Содержание
15) Индексирование в базах данных
Что такое индексирование?
INDEXING – это метод структуры данных, который позволяет вам быстро извлекать записи из файла базы данных. Индекс – это небольшая таблица, имеющая всего два столбца. Первый столбец содержит копию первичного или потенциального ключа таблицы. Его второй столбец содержит набор указателей для хранения адреса дискового блока, где хранится это конкретное значение ключа.
Индекс –
- Принимает ключ поиска в качестве ввода
- Эффективно возвращает коллекцию совпадающих записей.
Из этого руководства по индексированию СУБД вы узнаете:
- Типы индексации
- Первичная индексация
- Вторичный индекс
- Индекс кластеризации
- Что такое многоуровневый индекс?
- B-Tree Index
- Преимущества индексации
- Недостатки индексации
Типы индексации
Индексация базы данных определяется на основе ее атрибутов индексации. Два основных типа методов индексации:
Два основных типа методов индексации:
- Первичная индексация
- Вторичная индексация
Первичная индексация
Первичный индекс – это упорядоченный файл с фиксированной длиной и двумя полями. Первое поле – это тот же первичный ключ, а второе поле указывает на этот конкретный блок данных. В первичном индексе всегда существует отношение один к одному между записями в таблице индекса.
Первичная индексация также делится на два типа.
- Плотный индекс
- Разреженный индекс
Плотный индекс
В плотном индексе запись создается для каждого поискового ключа, оцененного в базе данных. Это помогает быстрее выполнять поиск, но требует больше места для хранения записей индекса. В этом индексировании записи метода содержат значение ключа поиска и указывают на реальную запись на диске.
Разреженный индекс
Это индексная запись, которая отображается только для некоторых значений в файле. Разреженный индекс поможет вам решить проблемы плотного индексирования. В этом методе методики индексирования диапазон столбцов индекса хранит один и тот же адрес блока данных, и когда данные должны быть извлечены, адрес блока будет выбран.
В этом методе методики индексирования диапазон столбцов индекса хранит один и тот же адрес блока данных, и когда данные должны быть извлечены, адрес блока будет выбран.
Однако разреженный индекс хранит записи индекса только для некоторых значений ключа поиска. Ему требуется меньше места, меньше затрат на обслуживание для вставки и удаления, но он медленнее по сравнению с плотным индексом для поиска записей.
Пример разреженного индекса
Вторичный индекс
Вторичный индекс может быть создан с помощью поля, которое имеет уникальное значение для каждой записи, и это должен быть ключ-кандидат. Он также известен как некластеризованный индекс.
Этот двухуровневый метод индексации базы данных используется для уменьшения размера отображения первого уровня. Для первого уровня из-за этого выбирается большой диапазон чисел; размер отображения всегда остается небольшим.
Пример вторичной индексации
В базе данных банковского счета данные хранятся последовательно с помощью acc_no; Вы можете найти все счета в конкретном отделении банка ABC.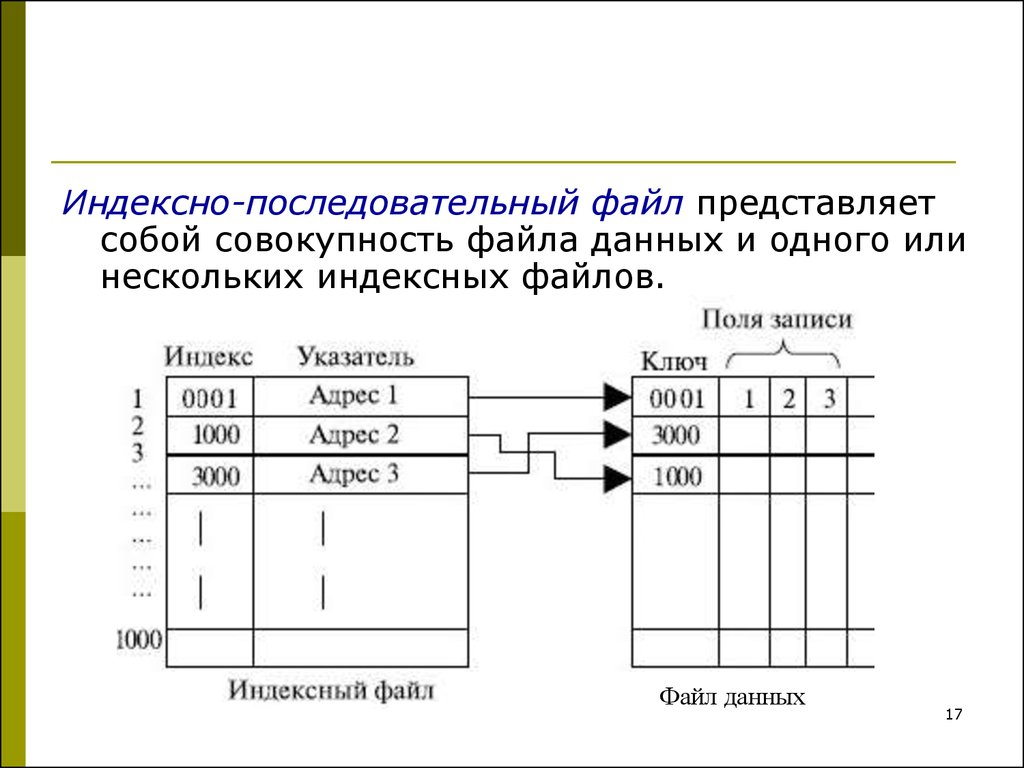
Здесь вы можете иметь вторичный индекс для каждого поискового ключа. Индексная запись – это точка записи в корзину, которая содержит указатели на все записи с определенным значением ключа поиска.
Индекс кластеризации
В кластеризованном индексе сами записи хранятся в индексе, а не в указателях. Иногда индекс создается для столбцов не первичного ключа, которые могут быть не уникальными для каждой записи. В такой ситуации вы можете сгруппировать два или более столбцов, чтобы получить уникальные значения и создать индекс, который называется кластеризованным индексом. Это также поможет вам быстрее идентифицировать запись.
Пример:
Давайте предположим, что компания набрала много сотрудников в различных отделах. В этом случае кластерная индексация должна быть создана для всех сотрудников, принадлежащих к одному отделу.
Он рассматривается в одном кластере, а индексные точки указывают на кластер в целом. Здесь Department _no – неуникальный ключ.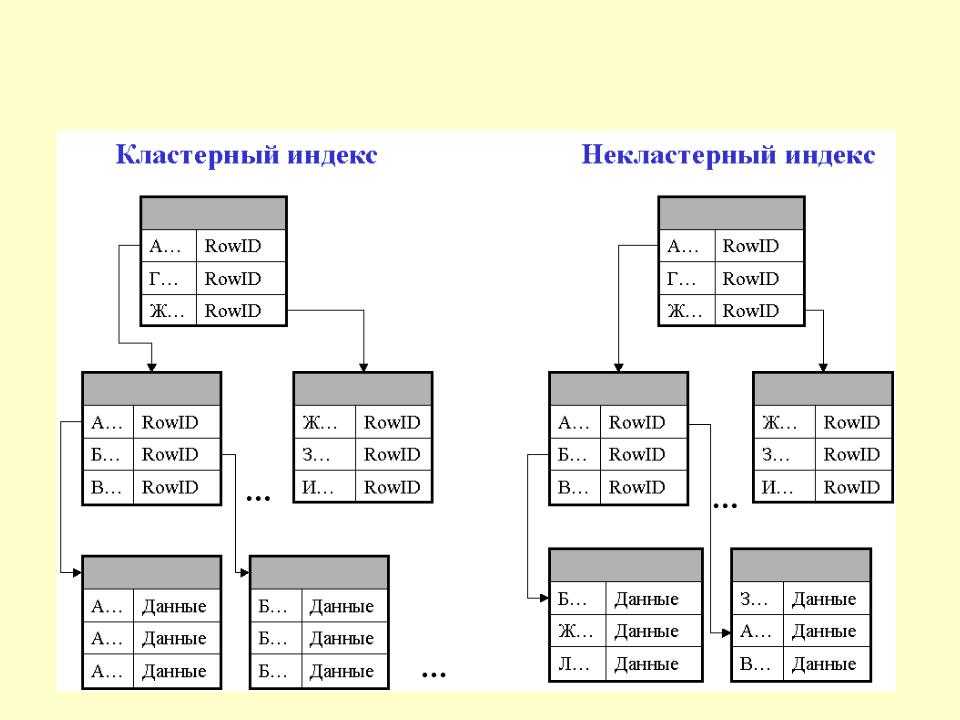
Что такое многоуровневый индекс?
Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти. В этом методе индексации вы можете сократить число обращений к диску, чтобы сократить любую запись и сохранить ее на диске в виде последовательного файла, а также создать разреженную базу для этого файла.
B-Tree Index
Индекс B-дерева – это широко используемые структуры данных для индексации. Это метод многоуровневого индексного формата, который сбалансирован бинарными деревьями поиска. Все конечные узлы дерева B обозначают фактические указатели данных.
Более того, все конечные узлы связаны между собой списком ссылок, что позволяет дереву B поддерживать как произвольный, так и последовательный доступ.
- Ведущие узлы должны иметь от 2 до 4 значений.
- Каждый путь от корня до листа в основном одинаковой длины.
- Нелистовые узлы, кроме корневого, имеют от 3 до 5 дочерних узлов.
- Каждый узел, который не является корнем или листом, имеет от n / 2] до n дочерних узлов.

Преимущества индексации
Важные плюсы / преимущества индексирования:
- Это помогает сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных, поэтому вам не нужно обращаться к строке в базе данных из структуры индекса.
- Предлагает более быстрый поиск и поиск данных для пользователей.
- Индексирование также помогает сократить табличное пространство, поскольку вам не нужно ссылаться на строку в таблице, поскольку нет необходимости хранить ROWID в индексе. Таким образом вы сможете уменьшить табличное пространство.
- Вы не можете сортировать данные в ведущих узлах, так как значение первичного ключа классифицирует их.
Недостатки индексации
Важными недостатками / минусами индексации являются:
- Для выполнения системы управления базами данных индексирования вам необходим первичный ключ в таблице с уникальным значением.
- Вы не можете выполнять какие-либо другие индексы для проиндексированных данных.
- Вам не разрешено разбивать организованную по индексу таблицу.
- Индексирование SQL Снижение производительности в запросах INSERT, DELETE и UPDATE.

Резюме:
- Индексирование – это небольшая таблица, состоящая из двух столбцов.
- Два основных типа методов индексации: 1) первичная индексация 2) вторичная индексация.
- Первичный индекс – это упорядоченный файл с фиксированной длиной и двумя полями.
- Первичная индексация также делится на два типа: 1) плотный индекс 2) разреженный индекс.
- В плотном индексе запись создается для каждого поискового ключа, оцененного в базе данных.
- Метод разреженной индексации помогает решить проблемы плотной индексации.
- Вторичный индекс – это метод индексации, ключ поиска которого определяет порядок, отличный от последовательного порядка файла.
- Индекс кластеризации определяется как файл данных заказа.
- Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти.
- Самым большим преимуществом индексирования является то, что оно помогает вам сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных.
- Самый большой недостаток для выполнения системы управления базами данных индексации, вам нужен первичный ключ в таблице с уникальным значением.
что это, как настроить и ускорить индексирование в поисковых системах
Как только вы создадите сайт для своего бизнеса, однозначно столкнетесь с понятием «индексация в поисковых системах». В статье постараемся как можно проще рассказать, что это такое, зачем нужно и как сделать, чтобы индексация проходила быстро и успешно.
Что такое индексация в поисковых системах
Под индексацией понимают добавление информации о сайте или странице в базу данных поисковой системы. Фактически поисковую базу можно сравнить с библиотечным каталогом, куда внесены данные о книгах. Только вместо книг здесь веб-страницы.
Если совсем просто, индексация — процесс сбора данных о сайте. Пока информация о новой странице не окажется в базе, ее не будут показывать по запросам пользователей. Это означает, что ваш сайт никто не увидит.
Пока информация о новой странице не окажется в базе, ее не будут показывать по запросам пользователей. Это означает, что ваш сайт никто не увидит.
Индексация сайта — базовая часть работы по продвижению ресурса. Только потом уже добавляются все остальные элементы по оптимизации сайта. Если у веб-страницы будут проблемы с индексированием, ваш бизнес не получит клиентов с сайта и понесет убытки.
Как проходит процесс индексации
Давайте посмотрим, как происходит индексирование страниц сайта.
-
Поисковый робот (краулер) обходит ресурсы и находит новую страницу.
-
Данные анализируются: происходит очистка контента от ненужной информации, заодно формируется список лексем. Лексема — совокупность всех значений и грамматических форм слова в русском языке.
-
Вся собранная информация упорядочивается, лексемы расставляются по алфавиту. Заодно происходит обработка данных, поисковая машина относит информацию к определенным тематикам.
-
Формируется индексная запись.

Это стандартный процесс индексации документов для поисковых систем. При этом у «Яндекса» и Google существуют небольшие отличия в технических моментах, про это мы расскажем дальше.
Читайте также:
Отличия SEO под Яндекс и Google
Технологии и алгоритмы индексации
Сразу стоит оговориться, что точные алгоритмы индексирования — закрытая коммерческая информация. Поисковые системы тщательно охраняют эти данные.
Поэтому в этом разделе расскажем про алгоритмы только в общих чертах
Вначале нужно отметить: «Яндекс» при индексации ориентируется в основном на файл robots.txt, а Google на файл sitemap.xml.
Основным отличием является использование технологии Mobile-first. Она подразумевает первоочередное сканирование и индексацию мобильной версии сайта. В индексе сохраняется именно мобильная версия. Получается, что если ваша страница при показе на мобильных устройствах будет содержать недостаточно нужной информации или в целом проигрывать основной версии сайта по качеству. Так, что она может даже не попасть в индекс.
Она подразумевает первоочередное сканирование и индексацию мобильной версии сайта. В индексе сохраняется именно мобильная версия. Получается, что если ваша страница при показе на мобильных устройствах будет содержать недостаточно нужной информации или в целом проигрывать основной версии сайта по качеству. Так, что она может даже не попасть в индекс.
Также Google подтверждает наличие «краулингового бюджета» — регулярности и объема посещения сайта роботом. Чем больше краулинговый бюджет, тем быстрее новые страницы будут попадать в индекс. К сожалению, точных данных о способах расчета этого показателя представители компании не раскрывают. По наблюдениям специалистов, тут оказывают сильное влияние возраст сайта и частота обновлений.
«Яндекс»
В «Яндексе» основной версией считается десктопная версия сайта, поэтому в первую очередь сканируется именно она. Официально краулингового бюджета здесь нет, поэтому индексирование происходит вне зависимости от траста и других показателей вашего ресурса. Еще может влиять количество выложенных в сеть на данный момент страниц. Речь про страницы, которые конкуренты и другие пользователи выкладывают одновременно с вами.
Еще может влиять количество выложенных в сеть на данный момент страниц. Речь про страницы, которые конкуренты и другие пользователи выкладывают одновременно с вами.
Приоритет при индексации имеют сайты с большой посещаемостью. Чем выше посещаемость, тем быстрее новая страница окажется в поисковой выдаче.
Также Яндекс не индексирует документы с весом более 10 Мб. Учитывайте это при создании страниц сайта. Советуем также почитать кейс: Продвижение сайта REG.RU за процент от продаж.
Заказать продвижение сейчас
Сайт
Телефон
Как настроить индексацию сайта
В целом сайт должен индексироваться самостоятельно, даже если вы не будете ничего предпринимать для этого. Но если вы разберетесь с настройкой, то получите быструю и надежную индексацию и в случае возникновения проблем с сайтом будете понимать, в чем причина.
Первое, что стоит сделать, — создать файл robots. txt. У большей части систем управления сайтом (CMS) есть автоматизированные решения для его генерации. Но нужно как минимум понимать, какие директивы используются в этом файле. На скриншоте показан стандартный документ для сайта на WordPress:
txt. У большей части систем управления сайтом (CMS) есть автоматизированные решения для его генерации. Но нужно как минимум понимать, какие директивы используются в этом файле. На скриншоте показан стандартный документ для сайта на WordPress:
Типовой файл robots.txt сайта на WordPress
Обратите внимание, что здесь нет директивы host: она не используется «Яндексом» с 2018 года, а Google никогда ее и не замечал. Но при этом до сих пор встречаются рекомендации по использованию этой директивы, и многие по инерции вставляют ее в файл.
В таблице ниже указаны основные параметры, используемые в robots.txt:
|
Директива |
Зачем используется |
|
User-agent: |
Показывает поискового робота, для которого установлены правила |
|
Disallow: |
Запрещает индексацию страниц |
|
sitemap: |
Показывает путь к файлу sitemap. 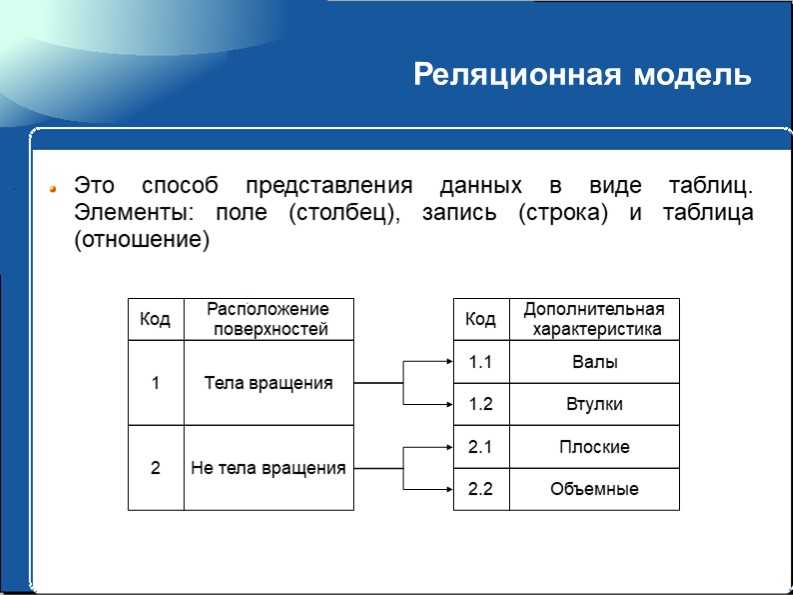 xml xml
|
|
Clean-param: |
Указывает на страницы, где часть ссылок не нужно учитывать, например UTM-метки |
|
Allow: |
Разрешает индексацию документа |
|
Crawl-delay: |
Указывает поисковому роботу минимальное время ожидания между посещением предыдущей и следующей страницы сайта |
Рассмотрим более подробно код на следующем скриншоте. User-agent показывает, что директивы предназначены для «Яндекса». А директива Disallow показывает, какие страницы не должны попасть в индекс. Это технические документы, в частности админ-панель сайта и плагины.
Фрагмент кода robots.txt
Более подробно о том, каким должен быть robots.txt для сайта, можно прочитать в справке сервиса «Яндекс. Вебмастер».
Вебмастер».
Далее делаем файл sitemap.xml: фактически это карта сайта, созданная в формате xml. Сделано это для упрощения считывания данных поисковыми роботами. В файл вносятся все страницы, которые должны быть проиндексированы.
Для правильной индексации файл не должен превышать 50 Мб или 50000 записей. Если нужно проиндексировать больше адресов, делают несколько файлов, которые в свою очередь перечисляются в файле с индексом sitemap.
На практике сайты, работающие с бизнесом, редко имеют потребность в подобном решении — просто имейте в виду такую особенность.
На скриншоте показан фрагмент кода sitemap.xml, сгенерированный одним из плагинов WordPress:
Так выглядит файл sitemap.xml «изнутри»
Остается разобраться, как создать файл sitemap.xml. Решение зависит от CMS вашего сайта. Если он сделан не на популярном «движке», придется делать все руками. Можно воспользоваться онлайн-генератором: например, mySitemapgenerator. Вводим адрес сайта и через короткое время получаем готовый файл.
Вводим адрес сайта и через короткое время получаем готовый файл.
Для сайтов на CMS WordPress сделать такую карту сайта еще проще. У вас все равно уже установлен один из плагинов для SEO-оптимизации ресурса. Заходим в настройки плагина и включаем генерацию sitemap.xml. На скриншоте показан пример включения карты сайта через плагин AIOSEO:
Плагин для настройки sitemap.xml в WP
Чтобы сайт максимально быстро индексировался, следует обеспечить перелинковку. Тогда поисковый робот без проблем будет переходить по страницам и своевременно найдет новый документ.
Далее необходимо выполнить настройку индексирования в «Яндекс.Вебмастер» и Google Search Console.
Читайте также:
Подробный гайд по оптимизации сайта на WordPress
Как ускорить индексацию сайта
В начале статьи мы рассказывали, как настроить индексирование. Теперь поговорим о том, как ускорить это процесс. В целом современные поисковые роботы довольно быстро собирают информацию о ресурсе: по моим наблюдениям, новые страницы появляются в индексе уже через 20–40 минут. Но так бывает не всегда, потому что может произойти сбой или еще какая-то нештатная ситуация, и страница будет индексироваться очень долго.
Теперь поговорим о том, как ускорить это процесс. В целом современные поисковые роботы довольно быстро собирают информацию о ресурсе: по моим наблюдениям, новые страницы появляются в индексе уже через 20–40 минут. Но так бывает не всегда, потому что может произойти сбой или еще какая-то нештатная ситуация, и страница будет индексироваться очень долго.
Появление адреса в списке проиндексированных страниц «Яндекс.Вебмастера» не совпадает с моментом индексации. На практике URL оказывается в индексе намного раньше, а в кабинете только при очередном апдейте.
При этом есть ситуации, когда индексирование нужно ускорить:
-
Сайт выходит из-под фильтров.
-
Молодой ресурс обладает небольшим краулинговым бюджетом.
В обоих случаях рекомендуется подтолкнуть поисковых роботов. Отметим, что для «Яндекса» и Google подход будет разным.
Начнем с отечественной поисковой системы.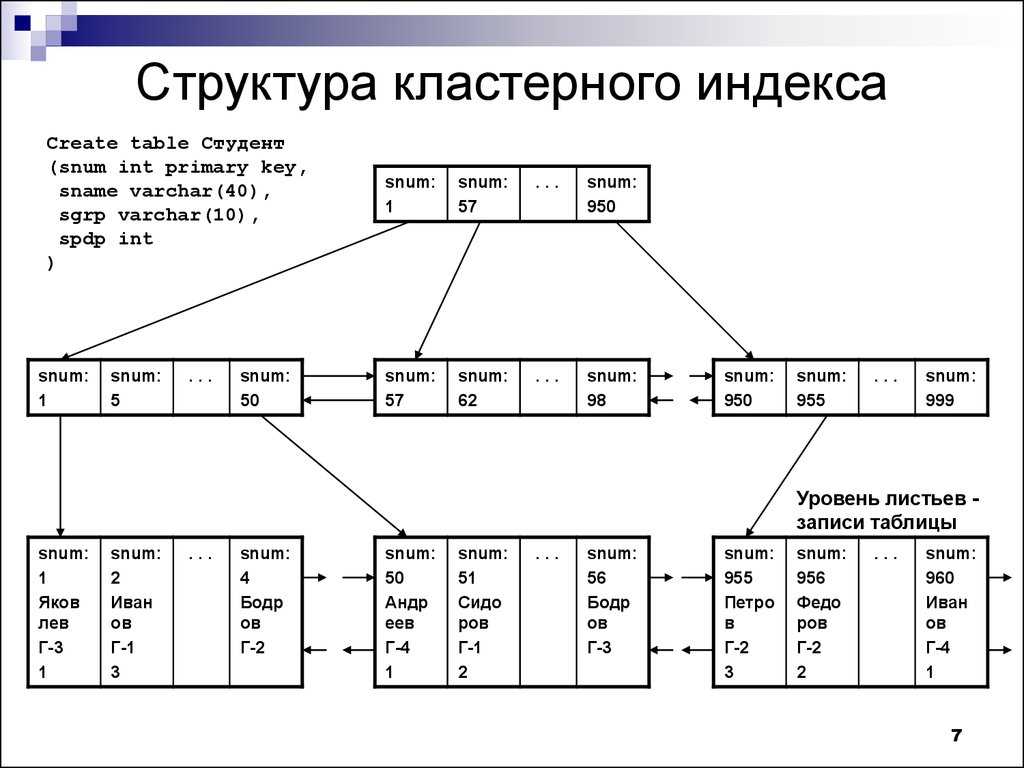 Заходим в «Яндекс.Вебмастер» и в меню слева, во вкладке «Индексирование», находим ссылку «Переобход страниц». Переходим по ней:
Заходим в «Яндекс.Вебмастер» и в меню слева, во вкладке «Индексирование», находим ссылку «Переобход страниц». Переходим по ней:
Яндекс.Вебмастер — подраздел «Переобход страниц» в меню «Индексирование»
На следующей вкладке вводим URL новой страницы, после чего жмем кнопку «Отправить». Отследить статус заявки можно в расположенном ниже списке:
Процесс отправки страниц сайта на переобход
Так можно поступать не только с новыми страницами, но и в случае изменения уже имеющихся на сайте. Только помните, что количество отправок в сутки ограничено, причем все зависит от возраста и траста сайта.
В самом «Вебмастере» предлагается для ускорения индексирования подключать переобход по счетчику «Яндекс.Метрики». Это не самое лучшее решение. Дело в том, что поисковый робот может ходить по всем страницам — даже тем, которые не нужно индексировать, причем в приоритете будут наиболее посещаемые документы. Может получиться ситуация, когда старые страницы робот обошел, а новые не заметил. Или вообще в поиск попадут технические страницы: например, страница авторизации или корзина интернет-магазина.
Или вообще в поиск попадут технические страницы: например, страница авторизации или корзина интернет-магазина.
У Google ускорение индексации состоит из двух этапов. Сначала идем в Search Console, где на главной странице вверху находится поле «Проверка всех URL». В него вставляем адрес страницы, которую нужно проиндексировать. Далее нажимаем на клавиатуре «Enter».
Поле для ввода URL страницы, которую мы хотим добавить для индексирования
Ждем около минуты. Сервис нам будет показывать вот такое окно:
Всплывающее окно в Search Console о получении данных из индекса
Следующая страница выглядит вот так:
Как видите написано, что URL отсутствует в индексе, поэтому нажимаем на кнопку «Запросить индексирование»
Некоторое время поисковая машина будет проверять, есть ли возможность проиндексировать адрес:
Техническое окно с сообщением о проверке
Если все прошло успешно, Google сообщает, что страница отправлена на индексирование.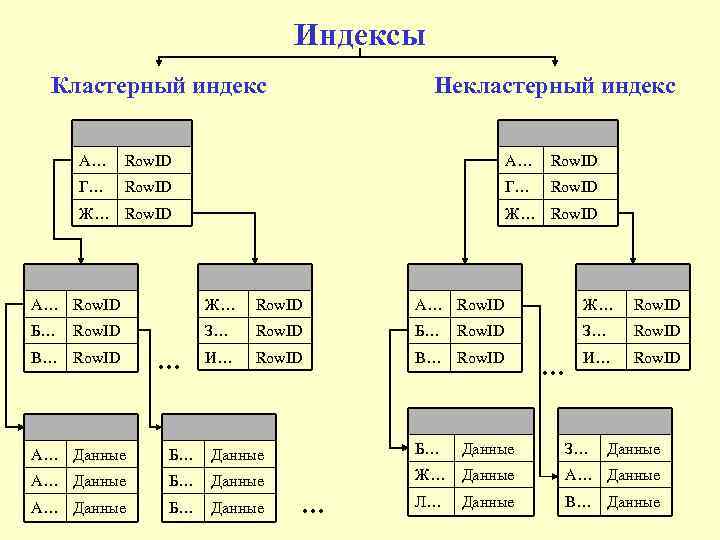 Остается только дождаться результатов.
Остается только дождаться результатов.
Сообщение об отправке запроса. Обратите внимание, что не стоит повторно отправлять на индексацию один и тот же URL
При отправке на индексирование страниц сайта, следует помнить, что Google до сих пор очень ценит ссылки. Поэтому, существует альтернативный способ ускорения индексации — Twitter.
Сразу после публикации страницы идем в Twitter и делаем твит с нужным адресом. Буквально через полчаса URL будет уже в индексе Google.
Лучше всего использовать эти обе способа совместно. Так будет надежнее.
Читайте также:
Внешняя оптимизация сайта: как продвигать сайт с помощью сторонних ресурсов
Как запретить индексацию страниц
В некоторых случаях может потребоваться не проиндексировать, а наоборот запретить индексацию. К примеру, вы только создаете страницу и на ней нет нужной информации, или вообще сайт в разработке и все страницы — тестовые и недоработанные.
К примеру, вы только создаете страницу и на ней нет нужной информации, или вообще сайт в разработке и все страницы — тестовые и недоработанные.
Существует несколько способов, чтобы «спрятать» страницу от поисковых роботов. Рассмотрим наиболее удобные варианты.
Способ первый
Если вам нужно скрыть всего один документ, можно добавить в код страницы метатег Noindex. Эта команда дает поисковому роботу команду не индексировать документ. Размещают его между тегами <head>. Вот код, который нужно разместить:
<meta name=»robots» content=»noindex» />
Большая часть CMS позволяют использовать этот метод в один клик, предлагая готовые решения. У WordPress, например, для этого имеется отдельная строчка в настройках редактора, а в «1С-Битрикс» путем настроек раздела и конкретной страницы.
Способ второй
Заключается в редактировании файла robots.txt. Разберем несколько примеров закрытия страниц от индексирования.
Начнем с полного закрытия сайта от индексирования. На скриншоте код, который выполняет эту задачу: звездочка говорит, что правило работает для всех поисковых роботов. Косая черта (слеш) показывает, что директива Disallow относится ко всему сайту.
Полное закрытие сайта от индексирования
Если нам нужно закрыть ресурс от индексирования в конкретной поисковой системе, указываем название ее краулера. На скриншоте показано закрытие от робота «Яндекса».
Закрываем сайт от индексации «Яндексом»
Когда нужно избежать индексирования конкретной страницы, после слеша указываем параметры пути к документу. Пример показан на скриншоте:
Закрытие одной страницы в Robots.txt
Для Google все перечисленные способы работают аналогично. С разницей лишь в том, что если страницу или целый сайт нужно скрыть конкретно от этой поисковой системы, в User-agent указывают атрибут Googlebot.
Закрытие страниц от индексации используется довольно часто.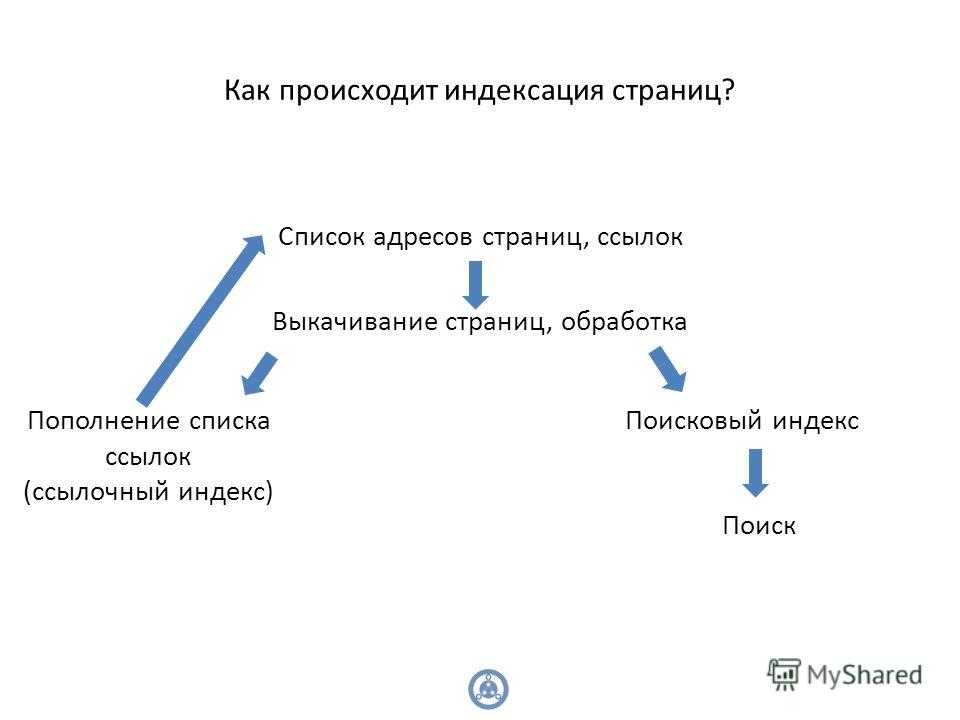 В процессе развития своего веб-ресурса вам часто придется делать новые страницы, или переделывать имеющиеся. Чтобы избежать попадания в поисковую выдачу не готовых к показу страниц, имеет смысл закрывать их от индексации.
В процессе развития своего веб-ресурса вам часто придется делать новые страницы, или переделывать имеющиеся. Чтобы избежать попадания в поисковую выдачу не готовых к показу страниц, имеет смысл закрывать их от индексации.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
Распространенные ошибки индексации
Чаще всего проблемы возникают из-за случайного закрытия сайта от индексирования. У меня был случай, когда клиент при самостоятельном обновлении плагинов как-то внес изменения в файл robots.txt, и сайт исчез из поисковой выдачи. Поэтому при всех действиях, которые связаны с этим файлом, обязательно проверяйте, нет ли изменений в директивах.
Для проверки можно использовать инструмент Яндекс.Вебмастер «Анализ robots.txt».
Анализатор robots.txt — бесплатный и полезный инструмент проверки файла на корректность записанных директив
В некоторых случаях могут индексироваться технические страницы. К примеру, на WordPress при размещении изображений в виде медиафайла поисковый робот может индексировать каждую картинку в качестве отдельной страницы. В таком случае делаем редирект с этой страницы на тот документ, где изображение будет выводиться.
Читайте также:
Как сделать редирект — подробное руководство по настройке и использованию
Иногда встречаются проблемы с индексированием из-за неполадок на сервере или хостинге, но это уже нужно решать с администратором сервера, что выходит за рамки этой статьи.
Медленное индексирование может быть следствием наложения фильтров со стороны поисковых систем. Посмотрите, нет ли предупреждений в сервисах для вебмастеров: если они есть, устраните проблемы.
Посмотрите, нет ли предупреждений в сервисах для вебмастеров: если они есть, устраните проблемы.
Как проверить индексацию сайта
Проверить индексацию сайта можно несколькими способами. Самым простой — в поисковой строке браузера набрать адрес сайта с оператором «site» или «url». Выглядит это вот так: «site: kokoc.com». На скриншоте показан запрос с проиндексированной страницей.
Проверка индексирования в поисковой системе
Если страница еще не вошла в индекс, вы увидите вот такую картину. Проверка в Google производится аналогично.
Страница не проиндексирована
Также можно посмотреть статус документа в «Яндекс.Вебмастер». Для этого находим в меню «Индексирование» и переходим на «Страницы в поиске».
Меню «Яндекс.Вебмастер»
Внизу страницы будут три вкладки. Нас интересуют «Все страницы», там можно увидеть статус документа, последнее посещение и заголовок.
Проиндексированные страницы
Обязательно посмотрите вкладку «Исключенные страницы». Тут вы увидите, какие документы оказались вне поискового индекса. Также указана причина исключения.
Тут вы увидите, какие документы оказались вне поискового индекса. Также указана причина исключения.
Исключенные страницы
При любых сложностях с индексированием в первую очередь следует смотреть конфигурационные файлы robots.txt и sitemap.xml. Если там все в порядке, проверяем, нет ли фильтров, и в последнюю очередь обращаемся к администратору хостинга.
Выводы
Индексация страниц сайта сейчас происходит в самые короткие сроки. При правильной настройке документы могут попадать в индекс поиска уже через полчаса после размещения.
Настройка сводится к созданию правильных конфигурационных файлов и созданию удобных условий для поискового робота для перехода по страницам сайта. Вот какие шаги нужно сделать для правильной индексации:
-
Создаем и настраиваем файл robots.txt.
-
Генерируем файл sitemap.xml.
-
Регистрируем сайт в сервисах Google Search Console и «Яндекс. Вебмастер».
-
Каждый раз после размещения статьи или новой страницы отправляем URL на проверку.
-
Используем дополнительные инструменты: размещение ссылок в Twitter и на других трастовых ресурсах.
 Вебмастер».
Вебмастер».
После этого вероятность возникновения каких-либо проблем с индексированием будет стремиться к нулю. Теперь нужно наращивать позиции в топе — но это уже совсем другая история…
Продвижение сайта в ТОП-10
- Оплата по дням нахождения в ТОП
- Подбираем запросы, которые приводят реальных покупателей!
Как работает индексация | Учебное пособие от Chartio
Что делает индексация?
Индексация — это способ привести неупорядоченную таблицу в порядок, максимально повышающий эффективность запроса при поиске.
Когда таблица не проиндексирована, порядок строк, скорее всего, не будет различим для запроса как оптимизированного каким-либо образом, и поэтому вашему запросу придется искать строки линейно. Другими словами, запросы должны будут выполнять поиск по каждой строке, чтобы найти строки, соответствующие условиям. Как вы понимаете, это может занять много времени. Просмотр каждой строки не очень эффективен.
Например, в таблице ниже представлена таблица в вымышленном источнике данных, которая полностью неупорядочена.
| идентификатор_компании | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1,3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Если бы мы выполнили следующий запрос:
SELECT Идентификатор компании, единицы, себестоимость единицы продукции ИЗ index_test КУДА идентификатор_компании = 18
База данных должна будет выполнить поиск по всем 17 строкам в порядке их появления в таблице, сверху вниз, по одной за раз.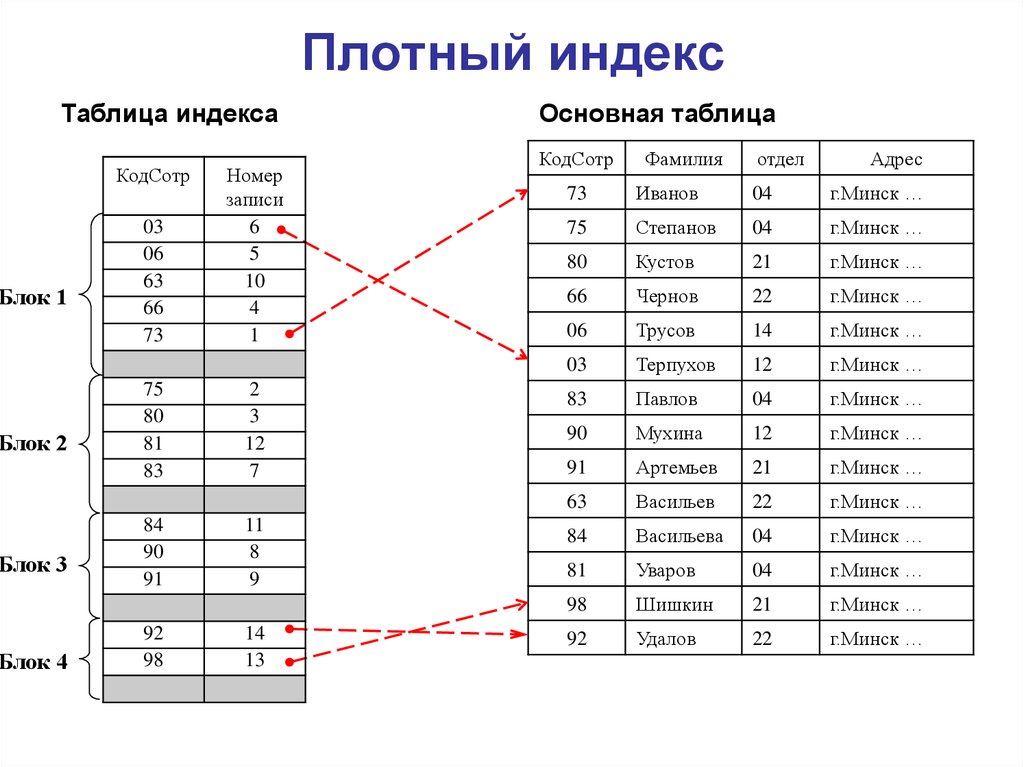 Таким образом, для поиска всех потенциальных экземпляров
Таким образом, для поиска всех потенциальных экземпляров company_id номер 18, база данных должна просмотреть всю таблицу на наличие всех вхождений 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере усложнения данных в конечном итоге может произойти следующее: таблица с одним миллиардом строк соединяется с другой таблицей с одним миллиардом строк; запрос теперь должен выполнять поиск в удвоенном количестве строк, что требует в два раза больше времени.
Вы можете видеть, как это становится проблематичным в нашем вечно насыщенном данными мире. Таблицы увеличиваются в размерах, а время выполнения поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Что делает индексация, так это настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, чтобы помочь оптимизировать производительность запроса.
С индексом в столбце company_id таблица будет, по существу, «выглядеть» так:
| company_id | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id номер 18 и возвращать все запрошенные столбцы для этой строки, а затем переходить к следующей строке. Если в следующей строке
Если в следующей строке comapny_id номер также равен 18, тогда он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равно 20, запрос прекращает поиск и завершается.
Как работает индексация?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса для оптимизации производительности запроса: это было бы нереалистично. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных. Тип структуры данных, скорее всего, B-Tree. Несмотря на множество преимуществ B-дерева, основное преимущество для наших целей заключается в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для приведенной выше таблицы будет содержать только номера company_id .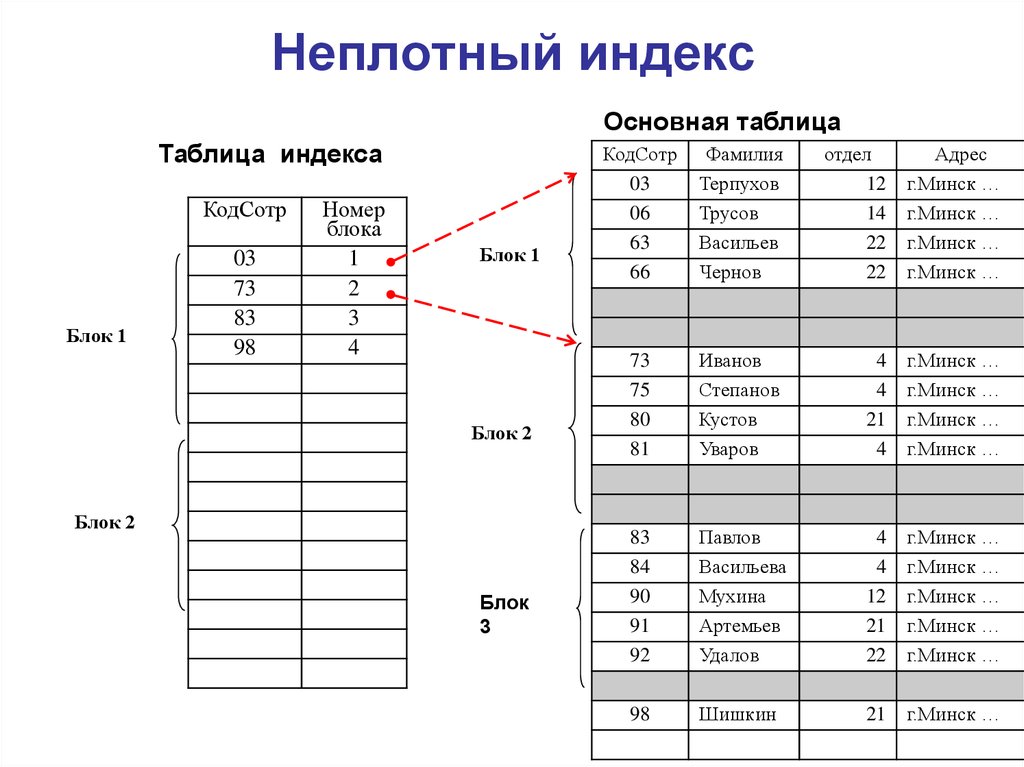 Units и
Units и unit_cost не будут храниться в структуре данных.
Откуда база данных узнает, какие еще поля в таблице нужно вернуть?
Индексы базы данных также будут хранить указатели, которые являются просто справочной информацией о расположении дополнительной информации в памяти. В основном индекс держит company_id и домашний адрес этой конкретной строки на диске памяти. На самом деле индекс будет выглядеть так:
| company_id | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С помощью этого индекса запрос может искать только строки в столбце company_id , которые имеют 18, а затем с помощью указателя можно перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.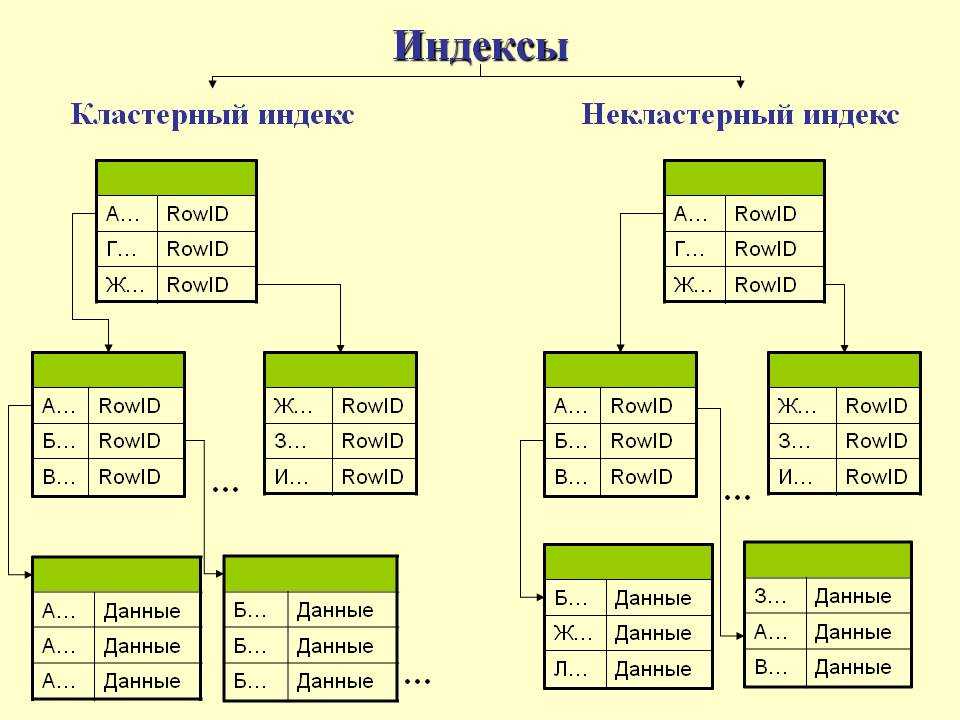 Затем запрос может перейти к таблице, чтобы получить поля для столбцов, запрошенных для строк, которые соответствуют условиям.
Затем запрос может перейти к таблице, чтобы получить поля для столбцов, запрошенных для строк, которые соответствуют условиям.
Если бы поиск был представлен визуально, он выглядел бы так:
Резюме
- Индексация добавляет структуру данных со столбцами для условий поиска и указатель
- Указатель — это адрес на диске памяти строки с остальной информацией
- Структура данных индекса отсортирована для оптимизации эффективности запросов
- Запрос ищет определенную строку в индексе; индекс относится к указателю, который найдет остальную информацию.
- Индекс уменьшает количество строк, которые должен искать запрос, с 17 до 4.
Индексирование в базах данных | Набор 1
Индексирование — это способ оптимизировать производительность базы данных за счет минимизации количества обращений к диску, необходимых при обработке запроса. Это метод структуры данных, который используется для быстрого поиска и доступа к данным в базе данных.
Индексы создаются с использованием нескольких столбцов базы данных.
- Первый столбец — Ключ поиска , который содержит копию первичного ключа или потенциального ключа таблицы. Эти значения хранятся в отсортированном порядке, чтобы можно было быстро получить доступ к соответствующим данным.
Примечание. Данные могут храниться или не храниться в отсортированном порядке. - Второй столбец — это Data Reference или Pointer , который содержит набор указателей, содержащих адрес блока диска, где можно найти это конкретное значение ключа.
Индексация имеет различные атрибуты:
- Типы доступа : относится к типу доступа, такому как поиск по значению, доступ к диапазону и т. д.
- Время доступа : относится ко времени, необходимому для поиска определенных данных. элемент или набор элементов.
- Время вставки : Время, необходимое для поиска подходящего места и вставки новых данных.
- Время удаления : Время, необходимое для поиска элемента и его удаления, а также для обновления структуры индекса.
- Space Overhead : Относится к дополнительному пространству, необходимому для индекса.

Как правило, существует два типа механизма организации файлов, за которыми следуют методы индексации для хранения данных:
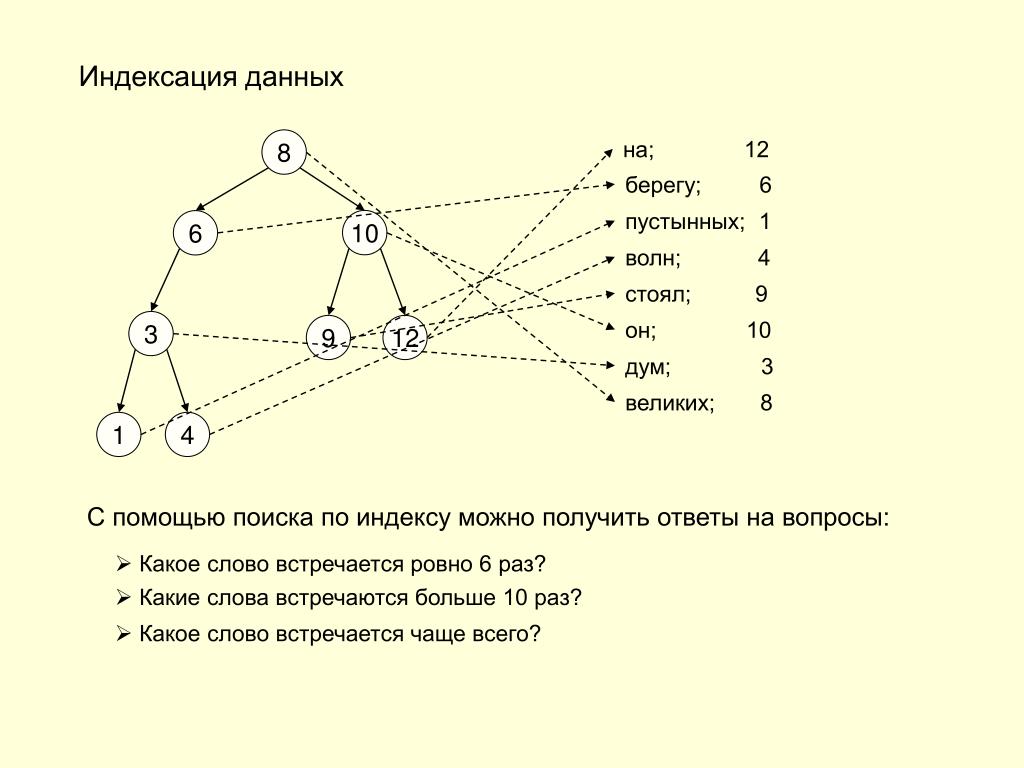
1. Последовательная организация файлов или упорядоченный индексный файл: В этом случае индексы основаны на отсортированном порядок значений. Как правило, это быстрый и более традиционный тип механизма хранения. Эти упорядоченные или последовательные организации файлов могут хранить данные в плотном или разреженном формате:
(i) Плотный индекс:
- Для каждого значения ключа поиска в файле данных существует запись индекса.
- Эта запись содержит ключ поиска, а также ссылку на первую запись данных с этим значением ключа поиска.

(ii) Разреженный индекс:
- Запись индекса появляется только для нескольких элементов в файле данных. Каждый элемент указывает на блок, как показано.
- Чтобы найти запись, мы находим индексную запись с наибольшим значением ключа поиска, меньшим или равным искомому значению ключа поиска.
- Мы начинаем с той записи, на которую указывает индексная запись, и действуем по указателям в файле (то есть последовательно), пока не найдем нужную запись.
- Требуемое количество обращений = log₂(n)+1, (здесь n=количество блоков, полученных индексным файлом)
Ассортимент ковшей. Сегменты, которым присваивается значение, определяются функцией, называемой хеш-функцией.
В основном существует три метода индексирования:
- Кластерное индексирование
- Некластерное или вторичное индексирование
- Многоуровневое индексирование
хранения, известного как кластерное индексирование. Используя кластерное индексирование, мы можем снизить стоимость поиска, поскольку несколько записей, связанных с одним и тем же объектом, хранятся в одном месте, а также часто происходит объединение более двух таблиц (записей).
Используя кластерное индексирование, мы можем снизить стоимость поиска, поскольку несколько записей, связанных с одним и тем же объектом, хранятся в одном месте, а также часто происходит объединение более двух таблиц (записей).
Индекс кластеризации определен для упорядоченного файла данных. Файл данных упорядочен по неключевому полю. В некоторых случаях индекс создается по столбцам, не являющимся первичными ключами, которые могут не быть уникальными для каждой записи. В таких случаях, чтобы быстрее идентифицировать записи, мы сгруппируем два или более столбца вместе, чтобы получить уникальные значения и создать из них индекс. Этот метод известен как индекс кластеризации. По сути, записи со схожими характеристиками группируются вместе, и для этих групп создаются индексы.
Например, студенты, обучающиеся в каждом семестре, группируются вместе. то есть 1 студентов -го семестра, 2 -го -го семестра студентов, 3 -го -го семестра студентов и т. д. группируются.
Кластерный индекс, отсортированный по имени (ключу поиска)
Первичное индексирование:
Это тип кластерного индексирования, при котором данные сортируются в соответствии с ключом поиска и первичным ключом таблица базы данных используется для создания индекса. Это формат индексации по умолчанию, который обеспечивает последовательную организацию файлов. Поскольку первичные ключи уникальны и хранятся в отсортированном виде, выполнение операции поиска достаточно эффективно.
2. Некластеризованное или вторичное индексирование
Некластеризованный индекс просто сообщает нам, где находятся данные, т. е. дает нам список виртуальных указателей или ссылок на место, где данные фактически хранятся. Данные физически не хранятся в порядке индекса. Вместо этого данные присутствуют в листовых узлах. Например. страница содержания книги. Каждая запись дает нам номер страницы или местоположение сохраненной информации.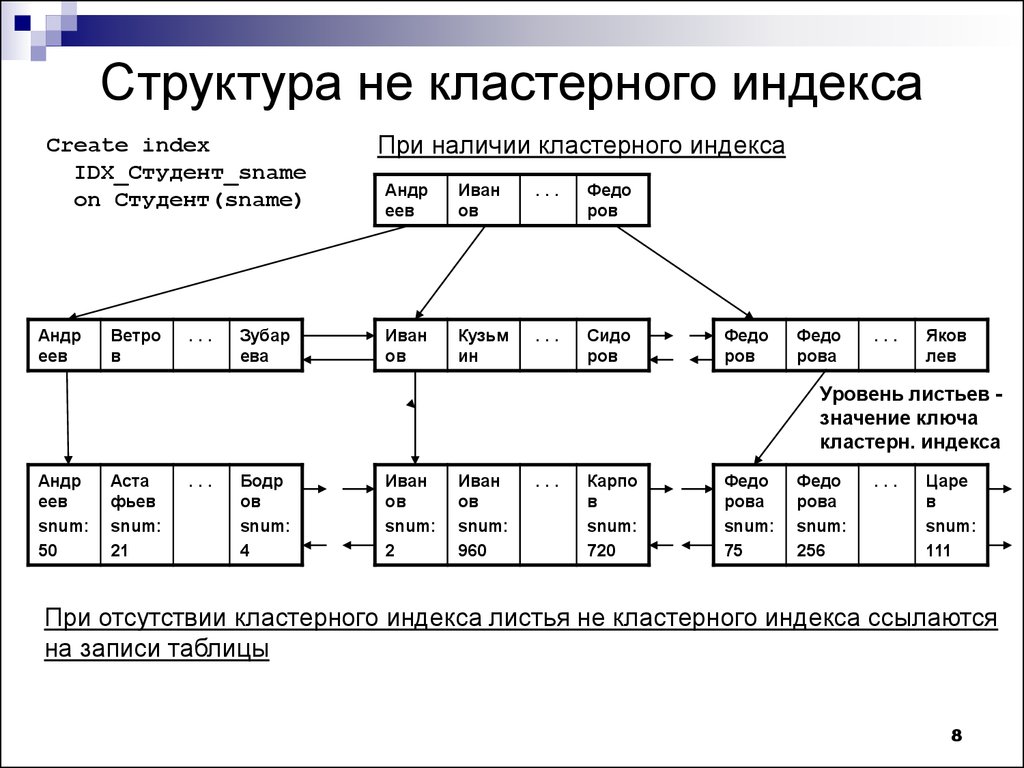 Фактические данные здесь (информация на каждой странице книги) не организованы, но у нас есть упорядоченная ссылка (страница содержания) на то, где фактически лежат точки данных. У нас может быть только плотное упорядочение в некластеризованном индексе, поскольку разреженное упорядочение невозможно, потому что данные физически не организованы соответствующим образом.
Фактические данные здесь (информация на каждой странице книги) не организованы, но у нас есть упорядоченная ссылка (страница содержания) на то, где фактически лежат точки данных. У нас может быть только плотное упорядочение в некластеризованном индексе, поскольку разреженное упорядочение невозможно, потому что данные физически не организованы соответствующим образом.
Это требует больше времени по сравнению с кластеризованным индексом, потому что выполняется некоторая дополнительная работа для извлечения данных путем дальнейшего следования указателю. В случае кластеризованного индекса данные находятся непосредственно перед индексом.
3. Многоуровневое индексирование
С ростом размера базы данных растут и индексы. Поскольку индекс хранится в основной памяти, одноуровневый индекс может стать слишком большим для хранения при многократном доступе к диску. Многоуровневая индексация разделяет основной блок на различные более мелкие блоки, чтобы они могли храниться в одном блоке.