адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого сайта (если этот сайт имеет файл robots.txt!). Это означает, что любой может видеть, какие страницы вы сканируете или не хотите, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельные файлы robots.txt. Это означает, что и у blog.example.com, и у example.com должны быть свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать местоположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:

Идентификация критических предупреждений robots.txt с помощью Moz Pro
Функция сканирования сайта Moz Pro проверяет ваш сайт на наличие проблем и выделяет срочные ошибки, которые могут помешать вам появиться в Google.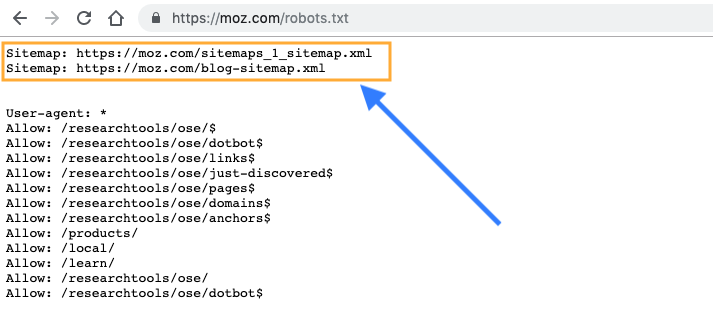 Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Начать мою бесплатную пробную версию
Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt . Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. Среди них:
Агент пользователя: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Запретить:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
Карта сайта: Используется для вызова местоположения любой карты сайта XML, связанной с этим URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов для блокировки или разрешения, файлы robots.txt могут быть довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных параметров URL. Google и Bing поддерживают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Этими двумя символами являются звездочка (*) и знак доллара ($).
- * — это подстановочный знак, представляющий любую последовательность символов
- $ соответствует концу URL-адреса
Здесь Google предлагает большой список возможных синтаксиса сопоставления с образцом и примеры.
Где находится файл robots.txt на сайте?
Всякий раз, когда они заходят на сайт, поисковые системы и другие поисковые роботы (например, поисковый робот Facebook, Facebot) знают, что нужно искать файл robots.txt. Но они будут искать этот файл только в одном конкретном месте : в основном каталоге (обычно это ваш корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует, скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots.
Чтобы ваш файл robots.txt был найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем вам robots.txt?
Файлы robots.txt контролируют доступ поисковых роботов к определенным областям вашего сайта. Хотя это может быть очень очень опасно, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение дублирования контента в поисковой выдаче (обратите внимание, что метароботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей инженерной группы)
- Предотвращение отображения страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карт сайта (карт)
- Предотвращение индексации поисковыми системами определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. д.)
- Указание задержки сканирования, чтобы предотвратить перегрузку ваших серверов, когда сканеры загружают несколько фрагментов контента одновременно
 д.)
д.)Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вам может вообще не понадобиться файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл robots Moz находится по адресу moz.com/robots.txt.
Если страница .txt не отображается, у вас в настоящее время нет (действующей) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создать его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов robots? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Передовой опыт SEO
Убедитесь, что вы не блокируете содержимое или разделы своего веб-сайта, которые хотите просканировать.
Ссылки на страницы, заблокированные robots.txt, не будут переходить. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. е. страницы, не заблокированные с помощью robots.txt, мета-роботов или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой вес ссылок не может быть передан с заблокированной страницы на место назначения ссылки. Если у вас есть страницы, на которые вы хотите передать право собственности, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность сделать это позволяет вам точно настроить сканирование содержимого вашего сайта.
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день. Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить URL-адрес robots.txt в Google.
 txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.Robots.