Содержание
Распространенные ошибки — Вебмастер. Справка
Одним из важнейших свойств интернета является свобода представления информации и большое разнообразие всевозможных форматов. Поисковая система Яндекс стремится корректно индексировать и ранжировать все документы, которые ей доступны. Однако, к сожалению, все еще возможны ситуации, когда та или иная информация будет воспринята нашими роботами не так, как это предполагалось вебмастерами:
Навигация через скрипты. Наиболее распространенным способом размещения ссылки является HTML тег <A>. Но существуют и другие способы навигации между страницами. Например, можно использовать технологии JavaScript или Flash. Робот Яндекса не переходит по таким ссылкам, поэтому следует дублировать ссылки, реализованные при помощи скриптов, обычными текстовыми ссылками.
Использование <iframe>. Для корректного ранжирования документа не рекомендуется использовать тег <iframe>, так как поисковый робот Яндекса не индексирует документы, подгружаемые в него.

Избыточное автоматическое перенаправление (редиректы). По возможности избегайте использования редиректов. Редирект может быть полезен только в том случае, если адреса страниц меняются по техническим причинам и необходимо перенаправить пользователя на новый адрес страницы. Подробно см. в разделе Обработка редиректов.
Адреса страниц. Каждая страница должна быть доступна по единственному и постоянному адресу. Желательно, чтобы адреса страниц сайта не содержали идентификаторы сессий, по возможности они также должны быть избавлены от списков cgi-параметров, заданных в явном виде.
Клоакинг. Избегайте ситуаций, когда поисковый робот индексирует одно содержание страницы, а пользователь при обращении к этой странице получает другое. Например, в версиях сайта для разных регионов, о которых будет рассказано в разделе «Региональность».
Изображения вместо текста. Избегайте создания страниц, не содержащих текст.
Если главная страница сайта выполнена в виде изображения, являющегося ссылкой на основную часть сайта, и сама не содержит текста, это может помешать ранжированию сайта. Это происходит из-за того, что большинство внешних ссылок, как правило, ведут на главную страницу сайта, и если это документ без текста, надежность определения содержания документа несколько уменьшается.Soft 404. Одна из распространенных ошибок заключается в замене сообщения об ошибке 404 (страница не найдена) для несуществующих страниц на страницу-заглушку, которая возвращается с кодом ответа 200 (ОК). В этом случае поисковая система считает, что страница с некорректным адресом существует, и не удаляет ее из своей базы. Это приводит к более медленному индексированию полезных страниц на сайте.
Движок сайта. Следите за корректностью работы программного обеспечения сайта — ошибки в скриптах сайта могут привести к тому, что одни и те же страницы при переходе на них из разных разделов будут иметь разные адреса.
Это может негативно отразиться на индексировании сайта. Кроме того, ошибки в «движках» могут быть использованы злоумышленниками (например, для размещения ссылки на вредоносный сайт).

 Если главная страница сайта выполнена в виде изображения, являющегося ссылкой на основную часть сайта, и сама не содержит текста, это может помешать ранжированию сайта. Это происходит из-за того, что большинство внешних ссылок, как правило, ведут на главную страницу сайта, и если это документ без текста, надежность определения содержания документа несколько уменьшается.
Если главная страница сайта выполнена в виде изображения, являющегося ссылкой на основную часть сайта, и сама не содержит текста, это может помешать ранжированию сайта. Это происходит из-за того, что большинство внешних ссылок, как правило, ведут на главную страницу сайта, и если это документ без текста, надежность определения содержания документа несколько уменьшается. Это может негативно отразиться на индексировании сайта. Кроме того, ошибки в «движках» могут быть использованы злоумышленниками (например, для размещения ссылки на вредоносный сайт).
Это может негативно отразиться на индексировании сайта. Кроме того, ошибки в «движках» могут быть использованы злоумышленниками (например, для размещения ссылки на вредоносный сайт).Узнавать об ошибках индексирования, если таковые возникают, можно в сервисе Яндекс Вебмастер.
Примечание.
Чем проще и понятнее будет устроен ваш сайт, тем лучше он будет индексироваться.
К следующему разделу
Написать в службу поддержки
отличия и особенности — SEO-словарь веб-студии Муравейник
Автор статьи
Андрей Буйлов
Подробнее об авторе
В данной статье рассмотрим различия в индексации Яндекса и Google и почему в разных поисковиках может быть проиндексировано разное количество страниц. Подписчик спрашивает: «По какой причине в индексе Яндекса и Google количество страниц моего сайта разное? К примеру, в Яндексе 155, а в Google 230. Насколько это плохо? Как определить, почему так случилось? Как исправить?».
Насколько это плохо? Как определить, почему так случилось? Как исправить?».
Почему необходимо попадание страниц в индекс
Индекс — это некоторая поисковая база, из которой потом поисковая система выбирает старнички, чтобы они участвовали в ранжировании (то есть участвовали в конкуренции за первые места) по тем или иным запросам.
Если страница вылетела из индекса либо в него не попала, то, соответственно, нигде не будет участвовать — и это плохо. Потому что если она хоть как-то худо-бедно в индекс залетела, то какой-нибудь запрос все равно на себя притянет, по нему выйдет. Пусть он даже будет супермикрочастотный, все равно хоть какой-то трафик может на себя собирать.
Потому за этим действительно нужно следить. У каждой поисковой системы существуют разные критерии по добавлению страниц в индекс и сохранении их там.
Есть четкие, например, и Яндекс, и Google выбрасывают дубли, а также страницы, закрытые от индексации тем или иным способом (и это очевидно, вебмастеры сами сказали поисковиком, что их не надо индексировать) и т.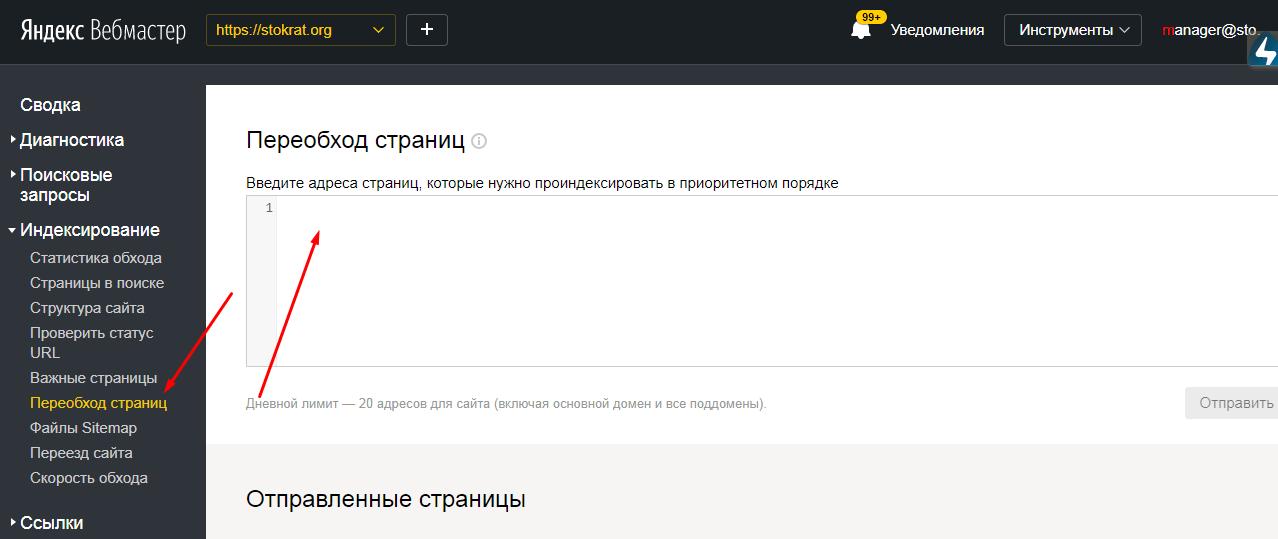 д.
д.
Но есть и более мягкие критерии:
в Яндексе — это те страницы, которые раньше называли недостаточно качественные, а сейчас — малополезные, малоценные либо невостребованные. И у Яндекса свой набор правил, по которым эти страницы вылетают;
в Google такие страницы попадают в «просканировано, но не проиндексировано». То есть поисковик об этих страницах узнал, но пока решил в индекс не добавлять.
В обе эти категории входят страницы, которые по этим «мягким», не всегда понятным критериям не попадают в индекс. И в основном различие в индексации Яндекса или Google относится к этим категориям страниц, которые вылетели и не попали в индекс по неоднозначным критериям.
Особенности индексирования в Яндексе и Google
В Яндексе «недостаточно качественное» поменялось на одтельные два блока — малополезное/малоценное и невостребованное — и две категории как бы объединены, но по факту это 2 разных проблемы.
Первая, когда они малополезны, малоценны — это про их качество: мало контента, либо он настолько некачественный или недостаточный по мнению Яндекса, что из-за этого страница не попадает в индекс. Обычно это карточки товаров без фотографий, документ практически без контента — только заголовок, а больше ничего нет, или заголовок и один комментарий. Вот такие часто вылетают. То есть просто страница настолько проигрывает конкурирующим, что не может быть показана по какому-либо запросу, потому что бесполезна.
А вот вторая часть — невостребованы — это абсолютно про другое. Такая страница не нужна, нет тех запросов, по которым она будет ранжироваться, люди такое не спрашивают, поэтому даже нет смысла ее добавлять. И здесь вопрос в спросе.
Например, у вас есть теговая страница на сайте. И вы берете и добавляете заголовок в Вордстат, можно даже без разметки (кавычек, восклицательных знаков), а просто в широком соответствии. Даже можно регион не выставлять, а выбрать всю страну. И смотрите, а есть ли в таком режиме хоть какой-то мизерный спрос на это. И если хотя бы 10-20 человек так спрашивают, то страницу можно оставлять и под «невостребована» она не попадет. Если там 0, то лучше такую теговую страницу вообще не создавать, не внедряйте искусственную семантику на сайт, это вам только навредит. В ряде случаев это может пройти, но потом все равно такие страницы вылетят и сайту будет плохо.
И смотрите, а есть ли в таком режиме хоть какой-то мизерный спрос на это. И если хотя бы 10-20 человек так спрашивают, то страницу можно оставлять и под «невостребована» она не попадет. Если там 0, то лучше такую теговую страницу вообще не создавать, не внедряйте искусственную семантику на сайт, это вам только навредит. В ряде случаев это может пройти, но потом все равно такие страницы вылетят и сайту будет плохо.
Иногда, конечно, бывает, что может повезти и получится. Есть опыт, когда сгенерировали всё на всё, немного доделали и оно все-таки зашло — но это довольно редкая ситуация.
В Google нет такой детализации. Данный поисковик не особо любит объяснять, почему он именно так решил и именно эти страницы в категорию «просканировано, но не проиндексировано» отправил. И, в общем, в справке у них это тоже описано довольно абстрактно. В Яндексе тоже раньше про недостаточно качественно толком написано не было, сейчас хоть расписали в новой формулировке, спасибо им за это. А вот у Google четких критериев нет.
А вот у Google четких критериев нет.
Что делать
Таким образом, все отличие в количестве проиндексированных страниц заключается в том, что критерии отличаются у разных поисковиков. Так что вам нужно заходить и в отчет Яндекса по просканивроанным и проиндексирвоанным старницам, смотреть, почему вылетели именно они: недостаточно качественные, дубли или еще какие-то причины, они случайно стали закрыты или не случайно. И обратить внимание, есть ли проблемы, какие, и постараться исправить их: сделать документы более качественными, а если не востребованы (спроса нет), то просто удалить, и в Яндекс и Google они не должны попадать.
И в Google тоже заходить в отчет «просканировано, но не проиндексировано» и смотреть, какие страницы туда попали, затем пробовать их либо прокачать, либо закрыть от индексации.
Поэтому в целом такое отличие, как правило, не несет ничего плохого, но если очень сильно отличается количество страниц, то нужно проверять и там, и там и как-то исправлять.
Справочник по ошибкам индексирования — веб-мастер. Справка
- Ошибки загрузки
- Ошибки обработки
Список ошибок, которые выдает робот Яндекса, если ему не удается скачать документ с вашего сайта.
| Ошибка | Описание |
|---|---|
| Соединение прервано при попытке скачать документ. После нескольких попыток загрузка была остановлена. | |
| Превышен предельный размер текста | Документ слишком длинный, попробуйте разбить его на части. |
| Документ заблокирован от индексации в robots.txt | Документ не проиндексирован, поскольку вы или другой администратор заблокировали его от сканирования в robots.txt. |
| Неверный адрес документа | Адрес документа не соответствует стандарту HTTP. |
| Формат документа не поддерживается | Сервер не указывает формат документа или указывает его неправильно, либо указанный формат не поддерживается Яндексом. |
| Ошибка DNS | Ошибка DNS. IP-адрес хоста не может быть определен по его имени. |
| Код состояния HTTP не соответствует стандарту | Сервер возвращает код состояния, не соответствующий стандарту HTTP. |
| Недопустимый HTTP-заголовок | HTTP-заголовок не соответствует стандарту (включая расширение от Яндекса). |
| Не удалось подключиться к серверу | Не удалось подключиться к серверу. |
| Недопустимая длина сообщения | Длина сообщения не указана или указана неправильно. |
| Неверная кодировка | Заголовок Transfer-Encoding установлен неправильно или кодировка неизвестна. |
| Неверный объем переданных данных | Длина передаваемых данных не соответствует указанной. Передача данных завершается до или продолжается после получения указанного объема данных. |
| Превышена максимальная длина заголовка HTTP | Превышен предел длины заголовков HTTP. Это может быть вызвано попыткой передать слишком много файлов cookie. |
| Превышена максимальная длина URL-адреса | Длина URL-адреса превышает ограничение. |
Список ошибок, возвращаемых роботами в случае успешной загрузки документа, но невозможности дальнейшей обработки.
| Ошибка | Описание |
|---|---|
Документ содержит метатег noindex | |
| Неверная кодировка | Документ содержит символы, не соответствующие заявленной кодировке. |
| Документ является журналом сервера | Документ распознан как журнал сервера. Если это страница, созданная для посетителей веб-сайта, попробуйте изменить ее так, чтобы она не была похожа на журнал сервера. |
| Недопустимый формат документа | Робот обнаружил, что документ не соответствует заявленному формату (HTML, PDF, DOC, RTF, SWF, XLS, PPT). |
| Кодировка не распознана | Кодировка документа не распознана. Возможно, документ не содержит текста или содержит текст в разных кодировках. |
| Язык не поддерживается | Язык документа не распознан или не поддерживается. Для получения подробной информации обо всех поддерживаемых языках перейдите в соответствующий раздел справки.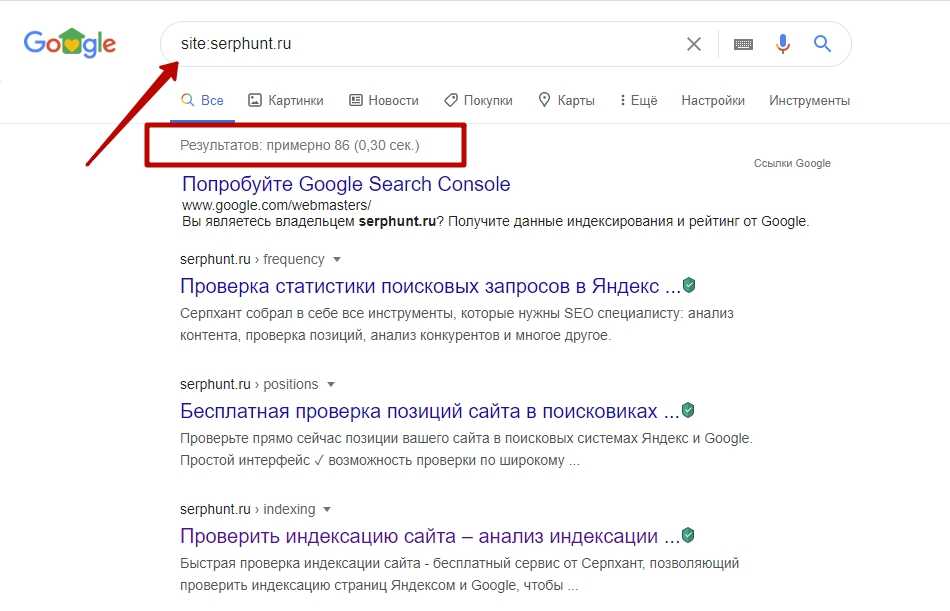 |
| Документ не содержит текста | Сервер возвращает пустой документ. |
| Слишком много ссылок | Количество ссылок на странице превышает лимит. |
| Ошибка извлечения | Произошла ошибка при распаковке потока данных GZIP или DEFLATE с сервера. |
| Пустой ответ сервера | Сервер вернул ответ нулевой длины. Свяжитесь с администратором хостинг-сервера. |
| Документ неканонический | Элемент link в коде документа содержит атрибут rel , для которого задано значение canonical и он указывает на другой (канонический) документ. Канонический документ был проиндексирован вместо текущего документа. Канонический документ был проиндексирован вместо текущего документа. |
Если страницы доступны для робота и отправлены на переиндексацию, но не появляются в поиске более двух недель, заполните форму ниже:
Как добавить сайт в поиск?
Страницы сайта появляются в результатах поиска после Яндекса Система, которая сканирует страницы сайта и загружает их в свою базу данных.
«}}»> посетите сайт. Чтобы робот сканировал и загружал страницы:
- Шаг 1. Сделать страницы сайта видимыми для робота
Сообщить роботу Яндекса об изменениях на сайте можно несколькими способами:
6
Метод Автоматизация Рекомендации Файл Sitemap Создайте и обновите файл. Это позволит вам отправлять информацию обо всех URL-адресах сайта. Робот может обработать содержимое файла при следующем обходе сайта.Сканирование страниц с тегом Яндекс.Метрики Установите тег Яндекс.Метрики на свой сайт и привяжите его к сайту в Яндекс.Вебмастере. Таким образом вы можете сообщить нам о популярных страницах. Переиндексация страницы — На странице Индексация → Переиндексация страницы в Яндекс.Вебмастере вы можете подать роботу сигнал на посещение определенных страниц сайта. Вы можете использовать этот метод, чтобы сообщить об изменениях на самых важных или новых страницах. Протокол IndexNow Помогает автоматически сообщать об обновленных, новых и удаленных страницах. Требуются навыки работы с API. Совет. Поддерживайте качество сайта. Чем больше полезных страниц будет найдено и загружено в базу роботом, тем больше вероятность того, что они будут отображаться в результатах поиска. Подробнее читайте в разделе Признаки некачественного сайта.
- Шаг 2. Скрыть закрытый контент
Тип страницы Что делать? Страницы действий. Например, добавление товара в корзину или сравнение товаров. Запрет индексации страницы Корзина с товаром. Личная информация. Например, адрес доставки и номер телефона клиента. Ограничение доступа к данным путем аутентификации пользователей на сайте Страница сайта, которая дублирует содержимое другой страницы того же сайта, но имеет другой URL. «}}»>. Например, URL с дополнительными параметрами (https://example.com/page?id=1).Укажите, какая страница предпочтительнее для включения в результаты поиска
 Робот может обработать содержимое файла при следующем обходе сайта.
Робот может обработать содержимое файла при следующем обходе сайта.
 «}}»>. Например, URL с дополнительными параметрами (https://example.com/page?id=1).
«}}»>. Например, URL с дополнительными параметрами (https://example.com/page?id=1).После того, как робот просканирует сайт, страницы могут появиться в поиске в течение двух недель.
Кроме того, роботы могут узнавать о сайте, открывая ссылки с других ресурсов. Это может занять некоторое время и не гарантирует, что робот просканирует все страницы, которые вы хотите показать в результатах поиска.
Подробнее о том, как работает поиск Яндекса
Чтобы отслеживать индексацию и позиции сайта в результатах поиска, добавьте сайт в Яндекс.Вебмастер. В Яндекс.Вебмастере вы также можете посмотреть, как сайт отображается в результатах поиска и какие улучшения вы можете внести — откройте страницу Просмотр в результатах поиска.
Убедитесь, что:
Страницы доступны для робота (используйте инструмент проверки ответа сервера).
